2、安装
解压,重命名,修改配置文件:
tar -zxvf apache-flume-1.9.0-bin.tar.gz -C /opt/installs/
mv apache-flume-1.9.0-bin/ flume
在企业中安装软件起始有两个地方比较常见:
/usr/local/
也可以安装在 /opt/installsexport FLUME_HOME=/opt/installs/flume
export PATH=$PATH:$FLUME_HOME/bin
source /etc/profile
修改一下flume的配置文件:
cp flume-env.sh.template flume-env.sh

修改 JAVA_HOME 的路径为自己的 jdk 路径。
export JAVA_HOME=/opt/installs/jdk3、flume的数据模型
- 单一数据模型 只有一个Agent
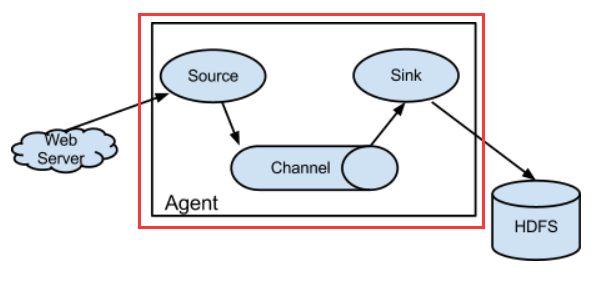
- 多数据流模型
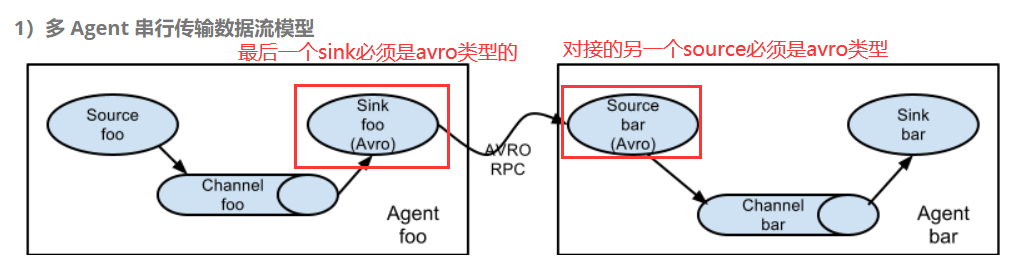
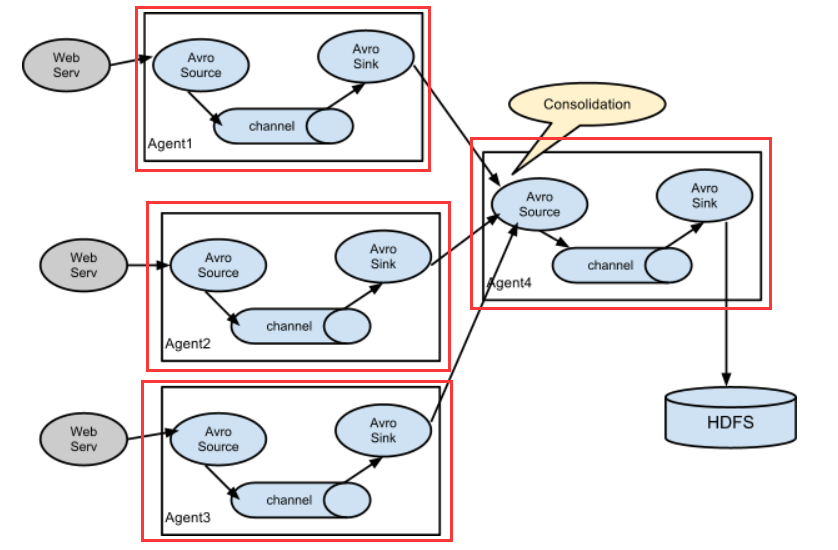
1)多AGENT串行传输数据流模型
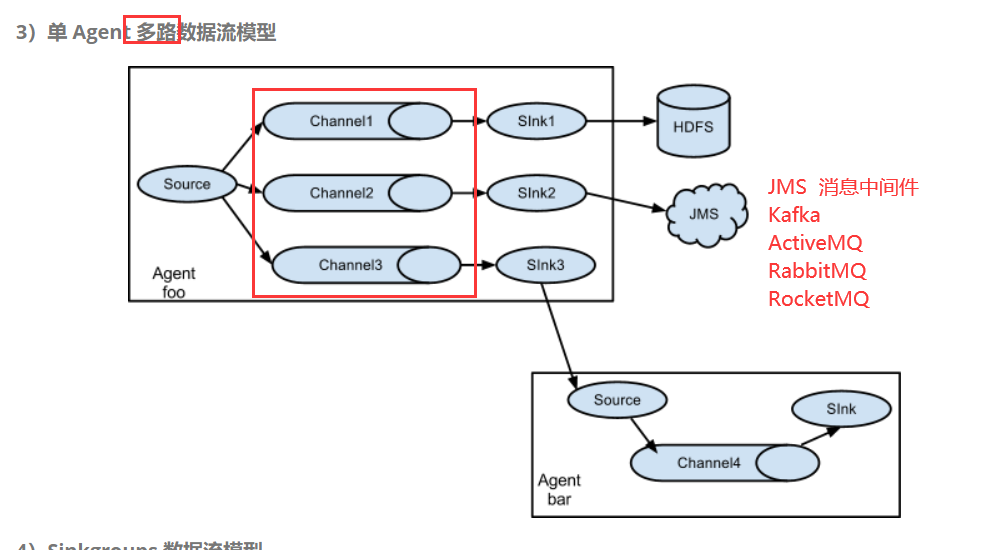
3)单AGENT 多路数据流模型
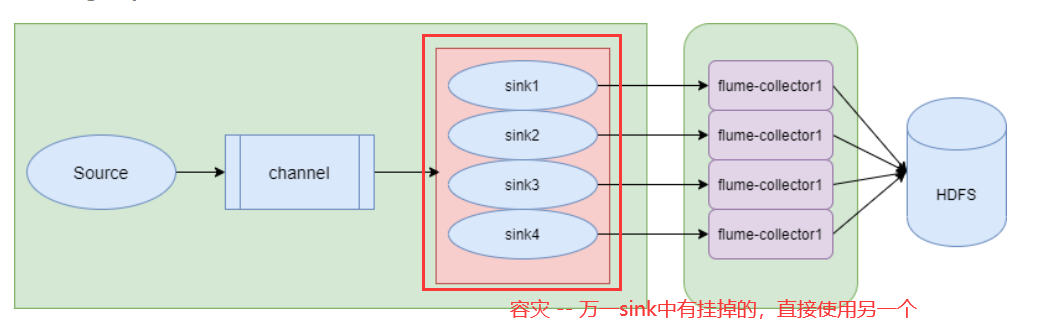
flume抽取数据的速度快吗?最大的速度有多快?最大速度也不能超过磁盘的读写速度,磁盘一秒钟最多写多少? 100M/S
4、关于flume的使用
flume 的使用是编写 conf文件的,运行的时候指定该文件
常见的source和channel 以及sink有哪些?
