Scikit-learn(通常缩写为sklearn)是一个流行的Python机器学习库,用于数据挖掘和数据分析任务。它建立在NumPy、SciPy和matplotlib等科学计算/可视化库的基础上,提供了丰富的工具和算法,用于处理各种机器学习问题,包括分类、回归、聚类、降维、特征选择、模型选择等。Scikit-learn的主要特点和功能有:解决各种机器学习和数据挖掘问题。
简单易用:sklearn提供了一些直观的API,使得用户可以轻松地加载数据、选择合适的模型、训练模型并进行预测。这使得初学者和专业人士都能够快速上手。
广泛的算法:库中包含了各种机器学习算法的实现,包括线性回归、逻辑回归、决策树、支持向量机、随机森林、K均值聚类、主成分分析等等。
数据预处理:sklearn提供了丰富的数据预处理工具,包括特征缩放、标准化、处理缺失值、特征选择和生成新特征等功能,以提高模型性能。
交叉验证:库中包含交叉验证工具,帮助用户评估模型的性能,避免过拟合,并选择合适的超参数。
可扩展性:sklearn允许用户自定义估算器(estimator),这样可以轻松地添加自己的算法或扩展现有算法。
集成方法:除了单独的机器学习算法外,sklearn还提供了集成方法,如Bagging和Boosting,以提高模型的性能和稳定性。
开源和活跃的社区:sklearn是一个开源项目,拥有庞大的用户社区和开发者社区,因此可以轻松获取支持、文档和示例代码。
总的来说,sklearn是一个功能强大、易于使用的Python机器学习库,适用于各种应用场景,从简单的数据分析到复杂的机器学习项目。无论您是初学者还是专业人士,它都是一个强大的工具,可用于解决各种机器学习和数据挖掘问题。
从这一章开始,我们正式进入python机器学习的学习,sklearn当然是python中的主流机器学习的库;
Python 生态系统中有许多流行的库如 Scikit-learn 提供了丰富的机器学习功能。然而,随着应用需求的多样化,有时标准库并不能满足所有需求。mlxtend(机器学习扩展库)应运而生,它提供了一组扩展功能,旨在补充现有机器学习库的不足,如数据预处理、分类器集成、频繁项集和关联规则挖掘等。mlxtend 轻量级且易于集成,是提升机器学习模型能力的有力工具。本文将详细介绍 mlxtend 库的安装、功能、基本与高级操作及其实际应用。
mlxtend 可以通过 Python 的包管理器 pip 安装。首先确保已经安装了 Scikit-learn,因为 mlxtend 大部分功能都基于该库。

通过检查版本来判断是否安装成功
一,mlxtend库的介绍与基础使用:
主要功能

- 分类器集成(Ensemble Learning)
- 数据预处理与转换
- 特征选择与特征提取
- 频繁项集与关联规则挖掘
- 可视化工具(如决策边界、学习曲线等)
基础功能
分类器集成
分类器集成(Ensemble Learning)是通过结合多个分类器的预测来提高模型的泛化能力。mlxtend 提供了如 StackingClassifier 和 VotingClassifier 等集成方法,能够将多个模型的优势结合起来。
StackingClassifier
以下是一个简单的 StackingClassifier 示例,将逻辑回归、KNN 和决策树结合为一个集成模型:
from mlxtend.classifier import StackingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
# 加载数据集
X, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 定义分类器
clf1 = LogisticRegression()
clf2 = KNeighborsClassifier()
clf3 = DecisionTreeClassifier()
# 使用逻辑回归作为堆叠分类器的元分类器
stack = StackingClassifier(classifiers=[clf1, clf2, clf3], meta_classifier=LogisticRegression())
# 训练模型
stack.fit(X_train, y_train)
# 预测
y_pred = stack.predict(X_test)
# 输出准确率
print(f"StackingClassifier 准确率: {accuracy_score(y_test, y_pred)}")
在这个示例中,将三个不同的分类器组合在一起,利用它们的多样性来提升模型的预测性能。
VotingClassifier
VotingClassifier 通过投票机制将多个分类器的预测结果结合起来,适合在多分类问题中使用。
以下是使用投票分类器的示例:
from mlxtend.classifier import VotingClassifier
# 定义投票分类器
voting_clf = VotingClassifier(classifiers=[clf1, clf2, clf3], voting='hard')
# 训练和预测
voting_clf.fit(X_train, y_train)
y_pred = voting_clf.predict(X_test)
# 输出准确率
print(f"VotingClassifier 准确率: {accuracy_score(y_test, y_pred)}")
通过 VotingClassifier,能够得到更为稳定的预测结果,特别是在分类器之间差异较大的情况下。
频繁项集和关联规则挖掘
mlxtend 还提供了频繁项集(Frequent Itemsets)和关联规则(Association Rules)的挖掘功能,这在市场篮分析等领域应用广泛。
频繁项集挖掘
apriori 算法用于找出频繁出现的项集。以下是使用 apriori 算法的示例:
import pandas as pd
from mlxtend.frequent_patterns import apriori
# 模拟交易数据
data = pd.DataFrame([
[1, 1, 0, 0],
[1, 0, 1, 0],
[1, 1, 1, 1],
[0, 0, 1, 1]
], columns=['牛奶', '面包', '啤酒', '尿布'])
# 使用 apriori 找出频繁项集
frequent_itemsets = apriori(data, min_support=0.5, use_colnames=True)
print(frequent_itemsets)
该示例展示了如何通过 apriori 算法找到支持度高于0.5的频繁项集。
关联规则挖掘
在找出频繁项集后,可以进一步挖掘其中的关联规则:
from mlxtend.frequent_patterns import association_rules
# 生成关联规则
rules = association_rules(frequent_itemsets, metric="confidence", min_threshold=0.7)
print(rules)
通过关联规则挖掘,可以揭示商品间的潜在关联关系,如“买啤酒的人更可能买尿布”。
进阶功能
特征选择与提取
mlxtend 还提供了多种特征选择和提取方法,找到最具代表性的特征。
例如,可以使用 SequentialFeatureSelector 来进行逐步特征选择:
from mlxtend.feature_selection import SequentialFeatureSelector as SFS
from sklearn.linear_model import LogisticRegression
# 逐步特征选择
sfs = SFS(LogisticRegression(), k_features=2, forward=True, floating=False, scoring='accuracy', cv=5)
sfs.fit(X_train, y_train)
print(f"选择的特征: {sfs.k_feature_idx_}")
通过逐步选择,可以选择出对模型预测最有贡献的特征,进而提高模型的性能。
分类器比较
mlxtend 提供了简单的分类器比较工具,允许开发者在多个模型间进行准确率和性能的比较。
以下是一个比较不同分类器性能的示例:
from mlxtend.evaluate import bias_variance_decomp
from sklearn.ensemble import RandomForestClassifier
# 比较偏差和方差
clf_rf = RandomForestClassifier()
avg_expected_loss, avg_bias, avg_var = bias_variance_decomp(clf_rf, X_train, y_train, X_test, y_test, loss='0-1_loss')
print(f"Random Forest 偏差: {avg_bias}, 方差: {avg_var}")
通过这个工具,开发者可以深入分析模型的偏差-方差权衡问题。
二,sklearn快速入门例子——1个简单的分类器(著名的鸢尾花数据集)
1,导入包与数据
### 导包 ###
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split # 用于随机划分训练集与测试数据集
from sklearn.preprocessing import StandardScaler,LabelEncoder
from sklearn.decomposition import PCA
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.metrics import *
from mlxtend.plotting import plot_decision_regions
总之,初学者需要知道每一步大概做什么,主要用到什么函数,又分别主要在哪些库中导入
接着查看我们的数据:
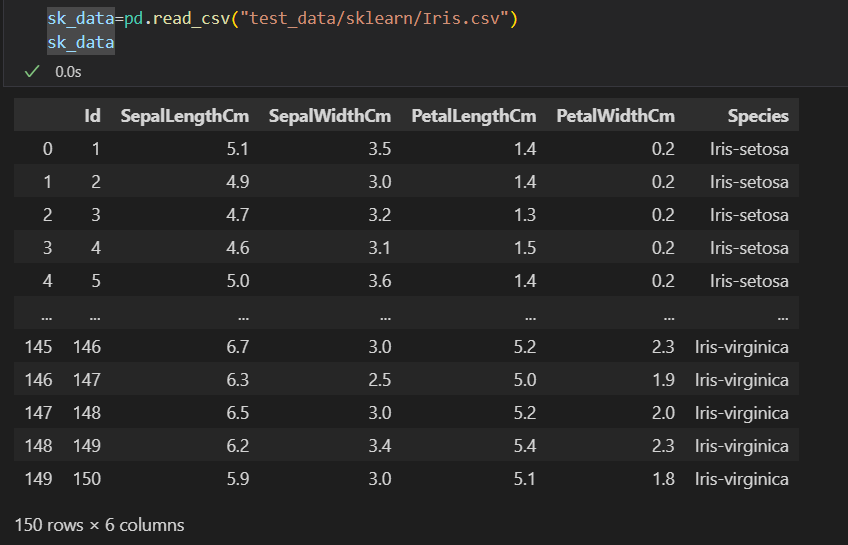
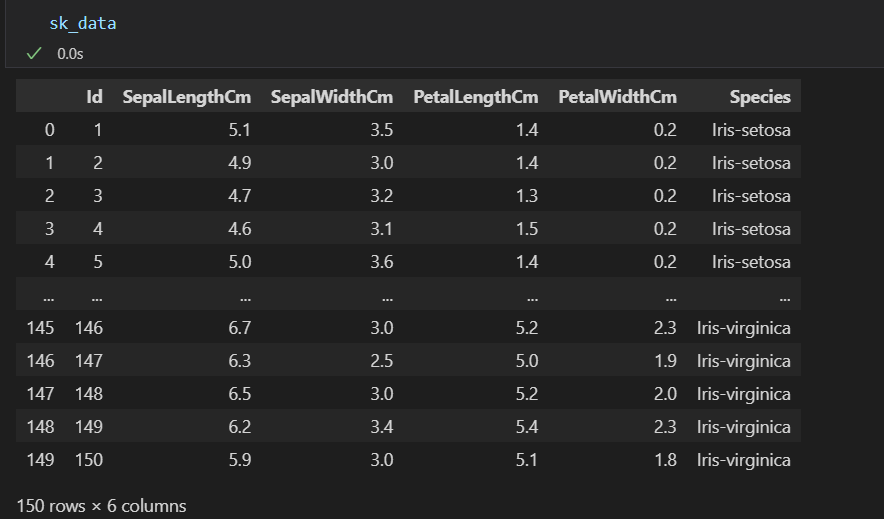
# 查看整体数据
print(sk_data)
sk_data
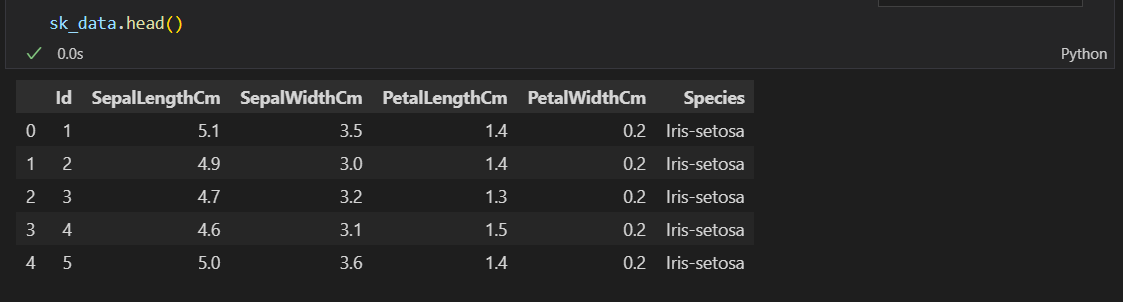
# head/tail首尾查看
sk_data.head #默认查看前5行,显示格式不好
sk_data.head() #同上,但是显示格式好
sk_data.head(n=0) #查看第1行,也就是列名
# type查看数据类型
type(sk_data)
# shape查看数据维度(几行几列之类)
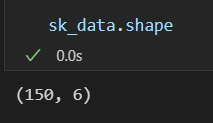
sk_data.shape
# columns查看数据列名(列变量)
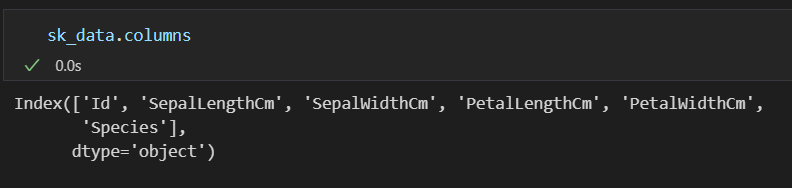
sk_data.columns
# index查看行名(索引)
sk_data.index
# info查看数据框的基本信息(类似于tidyverse中的str以及glimpse)
sk_data.info()
# describe查看数据框的统计摘要(类似于tidyverse中的summary)
sk_data.describe()
# dtypes查看数据框每一列的数据类型(列变量的数据类型)
sk_data.dtypes
import pandas as pd
# 读取数据
sk_data = pd.read_csv("test_data/sklearn/Iris.csv")
# 查看数据框的前5行
print(sk_data.head())
# 查看数据框的后5行
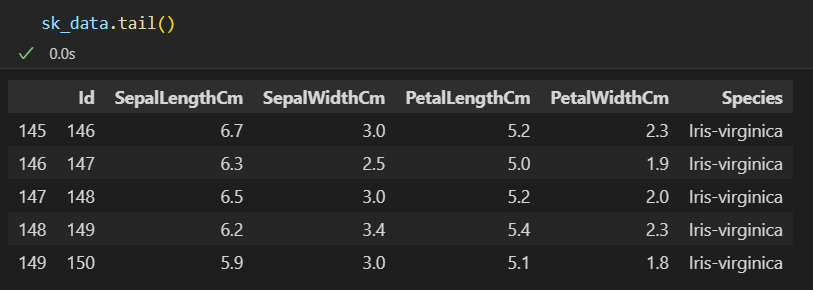
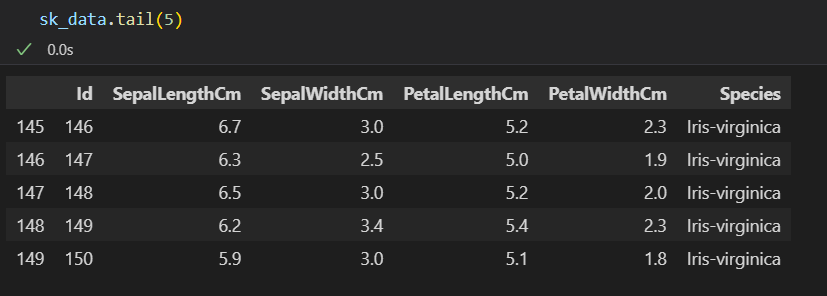
print(sk_data.tail())
# 查看数据框的形状(行数和列数)
print(sk_data.shape)
# 查看数据框的列名
print(sk_data.columns)
# 查看数据框的行名(索引)
print(sk_data.index)
# 查看数据框的基本信息
print(sk_data.info())
# 查看数据框的统计摘要
print(sk_data.describe())
# 查看数据框每一列的数据类型
print(sk_data.dtypes)
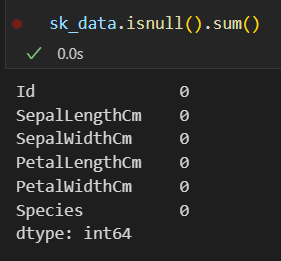
# 查看数据框中每一列的缺失值数量
print(sk_data.isnull().sum())
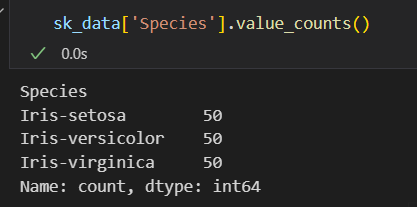
# 查看某一列中每个值的出现次数(以'Species'列为例)
print(sk_data['Species'].value_counts())
查看首尾:

差异在于()有无导致的数据类型不一致
数据维度
列名查看:
或至少可视化查看上

行名查看:查看数据框的行名(索引),实际上是索引
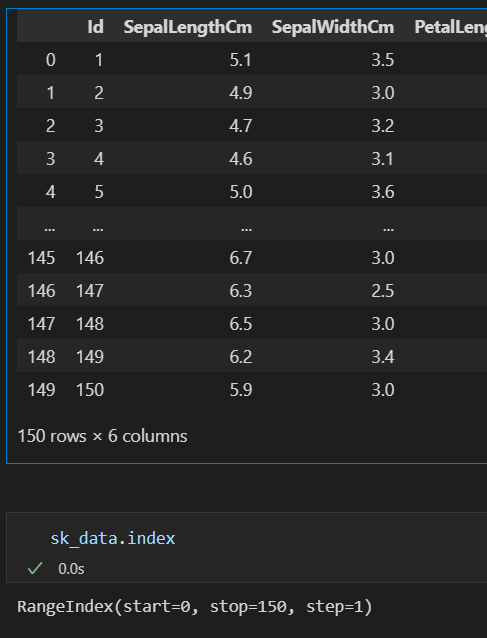
查看数据框的基本信息
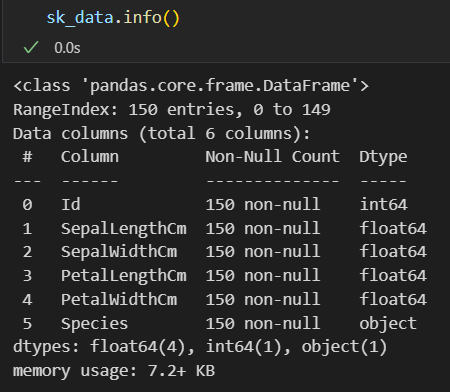
查看数据框的统计摘要
查看数据框每一列的数据类型
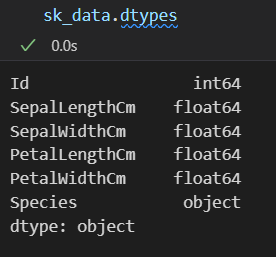
查看数据框中每一列的缺失值数量:NA值
查看某一列中每个值的出现次数(以’Species’列为例)
第1行:非列名
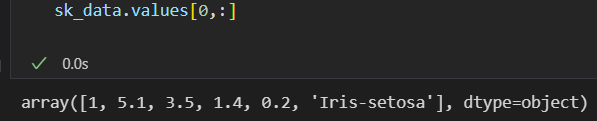
第1列:
=====》回到主题,正式导入数据
# 导入数据
sk_data = pd.read_csv('./test_data/sklearn/Iris.csv')# 读取csv文件
sk_data.head
sk_data = sk_data.drop('Id',axis=1)# 删除ID对应的列
# sk_data = sk_data.iloc[:,0:4]# 后面只需要前四列数据
#当然其实最后面2步都没必要做
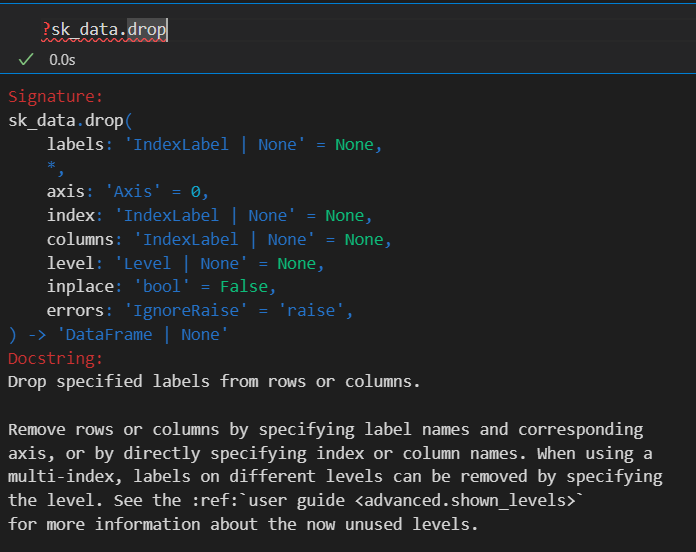
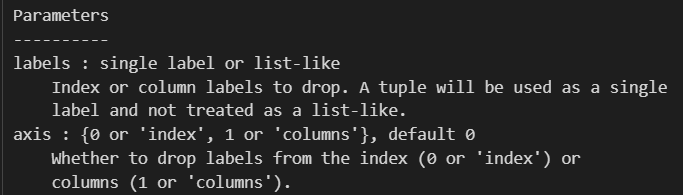

