摘 要
:本文运用Python编程语言进行数据挖掘与分析,针对豆瓣图书数据展开研究,力图展现中国图书市场中出版社的影响力格局、书籍的受众接受度及那些既高产又广受好评的作者概况。研究数据源自豆瓣网,涵盖书籍的多项基本信息:书名、作者姓名、出版社名称、出版年份、页码数量、定价、用户评分及评论累计量等核心参数。通过细致的数据清洗、严谨的预处理流程及深度分析,本研究不仅呈现了各大出版社的出版活跃度排名,还揭示了书籍的质量评价分布,以及创作丰硕且作品质量上乘的作家名单,为图书消费者、出版行业决策者及学术研究者提供了丰富的信息资源与实践指导。
关键词:数据预处理;豆瓣读书;Python编程;数据分析;数据清洗
随着互联网的普及,图书市场的竞争日益激烈,了解消费者偏好、出版社影响力以及优秀作者成为了业界关注的焦点。豆瓣作为重要的图书评价与分享平台,积累了大量的用户评分和评论数据,为图书推荐算法、消费者行为分析等研究提供了宝贵资源。然而,原始数据往往包含噪声和不一致性,因此数据预处理成为数据分析的关键步骤。本研究聚焦于豆瓣读书数据集的预处理和基本分析,因其用户基数大、评价体系完善,能够较好地反映书籍的市场表现。可以揭示书籍评价的基本模式和潜在趋势。
- 数据预处理理论:数据预处理是数据分析的第一步,包括数据清洗、格式转换、缺失值处理等。本文中重命名列名、重置索引、数据类型转换、处理非标准格式的“页数”和“价格”列、去除页数中的非数字字符和异常值、以及删除价格低于1元的记录等,都是数据预处理的重要组成部分。这一环节遵循数据质量保障理论,确保分析结果的准确性和可靠性。
- 数据探索性分析:通过调用df.describe()查看评分的统计信息,旨在通过统计摘要快速了解数据的中心趋势、分散程度等基本信息,为后续深入分析奠定基础。
- 数据质量与完整性管理:去除重复书名数据,保证数据的唯一性和准确性,确保分析有效性。
- 缺失值处理:数据集中经常会出现缺失值,处理方法包括删除含有缺失值的记录、填补缺失值(使用均值、中位数、众数或模型预测等),具体方法依据数据特点和分析目的决定。
- 数据标准化与规范化:在处理“页数”和“价格”列时,通过替换、删除非数字字符,确保数据格式的统一,可提高模型的稳定性和预测能力。
- 异常值处理:识别并剔除价格异常低的记录,基于统计学原理,避免因极端值影响整体分析结果的准确性。
- 数据类型转换:确保变量采用正确的数据类型是数据分析的前提,比如将文本型的数字转换为数值型,便于进行数学运算和统计分析。
- 数据可视化:通过图形展示数据,有助于快速理解数据分布、趋势、关联等特征,是数据分析不可或缺的一部分。常用的库有matplotlib、seaborn等。
2.1数据集来源
数据集来源于公开渠道,包含书籍的多项属性,比如书名、评分、评论数量、页数、价格等关键信息。
2.2数据预处理
- 数据清洗:去除无效数据,如缺失重要字段的记录,处理异常值,如非数字字符的页数和价格。
- 结构化处理:重命名列名,统一数据格式,如将出版时间标准化为年份,确保评分和评论数量为数值型。
- 筛选条件:保留2019年及以前出版的图书,页数大于0且价格合理的记录,以保证分析的时效性和准确性。
- 去重排序:根据评论数量降序排序,去除重复书籍,确保分析结果唯一性。
- 总结:通过多方面数据清洗,包括列重命名、数据类型的正确指定、去除不符合规范的数据(如非数字页数、异常价格等)、以及处理重复数据等,提高数据分析的准确性和有效性。通过这些预处理,数据集被整理得更加规范、整洁。
3.1出版社分析
