五、逻辑数据库设计
1、E-R转模式
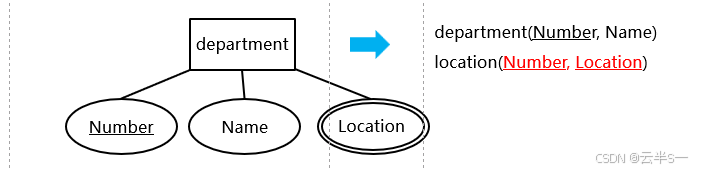
实体型的转换
转换规则
- 实体型的名称 ---->关系名
- 实体型的属性集 ---->关系的属性集(多值属性除外)
- 实体型的主键 ---->关系的主键
- 实体 ------>元组
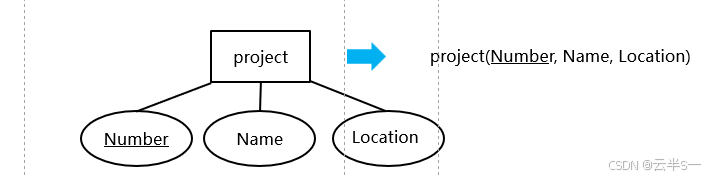 复合属性的转换
复合属性的转换
转换规则
复合属性的最低级组成成分 → 关系的属性
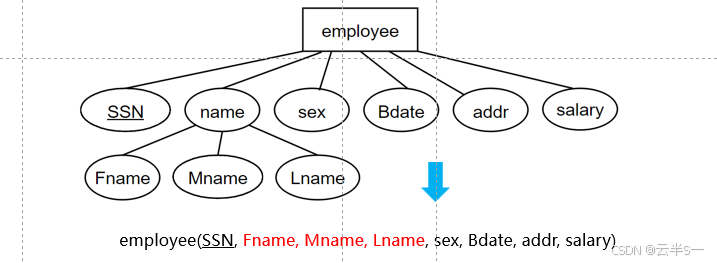
多值属性的转换
转换规则
- 实体型关系的属性集中不包含多值属性
- 多值属性 → 关系
- 将实体型的主键并入多值属性关系中
- 建立多值属性关系到实体型关系的外键约束
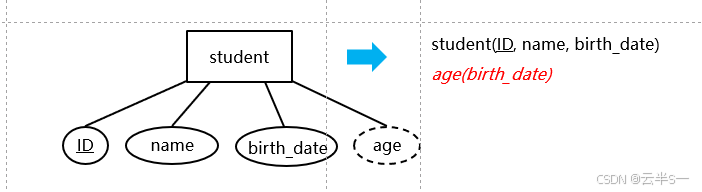
派生属性的转换
转换规则
- 实体型关系的属性集中不包含派生属性
- 派生属性 -> 自定义函数
弱实体型的转换
转换规则
- 弱实体型的名称 → 关系名
- 弱实体型的属性集 ⋃属主实体型的主键 → 关系的属性集
- 弱实体型的部分键 ⋃属主实体型的主键 → 关系的主键
- 建立弱实体型关系到属主实体型关系的外键约束
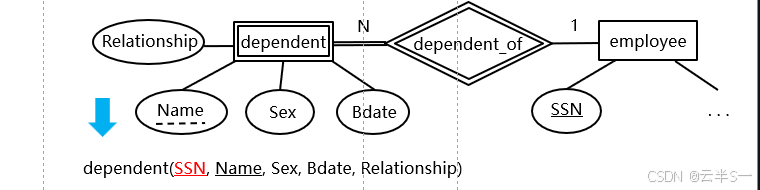
联系型的转换
M:N二元联系型的转换
转换规则
- 联系型的名称 → 关系名
- 实体型 1 的主键 ⋃实体型 2 的主键 ⋃联系型的属性集 → 关系的属性集
- 实体型 1 的主键 ⋃实体型 2 的主键 → 关系的主键
- 建立联系型关系到实体型 1 关系的外键约束
- 建立联系型关系到实体型 2 关系的外键约束
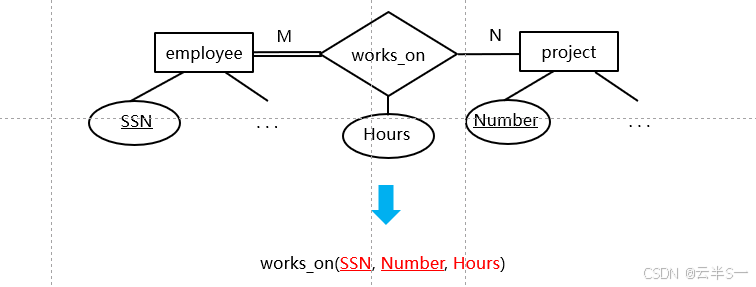
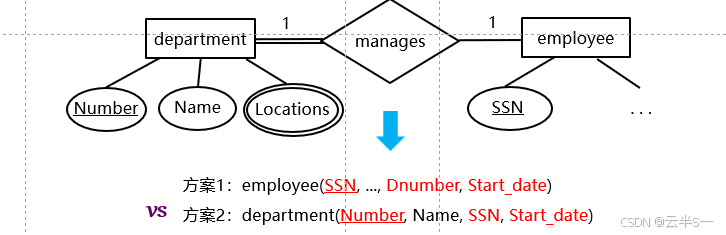
N:1二元联系型的转换
转换规则
- 设联系型中基数 N 一方的实体型(如 employee)为实体型 1
- 基数 1 一方的实体型(如 department)为实体型 2
- 将实体型 2 的主键和联系型的属性并入实体型 1 的属性集中
- 建立实体型 1 关系到实体型 2 关系的外键约束
