行人重识别的训练需要收集大量的人体数据到一个中心服务器上,这些数据包含了个人敏感信息,因此会造成隐私泄露问题。联邦学习是一种保护隐私的分布式训练方法,可以应用到行人重识别上,以解决这个问题。但是在现实场景中,将联邦学习应用到行人重识别上因为数据异构性,会导致精度下降和收敛的问题。
数据异构性:数据非独立分布 (non-IID) 和 各端数据量不同。
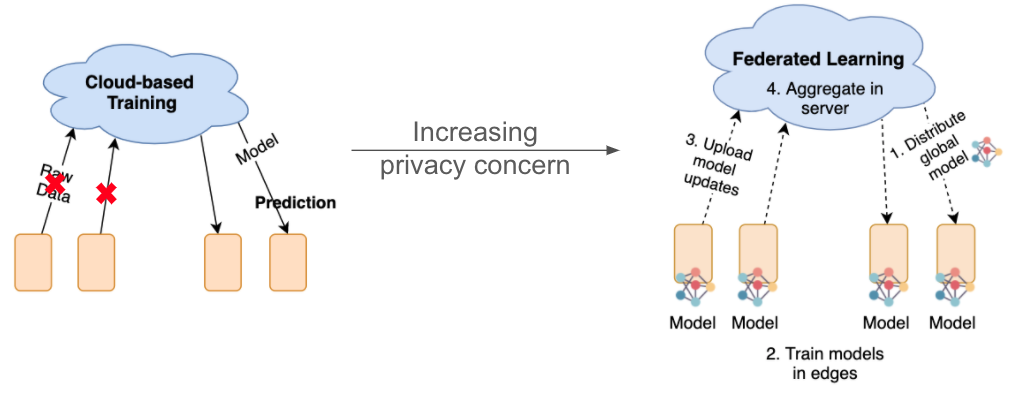
这是篇来自 ACMMM20 Oral 的论文,主要通过构建一个 benchmark,并基于 benchmark 结果的深入分析,提出两个优化方法,提升现实场景下联邦学习在行人重识别上碰到的数据异构性问题。

论文地址:Performance Optimization for Federated Person Re-identification via Benchmark Analysis
开源代码:https://github.com/cap-ntu/FedReID
本文主要对这篇文章的这三个方面内容做简要介绍:
- Benchmark: 包括数据集、新的算法、场景等