任务A:大数据平台搭建(容器环境)(15分)
环境搭建请看这篇文章大数据模块A环境搭建
环境说明:
服务端登录地址详见各任务服务端说明。
补充说明:宿主机可通过Asbru工具或SSH客户端进行SSH访问;
相关软件安装包在宿主机的/opt目录下,请选择对应的安装包进行安装,用不到的可忽略;
所有任务中应用命令必须采用绝对路径;
进入Master节点的方式为
docker exec -it master /bin/bash
进入Slave1节点的方式为
docker exec -it slave1 /bin/bash
进入Slave2节点的方式为
docker exec -it slave2 /bin/bash
三个容器节点的root密码均为123456
提前准备好hadoop-3.1.3.tar.gz、jdk-8u212-linux-x64.tar.gz放在/opt/下(模拟的自己准备,比赛时会提供)
子任务一:Hadoop 完全分布式安装配置
评分标准
| 主要知识与技能点 | 分值 |
|---|---|
| JDK的解压安装 | 1 |
| JDK的环境变量配置 | 1 |
| Host配置及三个节点的分发 | 1 |
| Hadoop解压安装及环境初始化 | 2 |
| Hadoop集群启动并查看 | 2 |
本任务需要使用root用户完成相关配置,安装Hadoop需要配置前置环境。命令中要求使用绝对路径,具体要求如下:
任务1
1、 从宿主机/opt目录下将文件hadoop-3.1.3.tar.gz、jdk-8u212-linux-x64.tar.gz复制到容器Master中的/opt/software路径中(若路径不存在,则需新建),将Master节点JDK安装包解压到/opt/module路径中(若路径不存在,则需新建),将JDK解压命令复制并粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下;
用终端连接宿主机
检查容器是否启动
docker ps -a
连接master
docker exec -it master /bin/bash
检查/opt/software路径是否存在
[root@master ~]# ls /opt/
module software
把宿主机里的资料复制到容器里面去
[root@Bigdata ~]# docker cp /opt/jdk-8u212-linux-x64.tar.gz master:/opt/software
Successfully copied 195MB to master:/opt/software
[root@Bigdata ~]# docker cp /opt/hadoop-3.1.3.tar.gz master:/opt/software
Successfully copied 338MB to master:/opt/software
将Master节点JDK安装包解压到/opt/module
tar zxvf /opt/software/jdk-8u212-linux-x64.tar.gz -C /opt/module/
任务2
2、 修改容器中/etc/profile文件,设置JDK环境变量并使其生效,配置完毕后在Master节点分别执行“java -version”和“javac”命令,将命令行执行结果分别截图并粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下;
重命名jdk文件夹
mv /opt/module/jdk1.8.0_212 /opt/module/java
在/etc/profile文件末尾写环境变量
#JAVA_HOME
export JAVA_HOME=/opt/module/java
#PATH
export PATH=$PATH:$JAVA_HOME/bin
使环境变量生效
source /etc/profile
输入 java -version
java version "1.8.0_212"
Java(TM) SE Runtime Environment (build 1.8.0_212-b10)
Java HotSpot(TM) 64-Bit Server VM (build 25.212-b10, mixed mode)
输入 javac
Usage: javac <options> <source files>
where possible options include:
-g Generate all debugging info
-g:none Generate no debugging info
-g:{lines,vars,source} Generate only some debugging info
-nowarn Generate no warnings
-verbose Output messages about what the compiler is doing
-deprecation Output source locations where deprecated APIs are used
-classpath <path> Specify where to find user class files and annotation processors
-cp <path> Specify where to find user class files and annotation processors
-sourcepath <path> Specify where to find input source files
-bootclasspath <path> Override location of bootstrap class files
-extdirs <dirs> Override location of installed extensions
-endorseddirs <dirs> Override location of endorsed standards path
-proc:{none,only} Control whether annotation processing and/or compilation is done.
