机翻,自己方便对着原文看的
Abstract
大型语言模型(llm)在语言理解和生成方面表现出了显著的能力。然而,这种令人印象深刻的能力通常伴随着相当大的模型大小,这在部署、推理和训练阶段都提出了重大的挑战。由于LLM是一个通用任务求解器,我们以任务不可知的方式探索其压缩,旨在保留原始LLM的多任务求解和语言生成能力。实现这一目标的一个挑战是LLM的训练语料库的巨大规模,这使得数据传输和模型后训练都过于繁重。因此,我们在两个约束的范围内解决llm的压缩问题:任务无关性和对原始训练数据集的依赖最小化。我们的方法被命名为LLM- pruner,采用基于梯度信息选择性去除非关键耦合结构的结构性剪枝,最大限度地保留LLM的大部分功能。为此,可以通过调优技术LoRA在3小时内有效地恢复修剪模型的性能,只需要50K数据。我们在LLaMA、Vicuna和ChatGLM三个llm上验证了LLM-Pruner,结果表明压缩后的模型仍然具有令人满意的零射击分类和生成能力。代码可从https://github.com/horseee/LLM-Pruner获得
1 Introduction
最近,大型语言模型(Large Language Models, llm)[39, 51, 50, 44, 64, 4,74]在语言理解和生成方面表现出了卓越的能力。随着模型尺寸的增加,它们更有能力处理复杂的任务[3,5,58,60],甚至表现出应急能力[57]。然而,尽管llm具有令人印象深刻的性能,但它在部署和推理方面提出了挑战。它们的广泛规模产生了大量的计算需求,并且所涉及的大量参数可能导致长延迟和其他相关问题。在预训练语言模型(PLM)的背景下,提出了几种技术来解决这些问题,如模型修剪[56,61,72,21],知识蒸馏[46,41,47],量化[1,13]。
虽然以前的方法在参数缩减中有效地保持了模型性能,但它们主要针对特定领域内的压缩或特定任务压缩上下文中的指定任务。例如,在特定的数据集上对PLM进行微调,例如GLUE基准中的一个分类任务[53],然后将这些模型提炼成更小的分类模型[46,18]。尽管这种范式可能被用于LLM压缩,但它损害了LLM作为通用任务求解器的能力,使其只适合于单个任务。
因此,我们努力在新的设置中压缩LLM:减少LLM的大小,同时保留其作为通用任务求解器的多种功能,如图1所示。这介绍了llm的任务无关压缩,它提出了两个关键挑战:
LLM培训语料库的规模是巨大的。以前的压缩方法严重依赖于训练语料库。LLM已经将语料库规模升级到1万亿个token或更多[17,51]。大量的存储需求和较长的传输时间使得数据集难以获取。此外,如果数据集是专有的,则训练语料库的获取几乎是不可能的,这是在[74,39]中遇到的情况。
修剪后的LLM培训后的不可接受的长时间。现有的方法需要大量的时间对较小的模型进行后训练[55,28]。例如,TinyBERT中的一般蒸馏大约需要14 GPU天[20]。即使在训练后,特定任务的BERT压缩模型也需要大约33个小时[61,22]。随着llm的模型和语料库的规模迅速增加,这一步必然会消耗更长的时间
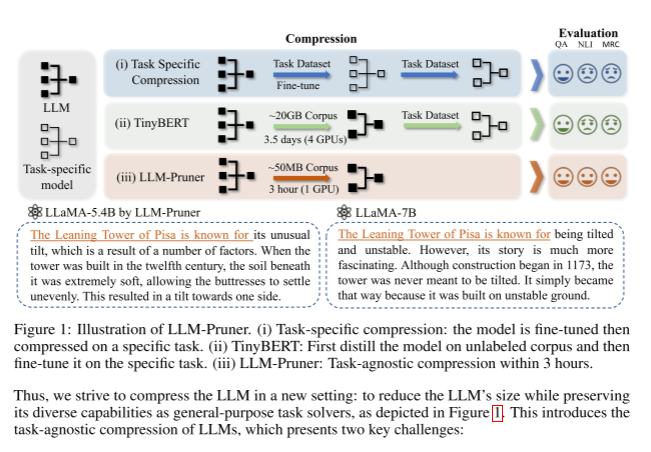
图1:LLM-Pruner示意图。(i)特定任务压缩:对模型进行微调,然后对特定任务进行压缩。(ii) TinyBERT:首先在未标记的语料库上提取模型,然后在特定任务上对其进行微调。(iii) LLM-Pruner: 3小时内的任务无关压缩。
