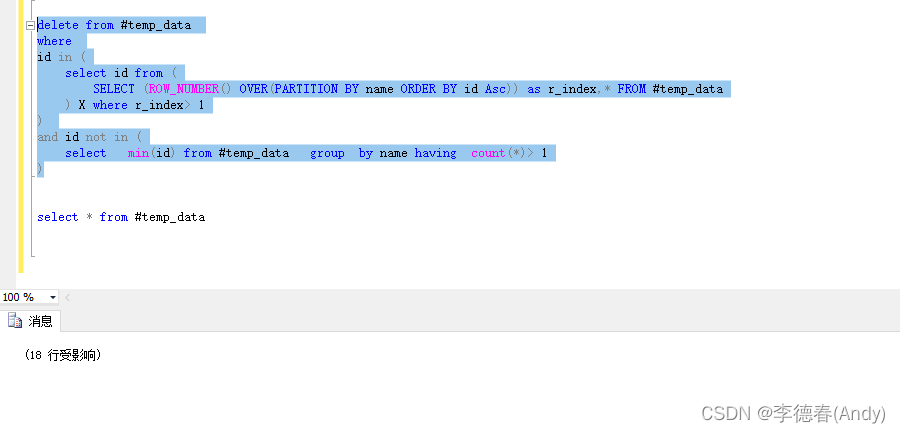
在几千条记录里,存在着些相同的记录,如何能用SQL语句,删除掉重复的呢?.
要求:删除表中多余的重复记录,且保留 id 最小的那一条记录。
CREATE TABLE #temp_data(
id BIGINT PRIMARY KEY IDENTITY,
name NVARCHAR(50),
category INT,--分类id
sort_id INT,--排序id
addtime DATETIME
)
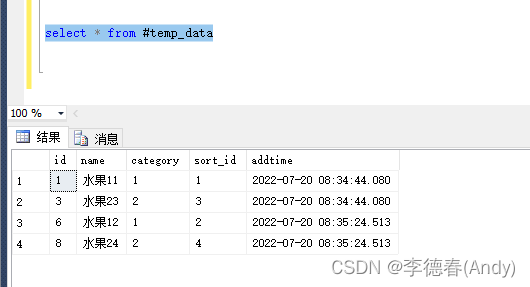
INSERT INTO #temp_data ( name,category,sort_id, addtime )VALUES ( '水果11', 1, 1,GETDATE());
INSERT INTO #temp_data ( name,category,sort_id, addtime )VALUES ( '水果12', 1, 2,GETDATE());
INSERT INTO #temp_data ( name,category,sort_id, addtime )VALUES ( '水果23', 2, 3,GETDATE());
INSERT INTO #temp_data ( name,category,sort_id, addtime )VALUES ( '水果24', 2, 4,GETDATE());
INSERT INTO #temp_data ( name,category,sort_id, addtime )VALUES ( '水果11', 1, 1,GETDATE());
INSERT INTO #temp_data ( name,category,sort_id, addtime )VALUES ( '水果12', 1, 2,GETDATE());
--SELECT * FROM #temp_data
--ROW_NUMBER() OVER
SELECT *,(ROW_NUMBER() OVER(ORDER BY name asc,id asc)) as r_index
FROM #temp_data d
--ORDER BY id --如果再写Order by子句,记录会按后面的Order by子句排序
--ROW_NUMBER() OVER PARTITION BY 记录按后面的order BY 子句排序输出,跟ROW_NUMBER方法产生的序号无关。
delete from #temp_data
where
id in (
select id from (
SELECT (ROW_NUMBER() OVER(PARTITION BY name ORDER BY id Asc)) as r_index,*
FROM #temp_data
) X where r_index> 1
)
and id not in (
select min(id) from #temp_data group by name having count(*)> 1
)
1、查找表中多余的重复记录,重复记录是根据单个字段(id)来判断的。
SELECT (ROW_NUMBER() OVER(PARTITION BY name ORDER BY id Asc)) as r_index,* FROM #temp_data
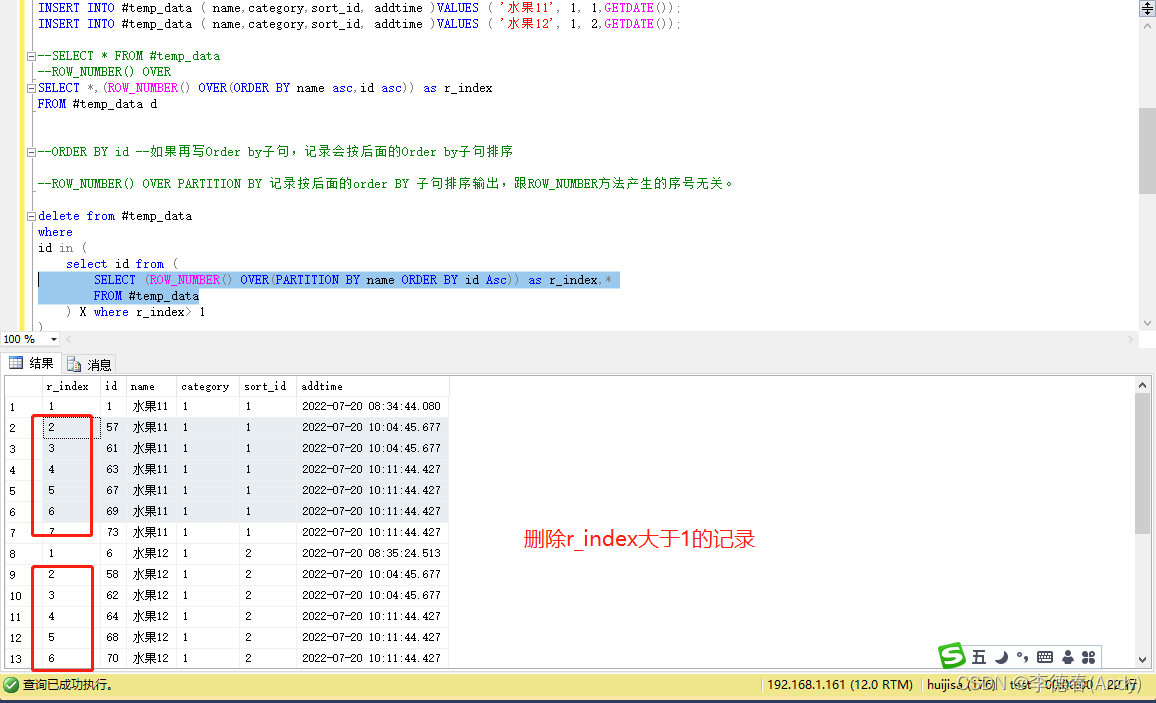
2. group by name 分组,查询count(*)>1的有重复项的min(id)。也就是最原始的,要保留。
select min(id) from #temp_data group by name having count(*)> 1
3. 删除重复记录,保留 id 最小的那一条记录 ( id not in (min(id))。