redis问题
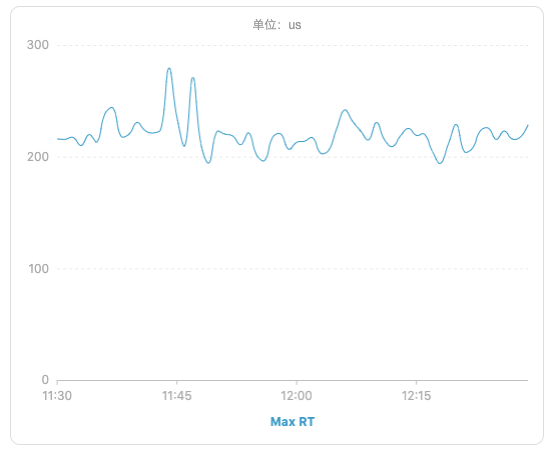
在最近公司内部使用redis的时候,在部分场景中发现redis经常会间歇性的抖动,具体表现为在短时间内redis rt上涨明显,RedisCommandTimeoutException异常陡增,如下图:
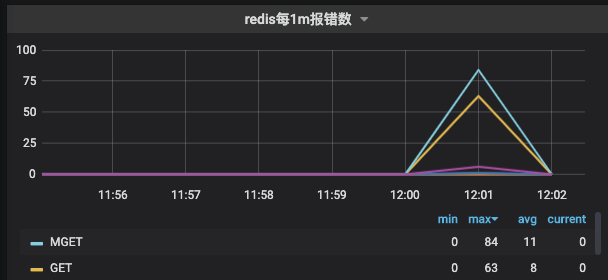
监控面板是按照分钟级别进行统计,所以rt上涨看起来不是很明显。
这种情况肯定不太正常,并且在近期出现的频率有上升趋势。
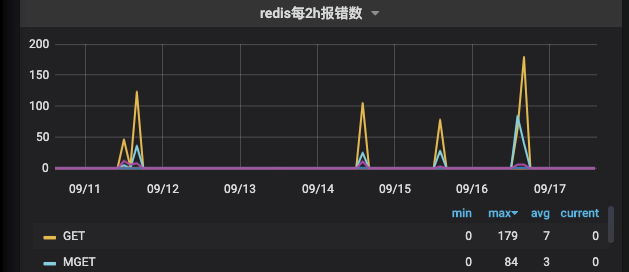
定位原因
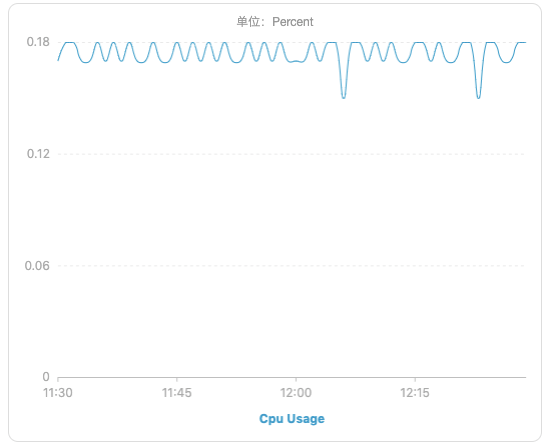
遇到这种问题,首先会想到是不是redis本身抖动造成的,看表象其实很像,无规律,间歇性,影响时间很短,所以第一时间找了DBA确认当时是不是redis实例发生了问题,或者网络出现了抖动,同时也去dms redis的监控面板上看下运行指标是否正常。很遗憾,得到的恢复是服务抖动这段时间内,redis运行情况正常,网络状况也无任何异常,而且从监控面板上看,redis 运行状况非常好,cpu负载不高,io负载也不高,内核运行rt也都正常,无明显波动。(下图选择了redis集群中的一个节点实例,16个节点的状况基本一致)
redis cpu:
redis io:
redis maxRT
到此,中间件本身的原因基本上是可以排除的了。那么,只能是使用姿势的问题了。使用姿势这块可能造成的影响,首先要定位是不是有hot key 还有big key,如果一个big key 又同时是hot key,那么极有可能在流量尖刺的同时造成这种现象。
先去阿里云redis监控面板上看hot key统计
发现一周内并无热点key,也没有大key,那么很显然,缓存内容本身还是比较合理的。这就有点头疼了,redis本身,以及缓存内容都没什么问题,那只能把目光放到代码中了,由代码异常来逆推原因。