为了解决上述与llm的任务无关压缩相关的挑战,我们引入了一种称为LLM-Pruner的新方法。由于我们的目标是压缩llm与减少数据依赖和加速训练后,如何修剪模型与最小的破坏起源是至关重要的。为了实现这一点,我们提出了一种依赖检测算法来识别模型内的所有依赖结构。一旦确定了耦合结构,我们采用一种有效的重要性估计策略,在任务不可知的情况下选择最优的剪枝组,其中考虑了一阶信息和近似的hessian信息。最后,执行快速恢复阶段,对有限数据的剪枝模型进行后训练。
贡献。在本文中,我们提出了一个新的框架,LLM-Pruner,用于大型语言模型的任务不可知压缩。据我们所知,LLM-Pruner是第一个为llm的结构化修剪而设计的框架。我们总结了LLMPruner的优点:(i)任务无关压缩,其中压缩的语言模型保留了作为多任务求解器的能力。(ii)减少了对原始训练语料库的需求,压缩只需要50k个公开可用的样本,大大减少了获取训练数据的预算(iii)快速压缩,压缩过程在三个小时内结束。(iv)自动结构修剪框架,其中所有相关结构都分组,无需任何人工设计。使用9个数据集对压缩模型进行评估,以评估裁剪模型的生成质量和零射击分类性能。实验结果表明,即使去除20%的参数,剪枝后的模型仍能保持原模型94.97%的性能。
2 Related Work
语言模型的压缩。语言模型[9,31,25]已经得到了广泛的关注,并且增加了减少参数大小和减少延迟的需求[23,48]。为了压缩语言模型,以前的工作可以分为几类:网络修剪[21,63,32,15],知识蒸馏[46,47,40],量化[68,1,71]和其他技术,如早期退出[62]或动态令牌约简[69]。我们专注于语言模型的修剪,特别是结构修剪b[26]。结构修剪从神经网络中去除整个过滤器,这对硬件更友好。有几种方法可以去除结构,如依赖于11的剪枝[16,72]、一阶重要性估计[18]、基于hessian的估计[21,54]或最优脑外科医生[24,21]。结构剪枝中的剪枝单元,有的采用整层[10]作为最小单位,有的采用多头注意[52]或前馈层[18,36]作为基本结构进行剪枝。CoFi[61]研究了不同粒度的修剪单元。
高效和低资源压缩。随着神经网络模型规模的不断扩大,对高效、低资源压缩的需求也越来越大[67,66,30,29,65]。在高效压缩方面,[22]通过将重构误差定义为线性最小二乘问题来加速后训练。[13,12]提出分层最佳脑外科医生。对于训练语料库可用性的约束,无数据修剪[45,70]提出了几种通过测量神经元相似度来修剪模型的策略。此外,[34,33,42]提出了在不依赖模型训练语料库的情况下提取模型的方法。然而,这些方法太耗时,涉及到通过反向传播预训练模型来合成样本。
3 Methods
在本节中,我们将详细解释LLM-Pruner。继传统模型压缩管道[22]之后,LLM-Pruner包括三个步骤:(1)发现阶段(第3.1节)。这一步的重点是识别llm中相互依赖的结构组。(2)估计阶段(第3.2节)。一旦对耦合结构进行分组,第二步需要估计每组对模型整体性能的贡献,并决定修剪哪一组。(3)恢复阶段(第3.3节)。这一步包括快速的后训练,以减轻由于结构移除而导致的潜在性能下降。
3.1 Discover All Coupled Structure in LLMs
鉴于训练后数据的可用性有限,在压缩模型时,必须优先考虑以最小的损伤去除结构。这强调了基于依赖的结构修剪,它确保了耦合结构的修剪是一致的。我们在第4.3节中提供了一个实验,以显示在压缩大型语言模型时基于依赖的结构修剪的重要性。
LLM的结构依赖关系。与[11]类似,修剪从构建llm的依赖项开始。假设Ni和Nj是模型中的两个神经元,in (Ni)和Out(Ni)表示指向Ni或指向Ni的所有神经元。结构之间的依赖关系可以定义为

