Tips:在两方场景下,设计的安全算法,如果存在信息不对等性,那么信息获得更多的一方可以有概率对另一方实施安全性攻击。
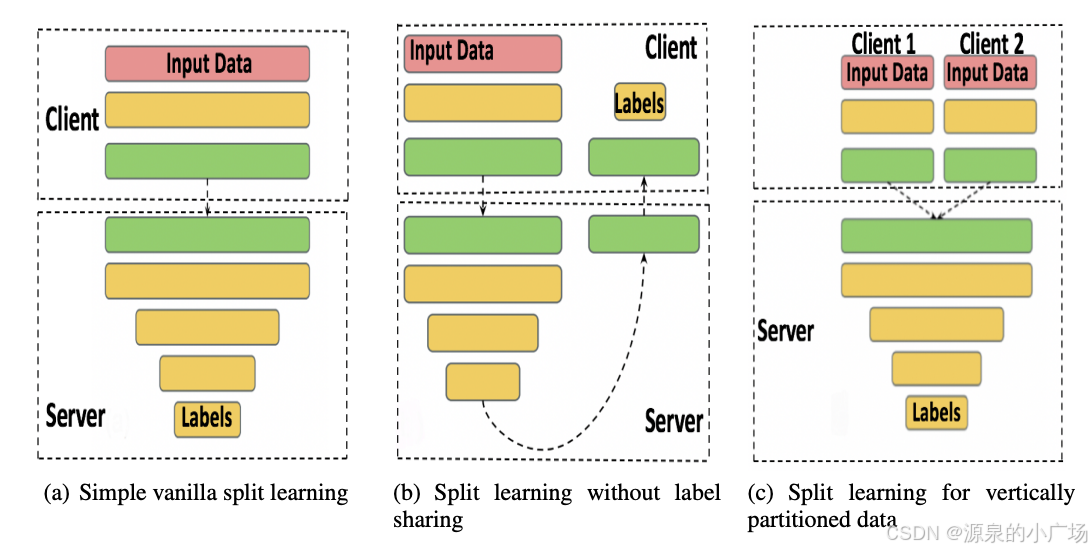
1. 拆分学习原理
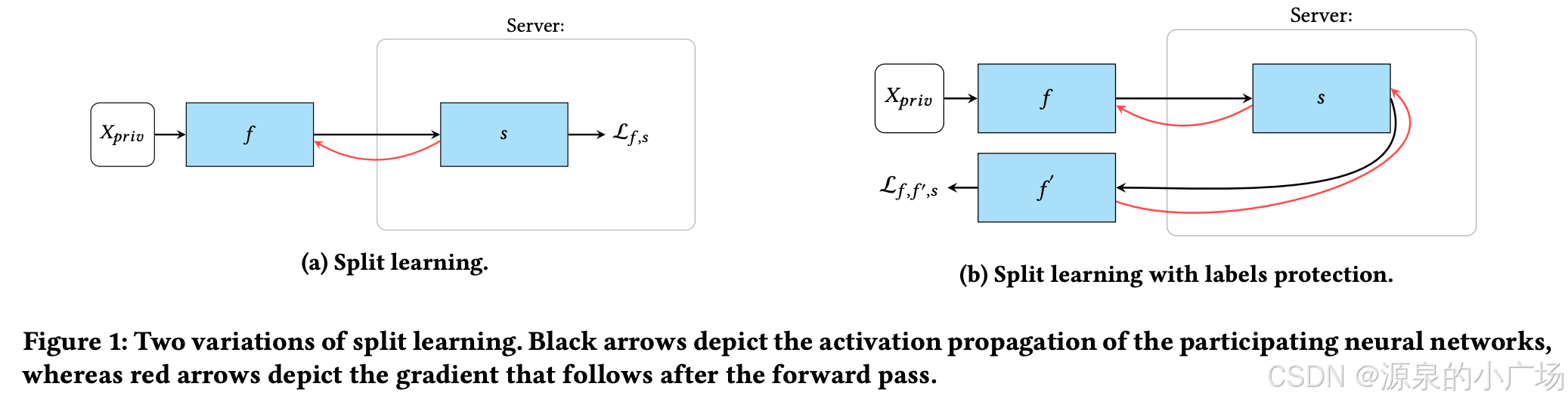
本文介绍了一种适用于隐私计算场景的深度学习实现方案——拆分学习,又称分割学习(Split Learning)【1, 2, 3】。该方法能够让服务器在无需访问客户端原始数据的前提下完成深度学习模型的训练或推理。通过拆分学习,合作的各方无需共享任何原始数据或模型详细信息,即可协同完成机器学习模型的训练或推断。
在拆分学习的基础配置中,每个客户端仅负责将深度网络的前几层训练至一个预定义的切割层。切割层的输出结果被传送到另一个实体(如服务器或其他客户端),由其完成剩余网络的训练,而无需访问任何客户端的原始数据。这样便完成了一次前向传播,而无需共享原始数据。随后,在反向传播阶段,梯度从网络的最后一层逐层传回至切割层,切割层的梯度(仅此部分梯度)再返回给客户端。客户端利用这些梯度完成剩余的反向传播操作。通过这样的循环过程,整个分布式分割学习网络得以完成训练,全程无需各方共享原始数据。
客户端只需传输切割层之前的初始层输出,显著降低了通信开销。同时,由于客户端仅需计算部分网络权重,其计算负担也大幅减少。在模型性能上,拆分学习的精度与联邦学习及大批量同步SGD等分布式深度学习方法相当,但在客户端数量较多的情况下,其计算代价可以更低。
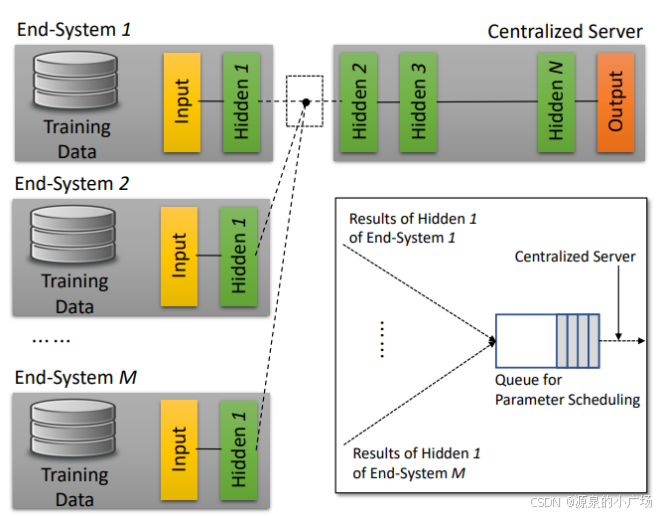
示例:一种基于centralized server模式的架构【4】:
2. 拆分学习 案例
以【5, 6】中例子说明执行方式。
以split DNN模型的拆分为例:
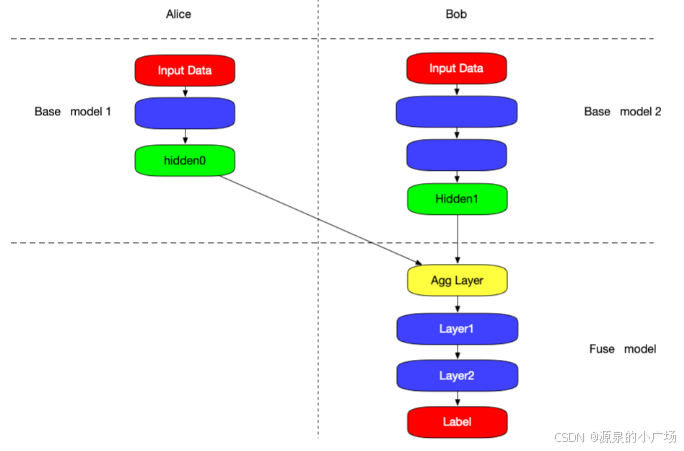
Alice :拥有 data_alice , model_base_alice
Bob :拥有 data_bob , model_base_bob , model_fuse
- Alice 用本方的数据通过 model_base_alice 得到 hidden0 ,发送给Bob
- Bob 用本方的数据通过 model_base_bob 得到 hidden1
- hidden_0 和 hidden_1 输入到 AggLayer 进行聚合,聚合后的 `hidden_merge`为输出