要丢弃的列名,以及是按行丢弃index,还是按列丢弃columns(axis=1)
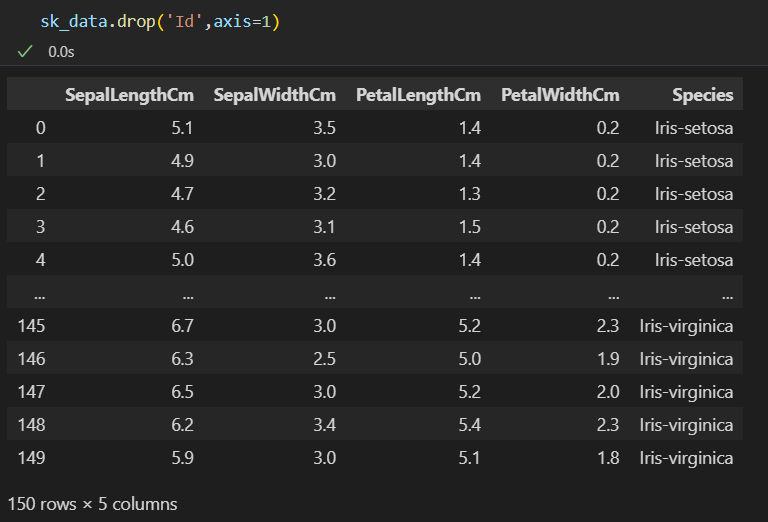
因为也不可能从index删除
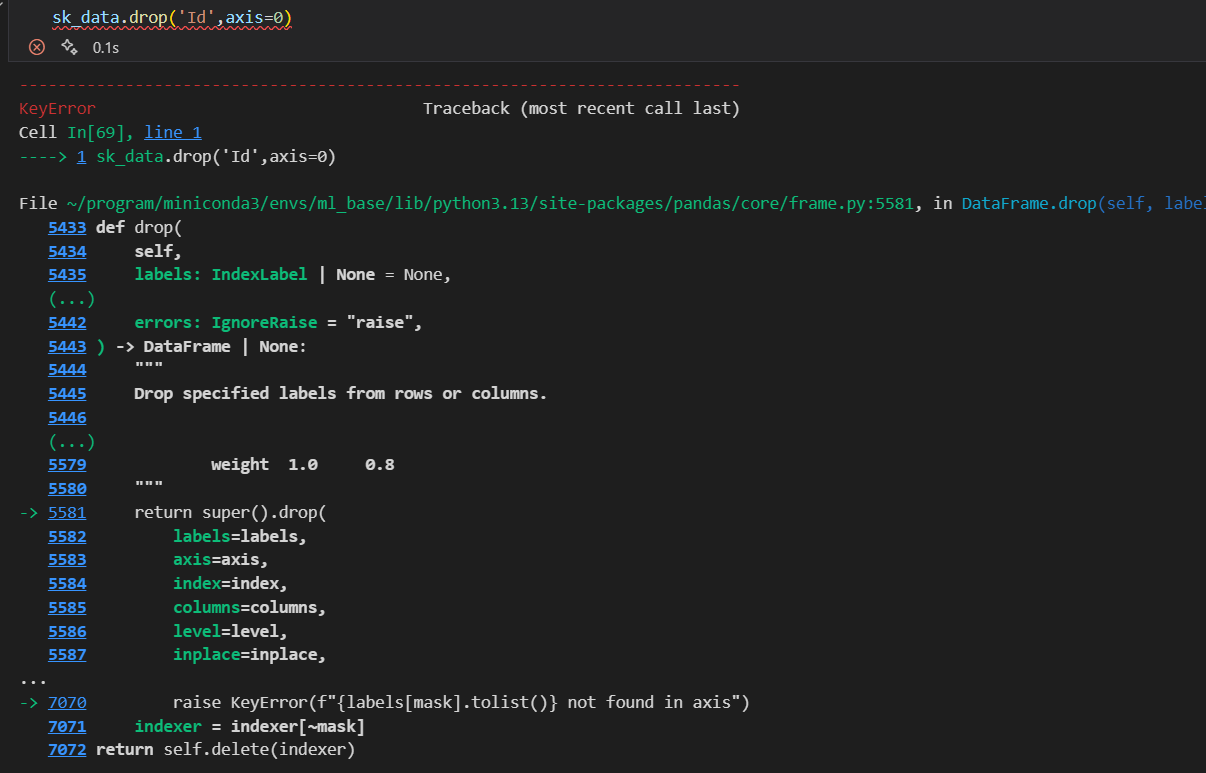
然后切片的话,我们都知道从0开始,然后终点取不到
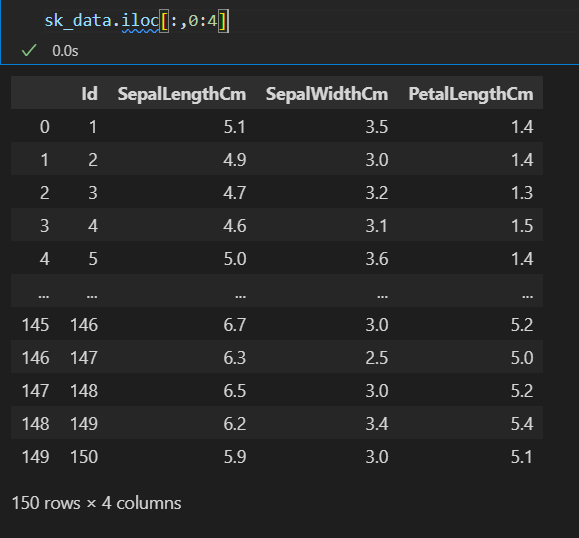
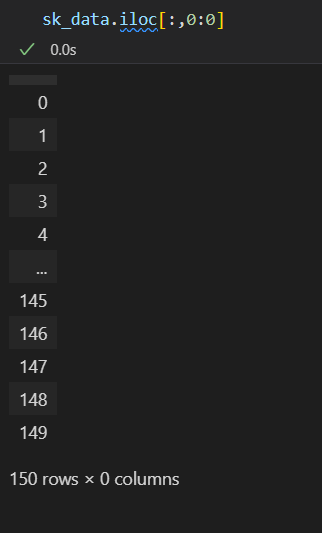
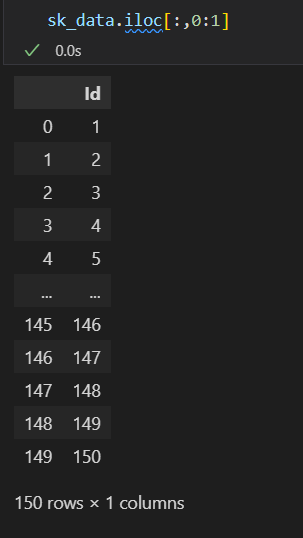
然后这里的iloc和loc是常见的取数据方式

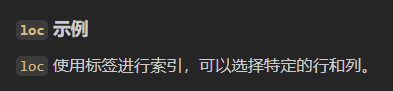
import pandas as pd
# 创建示例数据框
data = {'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]}
df = pd.DataFrame(data)
print(df)
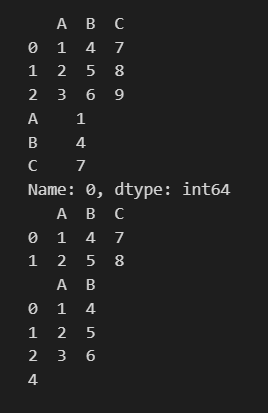
# 选择第1行(索引从0开始)
print(df.iloc[0])
# 选择第1行和第2行
print(df.iloc[0:2])
# 选择第1列和第2列
print(df.iloc[:, 0:2])
# 选择第1行和第2列的元素
print(df.iloc[0, 1])
import pandas as pd
# 创建示例数据框
data = {'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]}
df = pd.DataFrame(data)
print(df)
# 选择标签为0的行
print(df.loc[0])
# 选择标签为0和1的行
print(df.loc[0:1])
# 选择列名为'A'和'B'的列
print(df.loc[:, ['A', 'B']])
# 选择标签为0的行和列名为'B'的元素
print(df.loc[0, 'B'])

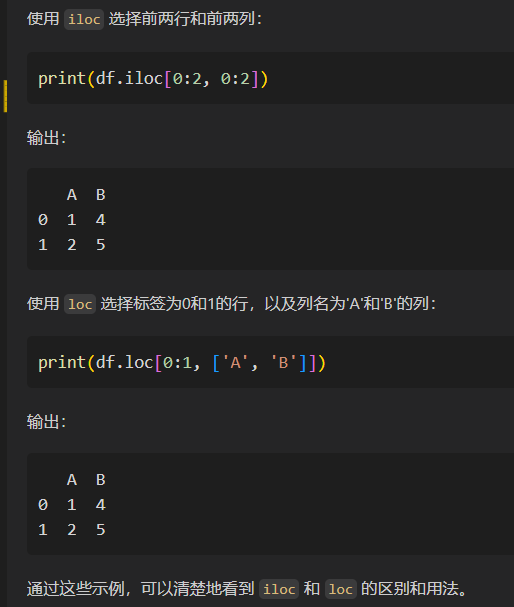
**总之:
**iloc是基于数字下标/数字索引,index,是符合数字索引方式的,是按照位置的方式进行抽取操作
loc是基于索引赋值的方式,index=/var=的方式,即取出行名index或列名var的方式进行元素抽取操作
有个很直观的例子可以比较
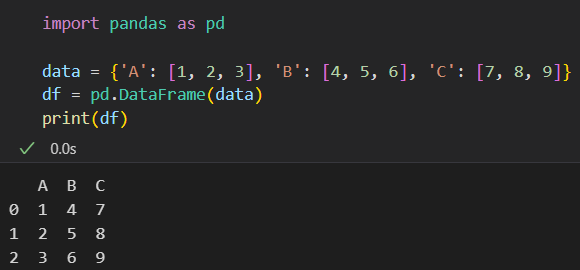
iloc是数字索引,所以取出切片的0/1,也就是前2行前2列
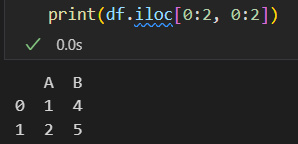
loc是赋值索引,所以取出行索引是0/1,以及列名是A、B的2行2列

2,整理标签并划分数据集
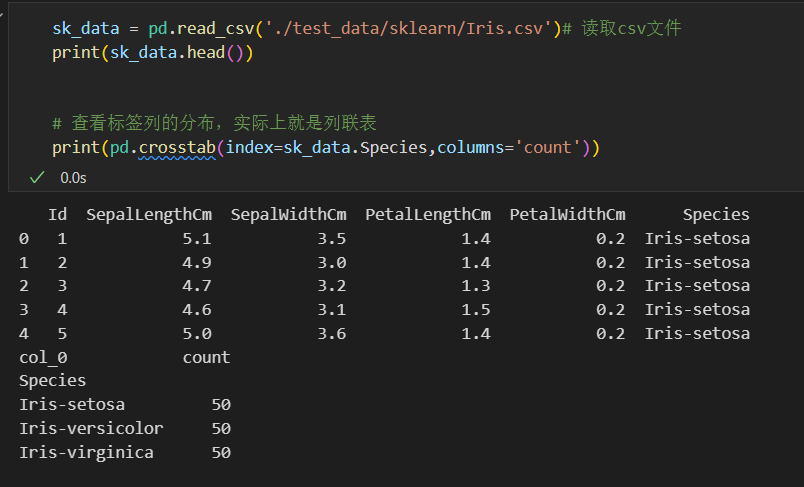
首先查看标签列,也就是最后1列的分布
可以使用pd.crosstab列联表,或对应列的value_counts函数
# 查看标签列的分布,实际上就是列联表,行是index,列是自定义count
print(pd.crosstab(index=sk_data.Species,columns='count'))
#或该列的value_counts函数
print(sk_data['Species'].value_counts())

