K-MEANS概念及复现
1.相关概念
聚类概念:
- 无监督问题:我们手里没有标签了
- 聚类:相似的东西分到一组
- 难点:如何评估,如何调参
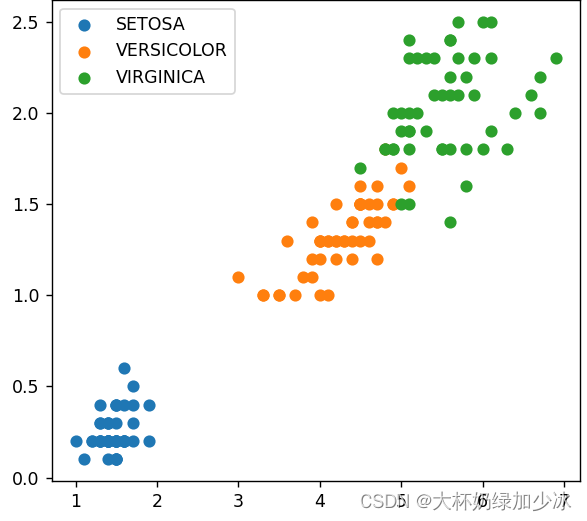
如下图,可看出有三个类别分别对应三个不同的颜色,通俗的来说:此算法就是类似于一个投票,少数服从多数,大概就是假如一个男生在一群女生里面,那么他也会被分类成一个女生
基本概念:
- 要得到簇的个数,需要指定K值(即K的取值对分类的结果存在影响)
- 质心:均值,即向量各维度取平均值即可
- 距离的度量:常用欧几里得距离和余弦相似度(注意需要标准化)
- 优化目标
2.K-MEANS算法的优缺点
优势:
- 简单,快速,适合常规数据集,因此,此算法比较适合处理那种已经分类好的数据集。
劣势:
- K值难确定
- 复杂度与样本呈线性关系
- 很难发现任意形状的族
可视化展示,大家可以自己去搜索这个网站,去了解,非常简单清晰
https://www.naftaliharris.com/blog/visualizing-k-means-clustering/
3.代码实现
- k_means.py
import numpy as np
class KMeans:
def __init__(self, data, num_clustres):
self.data = data # 初始化数据
self.num_clustres = num_clustres # 初始化簇的数量
def train(self, max_iterations):
# 1.先随机选择K个中心点
centroids = KMeans.centroids_init(self.data, self.num_clustres) # 调用静态方法初始化中心点
# 2.开始训练
num_examples = self.data.shape[0] # 获取样本数量
closest_centroids_ids = np.empty((num_examples, 1)) # 初始化最近中心点的索引数组
for _ in range(max_iterations): # 迭代更新中心点
# 3得到当前每一个样本点到K个中心点的距离,找到最近的
closest_centroids_ids = KMeans.centroids_find_closest(self.data, centroids) # 调用静态方法计算最近中心点的索引
# 4.进行中心点位置更新
centroids = KMeans.centroids_compute(self.data, closest_centroids_ids, self.num_clustres) # 调用静态方法计算新的中心点
return centroids, closest_centroids_ids # 返回最终的中心点和最近中心点的索引
@staticmethod
def centroids_init(data, num_clustres):
num_examples = data.shape[0] # 获取样本数量
random_ids = np.random.permutation(num_examples) # 随机打乱样本顺序
centroids = data[random_ids[:num_clustres], :] # 选取前K个样本作为初始中心点
