序言
本篇文章中,将带大家了解 五种 I/O 模型:

以及详细介绍 多路复用 的三种常用的方式。那废话不多说,让我们开始吧!
1. 为什么 I/O 浪费 CPU 资源?
为什么我们需要 五种 I/O ?因为我们需要其他非阻塞式的 I/O 来避免过多的 I/O 操作浪费 CPU 的资源。那为什么 I/O 浪费 CPU 资源?这个问题很重要,是我们所有问题的起因。
在网络编程中,当我们需要用户输入数据时需要两个阶段:
- 等待用户数据就绪,包括用户输入数据,并且数据传输到我们的设备中
- 拷贝数据,数据从内核拷贝到我们的进程上
这就是 I/O 中的读取数据,时间大部分都消耗在了等待用户数据就绪上。但是我们知道,在等待某个资源就绪时,CPU 不会傻傻的等待,该进程会被挂到该等待资源的等待队列中,拷贝数据时 CPU 确实会处于空闲状态,但是看起来也不是那么严重呀😲!
在高负载的服务器上中,哪怕是一丁点儿的漏洞都会带来严重的后果,这是因为 量变引起质变!在使用高峰期时,一个服务器会接受大量的 I/O 请求,问题就出现了:
- 数据不是一开始就是有的,需要等待用户的输入,确实 CPU 不会等待,但是 CPU 会切换该进程或者是线程呀,频繁地切换造成消耗
- 当大量拷贝数据时,CPU 长时间处于空闲的状态,这不是浪费吗
- I/O 操作会触发中断,中断会打断 CPU 的正常运行,使得 CPU 要处理中断请求和恢复执行状态,这也会增加 CPU 的负担
现在知道了事情的起因经过,就该想出解决方案了。
2. 阻塞 IO
1. 定义
这是最常见的 IO 方式,也是最简单的 IO 方式,当数据没有准备就绪时,会持续等待,过程如下:
这个流程可谓相当简单:
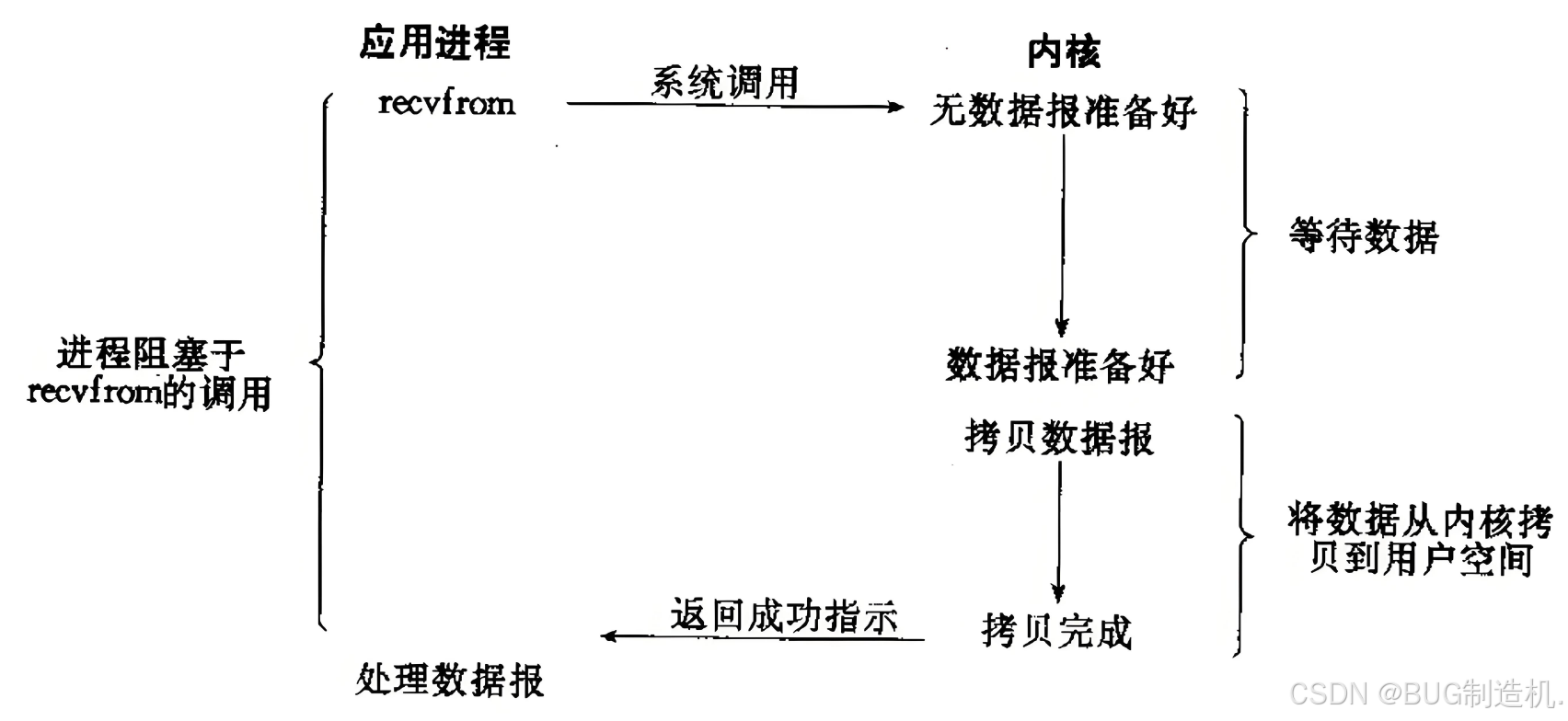
- 调用读取接口,进程等待数据就绪
- 数据就绪后从内核拷贝到我们的进程上
- 我们的进程进行处理数据
举个栗子,钓🐟的过程无非就是等待鱼上钩和上钩之后再把鱼钓上来,阻塞 IO 就相当于一心一意钓鱼的,耐心等待鱼上钩再钓起来。
2. 示例
我们在这里就简单的使用代码举个栗子:
#include <iostream>
#include <unistd.h>
int main()
{
