目录
2、创建topic为yuekao的主题,并使用flume将数据抽取到该主题的kafka中
3、将kafka中的数据放入到hdfs上,目录为:/yuekao/ods/zhuanzhang
4、 通过datax,对MySQL数据库中的表进行抽取,落入hdfs指定的目录中: /yuekao/ods/user_info
要求:
1、flume自定义拦截器
| 抽取trans_info.json的数据到kafka上,对其中的tr_flag=0的数据进行过滤抛弃,只保留正常的状态数据 |
在pom.xml中放入依赖包:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.25</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.5</version>
</dependency>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.9.0</version>
</dependency>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-sdk</artifactId>
<version>1.9.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.48</version>
</dependency>
使用java代码,自定义拦截器:
package com.bigdata.yuekao04;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import org.codehaus.jackson.JsonNode;
import org.codehaus.jackson.map.ObjectMapper;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
public class DemoInterceptor implements Interceptor {
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
try {
// 获取事件体中的数据(假设数据是JSON格式存储在事件体中)
String data = new String(event.getBody());
// 使用Jackson将JSON字符串解析为JsonNode对象
ObjectMapper objectMapper = new ObjectMapper();
JsonNode jsonNode = objectMapper.readTree(data);
// 获取tr_flag的值
int trFlag = jsonNode.get("tr_flag").asInt();
// 如果tr_flag不等于0,保留该事件
if (trFlag!= 0) {
return event;
}
} catch (IOException e) {
e.printStackTrace();
}
// 如果tr_flag等于0,返回null,表示过滤掉该事件
return null;
}
@Override
public List<Event> intercept(List<Event> list) {
return null;