1.通过条形图直观展示了各出版社的出版活跃度,有助于识别市场上的主要参与者。
2.利用value_counts()统计各出版社出版数量,对出版数量超过200的出版社进行了排名。
3.绘制出版社出版作品数量排名图,展示了出版集团的市场份额。
4.计算并展示出版社的平均书籍评分排名,反映各出版社出版书籍的整体质量。
3.2书籍排名
- 结合评论数量和评分的加权总分,为书籍评价提供了一种更综合的视角,有助于发现既受欢迎又高质量的书籍。
- 选取评论数量超过50000的书籍,计算其“加权总分”(结合评分和评论数量),以更全面地评估书籍的受欢迎程度和质量。
- 展示了加权总分排名前20的书籍,揭示了市场上的热门读物。
3.3作者分析
- 对作家创作质量进行了量化评估,有助于读者发现优秀作者,也为出版行业提供了潜在合作对象的参考。
- 筛选出评论数量超过100且评分不低于8的作品,统计作者作品数量。
- 对作品数量不少于10的作家计算平均评分,排名前20的作家名单揭示了高产且高评价的创作者。
4.1代码
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = ['SimHei']
import seaborn as sns
df = pd.read_csv(r'../../../Desktop/python/book_douban.csv', index_col=0)
print(df)
df.head(10)
df.info()
# 数据预处理
df.rename(columns={'数': '页数'}, inplace=True) # 重命名列
df.describe()#查看评分统计信息
# 处理缺失(null)值和数据清洗
df.replace('None', np.nan, inplace=True)#将'None'替换为NaN
df.isnull().sum()#查看缺失值情况
df.dropna(subset=['作者', '出版社', '出版时间', '页数', '价格', '评分', '评论数量'], how='any', inplace=True)#删除包含缺失值的行
df.drop('ISBM', axis=1, inplace=True)#去除‘ISBM’列
df.reset_index(drop=True, inplace=True)#重置索引
df.isna().sum()#确认是否还有空值
# 出版时间处理
df['出版时间'] = df['出版时间'].astype(str).str.replace(' ', '')
df['出版时间'] = df['出版时间'].str.extract(r'(\d{4})', expand=False).fillna(0).astype(np.int32)
df = df[df['出版时间'] <= 2024]
df['评分'] = df['评分'].astype(float) # 数据类型转换
df['评论数量'] = df['评论数量'].astype(np.int32)
# 页数处理
df['页数'] = df['页数'].astype(str) # 确保'页数'列是字符串类型
df['页数'] = df['页数'].str.replace(r'\D', '', regex=True) #去除非数字字符 将清理后的字符串转换回数值类型,并用coerce处理无法转换的值(转换为NaN)
df['页数'] = pd.to_numeric(df['页数'], errors='coerce')
