1.进程
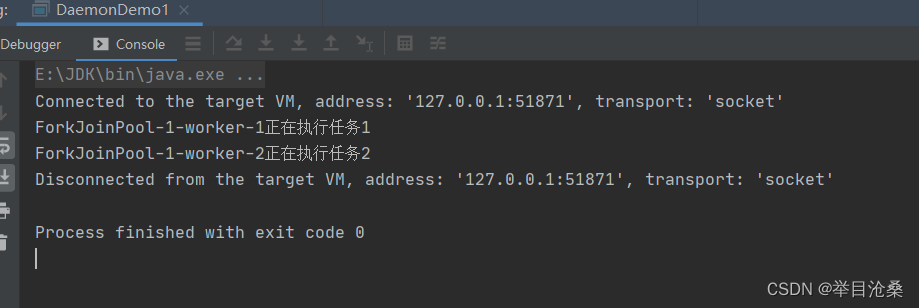
1.基本概念
- 1.进程:程序的一次启动执行(并发执行的程序在执行过程中分配和管理资源的基本单位)
- 2.程序:存放在硬盘中的可执行文件,主要包括代码指令和数据
- 3.关联:一个进程是一个程序的一次启动和执行,是操作系统将程序装入内存,给程序分配必要的系统资源,并且开始运行程序的指令(同一个程序可以多次启动,对应多个进程)
2.基本原理
- 1.计算机各个组成的任务
- 1.
CPU:承担所有的计算任务- 2.内存:承担运行时数据的保存任务
- 3.外存:承担数据外部永久存储的任务
- 4.操作系统:承担计算任务调度,资源分配的任务
- 2.一个进程由程序段,数据段,进程控制块三部分组成
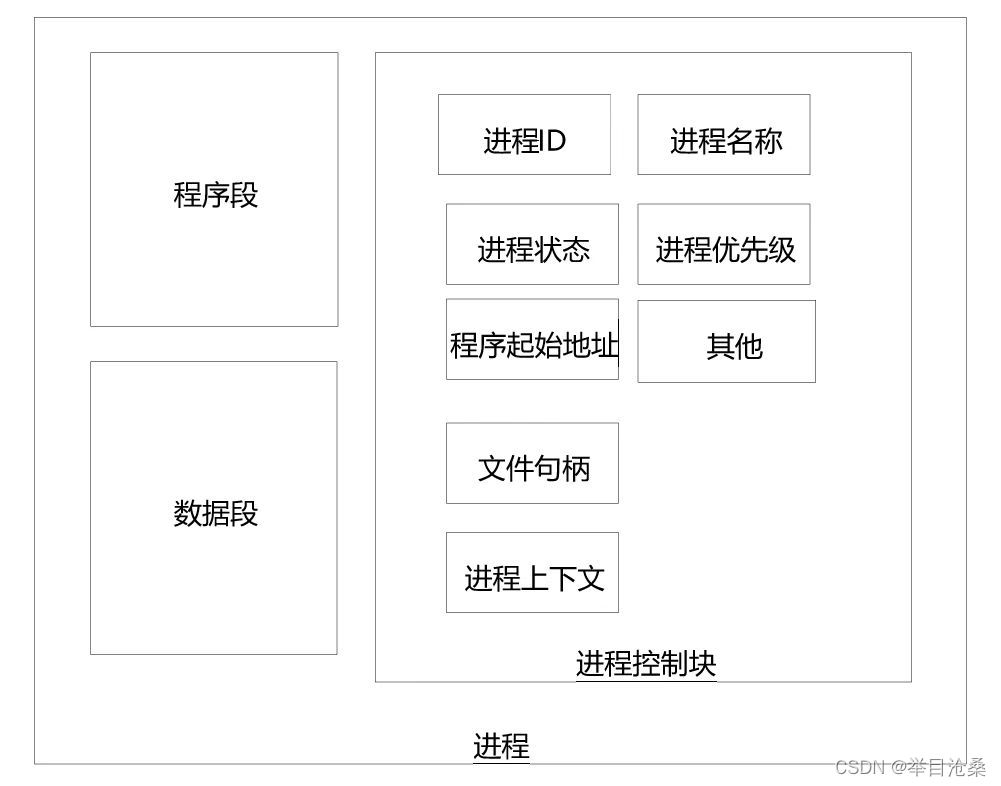
- 1.程序段: 进程指令在内存中的位置,包含需要执行的指令集合
- 2.数据段: 进程的操作数据在内存中的位置,包含需要操作的数据集合
- 3.程序控制块(Program Control Block,PCB): 包含进程的描述信息和控制信息等,是进程存在的唯一标志
- 1.程序的描述信息
- 1.进程ID: 唯一,代表进程的身份
- 2.进程名称
- 3.进程状态
- 1.三态模型:运行态,就绪态,阻塞态
- 2.五态模型:新建态,终止态,运行态,就绪态,阻塞态
- 4.进程优先级: 进程调度的依据
- 2.进程的调度信息
- 1.程序起始地址: 程序第一行指令的内存地址
- 2.通信信息: 进程间通信时的消息队列
- 3.进程的资源信息
- 1.内存信息: 内存占用情况和内存管理所用的数据结构
- 2.I/O设备信息: 所用的I/O设置编号及相应的数据结构
- 3.文件句柄: 也叫文件描述符,是所打开文件的信息
- 4.进程上下文信息(进程环境)
- 1.执行时各种
CPU寄存器的值- 2.当前程序计数器(
PC)的值以及各种栈的值- 3.当前进程被迫让出
CPU,当前进程的上下文就保存在PCB结构中,供下次恢复运行时使用- 3.注意
- 1.现代操作系统中,进程是并发执行的,任何进程都可以同其他进程一起执行(交替执行);
- 2.进程内部
程序段和数据段有自己独立的地址空间,不同进程的地址空间是相互隔离的
3.Java程序的进程
- 1.
Java编写的程序都运行在Java虚拟机(JVM)中,当使用Java命令启动一个Java应用程序时,就会启动一个JVM进程- 2.
JVM进程内部,所有Java程序代码都是以线程运行- 3.
JVM找到程序的入口点main()方法,然后运行main()方法,产生一个线程,这该线程被称为主线程- 4.当
main()方法结束后,主线程运行完成,JVM进程也随即退出
2.线程
1.基本概念
- 1.线程是指进程代码(程序)段的一次顺序执行流程
- 2.线程是CPU调度的最小单位
- 3.一个进程可以有一个或多个线程,各个线程之间共享进程的内存空间,系统资源
- 4.进程仍然是操作系统资源分配的最小单位
2.基本原理
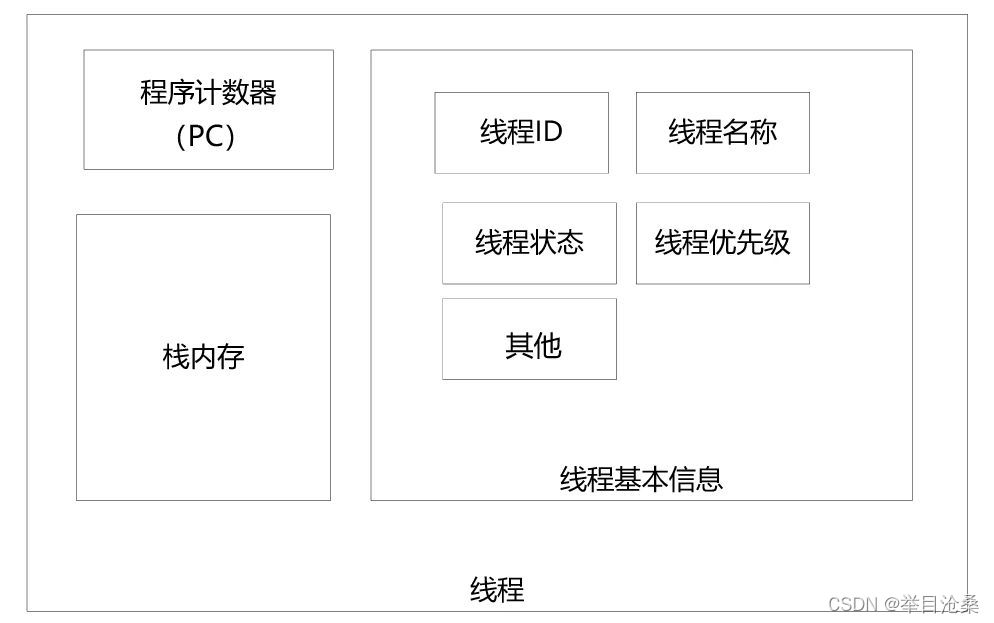
- 1.一个标准的线程主要由三部分组成
- 1.线程基本信息
- 1.线程ID(Thread ID,线程标识符): 线程的唯一标识,同一个进程内不同线程的
ID不会重叠- 2.线程名称: 方便用户识别,用户可以指定线程的名字,如果没有指定,系统会自动分配一个名称
- 3.线程优先级: 表示线程调度的优先级,优先级越高,获取CPU的执行机会就越大
- 4.线程状态: 表示当前线程的执行状态:
新建,就绪,运行,阻塞,结束- 5.其他: 是否为守护线程
- 2.程序计数器(Program Counter,PC)
- 1.记录着线程下一条指令的代码段内存地址(线程独享,每个线程都有自己的程序计数器)
- 3.栈内存
- 1.代码段中局部变量的储存空间,为线程所独立拥有,线程之间不共享
- 2
.JDK8中,每个线程在创建时默认被分配1MB大小的栈内存(注意栈溢出错误)- 3.栈内存和堆内存不同,栈内存不受垃圾回收器管理
3.执行流程
- 1.
Java中执行程序流程的重要单位是方法- 2.每个线程在创建时默认被分配
1MB大小的栈内存- 3.栈内存的分配单位是栈帧,方法的每一次执行都需要为其分配一个栈帧,栈帧主要保存该方法中的局部变量,方法的返回地址以及其他方法的相关信息
- 4.当线程的执行流程进入方法时,
JVM就会为方法分配一个对应的栈帧压入栈内存- 5.当线程的执行流程跳出方法时,
JVM就从栈内存弹出该方法的栈帧,此时栈内存中栈帧的局部变量的内存空间就会被回收package threadDemo; public class StackAreaDemo { public static void main(String[] args) throws InterruptedException { System.out.println("当前线程ID:"+Thread.currentThread().getId()); System.out.println("当前线程名:"+Thread.currentThread().getName()); System.out.println("当前线程状态:"+Thread.currentThread().getState()); System.out.println("当前线程优先级:"+Thread.currentThread().getPriority()); System.out.println("当前线程类加载器:"+Thread.currentThread().getContextClassLoader()); System.out.println("当前线程堆栈帧数组:"+Thread.currentThread().getStackTrace()); System.out.println("当前线程线程组:"+Thread.currentThread().getThreadGroup()); System.out.println("当前线程此线程突然终止时调用的处理程序:"+Thread.currentThread().getUncaughtExceptionHandler()); System.out.println("当前线程类对象:"+Thread.currentThread().getClass()); int a = 1, b = 1; int c = a / b; anotherFun(); Thread.sleep(10000); } private static void anotherFun() { int a = 1, b = 1; int c = a / b; anotherFun2(); } private static void anotherFun2() { int a = 1, b = 1; int c = a / b; } }
- 1.上述代码中使用
java.lang包中Thread.currentThread()静态方法,用于获取正在执行的当前线程- 2.上述代码定义了三个方法
main,anotherFun,anotherFun2,并且这三个方法有相同的三个局部变量a,b,c- 3.上述代码中
JVM的执行流程
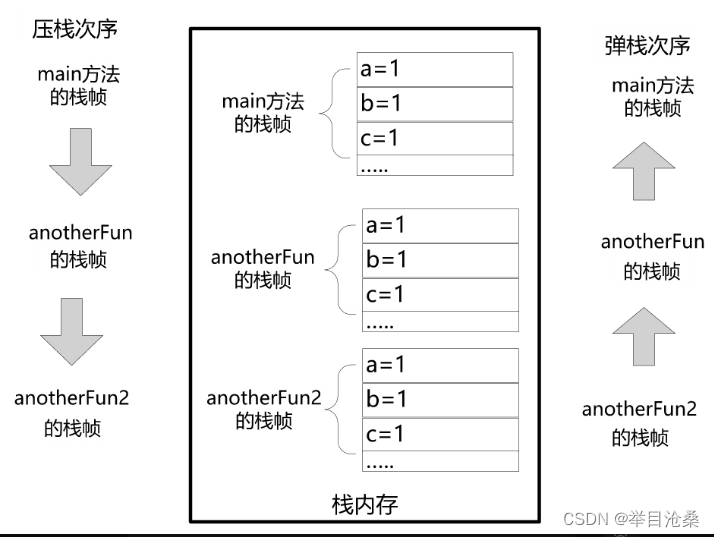
- 1.当执行
main()方法时,JVM为main()方法分配一个栈帧,保存三个局部变量,然后将栈帧压入main线程的栈内存,接着执行流程进入anotherFun()方法- 2.执行流程进入
anotherFun()方法之前JVM为其分配对应的栈帧,保存其三个局部变量,然后压入main线程的栈内存(每个方法都会有自己独立的栈帧,负责保存该方法内部的局部变量,然后压入当前线程的栈内存)- 3.执行流程进入
anotherFun2()方法之前JVM为其分配对应的栈帧,保存其三个局部变量,然后将栈帧压入main线程的栈内存,此时main线程含有三个栈帧- 4.三个方法的栈帧弹出过程与压入的过程刚好相反
- 5.
anotherFun2()方法执行完成后,其栈帧从main线程的栈内存首先弹出,执行流程回到anotherFun()方法,anotherFun()方法执行完成后,其栈帧从main线程的栈内存弹出,执行流程回到main()方法,main()方法执行完成后,其栈帧弹出,此时main线程的栈内存已经全部弹空,没有剩余的栈帧,至此main线程结束- 4.由于栈帧的操作是后进先出的模式,这是标准的栈操作模式,因此此存放栈帧的内存也叫作栈内存
4.Java程序的线程
- 1.
Java程序的进程执行过程就是标准的多线程的执行过程- 2.每当使用
Java命令执行一个class类的main方法时,实际上就启动了一个JVM进程- 3.理论上该进程内部至少会启动两个线程:一个是
main线程,另一个是GC(垃圾回收)线程- 4.实际上线程数量不止两个
5.核心原理
- 1.现代操作系统提供了强大的线程管理能力,
Java不需要再进行独立的线程管理和调度,而是将线程调度工作委托给操作系统的调度进程去完成- 2.某些系统上
JVM将每个Java线程一对一地对应到操作系统地本地线程,彻底将线程调度委托给操作系统
1.线程地调度和时间片
- 1.
时间片
- 1.由于
CPU的计算频率非常高,每秒计算数十亿次,因此可以将CPU的时间从毫秒地维度进行分段,每一小段叫做一个CPU时间片- 2.不同的操作系统,不同的
CPU,线程的CPU时间片长度都不同- 3.目前操作系统中主流的线程调度方式是:基于
CPU时间片方式进行线程调度- 4.线程只有得到
CPU时间片才能执行指令,没有得到时间片的线程处于就绪状态- 5.由于时间片非常短,在各个线程之间快速地切换,因此表现出地特征是很多个线程在同时执行或者并发执行
- 2.
线程地调度模型目前主要分为两种
- 1.
分时调度模型- 2.
抢占式调度模型
1.分时调度模型
- 1.系统平均分配
CPU的时间片,所有线程轮流占用CPU,在时间片调度的分配上所有线程人人平等

2.抢占式调度模型
- 1.系统按照
线程优先级分配CPU时间片,优先级高的线程优先分配CPU时间片,如果所有就绪线程的优先级相同,那么会随机选择一个,优先级高的线程获取的CPU时间片相对多一些- 2.由于目前大部分操作系统都是使用
抢占式调度模型进行线程调度,Java的线程管理和调度是委托给操作系统完成的,因此Java的线程调度也是使用抢占式调度模型,Java线程都有优先级
2.线程的优先级
- 1.
Thread类中有一个实例属性和两个实例方法,专门用于进行线程优先级相关的操作//属性一: private int priority; //该属性保存一个Thread实例的优先级,即1~10的值 //方法一: public final int getPriority() //获取线程优先级 //方法二: public final void setPriority() //获取线程优先级- 2.
Thread类中定义了三个优先级常量,priority默认是级别5,对应的类常量是NORM_PRIORITY,优先级最大值为10,最小值为1public static final int MIN_PRIORITY = 1; public static final int NORM_PRIORITY = 5; public static final int MAX_PRIORITY = 10;- 3.