return centroids # 返回初始中心点
@staticmethod
def centroids_find_closest(data, centroids):
num_examples = data.shape[0] # 获取样本数量
num_centroids = centroids.shape[0] # 获取中心点数量
closest_centroids_ids = np.zeros((num_examples, 1)) # 初始化最近中心点的索引数组
for example_index in range(num_examples): # 遍历每个样本
distance = np.zeros((num_centroids, 1)) # 初始化距离数组
for centroid_index in range(num_centroids): # 遍历每个中心点
distance_diff = data[example_index, :] - centroids[centroid_index, :] # 计算样本与中心点之间的距离差
distance[centroid_index] = np.sum(distance_diff ** 2) # 计算距离平方和
closest_centroids_ids[example_index] = np.argmin(distance) # 找到距离最小的中心点的索引
return closest_centroids_ids # 返回最近中心点的索引
@staticmethod
def centroids_compute(data, closest_centroids_ids, num_clustres):
num_features = data.shape[1] # 获取特征数量
centroids = np.zeros((num_clustres, num_features)) # 初始化中心点数组
for centroid_id in range(num_clustres): # 遍历每个中心点
closest_ids = closest_centroids_ids == centroid_id # 找到属于当前中心点的样本
centroids[centroid_id] = np.mean(data[closest_ids.flatten(), :], axis=0) # 计算当前中心点的坐标
return centroids # 返回中心点坐标
- demo.py
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
from k_means import KMeans
matplotlib.use('TkAgg')
data = pd.read_csv('./data/iris.csv')
iris_types = ['SETOSA', 'VERSICOLOR', 'VIRGINICA']
x_axis = 'petal_length'
y_axis = 'petal_width'
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
for iris_type in iris_types:
plt.scatter(data[x_axis][data['class'] == iris_type], data[y_axis][data['class'] == iris_type], label=iris_type)