- Bob 方输入 hidden_merge 到 model_fuse,结合`label` 得到梯度,并进行回传
- 通过 AggLayer 将梯度拆分为 g0 , g1 两部分,将 g0 和 g1 分别发送给 Alice 和 Bob
- Alice 和 Bob 的 basenet 分别根据 g0 和 g1 对本方的基础模型进行更新
以split GNN为例:

参与者在服务器(可信第三方)的协助下协作训练一个全局模型。服务器存储模型的一部分,但由于原始数据和其真实标签具有高度的隐私敏感性,参与者不愿直接共享这些数据和标签。在实际操作中,标签服务器与某一参与者相同,这名参与者希望通过其他参与者的数据增强分类模型的能力。
在神经网络模型中,每个原始样本被输入到输入层,而真实标签则与模型预测结果在输出层进行比较以计算损失。因此,为了保护每对样本与标签的隐私,输入层和输出层都应由每个参与者分别存储,而其余的网络层可以卸载到服务器上,从而形成三方分离的SplitGNN架构。三方分离SplitGNN中,每一层的前向计算可以分为三个步骤:首先,参与者使用私有数据单独计算本地嵌入;然后,服务器(可信第三方)收集非隐私的本地嵌入以计算全局嵌入;最后,服务器返回最终的计算结果。
3. 拆分学习的安全性问题及应对方案
从拆分学习的框架来看,存在两种主要的模式,第一种是一方的中间数据(cut layer输出)需要传给另一方(标签方)做后续计算。第二种是客户端的中间数据加密后发送给可信第三方进行后续计算。
3.1 风险案例1
【6】提出了一种针对拆分学习的全面攻击方法EXACT。假设客户端拥有仅限于自身的私有特征,这些特征不希望与任何第三方共享。同时,假设标注数据(ground-truth labels)也是私密的,仅为客户端所知,在该假设下研究标签泄露的情况。服务器试图基于切割层的梯度恢复客户端的私有数据和真实标注。考虑一个有 C 个分类类别的问题,其特征空间分为服务器端特征空间 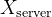
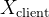
![Y = [C] = \{1, ..., C\}](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT9ZJTIwJTNEJTIwJTVCQyU1RCUyMCUzRCUyMCU1QyU3QjElMkMlMjAuLi4lMkMlMjBDJTVDJTdE)
