来源:CVPR2017
传统图像检索系统排序图像是根据一个单模态的相关性,随着互联网的发展,越来越多的图像可以通过相关的元数据这种丰富的模态形式使用。
本文问题:在学习子空间时,优于查询意图的变化,不是所有的模态具有同等的信息量。
解决方法:针对在图像检索中的问题,引入了两个注意力机制:
- 内部注意力机制(inrta-attention):帮助图像检索系统找到每个模态最具信息量的部分;
- 外部注意力机制(inter-attention):根据查询意图,平衡不同模态间的重要性。
即作者提出了一种新的学习方法:Attention guided Multi-modal Correlation(AMC)。AMC框架包括三个部分:visual intra-attention network (VAN), language intra-attention network (LAN) ; multi-modal inter-attention network (MTN).
相关性:在AMC space中,查询和与图像相关的模态间的相关性是通过计算查询嵌入向量和多模态嵌入向量的余弦距离。 多模态相关性学习:Canonical correlation analysis (CCA):学习一个子空间将不同模态的相关性最大化。(变种:KCCA, RCCA ,KPCA-CCA)
模型:
输入: a query , images ,related keywords 输出:image
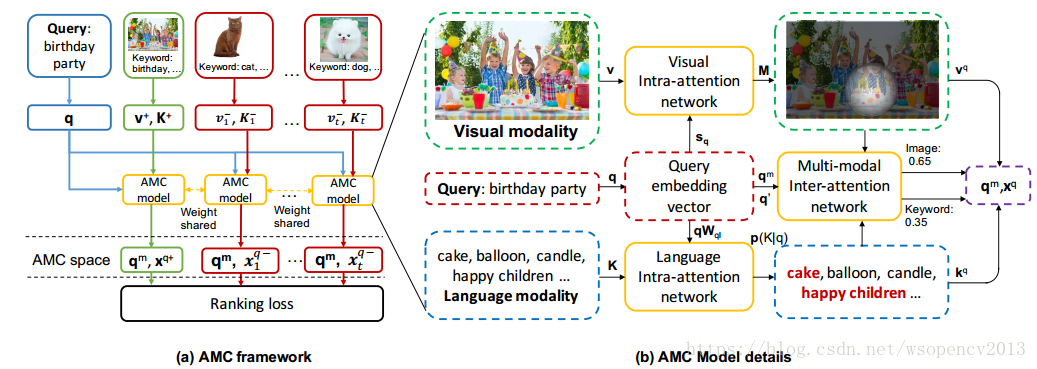
图1:AMC框架
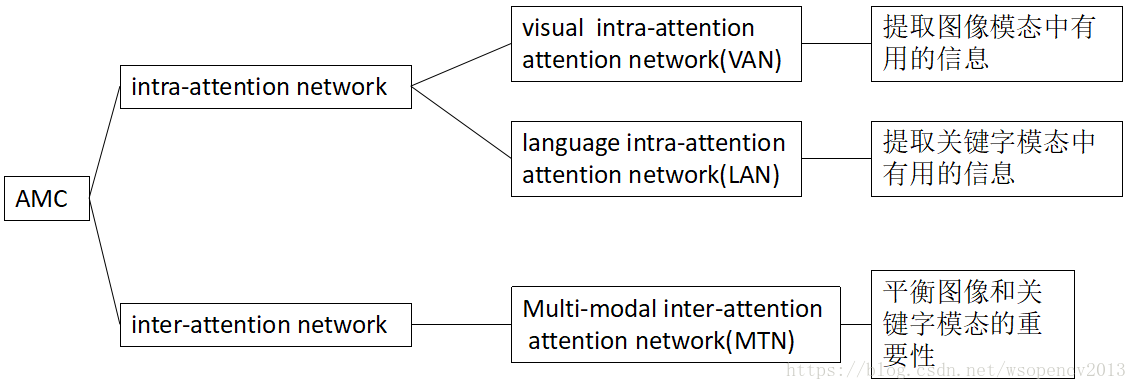
图2:AMC模型框架
数据集:
- Keyword datasets
- Adobe Stock Dataset(ASD)
- Clickture dataset
- COCO Image Caption dataset(CIC)
2)和3)用于多模态图像检索任务,4)用于字幕排序任务。
总结:作者提出了AMC框架根据输入查询的意图,处理吗,每个模态中有用的信息,滤除模态中无关的信息。针对此框架,作者进行了多模态图像检索和字幕排序实验。在今后研究中,AMC框架可通过融合更多与图像像相关的模态和外部知识来提升。