
论文题目:《AutoRAG: Automated Framework for optimization of Retrieval Augmented Generation Pipeline》
论文地址:https://arxiv.org/pdf/2410.20878
Github地址:https://github.com/Marker-Inc-Korea/AutoRAG
官方文档:https://docs.auto-rag.com/
一、AutoRAG介绍
市面上有很多RAG pipelines和模块,但是针对具体的数据和场景的最佳实践是什么?是非常耗时和困难的。而AutoRAG可以通过自动化评估不同RAG模块组合来弥补上述困难。
特点:
- Data Creation:使用您自己的原始文档创建 RAG 评估数据。
- Optimization:自动运行实验,为您自己的数据找到最佳 RAG 管道。
- Deployment:使用单个 yaml 文件部署最佳 RAG 管道。还支持 Flask 服务器。
二、AutoRAG支持的RAG技术栈
2.1 数据模块
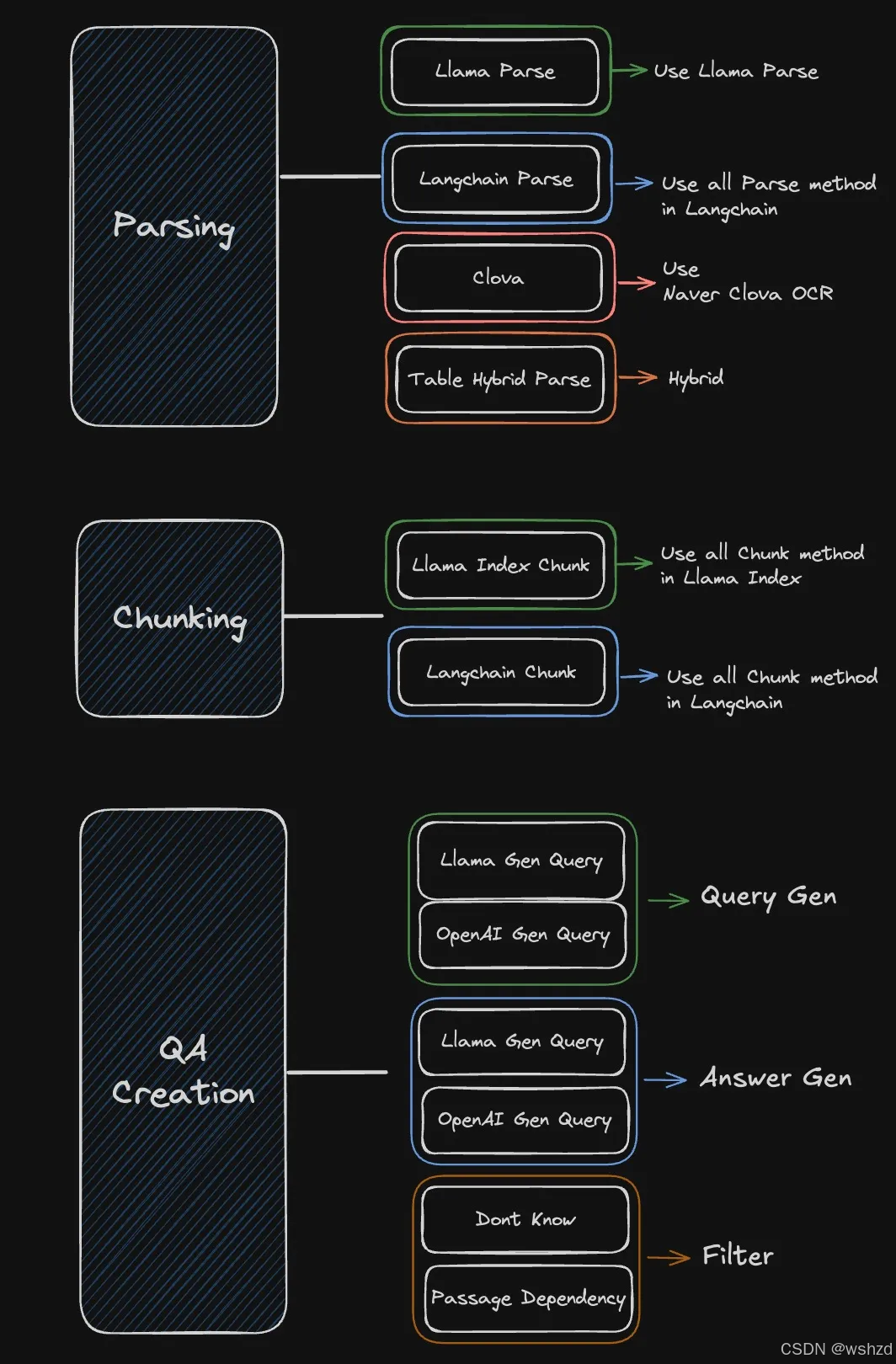


2.2 RAG优化模块







2.3 评估指标


三、AutoRAG使用
3.1 安装AutoRAG
a)建议使用python3.10+版本
pip install AutoRAGb)要使用本地模型,则需要安装gpu版本
pip install "AutoRAG[gpu]"c)如果涉及到解析文档,则需要使用parsing版本
pip install "AutoRAG[gpu,parse]"3.2 创建数据

RAG 优化需要两种类型的数据:QA 数据集和 Corpus 数据集。
- QA 数据集文件 (qa.parquet)
- 语料库数据集文件 (corpus.parquet)
QA 数据集对于准确可靠的评估和优化非常重要。
语料库数据集对 RAG 的性能至关重要。这是因为 RAG 使用语料库来检索文档并使用它生成答案。
3.3 解析
a)配置yaml文件
modules:- module_type: langchain_parseparse_method: pdfminer
也可以同时使用多个Parse模块,这种情况下,需要为每个解析的结果返回一个新进程。
b)开始解析
只需几行代码即可解析原始文档
from autorag.parser import Parserparser = Parser(data_path_glob="your/data/path/*")parser.start_parsing("your/path/to/parse_config.yaml")
3.4 分块
a)配置yaml文件
modules:- module_type: llama_index_chunkchunk_method: Tokenchunk_size: 1024chunk_overlap: 24add_file_name: en
也可以一次使用多个 Chunk 模块。在这种情况下,您需要使用一个语料库创建 QA,然后将语料库的其余部分映射到 QA 数据。如果 chunk 方法不同,retrieval_gt也会不同,因此我们需要将其重新映射到 QA 数据集。
b)开始分块
只需几行代码即可对解析后的结果进行分块