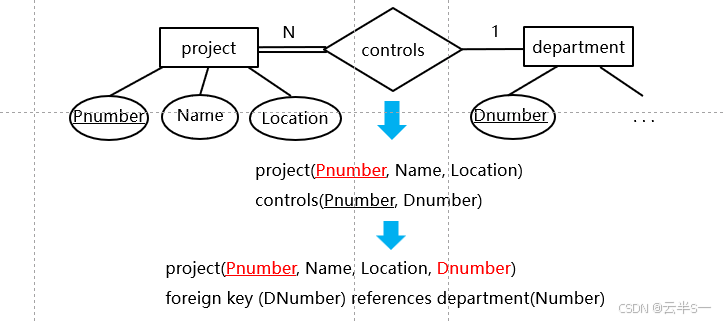
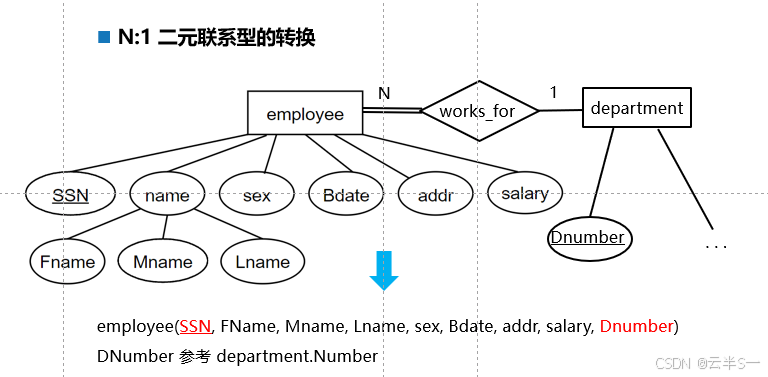
1:1二元联系型的转换
转换规则
- 与 N:1 联系的转换方法相同
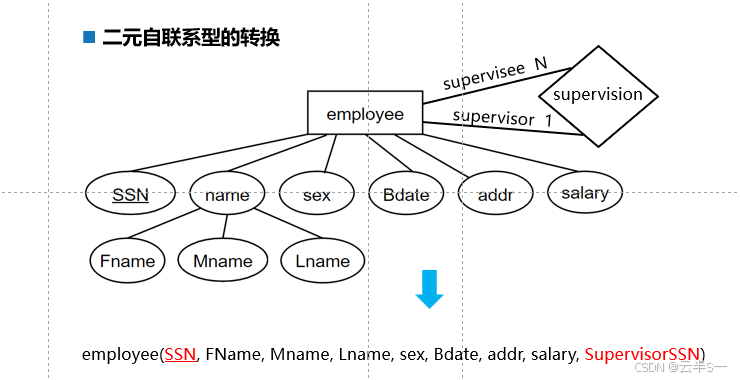
二元自联系型的转换
转换规则
- 与不同实体型间二元联系型的转换方法相同
- 对重名属性重命名
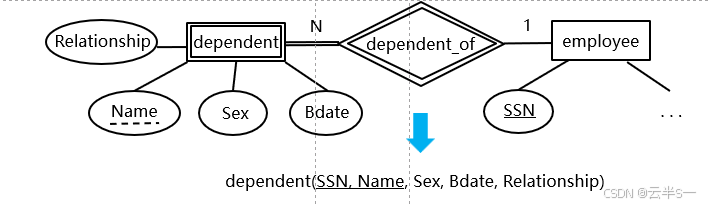
标识联系型的转换
转换规则
- 由于弱实体型转换成的关系已经包含了属主实体型的主键
- 因此标识联系型就不必转换了
评估
方法:用关系数据库规范化理论来评估
- 关系模式越规范,数据更新时产生的问题越少,因此就越“好”
- 关系模式越不规范,数据更新时产生的问题越多,因此就越“差”
注意:
- 关系数据库规范化程度不是评估关系数据库模式的唯一准则
- 某些情况下,规范的关系模式在数据库系统中的实际表现并不好
- 要“因地制宜”
数据库的规范性设计
数据库设计理论:
数据依赖理论、关系范式理论、模式分解理论
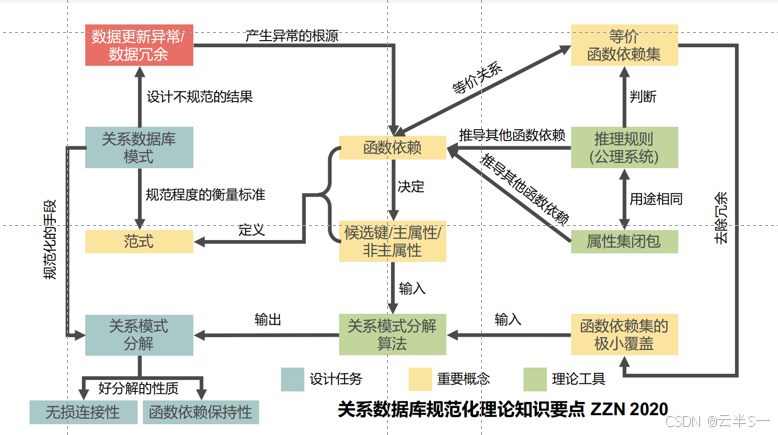
2、函数依赖
数据依赖
数据依赖(data dependency):关系的属性在语义上的依赖属性
关系模式SDC(Sno ,Sname ,Sdept ,Sdean,Cno , Grade)的属性间存在如下数据依赖:
- 一个学号(Sno)只对应一个学生姓名(Sname)
- 一名学生(Sno)只属于一个系(Sdept)
- 一个系(Sdept)只有一名系主任(Sdean)
- 一名学生(Sno)只对应一名系主任(Sdean)
- 一名学生学习一门课程(Sno , Cno )只有一个成绩(Grade)
关系模式中的不合理数据依赖会导致一系列问题
数据更新的问题:
数据插入异常:该插入的数据无法插入
数据删除异常:不该删除的数据不得不删除
数据修改繁琐:数据修改非常繁琐,容易出错
数据冗余:存在大量冗余数据
问题成因及解决办法
- 结论:关系模式 SDC(Sno, Sname, Sdept, Sdean, Cno, Grade)设计的不好
- 原因:由某些不合适的数据依赖导致的
解决办法:
- 运用关系数据库规范化理论来评估关系模式的规范化程度
- 通过关系模式分解来消除不合适的数据依赖
- 本节介绍和数据依赖有关的概念和理论
函数依赖的定义
设 R(U) 是属性集 U 上的关系模式,X⊆U, Y⊆U。对于 R(U) 的任意关系实例中的任意两个元组 t1 和 t2,如果由 t1[X] = t2[X] 可 以推出 t1[Y]= t2[Y],则称 X 函数决定 Y,或 Y 函数依赖于 X,记作 X→Y。
关系模式 SDC(Sno, Sname, Sdept, Sdean, Cno, Grade) 中的函数依赖:
- Sno→ Sname:一个学号只对应一个学生姓名
- Sno → Sdept:一名学生只属于一个系
- Sdept → Sdean:一个系只有一名系主任
- Sno → Sdean:一名学生只对应一名系主任
- (Sno, Cno) → Grade:一名学生学习一门课程只有一个成绩
续:
- 如果 Y 不函数依赖于 X,则记作 X → Y
- 如果 X → Y 且 Y → X,则记作 X ↔Y
注意:
- 函数依赖是关系模式的所有关系实例上都成立的依赖关系,不能只根据某些关系实例来确定函数依赖
- 函数依赖是语义范畴的概念,只能根据数据的语义来确定函数依赖。例如,Sname→Sno 只有在学生不同名时才成立
- 数据库设计者可以对现实世界作出强制规定。例如,规定学生不允许同名,从而使得 Sname→Sno
函数依赖的分类


候选键
设 K 为 R(U) 中的属性或属性组合,若 K → U,则称 K 为 R(U) 上的候选键。包含在任一候选键中的属性称为主属性,其他属性称为非主属性。
以SC关系为例:
- SC(Sno ,Cno ,Grade)
- {Sno ,Cno}-->SC
- {Sno, Cno} 为候选键
- Sno, Cno 为主属性
- Grade 为非主属性
Armstrong公理系统
逻辑蕴含(Definition)
设R(U.F)是一个关系模式,其属性集为U,函数依赖集为F。若在R的任意关系实例r中,函数依赖X- Y都成立(即对于r中任意两个元组t和t2’若t[X]= t[X],则t[Y]= t[Y]),则称F逻辑蕴含X→ Y,记作F
|=X→Y
设R(U,F)是一个关系模式,Armstrong公理系统包含以下3条推理规则:
- 自反律: 若Y∈X∈U,则F|=X→Y
- 增广律:若F|=X→Y,则对任意Z∈U,有F|=XZ→YZ
- 传递律: 若F|=X→Y且F|=Y→Z,則F|=X→Z
在关系数据库规范化理论中,XY代表X U Y
Armstrong公理系统是正确(sound)且完备(complete)的
- 正确性: 使用Armstrong公理系统推出的任何函数依赖一定被F逻辑蕴含
- 完备性:任何被F逻辑蕴含的函数依赖一定能够使用Armstrong公理系统推出
Armstrong公理系统的导出规则
设R(U,F)是一个关系模式
- 合并规则: 若F|=X→Y且F|=X→Z,则F|=X→ YZ
- 伪传递规则: 若F|=X→Y且F|=WY→Z,则F|=XW→Z
- 分解规则: 若F|=X→Y,则对任意Z⊆Y,有F|=X→Z
属性集的闭包
Definition:
设R(U,F)是一个关系模式,集合{A|A∈U,F|=X→A}称为X关于F的闭包(closure),
Theorem:
设R(U,F)是一个关系模式,X,Y∈U,F|=X→ Y的充要条件是

等价函数依赖集
1、函数依赖集的闭包
设R(U,F)是一个关系模式,由F逻辑蕴含的全部函数依赖的集合叫做F的闭包(closure),记作F+
2、等价函数依赖集
设F和G是关系模式R(U)上的两个函数依赖集;如果F+ = G+,则F与G等价
3、函数依赖集的覆盖
设F和G是关系模式R(U)上的两个函数依赖集,如果G+⊆F+(即G中每个函数依赖都被F逻辑蕴含),则称F覆盖G(FcoversG)
4、Theorem
函数依赖集F与G等价。当且仅当F覆盖G且G覆盖F
等价函数依赖集的判定

最小覆盖


3、关系范式
关系模式的范式
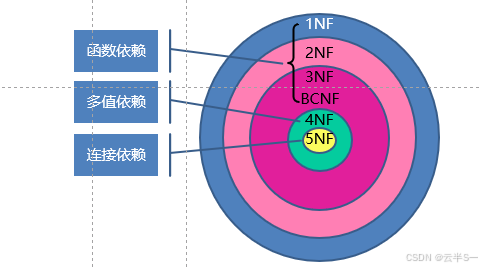
范式:在关系数据库规范化理论中,根据关系模式的规范化程度不同,把关系模式划分为若干类,称作范式(normal form)
范式的级别:
- 第一范式(1NF)
- 第二范式(2NF)
- 第三范式(3NF)
- 第四范式(4NF)
- 第五范式(5NF)
- Boyce-Codd范式(BCNF)
范式的关系:5NF ⊆ 4NF ⊆ BCNF ⊆ 3NF ⊆ 2NF ⊆ 1NF
关系模式的规范化程度越高,数据更新导致的问题越少