Java中使用抢占式调度模型进行线程调度,priority实例属性的优先级越高,线程获得CPU时间片的机会就越多,但非绝对package threadDemo; public class PriorityDemo1 { public static final int SLEEP_GAP = 1000; public static void main(String[] args) throws InterruptedException { PriorityThread[] priorityThreads = new PriorityThread[10]; for (int i = 0; i < priorityThreads.length; i++) { priorityThreads[i] = new PriorityThread(); priorityThreads[i].setPriority(i+1); } for (int i = 0; i < priorityThreads.length; i++) { priorityThreads[i].start(); } Thread.sleep(SLEEP_GAP); for (int i = 0; i < priorityThreads.length; i++) { priorityThreads[i].stop(); } for (int i = 0; i < priorityThreads.length; i++) { System.out.println(priorityThreads[i].getName() + "-优先级为-" + priorityThreads[i].getPriority() + "-机会值为-" + priorityThreads[i].opportunities); } } static class PriorityThread extends Thread{ static int threadNo = 1; public PriorityThread(){ super("thread-" + threadNo); threadNo++; } public long opportunities = 0; public void run(){ for (int i = 0; ; i++) { opportunities++; } } } }- 注意
- 1.执行机会的获取具有
随机性,优先级高的不一定获得的机会多,整体而言高优先级的线程获得的执行机会更多
3.线程的生命周期
- 1.
Java中线程的生命周期分为6种,其具体状态定义在Thread类的内部枚举类State中public enum State { /** * Thread state for a thread which has not yet started. */ NEW,// 初始状态,一个新创建的线程,还没开始执行 /** * Thread state for a runnable thread. A thread in the runnable * state is executing in the Java virtual machine but it may * be waiting for other resources from the operating system * such as processor. */ RUNNABLE,//可执行状态,要么是在执行,要么是一切就绪等待执行 BLOCKED,//阻塞状态,等待锁,以便进入同步块 WAITING,//等待状态,等待其他线程去执行特定的动作,没有时间限制 TIMED_WAITING,//限时等待状态,等待其他的线程去执行特定的动作,这个是在一个指定的时间范围内 TERMINATED;//终止状态,线程执行结束 }- 2.
Thread类中定义了属性和方法专门用来保存和获取线程的状态//实例属性 private int threadStatue;//以整数的形式保存线程的状态 //实例方法 public Thread.State getState();//返回当前线程的执行状态,一个枚举类型值
1.New状态
- 1.
Java源码对NEW状态的说明:创建成功但是没有调用start()方法启动的Thread线程实例都处于NEW状态
2.Runnable状态
- 1.调用
Thread实例的start()方法后,下一步如果线程获取CPU时间片开始执行,JVM将异步调用线程的run()方法执行其业务代码- 2.当
Java线程的Thread实例的start()方法被调用后,操作系统中对应线程进入的并不是运行状态而是就绪状态,而Java线程并没有就绪状态- 3.并不是
Thread线程实例的start()方法一经调用,其状态就从NEW状态切换RUNNABLE状态,因为此时并不意味着线程立即获取CPU时间片并且立即执行,中间需要一系列操作系统的内部操作- 4.
run()方法被异步执行前,JVM幕后工作和操作系统的线程调度有关,Java中的线程管理是通过JNI本地调用的方式委托操作系统的线程管理API完成的- 5.
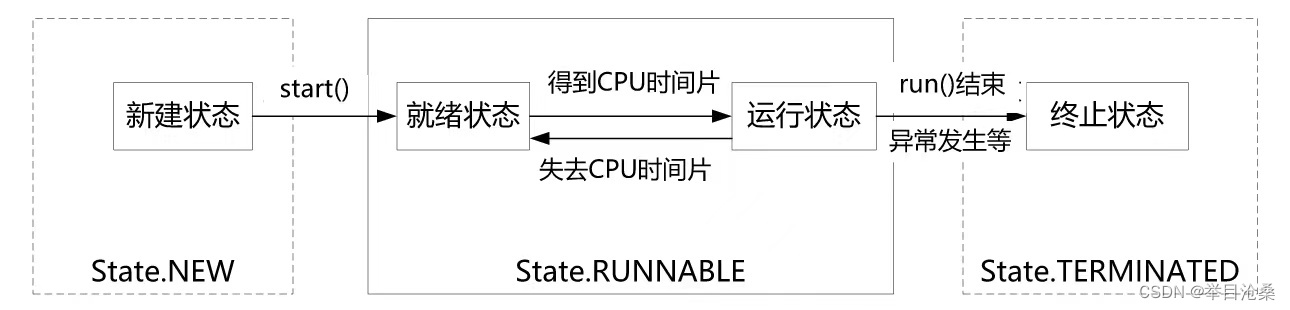
JVM的线程状态与其幕后的操作系统线程状态之间的转换关系如下图所示
- 6.说明
- 1.操作系统线程如果处于就绪状态,即该线程已经满足执行条件,但是还不能执行
- 2.处于
就绪状态的线程需要等待系统的调度,一旦该就绪状态的线程被系统选中,获得CPU时间片,线程就开始占用CPU执行线程的代码,此时线程的操作系统状态进入了运行状态- 3.操作系统中处于
运行状态的线程在CPU时间用完后又回到就绪状态,等待CPU的下一次调度- 4.操作系统线程在
就绪状态和执行状态之间被系统反复地调度,这种情况会持续直到线程的代码逻辑执行完成或异常终止- 5.此时线程的操作系统状态又发生了改变,进入线程的
TERMINATED(终止)状态- 7.注意
- 1.
就绪状态和运行状态都是操作系统中的线程状态- 2.
Java语言中并没有细分这两种状态,而是将这两种状态合并成同一种状态即RUNNABLE状态- 3.因此
Thread.state枚举类中并没有定义线程的就绪状态和运行状态而是只定义了RUNNABLE状态,这是Java线程状态和操作系统中线程状态不同地地方- 8.总结
- 1.
NEW状态的Thread实例调用了start()方法后,线程的状态将变成RUNNABLE状态- 2.但是线程的
run()方法不一定会马上被并发执行,需要在线程获取了CPU时间片之后才真正启动并发执行- 3.
Runnable状态之所以包含就绪和运行两种状态是因为操作系统中每个线程不会一直占有CPU时间片,所以需要在就绪和运行两种状态中反复切换直到该线程的业务代码执行完成或抛出异常- 4.不细分为就绪和运行是因为
JVM不能决定哪个线程什么时候来运行,这取决于操作系统的时间片调度,另一方面说明JVM无法对操作系统的调度做出积极的响应- 5.
就绪状态仅仅表示线程具备运行资格,如果没有被操作系统的调度程序挑选中,线程就永远处于就绪状态,当前线程进入就绪状态的条件包括一下几种
- 1.调用线程的
start()方法,此线程会进入就绪状态- 2.当前线程的执行时间片用完也会进入就绪状态
- 3.线程睡眠
sleep操作结束也是进入就绪状态- 4.对其他线程合入
join操作结束- 5.等待用户输入结束
- 6.线程争抢到对象锁
Object Monitor(虽然这个线程获取到了锁,但不是立马获取时间片)- 7.当前线程调用
yield()方法让出CPU执行权限
3.BLOCKED状态
4.WAITING状态
5.TIMED_WAITING状态
- 1.线程处于一种特殊的等待状态:
限时等待状态- 2.线程处于限时等待状态的操作大致分为以下几种
- 1.
Thread.sleep(int n):使当前线程进入限时等待状态,等待时间为n毫秒- 2.
Object.wait():带时限的抢占对象的monitor锁- 3.
Thread.join():带时限的线程合并- 4.
LockSupport.parkNanos():让线程等待,时间以纳秒为单位- 5.
LockSupport.parkUntil():让线程等待,时间可以灵活设置
6.TERMINATED状态
- 1.处于
RUNNABLE状态的线程在run()方法执行完成之后会变成终止状态TERMINATED- 2.如果
run()方法执行过程中发生了运行时异常而没有被捕获,run()方法将被异常终止,线程也会变成TERMINATED状态
4.线程状态演示案例
package threadDemo; import java.util.ArrayList; import java.util.List; import java.util.concurrent.locks.LockSupport; public class StatusDemo1 { public static final long MAX_TURN = 5; //每个线程执行的轮次 static int threadSeqNumber = 0; //线程编号 static List<Thread> threadList = new ArrayList<>(); //全局的静态线程列表 /** * 输出静态线程列表中每个线程的状态 */ private static void printThreadStatus(){ for (Thread thread : threadList) { System.out.println(thread.getName() + "状态为:" + thread.getState()); } } /** * 向全局的静态线程列表中加入线程 * @param thread 线程实例 */ private static void addStatusThread(Thread thread){ threadList.add(thread); } static class StatusDemoThread extends Thread{ public StatusDemoThread() { super("statusPrintThread" + (++threadSeqNumber)); addStatusThread(this); } public void run(){ System.out.println(getName() + "启动后状态为" + getState()); for (int turn = 0; turn < MAX_TURN; turn++) { sleepMilliSeconds(500); printThreadStatus(); } System.out.println(getName() + "- 运行结束"); } } public static void main(String[] args){ addStatusThread(Thread.currentThread()); Thread sThread1 = new StatusDemoThread(); System.out.println(sThread1.getName() + "-创建时状态为" + sThread1.getState()); Thread sThread2 = new StatusDemoThread(); System.out.println(sThread2.getName() + "-创建时状态为" + sThread2.getState()); Thread sThread3 = new StatusDemoThread(); System.out.println(sThread3.getName() + "-创建时状态为" + sThread3.getState()); sThread1.start(); sleepMilliSeconds(500); sThread2.start(); sleepMilliSeconds(500); sThread3.start(); sleepMilliSeconds(500); } public static void sleepMilliSeconds(int millisecond){ LockSupport.parkNanos(millisecond * 1000L * 1000L); } }E:\JDK\bin\java.exe "-javaagent:E:\IDEA\IntelliJ IDEA 2020.2.1\lib\idea_rt.jar=50289:E:\IDEA\IntelliJ IDEA 2020.2.1\bin" -Dfile.encoding=UTF-8 -classpath "E:\JDK\jre\lib\charsets.jar;E:\JDK\jre\lib\deploy.jar;E:\JDK\jre\lib\ext\access-bridge-64.jar;E:\JDK\jre\lib\ext\cldrdata.jar;E:\JDK\jre\lib\ext\dnsns.jar;E:\JDK\jre\lib\ext\jaccess.jar;E:\JDK\jre\lib\ext\jfxrt.jar;E:\JDK\jre\lib\ext\localedata.jar;E:\JDK\jre\lib\ext\nashorn.jar;E:\JDK\jre\lib\ext\sunec.jar;E:\JDK\jre\lib\ext\sunjce_provider.jar;E:\JDK\jre\lib\ext\sunmscapi.jar;E:\JDK\jre\lib\ext\sunpkcs11.jar;E:\JDK\jre\lib\ext\zipfs.jar;E:\JDK\jre\lib\javaws.jar;E:\JDK\jre\lib\jce.jar;E:\JDK\jre\lib\jfr.jar;E:\JDK\jre\lib\jfxswt.jar;E:\JDK\jre\lib\jsse.jar;E:\JDK\jre\lib\management-agent.jar;E:\JDK\jre\lib\plugin.jar;E:\JDK\jre\lib\resources.jar;E:\JDK\jre\lib\rt.jar;E:\IDEA\IntelliJ IDEA 2020.2.1\Code\out\production\CoreJava_Day1_20211201;E:\IDEA\IntelliJ IDEA 2020.2.1\plugins\Kotlin\kotlinc\lib\kotlin-stdlib.jar;E:\IDEA\IntelliJ IDEA 2020.2.1\plugins\Kotlin\kotlinc\lib\kotlin-reflect.jar;E:\IDEA\IntelliJ IDEA 2020.2.1\plugins\Kotlin\kotlinc\lib\kotlin-test.jar;E:\IDEA\IntelliJ IDEA 2020.2.1\plugins\Kotlin\kotlinc\lib\kotlin-stdlib-jdk7.jar;E:\IDEA\IntelliJ IDEA 2020.2.1\plugins\Kotlin\kotlinc\lib\kotlin-stdlib-jdk8.jar" com.wd.Test.StatusDemo1 statusPrintThread1-创建时状态为NEW statusPrintThread2-创建时状态为NEW statusPrintThread3-创建时状态为NEW statusPrintThread1启动后状态为RUNNABLE main状态为:RUNNABLE statusPrintThread1状态为:RUNNABLE statusPrintThread2状态为:RUNNABLE statusPrintThread3状态为:NEW statusPrintThread2启动后状态为RUNNABLE main状态为:TIMED_WAITING main状态为:TIMED_WAITING statusPrintThread1状态为:BLOCKED statusPrintThread1状态为:RUNNABLE statusPrintThread2状态为:BLOCKED statusPrintThread2状态为:RUNNABLE statusPrintThread3状态为:RUNNABLE statusPrintThread3状态为:RUNNABLE statusPrintThread3启动后状态为RUNNABLE main状态为:RUNNABLE main状态为:RUNNABLE main状态为:RUNNABLE statusPrintThread1状态为:BLOCKED statusPrintThread1状态为:RUNNABLE statusPrintThread2状态为:BLOCKED statusPrintThread3状态为:BLOCKED statusPrintThread2状态为:BLOCKED statusPrintThread3状态为:RUNNABLE statusPrintThread1状态为:BLOCKED statusPrintThread2状态为:RUNNABLE statusPrintThread3状态为:TIMED_WAITING main状态为:TERMINATED statusPrintThread1状态为:BLOCKED statusPrintThread2状态为:RUNNABLE statusPrintThread3状态为:BLOCKED main状态为:TERMINATED statusPrintThread1状态为:RUNNABLE main状态为:TERMINATED statusPrintThread2状态为:TIMED_WAITING statusPrintThread1状态为:BLOCKED statusPrintThread2状态为:TIMED_WAITING statusPrintThread3状态为:RUNNABLE statusPrintThread3状态为:BLOCKED main状态为:TERMINATED statusPrintThread1状态为:RUNNABLE statusPrintThread2状态为:BLOCKED statusPrintThread3状态为:BLOCKED main状态为:TERMINATED statusPrintThread1状态为:BLOCKED statusPrintThread2状态为:BLOCKED statusPrintThread3状态为:RUNNABLE main状态为:TERMINATED statusPrintThread1- 运行结束 statusPrintThread1状态为:RUNNABLE statusPrintThread2状态为:RUNNABLE statusPrintThread3状态为:TIMED_WAITING main状态为:TERMINATED statusPrintThread1状态为:TERMINATED statusPrintThread2状态为:BLOCKED main状态为:TERMINATED statusPrintThread3状态为:RUNNABLE statusPrintThread1状态为:TERMINATED statusPrintThread2状态为:RUNNABLE statusPrintThread3状态为:TIMED_WAITING statusPrintThread2- 运行结束 main状态为:TERMINATED statusPrintThread1状态为:TERMINATED statusPrintThread2状态为:TERMINATED statusPrintThread3状态为:RUNNABLE statusPrintThread3- 运行结束 Process finished with exit code 0
- 1.当线程新建之后,没有调用
start()方法启动之前状态为NEW- 2.调用
start()方法启动之后,其状态为RUNNABLE- 3.调用
LockSupport.parkNanos()方法使线程等待之后,线程的状态变成了TIMED_WAITING(LockSupport.parkNanos()方法使得当前线程限时等待,LockSupport是来自JDK中的锁辅助类)- 4.等待结束之后,其状态又变为了
RUNNABLE- 5.线程完成之后,它的状态变成了
TERMINATED
5.Jstack工具查看线程状态
- 1.如果
CPU使用率居高不下,说明有线程一直占用着CPU资源,通过Jstack工具可以查看线程的状态
1.Jstack工具
- 1.
Jstack.exe工具是Java虚拟机自带的一种堆栈跟踪工具,其位于JDK/bin目录下- 2.
