朴素贝叶斯文本情感分析
1.1 基本原理
从贝叶斯公式出发
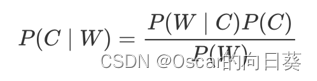
- P© 表示 C 出现的概率,也称为先验概率,是基于主观经验、历史数据或领域知识估计所得的信息,一般作为情感分析的目标值。
- P(W|C) 表示 C 条件下 W 出现的概率。
- P(W) 表示 W 出现的概率,也是情感分析中的文本特征。
- P(C|W)表示C的条件下,出现W的概率。也就是说:出现一些文本特征时,为C类情感的概率。
朴素贝叶斯在贝叶斯基础上增加:特征条件独立假设,即:特征之间是互为独立的。
联合概率的计算即可简化
如果P(A, B) = P(A)P(B),则称事件A与事件B相互独立
语言前后之间有逻辑关系,逻辑关系表现出语义,进而拥有了情感,那么添加了独立性假设,为什么能作用于情感分析呢?
原因很简单,将语句分词后,会将拥有情感的词语分离出来,如:喜欢、好,开心等等。当然加入一个“不”字,情感状态会发生180度大反转,词袋中情感向好的词会有,情感向不好的词也会有。但是数据增多后,词袋中情感向好的词会慢慢被稀释掉,渐渐趋向于0。所以只看各个情感词的词数即可,那么各词与各词之间便是独立的,就可以将朴素贝叶斯应用到情感分析中。