在函数依赖的范畴内,我们只讨论 1NF、2NF、3NF 和 BCNF
第一范式
如果关系模式 R 的每个属性都是不可分的,则称 R 为第一范式关系模式,记作R∈1NF
举例:关系模型 SDC(Sno, Sname, Sdept, Sdean, Cno, Grade)
Sno → Sname,Sno → Sdept,Sdept → Sdean,(Sno, Cno) → Grade
SDC∈1NF
(Sno, Cno) 为 SDC 的候选键,(Sno, Cno) → Sname
- 1NF 关系模式存在的问题:数据插入异常,现象:该插入的数据无法插入
- 1NF 关系模式存在的问题:数据删除异常,现象:不该删除的数据不得不删除
- 1NF 关系模式存在的问题:数据修改繁琐,现象:数据修改非常繁琐,容易出错
- 1NF 关系模式存在的问题:数据冗余,现象:存在大量冗余数据
解决方法:
- 问题原因:非主属性 Sdept 和 Sdean 部分函数依赖候选键 (Sno, Cno)
- 解决办法:把 SDC 分解为 SD(Sno, Sname, Sdept, Sdean) 和 SC(Sno, Cno, Grade)
好处:
- 解决了数据插入异常
- 解决了数据删除异常
- 简化了数据修改
- 减少了数据冗余
第二范式
如果关系模式 R∈1NF,且 R 的每个非主属性都完全函数依赖于 R 的候选键,则称 R 为第二范式关系模式,记作 R∈2NF
举例:
原因:SDC∈1NF,但 (Sno, Cno) → Sname
原因:SD∈1NF,且 Sname, Sdept, Sdean 均完全函数依赖 Sno
原因:SC∈1NF,且 Grade 完全函数依赖 (Sno, Cno)
- 2NF 关系模式存在的问题:数据插入异常,现象:该插入的数据无法插入
- 2NF 关系模式存在的问题:数据删除异常,现象:不该删除的数据不得不删除
- 2NF 关系模式存在的问题:数据修改繁琐,现象:数据修改非常繁琐,容易出错
- 2NF 关系模式存在的问题:数据冗余,现象:存在大量冗余数据
解决方法
- 问题原因:非主属性 Sdean 传递函数依赖候选键 Sno
- 解决办法:把 SD 分解为 S(Sno, Sname, Sdept) 和 D(Sdept, Sdean)