Jstack作用:生成或导出JVM虚拟机运行实例当前时刻的线程快照(DUMP)- 3.线程快照(
DUMP):是当前JVM实例内每一个线程正在执行的方法堆栈的集合- 4.生成或导出线程快照的主要目的:定位线程出现长时间运行,停顿或者阻塞的原因(线程间死锁,死循环,请求外部资源导致长时间等待)
- 5.线程出现停顿的时候可以通过
Jstack查看各个线程的调用堆栈,可以查看线程在后台做什么事情或等待什么资源
2.Jstack工具使用方法
//1.通过jps查看Java进程id<pid> jps //2.查看某个进程的线程快照 jstack pid
1.一般情况通过
Jstack输出的线程信息主要包括JVM线程,用户线程等2.其中
JVM线程在JVM启动时就存在,主要用于执行垃圾回收,低内存检测等后台任务,这些线程在JVM初始化时就存在,而用户线程则是在程序创建了新的线程才会生成3.注意
- 1.实际运行中一次
DUMP的信息不足以确认问题,建议产生三次DUMP信息,如果每次都指向同一个问题才能确定问题的典型性- 2.不同的
Java虚拟机的线程导出来的DUMP信息格式是不一样的,并且同一个JVM的不同版本,DUMP信息也有差别
3.Jstack运行实例
E:\IDEA\IntelliJ IDEA 2020.2.1\Code\CoreJava_Day1_20211201>jps 15440 Jps 12648 Launcher 15272 StatusDemo1 18296 E:\IDEA\IntelliJ IDEA 2020.2.1\Code\CoreJava_Day1_20211201>jstack 15272 2022-07-31 17:20:51 Full thread dump Java HotSpot(TM) 64-Bit Server VM (25.92-b14 mixed mode): "Service Thread" #11 daemon prio=9 os_prio=0 tid=0x000000001a1f2000 nid=0x3164 runnable [0x0000000000000000] java.lang.Thread.State: RUNNABLE "C1 CompilerThread3" #10 daemon prio=9 os_prio=2 tid=0x000000001a1ee800 nid=0x510 waiting on condition [0x0000000000000000] java.lang.Thread.State: RUNNABLE "C2 CompilerThread2" #9 daemon prio=9 os_prio=2 tid=0x000000001a1ec000 nid=0xb3c waiting on condition [0x0000000000000000] java.lang.Thread.State: RUNNABLE "C2 CompilerThread1" #8 daemon prio=9 os_prio=2 tid=0x000000001a1e3800 nid=0x2170 waiting on condition [0x0000000000000000] java.lang.Thread.State: RUNNABLE "C2 CompilerThread0" #7 daemon prio=9 os_prio=2 tid=0x000000001a1e2800 nid=0x3c08 waiting on condition [0x0000000000000000] java.lang.Thread.State: RUNNABLE "Monitor Ctrl-Break" #6 daemon prio=5 os_prio=0 tid=0x000000001a1e1000 nid=0x2dec runnable [0x000000001a92e000] java.lang.Thread.State: RUNNABLE at java.net.SocketInputStream.socketRead0(Native Method) at java.net.SocketInputStream.socketRead(SocketInputStream.java:116) at java.net.SocketInputStream.read(SocketInputStream.java:170) at java.net.SocketInputStream.read(SocketInputStream.java:141) at sun.nio.cs.StreamDecoder.readBytes(StreamDecoder.java:284) at sun.nio.cs.StreamDecoder.implRead(StreamDecoder.java:326) at sun.nio.cs.StreamDecoder.read(StreamDecoder.java:178) - locked <0x00000000d5e8c658> (a java.io.InputStreamReader) at java.io.InputStreamReader.read(InputStreamReader.java:184) at java.io.BufferedReader.fill(BufferedReader.java:161) at java.io.BufferedReader.readLine(BufferedReader.java:324) - locked <0x00000000d5e8c658> (a java.io.InputStreamReader) at java.io.BufferedReader.readLine(BufferedReader.java:389) at com.intellij.rt.execution.application.AppMainV2$1.run(AppMainV2.java:61) "Attach Listener" #5 daemon prio=5 os_prio=2 tid=0x000000001a10a000 nid=0x40bc waiting on condition [0x0000000000000000] java.lang.Thread.State: RUNNABLE "Signal Dispatcher" #4 daemon prio=9 os_prio=2 tid=0x000000001a109000 nid=0x2bf8 runnable [0x0000000000000000] java.lang.Thread.State: RUNNABLE "Finalizer" #3 daemon prio=8 os_prio=1 tid=0x0000000018213800 nid=0x308c in Object.wait() [0x000000001a5ce000] java.lang.Thread.State: WAITING (on object monitor) at java.lang.Object.wait(Native Method) - waiting on <0x00000000d5d08ee0> (a java.lang.ref.ReferenceQueue$Lock) at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:143) - locked <0x00000000d5d08ee0> (a java.lang.ref.ReferenceQueue$Lock) at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:164) at java.lang.ref.Finalizer$FinalizerThread.run(Finalizer.java:209) "Reference Handler" #2 daemon prio=10 os_prio=2 tid=0x000000001820c800 nid=0x2e74 in Object.wait() [0x000000001a0cf000] java.lang.Thread.State: WAITING (on object monitor) at java.lang.Object.wait(Native Method) - waiting on <0x00000000d5d06b50> (a java.lang.ref.Reference$Lock) at java.lang.Object.wait(Object.java:502) at java.lang.ref.Reference.tryHandlePending(Reference.java:191) - locked <0x00000000d5d06b50> (a java.lang.ref.Reference$Lock) at java.lang.ref.Reference$ReferenceHandler.run(Reference.java:153) "main" #1 prio=5 os_prio=0 tid=0x0000000002fbe000 nid=0x154c waiting on condition [0x0000000002f9f000] java.lang.Thread.State: TIMED_WAITING (parking) at sun.misc.Unsafe.park(Native Method) at java.util.concurrent.locks.LockSupport.parkNanos(LockSupport.java:338) at com.wd.Test.StatusDemo1.sleepMilliSeconds(StatusDemo1.java:68) at com.wd.Test.StatusDemo1.main(StatusDemo1.java:58) "VM Thread" os_prio=2 tid=0x0000000018209000 nid=0x26c8 runnable "GC task thread#0 (ParallelGC)" os_prio=0 tid=0x0000000003147800 nid=0x39c8 runnable "GC task thread#1 (ParallelGC)" os_prio=0 tid=0x0000000003149800 nid=0x33dc runnable "GC task thread#2 (ParallelGC)" os_prio=0 tid=0x000000000314b000 nid=0x810 runnable "GC task thread#3 (ParallelGC)" os_prio=0 tid=0x000000000314c800 nid=0x36e8 runnable "GC task thread#4 (ParallelGC)" os_prio=0 tid=0x000000000314e800 nid=0x41fc runnable "GC task thread#5 (ParallelGC)" os_prio=0 tid=0x0000000003150000 nid=0x4490 runnable "GC task thread#6 (ParallelGC)" os_prio=0 tid=0x0000000003153000 nid=0x3170 runnable "GC task thread#7 (ParallelGC)" os_prio=0 tid=0x0000000003155000 nid=0x3d04 runnable "VM Periodic Task Thread" os_prio=2 tid=0x000000001a2d0000 nid=0x3c48 waiting on condition JNI global references: 16
- 1.
tid:线程实例在JVM进程中的id- 2.
nid:线程实例在操作系统中对应的底层线程的线程id- 3.
prio:线程实例在JVM进程中的优先级- 4.
os_prio:线程实例在操作系统对应的底层线程的优先级- 5.线程状态:
runnable,waiting on condition等等- 6.线程名称:
Service Thread,main等等- 7.
GC tack thread:垃圾回收线程,该类线程会负责进行垃圾回收,通常JVM会启动多个GC线程,GC线程的名称中,#后面的数字会累加- 8.
VM Periodic Task Thread:JVM周期性任务调度的线程,该线程在JVM内使用得比较频繁(定期的内存监控、JVM运行状况监控)
6.基本操作
- 1.
Java线程的常用操作基本都定义在Thread类中,包括一些重要的静态方法和线程实例方法
1.线程名称的设置和获取
public class Thread implements Runnable { public Thread() { init(null, null, "Thread-" + nextThreadNum(), 0); } public Thread(Runnable target) { init(null, target, "Thread-" + nextThreadNum(), 0); } Thread(Runnable target, AccessControlContext acc) { init(null, target, "Thread-" + nextThreadNum(), 0, acc); } public Thread(ThreadGroup group, Runnable target) { init(group, target, "Thread-" + nextThreadNum(), 0); } public Thread(String name) { init(null, null, name, 0); } public Thread(ThreadGroup group, String name) { init(group, null, name, 0); } public Thread(Runnable target, String name) { init(null, target, name, 0); } public Thread(ThreadGroup group, Runnable target, String name, long stackSize) { init(group, target, name, stackSize); } private void init(ThreadGroup g, Runnable target, String name, long stackSize) { init(g, target, name, stackSize, null); } private void init(ThreadGroup g, Runnable target, String name, long stackSize, AccessControlContext acc) { if (name == null) { throw new NullPointerException("name cannot be null"); } this.name = name.toCharArray(); Thread parent = currentThread(); SecurityManager security = System.getSecurityManager(); if (g == null) { /* Determine if it's an applet or not */ /* If there is a security manager, ask the security manager what to do. */ if (security != null) { g = security.getThreadGroup(); } /* If the security doesn't have a strong opinion of the matter use the parent thread group. */ if (g == null) { g = parent.getThreadGroup(); } } /* checkAccess regardless of whether or not threadgroup is explicitly passed in. */ g.checkAccess(); /* * Do we have the required permissions? */ if (security != null) { if (isCCLOverridden(getClass())) { security.checkPermission(SUBCLASS_IMPLEMENTATION_PERMISSION); } } g.addUnstarted(); this.group = g; this.daemon = parent.isDaemon(); this.priority = parent.getPriority(); if (security == null || isCCLOverridden(parent.getClass())) this.contextClassLoader = parent.getContextClassLoader(); else this.contextClassLoader = parent.contextClassLoader; this.inheritedAccessControlContext = acc != null ? acc : AccessController.getContext(); this.target = target; setPriority(priority); if (parent.inheritableThreadLocals != null) this.inheritableThreadLocals = ThreadLocal.createInheritedMap(parent.inheritableThreadLocals); /* Stash the specified stack size in case the VM cares */ this.stackSize = stackSize; /* Set thread ID */ tid = nextThreadID(); } public final synchronized void setName(String name) { checkAccess(); this.name = name.toCharArray(); if (threadStatus != 0) { setNativeName(name); } } public final String getName() { return new String(name, true); } }
- 1.
Thread类中可以通过Thread()构造方法设置线程名称,如果没有指定则系统会自动为线程设置名称,线程将使用Thread-threadInitNumber的形式进行自动命名- 2.Thread类
Thread()构造方法实际调用的是init()方法进行初始化,具体初始化内容如上- 3.线程名称也可以通过
setName()方法设置,通过getName()方法取得线程名称- 4.注意
- 1.线程名称一般在启动线程前设置,但也允许为运行的线程设置名称
- 2.允许两个
Thread对象有相同的名称,但应该避免- 3.创建线程或线程池时,需要指定有意义的线程名称,方便出错时回溯
2.线程的sleep()操作
//使目前正在执行的线程休眠millis毫秒 public static native void sleep(long millis) throws InterruptedException; //使目前正在执行的线程休眠millis毫秒,nanos纳秒 public static void sleep(long millis, int nanos) throws InterruptedException { if (millis < 0) { throw new IllegalArgumentException("timeout value is negative"); } if (nanos < 0 || nanos > 999999) { throw new IllegalArgumentException( "nanosecond timeout value out of range"); } if (nanos >= 500000 || (nanos != 0 && millis == 0)) { millis++; } sleep(millis); }public final native void wait(long timeout) throws InterruptedException; public final void wait(long timeout, int nanos) throws InterruptedException { if (timeout < 0) { throw new IllegalArgumentException("timeout value is negative"); } if (nanos < 0 || nanos > 999999) { throw new IllegalArgumentException( "nanosecond timeout value out of range"); } if (nanos > 0) { timeout++; } wait(timeout); } public final void wait() throws InterruptedException { wait(0); }package threadDemo; public class SleepDemo1 { public static final int SLEEP_GAP = 5000;//睡眠时长5秒 public static final int MAX_TURN = 50;//睡眠次数,值稍微大点方便使用Jstack static class SleepThread extends Thread{ static int threadSeqNumber = 1; public SleepThread(){ super("sleepThread-" + threadSeqNumber); threadSeqNumber++; } public void run(){ for (int i = 0; i < MAX_TURN; i++) { System.out.println(getName() + ",睡眠轮次" + i); try { Thread.sleep(SLEEP_GAP); } catch (InterruptedException e) { System.out.println(getName() + "发生异常被中断"); System.out.println(getName() + "运行结束"); } } } } public static void main(String[] args) { for (int i = 0; i < 5; i++) { SleepThread sleepThread = new SleepThread(); sleepThread.start(); } System.out.println(Thread.currentThread().getName() + "运行结束"); } }E:\IDEA\IntelliJ IDEA 2020.2.1\Code\CoreJava_Day1_20211201>jps 2244 StatusDemo1 18296 17884 Launcher 9804 Jps E:\IDEA\IntelliJ IDEA 2020.2.1\Code\CoreJava_Day1_20211201>jstack 2244 2022-07-31 18:11:28 Full thread dump Java HotSpot(TM) 64-Bit Server VM (25.92-b14 mixed >mode): "DestroyJavaVM" #17 prio=5 os_prio=0 tid=0x000000000102e000 nid=0x2c5c waiting on condition [0x0000000000000000] java.lang.Thread.State: RUNNABLE "sleepThread-5" #16 prio=5 os_prio=0 tid=0x0000000019f9f800 nid=0x2bac waiting on condition [0x000000001b0ff000] java.lang.Thread.State: TIMED_WAITING (sleeping) at java.lang.Thread.sleep(Native Method) at com.wd.Test.StatusDemo1$SleepThread.run(StatusDemo1.java:19) "sleepThread-4" #15 prio=5 os_prio=0 tid=0x0000000019f9f000 nid=0x1028 waiting on condition [0x000000001afff000] java.lang.Thread.State: TIMED_WAITING (sleeping) at java.lang.Thread.sleep(Native Method) at com.wd.Test.StatusDemo1$SleepThread.run(StatusDemo1.java:19) "sleepThread-3" #14 prio=5 os_prio=0 tid=0x0000000019f9e000 nid=0x8f4 waiting on condition [0x000000001aeff000] java.lang.Thread.State: TIMED_WAITING (sleeping) at java.lang.Thread.sleep(Native Method) at com.wd.Test.StatusDemo1$SleepThread.run(StatusDemo1.java:19) "sleepThread-2" #13 prio=5 os_prio=0 tid=0x0000000019f9d800 nid=0x3f1c waiting on condition [0x000000001adff000] java.lang.Thread.State: TIMED_WAITING (sleeping) at java.lang.Thread.sleep(Native Method) at com.wd.Test.StatusDemo1$SleepThread.run(StatusDemo1.java:19) "sleepThread-1" #12 prio=5 os_prio=0 tid=0x0000000019f9c800 nid=0x2360 waiting on condition [0x000000001acff000] java.lang.Thread.State: TIMED_WAITING (sleeping) at java.lang.Thread.sleep(Native Method) at com.wd.Test.StatusDemo1$SleepThread.run(StatusDemo1.java:19) "Service Thread" #11 daemon prio=9 os_prio=0 tid=0x0000000019ec3800 nid=0x3d8c runnable [0x0000000000000000] java.lang.Thread.State: RUNNABLE "C1 CompilerThread3" #10 daemon prio=9 os_prio=2 tid=0x0000000019ec0800 nid=0x4410 waiting on condition [0x0000000000000000] java.lang.Thread.State: RUNNABLE "C2 CompilerThread2" #9 daemon prio=9 os_prio=2 tid=0x0000000019ebd800 nid=0x2788 waiting on condition [0x0000000000000000] java.lang.Thread.State: RUNNABLE "C2 CompilerThread1" #8 daemon prio=9 os_prio=2 tid=0x0000000019eb5800 nid=0x4428 waiting on condition [0x0000000000000000] java.lang.Thread.State: RUNNABLE "C2 CompilerThread0" #7 daemon prio=9 os_prio=2 tid=0x0000000019eb4800 nid=0x2610 waiting on condition [0x0000000000000000] java.lang.Thread.State: RUNNABLE "Monitor Ctrl-Break" #6 daemon prio=5 os_prio=0 tid=0x0000000019eb3000 nid=0x3d50 runnable [0x000000001a5fe000] java.lang.Thread.State: RUNNABLE at java.net.SocketInputStream.socketRead0(Native Method) at java.net.SocketInputStream.socketRead(SocketInputStream.java:116) at java.net.SocketInputStream.read(SocketInputStream.java:170) at java.net.SocketInputStream.read(SocketInputStream.java:141) at sun.nio.cs.StreamDecoder.readBytes(StreamDecoder.java:284) at sun.nio.cs.StreamDecoder.implRead(StreamDecoder.java:326) at sun.nio.cs.StreamDecoder.read(StreamDecoder.java:178) - locked <0x00000000d5e8c568> (a java.io.InputStreamReader) at java.io.InputStreamReader.read(InputStreamReader.java:184) at java.io.BufferedReader.fill(BufferedReader.java:161) at java.io.BufferedReader.readLine(BufferedReader.java:324) - locked <0x00000000d5e8c568> (a java.io.InputStreamReader) at java.io.BufferedReader.readLine(BufferedReader.java:389) at com.intellij.rt.execution.application.AppMainV2$1.run(AppMainV2.java:61) "Attach Listener" #5 daemon prio=5 os_prio=2 tid=0x0000000019e2d000 nid=0x2b80 waiting on condition [0x0000000000000000] java.lang.Thread.State: RUNNABLE "Signal Dispatcher" #4 daemon prio=9 os_prio=2 tid=0x0000000019dd9800 nid=0x18b8 runnable [0x0000000000000000] java.lang.Thread.State: RUNNABLE "Finalizer" #3 daemon prio=8 os_prio=1 tid=0x0000000019dc0800 nid=0x1bb0 in Object.wait() [0x000000001a29f000] java.lang.Thread.State: WAITING (on object monitor) at java.lang.Object.wait(Native Method) - waiting on <0x00000000d5d08ee0> (a java.lang.ref.ReferenceQueue$Lock) at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:143) - locked <0x00000000d5d08ee0> (a java.lang.ref.ReferenceQueue$Lock) at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:164) at java.lang.ref.Finalizer$FinalizerThread.run(Finalizer.java:209) "Reference Handler" #2 daemon prio=10 os_prio=2 tid=0x0000000017e9c800 nid=0x145c in Object.wait() [0x0000000019d9f000] java.lang.Thread.State: WAITING (on object monitor) at java.lang.Object.wait(Native Method) - waiting on <0x00000000d5d06b50> (a java.lang.ref.Reference$Lock) at java.lang.Object.wait(Object.java:502) at java.lang.ref.Reference.tryHandlePending(Reference.java:191) - locked <0x00000000d5d06b50> (a java.lang.ref.Reference$Lock) at java.lang.ref.Reference$ReferenceHandler.run(Reference.java:153) "VM Thread" os_prio=2 tid=0x0000000017e99000 nid=0x1a40 runnable "GC task thread#0 (ParallelGC)" os_prio=0 tid=0x0000000002e07800 nid=0x4780 runnable "GC task thread#1 (ParallelGC)" os_prio=0 tid=0x0000000002e09800 nid=0x3c50 runnable "GC task thread#2 (ParallelGC)" os_prio=0 tid=0x0000000002e0b000 nid=0x1224 runnable "GC task thread#3 (ParallelGC)" os_prio=0 tid=0x0000000002e0c800 nid=0x1530 runnable "GC task thread#4 (ParallelGC)" os_prio=0 tid=0x0000000002e0e800 nid=0x26e8 runnable "GC task thread#5 (ParallelGC)" os_prio=0 tid=0x0000000002e10000 nid=0x33c4 runnable "GC task thread#6 (ParallelGC)" os_prio=0 tid=0x0000000002e13000 nid=0x3704 runnable "GC task thread#7 (ParallelGC)" os_prio=0 tid=0x0000000002e15000 nid=0xeb0 runnable "VM Periodic Task Thread" os_prio=2 tid=0x0000000019f98000 nid=0xbbc waiting on condition JNI global references: 16
- 1.