触发依赖关系图。通过定义关联关系,可以对LLM中的耦合结构进行自动分析。将LLM中的任何神经元视为初始触发器,它具有激活依赖于它的神经元的能力。随后,这些新触发的神经元可以作为后续的触发器来识别依赖并激活各自的依赖神经元。这个迭代过程一直持续到没有新的神经元被检测到。然后,这些神经元形成一组进行进一步修剪。以LLaMA为例,通过搜索所有神经元作为初始触发器,我们可以找到所有的耦合结构,如图2所示。
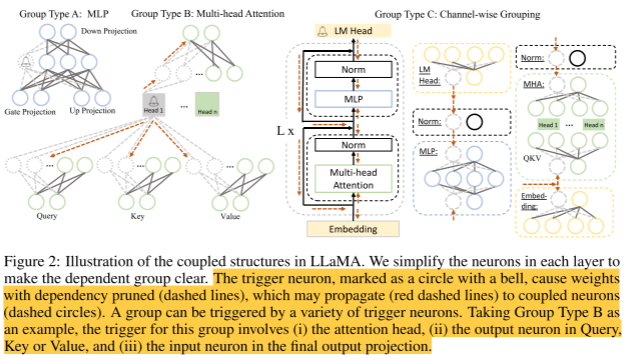
图2:LLaMA的耦合结构示意图。我们简化了每一层的神经元,使依赖组清晰。触发神经元,标记为带有钟形的圆圈,产生依赖性被修剪的权重(虚线),它可能会传播(红色虚线)到耦合神经元(虚线)。一个群体可以被多种触发神经元触发。以B组为例,该组的触发器涉及(i)注意头,(ii)查询、键或值中的输出神经元,(iii)最终输出投影中的输入神经元。
考虑到不同LLM结构的多样性,人工分析和去除每个LLM中的耦合结构可能非常耗时。而利用LLM-Pruner,可以自动识别和提取所有的耦合结构。
3.2 Grouped Importance Estimation of Coupled Structure
到目前为止,模型内的所有耦合结构都进行了分组。同一组中的权重应该同时被修剪,因为部分修剪不仅会增加参数大小,还会引入不一致的中间表示。因此,我们估计作为一个整体的组的重要性,而不是评估模块的重要性。鉴于对训练数据集的访问有限,我们探索使用公共数据集或手动创建的样本作为替代资源。尽管这些数据集的域可能与训练集不完全一致,但它们仍然为评估重要性提供了有价值的信息。
到目前为止,模型内的所有耦合结构都进行了分组。同一组中的权重应该同时被修剪,因为部分修剪不仅会增加参数大小,还会引入不一致的中间表示。因此,我们估计作为一个整体的组的重要性,而不是评估模块的重要性。鉴于对训练数据集的访问有限,我们探索使用公共数据集或手动创建的样本作为替代资源。尽管这些数据集的域可能与训练集不完全一致,但它们仍然为评估重要性提供了有价值的信息。
Vector-wise重要性。假设给定一个数据集D = {xi, yi}N i=1,其中N为样本数。在我们的实验中,我们设置N = 10,并使用一些公开的数据集作为d的来源。A组(之前定义为一组耦合结构)可以定义为G = {Wi}M i=1,其中M为一组中耦合结构的数量,Wi为每个结构的权值。在修剪时,我们的目标是去除对模型预测影响最小的组,这可以通过loss中的偏差来表示。特别地,为了估计wi的重要性,损耗的变化可以表示为[24]:

H是海森矩阵。这里,L表示下一个令牌预测损失。在之前的工作中,第一项通常被忽略[24,54,12],因为模型已经收敛到训练数据集上,其中∂L∈/∂Wi≈0。然而,由于这里的D不是从原始训练数据中提取的,这意味着∂L∈/∂Wi∈≈0。这为在LLM下通过梯度项确定wi的重要性提供了一个理想的性质,因为在LLM上计算第二项,即Hessian矩阵是不切实际的,复杂度为O O N2。
Element-wise重要性。以上可以看作是权重Wi的估计值。我们可以在更细的粒度上推导另一种重要性度量,其中评估Wi中的每个参数的重要性
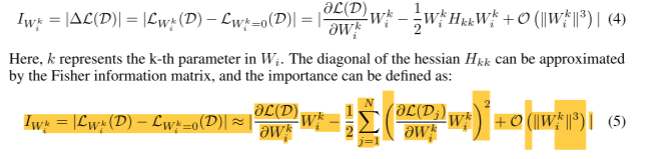
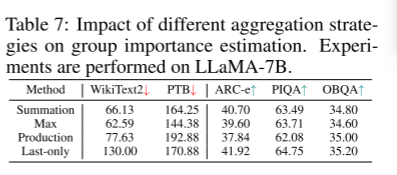
