Kafka
Kafka 介绍
阿里云消息队列 云消息队列 ApsaraMQ
 https://www.aliyun.com/product/ons?spm=5176.234368.h2v3icoap.427.2620db25lcHi1Q&aly_as=Tz_Lue_o
https://www.aliyun.com/product/ons?spm=5176.234368.h2v3icoap.427.2620db25lcHi1Q&aly_as=Tz_Lue_oKafka 被称为下一代分布式消息系统,由 Scala 和 Java编写,是非营利性组织ASF(Apache Software Foundation)基金会中的一个开源项 目,比如:HTTP Server、Tomcat、Hadoop、ActiveMQ等开源软件都属于 Apache基金会的开源软件,类似的消息系统还有RabbitMQ、 ActiveMQ、ZeroMQ。 Kafka用于构建实时数据管道和流应用程序。 它具有水平可伸缩性,容错性,快速性,可在数千家组织中同时投入生产协同工作。
官网: Apache Kafka
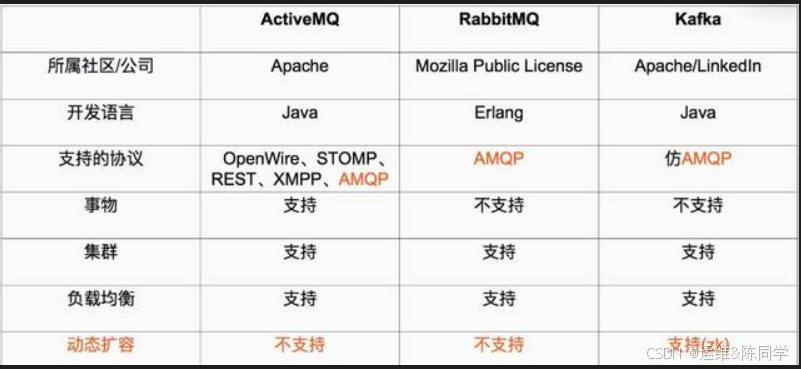
常用消息队列对比
kafka 最主要的优势是其具备分布式功能、并可以结合 zookeeper 可以实现动态扩容,Kafka 是一种高吞吐量的分布式发布订阅消息系统。
Kafka 特点和优势
特点
1、分布式: 多机实现,不允许单机
2、分区: 一个消息.可以拆分出多个,分别存储在多个位置
3、多副本: 防止信息丢失,可以多来几个备份
4、多订阅者: 可以有很多应用连接kafka
5、 Zookeeper: 早期版本的Kafka依赖于zookeeper, 2021年4月19日Kafka 2.8.0正式发布,此版本包括了很多重要改动,最主要的是
kafka通过自我管理的仲裁来替代ZooKeeper,即Kafka将不再需要ZooKeeper!
优势
1、Kafka 通过 O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以 TB 级别以上的消息存储也能够保持长时间的稳定性能。
2、高吞吐量:即使是非常普通的硬件Kafka也可以支持每秒数百万的消息。支持通过Kafka 服务器分区消息。
3、分布式: Kafka 基于分布式集群实现高可用的容错机制,可以实现自动的故障转移
4、顺序保证:在大多数使用场景下,数据处理的顺序都很重要。大部分消息队列本来就是排序的,并且能保证数据会按照特定的顺序来处理。 Kafka保证一个Partiton内的消息的有序性(分区间数据是无序的,如果对数据的顺序有要求,应将在创建主题时将分区数
