在科技日新月异的今天,人工智能(AI)领域再次迎来了一个令人瞩目的新星——DeepSeek。这个名字在近期迅速走红,成为了科技界、投资界乃至普通民众热议的焦点。近日,苹果中国区应用商店免费榜显示,DeepSeek成为中国区第一。

那么,DeepSeek究竟是什么呢?它为何能引发如此广泛的关注和讨论?
DeepSeek,全称杭州深度求索人工智能基础技术研究有限公司,是一家成立于2023年7月的创新型科技公司。这家年轻的企业专注于开发先进的大语言模型(LLM)和相关技术,致力于通过其强大的自然语言处理能力为用户提供高效的信息搜索和解答服务。
一、公司背景
-
成立时间:DeepSeek成立于2023年7月17日,其背后是国内对冲基金巨头幻方量化。
-
公司全称:杭州深度求索人工智能基础技术研究有限公司。
-
团队特点:集结了一批国内名校毕业的高密度年轻人才,其中不乏应届生、实习生。在这里,工作经验不再是衡量人才的唯一标准,着重考察人选素质和对大模型的热爱。

二、产品与服务
-
产品特点:DeepSeek旨在通过自然语言处理和机器学习算法来理解和回应用户的查询,它具备卓越的自然语言处理能力和代码生成能力,可以执行多种任务,包括但不限于信息检索、语言翻译、智能问答等。
-
开源与商用:DeepSeek是一款完全开源且可商用的大型语言模型,用户可以轻松地与AI进行对话,获取所需信息或生成代码。
-
主要模型:
-
DeepSeek-LLM:通用大语言模型,参数规模达到67B,性能接近GPT-4。
-
DeepSeek-Coder:代码大模型,免费供商业使用且完全开源。
-
DeepSeek-MoE:国内首个MoE大模型,在公开评测榜单及真实样本外的泛化效果有超越同级别模型的出色表现。
-
DeepSeek-V2:第二代MoE大模型,在性能上比肩GPT-4 Turbo,价格却只有GPT-4的百分之一。
-
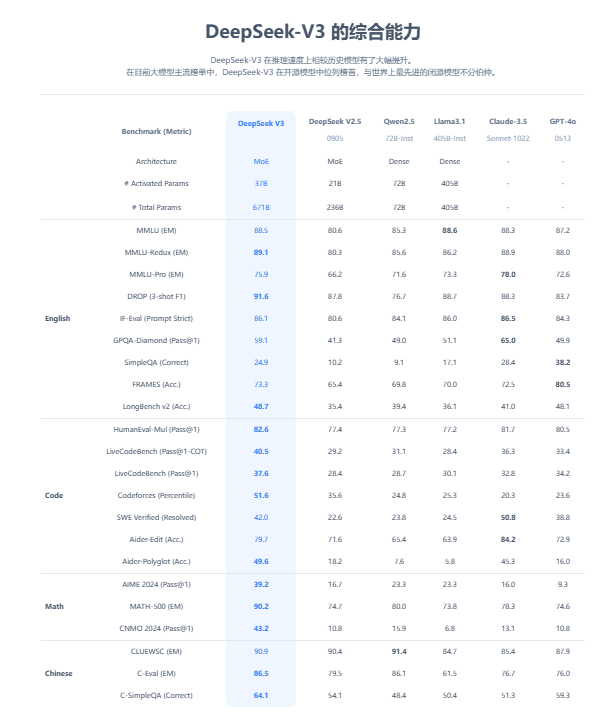
DeepSeek-V3:在多项评测中成绩超越了Qwen2.5-72B和Llama-3.1-405B等其他开源模型,并在性能上和世界顶尖的闭源模型GPT-4o以及Claude-3.5-Sonnet不分伯仲。
-
DeepSeek-R1:推理大模型,在数学、编程和推理等关键领域的表现能与OpenAI的最强推理模型o1相媲美,但其API调用成本却低了90%~95%。
-
Janus-Pro和JanusFlow:一系列开源多模态模型,参数大小从10亿到70亿不等,重点在于文生图能力方面。

三、技术优势
-
成本低廉:DeepSeek的大模型训练成本相对较低,例如DeepSeek-V3的训练成本仅为557.6万美元(约合人民币4070万元),大概是GPT-4的二十分之一。
-
高效能:DeepSeek的模型在多项测试中表现出色,甚至超越了某些主流开源模型。
-
创新架构:DeepSeek采用了创新的架构设计,如多头潜在注意力(MLA)机制,节约了显存和计算资源。
四、市场反响
-
DeepSeek的模型发布后,受到了海外市场的强烈关注,并在美区苹果App Store的免费排行榜中飙升至第一。
-
多位AI行业的资深专家和从业者对DeepSeek的模型表示了赞赏和认可。

五、未来展望
DeepSeek将继续致力于开发更先进的大语言模型和相关技术,以推动人工智能领域的发展。同时,它也将积极应对市场竞争和挑战,不断提升自身的技术实力和市场影响力。
DeepSeek 的迅速崛起,不仅彰显了中国 AI 技术的强大实力,也为全球 AI 市场格局带来了深远的变革。它向世界证明,通过创新的工程设计和高效的训练方法,人工智能的开发不再需要依赖海量的计算资源和巨额的资金投入,而是可以通过更加灵活、经济的方式实现技术突破。这一理念的成功实践,有望引发全球范围内的人工智能创新浪潮,为全球 AI 产业的发展注入新的活力。