char buf[1024];
int n = read(0, buf, sizeof(buf) - 1);
if (n > 0)
{
buf[n] = '\0';
std::cout << buf << std::endl;
}
return 0;
}
这个就是我们最熟悉不过的 阻塞IO,只要我们一直不输入数据,我们的进程就会一直等待。
3. 非阻塞 IO
1. 定义
当数据没有准备好时,该进程不会傻傻地等了,他会去执行其他的任务,但是会采用 轮询 的方式每隔一段时间就来看一下数据是否准备好了:
这个流程只是多了轮询的过程:

- 调用读取接口
- 进程在等待时可执行其他工作,每隔一会询问一下
- 直到数据就绪,并从内核拷贝到我们的进程上
- 我们的进程进行处理数据
这个钓鱼佬在钓鱼的时候,不会一直等待着鱼上钩,他会在等于的过程中干些别的事儿,每隔一段时间他才会看鱼上钩了没。
2. 示例
首先需要和大家先介绍一个系统调用的接口:
int fcntl(int fd, int cmd, … /* arg */ );
该函数可以改变已经打开的文件的性质,现在我们介绍它的参数:
fd:文件描述符,表示要操作的文件cmd:操作指令,用于指定fcntl函数要执行的具体操作arg:与cmd指令相关的参数
他的操作指令还是较多的,我们今天就介绍两个:
F_GETFL:获取文件描述符的状态标志F_SETFL:设置文件描述符的状态标志
我们首先通过第一个操作指令获取该文件描述符的状态,然后在该状态的基础上加上我们需要的非阻塞状态:
// 获取文件描述符的状态
int fd_flags = fcntl(fd, F_GETFL, 0);
if (fd_flags < 0)
{
perror("fcntl:");
return false;
}
// 设置非阻塞状态
if (fcntl(fd, F_SETFL, fd_flags | O_NONBLOCK))
{
perror("fcntl:");
return false;
}
最后我们将该新的状态写回文件中。现在当我们读取一个文件,但是数据还未就绪时,read 函数就会返回 -1。现在问题来了,原来返回 -1 是代表读操作出问题了,但是现在不一定了,还有可能是非阻塞返回!