常见的Source :

常见的channel:
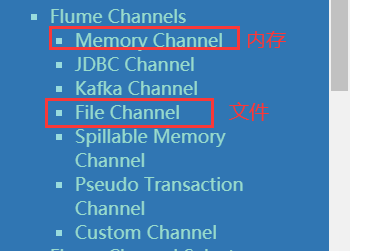
常见的sink:
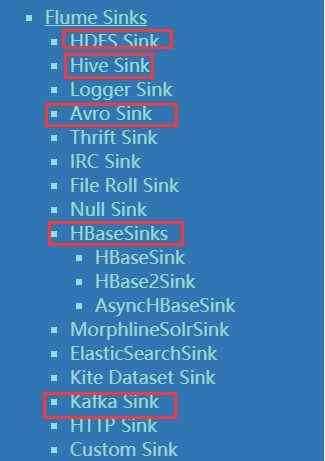
总结:Kafka 可以充当flume中的各个组件。三个组件可以两两组合在一起,所以使用场景非常的多。
5、案例展示
1)Avro+Memory+Logger【主要用于演示,没有实战意义】
avro: 是监听某个端口是否有信息的工具
memory: 内存
logger: 控制台
即将演示一个场景:给服务器上的一个端口发送消息,消息经过内存,打印到控制台上。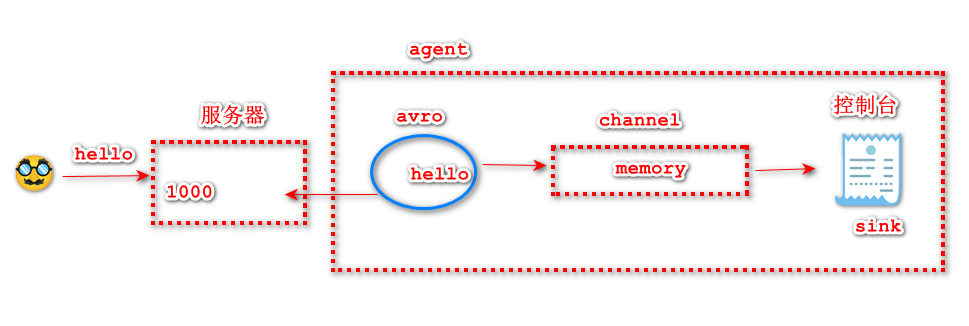
先找source 中的avro看需要设置什么参数

#编写s1的类型是什么
a1.sources.s1.type = avro
a1.sources.s1.bind = 192.168.32.128
a1.sources.s1.port = 4141
a1.sources.s1.channels = c1找到channel中的memory类型,再设置一下
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
#source 或者 sink 每个事务中存取 Event 的操作数量
a1.channels.c1.transactionCapacity = 10000接着查找sink,sink的类型是logger
a1.sinks.s2.channel = c1
a1.sinks.s2.type = logger最终合并起来的文件就是:
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = avro