1.2 原理事例
1.2.1 数据集介绍
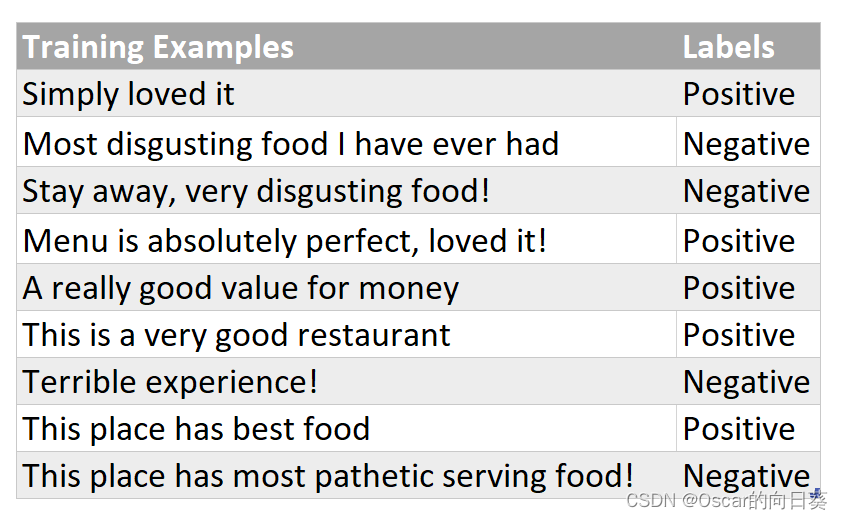
有如下训练数据, 记录了用户对餐厅的评价, 我们为每一条评论添加了相关标签, Positive 代表好评,Negative代表差评
1.2.2 模型训练
数据预处理
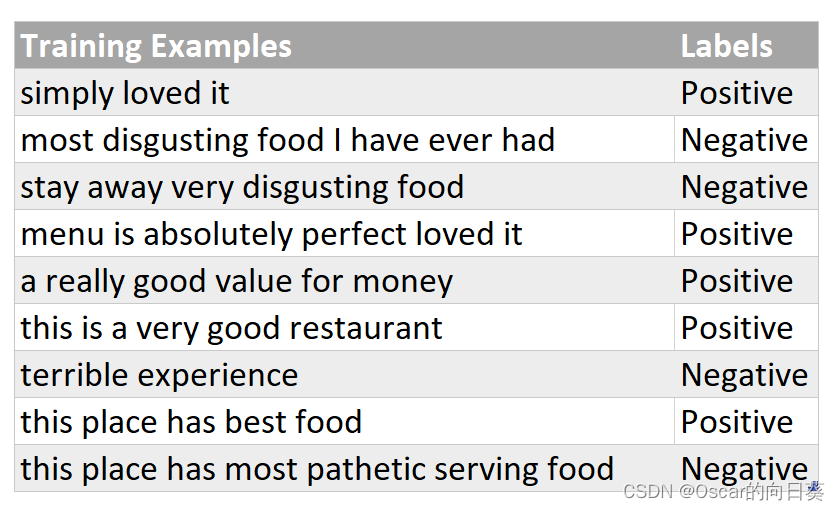
首先我们将训练数据集中的所有单词都 转换为小写 ,并去掉标点符号
准备词袋
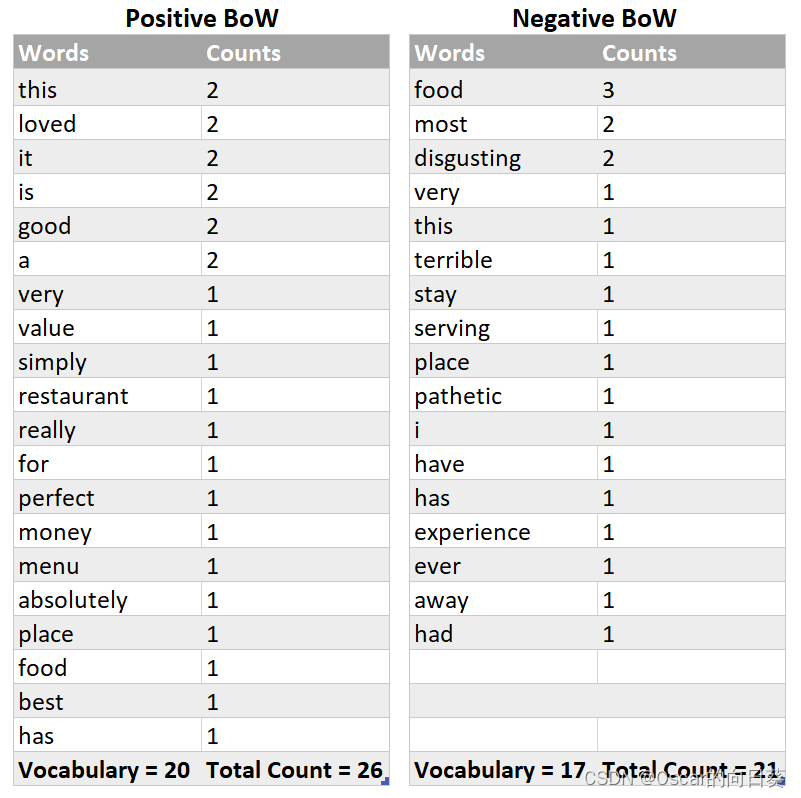
统计好评(Positive) 和 差评(Negative) 中出现的单词的词频(单词出现的次数),放到两个词袋中(bag of word)
到这儿我们的模型数据已经准备好, 可以进行预测了
1.2.3 朴素贝叶斯分类
此时有一条新的评论 ‘Very good food and service!!!’,要使用朴素贝叶斯模将其分类为好评或差评
数据预处理
按照训练阶段相同的方式处理数据