天眼监控上,发现很多RedisCommandTimeoutException异常,那么先采样看下产生异常的请求上下文
异常接口是:会场商品流批量算价服务
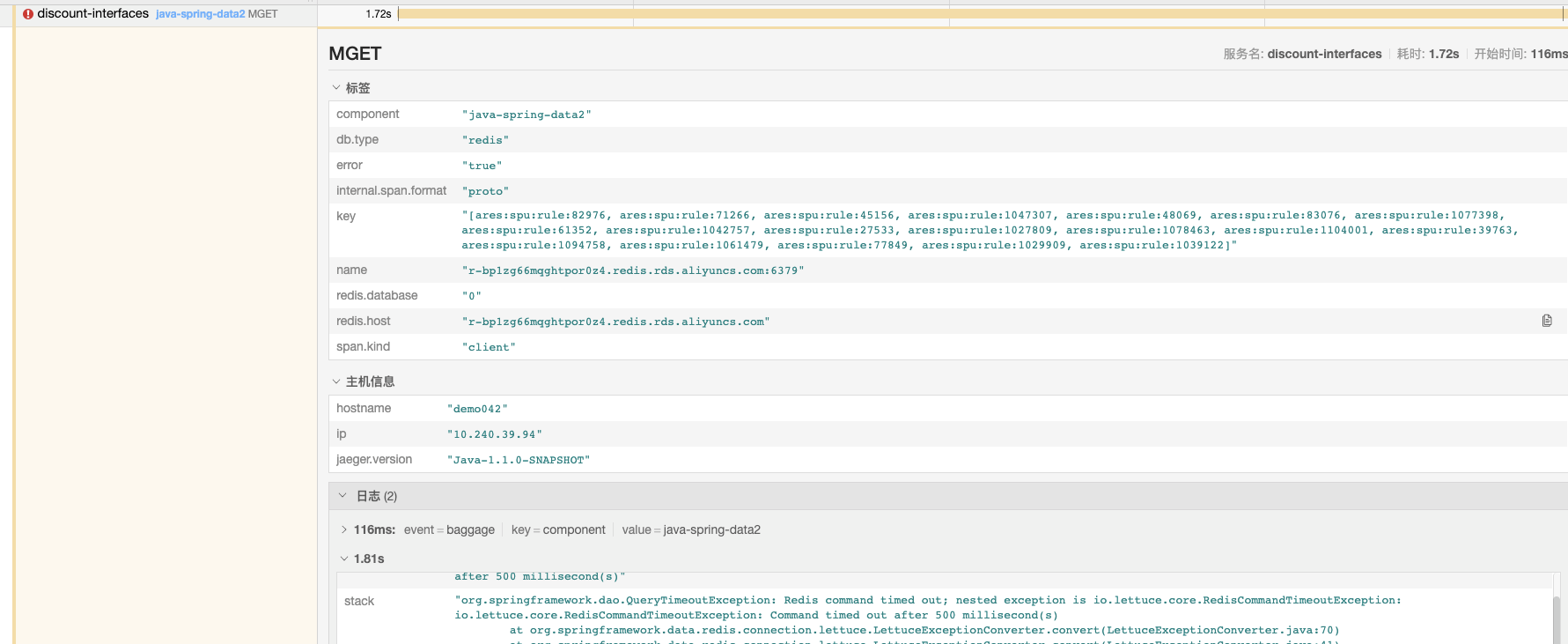
这个请求中用到了redis mget 同时获取多个keys,大概有几十个key,竟然超时了,500ms的时间都不够。
换个存在异常接口 :足迹批量算价服务
可以这两个接口都用到了mget批量拉取keys ,从key的命名看来,还是依赖同样的数据,当然这不影响。上面我们看到了redis 缓存的数据是没问题的,无大key 热点key,redis本身运行状态也健康,网络也正常,那么,只有一种可能,是不是这个mget有问题,mget是如何一次获取多个key的,带着疑问,我们追一下mget的源码(系统用的是Lettuce pool)
public RedisFuture<List<KeyValue<K, V>>> mget(Iterable<K> keys) {
//获取分区slot和key的映射关系
Map<Integer, List<K>> partitioned = SlotHash.partition(codec, keys);
//如果分区数小于2也就是只有一个分区即所有key都落在一个分区就直接获取
if (partitioned.size() < 2) {
return super.mget(keys);
}
//每个key与slot映射关系
Map<K, Integer> slots = SlotHash.getSlots(partitioned);
Map<Integer, RedisFuture<List<KeyValue<K, V>>>> executions = new HashMap<>();
//遍历分片信息,逐个发送
for (Map.Entry<Integer, List<K>> entry : partitioned.entrySet()) {
RedisFuture<List<KeyValue<K, V>>> mget = super.mget(entry.getValue());