a1.sources.r1.channels = c1
a1.sources.r1.bind = bigdata01
a1.sources.r1.port = 4141
a1.channels.c1.type = memory
a1.sinks = k1
a1.sinks.k1.type = logger
a1.sinks.k1.channel = c1在flume文件夹下创建一个文件夹 myconf,用于存放我们写好的文件
进入后创建 avro-memory-log.conf
将配置文件的内容拷贝进去先启动flume-ng
flume-ng agent -c ../ -f avro-memory-log.conf -n a1 -Dflume.root.logger=INFO,console
-c 后面跟上 配置文件的路径
-f 跟上自己编写的conf文件
-n agent的名字
-Dflume.root.logger=INFO,console INFO 日志输出级别 Debug,INFO,warn,error 等
接着向端口中发送数据:
flume-ng avro-client -c /opt/installs/flume/conf/ -H bigdata01 -p 4141 -F /home/hivedata/arr1.txt
给avro发消息,使用avro-clientflume是没有运行结束时间的,它一直监听某个Ip的端口,有消息就处理,没消息,就等着,反正不可能运行结束。
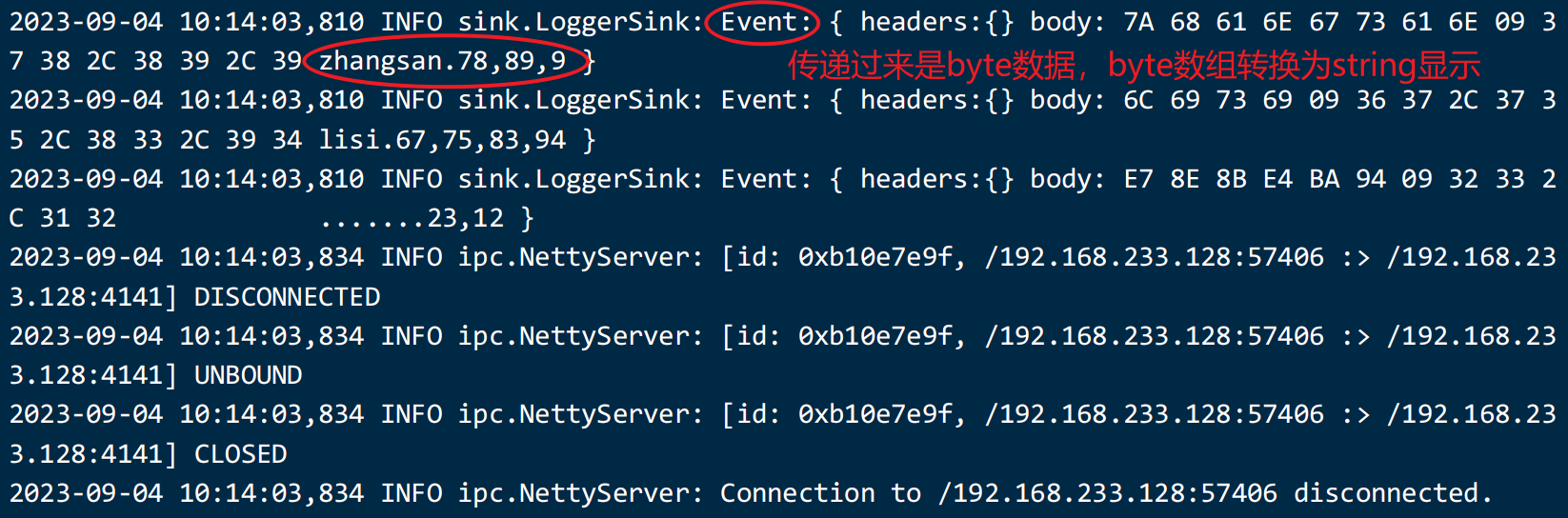
如果想停止,可以使用ctrl + c 终止flume。
2) Exec + Memory + HDFS
案例我写死了,告诉你了,到企业中怎么知道用什么呢?
