查看下面的我上期的文章选择好并下载合适自己的Hbase版本
下面开始完全分布式的Hbase安装
注:1、文档中hadoop101 hadoop102 hadoop103为三台虚拟机的主机名,进行安装配置时,要改成自己电脑的主机名或IP地址
2.教程中涉及到路径的,也要根据自己电脑的实际路径进行修改,不能一味的复制哦
开始之前必须确保你的zookeeper和Hadoop已经成功的安装配置好了再开始下面的步骤
本次用到的Hbase为2.4.6版本,Hadoop为3.1.3版本,JDK为JDK8
每台虚拟机或服务器都要进行Hbase的配置
先将安装包上传到主节点虚拟机,我的主节点是hadoop101,然后配置好后在进行集体分发
解压到自己的安装目录
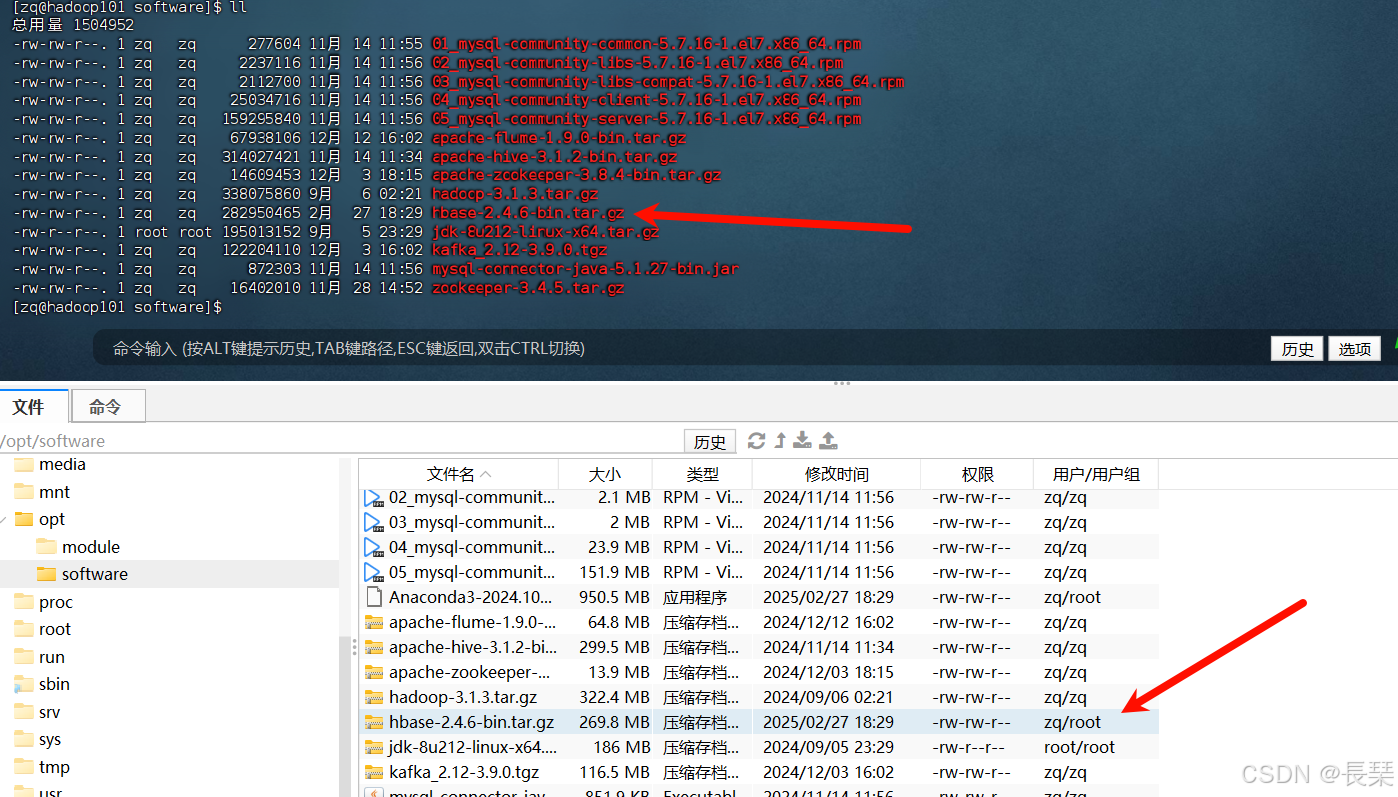
去到存放安装包的位置
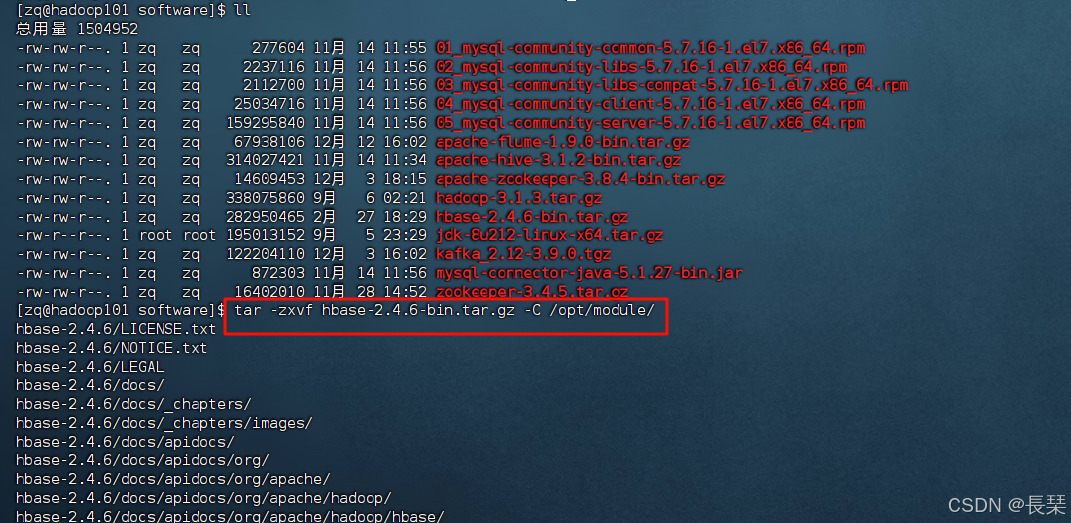
根据自己的软件安装位置解压,/opt/module/是我的安装路径,解压命令:tar -zxvf hbase-2.4.6-bin.tar.gz -C /opt/module/
配置环境变量
命令:sudo vim /etc/profile
文件最后添加如下内容:
#HBASE_HOME