#移除转换后仍然是NaN的行(原始数据中存在完全无法转换为数字的行)
df.dropna(subset=['页数'], inplace=True)
df['页数'] = df['页数'].astype(np.int32) #转为整数类型
df = df[df['页数'] > 0]
# 价格处理
df['价格'] = df['价格'].astype(str).str.replace(',', '').str.replace(' ', '') #将'价格'列转换为字符串
#尝试转换为浮点数,这里使用pd.to_numeric以便更好地处理异常值
df['价格'] = pd.to_numeric(df['价格'], errors='coerce')
# 价格处理后的检查
df.dropna(subset=['价格'], inplace=True)
if df.empty:
print("警告:价格处理后DataFrame为空,请检查价格转换条件。")
else:
df = df[df['价格'].astype(str).str[-1].str.isdecimal()]
df = df[df['价格'] >= 1]
# 去除价格非数字结尾的行
df = df[df['价格'].astype(str).str[-1].str.isdecimal()]
# 排序并去重
df['书名'].value_counts()#查看书名重复情况
df.sort_values(by='评论数量', ascending=False, inplace=True)#按评论数量降序排序然后去重
df.drop_duplicates(subset='书名', keep='first', inplace=True)
df['书名'].value_counts()#查看是否还有重复数据
if not df.empty:
df.to_excel(r'cleaned_book_data.xlsx', engine='openpyxl', index=False)
else:
print("警告:尝试保存数据前DataFrame为空,未执行保存操作。")
# 出版社分析
press = df['出版社'].value_counts().reset_index()
press.columns = ['出版集团', '出版数量']
# 出版社排名
press_rank = press[press['出版数量'] > 200].sort_values(by='出版数量', ascending=False)
press_rank.to_excel(r'press_rank.xlsx', engine='openpyxl', index=False)
# 书籍排名
sor = df[df['评论数量'] > 50000].sort_values(by='评分', ascending=False)
sor['加权总分'] = sor.apply(lambda x: ((x['评论数量'] / (x['评论数量'] + 50000)) * x['评分']) + (50000 / (x['评论数量'] + 50000)), axis=1)
book_rank = sor.nlargest(20, '加权总分')#加权总分=(v/(v+m))*R+(m/(v+n))
#R:评分,v:评论数量,m:评论数量阈值,R:平均评分,C:平均评分阈值