from autorag.chunker import Chunkerchunker = Chunker.from_parquet(parsed_data_path="your/parsed/data/path")chunker.start_chunking("your/path/to/chunk_config.yaml")
3.5 创建QA
import pandas as pdfrom llama_index.llms.openai import OpenAIfrom autorag.data.qa.filter.dontknow import dontknow_filter_rule_basedfrom autorag.data.qa.generation_gt.llama_index_gen_gt import (make_basic_gen_gt,make_concise_gen_gt,)from autorag.data.qa.schema import Raw, Corpusfrom autorag.data.qa.query.llama_gen_query import factoid_query_genfrom autorag.data.qa.sample import random_single_hopllm = OpenAI()raw_df = pd.read_parquet("your/path/to/parsed.parquet")raw_instance = Raw(raw_df)corpus_df = pd.read_parquet("your/path/to/corpus.parquet")corpus_instance = Corpus(corpus_df, raw_instance)initial_qa = (corpus_instance.sample(random_single_hop, n=3).map(lambda df: df.reset_index(drop=True),).make_retrieval_gt_contents().batch_apply(factoid_query_gen, # query generationllm=llm,).batch_apply(make_basic_gen_gt, # answer generation (basic)llm=llm,).batch_apply(make_concise_gen_gt, # answer generation (concise)llm=llm,).filter(dontknow_filter_rule_based, # filter don't knowlang="en",))initial_qa.to_parquet('./qa.parquet', './corpus.parquet')
3.6 RAG优化

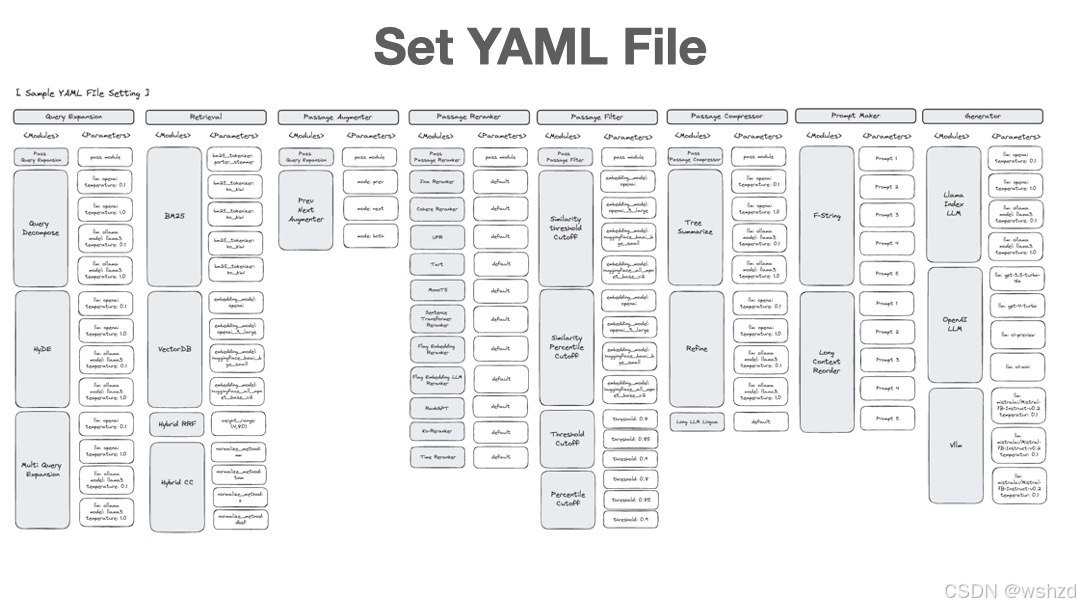
3.6.1 设置yaml文件
首先,您需要为 RAG 优化设置配置 YAML 文件。
可以在此处[1]获取各种配置 YAML 文件。强烈建议使用预制的配置 YAML 文件作为初学者。
如果想制作自己的配置 YAML 文件,可以查看配置 YAML 文件[2]部分。
以下是使用 retrieval、prompt_maker 和 generator 节点的配置 YAML 文件示例。
