Kafka:分布式消息系统的核心原理与安装部署-CSDN博客
自定义 Kafka 脚本 kf-use.sh 的解析与功能与应用示例-CSDN博客
Kafka 生产者全面解析:从基础原理到高级实践-CSDN博客
Kafka 工作流程解析:从 Broker 工作原理、节点的服役、退役、副本的生成到数据存储与读写优化-CSDN博客
Kafka 消费者全面解析:原理、消费者 API 与Offset 位移-CSDN博客
Kafka 分区分配及再平衡策略深度解析与消费者事务和数据积压的简单介绍-CSDN博客
Kafka 核心要点解析_kafka mirrok-CSDN博客
Kafka 核心问题深度解析:全面理解分布式消息队列的关键要点_kafka队列日志-CSDN博客
目录
在大数据处理领域,Kafka 作为一款高性能的分布式消息队列系统,扮演着至关重要的角色。而 Kafka 生产者则是数据进入 Kafka 集群的入口,其性能和可靠性直接影响着整个数据处理流程的效率和质量。本文将深入探讨 Kafka 生产者的相关知识,包括消息发送流程、API 使用、分区策略、生产经验等方面,帮助读者全面理解和掌握 Kafka 生产者的原理与实践。
一、生产者消息发送流程
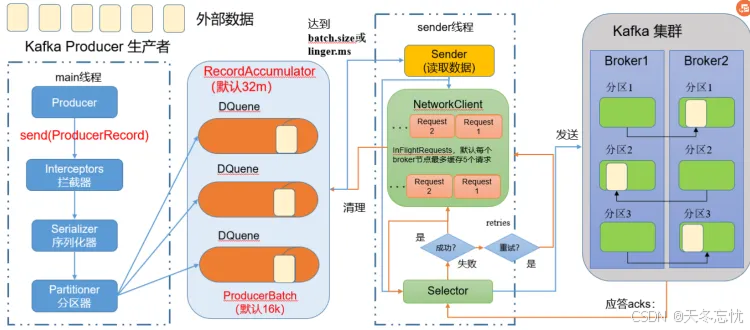
(一)发送原理
Kafka 生产者在消息发送过程中涉及到两个关键线程:main 线程和 Sender 线程。在 main 线程中创建了一个双端队列 RecordAccumulator,它作为消息的缓冲区。main 线程负责将消息发送到 RecordAccumulator 中,而 Sender 线程则不断从 RecordAccumulator 中拉取消息,并将其发送到 Kafka Broker。这种设计实现了生产者与 Broker 之间的异步消息传输,提高了整体的发送效率。
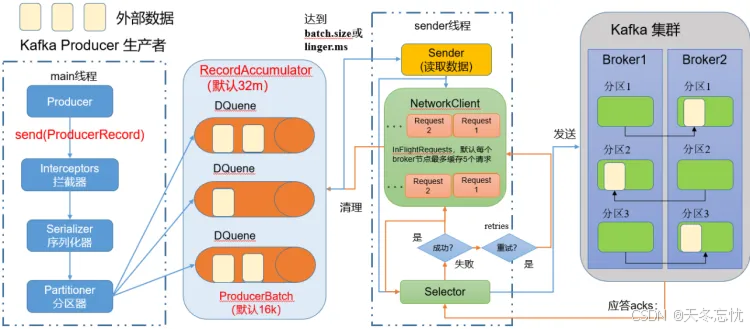

(二)生产者重要参数列表
| 参数名称 | 解释说明 |
| bootstrap.servers | 生产者连接集群所需的 broker 地 址 清 单 。 例 如hadoop11:9092,hadoop12:9092,hadoop13:9092,可以设置 1 个或者多个,中间用逗号隔开。注意这里并非需要所有的 broker 地址,因为生产者从给定的 broker 里查找到其他 broker 信息。 |
| key.serializer 和 value.serializer | 指定发送消息的 key 和 value 的序列化类型。一定要写 全类名。 |
| buffer.memory | RecordAccumulator 缓冲区总大小,默认 32m。 |
| batch.size | 缓冲区一批数据最大值,默认 16k。适当增加该值,可以提高吞吐量,但是如果该值设置太大,会导致数据 传输延迟增加。 |
| linger.ms | 如果数据迟迟未达到 batch.size,sender 等待 linger.time 之后就会发送数据。单位 ms,默认值是 0ms,表示没有延迟。生产环境建议该值大小为 5-100ms 之间。 |
| acks | 0:生产者发送过来的数据,不需要等数据落盘应答。 1:生产者发送过来的数据,Leader 收到数据后应答。 -1(all):生产者发送过来的数据,Leader+和 isr 队列 里面的所有节点收齐数据后应答。默认值是-1,-1 和 all 是等价的。 |
| max.in.flight.requests.per.connection | 允许最多没有返回 ack 的次数,默认为 5,开启幂等性 要保证该值是 1-5 的数字。 |
| retries | 当消息发送出现错误的时候,系统会重发消息。retries 表示重试次数。默认是 int 最大值2147483647。 如果设置了重试,还想保证消息的有序性,需要设置MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION=1 否则在重试此失败消息的时候,其他的消息可能发送成功了。 |
| retry.backoff.ms | 两次重试之间的时间间隔,默认是 100ms。 |
| enable.idempotence | 是否开启幂等性,默认 true,开启幂等性 |
| compression.type | 生产者发送的所有数据的压缩方式。默认是 none,也就是不压缩。 支持压缩类型:none、gzip、snappy、lz4 和 zstd。 |
二、异步发送 API
(一)普通异步发送
需求:
创建 Kafka 生产者,采用异步的方式将外部数据发送到 Kafka Broker,即将数据发送至 32M 的 RecordAccumulator 队列中,无需等待队列中的数据是否发送到 Kafka 集群。