book_rank.to_excel(r'book_rank.xlsx', engine='openpyxl', index=False)
# 作者分析
df1 = df[df['评论数量'] > 100]
df1 = df1[df1['评分'] >= 8]
writer = df1['作者'].value_counts().reset_index()
writer.columns = ['作家', '作品数量']
# 作家排名
lst1 = writer[writer['作品数量'] >= 10]['作家'].tolist()
writer_rank = df1[df1['作者'].isin(lst1)].groupby('作者')['评分'].mean().reset_index()
writer_rank.sort_values(by='评分', ascending=False, inplace=True)
writer_rank.head(20).to_excel(r'writer_rank.xlsx', engine='openpyxl', index=False)
# 加载清理后的数据
df_cleaned
pd.read_excel(r'C:\Users\fengbao\Desktop\python\cleaned_book_data.xlsx')
# 加载分析结果数据
press_rank = pd.read_excel(r'C:\Users\fengbao\Desktop\python\press_rank.xlsx')
book_rank = pd.read_excel(r'C:\Users\fengbao\Desktop\python\book_rank.xlsx')
writer_rank = pd.read_excel(r'C:\Users\fengbao\Desktop\python\writer_rank.xlsx')
# 出版社出版作品数量排名
plt.figure(figsize=(12, 6))
press_rank['出版数量'] = press_rank['出版数量'].astype(float)
sns.barplot(x='出版数量', y='出版集团', data=press_rank)
plt.title('出版社出版作品数量排名')
plt.xlabel('出版数量')
plt.ylabel('出版集团')
plt.show()
plt.tight_layout() # 自动调整子图参数, 使之填充整个图像区域
# 出版社平均评分排名
average_scores = book_rank.groupby('出版社')['评分'].mean()
average_scores_df = average_scores.reset_index()
plt.figure(figsize=(12, 6))
sns.barplot(x='评分', y='出版社', data=average_scores_df)
plt.title('出版社平均评分排名')
plt.xlabel('评分')
plt.ylabel('出版社')
plt.show()
# 评论数量超过50000的书籍排名(加权总分)
plt.figure(figsize=(12, 6))
sns.barplot(y='书名', x='加权总分', data=book_rank.head(20))
plt.title('加权总分排名前20的书籍')
plt.xlabel('加权总分')
plt.ylabel('书名')