export HBASE_HOME=/opt/module/hbase-2.4.6
export PATH=$PATH:$HBASE_HOME/bin
让环境变量生效命令:source /etc/profile
这里以分发到hadoop102为例,还需要分发到其它机子,命令:sudo scp -r /etc/profile zq@hadoop102:/etc/profile
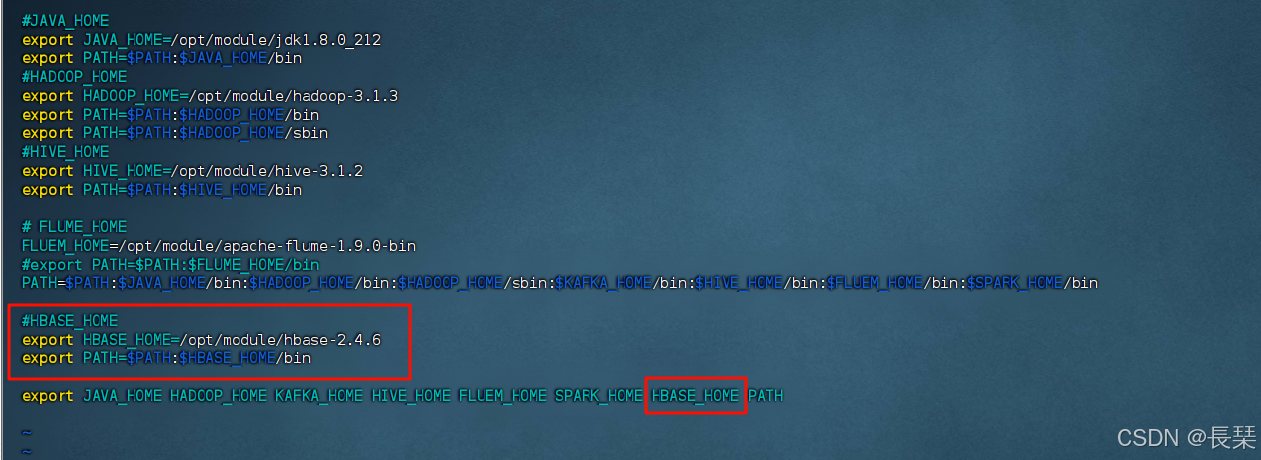
另一种环境变量配置方式
就是在profile.d下创建了一个属于自己的环境变量文件,就比如我的,my_env.sh是我自己创建的一个环境变量管理文件
命令:sudo vim /etc/profile.d/my_env.sh
将其添加到其中
使环境变量生效:source /etc/profile.d/my_env.sh
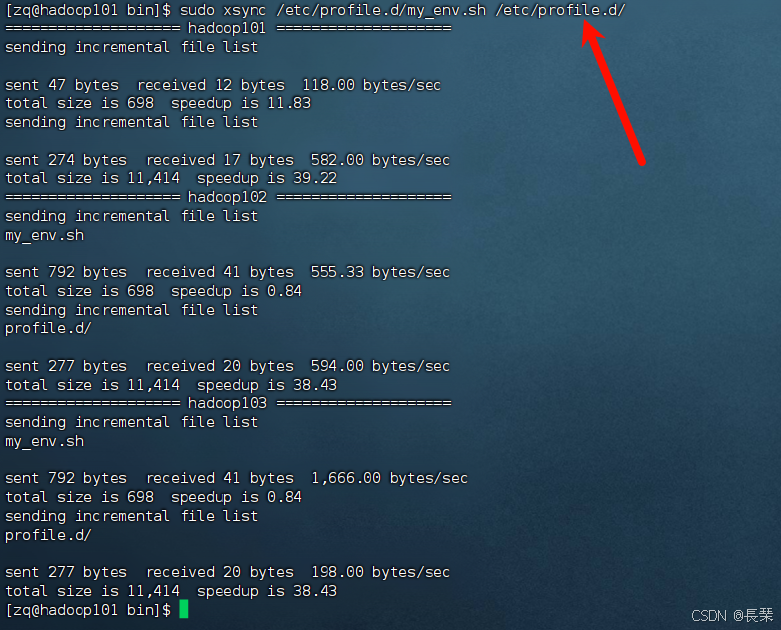
再分发到其它机子,我就用自己的分发脚本分发了,往期有脚本编写,链接如下,查看qsync集群分发脚本处
命令:sudo xsync /etc/profile.d/my_env.sh /etc/profile.d/
修改hbase-env.sh 内容,文件在Hbase安装目录下的conf文件夹下