代码编写
- 创建工程 kafka:首先创建一个名为 kafka 的 Java 工程,用于存放 Kafka 生产者相关的代码。
- 导入依赖:在项目的 pom.xml 文件中导入必要的依赖。主要包括 Kafka 客户端依赖 “org.apache.kafka:kafka-clients:3.0.0” 以及用于日志记录的 “org.slf4j:slf4j-log4j12:1.7.25”。
<dependencies> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>3.0.0</version> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>1.7.25</version> </dependency> </dependencies> - 创建包名:创建 “com.bigdata.kafka.producer” 包,用于组织生产者相关的代码类。
- 编写不带回调函数的 API 代码:
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class CustomProducer01 {
public static void main(String[] args) {
// 设置配置信息
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"bigdata01:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
// 创建生产者对象
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);
// 发送消息
for (int i = 0; i < 5; i++) {
ProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>("first","告诉你个秘密:"+i);
kafkaProducer.send(producerRecord);
}
kafkaProducer.close();
}
}
通过上述代码,我们创建了一个简单的 Kafka 生产者,将消息发送到指定的 Kafka 主题。在运行代码时,如果没有日志输出,可以按照以下步骤进行配置:
- 在 resources 文件夹中拷贝一个 log4J.properties 文件,用于配置日志输出格式。
# Global logging configuration # Debug info warn error log4j.rootLogger=DEBUG, stdout # MyBatis logging configuration... log4j.logger.org.mybatis.example.BlogMapper=TRACE # Console output... log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%5p [%t] - %m%n - 清空 target 目录,可以通过执行 “maven clean” 命令来实现。
- 如果遇到连接问题,可能需要修改 C:\Windows\System32\drivers\etc 中 hosts 文件中的映射。
测试:
在 bigdata01 上开启 Kafka 消费者。
bin/kafka-console-consumer.sh --bootstrap-server bigdata01:9092 --topic first(二)带回调函数的异步发送
回调函数会在 producer 收到 ack 时被调用,该方法有两个参数,分别是元数据信息(RecordMetadata)和异常信息(Exception)。如果 Exception 为 null,说明消息发送成功;如果 Exception 不为 null,则说明消息发送失败。需要注意的是,消息发送失败会自动重试,无需在回调函数中手动重试。
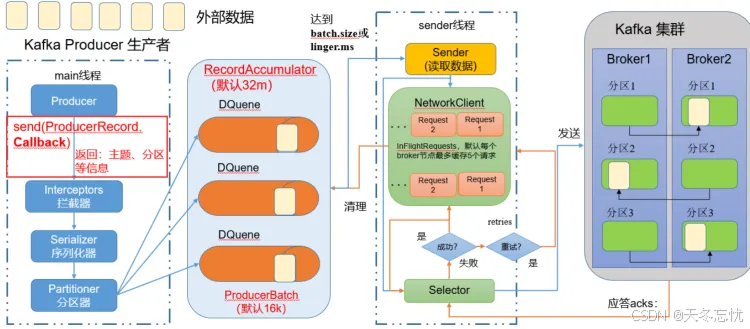
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
public class CustomProducer02 {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"bigdata01:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);
for (int i = 0; i < 5; i++) {
ProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>("first","告诉你个找女朋友的好办法:"+i);