plt.xticks(rotation=90)
plt.show()
# 作家平均评分排名
plt.figure(figsize=(12, 6))
sns.barplot(x='评分', y='作者', data=writer_rank.head(20))
plt.title('作家平均评分排名前20')
plt.xlabel('平均评分')
plt.ylabel('作者')
plt.show()
初始数据:
| 书名 | 作者 | ... | 评分 | 评论数量 | |
| 1 | 中国武侠小说史论 | 叶洪生 | ... | 0.0 | NaN |
| 2 | HowtocookandeatinChinese | 杨步伟 | ... | 0.0 | NaN |
| 3 | 吐鲁番考古记 | 黄文弼 | ... | 0.0 | NaN |
| 4 | 塞瓦斯托波尔故事 | 列夫·托尔斯泰 | ... | 0.0 | NaN |
| 5 | 敦煌变文集(上下集) | 王重民 | ... | 0.0 | NaN |
| ... | ... | ... | ... | ... | |
| 60667 | 佛教的精神与特色 | 林世敏 | ... | 8.6 | 49.0 |
| 60668 | 名苑猎凶·庄园迷案 | (英)阿加莎·克里斯蒂 | ... | 6.9 | 25.0 |
| 60669 | 坦克-前进! | [德]H.古德里安 | ... | 7.5 | 17.0 |
| 60670 | 怪物大师10:冰封的时之轮 | NaN | ... | 7.2 | 15.0 |
通过调用df.info(),获取到关于 DataFrame 结构和数据类型的快速概览。包括:数据框中每列名称,每列非空值数量,每列的数据类型数据框的内存使用情况。
| 0 | 书名 | 60626 | non-null | object |
| 1 | 作者 | 59612 | non-null | object |
| 2 | 出版社 | 57908 | non-null | object |
| 3 | 出版时间 | 59634 | non-null | object |
| 4 | 数 | 56369 | non-null | object |
| 5 | 价格 | 58777 | non-null | object |
| 6 | ISBM | 59539 | non-null | float64 |
| 7 | 评分 | 60626 | non-null | float64 |
表2 关于 DataFrame 结构和数据类型
| 书名 | 作者 | 出版社 | 出版时间 | 页数 | 价格 | 评分 | 评论数量 |
| 小王子 | [法] 圣埃克苏佩里 | 人民文学出版社 | 2003 | 97 | 22 | 9 | 209602 |
| 围城 | 钱锺书 | 人民文学出版社 | 1991 | 359 | 19 | 8.9 | 178288 |
| 挪威的森林 | [日] 村上春树 | 上海译文出版社 | 2001 | 350 | 18.8 | 8 | 177622 |
| 白夜行 | [日] 东野圭吾 | 南海出版公司 | 2008 | 467 | 29.8 | 9.1 | 170493 |
| 解忧杂货店 | (日)东野圭吾 | 南海出版公司 | 2014 | 291 | 39.5 | 8.6 | 160063 |
| 梦里花落知多少 | 郭敬明 | 春风文艺出版社 | 2003 | 252 | 20 | 7.2 | 142386 |