sleep()方法的作用:让目前正在执行的线程休眠,让CPU去执行其他的任务,线程状态从执行状态变成限时阻塞状态TIMED_WAITING- 2.当线程睡眠满后,线程不一定会立即得到执行,因为此时
CPU可能正在执行其他的任务,线程首先进入就绪状态,等待分配CPU时间片以便有机会执行- 3.
sleep()方法定义在Thread类中,是静态本地方法,使用其他语言实现,且该方法会抛出InterruptedException受检异常- 4.因此如果调用
sleep()方法,就必须进行异常审查,捕获InterruptException异常或再次通过方法声明存在InterruptException受检异常- 5.
sleep()和wait()方法的区别
- 1.
sleep()是Thread类的静态本地方法;而wait()是Object类的本地方法- 2.
sleep()方法不会释放锁也不需要占用锁;而wait()方法必须在同步代码块或同步方法中使用,即当前线程必须拥有该对象的监视器,线程释放该监视器的所有权并等待,直到另一个线程通过调用notify()或notifyAll()方法通知等待该对象监视器的线程唤醒,然后线程等待直到可以重新获得监视器的所有权并继续执行,否则会抛出IllegalMonitorStateException

3.线程的interrupt操作
public void interrupt() { if (this != Thread.currentThread()) checkAccess(); synchronized (blockerLock) { Interruptible b = blocker; if (b != null) { interrupt0(); // Just to set the interrupt flag b.interrupt(this); return; } } interrupt0(); } public static boolean interrupted() { return currentThread().isInterrupted(true); } public boolean isInterrupted() { return isInterrupted(false); } private native boolean isInterrupted(boolean ClearInterrupted); private native void interrupt0();@Deprecated public final void stop() { SecurityManager security = System.getSecurityManager(); if (security != null) { checkAccess(); if (this != Thread.currentThread()) { security.checkPermission(SecurityConstants.STOP_THREAD_PERMISSION); } } // A zero status value corresponds to "NEW", it can't change to // not-NEW because we hold the lock. if (threadStatus != 0) { resume(); // Wake up thread if it was suspended; no-op otherwise } // The VM can handle all thread states stop0(new ThreadDeath()); } @Deprecated public final synchronized void stop(Throwable obj) { throw new UnsupportedOperationException(); } private native void stop0(Object o);
- 1.
Java提供了stop()方法终止正在运行的线程,但是stop()方法已过时不建议使用,因为使用stop()方法就像突然关闭计算机电源,可能会导致程序异常- 2.程序中不能随便中断一个线程的,因为无法知道这个线程正在什么状态,它可能持有某把锁,强行中断线程可能导致
锁不能释放的问题或线程可能在操作数据库,强行中断线程可能导致数据不一致的问题- 3.由于调用
stop()方法来终止线程可能会产生不可预料的结果,因此不推荐调用stop()方法- 4.线程什么时候可以退出只有线程自己知道,
Thread类的interrupt()方法可以中断线程,本质不是中断线程,而是设置中断标志
- 1.
interrupt():将调用该方法的对象所表示的线程设置一个中断标记,并不是真的停止该线程- 2.
interrupted():获取当前线程的中断状态,并且会清除线程的状态标记,如果当前线程被中断,则为true- 3.
isInterrupted():获取调用该方法的对象所表示的线程的中断状态,不会清除线程的状态标记,如果当前线程被中断,则为true- 5.当调用线程的
interrupt()方法时其作用
- 1.如果此线程处于
阻塞状态,就会立马退出阻塞,并抛出InterruptException异常,线程就可以通过捕获InterruptException来做一定的处理,然后让线程退出- 2.如果线程被
Object.wait(),Thread.join()和Thread.sleep()三种方法之一阻塞,此时调用该线程的interrupt()方法,该线程将抛出InterruptException中断异常,从而提早终结被阻塞状态- 3.如果此线程正处在运行中,线程就不受任何影响继续运行,仅仅是线程的中断标记被设置为
true,程序可以在适当地位置通过调用isInterrupted()方法来查看自己是否被中断,并执行退出操作- 6.注意
- 1.如果线程的
interrupt()方法先被调用,然后线程开始调用阻塞方法进入阻塞状态,InterruptedException异常依旧会抛出- 2.如果线程捕获
InterruptedException异常后继续调用阻塞方法,将不再触发InterruptedException异常package threadDemo; import java.util.concurrent.locks.LockSupport; public class InterruptedExceptionDemo1 { public static final int SLEEP_GAP = 5000;//睡眠时长5秒 public static final int MAX_TURN = 50;//睡眠次数,值稍微大点方便使用Jstack static class SleepThread extends Thread{ static int threadSeqNumber = 1; public SleepThread(){ super("sleepThread-" + threadSeqNumber); threadSeqNumber++; } public void run(){ try { System.out.println(getName() + "进入睡眠"); Thread.sleep(SLEEP_GAP); } catch (InterruptedException e) { e.printStackTrace(); System.out.println(getName() + "发生异常被中断"); return; } System.out.println(getName() + "运行结束"); } } public static void main(String[] args) { Thread sThread1 = new SleepThread(); sThread1.start(); Thread sThread2 = new SleepThread(); sThread2.start(); Thread sThread3 = new SleepThread(); sThread3.start(); sleepSeconds(2); sThread1.interrupt(); sleepSeconds(2); //sleepSeconds(5); sThread2.interrupt(); sleepSeconds(2); System.out.println("程序运行结束"); } public static void sleepSeconds(int millisecond){ LockSupport.parkNanos(millisecond * 1000L * 1000L * 1000L); } }
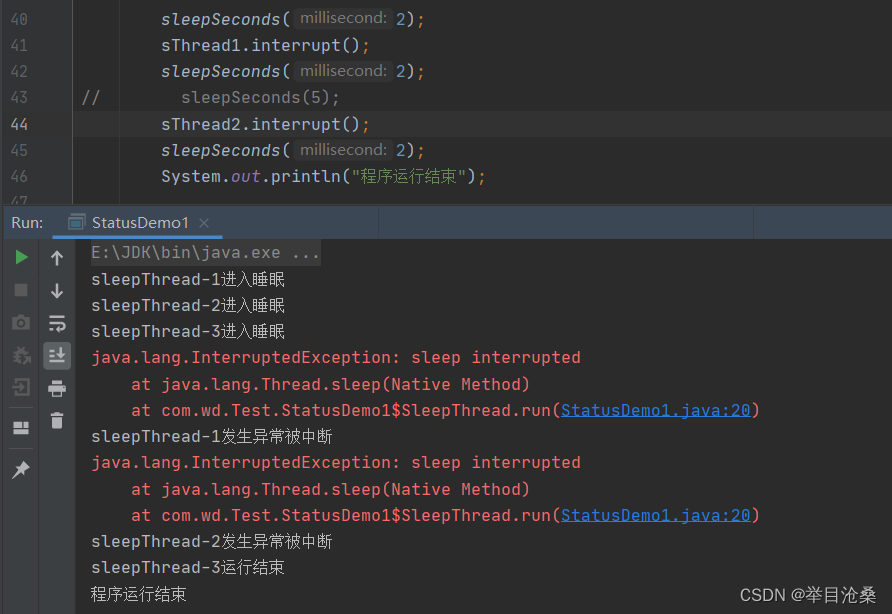
- 1.结果显示
sleepThread-1线程在睡眠了2秒后,被主线程中断,被打断的sleepThread-1线程停止睡眠,并捕获到InterruptedException受检异常,程序在异常处理时直接返回,其后面的执行逻辑被跳过- 2.
sleepThread-2线程在睡眠了7秒后,被主线程中断,但是在sleepThread-2线程被中断的时候,已经执行结束,所以thread2.interrupt()中断操作没有产生实质性的效果- 3.如果
interrupt()先于阻塞执行,当进入阻塞状态后会抛出异常,可以对整段代码捕获异常,捕获到异常后会直接跳到catch()部分,可以选择打印异常信息后return线程结束或不处理线程将继续执行- 4.导致阻塞状态的三种方式
- 1.
sleep()- 2.
wait()- 3.
join()- 5.上述代码中
interrupt本质是靠return结束处于阻塞状态的线程- 6.
Thread.interrupt()方法并不像Thread.stop()方法中止一个正在运行的线程,其作用是设置线程的中断标志,至于线程是死亡,等待新的任务还是继续运行至下一步,取决于这个程序本身,线程可不时地检测中断标志位从而做出响应
4.线程的join操作
//重载版本1:此方法会把当前线程变为TIMED_WAITING,直到被合并线程执行结束,或者等待被合并线程执行millis的时间 public final synchronized void join(long millis) throws InterruptedException { long base = System.currentTimeMillis(); long now = 0; if (millis < 0) { throw new IllegalArgumentException("timeout value is negative"); } if (millis == 0) { while (isAlive()) { wait(0); } } else { while (isAlive()) { long delay = millis - now; if (delay <= 0) { break; } wait(delay); now = System.currentTimeMillis() - base; } } } //重载版本2:此方法会把当前线程变为WAITING,直到被合并线程执行结束,或者等待被合并线程执行millis+nanos的时间 public final synchronized void join(long millis, int nanos) throws InterruptedException { if (millis < 0) { throw new IllegalArgumentException("timeout value is negative"); } if (nanos < 0 || nanos > 999999) { throw new IllegalArgumentException( "nanosecond timeout value out of range"); } if (nanos >= 500000 || (nanos != 0 && millis == 0)) { millis++; } join(millis); } //重载版本3:此方法会把当前线程变为TIMED_WAITING,直到被合并线程执行结束 public final void join() throws InterruptedException { join(0); }
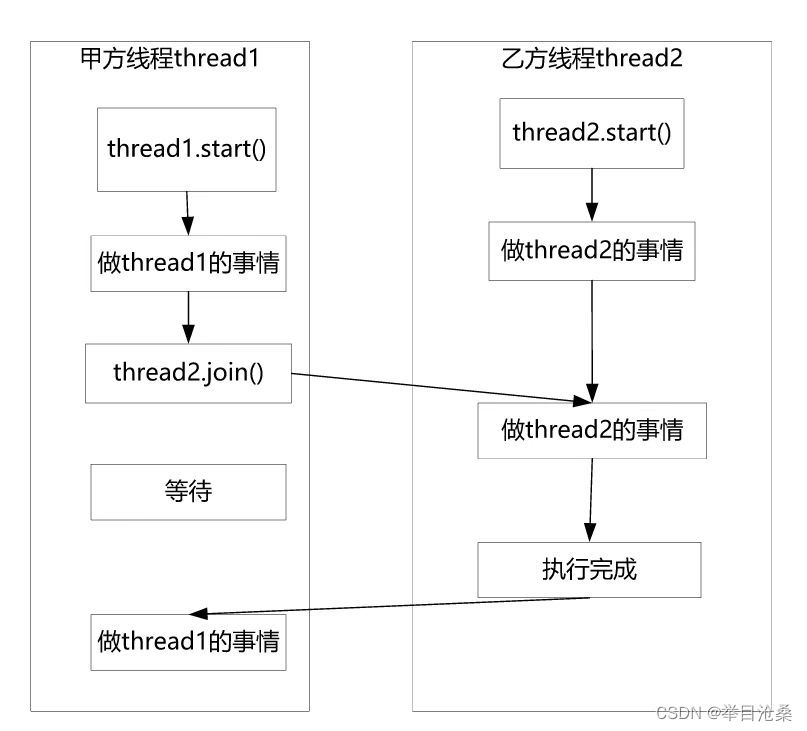
- 1.假设有两个线程
A和B,线程A在执行过程中对另一个线程B的执行有依赖- 2.具体的依赖为:线程
A需要将线程B的执行流程合并到自己的执行流程中,这就是线程合并,被动方线程B叫做被合并线程- 3.