组织的重要性。通过使用IWk i或IWi,我们可以在参数或权重向量的粒度上估计重要性。记住我们的目标是估计G的重要性,我们以四种方式汇总重要性分数:(i)总结:IG = PM i=1 IWi或IG = PM i=1 pkiwi, (ii)生产:IG = QM i=1 IWi或IG = QM i=1 pkiwi, (iii)最大:IG = maxM i=1 IWi或IG = maxM i=1 pkiwi;(iv) last - only:由于删除依赖组中最后一个执行结构相当于删除该组内的所有计算结果,因此我们将最后一个执行结构的重要性分配为该组的重要性:IG = IWl或IG = P k IWk l,其中l为最后一个结构。在评估每个组的重要性之后,我们对每个组的重要性进行排序,并根据预定义的修剪比例修剪重要性较低的组。

3.3 Fast Recovery with Low-rank Approximation
为了在有限数据条件下加快模型恢复过程,提高模型恢复效率,将恢复阶段需要优化的参数数量最小化是至关重要的。为了实现这一点,我们使用低秩近似LoRA[19]对修剪后的模型进行后训练。模型中每个可学习的权重矩阵,记为W,包含LLM中已修剪和未修剪的线性投影,可以表示为W。W的更新值∆W可以分解为∆W = PQ∈Rd−×d,其中P∈Rd−×d, Q∈Rd×d。正向计算现在可以表示为:

没看懂这句啥意思,什么叫包含LLM中已修剪和未修剪的线性投影,他应该是整组都给他去掉阿,不可能包含这个线性层剪但没剪完全,留下的应该都是没修剪的才对阿。这个已修剪和未修剪的定义是啥,有大佬帮我纠正一下吗

其中b是密集层中的偏置。只训练P和Q降低了整体的训练复杂度,减少了对大规模训练数据的需求。另外,额外的参数P和Q可以重新参数化为∆W,不会在最终的压缩模型中产生额外的参数。
4 Experiments
4.1 Experimental Settings
Foundation Large Language Model.为了展示LLM-Pruner的有效性和通用性,我们在三种具有两种结构的开源大型语言模型上进行了测试:LLaMA-7B b[51]、Vicuna-7B bbbb2和ChatGLM-6B[74]。
Evaluation and Datasets.
为了评估该模型在任务不确定设置下的性能,我们遵循LLaMA的评估,对常识推理数据集:BoolQ[6]、PIQA[2]、HellaSwag[73]、WinoGrande[43]、ARC-easy[7]、ARC-challenge[7]和OpenbookQA[38]进行零次任务分类。如[14]所示,该模型对多项选择任务中的选项进行排序,或者在开放式中生成答案。此外,我们还对WikiText2[37]和PTB[35]进行了零次困惑(PPL)分析,以补充我们的评估。
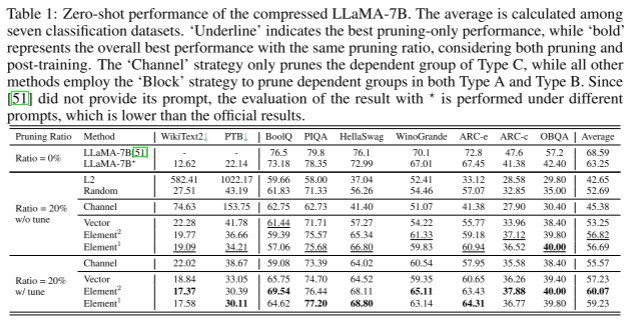
表1:压缩LLaMA-7B的零弹性能。在7个分类数据集之间计算平均值。“下划线”表示仅修剪的最佳性能,而“粗体”表示在考虑修剪和后训练的情况下,具有相同修剪比例的整体最佳性能。“Channel”策略只对Type C的依赖组进行了修剪,而其他所有方法都采用了“Block”策略对Type A和Type b的依赖组进行了修剪。由于[51]没有提供其提示符,因此使用—对结果的评估是在不同的提示符下进行的,比官方的结果要低。 (A,B,C在图2里,A线性层,B注意力模块,C整个解码器)Element上面带了1,2表示用1,2阶,上面Element-wise计算loss的方式
这个图前面两个看的困惑度,越低越好,后面几个数据集看的正确率越高越好,均值是后面几个正确率的均值。
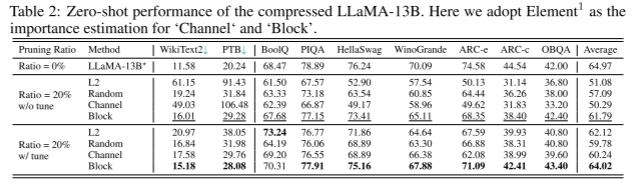
