目录
第一题握手,这个直接从49累加到7即可,没啥难度,后面7个不握手就好了,没啥讲的,(然后第二个题填空好难,嘻嘻不会)
第一题握手,这个直接从49累加到7即可,没啥难度,后面7个不握手就好了,没啥讲的,(然后第二个题填空好难,嘻嘻不会)
第三题.好数
不是哥们,真比JAVA简单一倍啊,啥奇怪的东西,牛魔的奇数位偶数位都出来了。纯暴力不说了也。
import java.util.Scanner; // 1:无需package // 2: 类名必须Main, 不可修改 public class Main { public static void main(String[] args) { Scanner in=new Scanner(System.in); int N=in.nextInt(); int count=0; for(int i=1;i<=N;i++){ int tmp=0; int k=1; int p=i; while(p!=0){ //求出来个位 int t=p%10; //个位 if(t%2==0&&k%2!=0){ tmp=1; break; } //十位, else if(t%2!=0&&k%2==0){ tmp=1; break; } k++; p=p/10; } if(tmp==1){ continue; }else{ count++; } } System.out.println(count); } }
第四题R格式
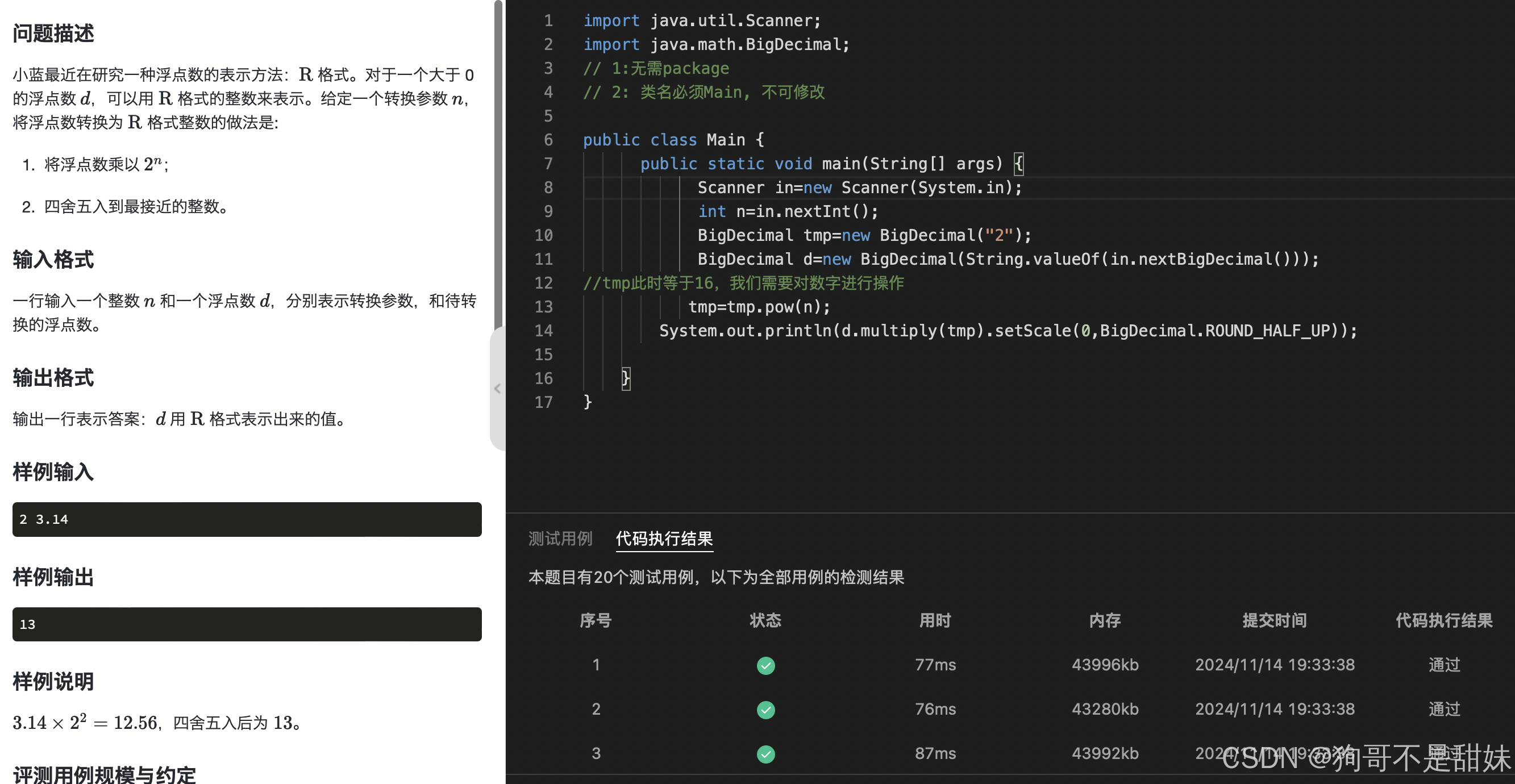
开始的时候没想到用BigDecimal,寻思拿long就够,谁知道根本跑不出来,所以选择使用这个大数,大数的很多东西我都没用过,比如说什么xx次幂,还可以,四舍五入,完全没接触过,我第一次不知道有对应的方法,选择求出中间数,然后计算比如一个进行+1取舍,一个减一,然后两个/2就好
知道遇上了这个
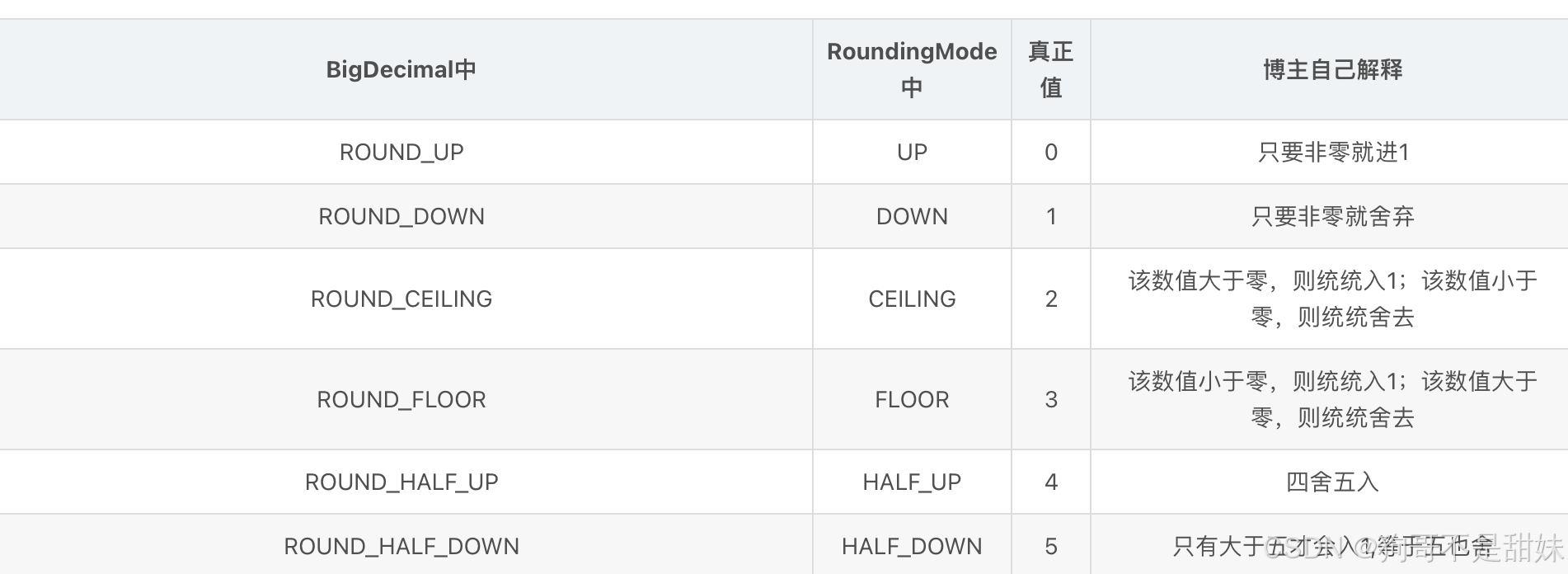
BigDecimal.setScale()方法用于格式化小数点
BigDecimal.setScale(1)保留小数点后一位小数,四舍五入
setScale(1,BigDecimal.ROUND_DOWN)直接删除多余的小数位,如2.35会变成2.3
setScale(1,BigDecimal.ROUND_UP)进位处理,2.35变成2.4
setScale(1,BigDecimal.ROUND_HALF_UP)四舍五入,2.35变成2.4setScale(1,BigDecimal.ROUND_HALF_DOWN)四舍五入,2.35变成2.3,如果是5也向下舍
下面这个图是从这个地方摘的
import java.util.Scanner;