我们如何判断是哪一种情况呢?大家还记得全局的错误码吗:
在非阻塞模式下,如果
read操作不能立即完成,则read不会使调用进程进入阻塞状态等待数据到达。相反,它会立即返回一个特定的值,并设置全局变量errno来指示错误或特殊情况。
所以我们只需要再次判断 errno 的值即可:
while (true)
{
int n = read(0, buf, sizeof(buf) - 1);
if (n > 0)
{
buf[n] = '\0';
std::cout << buf << std::endl;
}
else
{
if (errno == EWOULDBLOCK)
{
// do other
std::cout << "暂时还没有数据处理!" << std::endl;
sleep(1);
}
else
{
perror("read:");
break;
}
}
}
这就是不断地轮询去检查数据是否就绪啦!
4. 多路复用 IO
1. 定义
前面两者都是单个进程处理单个 IO 请求,但是现在多路复用可就厉害了,它允许单个进程或线程同时处理多个 IO 请求。 当某个文件描述符就绪时,通知该进程进行读写操作;反之,进程被允许执行其他操作。
总的来说,IO 多路复用是一种高效的 IO 处理模型,它允许单个进程或线程同时处理多个 IO 请求,提高了系统的资源利用率和吞吐量。
这个过程就不一样了,我们将我们的文件交给 select 管理,而不是自己管理:
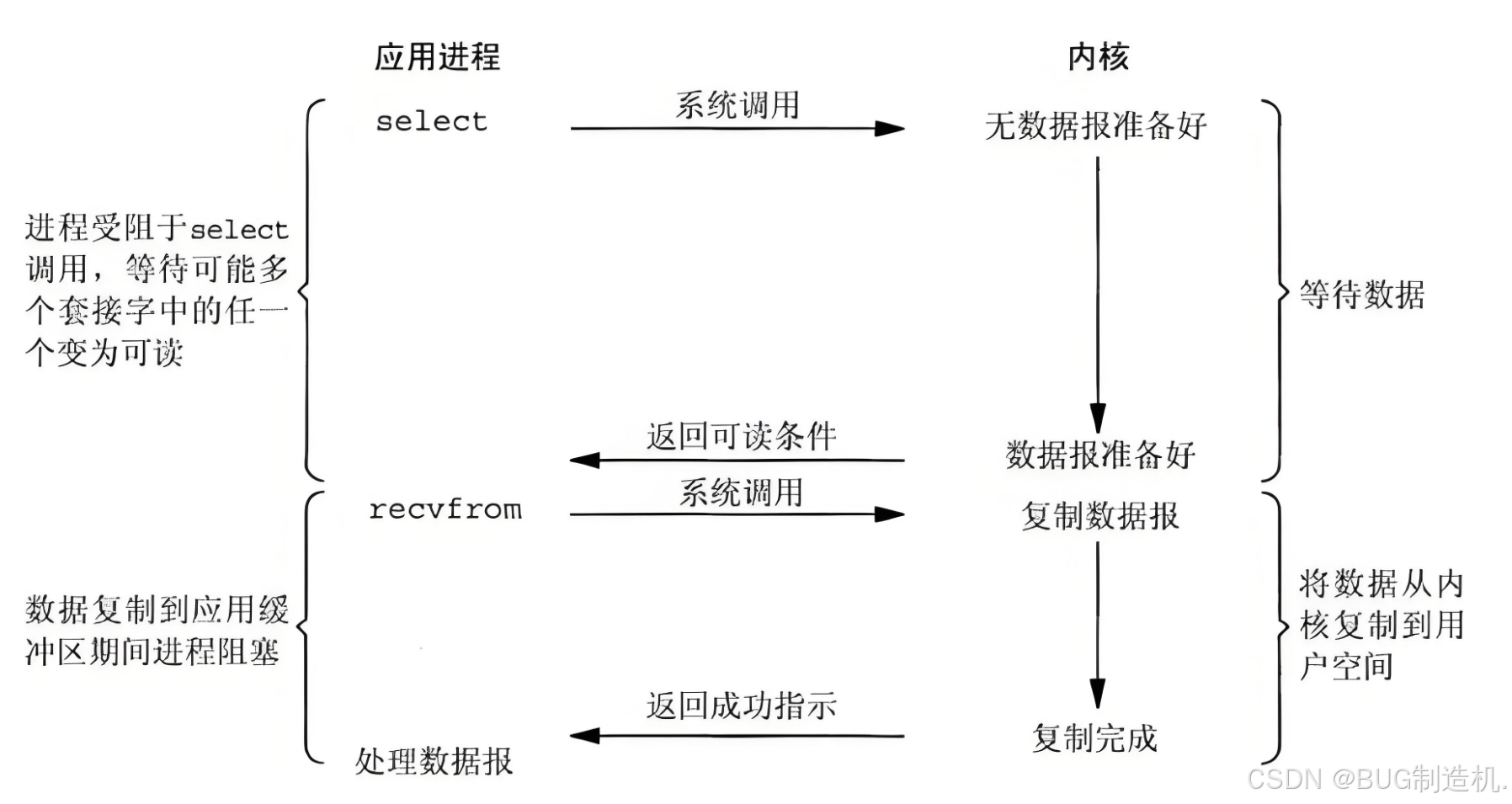
- 将我们的文件描述符交给
select - 进程在等待时可执行其他工作
- 直到数据就绪,
select返回可读条件 - 我们的进程拷贝数据进行处理
我们再次结合钓鱼佬来理解,这个钓鱼佬很注重效率,他钓鱼放了很多杆儿,在等待的同时他也会干其他事儿。但是因为杆儿多了,所以想都不用想他肯定处理数据的效率是很高的,因为杆儿多了鱼肯定也上钩的数量多了。
2. select 函数
多路复用主要涉及 select,poll,epoll 这三个,在本片文章中,我就介绍最经典的 select 方法,之后会专门给大家介绍后两个方法。
这是 select 的相关函数和结构体字段:
int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
参数看起来不少,因为它可以帮我们监视 读,写,异常 条件是否就绪,但是我们在这里只是关注 读条件 是否就绪:
nfds:需要监视的文件描述符的 最大值加1readfds:指向需要监视以进行读取操作的文件描述符集合的指针timeout:指定select函数等待的最大时间。如果为NULL,则select将无限期地等待返回值:函数返回准备好进行I/O操作的文件描述符的数量,或者如果发生错误,则返回 -1
现在我们来聊一聊这个函数的工作原理,在这里这是针对于读事件哦,但是明白了读其他两个也就触类旁通了!
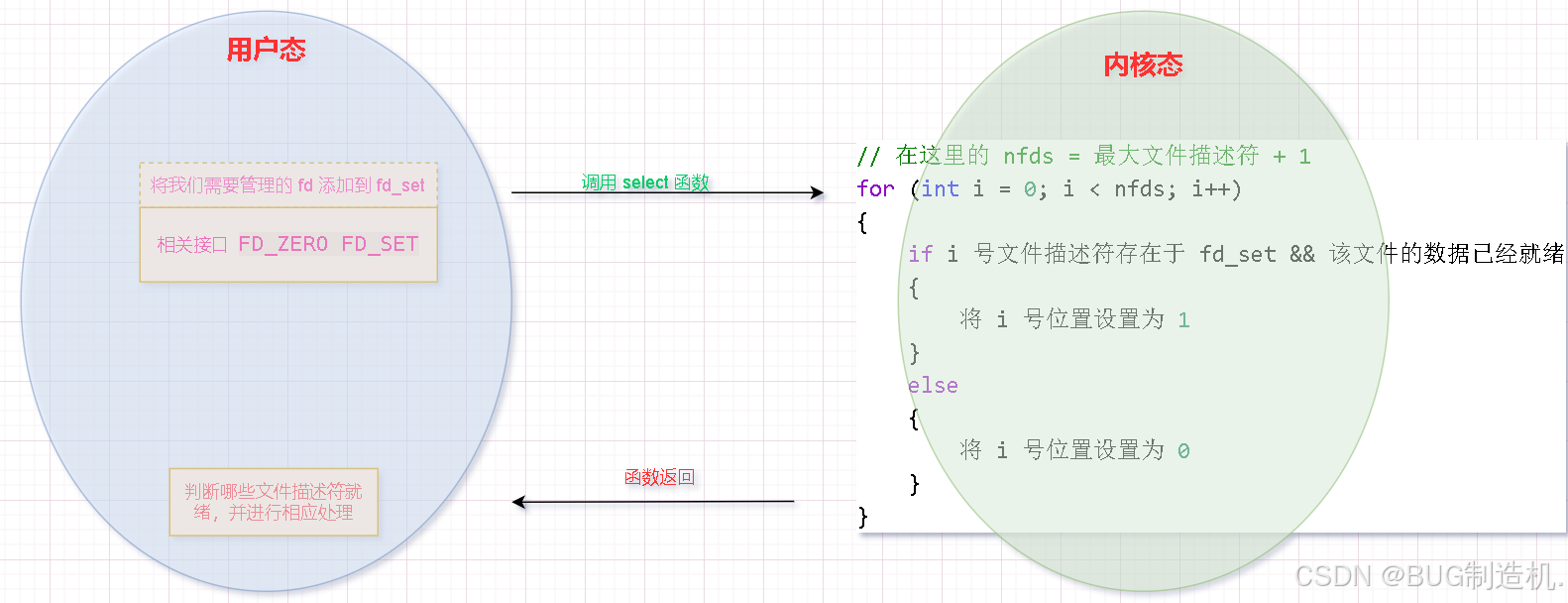
文件集合 fd_set 本质是一个位图(最大容量为 1024 ),位图的位置 表示 相对应的文件描述符,内容表示该文件描述符是否有效,1 代表该位置的文件描述符有效,0 则表示该位置的文件描述符无效:
比如:0101 ,这代表监控 0,2 这两个文件描述符
所以当我们想要 select 帮我们监视 4 号文件描述符时,怎么设置呢?如下:
fd_set read_fds;
// 初始化文件描述符集合,并添加要监视的文件描述符
FD_ZERO(&read_fds);
FD_SET(4, &read_fds);
当 select 返回一个大于 0 的数,代表有文件描述符就绪了,我怎么直到哪一个就绪呢。这里的 readfds 是一个输入输出型参数:
- 输入时,代表需要管理哪些文件描述符
- 输出时,代表哪些文件描述符就绪了
我们可以使用 FD_ISSET(int fd, fd_set *set) 来判断该文件描述符是否在 fd_set 中。
其实 timeout 也是一个输入输出型参数,如果 timeout 中 readfds 中有事件发生,则返回 timeout 剩下的时间。
好的,我们来看一下整体的流程:
select 函数作为最初版的多路复用函数,还是存在不少缺点:
- 文件描述符有上限 1024,不方便监视大量的文件描述符
select函数在每次调用时都需要遍历所有被监视的文件描述符,即使其中大部分都没有发生变化- 每次使用都会从用户态切换到内核态,切换带来的消耗
- 每次调用都需要重新设置
fd_set,因为他是输入输出型参数
所以说尽管并不完美,但是 select 对于少量文件的场景也是不错的。
3. 示例
在这里我们不再使用简单的 IO 作为演示了,我们在这里使用网络编程,因为在网络上我们才能更为便捷的创建多个 IO 请求,体现多路复用的强大!
在开始之前,如果大家不了解 Socket 编程 过程是怎么回事儿,可以先看一下 这篇文章😚了解一下。好的现在我们回忆一下 TCP 通信的具体的步骤:
- 创建套接字
- 绑定端口号和 IP