去到文件夹:cd /opt/module/hbase-2.4.6/conf/
编辑文件命令:vim hbase-env.sh
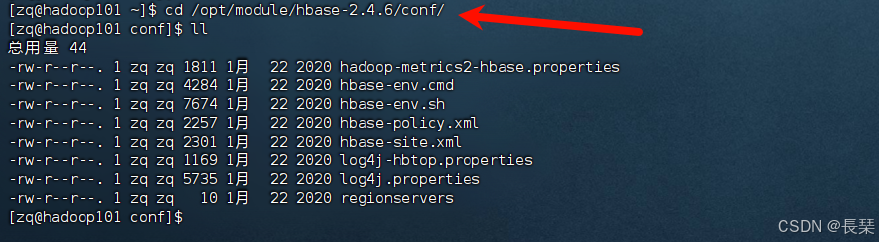
在文件最后添加如下内容保存退出:
export JAVA_HOME=/opt/module/jdk1.8.0_212
export HBASE_MANAGES_ZK=false
记得将JDK的路径改为自己的
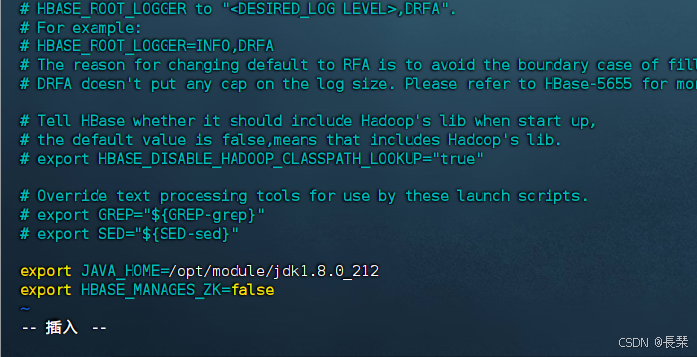
修改hbase-site.xml 内容
编辑文件命令:vim hbase-site.xml
把下面参数加configuration标签内保存并退出,原来有的内容就不要删了
要配分布式的话第一个要改为true
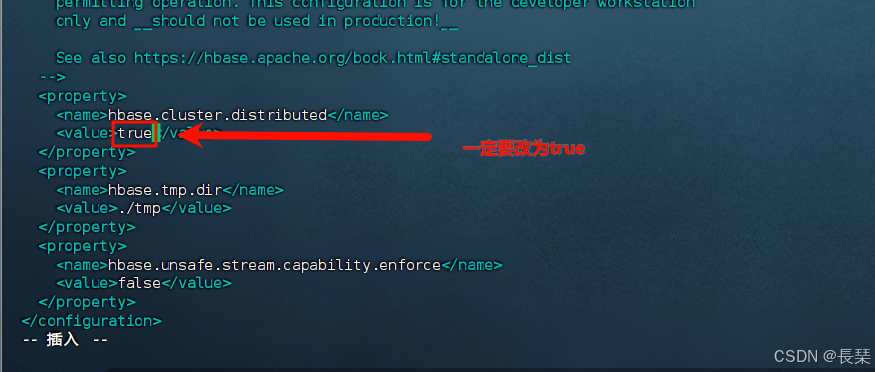
<!-- 8020或9000要与hadoop的core-site.xml fs.defaultFS的端口一致 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop101:8020/HBase</value>
</property>
<property>