表2:压缩LLaMA-13B的零弹性能。这里我们采用Element1作为“Channel”和“Block”的重要性估计。
实现细节。在模型修剪过程中,我们从Bookcorpus[75]中随机选择10个样本,每个样本截断为128个序列长度,作为LLaMA和Vicuna的依赖关系建立和梯度计算的校准样本。对于ChatGLM,我们从DailyDialog[27]中随机选择10个样本。在恢复阶段,我们使用了Alpaca的清洁版本[49],其中包括大约50k个样本。值得注意的是,调优这些样本只需要在单个GPU上花费3个小时,只有2个epoch。更多关于剪枝和训练的超参数见附录B。
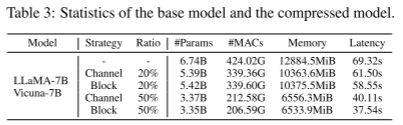
压缩模型统计表3给出了我们实验中使用的7B模型的统计数据:参数计数、mac、内存需求和运行每个模型的延迟。使用推理模式进行统计评估,其中向模型提供由64个令牌组成的句子。在一台A5000上的WikiText2测试集下测试延迟。在这里,“块”策略意味着模型中的修剪单元由组类型A和组类型B组成,如图2所示,而“通道”表示要修剪的单元是组类型c。我们将在第4.2节(通道策略与块策略)中深入分析这两种选择。这里所述的剪枝比表示需要剪枝的参数的近似比例,因为每个被剪枝的结构内的参数数量并不完全匹配被剪枝的参数总数。
4.2 Zero-shot Performance
表1、2、4、5给出了剪枝模型的零射击性能。根据在LLaMA上进行的评估,在不进行后训练的情况下,采用20%的参数缩减,修剪后的模型保留了未修剪模型89.8%的性能。通过高效的后训练,分类准确率进一步提高到60.07%,达到原模型准确率的94.97%。这个演示证明了使用LLM-Pruner在非常短的时间内有效压缩模型的可行性,即使不依赖于训练数据。这凸显了LLM-Pruner的优越性:如果需要定制尺寸的较小模型,与重新训练另一个具有令人满意性能的模型相比,LLM-Pruner更具成本效益。然而,如果对50%的参数进行修剪,则会观察到很大的精度下降(见附录C.4)。在高压缩率下压缩llm仍然是一个很大的挑战。
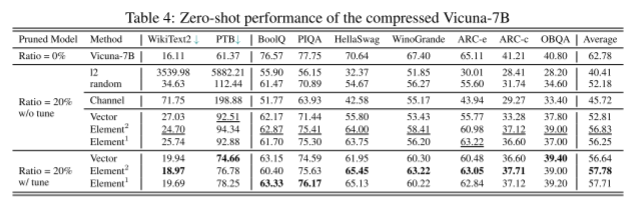
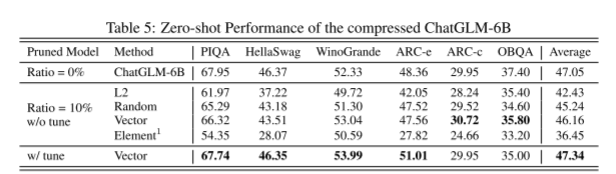
Vicuna-7B的压缩结果与LLaMA的结果一致,在Vicuna-7B上裁剪20%的参数,使性能保持在原模型的92.03%。我们在chatGLM-7B上测试了较小的修剪率为10%,其中修剪后的模型仅经历了0.89%的边际性能下降,可以通过后训练恢复。尽管修剪后的模型优于未压缩的模型,但我们不能断言它比原始模型更好。然而,训练后将其引入更多的英语语料库,尽管有限,但提高了其英语理解能力。
消融:重要性估计的影响。我们对3.2节中提到的所有建议的重要性估计技术进行了测试。结果如表1和表4所示。这里,Elementn表示利用式5中n阶项的重要性评估。向量表示公式3对应的结果。从LLaMA-7B和Vicuna-7B的结果来看,剪枝算法主要是利用各参数的二阶导数来获得最佳的平均性能。尽管如此,考虑到一阶导数比二阶导数效率高得多,尽管产生的结果略差,我们仍然投票选择一阶项作为竞争方法。此外,chatGLM-7B的结果与这些发现有很大不同。对每个参数的重要性估计都失败,甚至比l2还要差,而对权矩阵的重要性估计达到了最好的性能。
Ablation: Channel Strategy vs. Block Strategy
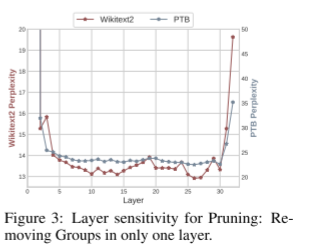