partitions设置为1)
5、支持 Hadoop 并行数据加载
6、通常用于大数据场合,传递单条消息比较大,而Rabbitmq 消息主要是传输业务的指令数据,单条数据较小
随机和顺序IO比较
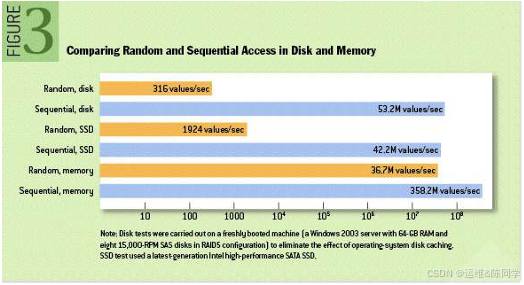
O(1)就是最低的时空复杂度,也就是耗时/耗空间与输入数据大小无关,无论输入数据增大多少倍,耗时/耗空间都不变,哈希算法就是典型的O(1)时间复杂度,无论数据规模多大,都可以在一次计算后找到目标
Kafka 角色和流程
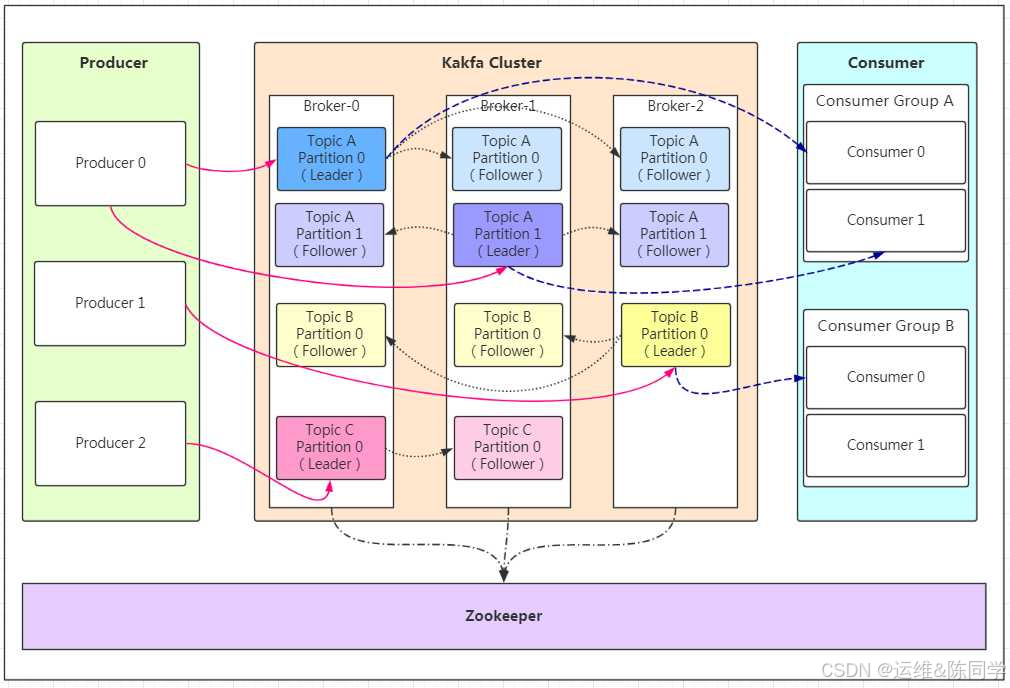
Kafka 角色
Producer:Producer即生产者,消息的产生者,是消息的入口。负责发布消息到Kafka broker。
Consumer:消费者,用于消费消息,即处理消息
Broker:Broker是kafka实例,每个服务器上可以有一个或多个kafka的实例,假设每个broker对应一台服务器。每个kafka集群内的broker都有一个不重复的编号,如: broker-0、broker-1等……
Topic :消息的主题,可以理解为消息的分类,一个Topic相当于数据库中的一张表,一条消息相当于关系数据库的一条记录,一个Topic或者相当于Redis中列表类型的一个Key,一条消息即为列表中的一个元素。kafka的数据就保存在topic。在每个broker上都可以创建多个topic。物理上不同 topic 的消息分开存储在不同的文件夹,逻辑上一个 topic的消息虽然保存于一个或多个broker 上, 但用户只需指定消息的topic即可生产或消费数据而不必关心数据存于何处,topic 在逻辑上对record(记录、日志)进行分组保存,消费者需要订阅相应的topic 才能消费topic中的消息。
Consumer group: 每个consumer 属于一个特定的consumer group(可为每个consumer 指定 group name,若不指定 group name 则属于默认的group),同一topic的一条消息只能被同一个consumer group 内的一个consumer 消费,类似于一对一的单播机制,但多个consumer group 可同时消费这一消息,类似于一对多的多播机制