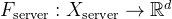
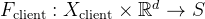
![S = \{z \mid \sum_{i=1}^C z_i = 1, z_i \geq 0, \forall i \in [C]\}](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT9TJTIwJTNEJTIwJTVDJTdCeiUyMCU1Q21pZCUyMCU1Q3N1bV8lN0JpJTNEMSU3RCU1RUMlMjB6X2klMjAlM0QlMjAxJTJDJTIwel9pJTIwJTVDZ2VxJTIwMCUyQyUyMCU1Q2ZvcmFsbCUyMGklMjAlNUNpbiUyMCU1QkMlNUQlNUMlN0Q%3D)
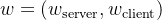
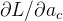
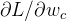
假设攻击者能够在训练期间访问客户端模型参数。虽然某些情况下可以通过安全聚合方案减少攻击者的访问权限,但假设默认攻击者掌握服务器端特征、服务器端模型及客户端模型的知识。这一假设符合分布式学习的实际情况。
EXACT 是一种基于梯度匹配的攻击方法,通过对切割层梯度
- 生成可能的特征组合列表:客户端的私有特征被认为是离散的,或可以离散化为有限类别。列出所有可能的特征组合
,其中
是私有特征,L 是标注类别。
- 梯度匹配:对于每一种可能的特征配置 L[i],计算服务器激活值
。然后,与客户端提供的真实梯度
距离),找出最接近的配置。
- 重构特征与标注:选择距离最小的特征组合作为重构结果。
EXACT 方法通过遍历所有可能的组合,确保能够重构最相关的私有特征,且不依赖传统优化步骤(如二阶导数计算或正则化调优)。虽然这种方法的搜索空间会随着私有特征数量或类别的增加而指数增长,但可以采用启发式或智能搜索方法加速收敛。
在实验中,【7】算法在平均 16.8 秒内成功重构了给定样本的特征。

3.2 风险案例2