node_lines:- node_line_name: retrieve_node_line # Set Node Line (Arbitrary Name)nodes:- node_type: retrieval # Set Retrieval Nodestrategy:metrics: [retrieval_f1, retrieval_recall, retrieval_ndcg, retrieval_mrr] # Set Retrieval Metricstop_k: 3modules:- module_type: vectordbvectordb: default- module_type: bm25- module_type: hybrid_rrfweight_range: (4,80)- node_line_name: post_retrieve_node_line # Set Node Line (Arbitrary Name)nodes:- node_type: prompt_maker # Set Prompt Maker Nodestrategy:metrics: # Set Generation Metrics- metric_name: meteor- metric_name: rouge- metric_name: sem_scoreembedding_model: openaimodules:- module_type: fstringprompt: "Read the passages and answer the given question. \n Question: {query} \n Passage: {retrieved_contents} \n Answer : "- node_type: generator # Set Generator Nodestrategy:metrics: # Set Generation Metrics- metric_name: meteor- metric_name: rouge- metric_name: sem_scoreembedding_model: openaimodules:- module_type: openai_llmllm: gpt-4o-minibatch: 16
3.6.2 运行AutoRAG评估
from autorag.evaluator import Evaluatorevaluator = Evaluator(qa_data_path='your/path/to/qa.parquet', corpus_data_path='your/path/to/corpus.parquet')evaluator.start_trial('your/path/to/config.yaml')
或者,使用命令行界面
autorag evaluate --config your/path/to/default_config.yaml --qa_data_path your/path/to/qa.parquet --corpus_data_path your/path/to/corpus.parquet完成后,可以看到在当前目录中创建的多个文件和文件夹。在命名为数字(如 0)的 trial 文件夹中,可以检查summary.csv文件,该文件汇总了评估结果和最适合您数据的 RAG 管道。
3.6.3 运行Dashboard
autorag dashboard --trial_dir /your/path/to/trial_dir
3.7 部署RAG pipeline
3.7.1 代码运行
可以立即从 trial 文件夹中使用最佳 RAG 管道。trial 文件夹是正在运行的控制面板中使用的目录。(如 0、1、2、...)