Partition :是物理上的概念,每个topic 分割为一个或多个partition,即一个topic切分为多份.创建 topic时可指定 partition 数量, partition的表现形式就是一个一个的文件夹,该文件夹下存储该partition的数据和索引文件,分区的作用还可以实现负载均衡,提高kafka的吞吐量。同一个topic在不同的分区的数据是不重复的,一般Partition数不要超过节点数,注意同一个partition数据是有顺序的,但不同的partition则是无序的。
Replication: 同样数据的副本,包括leader和follower的副本数,基本于数据安全,建议至少2个,是Kafka的高可靠性的保障,和ES的副本有所不同,Kafka中的副本数包括主分片数,而ES中的副本数不包括主分片数
为了实现数据的高可用,比如将分区 0 的数据分散到不同的kafka 节点,每一个分区都有一个 broker 作为 Leader 和一个 broker 作为Follower,类似于ES中的主分片和副本分片,
假设分区为 3, 即分三个分区0-2,副本为3,即每个分区都有一个 leader,再加两个follower,分区 0 的leader为服务器A,则服务器 B 和服务器 C 为 A 的follower,而分区 1 的leader为服务器B,则服务器 A 和C 为服务器B 的follower,而分区 2 的leader 为C,则服务器A 和 B 为C 的follower。
AR: Assigned Replicas,分区中的所有副本的统称,包括leader和 follower,AR= lSR+ OSR lSR:ln Sync Replicas,所有与leader副本保持同步的副本 follower和leader本身组成的集合,包括leader和 follower,是AR的子集 OSR:out-of-Sync Replied,所有与leader副本同步不能同步的 follower的集合,是AR的子集
分区和副本的优势:
-
实现存储空间的横向扩容,即将多个kafka服务器的空间组合利用
-
提升性能,多服务器并行读写
-
实现高可用,每个分区都有一个主分区即 leader 分布在不同的kafka 服务器,并且有对应follower 分布在和leader不同的服务器上
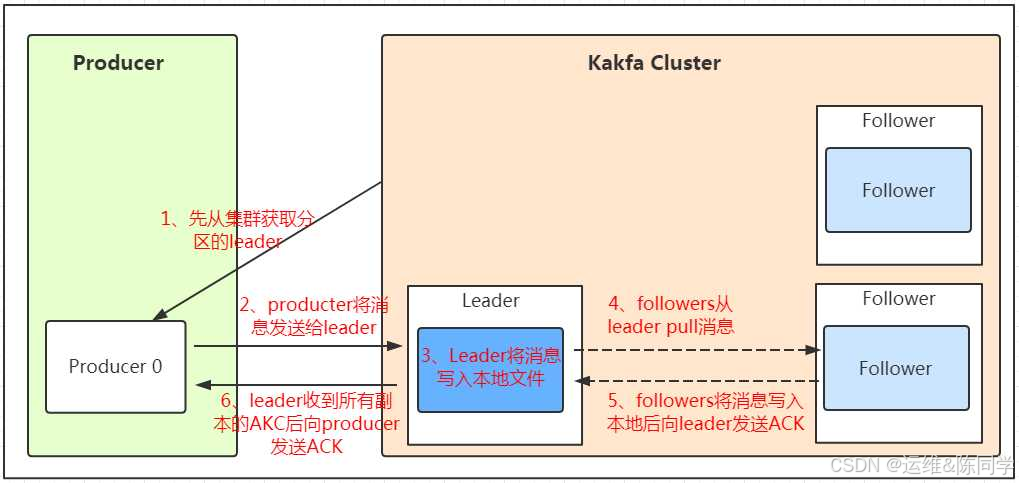
Kafka 写入消息的流程
我们看上面的架构图中,producer就是生产者,是数据的入口。注意看图中的红色箭头,Producer在写入数据的时候永远的找leader,不会直接将数据写入follower!那leader怎么找呢?写入的流程又是什么样的呢?