| 不能承受的生命之轻 | [捷克] 米兰·昆德拉 | 上海译文出版社 | 2003 | 394 | 23 | 8.5 | 129324 |
| 三体 | 刘慈欣 | 重庆出版社 | 2008 | 302 | 23 | 8.8 | 122959 |
| 达·芬奇密码 | [美] 丹·布朗 | 上海人民出版社 | 2004 | 432 | 28 | 8.2 | 122803 |
| 活着 | 余华 | 南海出版公司 | 1998 | 195 | 12 | 9.1 | 118521 |
| 嫌疑人X的献身 | [日] 东野圭吾 | 南海出版公司 | 2008 | 251 | 28 | 8.9 | 117699 |
| 1988:我想和这个世界谈谈 | 韩寒 | 国际文化出版公司 | 2010 | 215 | 25 | 7.9 | 116378 |
| 何以笙箫默 | 顾漫 | 朝华出版社 | 2007 | 247 | 15 | 8 | 113566 |
| 红楼梦 | [清] 曹雪芹 著 | 人民文学出版社 | 1996 | 1606 | 59.7 | 9.5 | 111576 |
| 看见 | 柴静 | 广西师范大学出版社 | 2013 | 424 | 39.8 | 8.8 | 107152 |
| 简爱 | [英] 夏洛蒂·勃朗特 | 世界图书出版公司 | 2003 | 436 | 18 | 8.5 | 100953 |
| 平凡的世界(全三部) | 路遥 | 人民文学出版社 | 2005 | 1631 | 64 | 9 | 92968 |
表3 经过预处理的数据(只选取了前20行)
| 书名 | 作者 | 出版社 | 出版时间 | 页数 | 价格 | 评分 | 评论数量 | 加权总分 |
| 小王子 | [法] 圣埃克苏佩里 | 人民文学出版社 | 2003 | 97 | 22 | 9 | 209602 | 7.45918 |
| 白夜行 | [日] 东野圭吾 | 南海出版公司 | 2008 | 467 | 29.8 | 9.1 | 170493 | 7.263207 |
| 围城 | 钱锺书 | 人民文学出版社 | 1991 | 359 | 19 | 8.9 | 178288 | 7.169729 |
| 红楼梦 | [清] 曹雪芹 著 | 人民文学出版社 | 1996 | 1606 | 59.7 | 9.5 | 111576 | 6.869659 |
| 解忧杂货店 | (日)东野圭吾 | 南海出版公司 | 2014 | 291 | 39.5 | 8.6 | 160063 | 6.791019 |
| 活着 | 余华 | 南海出版公司 | 1998 | 195 | 12 | 9.1 | 118521 | 6.696739 |
| 三体 | 刘慈欣 | 重庆出版社 | 2008 | 302 | 23 | 8.8 | 122959 | 6.54513 |
| 嫌疑人X的献身 | [日] 东野圭吾 | 南海出版公司 | 2008 | 251 | 28 | 8.9 | 117699 | 6.544589 |
| 挪威的森林 | [日] 村上春树 | 上海译文出版社 | 2001 | 350 | 18.8 | 8 | 177622 | 6.462363 |
表4 书籍排名(选取前十行数据)
| 作者 | 评分 |
| 汪曾祺 | 8.956 |
| 史铁生 | 8.9 |
| 鲁迅 | 8.886207 |
| 吕思勉 | 8.823077 |