从表2所示的结果可以明显看出,与修剪“块”相比,修剪“通道”会显著降低性能。这种差异的产生是因为堆叠变压器中的各层并没有均匀地分配它们的重要性。如图3所示,第一层和最后一层对模型的性能有深远的影响,与其他层相比,修剪它们会导致更大的性能下降。然而,由于对所有层的“通道”组进行统一处理,不可避免地要对第一层和最后一层进行修剪,从而导致性能显著下降。
4.3 More Analysis
不同修剪速度的影响。我们在图4中研究了在不同修剪比例下修剪LLM的影响。我们将我们的修剪结果与L2策略进行比较,因为L2也是一种无数据修剪算法。在LLaMA实验中观察到,当剪叶率达到20%左右时,依赖于幅度的算法会快速崩溃,导致信息丢失。相反,通过使用LLM-Pruner,我们能够将修剪比率提高到60%左右,同时达到等效的困惑水平。此外,在Vicuna-7B中,删除10%的参数导致的性能下降相当于LLM-Pruner删除60%的性能下降。LLM-Pruner的使用使得可以修剪的模型参数数量显著增加,从而大大减少了计算开销。
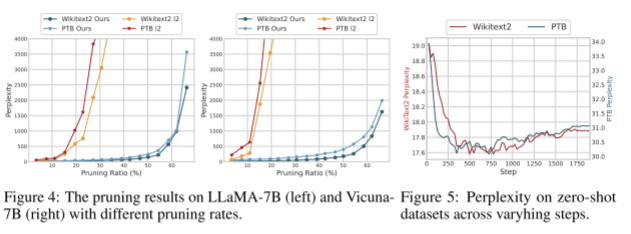
对外部数据集进行调优。为了调整修剪后的模型,我们使用外部数据集Alpaca[49]。后训练过程中,剪枝模型在两个零投数据集上的评价曲线如图5所示。结果表明,在300步内,剪接模型的困惑度迅速下降,然后逐渐增加。我们在附录C.3中提供了更全面的评价。需要注意的是,如果模型训练了过多的步骤,它就会有过度拟合外部数据集的风险,这可能会影响它在其他通用任务中的性能。
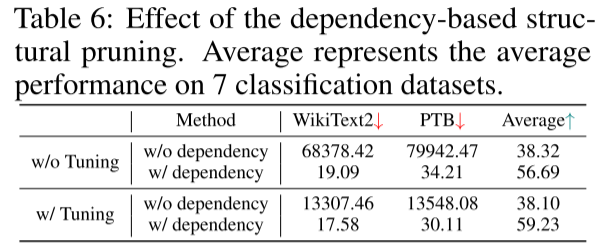
基于依赖的结构化修剪的影响。为了研究基于依赖的结构剪枝的重要性,我们进行了一个破坏组内依赖的实验,其中每个权重矩阵Wi仅根据对其自身的重要性评分进行剪枝。表6展示了结构修剪中依赖关系影响的结果。在缺乏依赖关系的情况下,该模型在零概率生成和分类任务中几乎失败。即使进行了调优,模型也无法恢复,这与基于依赖的修剪的结果有很大的不同。
不同聚合策略的影响。我们对3.2节中提出的聚合算法进行了测试。我们的实验结果揭示了不同聚合策略在模型性能上的显着差异,特别强调了“Last-only”策略。在被评估的方法中,“Max”策略在困惑度方面取得了最有利的结果,表明在句子生成方面增强了连贯性和流畅性。然而,值得注意的是,与所有四种策略相比,“Max”策略表现出最差的零投分类结果。相反,“仅限最后”策略展示了优越的分类性能,但却遭受了最差的生成质量。在我们的实验中,我们通过选择“求和”策略进行权衡,因为它既具有良好的泛化质量,又具有良好的分类性能。
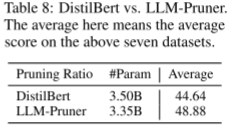
Comparison with DistilBERT 我们在LLaMA-7B上展示了DistilBERT和LLM-Pruner的比较结果,见表8。LLM-Pruner比DistilBERT平均高出4.24%,即使规模更小。原因在于LLM-Pruner在修剪过程中最大限度地减少了模型的中断,而蒸馏器仅仅从两层中选择一层。因此,与蒸馏器相比,LLM-Pruner修剪后的模型需要更少的数据来恢复其性能,从而获得更好的性能。
Scratch Training vs. Pruning.。我们比较了LLM-Pruner和StableLM-3B4具有相似的参数大小。为了确保公平性,两个模型都在Alpaca数据集上进行了微调。两种模型的实验结果见表9。LLM-Pruner用低资源制作轻量级llm,甚至有时可以获得比从头开始培训llm更好的性能。但是,我们也承认,由于训练语料库规模的巨大差距,LLM-Pruner获得的LLaMA-3B并不总是优于其他3B模型从头训练。