import java.math.BigDecimal;
// 1:无需package
// 2: 类名必须Main, 不可修改
public class Main {
public static void main(String[] args) {
Scanner in=new Scanner(System.in);
int n=in.nextInt();
BigDecimal tmp=new BigDecimal("2");
BigDecimal d=new BigDecimal(String.valueOf(in.nextBigDecimal()));
//tmp此时等于16,我们需要对数字进行操作
tmp=tmp.pow(n);
System.out.println(d.multiply(tmp).setScale(0,BigDecimal.ROUND_HALF_UP));
}
}宝石组合

数学知识:(最小公倍数)lcm(a,b)
最小公倍数:是能被A和B整除的最小正整数值
lcm(a,b)=a*b/gcd(a,b)
gcd两者之间的最大公约数
辗转相除法:a和b两者的最大公约数gcd(b,a%b)(b,a%b 记住顺口溜吧)
最大公约数,b逗a磨b
最小公倍数,相乘除公约(最大)
这个是我看到的题解,当然了,开始看公式谁来也会一脸懵,我们这样枚举一个数字
24 12 6 他们三个的最小公倍数 能被她们三个整除的最小正整数是24
这个是题解上看到的解释。
然后我们思考一下,gcd(a,b,c)最大公约数,是不是一定不会超过三者里面最大的那个。
因此我们直接枚举S,看abc啥的是否有符合的即可(最大公约数,这个数字可以整除这三个数字,那么我们是否可以思考一下,哪些数字可以整除最大s,假如不够3个,则往后走
import java.util.*; // 1:无需package // 2: 类名必须Main, 不可修改 public class Main { public static int S=100001; public static void main(String[] args) { Scanner scan = new Scanner(System.in); int N=scan.nextInt(); int[] a=new int[N]; for(int i=0;i<N;i++){ a[i]=scan.nextInt(); } //这里是个细节,你不写这一行,有一个用例过不去,我们使用的方法和C++大哥使用方法不一样,他是用S去找a[i],我是用a[i]找S. //区别:用S找a[i],他会自动找到顺序,比如S=3,他会先3,6,9,12这样找a[i]有没有这个值 //我们是什么a[i]找S,换句话说a[i]%S假如等于0就说明可以被a[i]整除, //那么这里来了一个问题,我们如何确保顺序性呢,比如14523,他们的可以确认顺序,因为是从1S,2S,3S这么过来的,那么我们找就可以选择使用一个排序,这样我们遍历使用就是字典序了,然后容器选啥都可以,Array,int[],我这个优先级队列(堆),因为排序做完了 Arrays.sort(a); PriorityQueue <Integer>p=new PriorityQueue<>(); while(S>=1) { int count = 0; for (int i = 0; i < N; i++) { //思考清楚是谁除谁,最大公约数是x的话,是a[i]%x==0才叫x是a[i]的公约数。 if (a[i]%S == 0) { p.add(a[i]); count++; } if(count==3) break;; } if(count==3) break;; p.clear(); S--; } while(!p.isEmpty()){ System.out.print(p.poll()+" "); } } }


数字接龙
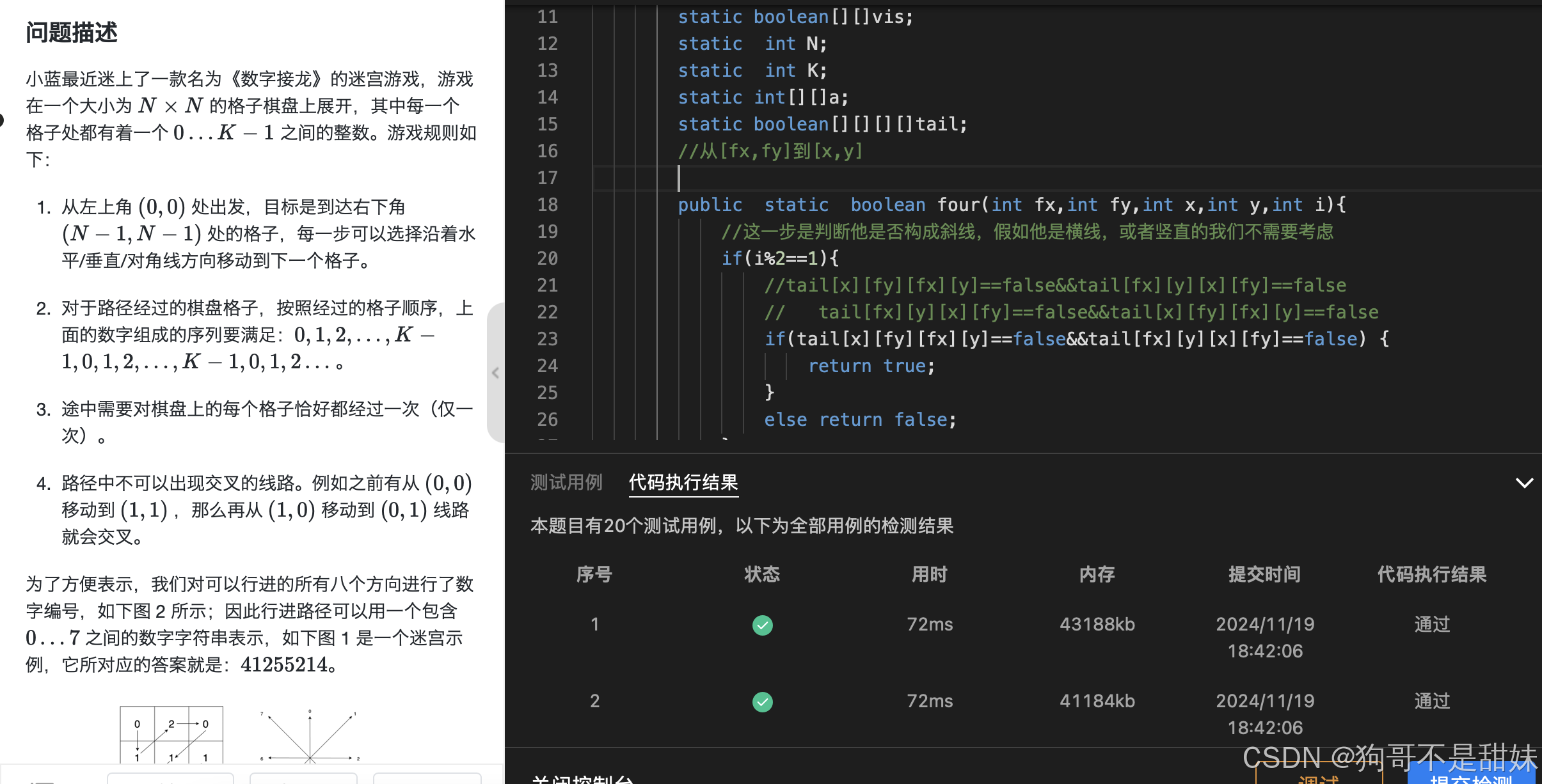


import java.util.*;
// 1:无需package
// 2: 类名必须Main, 不可修改
public class Main {
// 1:无需package
// 2: 类名必须Main, 不可修改
static int[]dx={-1,-1,0,1,1, 1, 0,-1};
static int[]dy={0, 1,1,1,0,-1,-1,-1};
static Stack<Integer>q=new Stack<>();
static boolean[][]vis;
static int N;
static int K;
static int[][]a;
static boolean[][][][]tail;
//从[fx,fy]到[x,y]
public static boolean four(int fx,int fy,int x,int y,int i){
//这一步是判断他是否构成斜线,假如他是横线,或者竖直的我们不需要考虑
if(i%2==1){
//tail[x][fy][fx][y]==false&&tail[fx][y][x][fy]==false
// tail[fx][y][x][fy]==false&&tail[x][fy][fx][y]==false
if(tail[x][fy][fx][y]==false&&tail[fx][y][x][fy]==false) {
return true;
}
else return false;
