ZooKeeper
ZooKeeper 介绍
ZooKeeper 是一个开源的分布式协调服务,ZooKeeper框架最初是在“Yahoo!"上构建的,用于以简单而稳健的方式访问他们的应用程序。
后来,Apache ZooKeeper成为Hadoop,HBase和其他分布式框架使用的有组织服务的标准。 例如,Apache HBase使用ZooKeeper跟踪
分布式数据的状态。ZooKeeper 的设计目标是将那些复杂且容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集,并以一系
列简单易用的接口提供给用户使用。
ZooKeeper 是一个典型的分布式数据一致性解决方案,分布式应用程序可以基于 ZooKeeper 实现诸如数据发布/订阅、负载均衡、命名服
务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。
Zookeeper 一个最常用的使用场景就是用于担任服务生产者和服务消费者的注册中心(提供发布订阅服务)。 服务生产者将自己提供的服务注
册到Zookeeper中心,服务的消费者在进行服务调用的时候先到Zookeeper中查找服务,获取到服务生产者的详细信息之后,再去调用服务
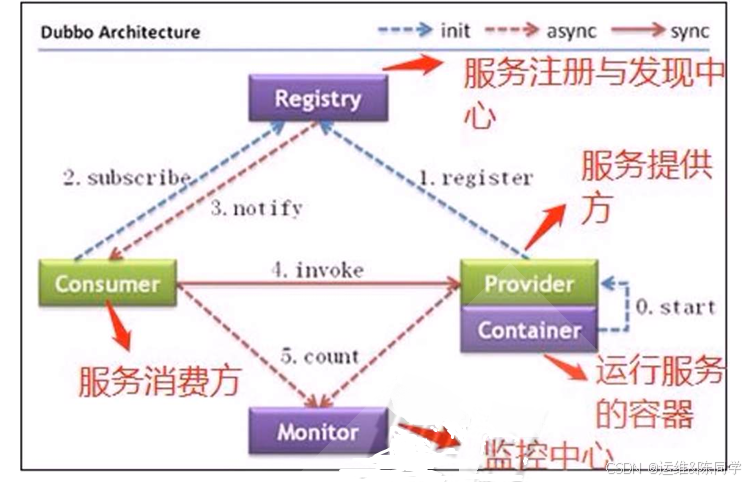
生产者的内容与数据。在 Dubbo架构中 Zookeeper 就担任了注册中心这一角色。官网:
官方文档:
ZooKeeper 工作原理
ZooKeeper 是一个分布式服务框架,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:命名服务、状态同步、配置中心、 集群管理等。
1.ZooKeeper 功能
命名服务
命名服务是分布式系统中比较常见的一类场景。命名服务是分布式系统最基本的公共服务之一。在分布式系统中,被命名的实体通常可以是 集群中的机器、提供的服务地址或远程对象等——这些我们都可以统称它们为名字(Name),其中较为常见的就是一些分布式服务框架 (如RPC、RMI)中的服务地址列表,通过使用命名服务,客户端应用能够根据指定名字来获取资源的实体、服务地址和提供者的信息等。
Zookeeper 数据模型
在 Zookeeper 中,节点分为两类
第一类是指构成Zookeeper集群的主机,称之为主机节点
第二类则是指内存中zookeeper数据模型中的数据单元,用来存储各种数据内容,称之为数据节点 ZNode。
Zookeeper内部维护了一个层次关系(树状结构)的数据模型,它的表现形式类似于Linux的文件系统,甚至操作的种类都一致。
Zookeeper数据模型中有自己的根目录(/),根目录下有多个子目录,每个子目录后面有若干个文件,由斜杠(/)进行分割的路径,就是一个ZNode,每个 ZNode上都会保存自己的数据内容和一系列属性信息.
状态同步
每个节点除了存储数据内容和 node 节点状态信息之外,还存储了已经注册的APP 的状态信息,当有些节点或APP 不可用,就将当前状态同
步给其他服务。
配置中心
现在我们大多数应用都是采用的是分布式开发的应用,搭建到不同的服务器上,我们的配置文件,同一个应用程序的配置文件一样,还有就是多个程序存在相同的配置,当我们配置文件中有个配置属性需要改变,需要改变每个程序的配置属性,这样会很麻烦的去修改配置,那么可用使用ZooKeeper 来实现配置中心
ZooKeeper 采用的是推拉相结合的方式:客户端向服务端注册自己需要关注的节点,一旦该节点的数据发生变更,那么服务端就会向相应的客户端发送Watcher事件通知,客户端接收到这个消息通知后,需要主动到服务端获取最新的数据。
Apollo(阿波罗)是携程框架部门研发的开源配置管理中心,此应用比较流行
2. ZooKeeper 服务流程
1. 生产者启动
2. 生产者注册至zookeeper
3. 消费者启动并订阅频道
4. zookeeper 通知消费者事件
5. 消费者调用生产者
6. 监控中心负责统计和监控服务状态