或

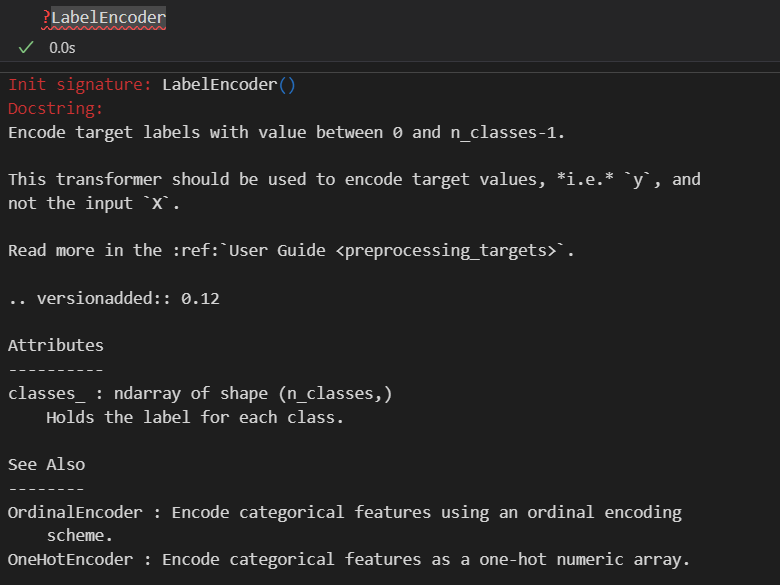
主要是对train以及test中的target y做encode(标签y)
将标签编码为数字
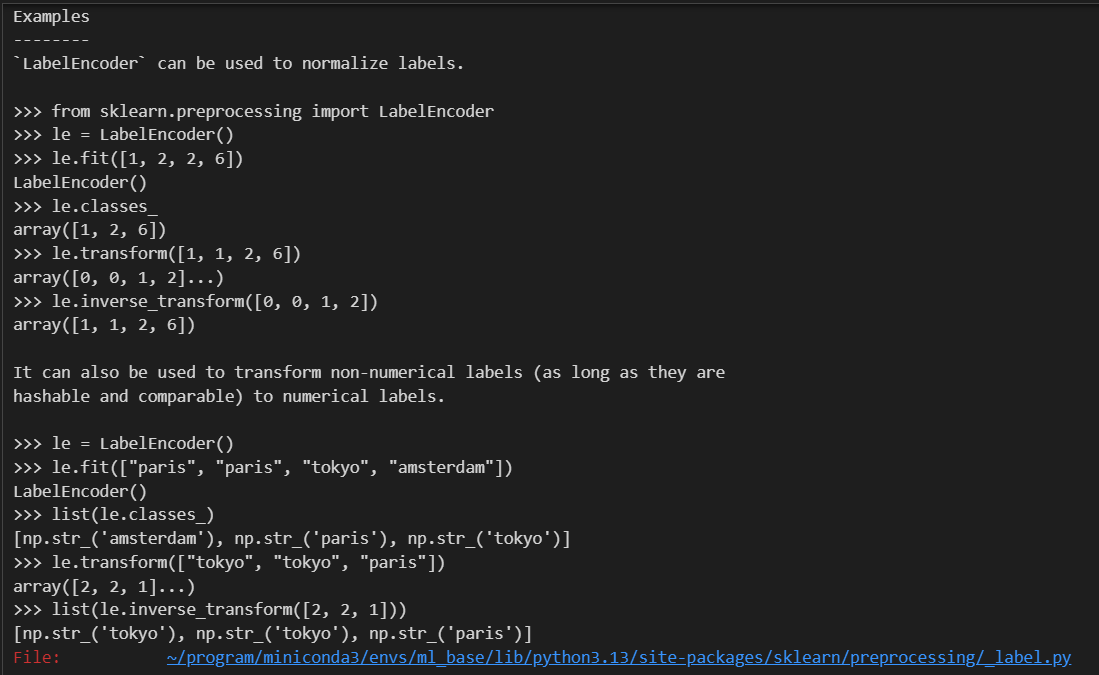
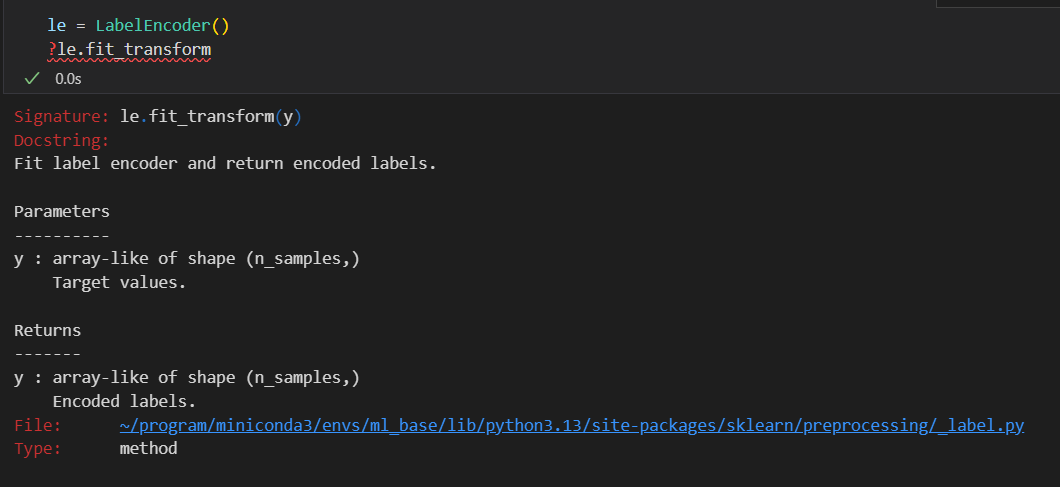
主要是运用该实例的一个函数(该实例/该class的1个对象 的 某个函数)


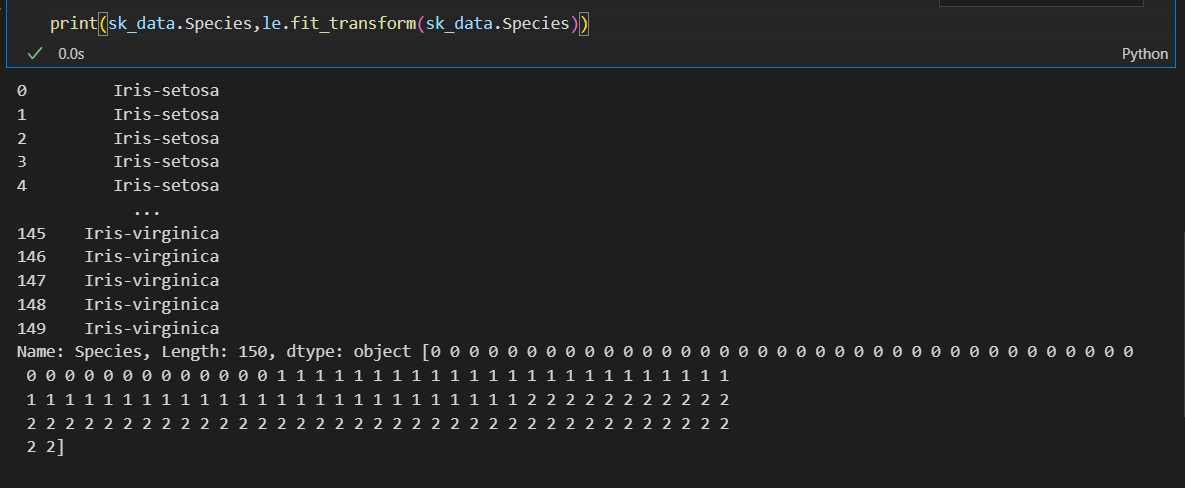
如果我们先看编码的对应关系:
查看标签列原来的值与编码之后的数值之间的对应关系
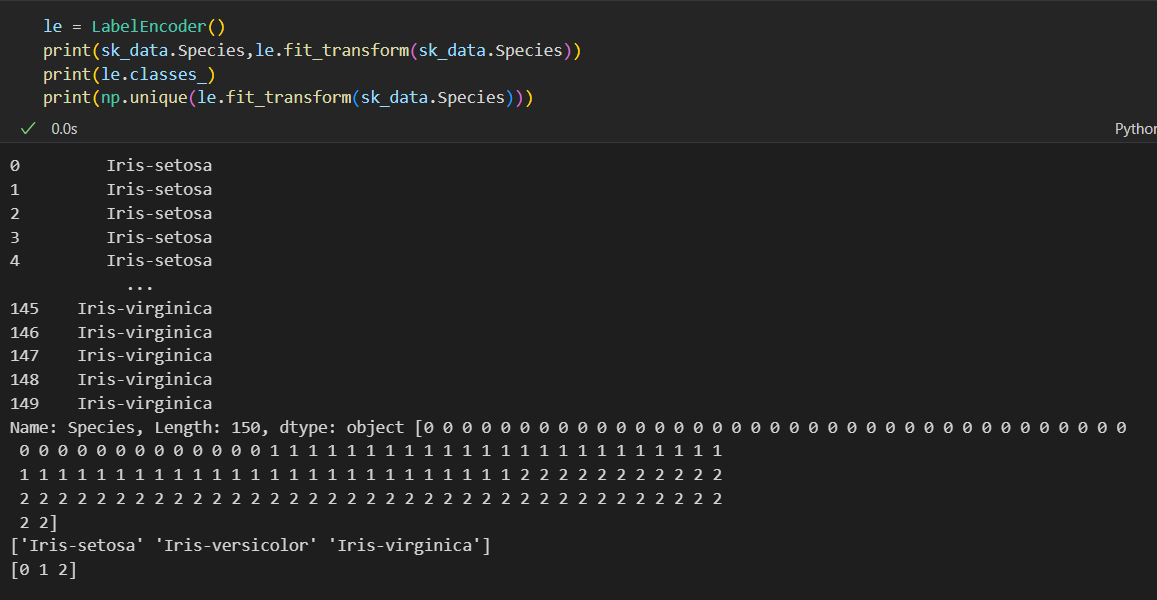
总之:
首先这个编码类我们可以查看的属性有:
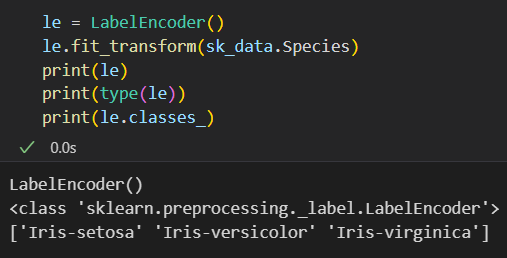

如果要查看对应编码关系:
import pandas as pd
from sklearn.preprocessing import LabelEncoder
# 读取csv文件
sk_data = pd.read_csv('./test_data/sklearn/Iris.csv')
# 删除ID对应的列
sk_data = sk_data.drop('Id', axis=1)
# 创建新的分类变量
le = LabelEncoder()
# 转换为数字编码
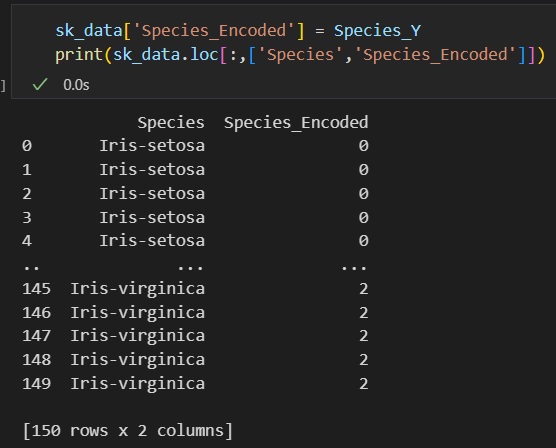
Species_Y = le.fit_transform(sk_data['Species'])
# 查看标签列原来的值与编码之后的数值之间的对应关系
label_mapping = dict(zip(le.classes_, range(len(le.classes_))))
print("标签列原来的值与编码之后的数值之间的对应关系:")
print(label_mapping)
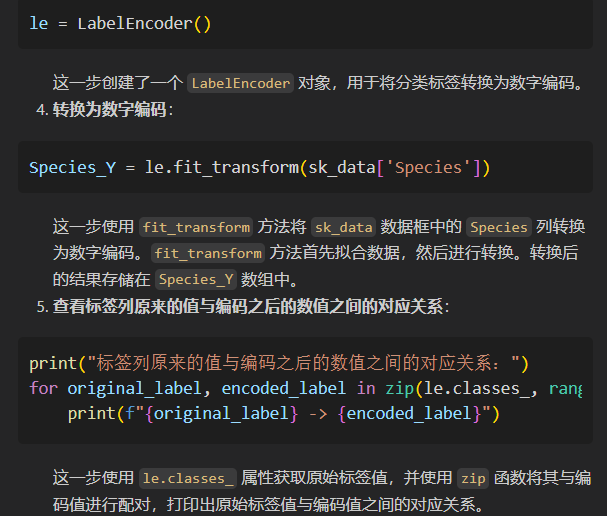