}
return true;
}
public static boolean check(int fx,int fy,int x,int y,int i){
// (fy-y)/(fx-x)==1)&&x<fx
//比较难处理的就是条件四
if (x >= 0 && y >= 0 && x < N && y < N
//当前没有被遍历过
&& vis[x][y] == false
&& ((a[x][y]<K&&a[fx][fy] + 1 == a[x][y]) ||a[x][y] ==(a[fx][fy]+1)%K) &&
four(fx,fy,x,y,i)==true) {
return true;
}
return false;
}
//表示起点
public static boolean dfs(int a,int b){
if(a==N-1&&b==N-1){
return q.size()==N*N-1;
}
for(int i=0;i<8;i++){
int x=a+dx[i];
int y=b+dy[i];
if(check(a,b,x,y,i)==true){
vis[x][y]=true;
tail[a][b][x][y]=true;
q.add(i);
if (dfs(x,y)==true) return true;
vis[x][y]=false;
tail[a][b][x][y]=false;
q.pop();
}
}
return false;
}
public static void main(String[] args) {
//这道题的思考,首先肯定不是bfs因为他没办法进行回溯,我牛魔不去回溯,我怎么知道那条路可以走到,所以需要回溯,使用dfs
Scanner in=new Scanner(System.in);
N=in.nextInt();
K=in.nextInt();
a=new int[N][N];
//思维数组纯暴力破解
tail=new boolean[N][N][N][N];
for(int i=0;i<N;i++){
for(int j=0;j<N;j++) {
a[i][j]=in.nextInt();
}
}
vis=new boolean[N][N];
vis[0][0]=true;
if(dfs(0,0)==true){
for(int i=0;i<q.size();i++){
//注意我开始写的时候,假如用栈的话,你不可以poll哦,因为假如说是poll就会后面的先出来,顺序
System.out.print(q.get(i));
}
}else {
System.out.print(-1);
}
}
}最后一题:拔河