<name>hbase.master.port</name>
<value>16000</value>
</property>
<!-- 在分布式的情况下一定要设置,不然容易出现Hmaster起不来的情况 -->
<property> <name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
<property>
<name>hbase.wal.provider</name>
<value>filesystem</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/module/zookeeper-3.8.4/zkData</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop101,hadoop102,hadoop103</value>
</property>
还要注意其中的hbase.rootdir下的端口要与Hadoop里配置的一样,如下图所示,以及注意改zookeeper的路径
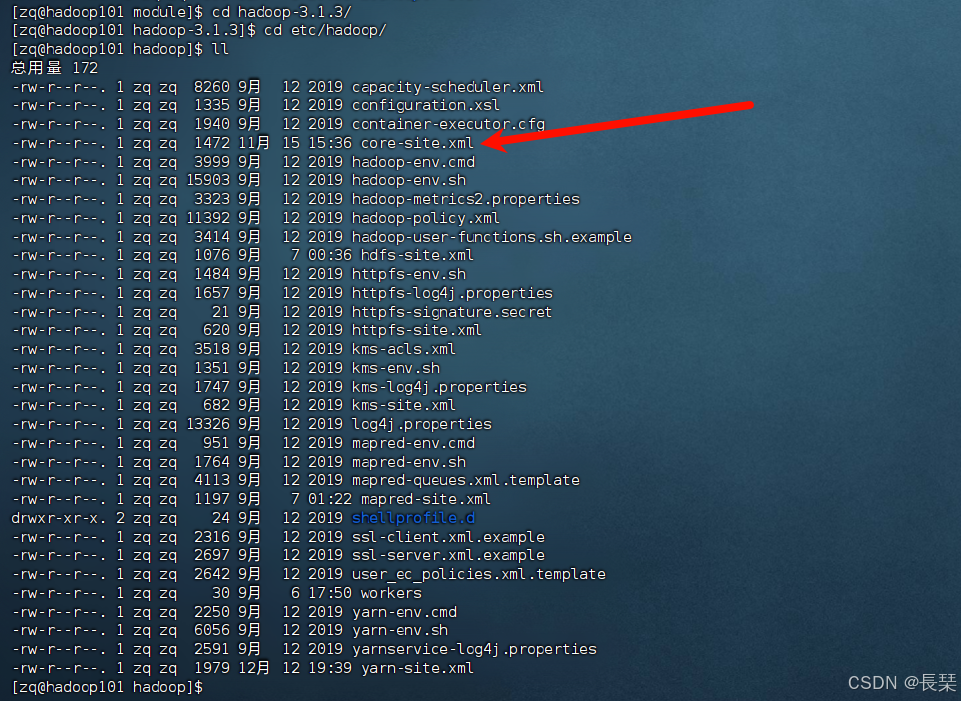
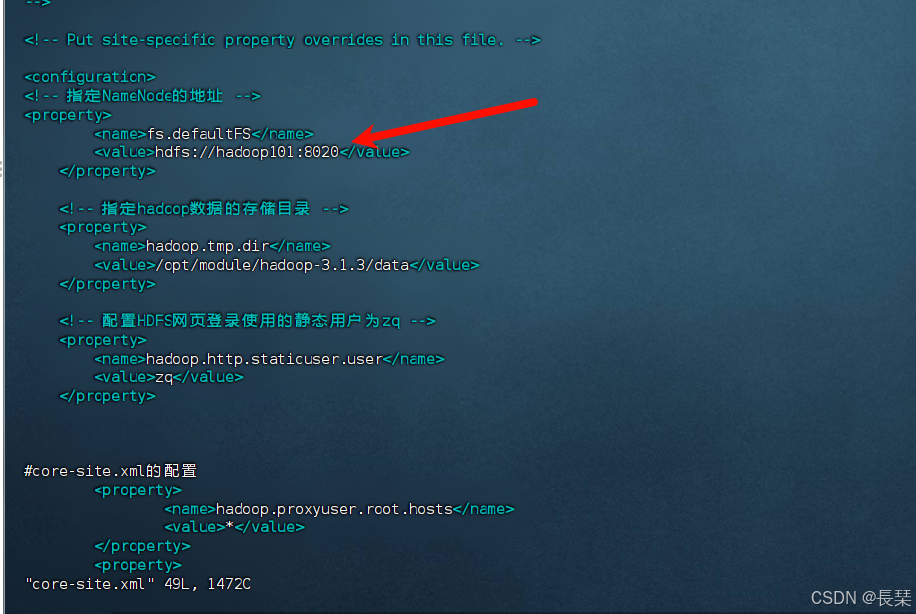