拆分学习的主要漏洞在于服务器对客户端网络学习过程的控制权。 即使攻击者不了解 f 的架构及其权重,也可以伪造适当的梯度并强制 f 收敛到攻击者选择的任意目标函数。通过这种方式,攻击者可以在客户端生成的数据中引入某些属性,从而针对底层的隐私数据实施推理或重建攻击。
【8】提出了一个通用框架来实现这一攻击过程。在该框架中,恶意服务器将客户端选择的原始学习任务替换为一个新目标,刻意塑造 f 的余域/特征空间。在攻击中,服务器利用其对训练过程的控制,劫持 f,将其引导到一个特定的、精心设计的目标特征空间 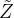
这种攻击包括两个阶段,图来自【9】:

- 设置阶段(Setup phase):服务器劫持 f 的学习过程;
- 推理阶段(Inference phase):服务器自由恢复从客户端发送的 smashed 数据。
将这一过程称为特征空间劫持攻击(Feature-space Hijacking Attack,简称 FSHA)。

设置阶段
设置阶段在拆分学习的多个训练迭代中进行,逻辑上分为两个并行步骤,如图 2a 和图 2b 所示。在这一阶段,服务器训练三个不同的网络: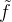

。
- D:一种判别器,间接引导 f 学习将私有数据映射到由
设置阶段还需要一个未标记数据集 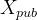
在每次分裂学习训练迭代中(即客户端向服务器发送 smashed 数据时),恶意服务器通过两个并行步骤训练上述三个网络(a 和b):
服务器从
。通过以下损失函数实现:
其中 d 是合适的距离函数,例如均方误差(MSE)。
同时训练判别器 D。它的作用是区分
和
(即 smashed 数据)之间的特征空间。D 的输入为
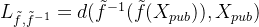
完成 D 的局部训练后,恶意服务器使用 D 生成一个适合的梯度信号发送到远程客户端,以训练 f。此梯度通过以下对抗性损失函数生成:
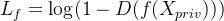
f 被训练以最大化判别器 D 的错误分类概率。客户端的网络需要学习将数据映射到一个与
攻击推理阶段
