1、综述
今天来看一篇非常有名的论文,名字叫做《High-Resolution Image Synthesis with Latent Diffusion Models》,这篇论文被当年的CVPR收录,是文生图领域开源的最有名的算法stable diffusion的原理。
在这篇论文之前,所有的DM(diffusion model)模型都是在图片像素级别上进行操作,这使得计算开销非常大,很难大规模商用。这篇文章解决的问题就是把计算放在了网络隐层中,使得计算开销大幅度减少,使得最终的商用成为可能。
并且作者引入了条件控制机制,这就使得用文字控制图像生成或者其他类似的任务成为可能。后面著名的开源项目stable diffusion就是基于此构建的。
2、Related Work
老规矩,这部分就不详细说了,感兴趣的朋友自己看一下原文。
3、Method
整体算法的原理其实非常清晰,原理图如下所示:
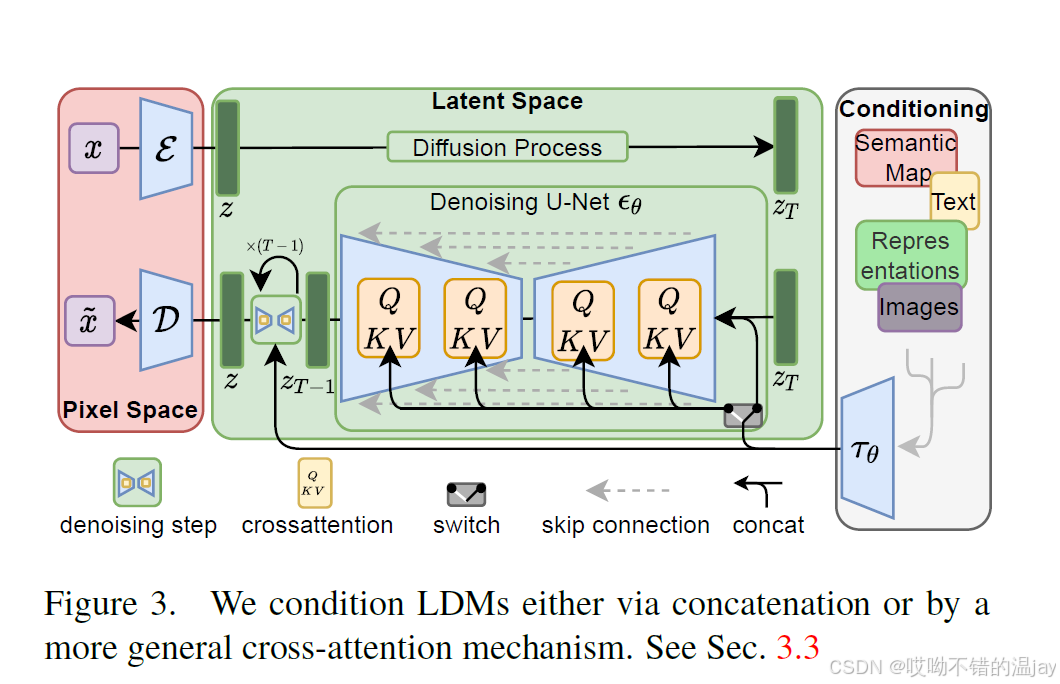
具体由以下三个部分组成:
3.1 Perceptual Image Compression
上图最左边红色的框,作者称为perceptual compression model 感知压缩模型,是基于《Taming transformers for high-resolution image synthesis》这篇论文,也就是VQ-GAN。VQ-GAN在VQVAE的基础上做了一些改进,而VQVAE最大的贡献是提出了codebook这个概念,也就是把特征向量变为离散的,这里就不具体展开说了。
回到本论文,这里的自编码模型是用感知损失和patch-based的对抗损失训练出来的。具体看图里的红框,给定一张RGB图片x(形状为H*W*3),输入encoder E,得到特征向量z,使用decoder D还原回图片,能使得:

x与还原的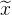
与此同时,作者还使用了KL-reg和VQ-reg这两种正则化方式来避免潜空间的方差过大。其中KL-reg相当于在潜空间上施加了KL惩罚,使得得到的特征的分布接近正态分布。VQ-reg则是使用了一个向量量化层(vector quantization layer),向量量化层将特征归一化为codebook中最近的那个特征。
3.2 Latent Diffusion Models
接下来我们来看上图中间的这个框,这里就是一个diffusion model(DM,扩散模型),只不过是在latent也就是潜空间中。
扩散模型的原理说来也简单,就是不断地在一个图像中加入高斯噪声,而模型就是学习这个去噪的过程。也就是说扩散模型可以理解为一个时序去噪自编码器。
对于一个正常的DM来说,假设时间步t = 1 . . . T,并且t在{1, . . . , T}上均匀采样,则损失函数为:

但是在这篇论文中,由于是在潜空间中训练,也就是预测zT上添加的噪声,则损失函数变为:
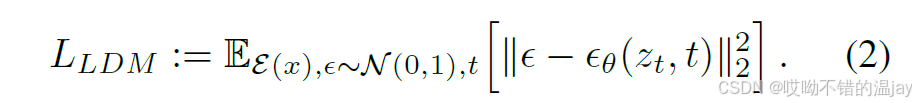
其中的神经网络
上图的中间绿色部分就是在潜变量空间的扩散模型,其中上半部分是加噪过程,用于将特征 z 加噪为 zT 。下半部分是去噪过程,去噪的核心结构就是这个由交叉注意力(Cross Attention)组成的U-Net,用于将 zT 还原为 z 。由于左边红框里的自编码器是训练好的(fixed),所以只需要前向执行一次就能得到z或是
3.3 Conditioning Mechanisms
作者在这里引入了条件控制机制,这也是为什么文字能控制图像的生成,当然不止文字可以作为条件,作者在这里自己举了一些例子:such as text [66], semantic maps [32, 59] or other image-to-image translation tasks。
看上图最右边这个框,文字等条件信息y预先编码成特征向量,并将其通过cross-attention送入到扩散模型的去噪过程中。定义τθ为一个特征提取器,用来提取y的信息成为一个特征向量,例如可以用预训练的BERT转换文本,使用CLIP转换图像等。接着我们使用交叉注意力将条件融入到U-Net的中间层:

这里大概说一下cross-attention,这个注意力机制由QKV矩阵(Query、Key、Value)控制,由于是使用文字控制图片,所以K和V矩阵与y相关,而Q矩阵与z相关。具体细节建议大家详细去了解一下。cross-attention模块相当于在U-Net的降采样部分和上采样部分的残差块之后都添加了一个交叉注意力。
最终加入了条件的LDM损失为:
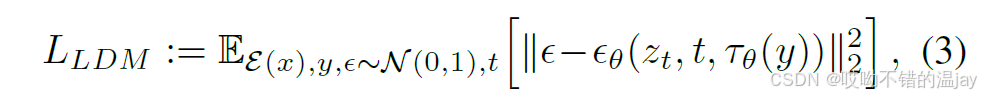
上面这三点就构成了这篇论文的核心创新点,后面的实验部分如果大家有兴趣的可以自己去看看。