修改regionservers
命令:vim regionservers
删除原来的localhost

把所有的主机IP填写进去,如果是配置IP映射的话填所有的IP对应的名称也行,前后不要有空格,最好手动敲,然后保存退出

软连接hadoop 配置文件到HBase
命令:ln -s /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml /opt/module/hbase-2.4.6/conf/core-site.xml
命令:ln -s /opt/module/hadoop-3.1.3/etc/hadoop/hdfs-site.xml /opt/module/hbase-2.4.6/conf/hdfs-site.xml
根据自己的Hbase安装路径和Hadoop的安装路径作修改
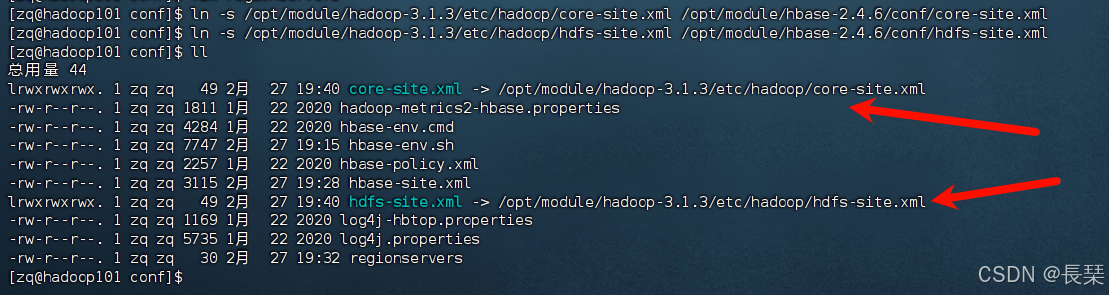
分发到其它节点
使用scp,以分发到hadoop102为例
命令:scp -r /opt/module/hbase-2.4.6/ zq@hadoop102:/opt/module/
我使用自己编写的脚本
命令:xsync /opt/module/hbase-2.4.6/ /opt/module/
