聚类目标:将数据集中的样本划分为若干个通常不相交的子集(“簇”,cluster),子集内部具有相似性,子集之间具有差异性。
原型聚类
通常情况下,算法先对原型进行初始化,再对原型进行迭代更新求解
-
K-means聚类

-
算法流程:

(1)随机选取K个点作为聚类中心,即k个类中心向量
(2)分别计算其他样本点到各个类中心向量的距离,并将其划分到距离最近的类
(3)更新各个类的中心向量
(4)判断新的类中心向量是否发生改变,若发生改变则转到step2,若类中心向量不再发生变化,停止并输出聚类结果
-
算法特点
优点:
原理简单,容易实现
可解释度较强
缺点:
K值很难确定
可能陷入局部最优
对噪音和异常点敏感
聚类效果依赖于聚类中心的初始化
对于非凸数据集或类别规模差异太大的数据效果不好
2.学习向量量化LVQ
学习向量量化同k-means聚类类似,也是试图找到一组原型向量来刻画聚类结构。不同的是,LVQ针对于带有类别标记的数据样本,学习过程利用样本的监督信息(类别标记)来辅助聚类。
流程:随机初始化一组原型向量。从样本集中随机选取一个样本,计算得到最近原型向量,根据类别标记是否相同更新该原型向量,不断迭代直至满足停止条件。

3.高斯混合聚类
假设每个簇中的样本都服从一个多维高斯分布,那么空间中的样本可以看作由k个多维高斯分布混合而成
-
多维高斯分布:

-
高斯混合分布:
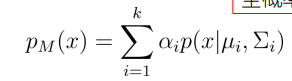

-
后验概率



-
似然函数:
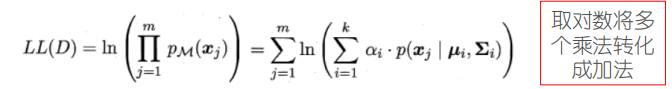
-
算法流程:

把
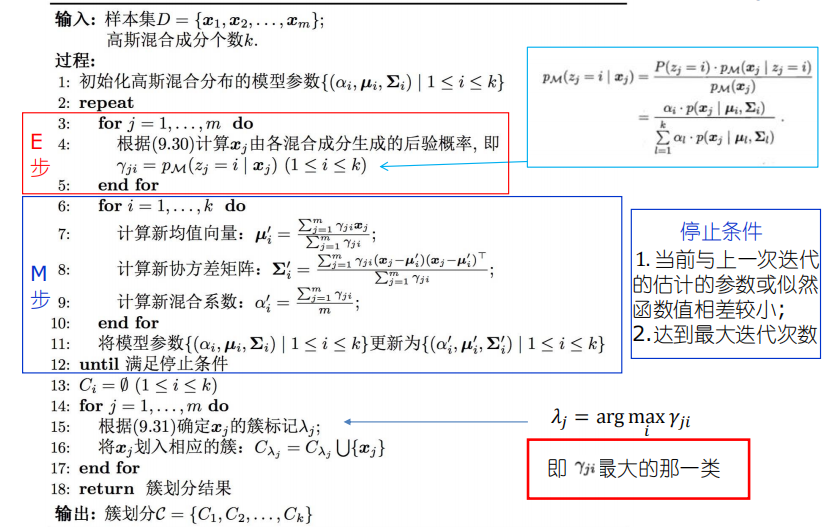
密度聚类
通常情况下,密度聚类算法从样本密度的角度来考察样本之间的可连接性,并基于可连接样本不断扩展聚类簇来获得最终的聚类结果。
特点:
生成任意形状的簇、抗噪声、不要求提前设置K值、有点类似于人类的视觉。

DBSCAN算法:

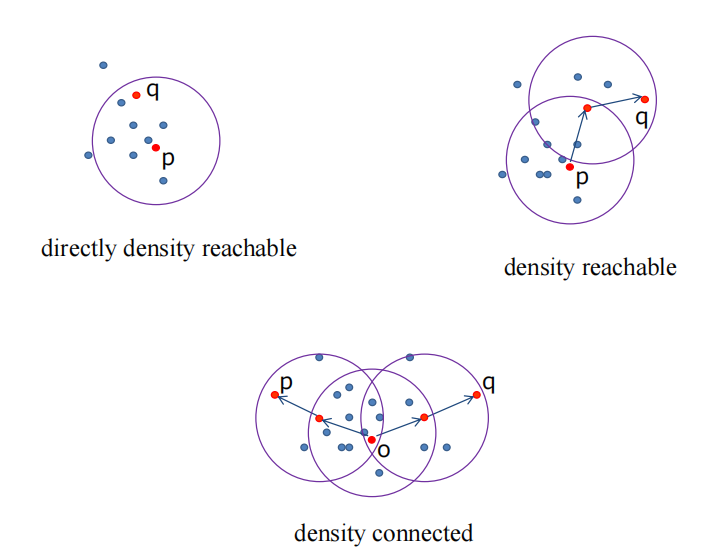


遍历样本找出数据集中的核心对象集。每次循环从核心对象集中取出一个核心对象,根据密度可达,生成一个簇,然后把被划分到该簇中的核心对象从核心对象集中去除。
层次聚类
-
层次聚类试图在不同层次对数据集进行划分,从而形成树形的聚类结构。数据集划分既可采用“自底向上”的聚合策略,也可采用“自顶向下”的分拆策略。
-
灵活停止
AGNES算法(自底向上的层次聚类算法)
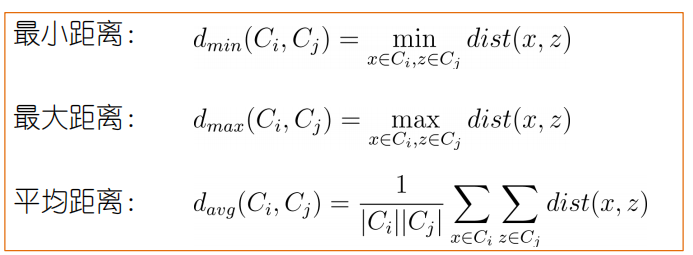

初始化样本,每个样本作为一个初始聚类簇,初始化簇间距离矩阵。合并距离最近的聚类簇,并对合并得到的聚类簇的距离矩阵进行更新,上述过程不断重复直到达到预设的聚类簇数。