接下来我们要将数据拆成一个一个单词

朴素贝叶斯分类
此时我们要分别计算 P(好评|very,good,food,and, service) , P(差评|very,good,food,and,service), 并比较他们的大小
根据贝叶斯公式
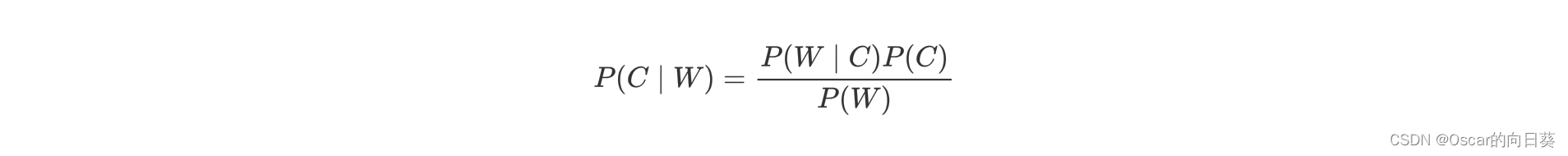
我们需要计算 :
P ( v e r y , g o o d , f o o d , a n d , s e r v i c e ∣ 好评 ) ∗ P ( 好评 ) P ( v e r y , g o o d , f o o d , a n d , s e r v i c e ) \huge \frac{P(very,good,food,and, service|好评) * P(好评)}{P(very,good,food,and, service)} P(very,good,food,and,service)P(very,good,food,and,service∣好评)∗P(好评)
P ( v e r y , g o o d , f o o d , a n d , s e r v i c e ∣ 差评 ) ∗ P ( 差评 ) P ( v e r y , g o o d , f o o d , a n d , s e r v i c e ) \huge \frac{P(very,good,food,and, service|差评) * P(差评)}{P(very,good,food,and, service)} P(very,good,food,and,service)P(very,good,food,and,service∣差评)∗P(差评)
由于只需要比较大小,而分母又相同,所以我们只需要计算分子:
P ( v e r y , g o o d , f o o d , a n d , s e r v i c e ∣ 好评 ) P ( 好评 ) \large P(very,good,food,and, service|好评) P(好评) P(very,good,food,and,service∣好评)P(好评)
P ( v e r y , g o o d , f o o d , a n d , s e r v i c e ∣ 差评 ) P ( 差评 ) \large P(very,good,food,and, service|差评) P(差评) P(very,good,food,and,service∣差评)P(差评)
先计算 P(好评) P(差评)

训练集中,共9条数据,4条消极的,5条积极的
根据朴素贝叶斯的独立假设可得:
P(very,good,food,and, service|好评) = P(very|好评) * P(good|好评) * P(food|好评) * P(and|好评) * P(service|好评)
P(very,good,food,and, service|差评) = P(very|差评) * P(good|差评) * P(food|差评) * P(and|差评) * P(service|差评)
统计待预测样本的单词在不同类别中的词频,0说明训练集词袋中没有该测试集词汇:

统计带预测样本的单词在不同类别中的概率,如very在positive中的概率为1/26=0.038461538

计算P(very,good,food,and, service|好评) 和P(very,good,food,and, service|差评)

由于在训练集中, 好评的词袋中没有and 和 service,差评的词袋中没有 good , and ,service 导致概率计算为0, 也就是分子为0了,无法完成好评与差评的预测。
此时,需要为其加上 拉普拉斯平滑系数
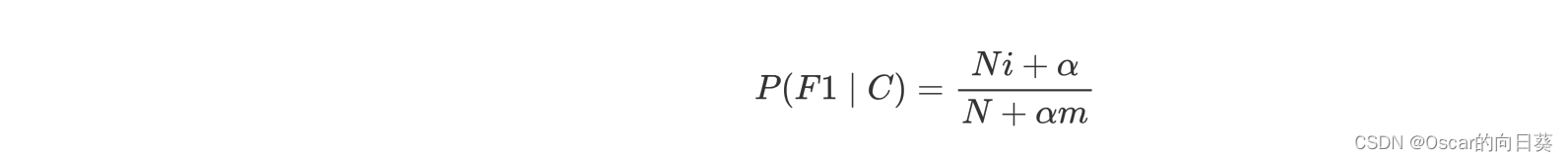
F1为前面公式中的W,一般α = 1 , m为总的特征数量, 本例为训练集中出现的单词数量
本例中训练集一共有32个不同的单词
N+αm Positive Class 26+32=58 Negative Class 21+32 = 53
统计词频