- 创建监听套接字
- 等待客户端连接
- 连接成功,数据处理
现在我们将我的代码包装了一下,我们前 3 步相当于直接完成了,我们只需要关心其他客户端的连接,以及管理建立连接后的套接字文件。
简单介绍他的操作流程:
首先非常重要的三个成员变量:
int _maxfd;
std::vector<int> _fds;
std::unique_ptr<Socket> _listensock;
_maxfd:每次新创建fd后都要更新这个值,方便传入select函数_fds:我们在之前说过,select函数会更新readfds,所以我们需要自己记录一下哪些文件描述符需要被监管_listensock:这个就是被包装后的监听套接字
通过 select 我们就可以使用单进程管理多个套接字文件,达到多线程的效果:
void Loop()
{
while (true)
{
// 初始化 rfds,并将需要监控的文件描述符写入
fd_set rfds;
InitFdset(rfds);
int n = select(_maxfd, &rfds, nullptr, nullptr, nullptr);
switch(n)
{
case 0:
std::cout << "超时了..." << std::endl;
break;
case -1:
perror("select:");
break;
default:
std::cout << n << " 个读事件已经就绪,尽快处理!" << std::endl;
HandleEvent(rfds);
break;
}
}
}
这个核心代码的逻辑如下:
- 每次循环都初始化
fd_set,将我们的需要管理的文件写入 - 将
fd_set交给select管理,等待文件出现事件 - 更具返回值处理事件,现在假设
n > 0,处理读取事件
现在我们再来看文件处理逻辑:
void Accepter()
{
// 获取最新连接的套接字
SockAddHelper Client;
int newsockfd = _listensock->AcceptConnect(Client)->GetFd();
if (_fds.size() == MaxSize)
{
std::cout << "FD_SET is full..." << std::endl;
return;
}
_fds.push_back(newsockfd);
if (newsockfd > _maxfd) _maxfd = newsockfd;