好处:
- 解决了数据插入异常
- 解决了数据删除异常
- 简化了数据修改
- 减少了数据冗余
第三范式
如果关系模式 R∈2NF,且 R 的每个非主属性都不传递函数依赖于 R 的候选键,则称 R 为第三范式关系模式,记作 R∈3NF
举例:
原因:SD∈2NF,但非主属性 Sdean 传递函数依赖与 SD 的候选键 Sno
原因:S∈2NF,且非主属性 Sname 和 Sdept 均直接函数依赖与 S 的候选键 Sno
原因:D∈2NF,且非主属性 Sdean 直接函数依赖于 D 的候选键 Sdept
- 3NF 关系模式存在的问题:数据插入异常,现象:该插入的数据无法插入
- 3NF 关系模式存在的问题:数据删除异常,现象:不该删除的数据不得不删除
- 3NF 关系模式存在的问题:数据修改繁琐,现象:数据修改非常繁琐,容易出错
- 3NF 关系模式存在的问题:数据冗余,现象:存在大量冗余数据
解决方法
- 问题原因:主属性 Cno 部分函数依赖候选键 (Sno, Tno)
- 解决办法:把 STC 分解为 TC(Tno, Cno) 和 ST(Sno, Tno)
Boyce-Codd范式
若关系模式 R(U,F)∈3NF,且 R 的任意主属性都直接完全函数依赖于 R 的候选键,则称 R 为 Boyce-Codd 范式关系模式,记作 R∈BCNF
举例:
原因:STC∈3NF,但 Tno → Cno 的左部不是候选键
原因:TC∈3NF,且 Tno → Cno 的左部是候选键
原因:ST∈3NF,候选键是 (Sno, Tno)
总结
- 1NF:属性不能再分
- 2NF:消除非主属性对候选键的部分函数依赖
- 3NF:消除非主属性对候选键的传递函数依赖
- BCNF:消除主属性对候选键的部分函数依赖和传递函数依赖
在函数依赖范畴内,BCNF 已经达到了最高的范式级别
从E-R到规范的关系模式
- 1NF:SDC(Sno, Sname, Sdept, Sdean, Cno, Grade)
- 2NF:SD(Sno, Sname, Sdept, Sdean) 和 SC(Sno, Cno, Grade)
- 3NF:S(Sno, Sname, Sdept)、D(Sdept, Sdean) 和 SC(Sno, Cno, Grade)
- BCNF:........
