一、背景介绍
因为google官方bert不支持GPU并行化训练,在git上找了相关的multi gpu的都无法跑起来,内心无比的愤怒,花了几天时间,百度,google,查找各种方法,终于把bert multi gpu 训练成功搞定,以下记录详细各种采坑过程,以便相关同学学习。
二、所需要的软件
先列出来硬件软件版本
1.centos 7 服务器 两块P40 GPU
2.tensorflow=1.11.0 当时尝试了 1.14.0 各种跑不通
3.cuda=9.0 cudnn=7.5.1
4.NCCL v2.4.2, for CUDA 9.0
5.Open MPI 3.1.2
6. horovod =0.19.0. 默认版本
7. python= 3.6
8. gcc = 5.0.1 这个不确定 可能 4.8.5也行,我升级了一下
三、配置流程
1.分布式bert 代码
google 官方bert本身不支持分布式训练,因此有其他用户自己修改了一个版本分支,官方bert也接受了,我认为是最正统的分布式了
分支地址:https://github.com/google-research/bert/pull/568
代码地址:https://github.com/abditag2/bert
接下来就环境配置了
2.安装Openmpi
在以上代码的readme里面仔细查找:Using BERT with multi-GPU support using Horovod, bert分布式依赖horovod, 而 horovod依赖 OpenMPI,所以先安装它,官网建议版本 MPI 3.1.2
官网下载地址:https://www.open-mpi.org/software/ompi/v3.0/
下载 3.1.2.tar.gz
官网安装方法:
shell$ gunzip -c openmpi-4.0.2.tar.gz | tar xf -
shell$ cd openmpi-4.0.2
shell$ ./configure --prefix=/usr/local
<...lots of output...>
shell$ make all install
3.安装horovod(采坑)
这一步是最难最操蛋的一部,官网推荐有三种安装方法,我用了第一种,花了两天时间各种错误,各种google都没有调好。
注意这里面有个大大的坑,看官网文档:
https://github.com/horovod/horovod#install
我最开始用的 pip install horovod ,然后后面很顺利的跑了起来,两个GPU都能调用了,很开心,观察后发现不对头,两个GPU的使用频率在 0%到100%之间来回波动,而且在0%的时间居多,猜想可能是不同GPU在更新参数通信的时候占用了大量时间,但是理论上不应该出现这个问题,肯定是GPU之间在梯度下降参数更新之间通信存在问题。
在这种情况下我用了20W短文本分类,epoch=1,batch_size=64
1个GPU情况下用了半个小时训练完毕,acc=0.95
2个GPU情况下用了一个小时训练完毕,acc=0.95
日了狗了,分布式还不胜单GPU,在这个地方纠结1天,各种查资料,发现网上基本没有遇到这种情况,后来仔细阅读文档,才发现上面的
Horovod on GPU ,文档:
https://github.com/horovod/horovod/blob/master/docs/gpus.rst
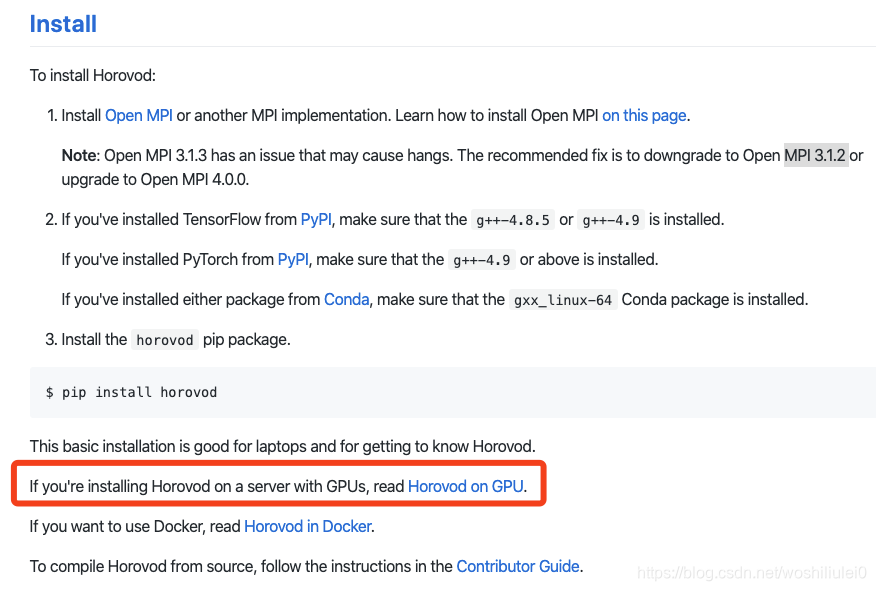
阅读文档后需要安装 NCCl.