executions.put(entry.getKey(), mget);
}
// restore order of key 恢复key的顺序
return new PipelinedRedisFuture<>(executions, objectPipelinedRedisFuture -> {
List<KeyValue<K, V>> result = new ArrayList<>();
for (K opKey : keys) {
int slot = slots.get(opKey);
int position = partitioned.get(slot).indexOf(opKey);
RedisFuture<List<KeyValue<K, V>>> listRedisFuture = executions.get(slot);
result.add(MultiNodeExecution.execute(() -> listRedisFuture.get().get(position)));
}
return result;
});
}整个mget操作其实分为了以下几步:
- 获取分区slot和key的映射关系,遍历出所需的每个分区slot对应那些key。
- 判定,slot个数是不是小于2,也就是是否所有的key都在同一分区,如果是,发起一次mget命令,直接获取。
- 如果分区数量大于2,keys对应多个分区,那么遍历所有分区,分别向redis发起mget请求获取数据。
- 等待所有请求执行结束,重新组装结果数据,保持跟入参key的顺序一致,然后返回结果。
可以看到,当使用mget方法获取多个key,并且这些key还存在于不同的slot分区中,那么一次mget操作其实会对redis发起多次mget命令的请求,有多少个slot,就发起多少次,然后在所有请求执行完毕之后,整个mget方法才会能够继续执行下去。所以,看似一次mget方法调用,其实底层对应的是多次redis调用和多次io交互。