-processor <class1>[,<class2>,<class3>...] Names of the annotation processors to run; bypasses default discovery process
-processorpath <path> Specify where to find annotation processors
-parameters Generate metadata for reflection on method parameters
-d <directory> Specify where to place generated class files
-s <directory> Specify where to place generated source files
-h <directory> Specify where to place generated native header files
-implicit:{none,class} Specify whether or not to generate class files for implicitly referenced files
-encoding <encoding> Specify character encoding used by source files
-source <release> Provide source compatibility with specified release
-target <release> Generate class files for specific VM version
-profile <profile> Check that API used is available in the specified profile
-version Version information
-help Print a synopsis of standard options
-Akey[=value] Options to pass to annotation processors
-X Print a synopsis of nonstandard options
-J<flag> Pass <flag> directly to the runtime system
-Werror Terminate compilation if warnings occur
@<filename> Read options and filenames from file
任务3
3、 请完成host相关配置,将三个节点分别命名为master、slave1、slave2,并做免密登录,用scp命令并使用绝对路径从Master复制JDK解压后的安装文件到slave1、slave2节点(若路径不存在,则需新建),并配置slave1、slave2相关环境变量,将全部scp复制JDK的命令复制并粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下;
分别进入三个容器检查ip
输入 ifconfig
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.100.102 netmask 255.255.255.0 broadcast 192.168.100.255
ether 00:50:56:80:3e:d7 txqueuelen 0 (Ethernet)
RX packets 6934 bytes 575269 (561.7 KiB)
RX errors 0 dropped 334 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
编写/etc/hosts文件 vi /etc/hosts
在末尾添加
192.168.100.101 master
192.168.100.102 slave1
192.168.100.103 slave2
配置免密
输入 ssh-keygen 一直敲回车
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:a5KqXjGa6r1CO1pe9cG9bR3Pp2om6BstpOB9l6SW24E root@master
The key's randomart image is:
+---[RSA 2048]----+
| |
| |
| |
| . . |
| + . S o . |
| . + * = O + . + |
|. = + = E.* o . +|
| B.o . =.*.oo ..|
|=o*+o .+..+... |
+----[SHA256]-----+
复制密钥
ssh-copy-id master
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: “/root/.ssh/id_rsa.pub”
The authenticity of host ‘master (192.168.100.102)’ can’t be established.
RSA key fingerprint is SHA256:nuf/qVhd2k6k0u5t7GvhylqRi+4xMC3MNGmJKJNXipo.
RSA key fingerprint is MD5:e6:fd:96:10:3f:2c:9a:68:40:cc:d7:7c:e2:ee:6e:67.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed – if you are prompted now it is to install the new keys
root@master’s password:
Number of key(s) added: 1
Now try logging into the machine, with: “ssh ‘master’”
and check to make sure that only the key(s) you wanted were added.
ssh-copy-id slave1
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: “/root/.ssh/id_rsa.pub”
The authenticity of host ‘slave1 (192.168.100.103)’ can’t be established.
RSA key fingerprint is SHA256:nuf/qVhd2k6k0u5t7GvhylqRi+4xMC3MNGmJKJNXipo.
RSA key fingerprint is MD5:e6:fd:96:10:3f:2c:9a:68:40:cc:d7:7c:e2:ee:6e:67.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed – if you are prompted now it is to install the new keys
root@slave1’s password:
Number of key(s) added: 1
Now try logging into the machine, with: “ssh ‘slave1’”
and check to make sure that only the key(s) you wanted were added.
ssh-copy-id slave2
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: “/root/.ssh/id_rsa.pub”
The authenticity of host ‘slave2 (192.168.100.104)’ can’t be established.
RSA key fingerprint is SHA256:nuf/qVhd2k6k0u5t7GvhylqRi+4xMC3MNGmJKJNXipo.
RSA key fingerprint is MD5:e6:fd:96:10:3f:2c:9a:68:40:cc:d7:7c:e2:ee:6e:67.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed – if you are prompted now it is to install the new keys
root@slave2’s password:
Number of key(s) added: 1
Now try logging into the machine, with: “ssh ‘slave2’”
and check to make sure that only the key(s) you wanted were added.