std::cout << "Successful add fd = " << newsockfd << ", the client is " << Client.GetIP() << std::endl;
}
void HandleIO(int index)
{
char Buf[MaxSize];
int n = recv(_fds[index], Buf, MaxSize, 0);
// 客户端退出逻辑
if (n == 0)
{
std::cout << "Client quit..." << std::endl;
close(_fds[index]);
_fds.erase(_fds.begin() + index);
}
else if(n > 0)
{
Buf[n] = '\0';
std::cout << Buf << std::endl;
}
else
{
perror("recv:");
}
}
// 文件描述符处理逻辑
void HandleEvent(fd_set& rfds)
{
for (int i = 0; i < _fds.size(); i++)
{
// 如果该文件已经就绪
if (FD_ISSET(_fds[i], &rfds))
{
// 判断是否是 listenfd
if (_fds[i] == _listensock->GetFd())
{
Accepter();
}
else
{
HandleIO(i);
}
}
}
std::cout << "Successful handle all fd..." << std::endl;
}
- 遍历管理的文件,查看哪一个文件就绪了
- 判断是监听文件就绪了,还是普通套接字文件就绪了
- 监听文件就绪就执行增添套接字的逻辑
- 普通文件就绪就执行读或者是其他逻辑
依次不断地循环,就可以达到管理多个文件描述符的作用。
5. 信号驱动 IO
1. 定义
信号驱动IO 通常用于非阻塞模式下,当文件描述符(如套接字、管道或终端)的状态发生变化时,通过发送信号来通知进程。但是并不是很推荐,因为它们会打断正常的程序流程。在信号处理函数中执行复杂的IO操作可能会导致不可预测的行为。
这种方式并不常见,但是我们还是介绍一下过程:
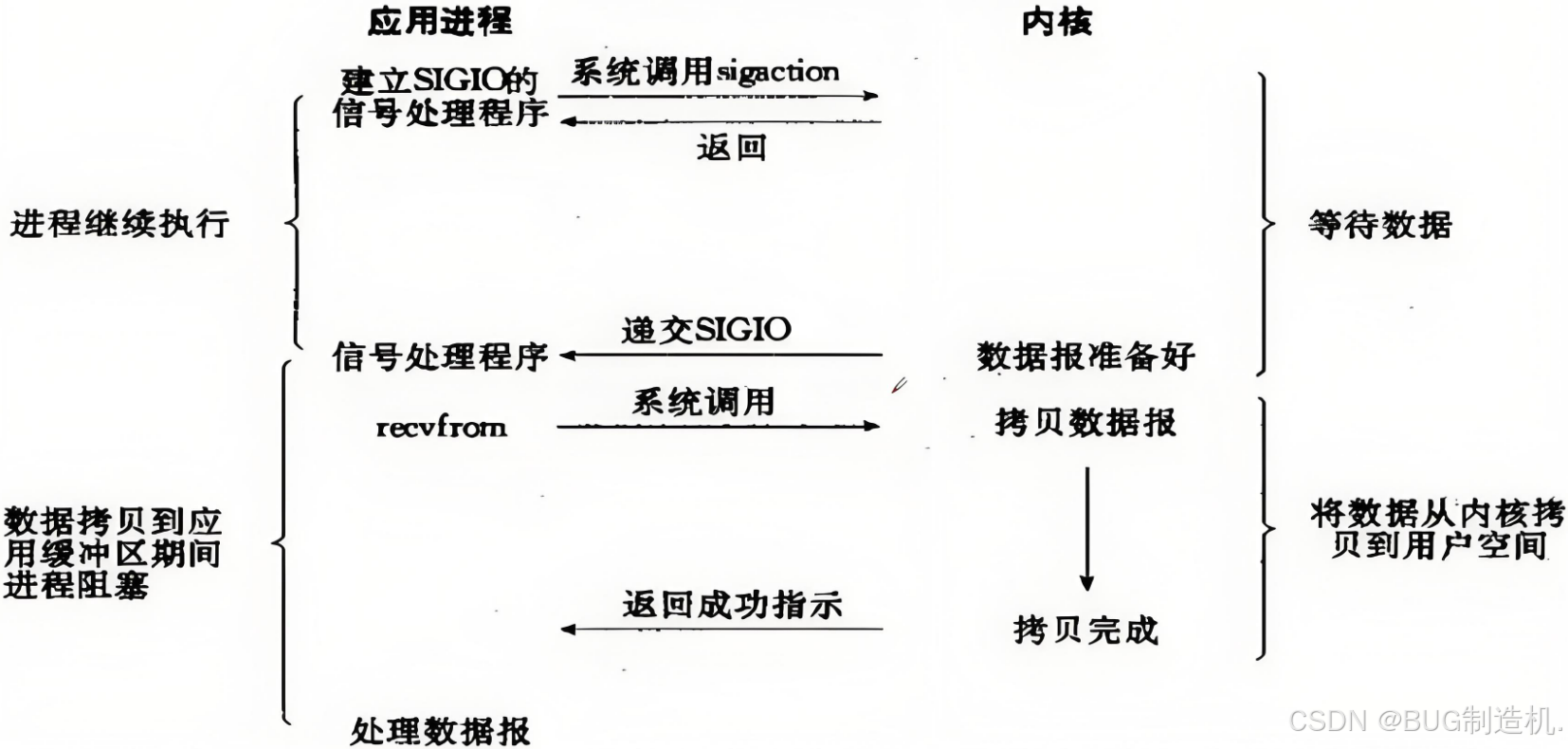
- 设置文件描述符为非阻塞模式:这是 信号驱动IO 的前提。
- 使用
fcntl的F_SETOWN操作:将文件描述符与进程ID关联,以便当文件描述符就绪时,可以向该进程发送信号。 - 使用
