目录
2. convert llama weights files into hf format
3. use llama2 to generate text
1. obtain llama weights
(1)登录huggingface官网,搜索llama-2-7b
(2)填写申请表单,VPN挂在US,表单地区选择US,大约10min,请求通过,如下图
(3)点击用户头像来获取token
Because you just need read and download the resource,so token type of 'Read' is engough.
After you access your token,please save it!if not,you have to generate it again.
(4)下载llama-2-7b的权重文件
安装依赖
pip install -U huggingface_hub设置hugging face镜像
vim ~/.bashrcexport HF_ENDPOINT=https://hf-mirror.comsource ~/.bashrc使用刚刚获取的token下载llama-2-7b的权重文件
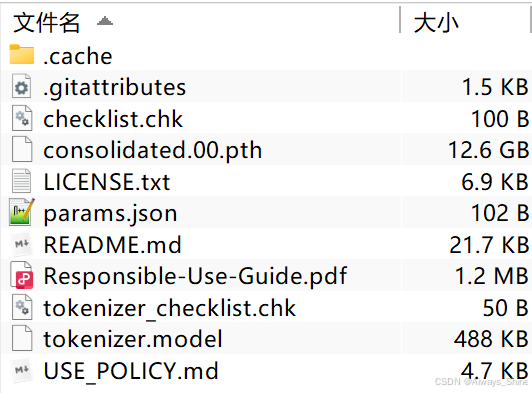
huggingface-cli download --token hf_*** --resume-download meta-llama/Llama-2-7b --local-dir ./llama-2-7b下载成功后llama-2-7b权重目录如下图
2. convert llama weights files into hf format
Follow instructions provided by Huggingface to convert it into Huggingface format.
其实就两步:
(1)点击链接,下载转换脚本convert_llama_weights_to_hf.py
(2)执行命令
python ./convert_llama_weights_to_hf.py --input_dir /hy-tmp/Llama-2-7b --model_size 7B --output_dir /hy-tmp/llama-2-7b-hfMaybe you need a long time to solve dependencies version conflicts, be patient!
转换成功后llama-2-7b-hf目录如下图

网上有很多地方会直接提供hf格式的llama模型文件,那我们便无需上述复杂的转换操作,只需下载到实例即可,很简单。
3. use llama2 to generate text
(1)代码内容
import os
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from torch.cuda.amp import autocast
# 设置环境变量避免显存碎片化
os.environ['PYTORCH_CUDA_ALLOC_CONF'] = 'max_split_size_mb:128'
# 清理缓存
torch.cuda.empty_cache()
# 加载Llama-2-7b模型和分词器
model_name = "/hy-tmp/llama-2-7b-hf"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name,torch_dtype=torch.float16)
# 加载模型到GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = model.to(device)
input_text = "How to learn skiing?"
# 输入文本的编码
input_ids = tokenizer.encode(input_text, return_tensors="pt").to(device)
# 设置生成文本参数
max_length = 256
temperature = 0.7
top_k = 50
top_p = 0.95
# 使用混合精度加速进行推理
with autocast():
output = model.generate(
input_ids,
max_length=max_length,
num_return_sequences=1,
temperature=temperature,
top_k=top_k,
top_p=top_p,
do_sample=True # 使用采样,避免贪婪生成
)
# 解码生成的文本
generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
print(generated_text)(2)执行结果