取决于公司的业务,理论将 sources channel sink 可以任意组合
经过一个执行的命令,将数据通过内存,上传至hdfs
以下版本演示的是没有时间语义的案例:
接着我们演示hdfs文件中含有时间转义字符怎么办?
tail -f tomcat.log 查看这个文件,而且是不断的查看
linux中查看文件 cat more less tail
tail -f 文件名 不断查看一个文件的内容,长用于查看日志文件以下版本演示的是没有时间语义的案例:
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/hivedata/arr1.txt
a1.sources.r1.channels = c1
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 10000
a1.channels.c1.byteCapacityBufferPercentage = 20
a1.channels.c1.byteCapacity = 800000
a1.sinks = k1
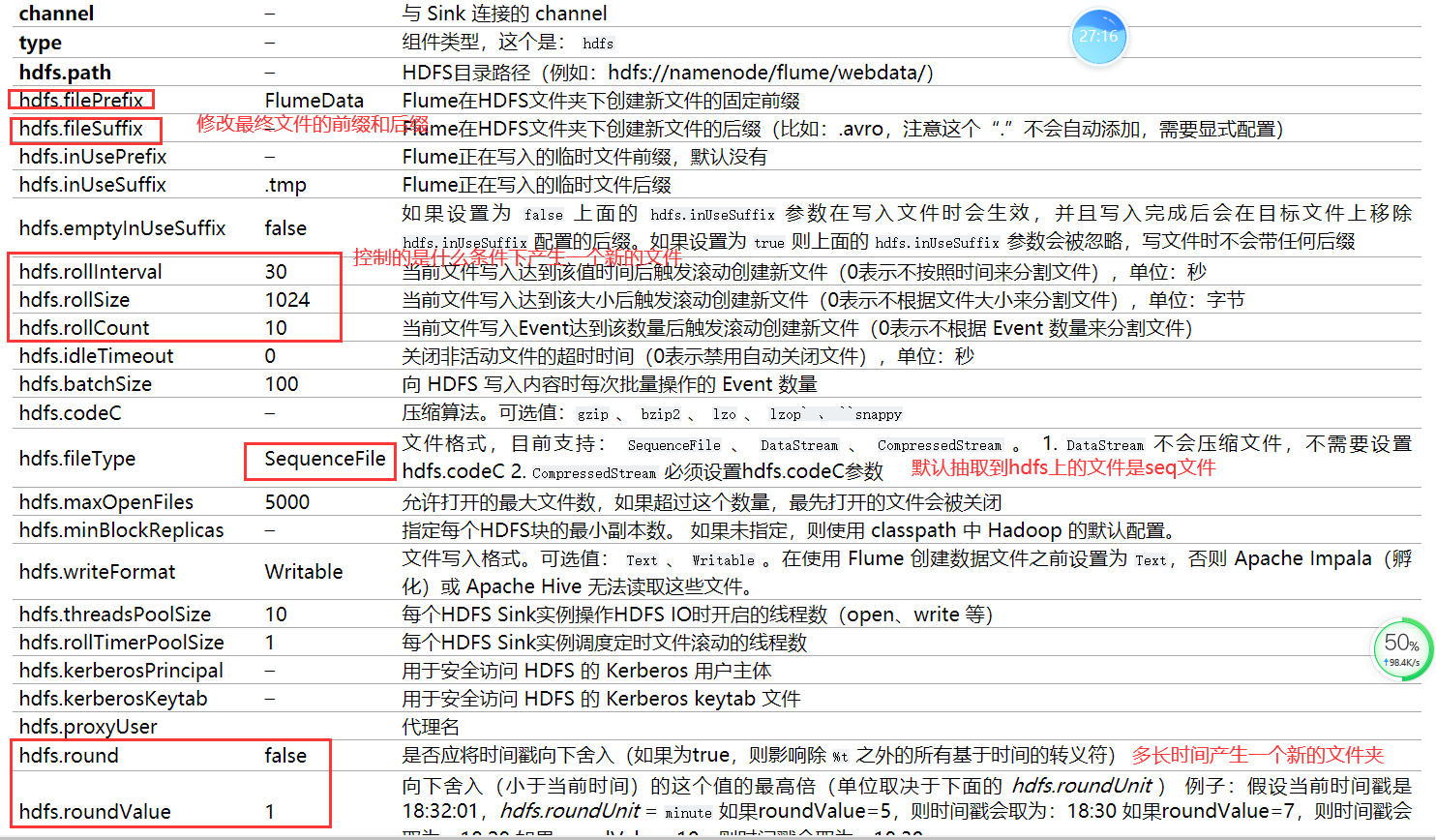