启动Hbase之前记得先启动Hadoop和zookeeper
启动方式1:
逐个启动
命令:/opt/module/hbase-2.4.6/bin/hbase-daemon.sh start master
命令:/opt/module/hbase-2.4.6/bin/hbase-daemon.sh start regionserver
对应的停止服务,将start改为stop
启动方式2:
命令:/opt/module/hbase-2.4.6/bin/start-hbase.sh
对应的停止服务命令将start改为stop
启动后主节点有三个进程,其余机子各有两个进程,Q开头的是zookeeper进程
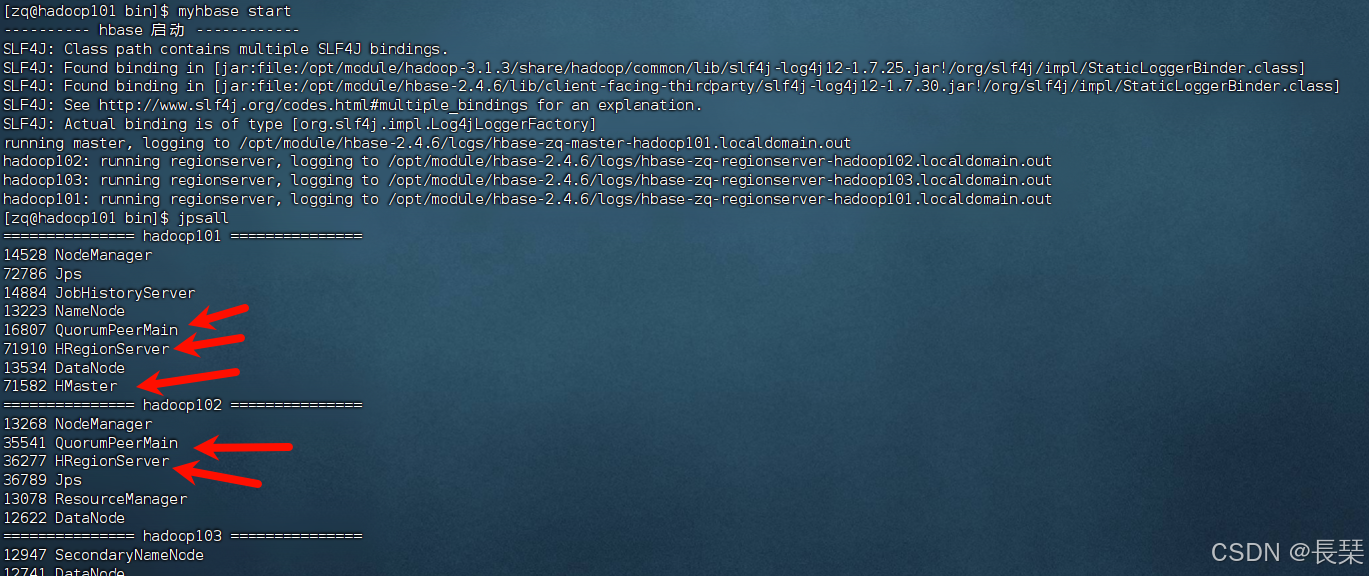
Hbase启动脚本
回到根目录:cd ~
进入bin目录,这个目录是我存放脚本的地方: cd bin/
创建脚本文件:vim myhbase
添加下面的内容保存退出,注意修改必要的地方,如Hbase的安装路径,脚本的位置根据你自己的需求存放即可,但注意要将你存放的位置加入变量里
给执行权限:chmod +x myhbase

#!/bin/bash
case $1 in
"start"){
for i in hadoop101
do