More Data for Recovery 尽管我们的初步实验使用了50k个样本,但我们仍然相信,包含额外的数据可以大大增强恢复过程,尽管计算成本要高得多。因此,我们使用包含259万个样本的数据集进行了旨在使用更多数据进行模型恢复的实验[59]。结果详见表10。从结果可以看出,压缩模型的性能与基本模型非常接近,仅表现出0.89%的边际性能下降。

案例研究。我们在表11中提供了使用LLM-Pruner压缩的模型生成的一些句子示例。我们努力确保这些生成的句子与调优语料库中包含的信息之间的重叠最小,这表明信息来自原始模型而不是调优语料库。我们在附录中提供了额外的示例,包括未经后训练的模型生成的句子。从表11中的案例可以明显看出,压缩模型生成的句子与原始模型生成的句子是相当的。他们表现出对给定主题的流畅性、相关性和信息性。然而,在我们的实验中,我们观察到修剪后的模型的性能偏离了原始模型,特别是在生成长句子时。偶尔,它可能会生成无意义或包含重复标记的句子。

5 Conclusion
在本文中,我们提出了LLM-Pruner,一种针对大型语言模型的结构化修剪方法。LLM-Pruner旨在以任务无关的方式压缩规模可观的语言模型,同时最大限度地减少对原始训练语料库的依赖,并保留llm的语言能力。LLM- pruner通过迭代检查模型中的每个神经元作为识别依赖组的触发器来实现这一点,从而构建LLM的依赖图。随后,LLM-Pruner使用参数估计和权重估计来评估这些组的重要性。最后,利用LoRA对剪枝模型进行快速恢复和调整。我们利用各种零射击数据集评估LLM-Pruner对三种不同模型(llama, Vicuna和chatglm)的功效。我们的实验结果表明,LLM-Pruner成功地修剪了模型,减少了计算负担,同时保留了零射击能力。然而,当采用高剪枝率时,例如去除50%的LLaMA参数,会导致相当大的性能下降,导致模型性能大幅下降。此外,我们观察到模型产生不连贯句子的实例。以更高的修剪速率压缩llm仍然是一项具有挑战性的任务。
A Detailed Explanations for the Dependency Rules
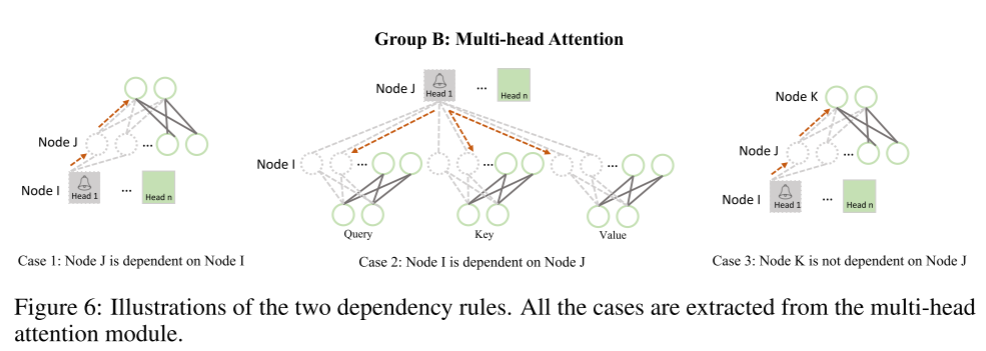
我们提供了两个依赖规则的详细解释。重要的是要注意,这些依赖规则并不仅仅适用于前向计算。相反,它们表示存在于两个方向上的方向关系。例如,在后继层中删除一个节点也可能导致前一层中的一个节点被修剪。回想一下两个依赖规则,如下所示:

B Implementation Details
B.1 For Pruning
对于基线 鉴于之前在任务不可知和低资源设置下对大型语言模型进行结构修剪的工作缺乏,目前我们的模型没有现有的基线。为了全面展示LLM-Pruner的有效性,我们采用了两种额外的评估方法,以及无数据修剪方法。所有这些方法都建立在第3.1节中确定的依赖组之上:
•L2:我们根据其权重矩阵的大小评估每个组的重要性。
•随机:这种方法包括随机选择某些组进行修剪。
对于Block组。根据表3的发现,最好保持前三层和最后一层不变,因为修改这些层的参数会对模型产生重大影响。在每个模块(如MLP或Multi-head Attention)中,发现的组将根据预先设定的比例进行修剪。例如,在LLaMA-7B的MLP层,我们确定了11,008个组,在25%的剪枝率下,该模块将剪枝2,752个组。值得注意的是,所选组的剪枝率高于参数的剪枝率,因为某些层(如上述的嵌入层和排除层)保留了它们的参数。当目标参数修剪率为20%时,我们从第5层到第30层修剪25%。类似地,对于50%的参数去除,我们将60%的组从第4层修剪到第30层。