(说实话,真比JAVA最后一题简单一些,但是他也有难的地方,区间的一个排序很难,以及你暴力没办法解决)
纯暴力是肯定不能ac,估计也就通过6,7个例子,我们从暴力的过程中,学到优化才是核心目的。
import java.util.Scanner;
// 1:无需package
// 2: 类名必须Main, 不可修改
public class Main {
public static void main(String[] args) {
Scanner in=new Scanner(System.in);
int n=in.nextInt();
long []a=new long[n+1];
for(int i=1;i<=n;i++){
a[i]=in.nextLong();
}
long[][]dp=new long[n+1][n+1];
for(int i=1;i<=n;i++){
for(int j=i;j<=n;j++){
//从i位置到j,i到j-1然后+1
dp[i][j]=dp[i][j-1]+a[j];
}
}
//最后我们思考,他的区间一定是连续,并且不重叠的
for(int i=0;i<=n;i++) {
dp[0][i]=dp[i][0]=0x3f3f3f3f3f3f3f3fL;
}
long min=0x3f3f3f3f3f3f3f3fL;
//换句话,正确的话,就是暴力枚举,一个枚举左边的左端点,另一个枚举右端点,再来一个枚举右边的左端点,来一个枚举右边的右端点
//左端点从左侧,开始最后的n,但是细想一下,左端点是否可以等于n,答案应该是不可以的,左端点的右端点也不该到n,右端点的左端点肯定不可以和那个是左端点的右连起来
for(int i=1;i<n;i++){
for(int j=i;j<n;j++){
for(int t=j+1;t<=n;t++) {
for (int k = t; k <= n; k++) {
min = Math.min(Math.abs(dp[i][j ] - dp[t][k]), min);
}
}
}
}
System.out.println(min);
}
}那么我们该如何优化呢?,
在这里引入数据结构
TheeSet:特点有序性,唯一性,插入删除查找都是O(logN)(内部是红黑)
first(返回数组中最小的元素)
last(返回数组中最大的元素)
higher(E e)返回集合中大于给定元素的最小元素
lower(E e):返回集合中严格小于给定元素的最大元素
ceiling(E e)返回集合中最小的大于或等于给定元素的元素
引入这个结构是为了让他有序,我们根据这个有序,随便来组合,不管他重复与否,全给他放入,