}
@Override
public void close() {
}
public static class BuilderEvent implements Builder{
@Override
public Interceptor build() {
return new DemoInterceptor();
}
@Override
public void configure(Context context) {
}
}
}打包java代码,放入/flume/lib下面
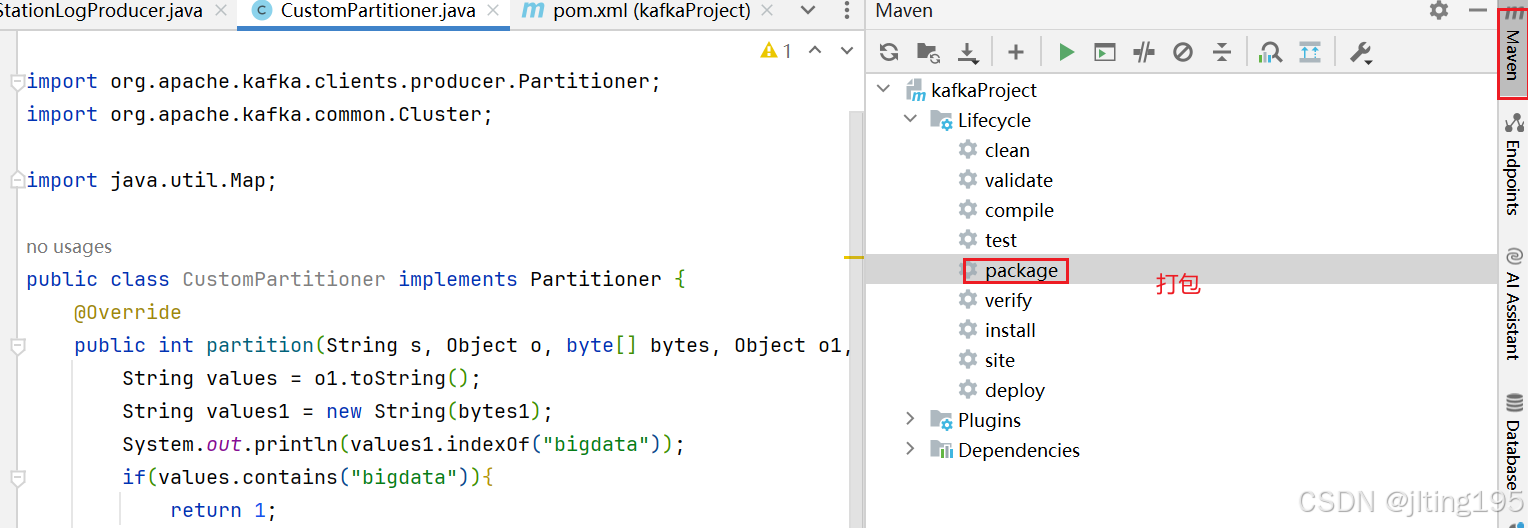
2、创建topic为yuekao的主题,并使用flume将数据抽取到该主题的kafka中
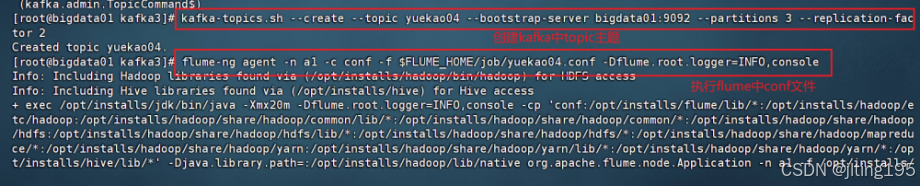
# 定义Flume agent名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 配置source
a1.sources.r1.type = TAILDIR
#以空格分隔的文件组列表。每个文件组表示要跟踪的一组文件
a1.sources.s1.filegroups = f1
#文件组的绝对路径
a1.sources.s1.filegroups.f1=/home/trans_info1.json
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.bigdata.DemoInterceptor$Builder
# 配置channel
a1.channels.c1.type = file
# 配置sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = yuekao04
a1.sinks.k1.kafka.bootstrap.servers = bigdata01:9092
a1.sinks.k1.channel = c13、将kafka中的数据放入到hdfs上,目录为:/yuekao/ods/zhuanzhang
编写conf文件,然后执行该文件,将kafka中的数据放入hdfs中:
a1.sources = r1
a1.channels = c1
a1.sinks=k1
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.kafka.bootstrap.servers = bigdata01:9092,bigdata02:9092,bigdata03:9092
a1.sources.r1.kafka.topics = yuekao04
a1.sources.r1.kafka.consumer.group.id =yuekao
a1.sources.r1.batchSize = 100
a1.sources.r1.batchDurationMillis = 2000
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
a1.sinks.k1.hdfs.path = /yuekao/ods/zhuanzhang/%y-%m-%d
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
a1.sinks.k1.hdfs.fileType = DataStream 结果展示:
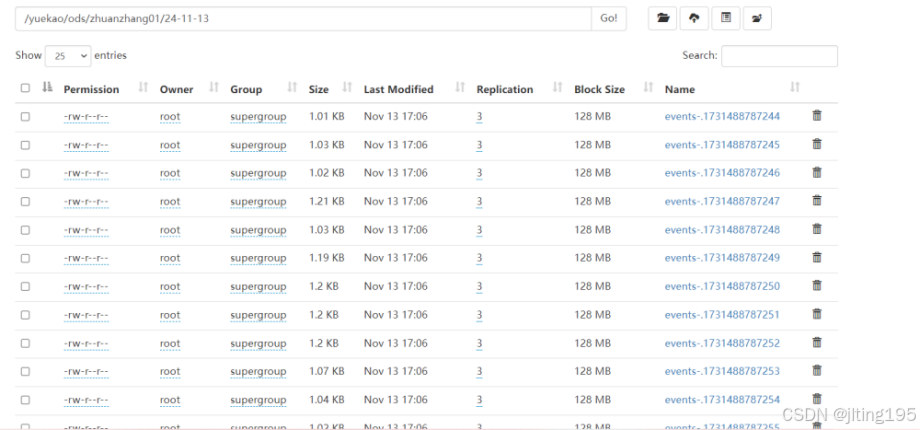
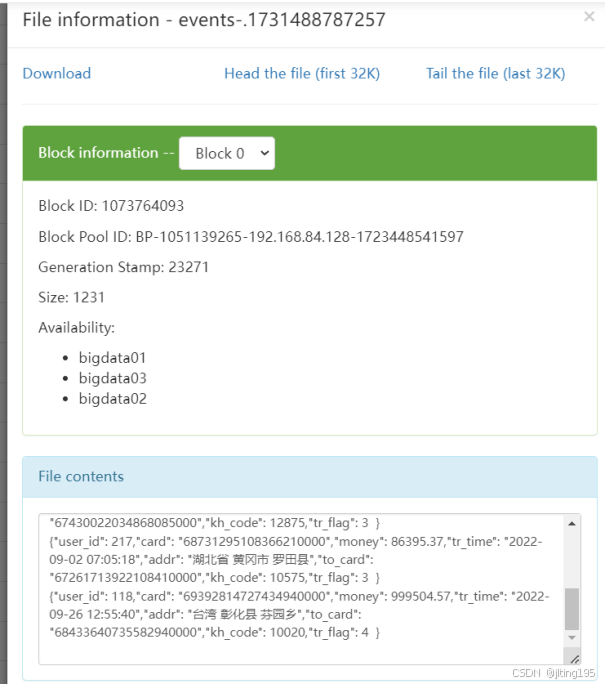
4、 通过datax,对MySQL数据库中的表进行抽取,落入hdfs指定的目录中: /yuekao/ods/user_info
先在mysql中建表,然后将user_info.sql表中数据插入:
CREATE TABLE `user_info` (
`name` VARCHAR (255) ,
phone_num VARCHAR (255) ,
email VARCHAR (255) ,
addr_info VARCHAR (255) ,
gender VARCHAR (255) ,
idno VARCHAR (255) ,
create_time VARCHAR (255) ,
user_id int
);编写json文件(demo.json),然后执行,将数据库中的数据放入hdfs中:
{
"job": {
"setting": {
"speed": {
"channel": 3
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"writeMode": "insert",
"username": "root",
"password": "123456",
"column": [
"name",
"phone_num",
"email",
"addr_info",
"gender",
"idno",
"create_time",
"user_id"
],
"splitPk": "user_id",
"connection": [
{
"table": [
"user_info"
],
"jdbcUrl": [
"jdbc:mysql://bigdata01:3306/yuekao"
]
}
]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://bigdata01:9820",
"fileType": "text",
"path": "/yuekao/ods/user_info",
"fileName": "user_info.txt",
"column": [
{
"name": "name",
"type": "string"
},
{
"name": "phone_num",
"type": "string"
},
{
"name": "email",
"type": "string"
},
{
"name": "addr_info",
"type": "string"
},
{
"name": "gender",
"type": "string"
},
{
"name": "idno",
"type": "string"
},
{
"name": "create_time",
"type": "string"
},
{
"name": "user_id",
"type": "int"
}
],
"writeMode": "append",
"fieldDelimiter": ","
}
}
}
]
}
}执行json文件:
datax.py demo.json 结果展示:
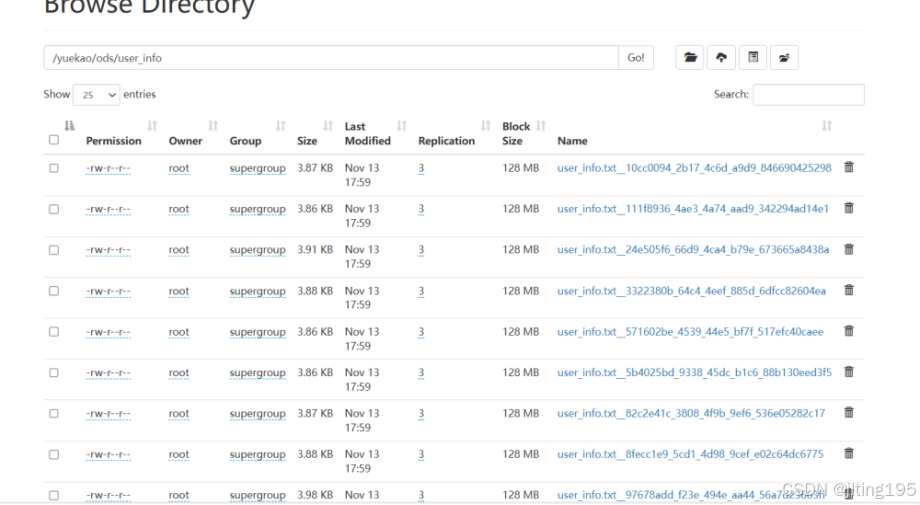
数据放不进来,有需要的小伙伴可以私我!!!