从而避免了0的效应,计算概率
| very | good | food | and | service | |
|---|---|---|---|---|---|
| Positive Class | 0.03448 | 0.05172 | 0.03448 | 0.017241 | 0.017241 |
| Negative Class | 0.03773 | 0.01887 | 0.07547 | 0.018868 | 0.018868 |
计算P(very) * P(good) * P(food) * P(and) * P(service):
Positive Class 0.03448 * 0.05172 * 0.03448 * 0.017241* 0.017241 = 1.8277548046720714e-08
Negative Class 0.03773 * 0.01887 * 0.07547 * 0.018868 * 0.018868 = 1.912867068490868e-08
计算最终结果
Positive Class 1.8277548046720714e-08 * 5/9 = 1.0154193359289285e-08
Negative Class 1.912867068490868e-08 * 4/9 = 0.8501631415514969e-08
从上面结果中看出,好评的概率 > 差评的概率, 所以该条评论为好评
1.2.4 流程小结
训练数据处理(去掉无关符号, 字母转小写)→ 统计训练数据词频→ 得到词袋(BoW)
带预测样本数据处理(去掉无关符号, 字母转小写) → 统计待预测样本中单词在训练集中的词频→ 计算概率→得出分类结果
1.3 做文本分类时的具体应用
文本分类模型训练时需要做的事儿
- 训练数据处理(去掉无关符号, 字母转小写)→ 统计训练数据词频(去掉无关词)→ 得到词袋(BoW)
使用朴素贝叶斯进行分类时的流程
- 待预测样本数据处理(去掉无关符号, 字母转小写) → 统计带预测样本中单词在训练集中的词频→ 计算概率→得出分类结果
- 在做文本分类的时候, 可能会出现在训练集中不曾出现的单词, 可以使用拉普拉斯平滑系数来解决问题
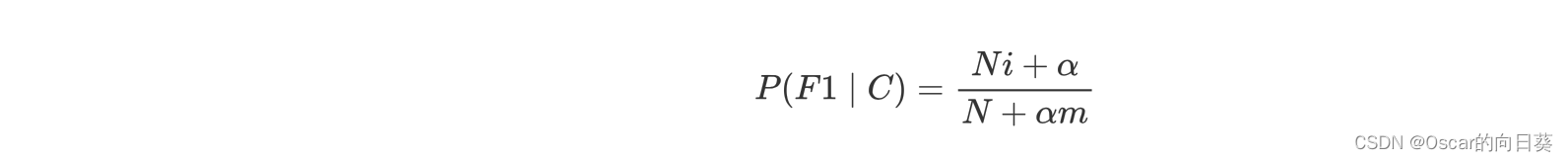
一般α = 1 , m为特征数量, 本例为训练集中出现的单词总数
1. 4 评论情感分类案例
基本套路
- 加载文本内容之后, 先做分词 jieba (中文分词)
- 分词之后做词频统计 CountVectorizer
- 加载停用此表
- 数据资料:链接:https://pan.baidu.com/s/1uBYr-CY23rGP0xvNGmNKRA
提取码:90ns
import pandas as pd
import numpy as np
import jieba
from sklearn.feature_extraction.text import CountVectorizer # 词频统计的库(文本转换成向量) feature_extraction 特征抽取
from sklearn.naive_bayes import MultinomialNB # 朴素贝叶斯
# 加载数据
data = pd.read_csv('书籍评价.csv',encoding='gbk')
# 处理目标值
# np.where(条件, 满足条件时的取值, 不满足条件时的取值)
data['label'] = np.where(data['评价']=='好评',1,0)
y = data['label']
## 加载停用词表
stopwords = []
with open('stopwords.txt','r',encoding='utf-8') as f:
lines = f.readlines()
stopwords = [line.strip() for line in lines] # 去空格 去掉字符串前面跟后面的空格
stopwords = list(set(stopwords)) # 放到集合里, 做去重, 去重之后再变成列表
# 使用jieba 中文分词工具 进行中文分词
comment_list = [','.join(jieba.lcut(line)) for line in data['内容']]
# ','.join 把jieba分词 之后的列表, 再用逗号拼成一句话
# 使用CountVectorizer 对评论文本列表进行处理, 得到每个单词作为一个特征的 特征数据
# 加载之前处理好的停用词表 通过 stop_words参数传进来
count_vec = CountVectorizer(stop_words=stopwords)
x = count_vec.fit_transform(comment_list)
## 使用朴素贝叶斯进行文本分类
x_train = x[:10,:] # 训练集
y_train = y[0:10]
x_test = x[10:,:] # 训练集
y_test = y[10:]
# 创建朴素贝叶斯对象 默认拉普拉斯平滑系数是1
estimator = MultinomialNB()
estimator.fit(x_train,y_train)
y_pred = estimator.predict(x_test)
count_vec.fit_transform(comment_list) 返回的是一个稀疏向量
通过 x.toarray() 可以展示成二维表的形式
count_vec.get_feature_names_out() # 打印所有特征, 出现的单词
1.5 额外小知识
# Linux中解压zip压缩包
unzip trec06c.zip
unzip trec06c.zip -d 目标路径