echo ---------- hbase 启动 ------------
ssh $i "/opt/module/hbase-2.4.6/bin/start-hbase.sh"
done
};;
"stop"){
for i in hadoop101
do
echo ---------- hbase 停止 ------------
ssh $i "/opt/module/hbase-2.4.6/bin/stop-hbase.sh"
done
};;
*)
echo "Input Args Error..."
echo "$0 [start|stop]..."
;;
esac
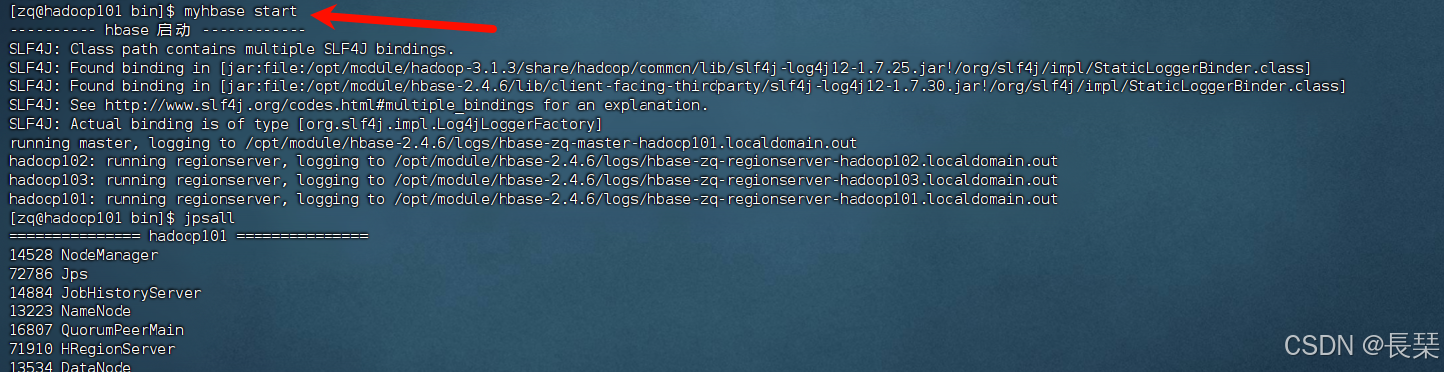
用myhbase start启动
用myhbase stop关闭
启动成功后,可以通过“host:port”的方式来访问HBase 管理页面,例如:
http://hadoop101:16010或192.168.89.101:16010
根据自己的IP修改

查看版本命令: hbase version

输入hbase shell 进入hbase

输入exit退出

关闭服务顺序,建议先关闭hbase,在关闭zookeeper和hadoop
到此教程完毕!!!