join()方法是Thread类的一个实例方法,有三个重载版本,需要使用被合并线程的句柄(指针,引用)去调用- 4.执行
thread.join()代码的当前线程为合并线程,thread为被合并线程,合并线程进入WAITING状态让出CPU,被合并线程获得CPU进入RUNNABLE状态- 5.如果设置了
被合并线程的执行时间millis或millis+nanos,并不能保证当前线程一定会在millis时间后变为RUNNABLE,即并不意味着被合并线程在millis后会执行完毕释放CPU资源- 6.如果主动合并线程在等待时被中断,就会抛出
InterruptedException受检异常- 7.调用
jion()方法的语句可以理解为合并点,合并的本质是:调用wait()方法,线程A需要在合并点等待,一直等到线程B执行完成或等待超时- 8.将依赖线程
A叫作甲方线程,被依赖线程B叫做乙方线程,线程合并就是甲方线程调用乙方线程的jion()方法,执行流程上将乙方线程合并到甲方线程,甲方线程等待乙方线程执行完成后,甲方线程再继续执行- 9.调用
join()方法的优点:比较简单;缺点:join()方法没有办法直接取得乙方线程的执行结果
1.join线程的WAITING状态
- 1.线程
WAITING状态表示线程在等待被唤醒,处于WAITING状态的线程不会被分配CPU时间片- 2.执行以下两个操作当前线程将处于
WAITING状态
- 1.执行没有时限
timeout参数的thread.join(),线程合并场景中,若线程A调用B.join()去合入B线程,则在B执行期间线程A处于WAITING状态,一直等待线程B执行完成- 2.执行没有时限
timeout参数的object.wait(),指一个拥有object对象锁的线程,进入相应的代码临界区后,调用相应的object的wait()方法去等待其对象锁(Object Monitor)上的信号,若对象锁上没有信号,则当前线程处于WAITING状态
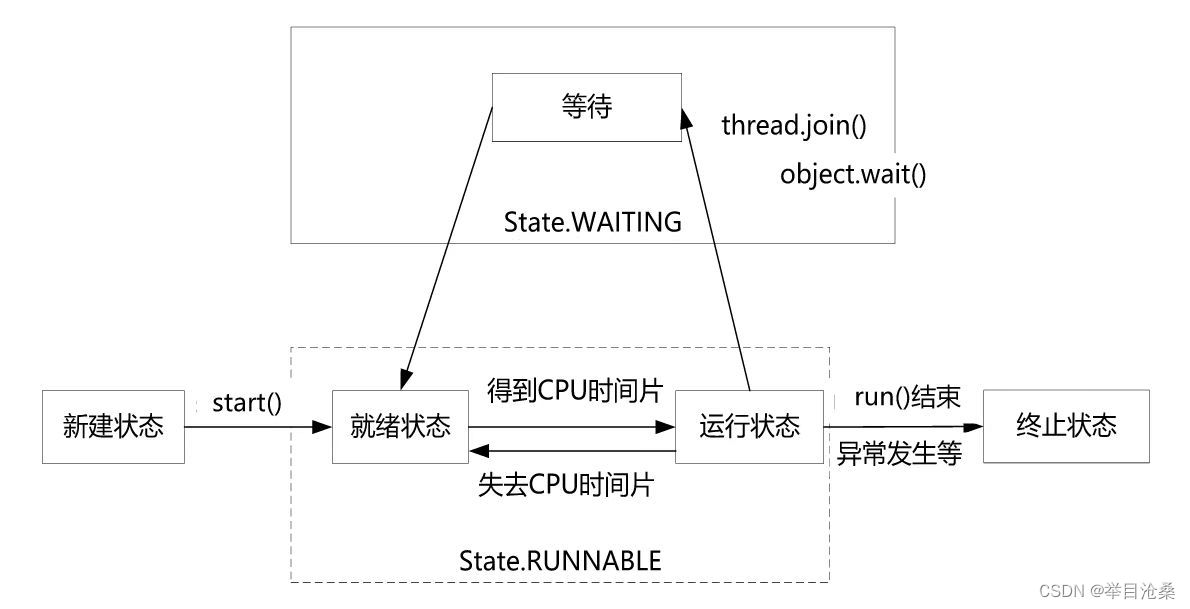
2.join线程的TIMED_WAITING状态
- 1.线程
TIMED_WAITING状态表示在等待唤醒,处于TIMED_WAITING状态的线程不会被分配CPU时间片,需要等待被唤醒或直到等待的时限到期- 2.线程合入场景中,若线程
A在调用B.join()操作时加入了时限参数,则在B执行期间线程A处于TIMED_WAITING状态,若B在等待时限内没有返回,则线程A结束等待TIMED_WAITING状态,恢复成RUNNABLE状态
5.线程的yield操作
public static native void yield();
- 1.线程的
yield操作作用:让目前正在执行的线程放弃当前的执行,让出CPU的执行权限,使得CPU去执行其他的线程,即让步- 2.处于
让步状态的JVM层面的线程状态仍然是RUNNABLE状态,但是该线程所对应的操作系统层面的线程从执行状态变成就绪状态- 3.线程
yield时,线程放弃和重占CPU的时间是不确定的,可能刚刚放弃CPU马上又获得CPU执行权限,重新开始执行- 4.
yield()方法是Thread类提供的一个静态本地方法,通过C++实现,可以让当前正在执行的线程暂停但不会阻塞该线程,只是让线程操作系统层面转入就绪状态- 5.注意:
- 1.
Java线程的RUNNABLE状态对应操作系统层级的线程状态包括就绪和运行,严格来讲Java线程并没有就绪和运行- 2.执行
yield()方法,操作系统层面:线程从运行状态进行就绪状态,但是jvm层面:线程还是处于runnable状态,因为Java线程的runnable状态对应操作系统的就绪状态和运行状态
1.yield实例
- 1.
yield操作仅能使一个线程从运行状态转到就绪状态,而不是阻塞状态- 2.
yield不能保证使得当前正在运行的线程迅速转换到就绪状态- 3.即使完成了迅速切换,系统通过
线程调度机制从所有就绪线程中挑选下一个执行线程时,就绪的线程有可能被选中,也有可能不被选中,其调度的过程受到其他因数(优先级)的影响- 4.线程调用
yield之后,操作系统在重新进行线程调度时偏向于将执行机会让给优先级高的线程package threadDemo; import java.util.HashMap; import java.util.Map; import java.util.concurrent.atomic.AtomicInteger; public class YieldDemo1 { public static final int MAX_TURN = 100;//执行次数 public static AtomicInteger index = new AtomicInteger(0);//执行编号 //记录线程的执行次数 public static Map<String,AtomicInteger> metric = new HashMap<>(); //输出线程的执行次数 private static void printMetric(){ System.out.println("metric = " + metric); } static class YieldThread extends Thread{ static int threadSeqNumber = 1; public YieldThread(){ super("sleepThread-" + threadSeqNumber); threadSeqNumber++; metric.put(this.getName(),new AtomicInteger(0)); } public void run(){ for (int i = 0; i < MAX_TURN && index.get() < MAX_TURN; i++) { System.out.println("线程优先级" + getPriority()); index.incrementAndGet(); metric.get(this.getName()).incrementAndGet(); if(i % 2 == 0){ Thread.yield(); } } printMetric(); System.out.println(getName() + "运行结束"); } } public static void main(String[] args) { Thread thread1 = new YieldThread(); thread1.setPriority(Thread.MAX_PRIORITY); Thread thread2 = new YieldThread(); thread2.setPriority(Thread.MIN_PRIORITY); System.out.println("启动线程"); thread1.start(); thread2.start(); } }
6.线程的daemon操作
/* Whether or not the thread is a daemon thread. */ private boolean daemon = false; private void init(ThreadGroup g, Runnable target, String name, long stackSize) { init(g, target, name, stackSize, null); } private void init(ThreadGroup g, Runnable target, String name, long stackSize, AccessControlContext acc) { if (name == null) { throw new NullPointerException("name cannot be null"); } this.name = name.toCharArray(); Thread parent = currentThread(); SecurityManager security = System.getSecurityManager(); if (g == null) { /* Determine if it's an applet or not */ /* If there is a security manager, ask the security manager what to do. */ if (security != null) { g = security.getThreadGroup(); } /* If the security doesn't have a strong opinion of the matter use the parent thread group. */ if (g == null) { g = parent.getThreadGroup(); } } /* checkAccess regardless of whether or not threadgroup is explicitly passed in. */ g.checkAccess(); /* * Do we have the required permissions? */ if (security != null) { if (isCCLOverridden(getClass())) { security.checkPermission(SUBCLASS_IMPLEMENTATION_PERMISSION); } } g.addUnstarted(); this.group = g; this.daemon = parent.isDaemon(); this.priority = parent.getPriority(); if (security == null || isCCLOverridden(parent.getClass())) this.contextClassLoader = parent.getContextClassLoader(); else this.contextClassLoader = parent.contextClassLoader; this.inheritedAccessControlContext = acc != null ? acc : AccessController.getContext(); this.target = target; setPriority(priority); if (parent.inheritableThreadLocals != null) this.inheritableThreadLocals = ThreadLocal.createInheritedMap(parent.inheritableThreadLocals); /* Stash the specified stack size in case the VM cares */ this.stackSize = stackSize; /* Set thread ID */ tid = nextThreadID(); } public final void setDaemon(boolean on) { checkAccess(); if (isAlive()) { throw new IllegalThreadStateException(); } daemon = on; } public final boolean isDaemon() { return daemon; }
- 1.
Java中的线程分为两类
- 1.
守护线程- 2.
用户线程- 2.守护线程:也称为
后台线程,指程序运行过程中在后台提供某种通用服务的线程(垃圾回收线程GC)- 3.守护线程是随着
JVM进程一同结束的,即在JVM的所有线程中守护线程是最后结束的- 4.只要
JVM实例中尚存在一个用户线程没有结束,守护线程就能执行自己的工作,只有当最后一个用户线程结束,守护线程随着JVM一同结束工作- 5.
Thread类中有专门的属性daemon(默认为false)和方法可以设置或判断是否守护线程,同时在构造函数初始化的init()方法中会对daemon进行初始化设置
1.daemon实例
package threadDemo; import static java.lang.Thread.currentThread; import static java.lang.Thread.sleep; public class DaemonDemo1 { public static final int SLEEP_GAP = 500;//每一轮的睡眠时长 public static final int MAX_TURN = 4;//用户线程执行轮次 static class DaemonThread extends Thread{ public DaemonThread(){ super("daemonThread"); } public void run(){ System.out.println("--daemon线程开始--"); for (int i = 1; ; i++) { System.out.println("--轮次:" + i); System.out.println("--守护状态为:" + isDaemon()); try { sleep(SLEEP_GAP); } catch (InterruptedException e) { e.printStackTrace(); } } } } public static void main(String[] args) { Thread daemonThread1 = new DaemonThread(); daemonThread1.setDaemon(true); daemonThread1.start(); Thread userThread = new Thread(() -> { System.out.println(">>用户线程开始"); for (int i = 1; i <= MAX_TURN; i++) { System.out.println(">>轮次:" + i); System.out.println(">>"+ Thread.currentThread() +"守护状态为:" + Thread.currentThread().isDaemon()); try { sleep(SLEEP_GAP); } catch (InterruptedException e) { e.printStackTrace(); } } System.out.println(">>用户线程结束"); },"userThread"); userThread.start(); System.out.println("守护状态为:" + currentThread().isDaemon()); System.out.println(currentThread() + "运行结束"); } }
- 1.上述代码创建了
2个线程
- 1.一个守护线程:名称为
daemonThread,通过继承Thread的方式创建- 2.一个用户线程,名称为
userThread,通过Lambda表达式新建一个Runnable实例传入Thread构造器来创建- 3.程序中使用
setDaemon(true)语句将daemonThread线程设置成守护线程,守护线程daemonThread的run()方法中设置了死循环,启动后理论上永远也不会停止- 4.结果显示
- 1.
main线程也是一条用户线程,main线程在创建和启动daemonThread和userThread后提前结束- 2.虽然
main线程结束,但是其他2个线程还在继续执行,其中userThread是用户线程,所以进程还不能结束- 3.当用户线程
userThread的run()方法执行完成后,userThread线程执行结束,这时所有的用户线程执行完成,JVM进程随之退出- 4.
JVM退出时守护线程daemonThread还在死循环的执行中并未结束,但是JVM会强行终止所有守护线程的执行- 5.当所有用户线程结束后,
JVM进程会强制结束进程内所有守护线程- 6.注意
- 1.守护线程必须在调用
start()方法启动前将其守护状态设置为true,启动之后不能再将用户线程设置为守护线程,否则JVM会抛出一个InterruptedException异常- 2.守护线程存在被
JVM强行终止的风险,所以守护线程中尽量不去访问系统资源(文件句柄,数据库连接等),守护线程被强行终止时可能会引发系统资源操作不负责任的中断从而导致资源不可逆的损坏- 3.守护线程创建的线程也是守护线程,创建之后如果通过调用
setDaemon(false)将新的线程显式地设置为用户线程,新的线程可调整为用户线程
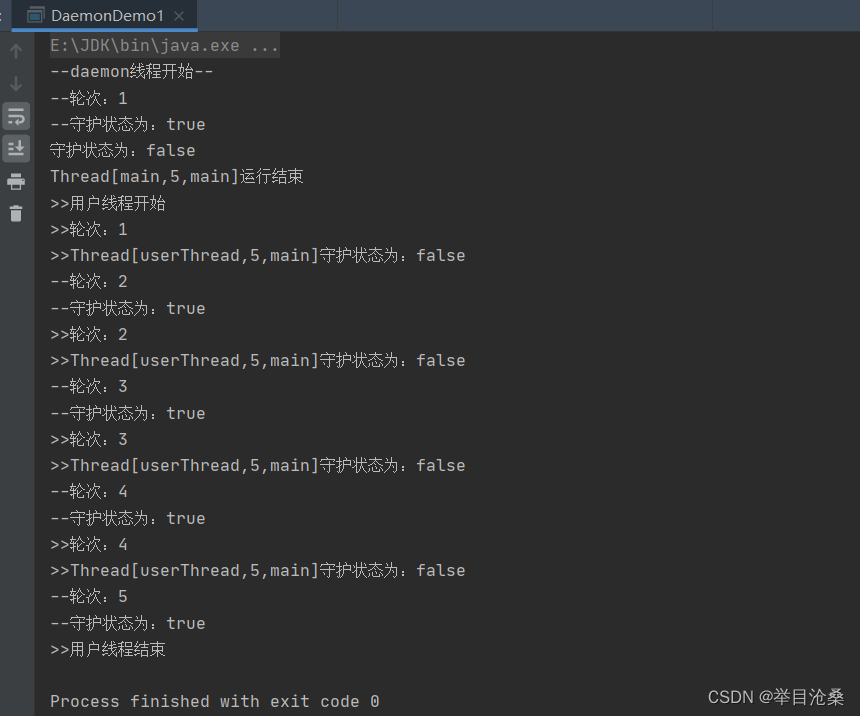
2.守护线程与用户线程的关系
- 1.从是否为守护线程的角度对
Java线程进行分类
- 1.
用户线程- 2.
守护线程- 2.守护线程和用户线程的本质区别:二者与
JVM虚拟机进程终止的方法不同

- 1.用户线程与
JVM进程是主动关系,如果用户线程全部终止JVM虚拟机进程也随之终止- 2.守护线程和
JVM进程是被动关系,如果JVM进程终止,所有的守护线程也随之终止
7.线程的notify操作
public final native void notify(); public final native void notifyAll();
- 1.
Java中提供了两种本地唤醒线程的操作,其位于Object类
- 1.
notify()方法
- 1.唤醒正在此对象的监视器上等待的单个线程
- 2.如果有线程正在等待此对象,则选择其中一个线程来唤醒,这种选择是任意的,是在执行过程中自行决定的
- 3.线程通过调用其中一个等待方法(
wait)来等待对象的监视器- 4.如果当前线程不是此对象监视器的所有者的话会抛出
IllegalMonitorStateException,即notify()方法同wait()方法一样必须在同步代码块或同步方法中使用- 5.当前线程放弃对该对象的锁之前,被唤醒的线程将无法继续,被唤醒的线程将以通常的方式与任何其他线程竞争
- 2.
notifyAll()方法
- 1.唤醒在该对象的监视器上等待的所有线程
- 2.线程通过调用其中一个等待方法(
wait)来等待对象的监视器- 3.如果当前线程不是此对象监视器的所有者的话会抛出
IllegalMonitorStateException,即notifyAll()方法同notify()方法一样必须在同步代码块或同步方法中使用- 4.当前线程放弃对该对象的锁之前,被唤醒的线程将无法继续,被唤醒的线程将以通常的方式与任何其他线程竞争
- 2.
notify()和notifyAll()的区别
- 1.
notify()唤醒一个正在等待该对象锁的线程,notifyAll()唤醒所有正在等待该对象锁的线程- 2.
notify()可能会导致死锁,而notifyAll()`则不会导致死锁- 3.
notify()和notifyAll()的区别另一种解释
- 1.
等待池:假设一个线程A调用了某个对象的wait()方法,线程A就会释放该对象的锁,进入到了该对象的等待池,等待池中的线程不会去竞争该对象的锁- 2.
锁池:只有获取了对象的锁,线程才能执行对象的synchronized代码,对象的锁每次只有一个线程可以获得,其他线程只能在锁池中等待- 3.
notify()方法随机唤醒对象的等待池中的一个线程进入锁池,而notifyAll()唤醒对象等待池中的所有线程进入锁池- 4.注意:
java中Thread类线程执行完run()方法后,一定会自动执行notifyAll()方法
1.线程间的通信
- 1.
线程通信:指当多个线程共同操作共享的资源时,互相告知自己的状态以避免资源争夺- 2.线程通信的方式
- 1.共享内存
- 1.
volatile共享内存- 2.具体可参考
Java SE的volatile- 2.消息传递
- 1.
wait/notify/notifyAll等待通知方式- 2.具体可参考上述内容
- 3.管道流
- 管道输入/输出流
8.线程的组操作
public class ThreadGroup implements Thread.UncaughtExceptionHandler { private final ThreadGroup parent; String name; int maxPriority; boolean destroyed; boolean daemon; boolean vmAllowSuspension; int nUnstartedThreads = 0; int nthreads; Thread threads[]; int ngroups; ThreadGroup groups[]; private ThreadGroup() { // called from C code this.name = "system"; this.maxPriority = Thread.MAX_PRIORITY; this.parent = null; } public ThreadGroup(String name) { this(Thread.currentThread().getThreadGroup(), name); } public ThreadGroup(ThreadGroup parent, String name) { this(checkParentAccess(parent), parent, name); } private ThreadGroup(Void unused, ThreadGroup parent, String name) { this.name = name; this.maxPriority = parent.maxPriority; this.daemon = parent.daemon; this.vmAllowSuspension = parent.vmAllowSuspension; this.parent = parent; parent.add(this); } }
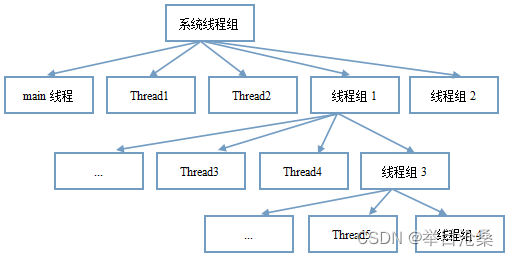
- 1.