经过足够多的设置迭代后,f 达到一个状态,攻击者可以从 smashed 数据中恢复私有训练实例。此时,由于对抗训练,f 的余域与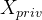
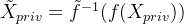
其中 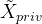
4. 风险应对措施案例
正如上述原理分析,拆分学习是一种协作学习技术,允许参与者(例如客户端和服务器)在不共享原始数据的情况下训练机器学习模型。在这种设置中,客户端最初对原始数据应用其部分机器学习模型生成激活图,然后将其发送给服务器以继续训练过程。从我们列举的风险案例来看,重建激活图可能会导致客户端数据的隐私泄露。
【10】通过构建一个基于U形拆分学习的协议,可以在同态加密数据上运行。更具体地说,在该方法中,客户端在将激活图发送给服务器之前对其进行同态加密,从而保护用户隐私。相比于其他基于SL的工作,减少了隐私泄露。在最优参数设置下,使用同态加密数据训练的U形拆分学习仅比在明文数据上训练的准确性降低2.65%。原始训练数据的隐私得到了保护。
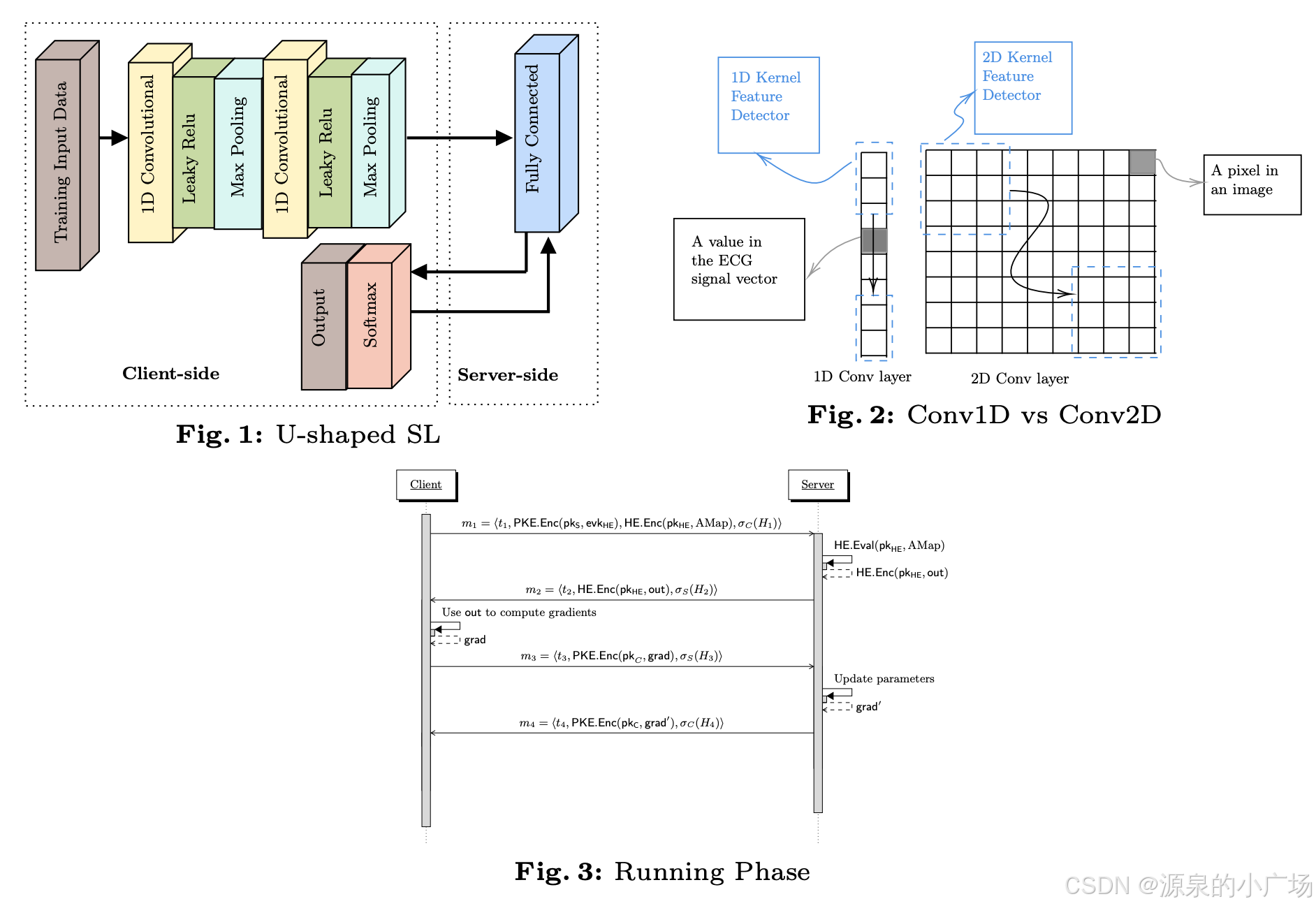
根据这个思路,还可以进一步将MPC、TEE等多种隐私计算引入来提升拆分学习的安全性。比如【11】提出将mpc引入到拆分学习加强安全性,建议融合MPC和拆分学习技术,敏感数据相关计算采用MPC技术来执行;而其余的大量的复杂非线性计算由服务器来执行,并运用对抗学习、差分隐私、贝叶斯学习、随机置换等技术加固算法的安全性,以取得安全性、效率、精确性的平衡。

5. 基于拆分学习的大模型训练机制
因为拆分学习的高效性能,目前在大模型的训练中,已经出现了一些方案。
比如【12】提出一种split-llm模型框架。
在拆分学习中,大模型被分为三部分:
- 底层(Bottom Layers)
- 主干层(Trunk Layers,也称为适配器层)
- 顶层(Top Layers)
其中,底层和顶层分别是模型的输入端和输出端,而主干层则是模型的中间部分。

- 在每轮联邦学习开始时,选择客户端0、1和2。
- 从磁盘加载客户端0的模型参数(包括底层和顶层以及其对应的服务器端的主干部分)到GPU模型中。
- 客户端0进行本地训练,更新所有模型参数,遵循与集中式学习一致的流程。
- 客户端0完成训练后,将模型参数保存到磁盘。
- 从磁盘加载客户端1的模型参数到GPU模型中。
- ...