plt.title('label known')
plt.legend()
plt.subplot(1, 2, 2)
plt.scatter(data[x_axis][:], data[y_axis][:])
plt.title('label unknown')
plt.show()
num_examples = data.shape[0]
x_train = data[[x_axis, y_axis]].values.reshape(num_examples, 2)
# 指定好训练所需的参数
num_clusters = 3
max_iteritions = 50
k_means = KMeans(x_train, num_clusters)
centroids, closest_centroids_ids = k_means.train(max_iteritions)
# 对比结果
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
for iris_type in iris_types:
plt.scatter(data[x_axis][data['class'] == iris_type], data[y_axis][data['class'] == iris_type], label=iris_type)
plt.title('label known')
plt.legend()
plt.subplot(1, 2, 2)
for centroid_id, centroid in enumerate(centroids):
current_examples_index = (closest_centroids_ids == centroid_id).flatten()
plt.scatter(data[x_axis][current_examples_index], data[y_axis][current_examples_index], label=centroid_id)
for centroid_id, centroid in enumerate(centroids):
plt.scatter(centroid[0], centroid[1], c='black', marker='x')
plt.legend()
plt.title('label kmeans')
plt.show()
在demo.py软件运行时候,出现以下报错:
AttributeError: module 'backend_interagg' has no attribute 'FigureCanvas'. Did you mean: 'FigureCanvasAgg'
通过搜索,发现是matplotlib的backend的默认渲染器是agg,agg是一个没有图形显示界面的终端,如果要图像正常显示,则需要切换为图形界面显示的终端TkAgg
import matplotlib
matplotlib.use('TkAgg')
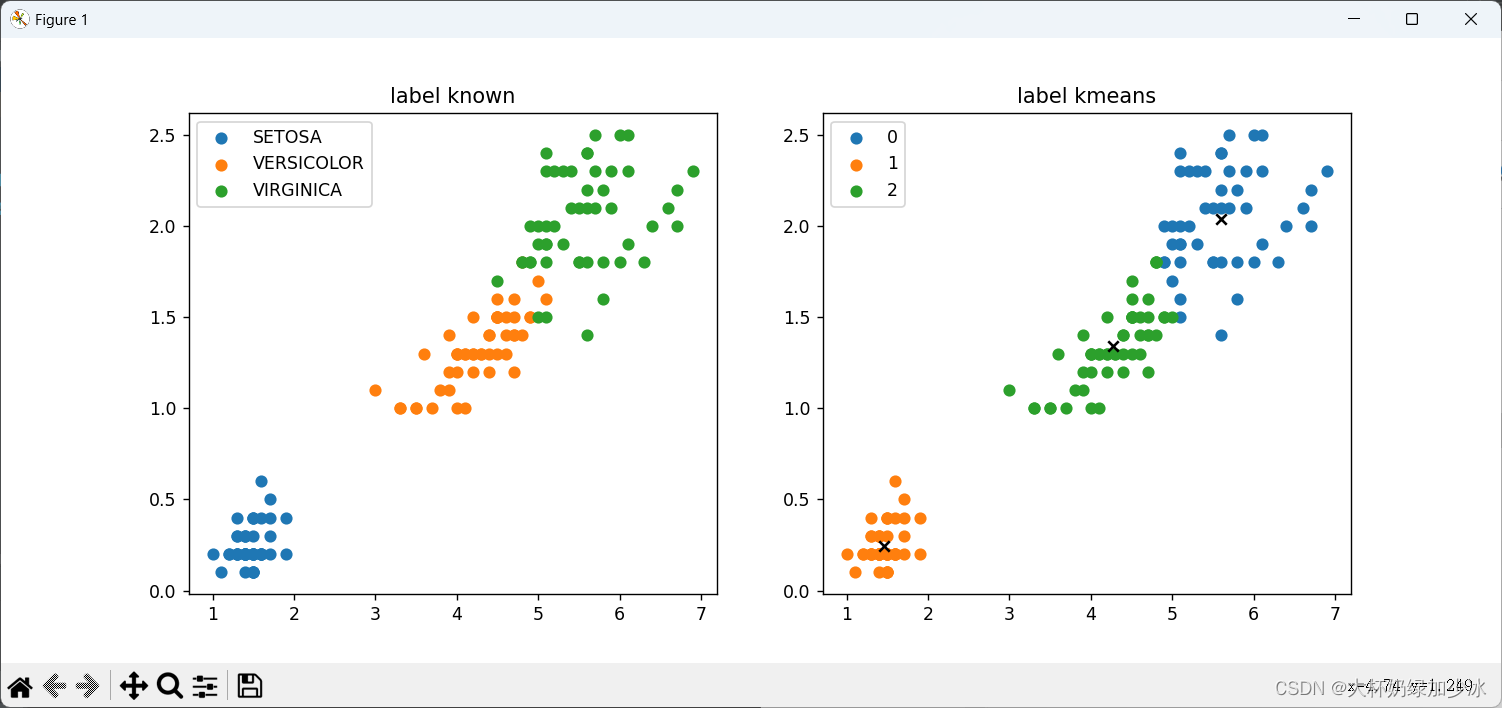
结果展示:
结果一:
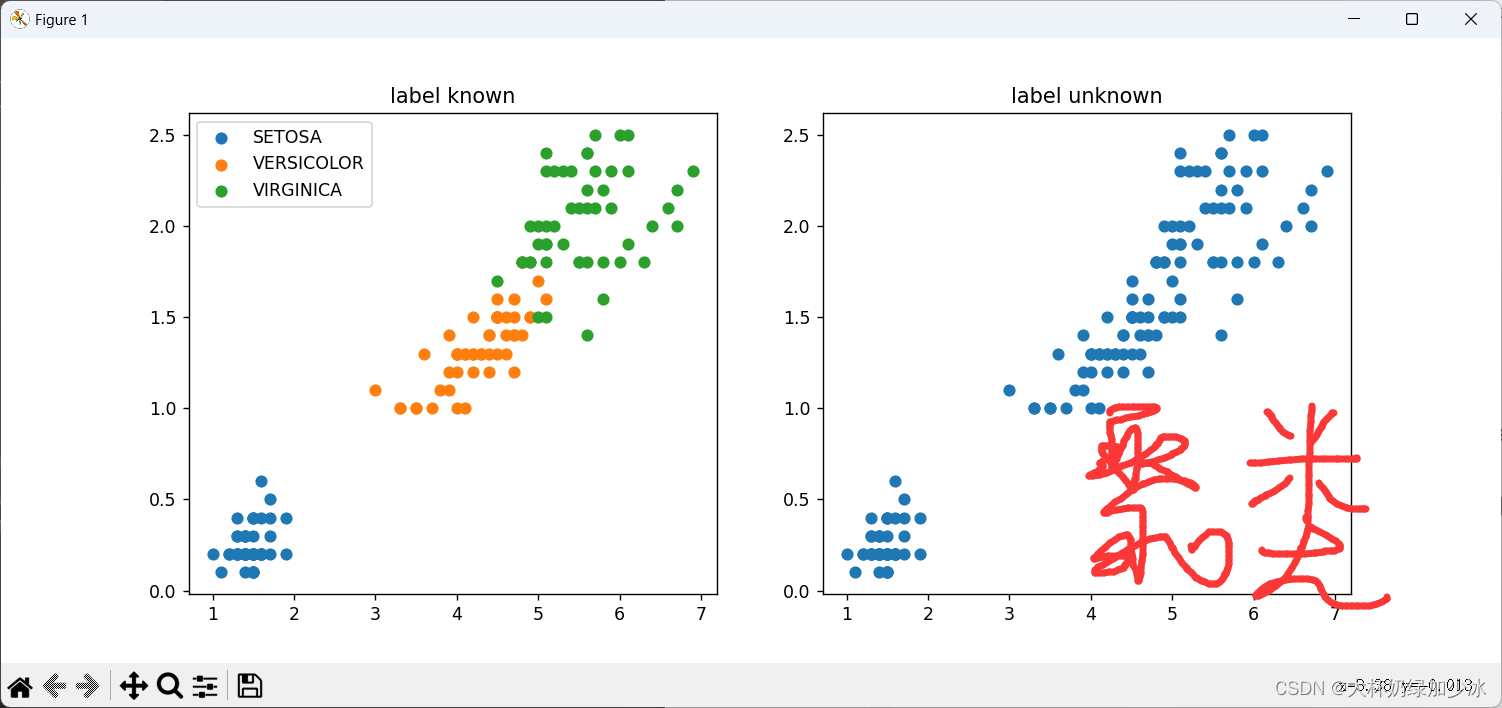
结果二:(×代表质心)