Java中提供ThreadGroup类用于对线程组进行操作- 2.
线程组作用:可以批量管理线程或线程组对象,有效地对线程或线程组对象进行组织- 3.线程数组、线程池、线程组区分
- 1.线程数组是将线程放入数组中,方便做一些简单的操作
- 2.线程池的作用是减少线程频繁创建销毁的开销
- 3.线程组
ThreadGroup所维持的线程结构更像是树,提供了管理线程组的方法
- 4.线程组的方法
- 1.
getName():返回此线程组的名称- 2.
getParent():返回此线程组的父级- 3.
parentOf(ThreadGroup g):测试此线程组是否是其祖先线程组之一- 4.
interrupt():中断此线程组中的所有线程- 5.
setMaxPriority(int pri):设置组的最大优先级- 6.
getMaxPriority():返回此线程组的最大优先级- 7.
setDaemon(boolean daemon):更改此线程组的守护程序状态- 8.
isDaemon():测试此线程组是否是守护线程组- 9.
destroy():销毁此线程组及其所有子组, 此线程组必须为空,表示此线程组中的所有线程已停止,如果线程组不为空或线程组已被破坏,则抛出IllegalThreadStateException- 10.
isDestroyed():测试此线程组是否已被破坏- 11.
activeCount():返回此线程组及其子组中活动线程数的估计- 12.
activeGroupCount():返回此线程组及其子组中活动组数的估计- 13.
list():将有关此线程组的信息打印到标准输出
7.创建线程的4种方法
- 1.
Java进程中每一个线程都对应着一个Thread实例- 2.线程的描述信息在
Thread的实例属性中得到保存,供JVM进行线程管理和调度时使用- 3.虽然一个进程有很多个线程,但是单
CPU内核上,同一时刻只能有一个线程是正在执行,该线程也被叫做当前线程,可通过Thread.currentThread()获取- 4.
Thread类是Java多线程编程的基础,Java中创建线程虽然有3种方式,但是3种方式都会涉及Thread类
1.线程创建方法一:继承Thread类创建线程类
- 1.如果需要并发执行业务代码则按以下步骤
- 1.创建一个自定义类并继承
Thread类- 2.重写
run()方法并将需要并发执行的业务代码编写在run()方法中package threadDemo; public class ThreadDemo2 { // 最大轮循次数 public static final int MAX_TURN = 5; // 线程编号 public static int threadNo = 1; // 获取当前线程名称 public static String getCurThreadName(){ return Thread.currentThread().getName(); } public static void main(String[] args) { Thread thread = null; for (int i = 0; i < 2; i++) { thread = new DemoThread(); thread.start(); } System.out.println(getCurThreadName() + "运行结束"); } // 静态内部类,方便访问外部类的静态成员属性和方法 static class DemoThread extends Thread{ public DemoThread(){ super("DemoThread-"+threadNo++); } public void run(){ for (int i = 1; i < MAX_TURN; i++) { System.out.println(getName() + ",轮次:" + i); } System.out.println(getName() + "运行结束"); } } }
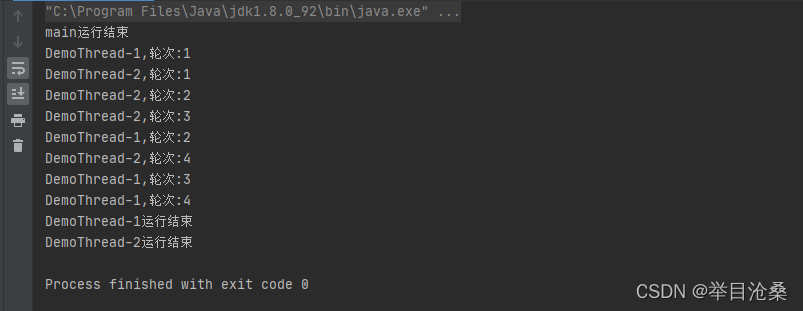
1.Thread类
public class Thread implements Runnable { /* Make sure registerNatives is the first thing <clinit> does. */ private static native void registerNatives(); static { registerNatives(); } private volatile char name[]; private int priority; private Thread threadQ; private long eetop; private boolean single_step; private boolean daemon = false; private boolean stillborn = false; private Runnable target; private ThreadGroup group; private ClassLoader contextClassLoader; private AccessControlContext inheritedAccessControlContext; private static int threadInitNumber; ThreadLocal.ThreadLocalMap threadLocals = null; ThreadLocal.ThreadLocalMap inheritableThreadLocals = null; private long stackSize; private long nativeParkEventPointer; private static long threadSeqNumber; private volatile int threadStatus = 0; volatile Object parkBlocker; private volatile Interruptible blocker; private final Object blockerLock = new Object(); public final static int MIN_PRIORITY = 1; public final static int NORM_PRIORITY = 5; public final static int MAX_PRIORITY = 10;
- 1.
Java中一个线程使用一个Thread实例来描述- 2.
Thread类的属性
- 1.
name:线程名称,- 2.
priority:线程优先级- 3.
Thread类的方法
- 1.
start()方法
- 1.启动一个线程,当调用
start()方法后,线程状态从New转换为Runnable,当获取到CPU时间片后会开始执行run()方法中的实际业务代码- 2.
run()方法
- 1.线程业务代码的入口方法,
run()方法不是由用户程序来调用的,当调用start()方法启动一个线程之后,只要线程获得了CPU执行时间,便进入run()方法体去执行具体的业务代码- 3.总结
- 1.
start()方法用于线程的启动,run()方法作为业务代码的执行入口- 2.
start()方法调用后线程并没有立即执行,而是等待CPU调度执行,一旦得到CPU的调度即获取了CPU的时间片后才会调用run()方法执行业务代码
2.线程创建方法二:实现Runnable接口创建线程目标类
@FunctionalInterface public interface Runnable { public abstract void run(); }/* What will be run. */ private Runnable target; ... @Override public void run() { if (target != null) { target.run(); } } ... public Thread(Runnable target) { init(null, target, "Thread-" + nextThreadNum(), 0); }
- 1.
Thread类的run()方法实际是重写Runnable接口中run()方法,如果Runnable类型的属性target不为空,则执行target属性的run()方法- 2.通过含有
Runnable类型的Thread构造方法传入Runnable类型target实例,然后直接通过实现Runnable的run()方法达到线程并发执行的目的- 3.
应用场景:单继承可以使用Thread类,多实现则可以采用Runnable接口- 4.
使用步骤
- 1.定义一个自定义类实现
Runnable接口- 2.重写
Runnable接口中的run()抽象方法,将业务代码写入其中- 3.通过
Thread类创建线程对象,将Runnable实例作为实际参数传递给Thread类的构造器,由Thread构造器将该Runnable实例赋值给其Runnable类型的target执行目标属性- 4.调用
Thread实例的start()方法启动线程- 5.线程启动后,线程
run()方法将被JVM执行,该run()方法将调用target属性的run()方法,从而完成Runnable实现类中业务代码的并发执行package threadDemo; import sun.misc.ThreadGroupUtils; public class ThreadDemo3 { // 最大轮循次数 public static final int MAX_TURN = 5; // 线程编号 public static int threadNo = 1; // 获取当前线程名称 public static String getCurThreadName(){ return Thread.currentThread().getName(); } public static void main(String[] args) { Thread thread = null; for (int i = 0; i < 2; i++) { RunTarget runTarget = new RunTarget(); thread = new Thread(runTarget,"RunnableThread"+threadNo++); thread.start(); } System.out.println(getCurThreadName() + "运行结束"); } // 静态内部类,方便访问外部类的静态成员属性和方法 static class RunTarget implements Runnable{ public void run(){ for (int i = 1; i < MAX_TURN; i++) { System.out.println(getCurThreadName() + ",轮次:" + i); } System.out.println(getCurThreadName() + "运行结束"); } } }- 5.说明
- 1.静态内部类
RunTarget执行目标类不再继承Thread线程类而是实现Runnable接口并重写run()方法- 2.实现
Runnable接口与继承Thread类方法实现异步执行的区别
- 1.通过实现
Runnable接口的方式创建的执行目标类,如果需要访问线程的任何属性和方法,必须通过Thread.currentThread()获取当前的线程对象,通过当前线程对象间接访问- 2.而通过继承
Thread类的方式创建的线程类,可以在子类中直接调用Thread父类的方法访问当前线程的名称、状态等信息
1.Runnable接口
@FunctionalInterface public interface Runnable { public abstract void run(); }
- 1.
Runnable接口有且仅有一个抽象run()方法- 2.
Runnable接口上声明了@FunctionalInterface注解,该注解标记Runnable接口是一个函数式接口,因此接口实现时可以使用Lambda表达式提供匿名实现- 3.将业务逻辑代码编写在
Runnable实现类的run()的实现版本中,当Runnble实例传入Thread实例的target属性后,Runnable接口的run()的实现版本将被异步调用- 4.如果直接调用
Thread.run()方法就变成同步方法,而不是异步处理方式- 5.通过调用线程类的
start()方法启动一个线程,使线程处于就绪状态即可以被JVM来调度执行,调用过程中JVM通过调用线程类的run()方法执行实际的业务代码,当run()方法结束后线程就会终止- 6.如果直接调用线程类的
run()方法会被当做一个普通的函数调用,程序中任然只有主线程这一个线程,即start()方法能够异步的调用run()方法,但直接调用run()方法却是同步的无法达到多线程的目的
2.创建Runnable线程目标类的两种方式
- 1.实现
Runnable接口创建线程目标类除了直接实现Runnable接口外,还有两种比较优雅的代码组织方式
- 1.通过
匿名内部类创建Runnable线程目标类//如果target实现类是一次性类,可以使用匿名实例的形式 package threadDemo; public class ThreadDemo4 { // 最大轮循次数 public static final int MAX_TURN = 5; // 线程编号 public static int threadNo = 1; // 获取当前线程名称 public static String getCurThreadName(){ return Thread.currentThread().getName(); } public static void main(String[] args) { Thread thread = null; for (int i = 0; i < 2; i++) { // 通过编写匿名类的实现代码直接创建一个Runnable类型的匿名target执行目标对象 thread = new Thread(new Runnable() { public void run() { for (int i = 1; i < MAX_TURN; i++) { System.out.println(getCurThreadName() + ",轮次:" + i); } System.out.println(getCurThreadName() + "运行结束"); } },"RunnableThread" + threadNo++); thread.start(); } System.out.println(getCurThreadName() + "运行结束"); } }
- 2.通过
Lambda表达式创建Runnable线程目标类package threadDemo; public class ThreadDemo5 { // 最大轮循次数 public static final int MAX_TURN = 5; // 线程编号 public static int threadNo = 1; // 获取当前线程名称 public static String getCurThreadName(){ return Thread.currentThread().getName(); } public static void main(String[] args) { Thread thread = null; for (int i = 0; i < 2; i++) { // 通过编写匿名类的实现代码直接创建一个Runnable类型的匿名target执行目标对象 thread = new Thread(() -> { for (int j = 1; j < MAX_TURN; j++) { System.out.println(getCurThreadName() + ",轮次:" + j); } System.out.println(getCurThreadName() + "运行结束"); },"RunnableThread" + threadNo++); thread.start(); } System.out.println(getCurThreadName() + "运行结束"); } }
3.Runnable接口创建线程目标类的优缺点
- 1.缺点
- 1.所创建类并不是线程类,而是线程的
target执行目标类,需要将其实例作为参数传入线程类的构造器,才能创建真正的线程- 2.如果访问当前线程的属性,不能直接访问
Thread实例方法,必须通过Thread.currentThread()获取当前线程实例,才能访问和控制当前线程- 2.优点:
- 1.可以避免由于
Java单继承带来的局限性,如果异步逻辑类已经继承了一个基类,就没有办法再继承Thread类,所以在已经存在继承关系的情况下,只能使用实现Runnable接口的方式- 2.逻辑和数据更好分离,通过实现
Runnable接口的方式创建多线程更适合同一个资源被多段业务逻辑并行处理的场景- 3.同一个资源被多个线程逻辑异步并行处理的场景中,通过实现
Runnable接口的方式设计多个target执行目标类可以更加方便,清晰地将执行逻辑和数据存储分离,更好地体现面向对象的设计思想
4.线程安全问题
- 1.通过继承
Thread类实现多线程能更好地做到多个线程并发地完成各自的任务,访问各自的数据资源- 2.通过实现
Runnable接口实现多线程能更好地做到多个线程并发地完成同一个任务,访问同一份数据资源
- 1.创建多个线程但每个线程共享同一个
Runnable接口,从而对该对象的操作也是共享的- 2.需要多线程操作同一个对象实例时可以采用这种方法,同时需要注意数据一致性,这样可以将线程逻辑和业务数据进行有效的分离
- 3.通过实现
Runnable接口实现多线程时,如果数据资源存在多线程共享的情况,那么数据共享资源需要使用原子类型而非普通数据类型或需要进行线程的同步控制,以保证对共享数据操作时不会出现线程安全问题package threadDemo; import java.util.concurrent.atomic.AtomicInteger; public class ThreadDemo6 { public static final int MAX_AMOUNT = 50; // 商品数量 public static void main(String[] args) throws InterruptedException { System.out.println("商店版本的销售"); for (int i = 1; i <= 3; i++) { Thread thread = new StoreGoods("店员" + i); thread.start(); } System.out.println("商场版本的销售"); MallGoods mallGoods = new MallGoods(); for (int i = 1; i <= 4; i++) { Thread thread = new Thread(mallGoods,"商场销售员" + i); thread.start(); } System.out.println(Thread.currentThread().getName() + "运行结束."); } // 商店商品类(销售线程类)一个商品一个销售线程,每个线程异步销售4次 static class StoreGoods extends Thread{ private int goodsAmount = MAX_AMOUNT; StoreGoods(String name){ super(name); } @Override public void run(){ for (int i = 0; i <= MAX_AMOUNT; i++) { if(this.goodsAmount > 0){ System.out.println(getName() + "卖出一件,还剩:" + (--goodsAmount)); } } System.out.println(getName() + "运行结束"); } } // 商场商品类(target销售线程的目标类),一个商品最多销售4次,可以多人销售 static class MallGoods implements Runnable{ // 多人销售可能导致数据出错,使用原子数据类型保障数据安全 private final AtomicInteger goodsAmount = new AtomicInteger(MAX_AMOUNT); @Override public void run() { for (int i = 0; i <= MAX_AMOUNT; i++) { test(); } System.out.println(Thread.currentThread().getName() + "运行结束"); } // 注意需要加同步锁,否则会同时有多人同时销售同一个商品,导致数据错误 public synchronized void test(){ if (this.goodsAmount.get() > 0) { System.out.println(Thread.currentThread().getName() + "卖出一件,还剩:" + (goodsAmount.decrementAndGet())); } } } }
3.线程创建方法三:使用Callable和FutureTask创建线程
- 1.继承
Thread类或实现Runnable接口两种方式创建线程类共同的缺点:不能获取异步执行的结果- 2.因为两者本质都是重写
run()方法,而run()方法不支持返回值- 3.为了解决异步执行的结果问题,
Java在1.5版本之后提供了一种新的多线程创建方式
- 1.通过
Callable接口和FutureTask类相结合创建线程
1.Callable接口
@FunctionalInterface public interface Callable<V> { V call() throws Exception; }
- 1.
Callable接口位于java.util.concurrent包中- 2.
Callable接口是一个泛型接口也是一个函数式接口- 3.其唯一抽象方法
call()有返回值,还有一个Exception受检异常声明,允许方法的实现版本的内部异常直接抛出不予捕获- 4.
Callable接口和Runnable接口的区别
- 1.
Runnable接口的唯一抽象方法run()没有返回值也没有受检异常的异常声明,而Callable接口的唯一抽象方法call()方法有返回值,并且声明了受检异常- 2.
Runnale接口实例作为Thread线程实例的target进行使用,而Callable接口实例不可作为Thread线程实例的target进行使用
- 因为
Thread类的target属性的类型为Runnable,而Callable接口与Runnable接口时间没有任何继承关系,所以Callable接口实例没办法作为Thread线程实现的target使用- 5.