4、模式分解
关系模式分解
关系模式规范化是通过关系模式分解实现的
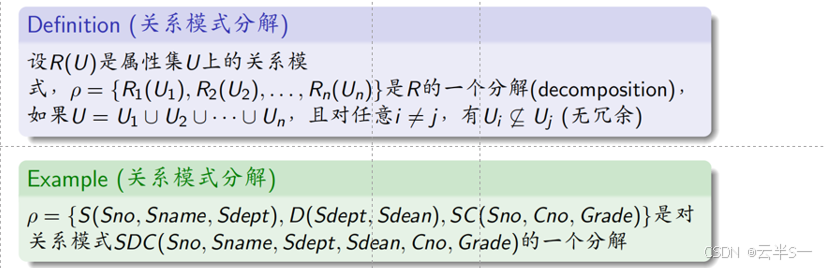
- 关系模式分解的方法是不唯一的
- 在各种分解方法中,只有能够保证分解后的关系模式与原关系模式等价的分解方法才有意义
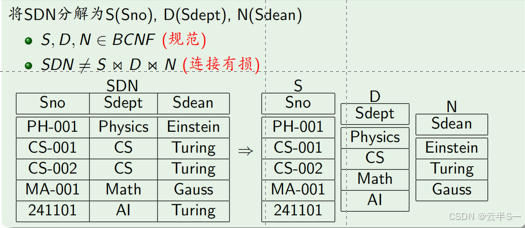
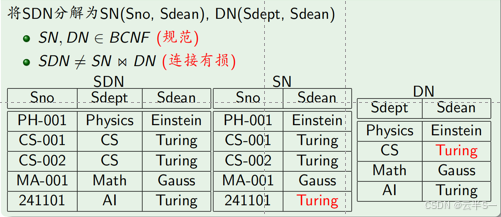
举例:SDN(Sno,Sdept,Sdean)有多种分解方法
分解方法1
分解方法2
分解方法3
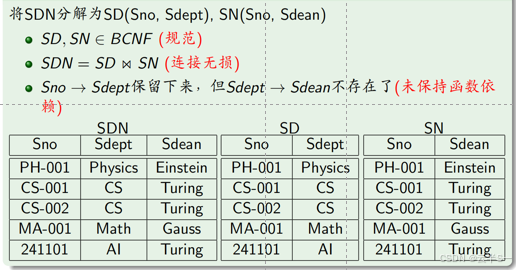
分解方法4
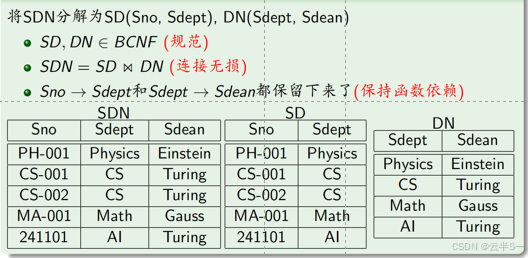
关系模式分解准则
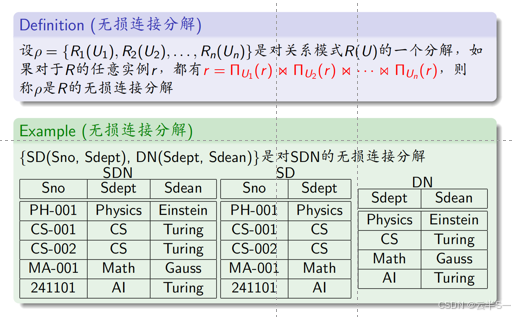
1、无损连接性
可能存在的问题
对关系模式进行无损连接分解后,可能还存在数据更新异常、数据冗余等问题
无损连接性的判定
- 目的:判定一个关系模式分解是否满足无损连接性
- 方法1:一个关系模式被分解为两个关系模式时的判定方法
-
有一个能推出来就是无损连接



- 方法2:一个关系模式被分解为3个以上关系模式时的判定方法
2、函数依赖保持

- 目的:判定一个关系模式分解是否满足函数依赖保持性
- 方法1:根据函数依赖保持性的定义进行判断
- 方法2:对于函数依赖集F中每个函数依赖X→Y,使用下面的算法判断是否
一个好的关系模式分解需要满足的特性:
- 无损连接性:确保分解后数据不丢失
- 函数依赖保持性:减轻或解决异常情况
无损连接性和函数依赖保持性是两个相互独立的准则
- 无损连接分解不一定是保持函数依赖的分解
- 保持函数依赖的分解也不一定是无损连接分解
关系模式的分解方法
- 人工分解:由数据库设计者根据关系模式上的函数依赖对关系模式进行人工分解
优点:对关系模式的语义具有深入理解,不会“过度分解”
缺点:只能对属性较少的关系模式进行分解
- 关系模式分解算法:使用算法对关系模式进行自动分解
优点:能够对具有很多属性的关系模式进行自动分解
缺点:缺少对关系模式语义的理解,可能会“过度分解”