For the ‘Channel’ Group. 在模型中表现出与维度修剪相似的特征,目标是修剪某些维度。对于MHA中的Query、Key和Value投影,只修剪输入维度,而对于MHA中的Output投影,只修剪输出维度。重要的是要注意,整个依赖关系是自动建立的,不涉及任何手动设计。“通道”组以一种与“块”组互补的方式运作。在Channel Group中,该组的剪枝比等于参数的剪枝比,因为包括嵌入矩阵在内的所有权矩阵都进行了剪枝。因此,参数的修剪比例为20%意味着修剪20%的组,而修剪比例为50%意味着修剪50%的组。
B.2 For Recovery Stage
我们在恢复阶段遵循[19]。在我们的实验中,我们将d设置为8。学习率设置为1e-4,有100个升温步骤。训练的批大小从{64,128}中选择,我们的实验使用AdamW优化器。我们发现最好的训练epoch是2 epoch,因为更多epoch的训练甚至会对模型性能产生负面影响。我们在具有24GB内存的单个GPU上运行我们的实验,如果使用RTX4090,则使用大约2.5小时。所有的线性模块都考虑到有效的调谐。表12显示了一个消融实验。
C More Analysis
C.1 Pruning vs. Quantization
在这里,我们对不同的压缩技术进行了比较分析,并说明这些技术可以有效地结合起来,而性能几乎没有下降。我们选择LLM.int8()[8]作为量化方法的代表性例子。结果表明LLM.int8()优于LLM-Pruner,而LLM-Pruner增强了延迟,减小了参数大小。当这两种技术同时应用时,它们共同减少了内存消耗并加快了推理速度,提供了一种平衡的方法,结合了这两种方法的优点。(怎么结合的没说呀,这个量化,剪枝和微调的顺序是啥,哪种顺序效果好啊)

C.2 Global Pruning vs. Local Pruning
以LLaMA-7B为基础模型,剪枝率为20%,对全局剪枝和局部剪枝进行了对比分析。全局剪枝是指将模型中的所有组排列在一起,而局部剪枝只对同一模块内的组进行剪枝。全局修剪的结果导致不同层和模块之间的宽度不同,而局部修剪确保所有层之间的均匀性。
根据我们的实验结果,我们观察到局部修剪比全局修剪有轻微的优势。我们认为这是因为在不同的层或模块的大小不同,这使得不同层的组之间的重要性得分无法比较。(那是不是对参数量和层数有个公式可以计算,以得到优于局部剪枝的效果)

C.3 Overfitting Phenomena in Post-Training
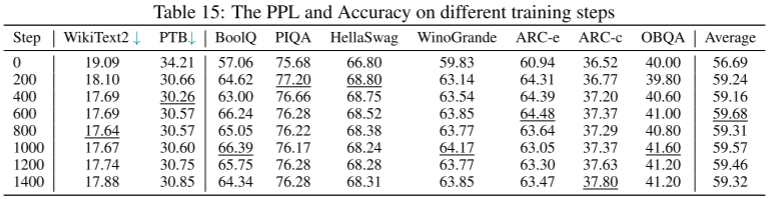
我们对恢复阶段的过拟合问题进行了全面分析,如图5所示。这里的结果涵盖了不同训练步骤的所有9个数据集。根据表15所示的结果,出现了一个明显的趋势:准确性或生成质量最初显示出改善,但随后经历了轻微的下降。这种模式表明恢复过程在短时间内完成。考虑到训练语料库是领域约束的,更多的训练时间可能导致对特定数据集的过度拟合,同时可能损害语言模型的原始功能。
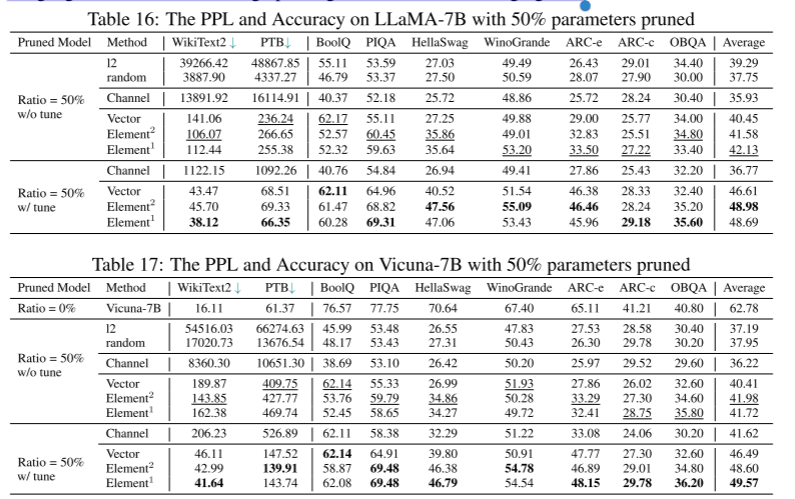
C.4 Pruning with Large Rates
此外,我们还对LLaMA-7B和Vicuna-7B进行了50%参数修剪的试验。与基本模型相比,我们观察到性能显著下降。然而,恢复阶段被证明是有益的,导致大约7.39%的改善。对具有如此高剪枝率的语言模型进行剪枝仍然是一项具有挑战性的任务。