Callable接口与Thread线程之间存在一个桥梁是RunnableFuture接口
2.Future接口
public interface Future<V> { boolean cancel(boolean mayInterruptIfRunning);// 取消异步执行 boolean isCancelled();// 判断异步任务是否在完成前被取消。如果任务完成前被取消,就返回true boolean isDone();// 判断异步任务是否执行完成 V get() throws InterruptedException, ExecutionException;// 获取异步任务完成后的执行结果 V get(long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException;// 设置时限,获取异步任务完成后的执行结果 }
- 1.
Future接口位于java.util.concurrent包中,是一个泛型接口- 2.
Future接口至少提供了三大功能
- 1.能够取消异步执行中的任务
- 2.判断异步任务是否执行完成
- 3.获取异步任务完成后的执行结果
- 3.
Future提供对异步任务进行交互操作的接口,JDK提供了一个默认的实现类FutureTask- 4.
Futrue接口抽象方法
- 1.
get()方法
- 1.获取异步任务执行的结果,该方法的调用是阻塞性的
- 2.如果异步任务没有执行完成,异步结果获取线程(调用线程)会一直被阻塞,一直阻塞到异步任务执行完成,其异步结果返回给调用线程
- 2.
get(long timeout, TimeUnit unit)方法
- 1.调用线程阻塞性地获取异步任务执行地结果,但调用线程会有一个阻塞时长限制,不会无限制地阻塞和等待
- 2.如果其阻塞时间超过设定时间
timeout,该方法将抛出异常,调用线程可捕获此异常
3.RunnableFuture接口
public interface RunnableFuture<V> extends Runnable, Future<V> { void run(); }
- 1.
RunnableFuture接口位于java.util.concurrent包中,是一个泛型接口- 2.
RunnableFuture接口继承了Runnable和Future两个接口从而实现两个目标
- 1.可以作为
Thread线程实例的target:RunnableFuture继承Runnable接口,保证其实例可作为Thread线程实例的target- 2.可以获取异步执行的结果:
RunnableFuture继承Future接口,保证其实例可获取未来的异步执行结果
4.FutureTask类
public class FutureTask<V> implements RunnableFuture<V> { private volatile int state; private static final int NEW = 0; private static final int COMPLETING = 1; private static final int NORMAL = 2; private static final int EXCEPTIONAL = 3; private static final int CANCELLED = 4; private static final int INTERRUPTING = 5; private static final int INTERRUPTED = 6; private Callable<V> callable; private Object outcome; private volatile Thread runner; private volatile WaitNode waiters; @SuppressWarnings("unchecked") private V report(int s) throws ExecutionException { Object x = outcome; if (s == NORMAL) return (V)x; if (s >= CANCELLED) throw new CancellationException(); throw new ExecutionException((Throwable)x); } public FutureTask(Callable<V> callable) { if (callable == null) throw new NullPointerException(); this.callable = callable; this.state = NEW; // ensure visibility of > callable } public FutureTask(Runnable runnable, V result) { this.callable = Executors.callable(runnable, result); this.state = NEW; // ensure visibility of callable } public boolean isCancelled() { return state >= CANCELLED; } public boolean isDone() { return state != NEW; } public boolean cancel(boolean mayInterruptIfRunning) { if (!(state == NEW && UNSAFE.compareAndSwapInt(this, stateOffset, NEW, mayInterruptIfRunning ? INTERRUPTING : CANCELLED))) return false; try { // in case call to interrupt throws exception if (mayInterruptIfRunning) { try { Thread t = runner; if (t != null) t.interrupt(); } finally { // final state UNSAFE.putOrderedInt(this, stateOffset, INTERRUPTED); } } } finally { finishCompletion(); } return true; } public V get() throws InterruptedException, ExecutionException { int s = state; if (s <= COMPLETING) s = awaitDone(false, 0L); return report(s); } public V get(long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException { if (unit == null) throw new NullPointerException(); int s = state; if (s <= COMPLETING && (s = awaitDone(true, unit.toNanos(timeout))) <= COMPLETING) throw new TimeoutException(); return report(s); } protected void done() { } public void run() { if (state != NEW || !UNSAFE.compareAndSwapObject(this, runnerOffset, null, Thread.currentThread())) return; try { Callable<V> c = callable; if (c != null && state == NEW) { V result; boolean ran; try { result = c.call(); ran = true; } catch (Throwable ex) { result = null; ran = false; setException(ex); } if (ran) set(result); } } finally { // runner must be non-null until state is settled to // prevent concurrent calls to run() runner = null; // state must be re-read after nulling runner to prevent // leaked interrupts int s = state; if (s >= INTERRUPTING) handlePossibleCancellationInterrupt(s); } } protected void set(V v) { if (UNSAFE.compareAndSwapInt(this, stateOffset, NEW, COMPLETING)) { outcome = v; UNSAFE.putOrderedInt(this, stateOffset, NORMAL); // final state finishCompletion(); } }
- 1.
FutureTask类是RunnableFuture接口的实现类,提供对异步任务操作的具体实现- 2.
FutureTask类中有一个Callable类型的callable属性,用来保存并发执行的Callable类型的任务,并且callable属性需要在FutureTask实例构造时初始化- 3.
FutureTask类实现了Runnable接口,其run()方法的中会执行callable属性的call()方法- 4.
FuntureTask类中有一个Object类型的outcome属性,用来保存callable属性的call()方法的异步执行结果- 5.
FutureTask类的run()方法执行callable属性的call()方法之后,将其结果保存在outcome实属性中,通过get()方法获取
5.Callable和FutrueTask创建线程的具体步骤
- 1.通过
FutureTask类和Callable接口联合使用可以创建能够获取异步执行结果的线程
- 1.创建一个
Callable接口的自定义实现类并实现其Call方法,可以有返回值- 2.使用
Callable实现类的实例构建一个FutureTask实例- 3.使用
FutureTask实例作为Thread构造器的target入参,构造新的Thread线程实例- 4.调用
Thread实例的start()方法启动新线程,启动新线程的run()方法并发执行- 5.其内部的执行过程:启动
Thread实例的run()方法并发执行后会执行FutureTask实例的run()方法,最终会并发执行Callable实现类的call()方法- 6.调用
FutureTask对象的get()方法阻塞性地获得并发线程地执行结果
6.Callable和FutrueTask创建线程的实例
package threadDemo; import java.util.concurrent.Callable; import java.util.concurrent.ExecutionException; import java.util.concurrent.FutureTask; public class ThreadDemo7 { public static final int MAX_TURN = 5; public static final int COMPUTE_TIMES = 100000000; public static void main(String[] args) throws InterruptedException, ExecutionException { ReturnableTask returnableTask = new ReturnableTask(); FutureTask<Long> longFutureTask = new FutureTask<>(returnableTask); Thread thread = new Thread(longFutureTask, "returnableThread"); thread.start(); Thread.sleep(500); System.out.println(Thread.currentThread().getName() + "让子弹飞会!"); System.out.println(Thread.currentThread().getName() + "做一点自己地事情!"); for (int i = 0; i < COMPUTE_TIMES/2; i++) { int j = i * 10000; } System.out.println(Thread.currentThread().getName() + "获取并发任务地执行过程"); System.out.println(thread.getName() + "线程占用时间:" + longFutureTask.get()); System.out.println(Thread.currentThread().getName() + "运行结束."); } static class ReturnableTask implements Callable<Long> { @Override public Long call() throws Exception { long startTime = System.currentTimeMillis(); System.out.println(Thread.currentThread().getName() + "线程运行开始."); Thread.sleep(1000); for (int i = 0; i < COMPUTE_TIMES; i++) { int j = i * 1000; } long usedTime = System.currentTimeMillis() - startTime; System.out.println(Thread.currentThread().getName() + "线程运行结束."); return usedTime; } } }
- 1.上述代码中创建了两个线程
- 1.执行
main()方法的主线程- 2.通过
thread.start()方法启动的returnableThread线程,该线程是以FutureTask实例作为target的Thread线程- 2.上述代码执行流程
- 1.首先执行
main主线程- 2.然后
main主线程通过thread.start()方法启动returnableThread线程- 3.
main主线程继续执行,ruturnableThread线程开始并发执行- 4.
returnableThread线程首先执行thread.run()方法,然后会执行到其target(futureTask实例)的run()方法- 5.接着
futureTask.run()方法中执行futureTask的callable属性的call()方法- 6.最后
FuntureTask的Callable属性的call()方法执行完成后会将结果保存在FutrueTask的outcome属性中- 7.到此异步
returnnableThread线程执行完毕,main线程处理完自己的事情后通过futureTask的get()方法获取异步执行结果- 3.获取结果的两种情况
- 1.情况一
- 1.
callable.call()执行完成,futureTask的结果outcome不为空,此时futrueTask.get()会直接取回outcome结果返回给main主线程- 2.情况二
- 1.
callable.call()还没执行完,futureTask的结果outcome为空,此时main主线程作为结果获取线程会被阻塞,一直阻塞到callable.call()执行完成- 2.当执行完成后,最终结果会保存到
outcome中,futrueTask会唤醒main主线程去获取callable.call()执行结果- 3.注意:如果
callable.call()方法执行完后返回值为null,这种情况并不会阻塞,因为其只和状态有关而和返回的具体值无关
4.线程创建方法四:通过线程池创建线程
- 1.上述所创建的
Thread实例执行完成之后都进行了销毁,这些线程实例都不可复用- 2.实际创建一个线程实例时间成本,资源耗费都很高,高并发的场景中不能
频繁进行线程实例的创建和销毁,而是需要对以已经创建好的线程实例进行复用,因此需要使用线程池- 3.线程池会维护指定数量的活跃可用线程,避免了重复创建造成的资源浪费
- 4.
Java中和线程池相关的主要接口和类
- 1.
Executor接口- 2.
ExecutorService接口- 3.
Executors类- 3.
ThreadPoolExecutor类
1.Executor接口
package java.util.concurrent; public interface Executor { void execute(Runnable command); }
- 1.
Exector接口位于JUC包中,其是一个顶层接口并只声明了一个方法execute(Runnable)- 2.
execute(Runnable)方法
- 1.接收
Runnable对象作为参数,并且以异步的方式执行,该命令可以在一个新线程中,一个池线程中或调用线程中执行,由Executor实现决定
2.ExecutorService接口
package java.util.concurrent; import java.util.List; import java.util.Collection; public interface ExecutorService extends Executor { // 启动有序关机,其中执行先前提交的任务,但不接受新任务。如果调用已经关闭,则没有额外的效果 void shutdown(); // 尝试停止所有正在执行的任务,停止对等待任务的处理,并返回等待执行的任务列表,此方法不等待正在执行的任务终止,而是使用awaitTermination来完成 List<Runnable> shutdownNow(); // 如果执行器已关闭,则返回true boolean isShutdown(); boolean isTerminated(); boolean awaitTermination(long timeout, TimeUnit unit) throws InterruptedException; // 提交一个返回值的任务以供执行,并返回表示该任务的挂起结果的Future。Future的get方法将在任务成功完成时返回任务的结果 <T> Future<T> submit(Callable<T> task); Future<?> submit(Runnable task); <T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks) throws InterruptedException; <T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit) throws InterruptedException; <T> T invokeAny(Collection<? extends Callable<T>> tasks) throws InterruptedException, ExecutionException; <T> T invokeAny(Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException; }
- 1.
ExecutorService接口位于JUC包中,其继承Executor接口,因此继承了父接口的execute()抽象方法
- 2.
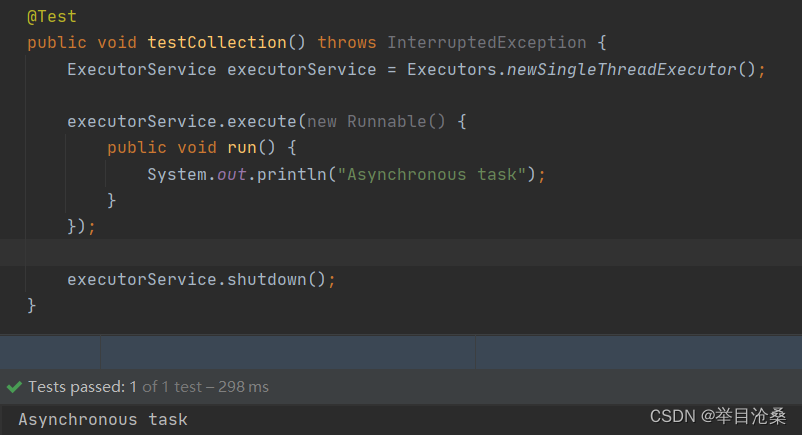
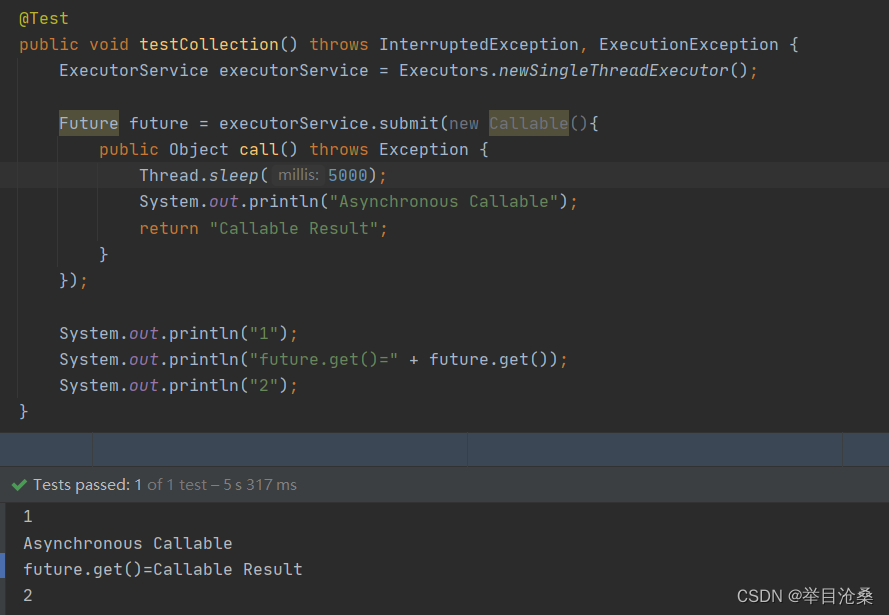
submit(Runnable task)方法
- 1.接收一个
Runnable的实现作为参数并返回一个Future对象- 2.该
Future对象可用于判断Runnable是否结束执行,因为其get()方法是阻塞执行- 3.因为
sleep()方法需要抛出受检异常,所以通过@SneakyThrows进行捕获,其中的@SneakyThrows注解可参考https://blog.csdn.net/qq_22162093/article/details/115486647
- 3.
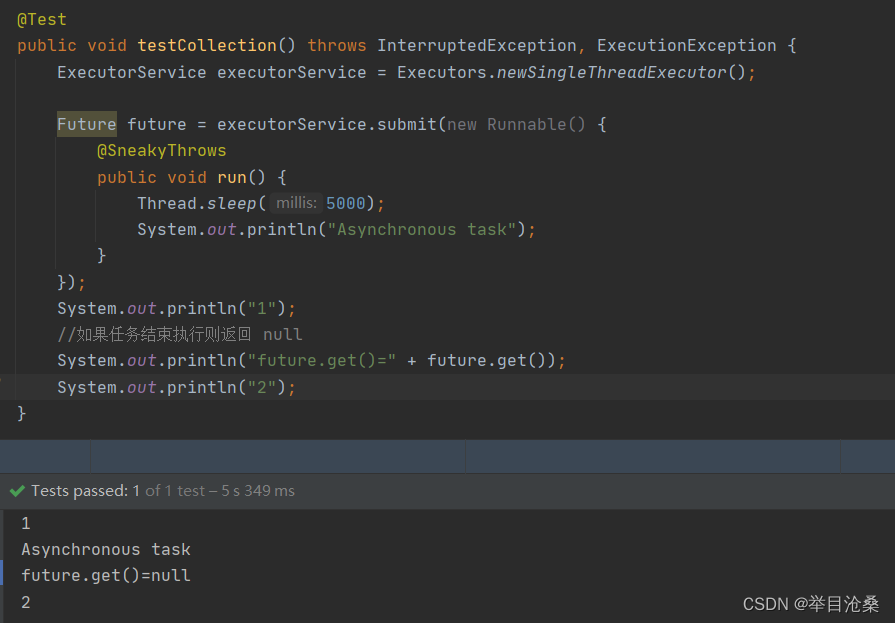
submit(Callable< T > task)方法
- 1.类似
submit(Runnable task)方法,区别在于接收不同的参数类型- 2.