kafkaProducer.send(producerRecord, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if(exception == null){
System.out.println("消息发送成功");
System.out.println(metadata.partition());
System.out.println(metadata.offset());
System.out.println(metadata.topic());
}else{
System.out.println("消息发送失败,失败原因:"+exception.getMessage());
}
}
});
}
kafkaProducer.close();
}
}
在上述代码中,我们为 send 方法添加了回调函数,以便在消息发送完成后获取发送结果信息。在测试时,可以在 bigdata01 上开启 Kafka 消费者,使用 “bin/kafka-console-consumer.sh --bootstrap-server bigdata01:9092 --topic first” 命令来查看接收到的消息。同时,在 IDEA 控制台可以观察到回调信息,包括消息发送成功或失败的状态以及相关的元数据信息。
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first 三、同步发送 API
同步发送的特点是一批数据到达队列中之后,这批数据必须全部都成功发送到 Kafka 集群之后,下一波数据才能发送。实现同步发送只需在异步发送的基础上,对 send 方法调用 get () 方法即可。
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
public class CustomProducerTongBu {
public static void main(String[] args) throws ExecutionException, InterruptedException {
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop11:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);
for (int i = 0; i < 5; i++) {
// 同步发送
kafkaProducer.send(new ProducerRecord<>("first","bigdata: "+i)).get();
}
kafkaProducer.close();
}
}
在测试同步发送时,在 hadoop102 上开启 Kafka 消费者,使用 “bin/kafka-console-consumer.sh --bootstrap-server hadoop11:9092 --topic first” 命令来查看接收到的消息。
bin/kafka-console-consumer.sh --bootstrap-server hadoop11:9092 --topic first 四、生产者分区
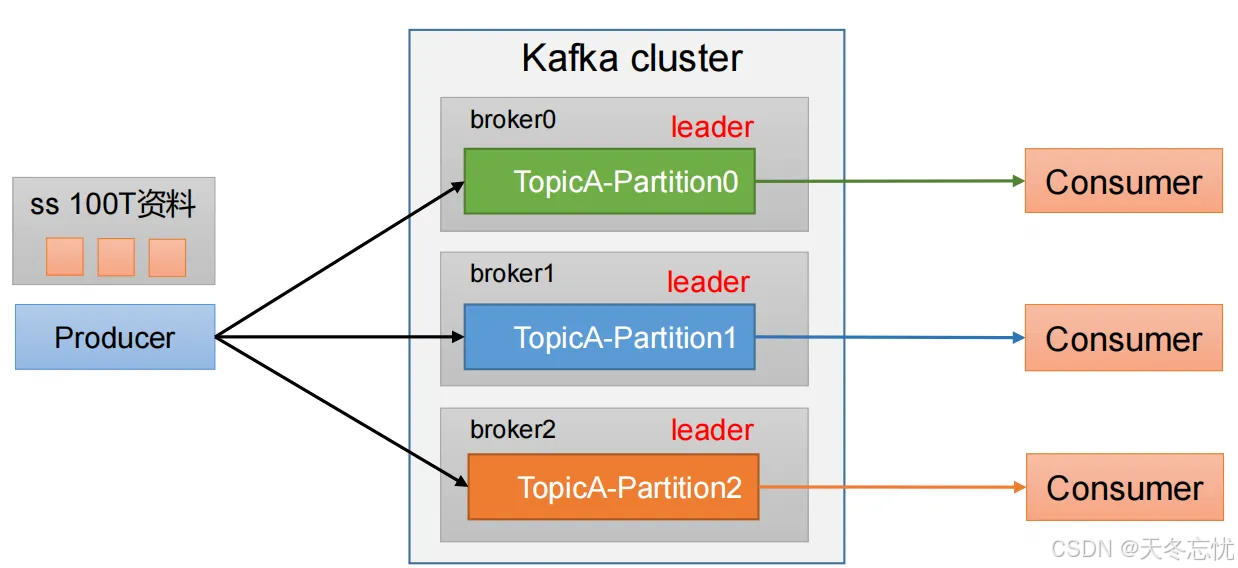
(一)分区好处
- 合理使用存储资源:每个 Partition 在一个 Broker 上存储,可以把海量的数据按照分区切割成一块一块数据存储在多台 Broker 上。通过合理控制分区的数量和分布,可以实现负载均衡的效果,避免数据集中存储在少数几个 Broker 上,提高整个集群的存储利用率和扩展性。
- 提高并行度:生产者可以以分区为单位发送数据,不同的分区可以并行处理,从而提高数据发送的效率。消费者也可以以分区为单位进行消费数据,多个消费者实例可以同时消费不同的分区,进一步提高数据处理的并行度。
(二)生产者发送消息的分区策略
默认的分区器 DefaultPartitioner:
- 如果发送消息时指定了分区,就使用该指定分区。
- 如果没有指定分区但指定了 Key 值,对 Key 进行 hash,然后对分区数取模,得到对应的分区并使用。
- 如果分区和 Key 值都没有指定,使用粘性分区(sticky partition)。粘性分区会在当前批次满了(默认 16k)或者 linger.ms 设置的时间到的时候,随机选择一个分区进行使用,并且在批次未结束前会一直使用该分区,直到批次结束或者需要切换分区。
案例解析:
例如,第一次随机选择 0 号分区,等 0 号分区当前批次满了(默认 16k)或者 linger.ms 设置的时间到,Kafka 再随机一个分区进行使用(如果还是 0 会继续随机)。
案例一:将数据发往指定 partition:
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
public class CustomProducer04 {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"bigdata01:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);
for (int i = 0; i < 5; i++) {
ProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>("first",0,"keyaaa","告诉你个找女朋友的好办法:"+i);
kafkaProducer.send(producerRecord, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if(exception == null){
System.out.println("消息发送成功");
System.out.println(metadata.partition());
System.out.println(metadata.offset());
System.out.println(metadata.topic());
}else{
System.out.println("消息发送失败,失败原因:"+exception.getMessage());
}
}
});
}
kafkaProducer.close();
}
}
在测试时,在 bigdata01 上开启 Kafka 消费者,使用 “bin/kafka-console-consumer.sh --bootstrap-server bigdata01:9092 --topic first” 命令来查看接收到的消息。在 IDEA 控制台可以观察到回调信息,所有消息都将被发送到指定的 1 号分区。
bin/kafka-console-consumer.sh --bootstrap-server bigdata01:9092 --topic first案例二:没有指明 partition 值但有 key 的情况
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
public class CustomProducer05 {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"bigdata01:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);
for (int i = 0; i < 5; i++) {
ProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>("first","keyaaa","告诉你个找女朋友的好办法:"+i);
kafkaProducer.send(producerRecord, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if(exception == null){
System.out.println("消息发送成功");
System.out.println(metadata.partition());
System.out.println(metadata.offset());
System.out.println(metadata.topic());
}else{
System.out.println("消息发送失败,失败原因:"+exception.getMessage());
}
}
});
}
kafkaProducer.close();
}
}
(三)自定义分区器
需求:
实现一个分区器,若发送过来的数据中包含 “bigdata”,就发往 0 号分区,不包含则发往 1 号分区。
实现步骤
- 定义类实现 Partitioner 接口并实现 partition () 方法:
package com.bigdata.producter;
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import java.util.Map;
/**
* 自定义分区器:需求:
* 假如消息中含有bigdata 进入0号分区,假如不含有,进入 1号分区
*
*/
public class CustomPartitioner implements Partitioner {
/**
* 返回信息对应的分区
* @param topic 主题
* @param key 消息的 key
* @param keyBytes 消息的 key 序列化后的字节数组
* @param value 消息的 value