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
a1.sinks.k1.hdfs.path = /flume/event/接着我们演示hdfs文件中含有时间转义字符怎么办?
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /opt/data/c.txt
a1.sources.r1.channels = c1
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 10000
a1.sinks = k1
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
a1.sinks.k1.hdfs.path = /flume/events/%y-%m-%d/%H%M/
# round 用于控制含有时间转义符的文件夹的生成规则
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
# 使用本地时间,否则会报时间戳是null的异常
a1.sinks.k1.hdfs.useLocalTimeStamp=true0000000000000000000000000
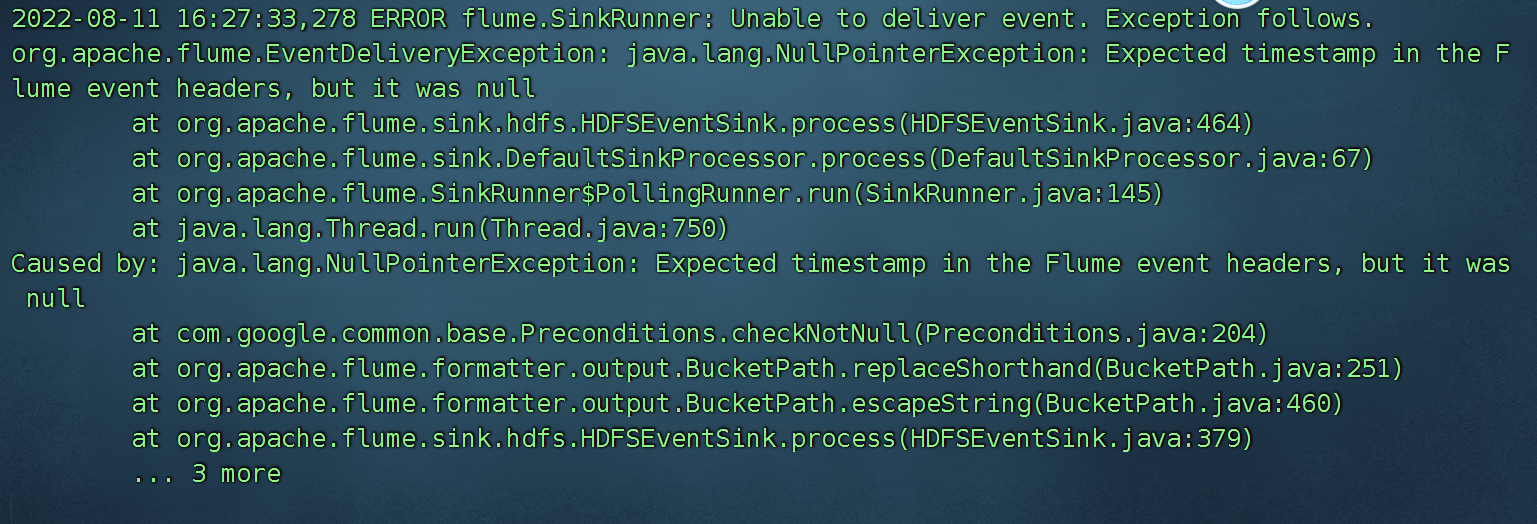
假如hdfs中使用了时间转义字符,配置文件中必须二选一:
1)useLocalTimeStamp=true
2)使用时间戳拦截器
为啥呀:
时间需要转义,没有时间无法翻译为具体的值 %d 就无法翻译为 日期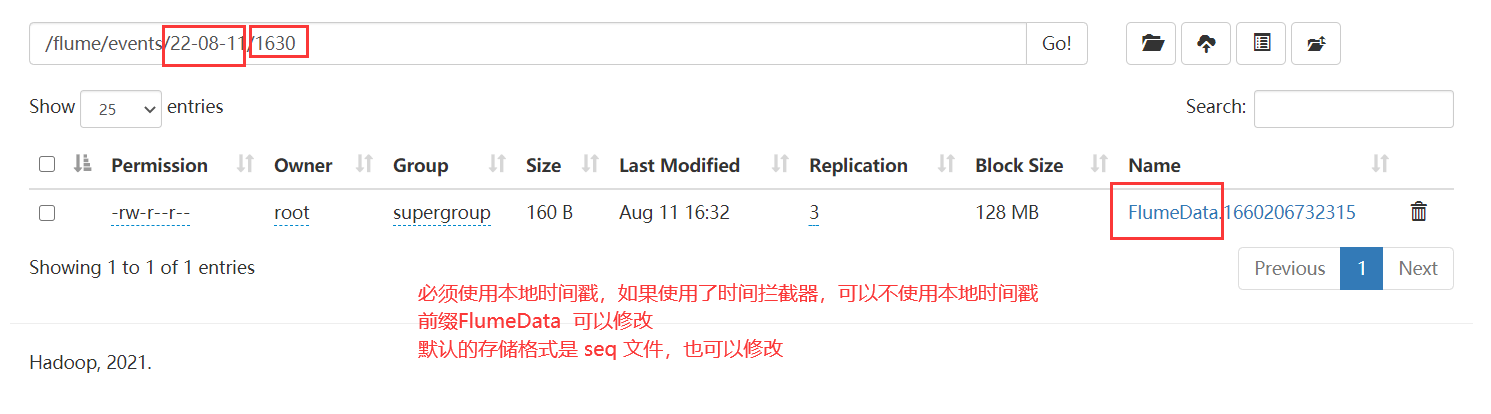
如何实现不断的向a.txt中存入数据的效果呢?
echo "Hello World" >> a.txt运行我们的脚本:
flume-ng agent -c ./ -f exec-memory-hdfs.conf -n a1 -Dflume.root.logger=INFO,console3)Spool +File + HDFS
Spooling Directory
spool 这个效果是抽取一个文件夹的效果,文件夹中不断的产生新的文件,我将这些新的文件上传至hdfs。
a1.channels = ch-1
a1.sources = src-1