4.安装NCCL
安装NCCl的时候也是各种坑。
各版本官网:
https://developer.nvidia.com/nccl/nccl-legacy-downloads
需要注册后才能下载。
此处要和你的 CUDA和操作系统版本一致。
我之前采坑用的通用版本,非安装直接下载,发现各种问题,放弃
我用的版本:Download NCCL v2.4.2, for CUDA 9.0, Jan 29,2019
我是在线安装的,需要安装相关的依赖
其实,可以看出NCLL有三种安装方式
1.NCCL2 using the nccl-.txz 也就通用版本,下载之后是.txz的包
2.installed NCCL 2 using the Ubuntu package,也就是 ubuntu操作系统
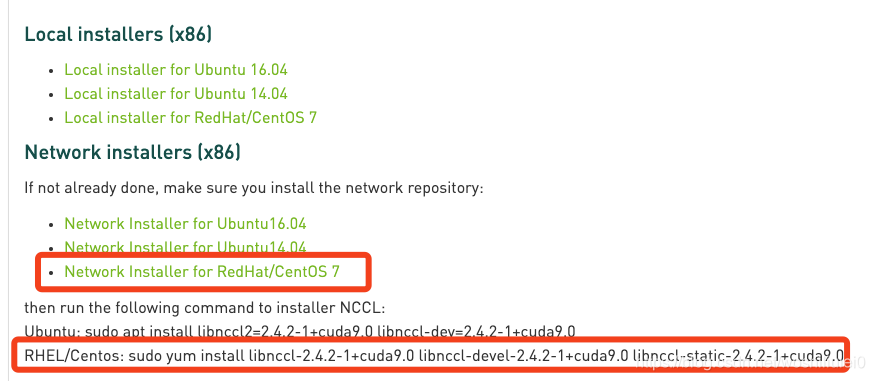
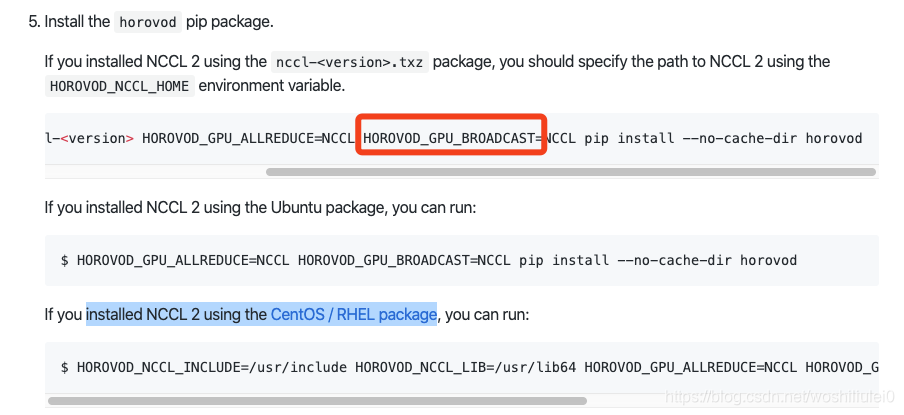
3.installed NCCL 2 using the CentOS / RHEL package,我是用这个版本跑通了
5.安装horovod
我们接着回到官网安装方式:
https://github.com/horovod/horovod/blob/master/docs/gpus.rst
这里面也有个大坑
我原来用第一方式安装的时候,出现了bug,就是在安装的过程中,会自动安装一些依赖,但是其中的一个依赖安装失败,查了原因之后,是GCC版本不对,我但是版本是gcc 4.8.5,没办法只有升级到了 5.0.1,升级办法看我的另一篇博客,升级之后又出了各种错误吧,都是一些依赖问题,后来解决了,注意如果你是安装的有python2和python3 ,上面安装命令 要用pip3 .
按照第一种办法安装成功后,在训练期间还是有错误。此时我已经快要崩溃了,然后各种卸载重装,卸载方式为:将安装命令中的install 换成 uninstall就行了
后来还是不行,就尝试第三种安装方式,成功安装
其实我还查到了英伟达官方安装教程,但是里面安装方法不同于上面的方法,不知道什么原因,有看到的大佬希望解答:
https://docs.nvidia.com/deeplearning/sdk/nccl-install-guide/index.html
6.分布式运行方法
这里参考官网运行方式:
https://github.com/google-research/bert/pull/568/commits/ca7883a27d8576aa3c81aacf19bd5f1c41e97ebb
我们本地的运行代码为:
xport BERT_BASE_DIR=../model/chinese_L-12_H-768_A-12
export DATASET=../data/
horovodrun -np 2 -H localhost:2 \
python3 run_classifier.py \
--data_dir=$MY_DATASET \
--task_name=mytask \
--vocab_file=$BERT_BASE_DIR/vocab.txt \
--bert_config_file=$BERT_BASE_DIR/bert_config.json \
--output_dir=../output2_two/ \
--do_train=true \
--do_eval=true \
--init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt \
--max_seq_length=64 \
--train_batch_size=64 \
--learning_rate=2e-5 \
--num_train_epochs=1.0 \
--use_multi_gpu=true
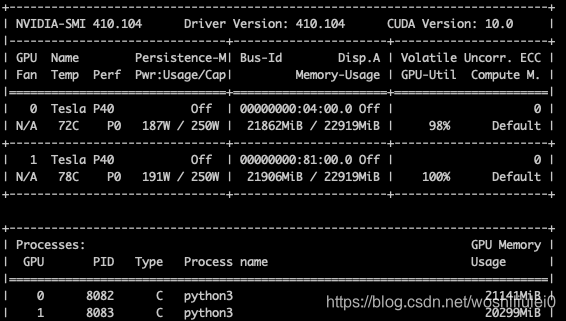
下图为nvidia-smi的结果
2个GPU训练时间15分钟左右,比单个减少一半时间。
大工搞成。
相信自己,想干成一件事,总会成功的。
遗留问题:
cuda,openmpi,horovod到底什么关系还不明白。