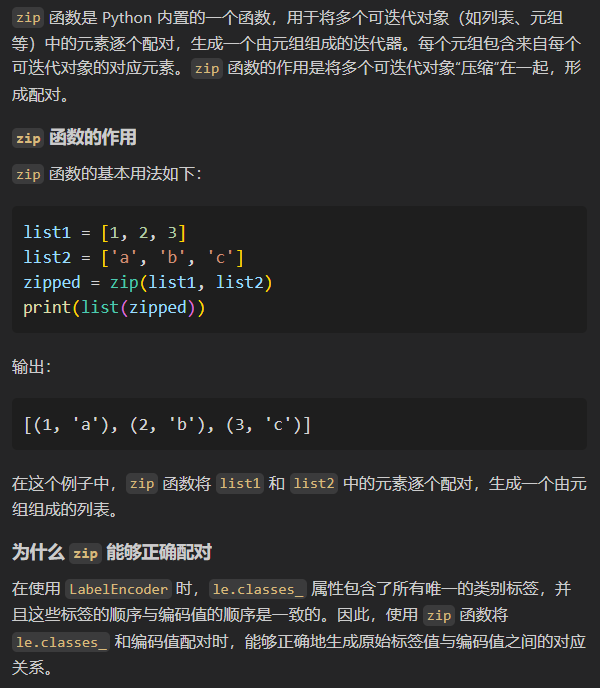
所以其实是人为知道哪些值是编码在一起的,然后使用了dict构造字典
然后这个编码是看顺序的,这个其实在我之前的CNN-motif博客使用one-hot编码问题中我就提到了;
初学者很容易搞混,到底这个编码是按照什么顺序规则来定义的?
是某个值在标签列中首先出现,然后编码为0吗?就像:

其实不是这样的,这样是违反常理的,违反正常思维逻辑的!
大家如果都能按照unicode,或者类似于ASCII码,就编码所有的标签的levels水平,码小的取0,不是很正常的嘛!
当然,事实胜于雄辩,举个简单的例子,当我打混字母的顺序进行默认编码,看它到底是按照出现顺序还是按照码值大小进行编码:
import pandas as pd
from sklearn.preprocessing import LabelEncoder
# 创建示例数据框
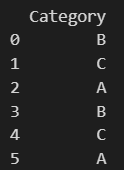
data = {'Category': ['B', 'C', 'A', 'B', 'C', 'A']}
df = pd.DataFrame(data)
print(df)
# 创建新的分类变量
le = LabelEncoder()
# 转换为数字编码
encoded_labels = le.fit_transform(df['Category'])
# 将编码后的值添加到数据框中作为新列
df['Category_Encoded'] = encoded_labels
print(df.loc[:,['Category','Category_Encoded']])
print('\n如果按照zip的方式来查看\n')
# 查看标签列原来的值与编码之后的数值之间的对应关系
label_mapping = dict(zip(le.classes_, range(len(le.classes_))))
print("标签列原来的值与编码之后的数值之间的对应关系:")
print(label_mapping)
# 打印出数据框,查看原始值和编码值
print(df)
这里是数据:
这里是新增一列查看效果:

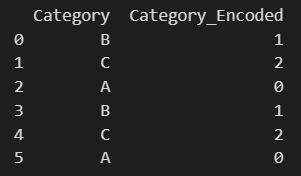
其实效果很明显,就是按照码值大小!
不是按照出现顺序!
整体效果:

至于这个码值,我们python中熟悉一点的有unicode,用的最常见的两个函数就是chr以及ord,在我更新的python博客系列运算符那章就有!
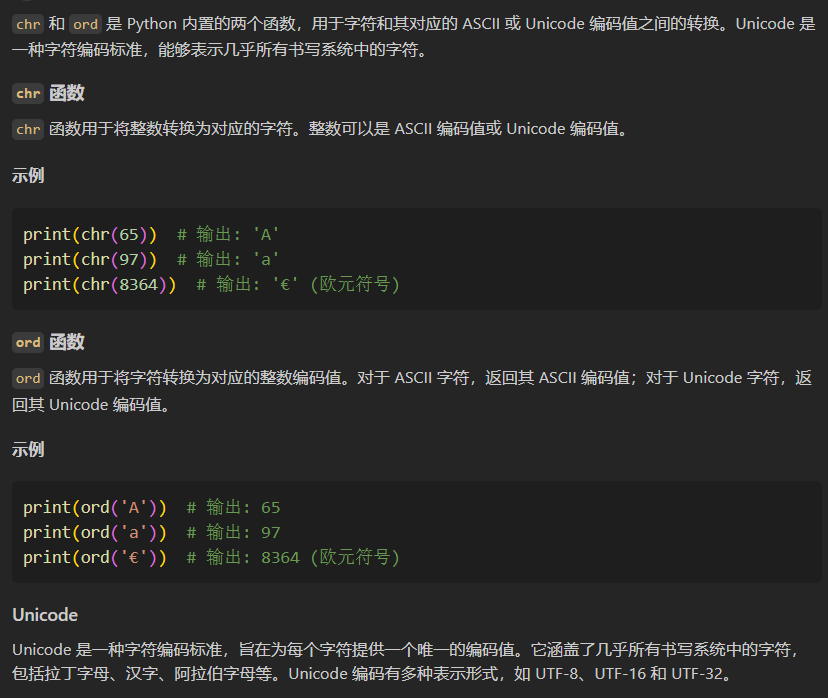
那我能指定编码吗,毕竟不指定的话按照默认的顺序我还不知道哪个对应哪个呢?
当然最好或者是直观上查看是自己进行自定义编码
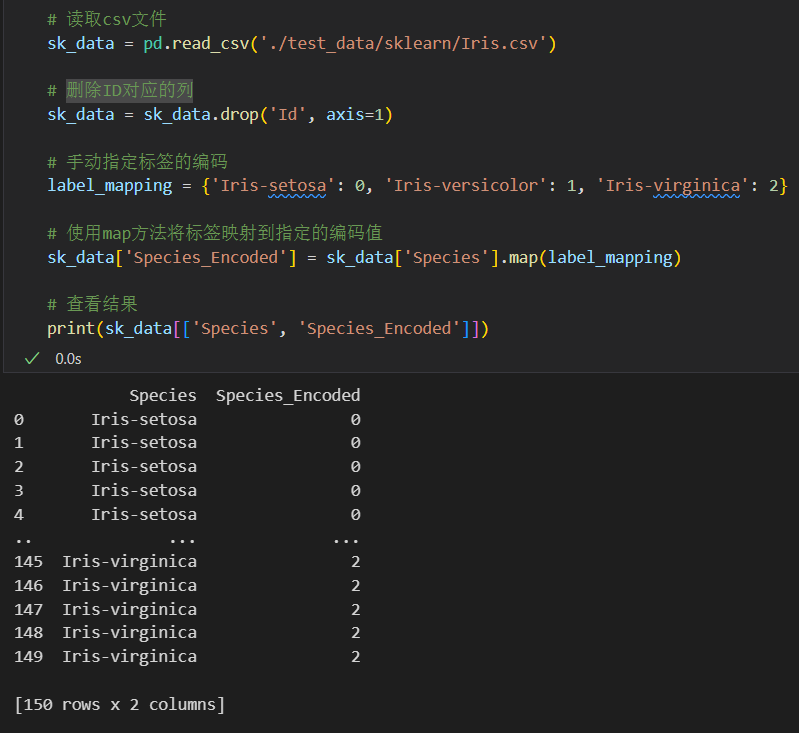
# 手动指定标签的编码
label_mapping = {'Iris-setosa': 0, 'Iris-versicolor': 1, 'Iris-virginica': 2}
# 使用map方法将标签映射到指定的编码值
sk_data['Species_Encoded'] = sk_data['Species'].map(label_mapping)
# 查看结果
print(sk_data[['Species', 'Species_Encoded']].head())
实际上就是新命名了2列
当然,如果是原来的默认编码的话:
也可以直接增加到新的1列中,然后对应起来进行可视化比较
在sklearn中,在机器学习任务中,通常会将原始数据集划分成两个部分:一个用于训练,一个用于测试。这个划分通常按照一定的比例进行,例如,常见的是将数据集划分为训练集(通常占大部分数据的比例,如7080%)和测试集(通常占小部分数据的比例,如2030%)。这种划分允许我们在训练模型后,使用测试数据集来评估模型的性能(例如准确率、精确度、召回率等),以确定模型是否能够有效地泛化到新的数据。在sklearn中,通常使用train_test_split函数来完成这一操作。
训练数据集(Training Dataset):
训练数据集是用于训练机器学习模型的数据集。它包含了模型用来学习特征与目标之间关系的样本数据。在训练过程中,模型分析训练数据集中的特征与相应的已知目标值,然后根据这些关系来构建模型。训练数据集通常包括输入特征(特征矩阵)和相应的目标值(标签或目标向量)。模型通过反复处理训练数据集,调整自身的参数,以最大程度地拟合训练数据中的模式。
测试数据集(Test Dataset):
测试数据集是用于评估和验证机器学习模型性能的数据集。它独立于训练数据集,并且用于评估模型在未见过的数据上的表现。测试数据集的目的是检查模型是否能够泛化到新的、未知的数据。通常,测试数据集也包含输入特征和相应的目标值,但是这些目标值不会在模型训练阶段中用于调整模型参数。
然后在划分数据集前,我先去掉一些我认为觉得不靠谱的feature:
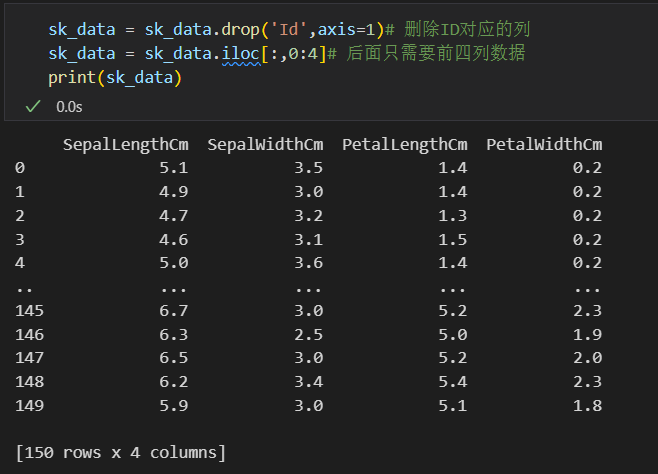
比如说是id列,我的标签基本上就是按照顺序分这3类的,我可不想让机器学到编号id多少到多少是第一类,中间是第2类,最后是第三类这种没有用的分类规则(大概);
人为选feature也是需要domain knowledge的,所以我选了前面4列
划分训练集以及测试集比例最常用的函数:
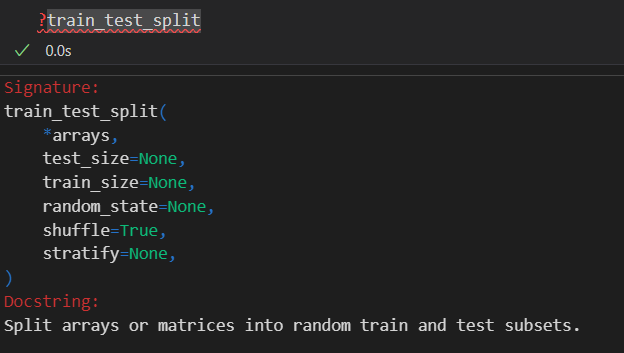
然后参数的话就比较简单了:
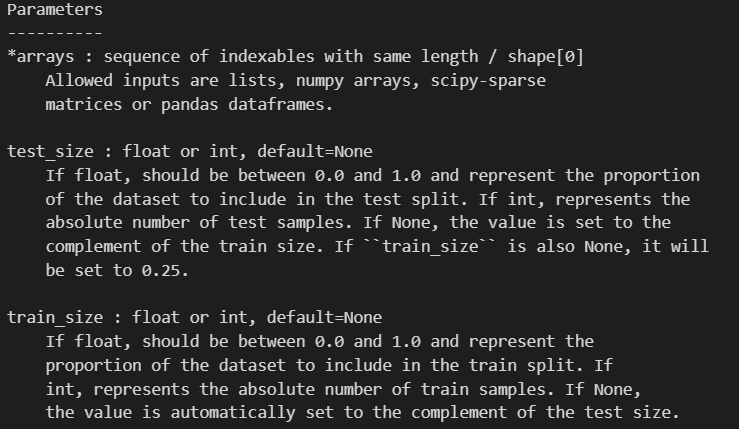
train和test划分参数是互补的,看一个就够了,是给出绝对样本数目还是给出比例
看example这里就是拆分完之后解包4个值
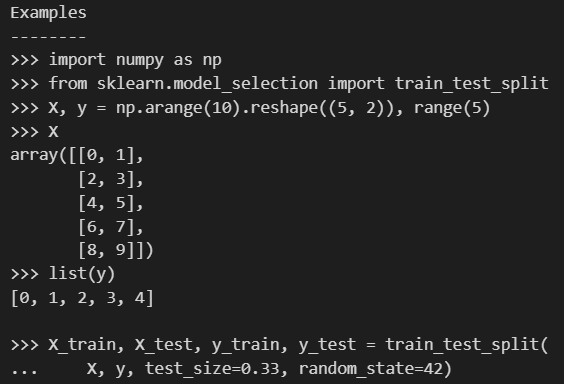
核心参数在于首先是没有label的特征矩阵、以及标签label,其实就是(x,y),其实就是上面的*array
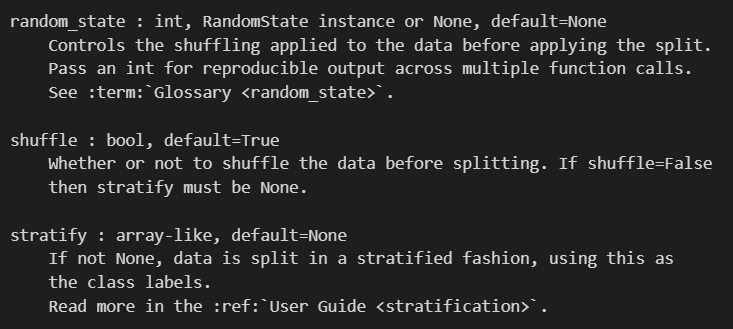
然后重点的参数在于上面这几个:
首先是随机数
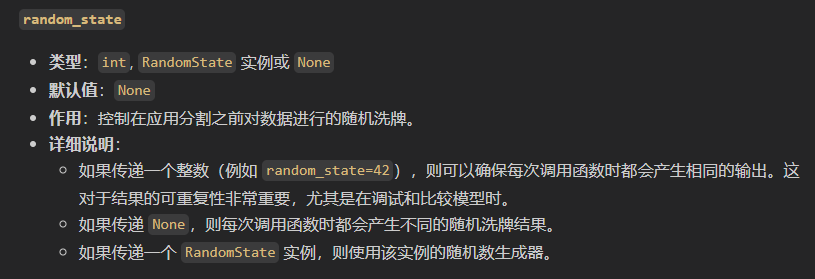
然后就是打乱训练集和测试集,主要是分布上不能太有规律了,比如原始数据中的前中后分别对应3个分类,就应该随机点
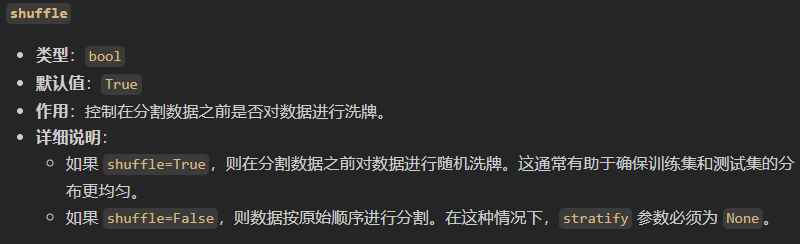
然后就是划分比例的问题,比如说原本的三类是1:1:1在原始数据集中,那我划分之后还要不要这么做;
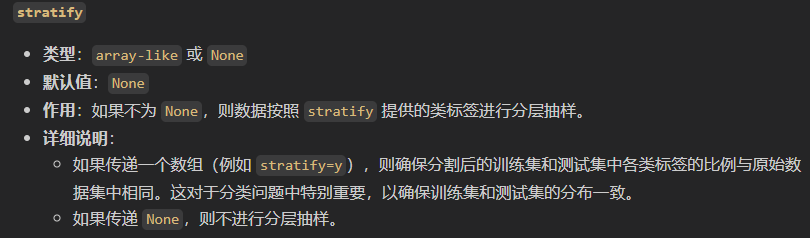
当然默认的话就是shuffle,然后不用stratify;
这一块代码如下:
# 划分测试数据集/标签与训练数据集/标签:
X_train,X_test,Y_train,Y_test = train_test_split(
sk_data,Species_Y,
test_size=0.3,# 70%的为训练数据集,30%的为测试数据集
random_state=2025# 设置随机数
)
print(sk_data,sk_data.shape,'\n')
print(Species_Y,Species_Y.shape,'\n')
print(X_train,X_train.shape,'\n')
print(X_test,X_test.shape,'\n')
print(Y_train,Y_train.shape,'\n')
print(Y_test,Y_test.shape,'\n')
首先是查看特征矩阵以及标签,以及维度