a1.sources.src-1.type = spooldir
a1.sources.src-1.channels = ch-1
a1.sources.src-1.spoolDir = /home/scripts/
a1.sources.src-1.fileHeader = true
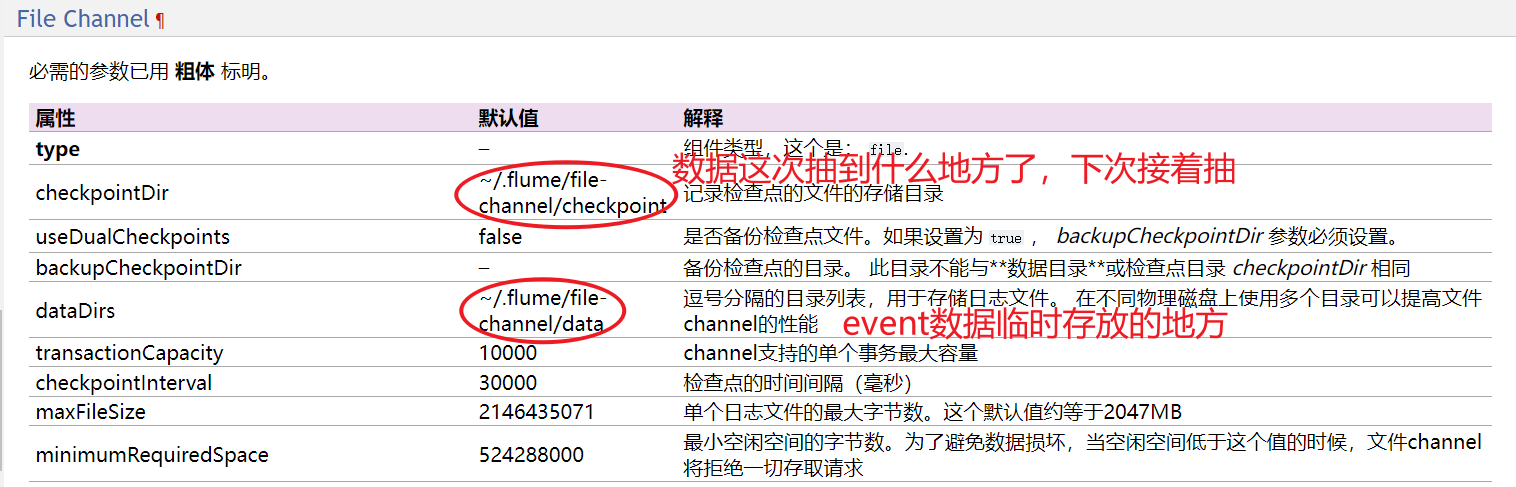
a1.channels.ch-1.type = file
a1.sinks = k1
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = ch-1
a1.sinks.k1.hdfs.path = /flume/
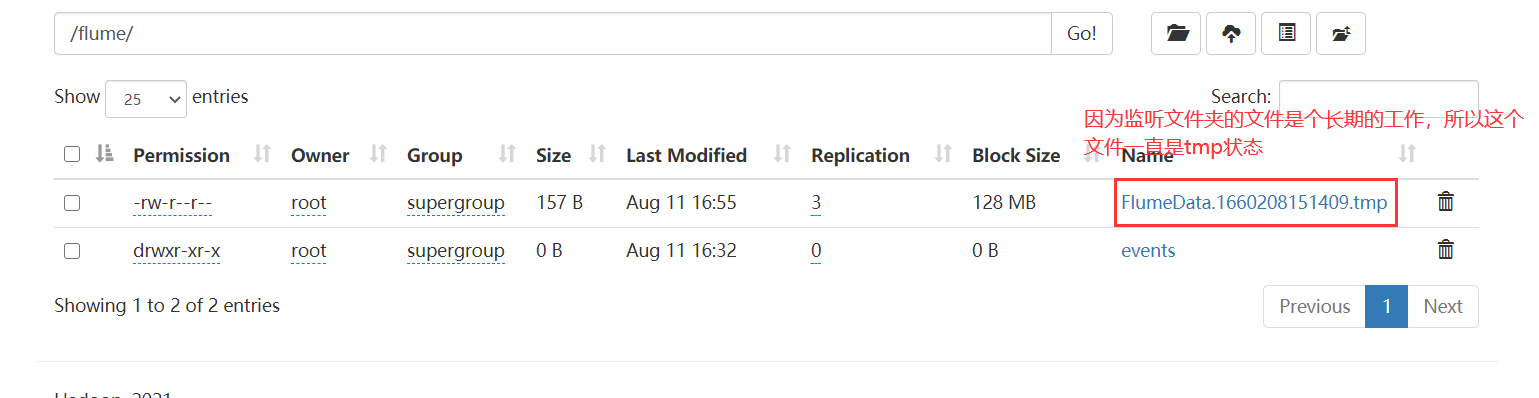
数据采集的意思:不管是一个文件还是一个文件夹,数据都是不断产生的,特别是生产环境下更是如此。
以上的采集只能采集到文件夹中是否有新的文件产生,不能采集变化的文件。
抽取一个文件夹中的所有文件,子文件夹中的文件是不抽取的,抽取过的文件,数据发生了变化,也不会再抽取一次。
假如你的channel是 file类型,必定会有临时文件产生,产生的文件在哪里?