* @param valueBytes 消息的 value 序列化后的字节数组
* @param cluster 集群元数据可以查看分区信息
* @return
*/
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
String val = value.toString();
String val2 = new String(valueBytes);
// value.toString 的结果和 byte数组的结果其实是一样的,使用哪个都可以
System.out.println(val+","+val2);
// String 工具类 api
// 判断一个单词是否在一个字符串中
if(val.contains("bigdata")){
return 0;
}
/* 判断一个词在一句话中的位置,假如存在返回下标,假如不存在,返回 -1
if(val.indexOf("bigdata")!=-1){
}*/
return 1;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}
- 在生产者的配置中添加分区器参数:
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
public class CustomProducer06 {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"bigdata01:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
properties.put("partitioner.class",
"com.bigdata.producter.CustomPartitioner");
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);
for (int i = 0; i < 5; i++) {
ProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>("first","c","告诉你个找bigdata的好办法:"+i);
kafkaProducer.send(producerRecord, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if(exception == null){
System.out.println("消息发送成功");
System.out.println(metadata.partition());
System.out.println(metadata.offset());
System.out.println(metadata.topic());
}else{
System.out.println("消息发送失败,失败原因:"+exception.getMessage());
}
}
});
}
kafkaProducer.close();
}
}
- 测试
在 bigdata01 上开启 Kafka 消费者。
bin/kafka-console-consumer.sh --bootstrap-server bigdata01:9092 --topic first 五、总结
本文深入探讨了 Kafka 生产者相关知识。在消息发送流程方面,其涉及 main 线程与 Sender 线程,main 线程将消息存入 RecordAccumulator 缓冲区,Sender 线程从该缓冲区拉取消息发往 Kafka Broker,同时介绍了如 bootstrap.servers、key.serializer 等一系列重要参数,这些参数对生产者性能与可靠性有着关键影响。
异步发送 API 包含普通异步发送与带回调函数的异步发送。普通异步发送只需构建生产者对象并发送消息,而带回调函数的异步发送能在收到 ack 时获取消息发送结果,包括成功与否及相关元数据信息。同步发送则是在异步发送基础上调用 send 方法的 get () 方法,确保一批数据全部成功发送至集群后才进行下一批数据发送。
生产者分区具有重要意义,既能合理利用存储资源,通过将数据按分区存储在多台 Broker 上实现负载均衡,又能提高并行度,使生产者和消费者可按分区单位进行数据处理。其分区策略有默认分区器,依据是否指定分区和 key 来确定分区方式,还可自定义分区器。例如实现一个根据消息是否包含 “bigdata” 来决定发往 0 号或 1 号分区的自定义分区器,需定义类实现 Partitioner 接口并在生产者配置中添加相应参数。总之,掌握 Kafka 生产者这些知识对于构建高效、可靠的数据处理流程至关重要,无论是开发人员还是运维人员都需深入理解并灵活运用。