from autorag.deploy import Runnerrunner = Runner.from_trial_folder('/your/path/to/trial_dir')runner.run('your question')
3.7.2 作为API服务器运行
import nest_asynciofrom autorag.deploy import ApiRunnernest_asyncio.apply()runner = ApiRunner.from_trial_folder('/your/path/to/trial_dir')runner.run_api_server()
3.7.3 作为WEB界面运行
autorag run_web --trial_path your/path/to/trial_path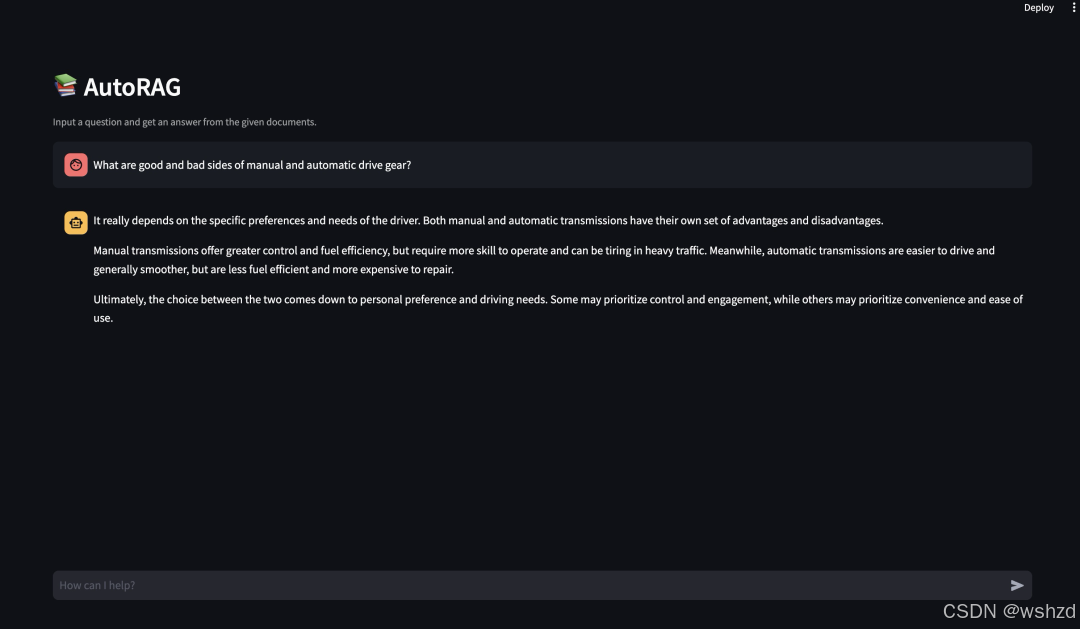
3.7.4 使用高级WEB界面
可以将 Kotaemon[3] 提供的高级 Web 界面部署到 fly.io。可以参考[4]并部署到 fly.io。
参考文献:
[1] https://github.com/Marker-Inc-Korea/AutoRAG/blob/main/sample_config
[2] https://github.com/Marker-Inc-Korea/AutoRAG?tab=readme-ov-file#-create-your-own-config-yaml-file
[3] https://github.com/Cinnamon/kotaemon
[4] https://github.com/vkehfdl1/AutoRAG-web-kotaemon