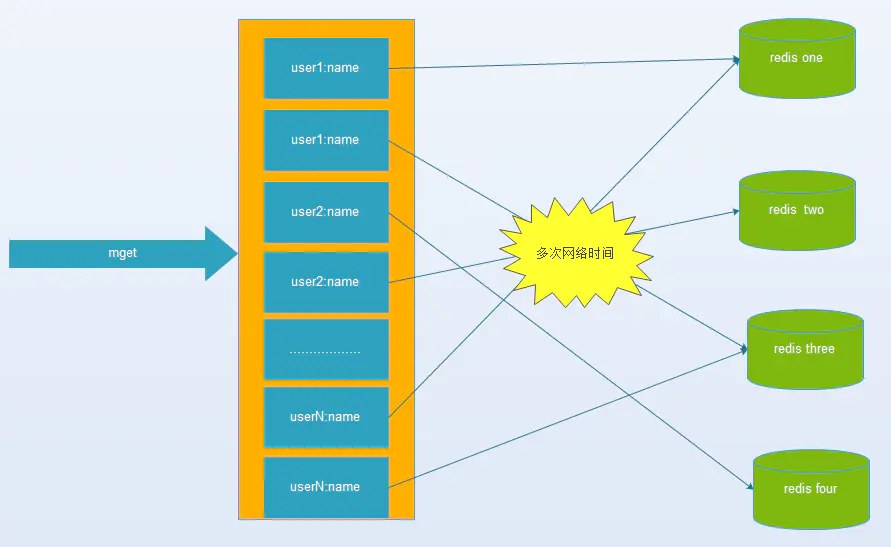
这张图就能很直观的看出redis 在集群模式下,mget的弊病。
问题优化:
方案1 - hashtag
hashtag 强制将key放在一个redis node上。这个方案,相当于将redis集群退化成了单机redis,系统的高可用,容灾能力就大打折扣了,只能尝试使用主从,哨兵等其他分布式架构来缓减,但是,既然选择了集群,肯定集群模式是相比于其他模式是最符合当前系统架构现状的,使用这种方案,可能会引发更大的问题。不推荐。
方案2 -并发调用
我们从图a,以及上面的代码中可以看到,for循环内多次串行的redis调用,是导致执行rt上涨的原因,那么,自然而然可以想到,是否可以用并行替代底层串行的逻辑。也就是将mget中的keys,根据slot分片规则,先groupBy一下,然后用多线程的方式并行执行。
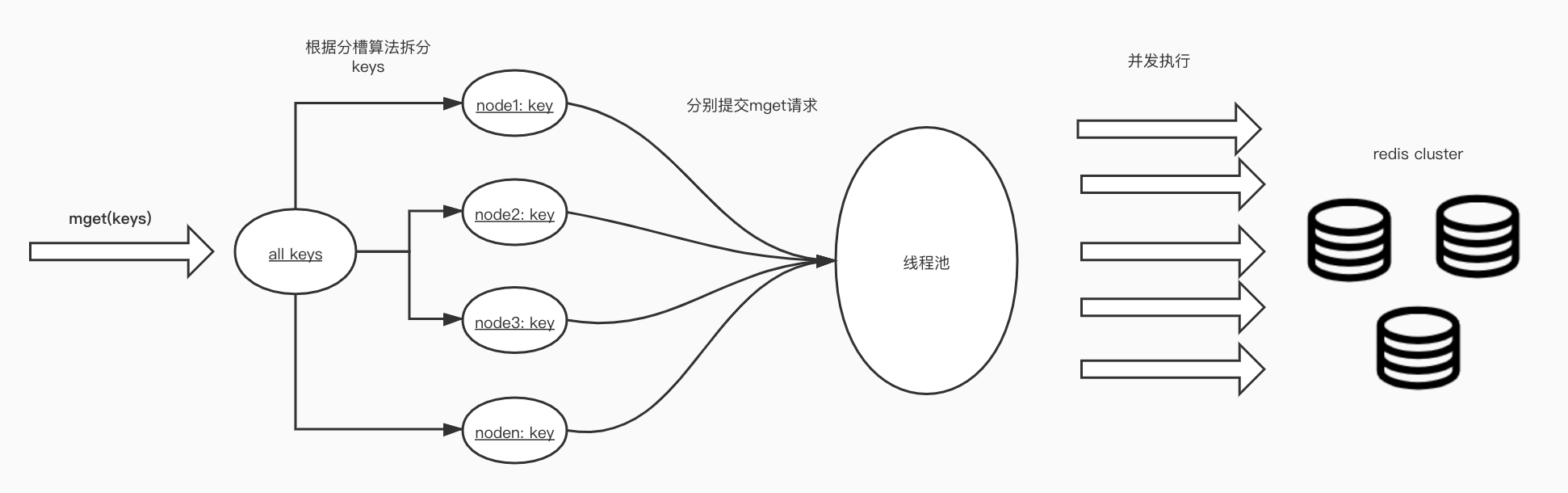
那么rt最理想的情况其实就是一次单机mget的rt耗时,也就是一次网络io耗时,一次redis mget命令耗时。
看似比较完美的解决方案,其实不尽然,我们考虑一下实际场景:首先,这个方案中,用于并发调用提交redis mget任务的线程池的设计非常重要,各种参数的调校,势必需要非常充分的压测,这本身难度就比较大。其次,我们在日常使用中,一次mget的key基本上在几十到100,相比于redis 16384的固定槽位数量,是数量级上的差距,所以,我们一次请求的这些key,基本上是分布在不同的slot中的,换句话讲,如果按照这么拆分keys,大概率是相当于拆出了等于key数量的get请求。。也就丧失了mget的意义。
两种方案各有利弊吧,方案一简单,但是架构层面的隐患比较大,方案二实现复杂,但是可靠性相对比较好一点。mget 一直是让人又爱又恨,关键还是看使用场景,key分散到的redis集群节点越多,性能就越差,但是对于小数量级别,比如5~20个这种,其实问题都不大。