复制hosts文件到slave机器上
scp /etc/hosts slave1:/etc/
hosts 100% 219 218.0KB/s 00:00
scp /etc/hosts slave2:/etc/
hosts 100% 219 218.0KB/s 00:00
在两台slave机器里也配置免密连接
ssh-keygen
ssh-copy-id master
ssh-copy-id slave1
ssh-copy-id slave2
复制jdk到slave1、slave2
scp -rq /opt/module/java slave1:/opt/module
scp -rq /opt/module/java slave2:/opt/module
复制环境变量
scp /etc/profile slave1:/etc/profile
scp /etc/profile slave2:/etc/profile
任务4
4、 在Master将Hadoop解压到/opt/module(若路径不存在,则需新建)目录下,并将解压包分发至slave1、slave2中,其中master、slave1、slave2节点均作为datanode,配置好相关环境,初始化Hadoop环境namenode,将初始化命令及初始化结果截图(截取初始化结果日志最后20行即可)粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下;
解压Hadoop
[root@master ~]# tar zxvf /opt/software/hadoop-3.1.3.tar.gz -C /opt/module/
重命名文件夹
[root@master ~]# mv /opt/module/hadoop-3.1.3 /opt/module/hadoop
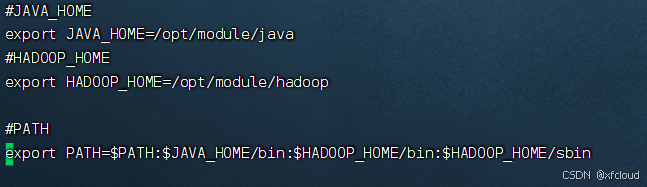
环境配置 vi /etc/profile
增加下面代码
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop
#PATH
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
使环境生效
source /etc/profile
配置hadoop文件
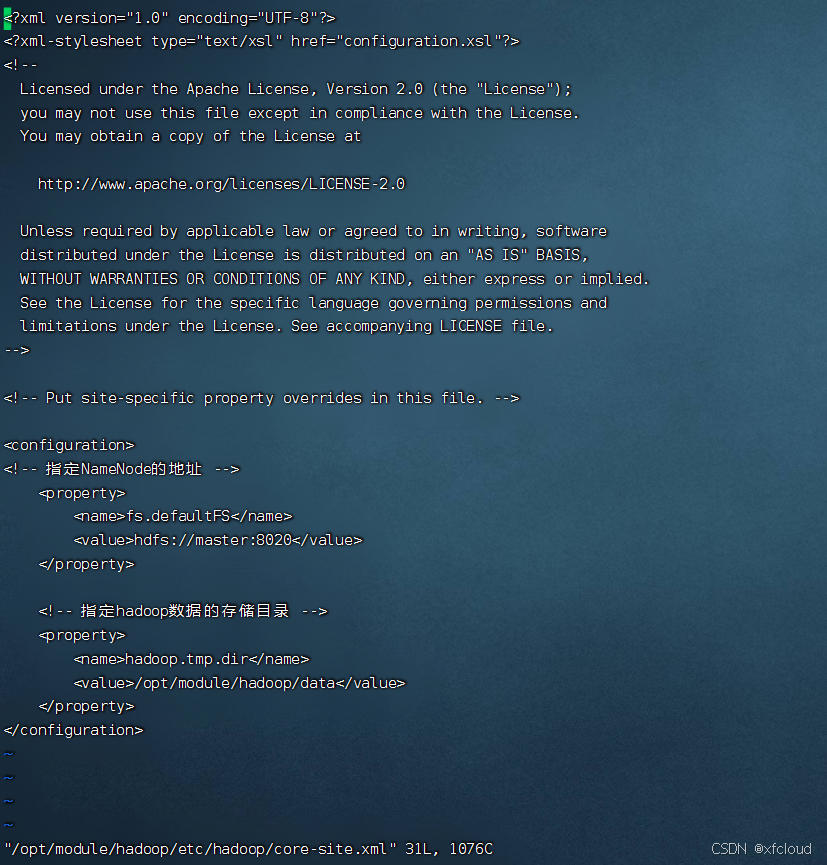
core-site.xml
vi /opt/module/hadoop/etc/hadoop/core-site.xml
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop/data</value>
</property>
hdfs-site.xml
vi /opt/module/hadoop/etc/hadoop/hdfs-site.xml
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>master:9870</value>
</property>
<!-- 2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave2:9868</value>
</property>
yarn-site.xml
vi /opt/module/hadoop/etc/hadoop/yarn-site.xml