- 在联邦学习轮次结束时,将所有客户端对应的主干参数在磁盘上进行聚合,得到平均主干。然后,将所有客户端的主干参数更新为平均主干。
- 重复步骤1-7。
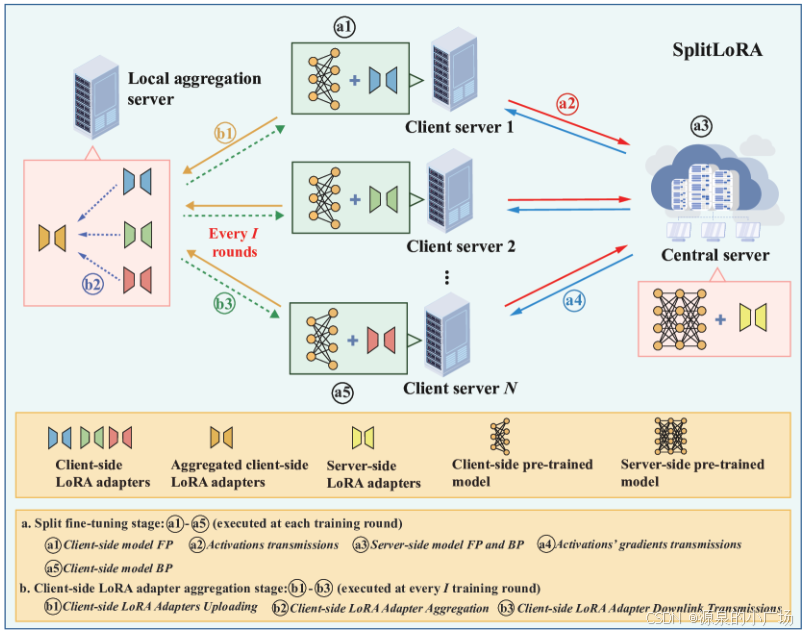
【13】提出大模型微调对资源有限的计算实体造成了计算负担。采用拆分学习在解决这一问题上具有潜力。后续可以继续关注一下。
6. 参考材料
【1】SplitNN-driven Vertical Partitioning
【2】SplitFed: When Federated Learning Meets Split Learning
【3】Split learning for health: Distributed deep learning without sharing raw patient data
【4】A Study of Split Learning Model
【5】拆分学习:银行营销
【6】SplitGNN: Splitting GNN for Node Classification with Heterogeneous Attention
【7】Evaluating Privacy Leakage in Split Learning
【8】Unleashing the Tiger: Inference Attacks on Split Learning
【9】Combined Federated and Split Learning in Edge Computing for Ubiquitous Intelligencein Internet of Things: State-of-the-Art and Future Directions
【10】A More Secure Split: Enhancing the Security of Privacy-Preserving Split Learning
【12】SplitLLM:Split Learning Simulation Framework for LLMs
【13】SplitLoRA: A Split Parameter-Efficient Fine-Tuning Framework for Large Language Models