| 朱光潜 | 8.82 |
| 叶嘉莹 | 8.8 |
| 余英时 | 8.8 |
| 沈从文 | 8.781818 |
| 三毛 | 8.776923 |
| (美)艾萨克·阿西莫夫 | 8.77 |
| 夏达 | 8.761538 |
| 顾城 | 8.757143 |
| 南怀瑾 | 8.7275 |
| 王小波 | 8.721667 |
| 出版集团 | 出版数量 |
| 中信出版社 | 1391 |
| 人民文学出版社 | 979 |
| 广西师范大学出版社 | 879 |
| 生活·读书·新知三联书店 | 835 |
| 人民邮电出版社 | 809 |
| 上海译文出版社 | 795 |
| 机械工业出版社 | 766 |
| 中华书局 | 741 |
| 新星出版社 | 716 |
| 上海人民出版社 | 685 |
| 北京大学出版社 | 684 |
| 译林出版社 | 634 |
| 商务印书馆 | 633 |
| 电子工业出版社 | 614 |
表5 出版社出版数量排名(部分) 表6 作家评分排名(部分)
附录:图表展示
包括出版社出版作品数量排名图、出版社平均评分排名图、加权总分排名前20的书籍图以及作家平均评分排名图,直观展示了分析结果。展示了一个全面的绩效视图,方便我们后续继续深入了解出版市场的现状和趋势
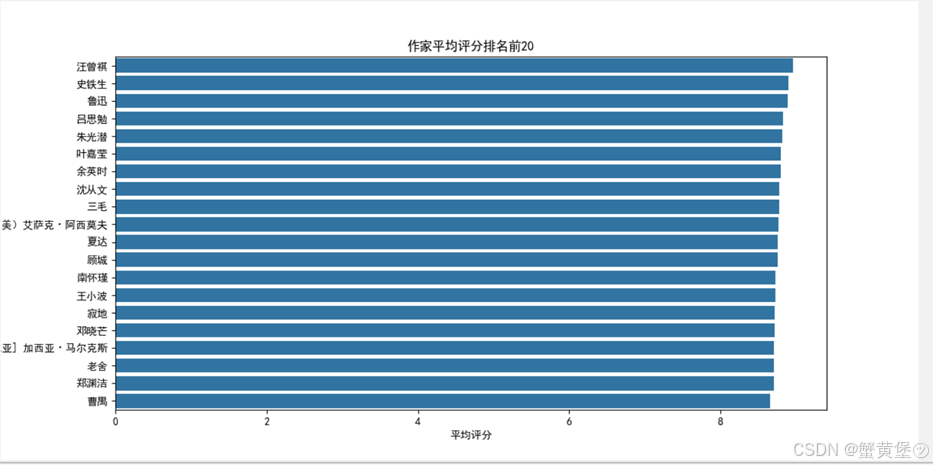
表格体现了文学市场中顶尖创作者的表现。排名靠前的作者不仅展现了广泛读者认可的卓越文学功底,这些作家的成功在于独特的创作风格、深刻的主题挖掘及稳定的内容质量,即便作品数量不一,亦能维持高水准,证明了创意与匠心在读者心中的恒久价值。
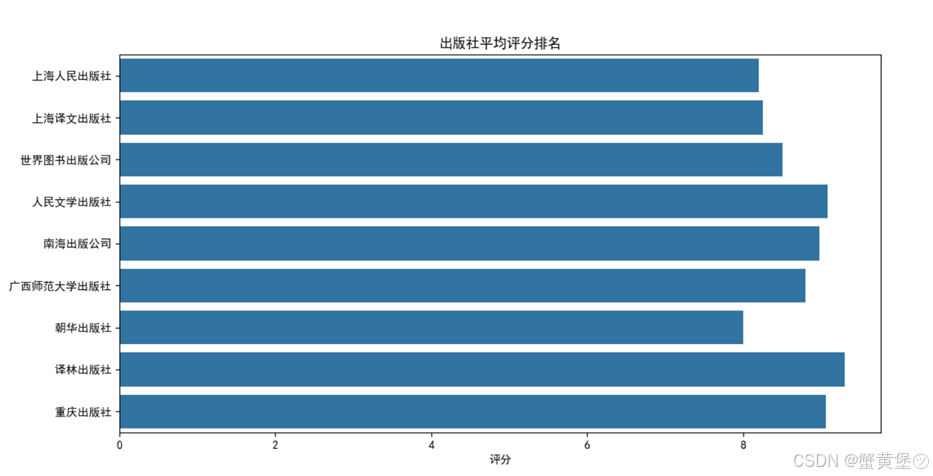
图2 出版社平均评分排名图
上图数据源为上文中作者排名(10部作品以上),可知汪曾祺先生的作品评分最高,达到8.96分。汪曾祺在短篇小说创作上颇有成就,作品有《受戒》《晚饭花集》《逝水》等。
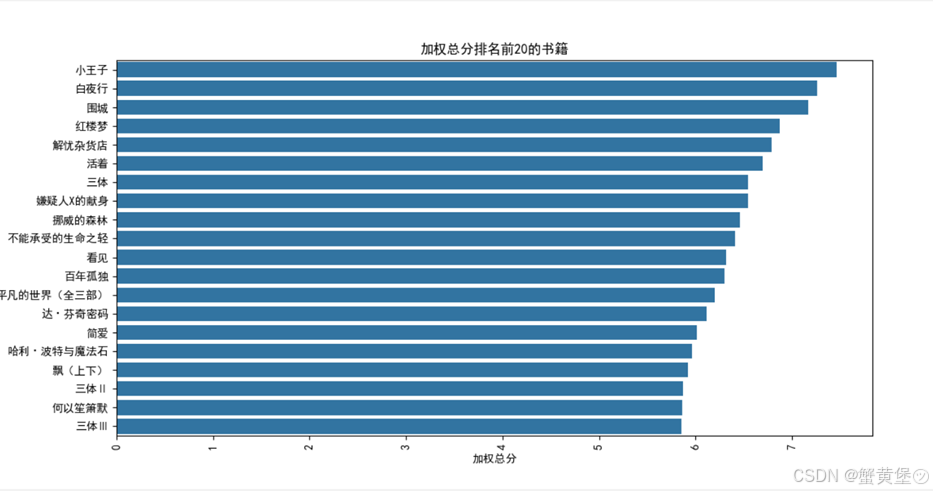
此评分是通过上文中加权总分取得,可以看出,中文,英文,日文作品均有上榜。在文明的传承中,书籍发挥的作用是空前的,华夏文明,从甲骨文开始,一直被纪录至今,不管是中国的儒家文化,还是西方的文艺复兴,书籍总是不可替代的记录工具,所以在此统计评分排名前20部作品。
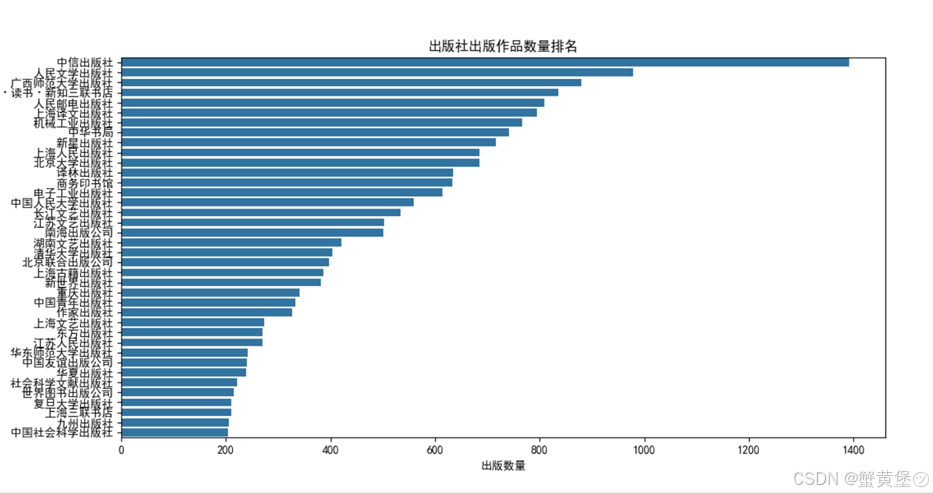
可以看出中信出版社在市场中最为活跃,出版书籍种类最多。对于理解图书市场的竞争格局、出版行业的集中度以及各出版社的市场份额都有重要意义。
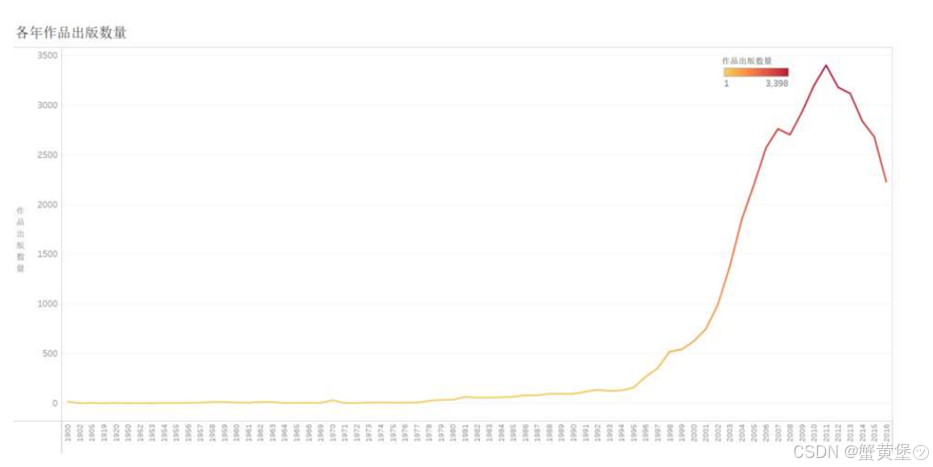
年份从1900年开始统计,可知:在1995年之前每年出版的作品数量增长较为缓慢,在1995年之后出版的作品数量迅速增长,并在2011年达到顶峰,在2011年后出版数量虽然有所下滑,但仍保持较高水平。

从图中可知,在20元到40元价格区间的书籍占比超过总数量的50%,说明大多数读者最能接受的价位在20到40元之间,但也可以发现超过120元的书籍也占有不小的比例。
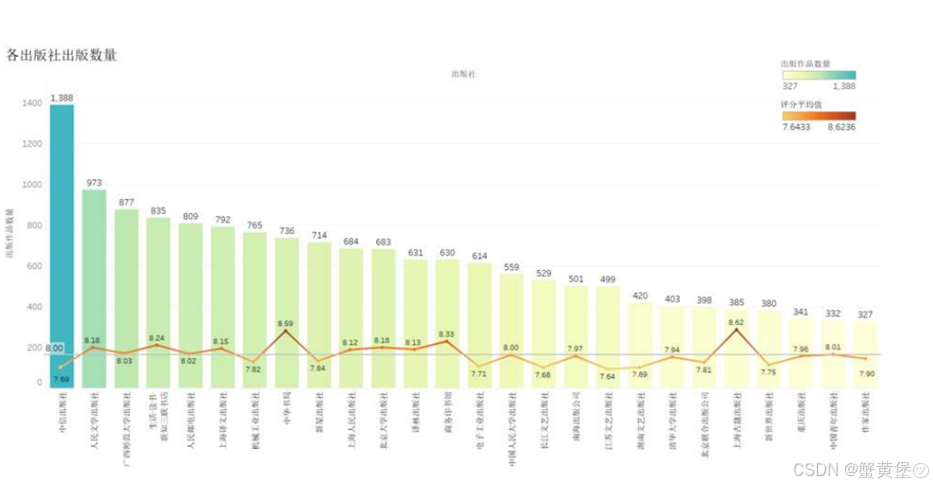
由于数据较多,上图支筛选了出版作品数量大于300的出版社,可知作品出版数量最多的是中信出版社,最少的是作家出版社,所有出版社的总平均分为8.0分,其中中华书局出版社与上海古籍出版社平均分较高。