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<!-- 环境变量的继承 --> ·
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,
CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
mapred-site.xml
vi /opt/module/hadoop/etc/hadoop/mapred-site.xml
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
hadoop-env.sh
vi /opt/module/hadoop/etc/hadoop/hadoop-env.sh
把下面代码复制到这个文件末尾
export JAVA_HOME=/opt/module/java
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
workers
vi /opt/module/hadoop/etc/hadoop/workers
localhost删除这个填下面的代码
master
slave1
slave2
分发到集群去
分发环境变量
[root@master ~]# scp /etc/profile slave1:/etc/
[root@master ~]# scp /etc/profile slave2:/etc/
分发hadoop
[root@master ~]# scp -rq /opt/module/hadoop slave1:/opt/module/
[root@master ~]# scp -rq /opt/module/hadoop slave2:/opt/module/
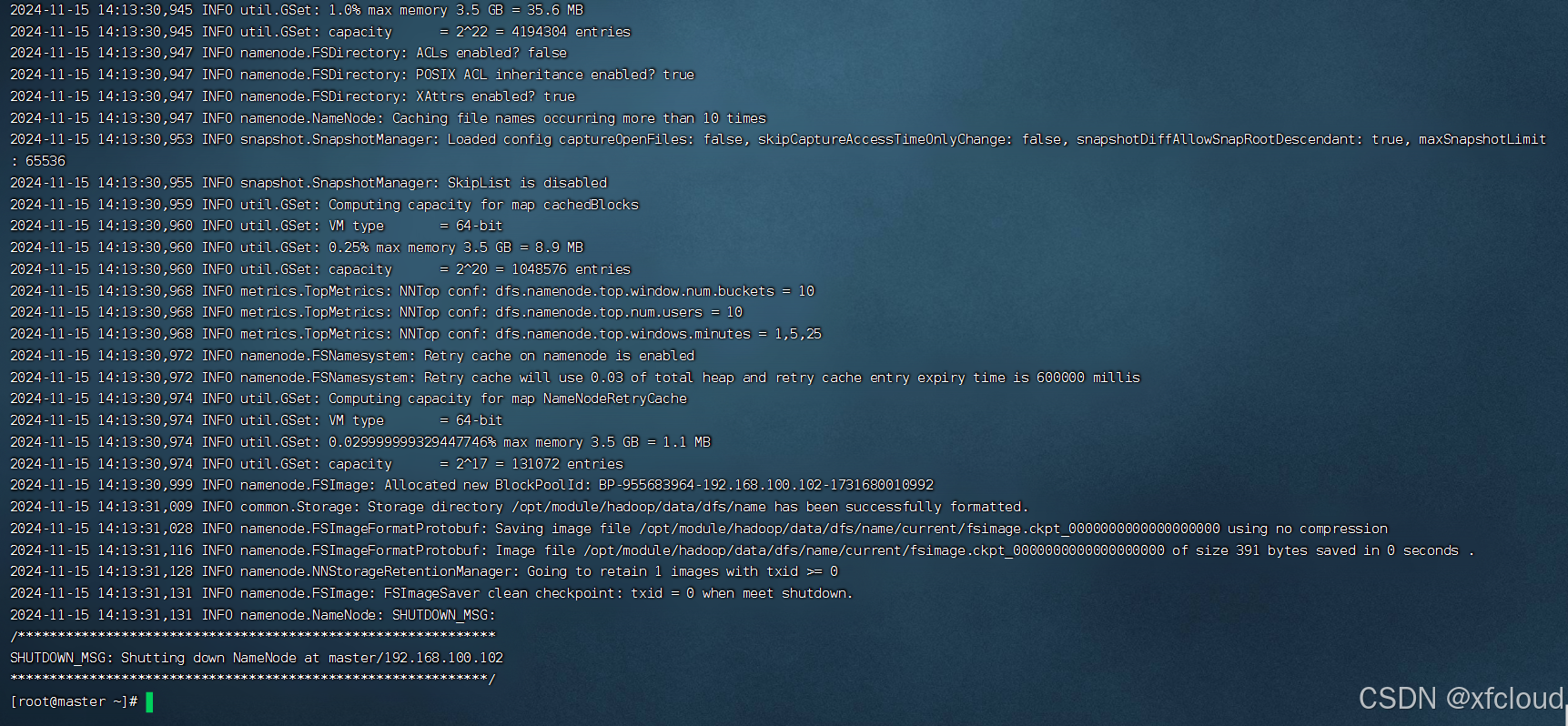
初始化Hadoop环境namenode
[root@master ~]# hdfs namenode -format
任务5
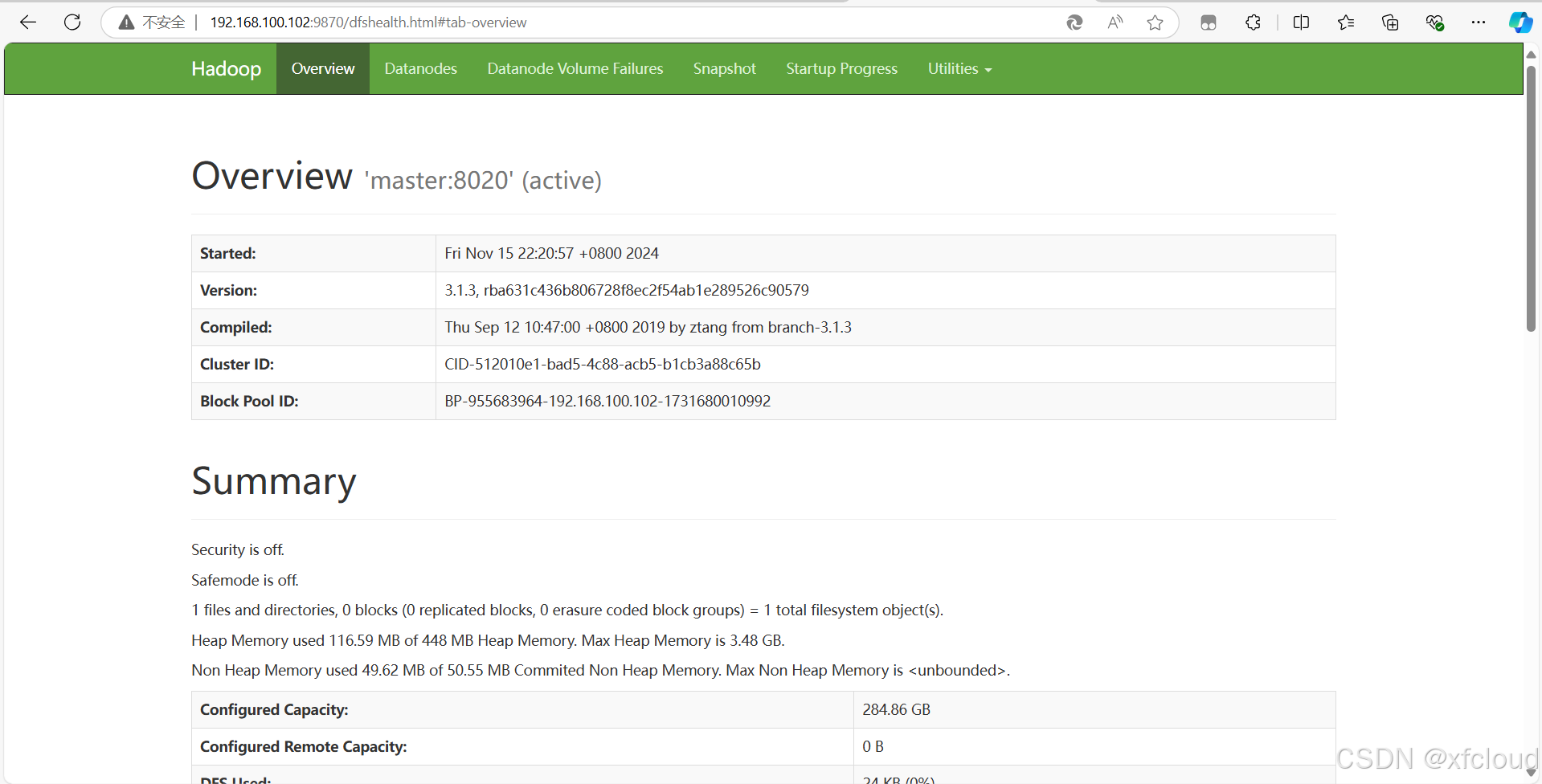
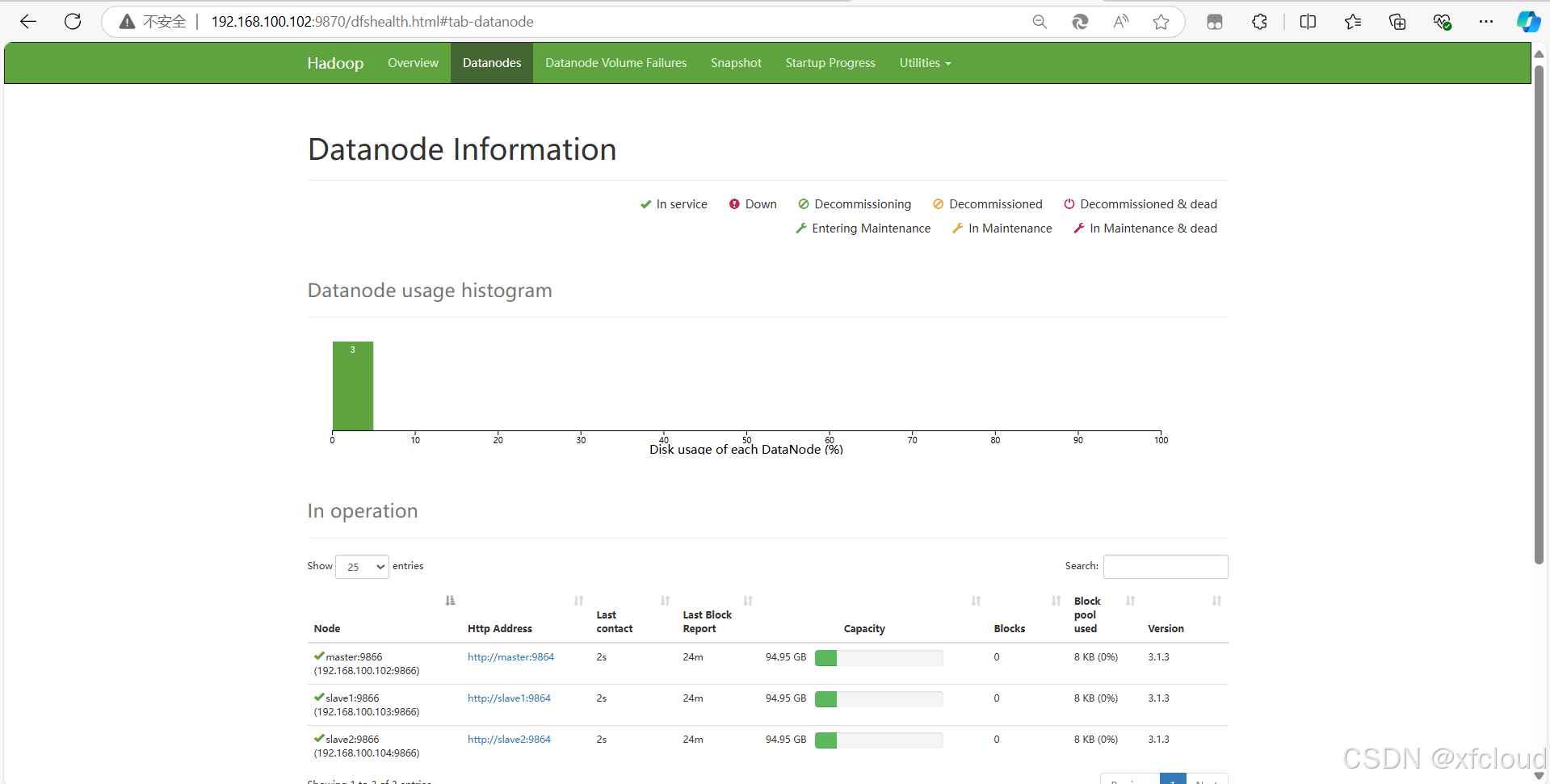
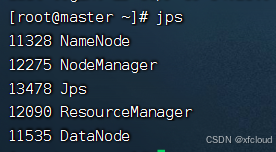
5、 启动Hadoop集群(包括hdfs和yarn),使用jps命令查看Master节点与slave1节点的Java进程,将jps命令与结果截图粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下。
启动Hadoop集群
[root@master ~]# start-all.sh
或者
[root@master ~]# /opt/module/hadoop/sbin/start-all.sh
使用jps命令查看Master节点与slave1节点的Java进程
[root@master ~]# jps
[root@slave1 ~]# jps
12161 Jps
11112 NodeManager
10846 DataNode
[root@slave2 ~]# jps
10451 DataNode
10821 NodeManager
10582 SecondaryNameNode
11944 Jps
测试web网页是否正常http://192.168.100.101:9870