ioctl的FIOASYNC操作:启用文件描述符的异步通知功能。 - 设置信号处理函数:使用
sigaction来设置一个信号处理函数,该函数将在接收到信号时被调用。 - 在信号处理函数中处理
IO:当文件描述符就绪时,系统将发送信号。在信号处理函数中,你可以检查文件描述符的状态,并相应地处理IO。
6. 异步 IO
1. 定义
异步IO 是指程序在等待某个 IO 操作(如读写文件、网络通信等)完成的同时,能够继续执行其他任务,而不是一直等待 IO 操作完成。当IO操作完成时,通常会通过回调函数、事件通知或状态检查等方式来通知程序。
有些时候,可能经常会混淆异步和多路复用,现在大家只要记住一点:异步IO既不参与数据的等待,也不参与数据的拷贝!

- 调用读取函数,但是不参与过程,直接返回做自己的事
- 在内核完成IO操作后,通过信号或回调来通知调用者
钓鱼佬的例子又来啦,这个钓鱼佬比较豪横,根本不想等待,直接请了个人帮自己钓鱼,自己去干其他事儿了,只需要那个人通知自己就行了。
2. 示例
这个就简单举个例子吧:
#include <iostream>
#include <future>
#include <chrono>
#include <thread>
// 模拟一个异步 I/O 操作
int asyncIOOperation(int duration) {
std::this_thread::sleep_for(std::chrono::seconds(duration)); // 模拟耗时操作
return duration; // 返回操作持续的时间
}
int main() {
std::cout << "开始异步 I/O 操作..." << std::endl;
// 使用 std::async 启动异步操作
std::future<int> result = std::async(std::launch::async, asyncIOOperation, 3);
// 在这里可以执行其他任务
std::cout << "异步操作正在进行..." << std::endl;
// 获取异步操作的结果
std::cout << "异步操作的结果: " << result.get() << " 秒" << std::endl;
std::cout << "异步 I/O 操作完成!" << std::endl;
return 0;
}
7. 总结
在本篇文章中我们首先了解了为什么大量的 IO 操作浪费 CPU 资源?之后介绍了 五种 IO 模型,特别是着重介绍了 多路复用IO,希望大家有所收获!