Scanner scanner = new Scanner(System.in); int n = scanner.nextInt(); long[] a = new long[n + 1]; for (int i = 1; i <= n; i++) { a[i] = scanner.nextInt(); a[i] += a[i - 1]; } TreeSet<Long> s = new TreeSet<>(); //初始化一个很大数字 long ans = 1000000000L; for (int i = 1; i <= n; i++) { for (int j = i; j <= n; j++) { //从1开始不断因为我们前缀和,所以需要不断减去a[i-1]的值,从a[1]-a[0],a[2]-a[0]...a[2]-a[1]...,不断求出不同位置的前缀和 if (!s.contains(a[j] - a[i - 1])) { //假如s里面之前已经有了这个值,就说明两个数字相同,直接返回0就行 s.add(a[j] - a[i - 1]); } else { System.out.println(0); return; } } } //此时已经把所有的数组都处理好了,然后我们需要做 for (int i = 1; i < n; i++) { for (int j = 1; j <= i; j++) { //t会走到所有的元素,假如TreeSet里面有(你要是说有最大的,最大的你想找较小的, // 那么是否我们会找到较小的,然后找到最大的,所以不用去顾虑顺序啥的 long t = a[i] - a[j - 1]; // higher(E e)返回集合中大于给定元素的最小元素 //我在思考一个问题假如说 a b c x y z 假如说a+b和b+c他俩相差最小的情况呢,那么是否ac就可以,b不用管 //或者a b c 我们发现一个问题,假如出现重复的最小的情况,那么不需要重复的,换句话说 a+b 和b+c最小,其实不用看b,a和c最小 //我思考的是什么(如何保证两个前缀和,之间没有重复元素,假如有重复元素不就不可以了吗,但是实际上两个出现重复就不需要看重复 //这样一想,一切的2个连续子数组之和,求最小即可,有重复也可以(我重复的可以认为是把重复的去除) Long p = s.higher(t); if (p == null) { //假如没有比他大的,那就去找first(返回数组中最小的元素) //这里就是需要处理一下边界条件,但是假如是空,返回任意一个即可,无需说是一定就first p = s.first(); } //没有比他大的,然后用t这个值减去p这个值 ans = Math.min(ans, Math.abs(t - p)); } } System.out.println(ans);