然后是查看训练集的特征:正好是150*0.7=105
然后是测试集的特征:反正id都是打乱了shuffle
然后就是训练集以及测试集的标签y

3,数据预处理:
这里做的主要是数据的标准化以及PCA
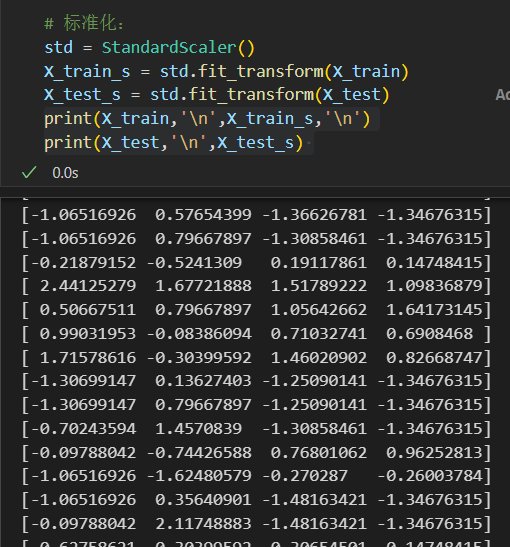
首先是数据的标准化:
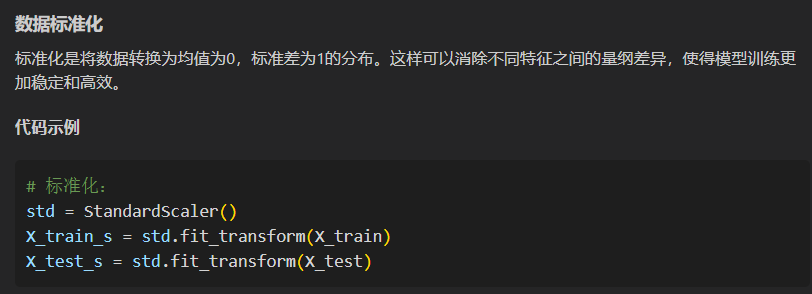
用的函数:
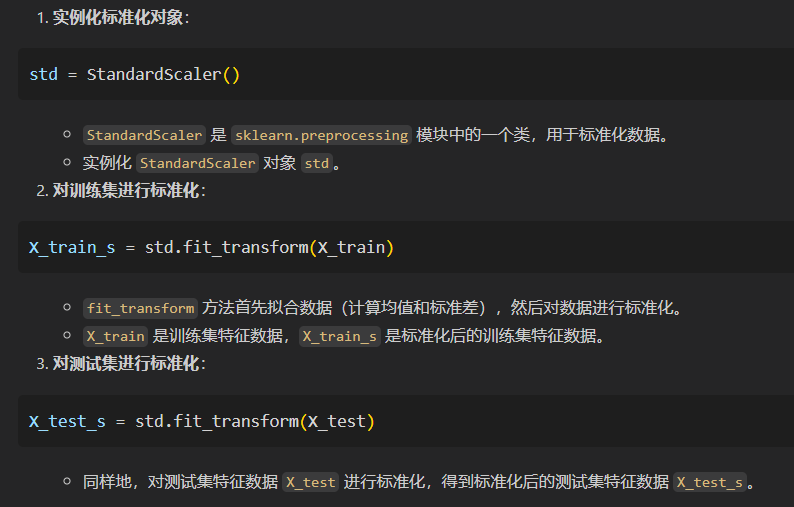
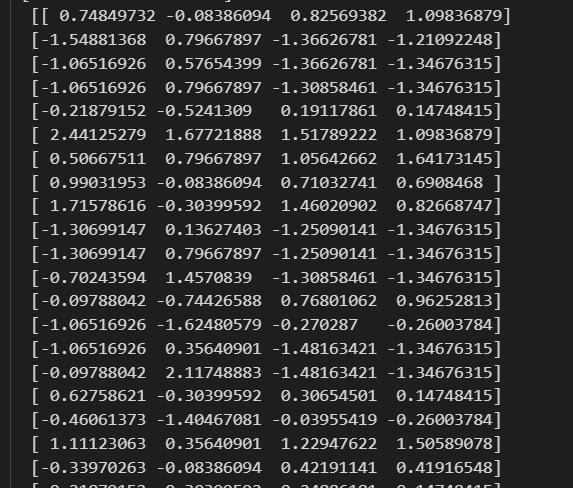
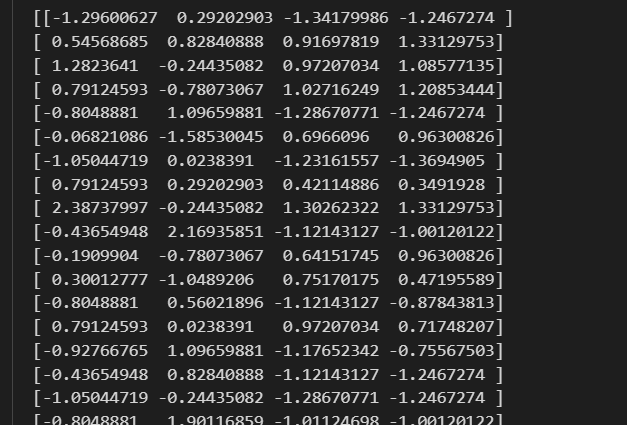
然后可以看到,和前面我们保留下来的人为选择的4个feature一致:
我们的feature维度其实就只有4,标准化前后
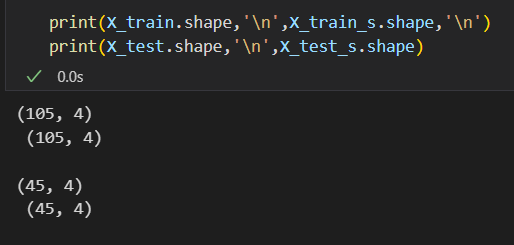
如果我还是觉得特征太多了怎么办,比如说我还是想降维,再降一点;
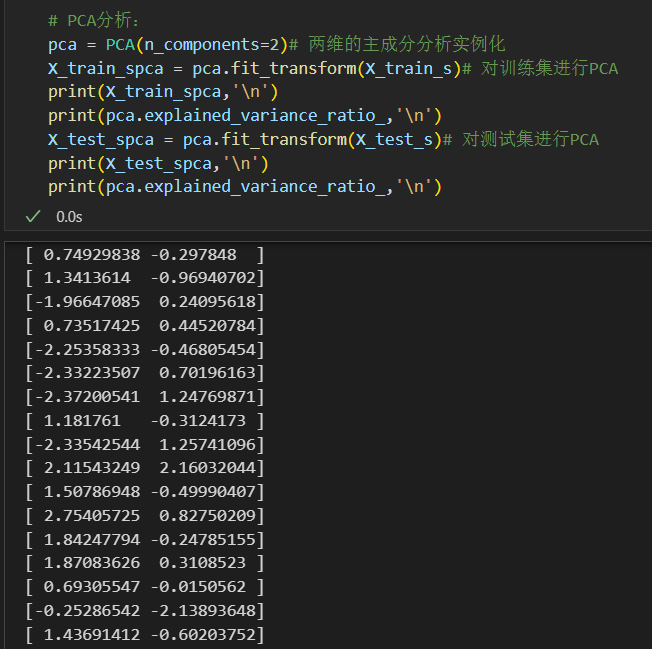
那就可以用经典的降维算法,比如说是PCA,比如说我要从4维降到2维
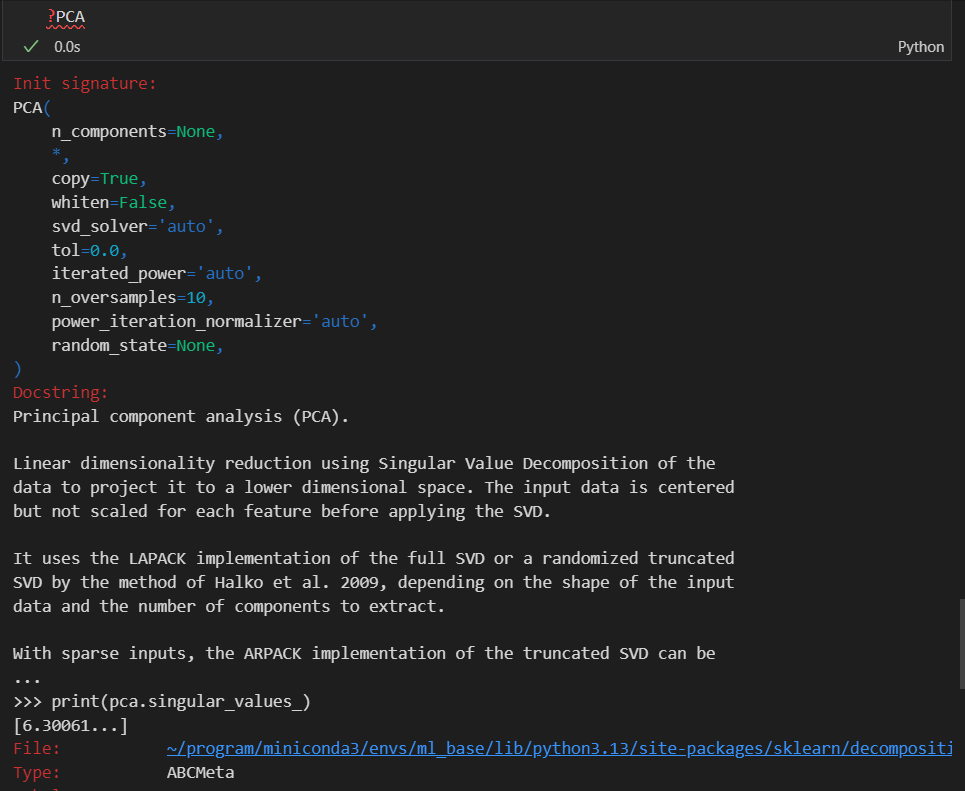
总之就是修改为2维度的feature(当然是旧的4 feature的线性组合)
然后查看示例:

总之这里的PCA函数还是需要实例化,再然后运用到数据上(也就是所谓的对数据拟合)
# PCA分析:
pca = PCA(n_components=2)# 两维的主成分分析实例化
X_train_spca = pca.fit_transform(X_train_s)# 对训练集进行PCA
print(X_train_spca,'\n')
print(pca.explained_variance_ratio_,'\n')
X_test_spca = pca.fit_transform(X_test_s)# 对测试集进行PCA
print(X_test_spca,'\n')
print(pca.explained_variance_ratio_,'\n')
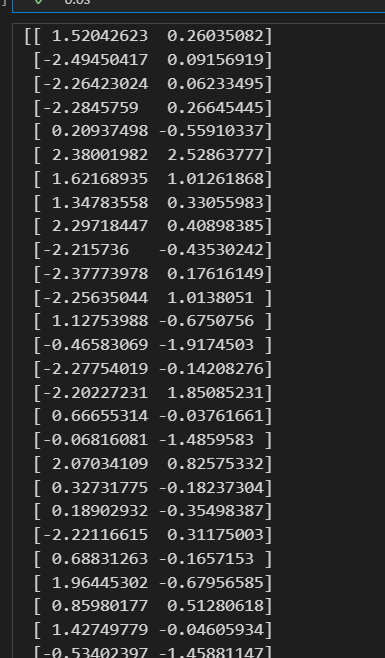
看训练集方差可解释性

接着是测试集
总之我们已经看到了feature已经降到了2维
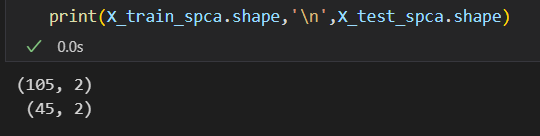

其实这里只有4维的feature,也没必要降维
4,线性判别分类器:
线性判别分类器(Linear Discriminant Classifier),是一种常见的监督学习分类算法,用于将数据点分为两个或多个不同的类别。LDC被广泛应用于模式识别、图像处理、生物医学和自然语言处理等领域。其基本思想是通过寻找最佳的线性决策边界来将不同类别的数据点分隔开。
以下是关于线性判别分类器的简要介绍:
工作原理基于两个主要概念,即类内方差最小化和类间方差最大化。
类内方差最小化:LDC试图使每个类别内部的数据点更加紧密地聚集在一起,以最小化类内方差。这意味着它寻找一个线性决策边界,使同一类别内的数据点尽可能靠近彼此。
类间方差最大化:同时,LDC也试图使不同类别之间的边界尽可能远离,以最大化类间方差。这意味着它寻找一个线性决策边界,使不同类别之间的分离程度最大化。
总之,线性判别分类器是一种简单而强大的分类算法,适用于很多实际问题。它的优点包括易于理解、计算效率高以及在某些情况下表现良好。但需要注意,当数据具有复杂的非线性关系时,线性判别分类器可能不适合,需要考虑更复杂的分类模型。
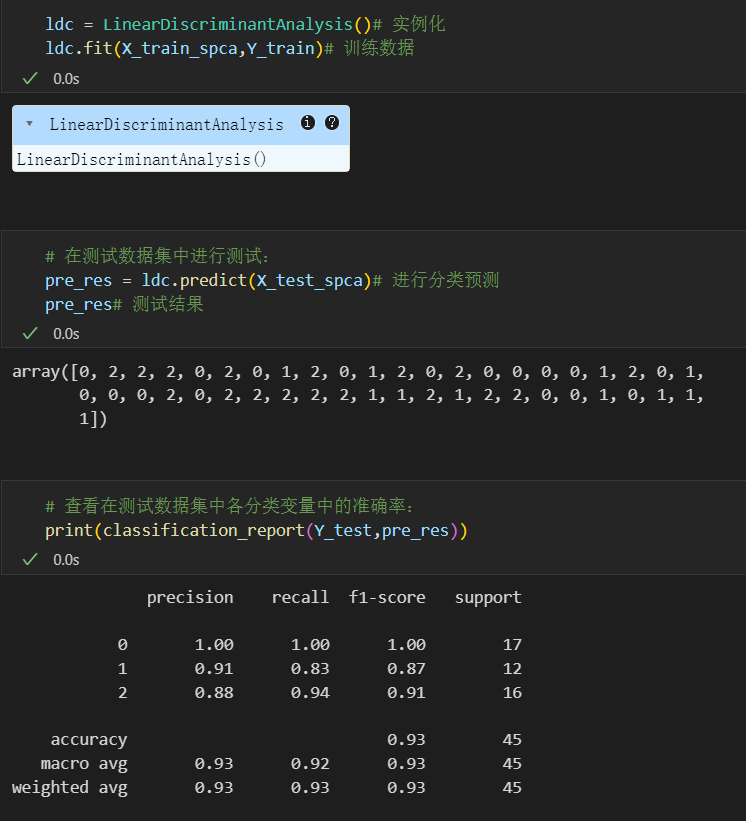
同样简单的实例化,再然后提供训练集以及测试集前面预处理好的
ldc = LinearDiscriminantAnalysis()# 实例化
ldc.fit(X_train_spca,Y_train)# 训练数据
其实可以点击上面的这里帮助文档直接到sklearn官网中去查看
然后就是对测试集进行预测,fit好之后的model在test set上predict
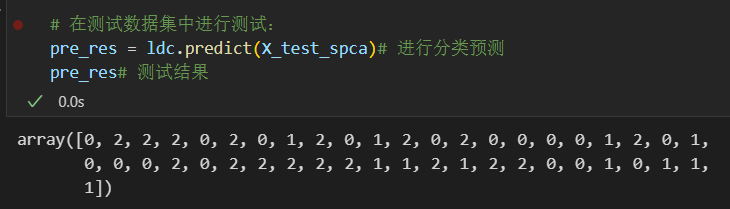
# 在测试数据集中进行测试:
pre_res = ldc.predict(X_test_spca)# 进行分类预测
pre_res# 测试结果
然后评估一下模型指标:
from sklearn.metrics import classification_report
# 查看在测试数据集中各分类变量中的准确率:
print(classification_report(Y_test,pre_res))
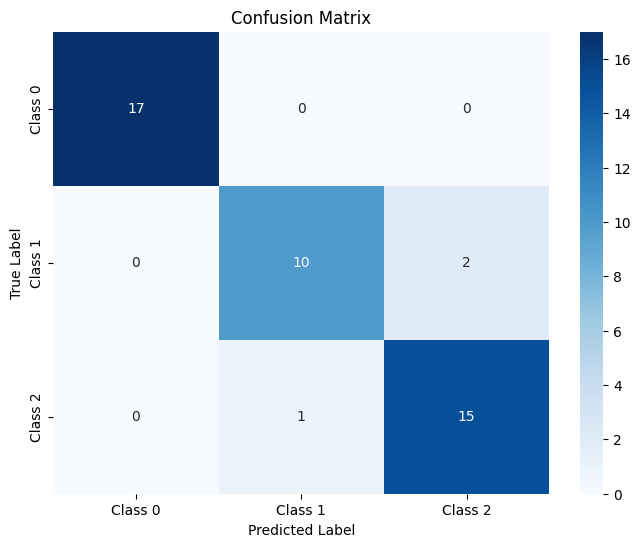
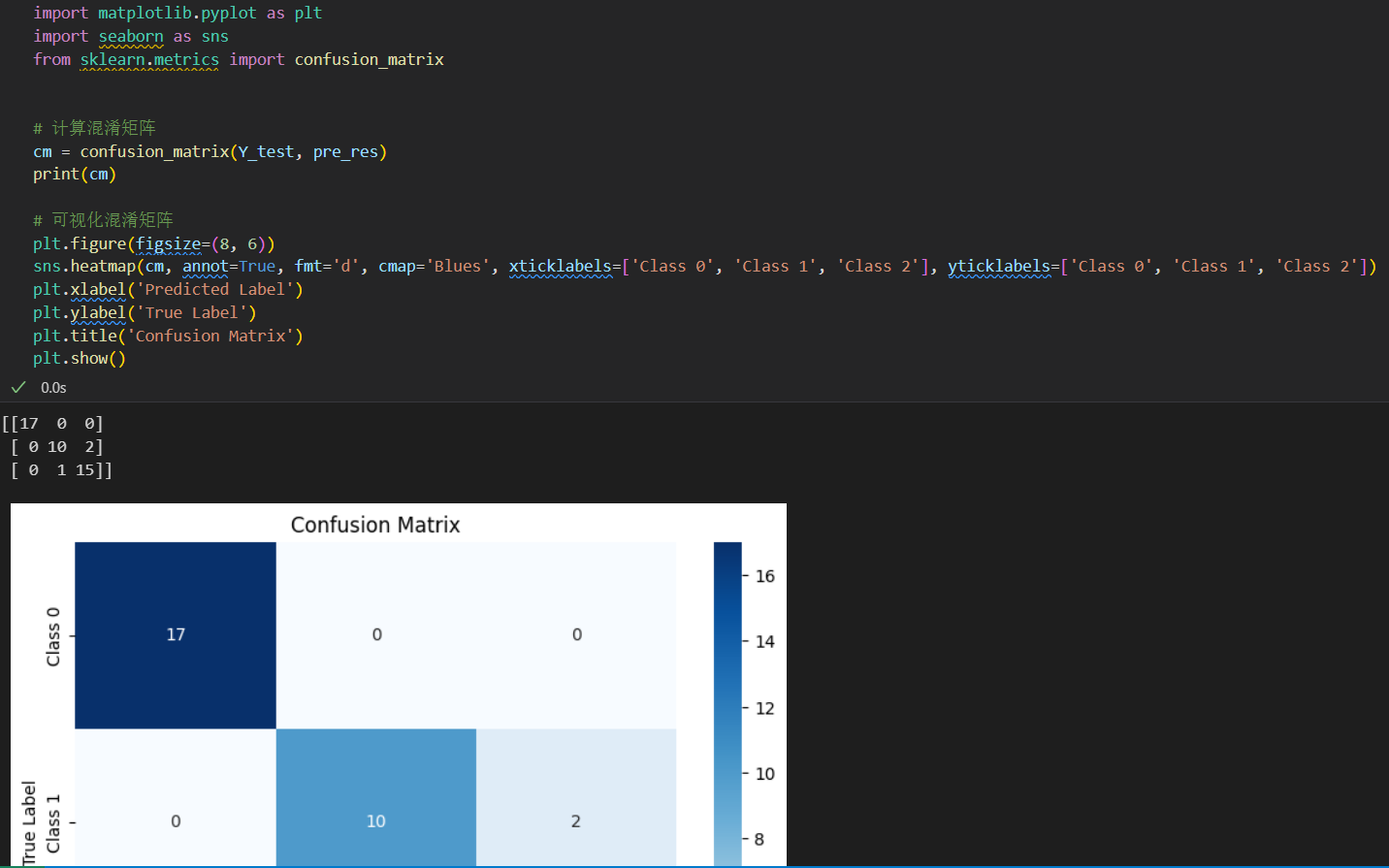
查看结果:可以看到accuracy是93%
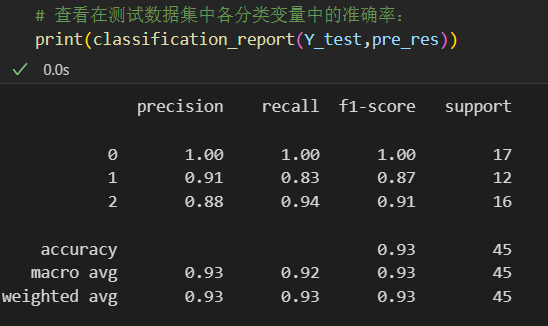
这些指标都是机器学习的常见指标:

具体的分类指标可以参考我之前的博客:
https://blog.csdn.net/weixin_62528784/article/details/145379239?spm=1001.2014.3001.5501
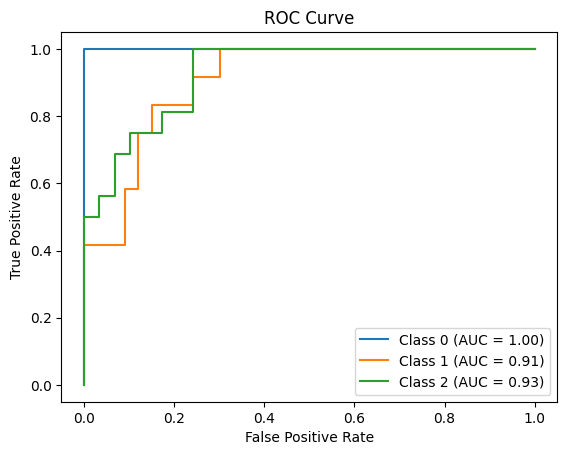
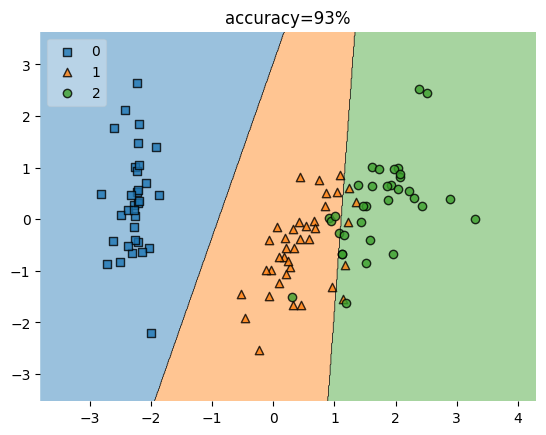
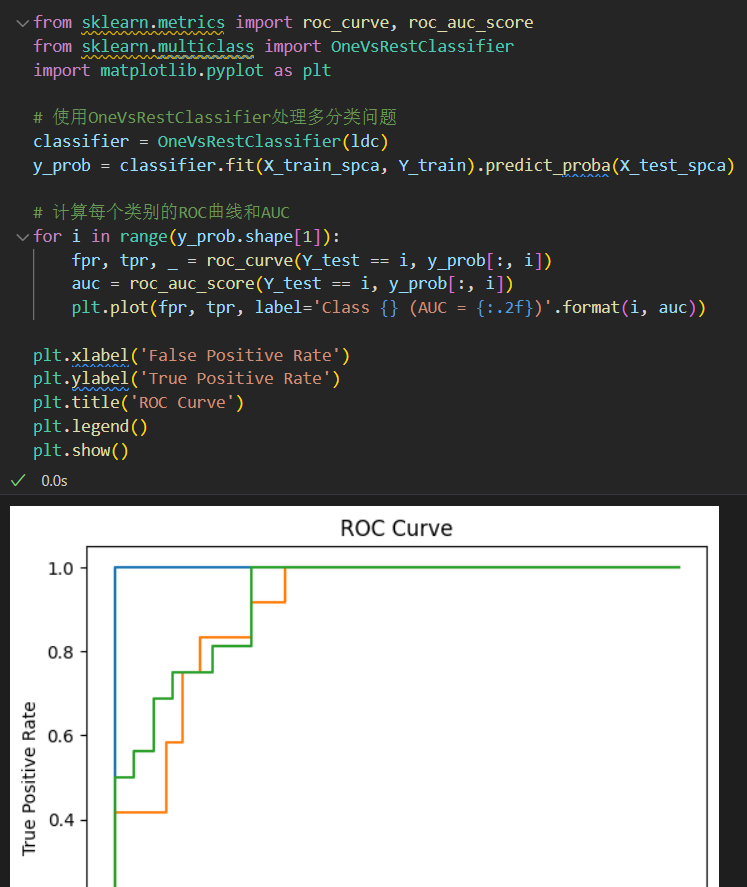
5,对准确率的分布进行可视化
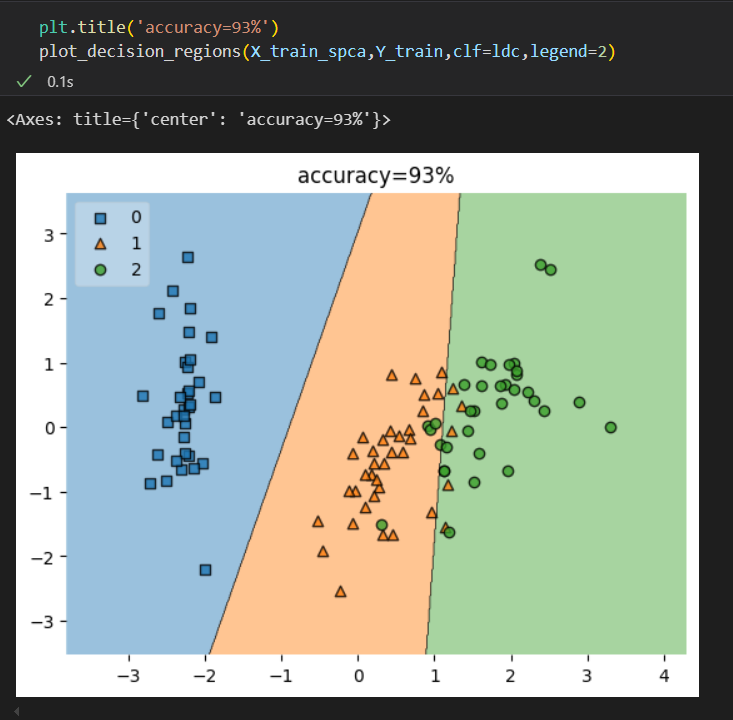
查看各组数据预测结果,可以看到0类的数据分布比较准确,1类和2类均有落在彼此区域的点
plt.title('accuracy=93%')
plot_decision_regions(X_train_spca,Y_train,clf=ldc,legend=2)

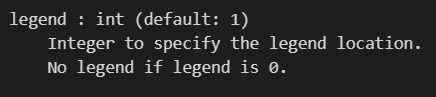
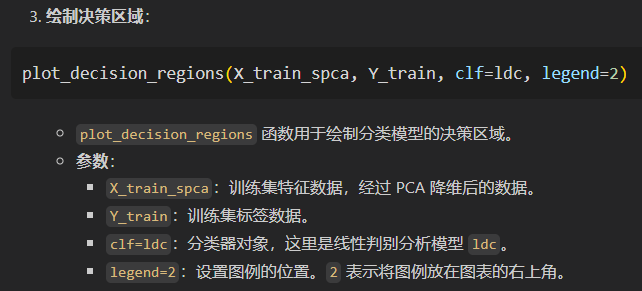
整体code如下:
此外这里介绍一下google的ML速成课程:
https://developers.google.com/machine-learning/crash-course?hl=zh-cn