总结:
channel 一般常用的只要两个,一个是memory,一个是file ,最高效的是memory ,也是最常用的。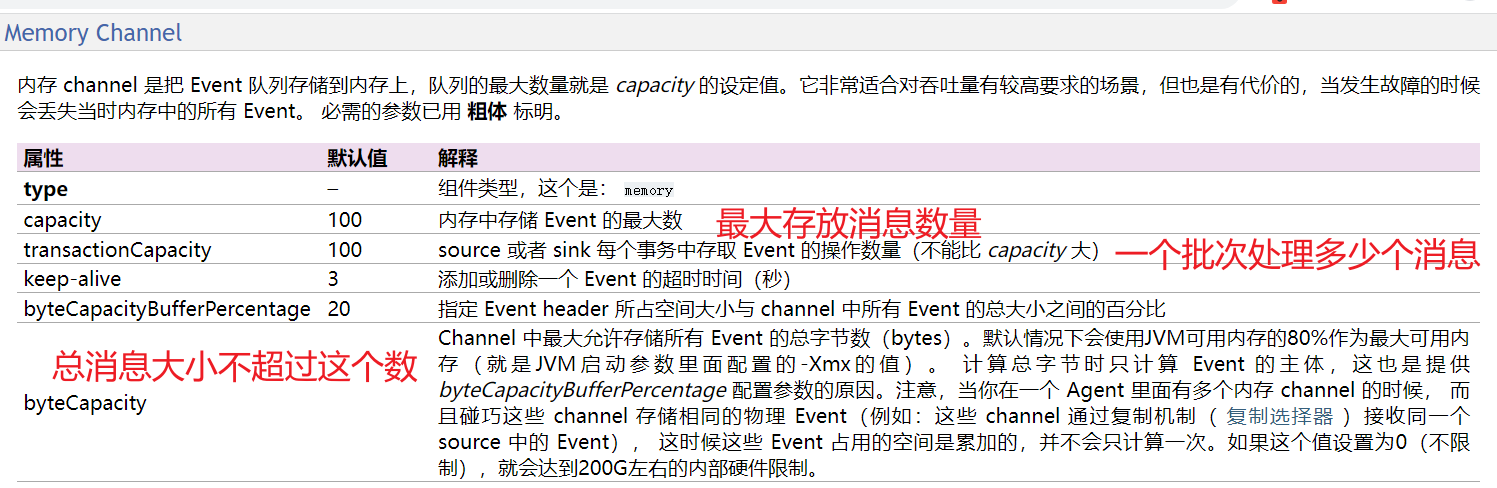
4) tailDir + Memory + HDFS [ 非常常用 ]
tailDir 是用来监控多个文件夹下的多个文件的,只要文件内容发生变化,就会再次的进行数据的抽取a1.sources = r1
a1.channels = c1
a1.sources.r1.type = TAILDIR
a1.sources.r1.channels = c1
a1.sources.r1.filegroups = f1
# . 代表的意思是一个任意字符 * 代表前面的字符出现0到多次
a1.sources.r1.filegroups.f1 = /home/scripts/datas/.*txt.*
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 10000
a1.sinks = k1
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
a1.sinks.k1.hdfs.path = /flume3/logstailDir 可以采集一个不断变化的文件。 a.log 不断的有数据产生,就可以不断的上传至hdfs了。
flume-ng agent -c ./ -f taildir_memory_hdfs.conf -n a1 -Dflume.root.logger=INFO,console数据不断的发生变化,每发生一次变化,就传递一次,源源不断的抽取出来。
刚才为什么抽取了那么多个文件还没有抽取完?
由于我们刚才的一些数据非常的大,根据如下参数可以疯狂创建文件:
hdfs.rollInterval 30 当前文件写入达到该值时间后触发滚动创建新文件(0表示不按照时间来分割文件),单位:秒
hdfs.rollSize 1024 当前文件写入达到该大小后触发滚动创建新文件(0表示不根据文件大小来分割文件),单位:字节
hdfs.rollCount 10 当前文件写入Event达到该数量后触发滚动创建新文件(0表示不根据 Event 数量来分割文件)
再次抽取,发现不抽了,原因是有一个文件记录了以前抽取过的内容,将其删除:
rm -rf /root/.flume/taildir_position.json
修改1.txt 里面的内容,flume会再次抽取数据
echo "hello" >> 1.txt