Callable的call()方法可以返回结果且可以抛出异常,Runnable的run()方法不能返回结果也不能抛出异常- 3.
Callable的返回值可以从返回的Future对象中获取
- 4.
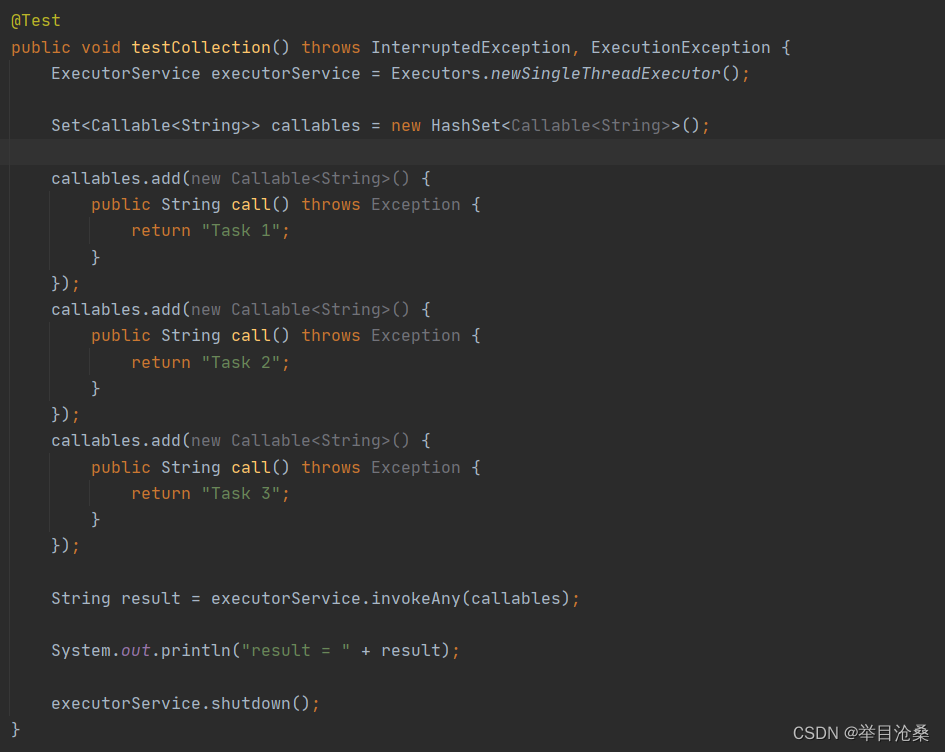
inVokeAny()方法
- 1.接收一个包含
Callable对象的集合作为参数- 2.调用该方法不会返回
Future对象,而是返回集合中某一个Callable对象的结果- 3.无法保证调用之后返回的结果属于哪个
Callable,只知道属于该Callable 集合中的一个执行结束的Callable对象- 4.如果一个任务运行完毕或抛出异常则会取消其它的
Callable的执行
- 5.
invokeAll()方法
- 1.接收一个包含
Callable对象的集合作为参数- 2.调用参数集合中的所有
Callable对象,并且返回一个包含Future对象的集合,通过该集合来管理每个Callable的执行结果- 3.注意:任务有可能因为异常而导致运行结束,所以可能并不是真的成功运行,但是没有办法通过
Future对象来感知到这个差异- 6.
ExecuteService的关闭
- 1.使用
ExecutorService完毕之后应该关闭它,这样才能保证线程不会继续保持运行状态- 2.如果程序通过
main()方法启动并且主线程退出了程序,如果还有活动的ExecutorService存在程序中则程序将会继续保持运行状态,存在于ExecutorService中的活动线程会阻止Java虚拟机关闭- 3.为了关闭在
ExecutorService中的线程可以调用shutdown()方法,ExecutorService并不会马上关闭所,而是不再接收新的任务,一旦所有的线程结束执行当前任务,ExecutorServie才会真的关闭,所有在调用shutdown()方法之前提交到ExecutorService的任务都会执行- 4.如果希望立即关闭
ExecutorService可以调用shutdownNow()方法,该方法会尝试马上关闭所有正在执行的任务,并且跳过所有已经提交但是还没有运行的任务,但是对于正在执行的任务,是否能够成功关闭它是无法保证的,有可能真的被关闭掉了也有可能会一直执行到任务结束
3.Executors类
public class Executors { public static ExecutorService newFixedThreadPool(int nThreads) { return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()); } public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory) { return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>(), threadFactory); } public static ExecutorService newWorkStealingPool(int parallelism) { return new ForkJoinPool (parallelism, ForkJoinPool.defaultForkJoinWorkerThreadFactory, null, true); } public static ExecutorService newWorkStealingPool() { return new ForkJoinPool (Runtime.getRuntime().availableProcessors(), ForkJoinPool.defaultForkJoinWorkerThreadFactory, null, true); } public static ExecutorService newSingleThreadExecutor() { return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>())); } public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) { return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>(), threadFactory)); } public static ExecutorService newCachedThreadPool() { return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>()); } public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) { return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>(), threadFactory); } public static ScheduledExecutorService newSingleThreadScheduledExecutor() { return new DelegatedScheduledExecutorService (new ScheduledThreadPoolExecutor(1)); } public static ScheduledExecutorService newSingleThreadScheduledExecutor(ThreadFactory threadFactory) { return new DelegatedScheduledExecutorService (new ScheduledThreadPoolExecutor(1, threadFactory)); } public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) { return new ScheduledThreadPoolExecutor(corePoolSize); } public static ScheduledExecutorService newScheduledThreadPool( int corePoolSize, ThreadFactory threadFactory) { return new ScheduledThreadPoolExecutor(corePoolSize, threadFactory); } public static ThreadFactory defaultThreadFactory() { return new DefaultThreadFactory(); } public static ThreadFactory privilegedThreadFactory() { return new PrivilegedThreadFactory(); } public static <T> Callable<T> callable(Runnable task, T result) { if (task == null) throw new NullPointerException(); return new RunnableAdapter<T>(task, result); } public static Callable<Object> callable(Runnable task) { if (task == null) throw new NullPointerException(); return new RunnableAdapter<Object>(task, null); } /** Cannot instantiate. */ private Executors() {} }
- 1.
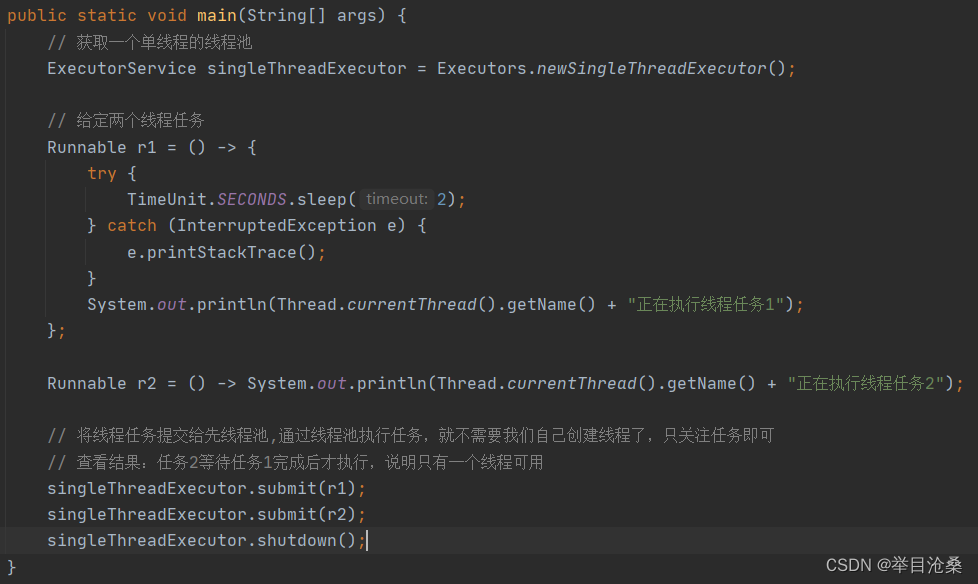
Java中提供了Executors类,其采用工厂设计模式,相当于一个线程池工厂(注意:是线程池工厂而不是线程工厂),提供了多种不同的线程池可供直接使用,即创建线程池的方法都是静态方法可以直接使用类名调用就能获取- 2.
newSingleThreadExecutor
- 1.创建一个单线程的线程池,返回类型为
ExecutorService- 2.其本质是调用
ThreadPoolExecutor类的构造方法并固定线程数为1
- 3.
newFixedThreadPool
- 1.创建一个指定数量的线程池,返回类型为
ExecutorService- 2.其本质是调用
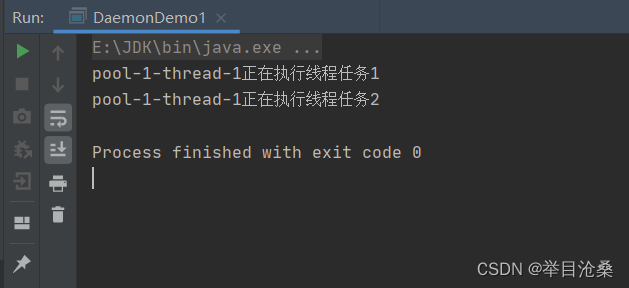
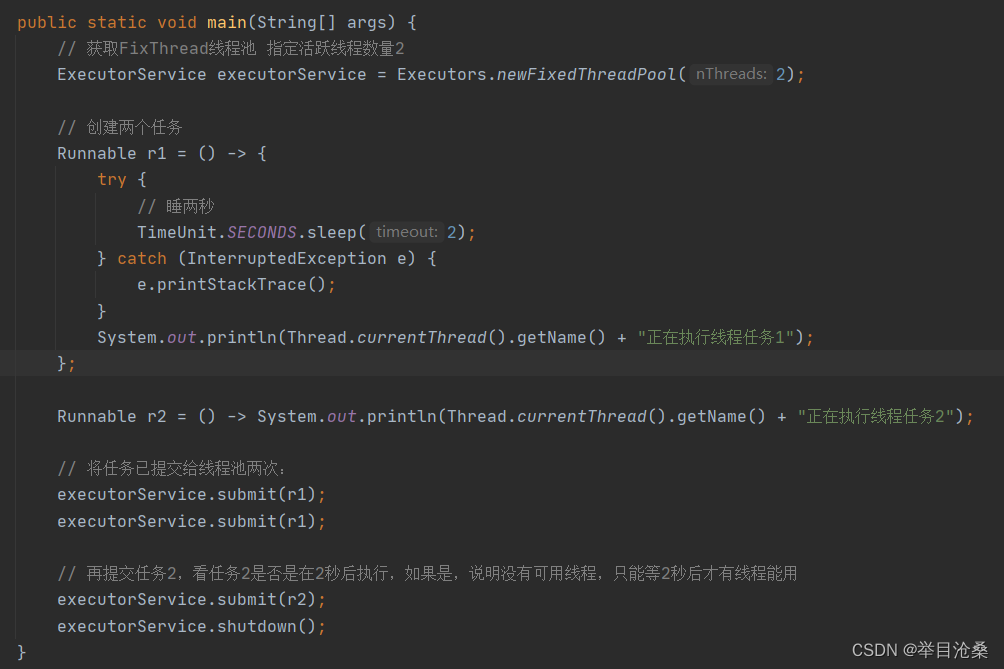
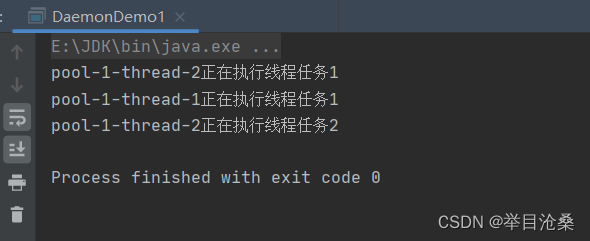
ThreadPoolExecutor类的构造方法并指定线程数- 3.当线程池中有可用线程,提交的任务就会立即执行,当前线程中没有可用线程,则会将任务放入到一个队列中直到有线程可用
- 4.
newCachedThreadPool
- 1.创建一个可缓存的线程池,返回类型为
ExecutorService- 2.其本质是调用
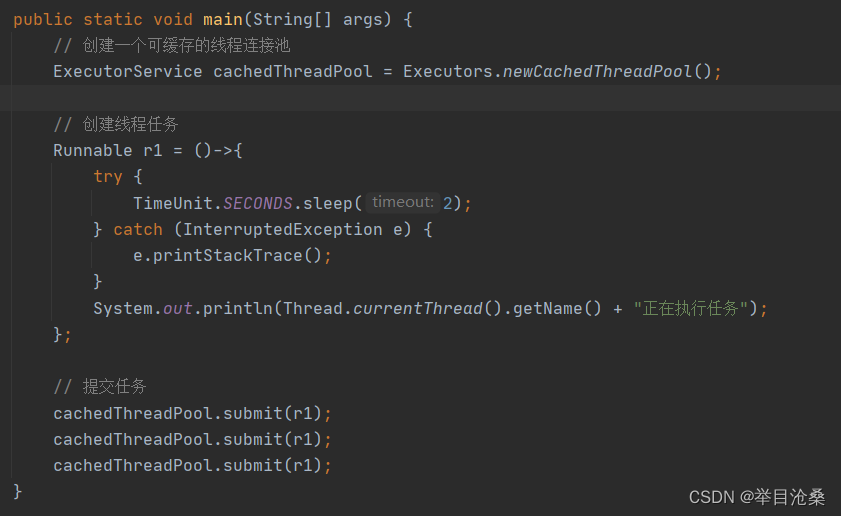
ThreadPoolExecutor类的构造方法- 3.该线程池不对线程的数量做限制,只要有线程任务没有线程来处理,就会创建一个线程,同时该线程池有一个回收的功能,如果某个线程超过
60秒还没有任务,就会被自动回收掉
- 5.
newScheduledThreadPool
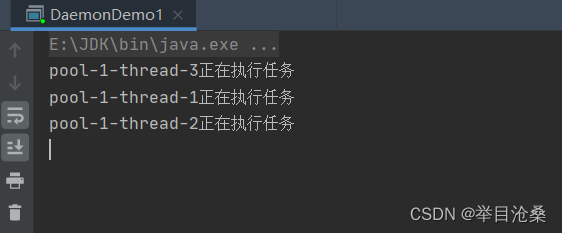
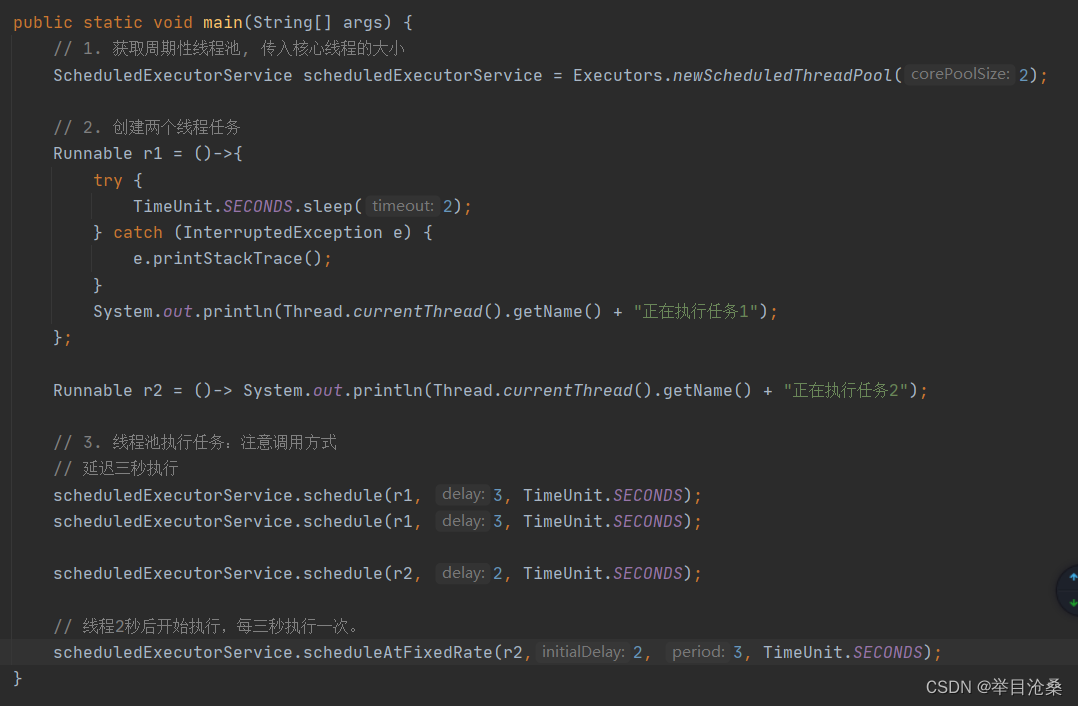
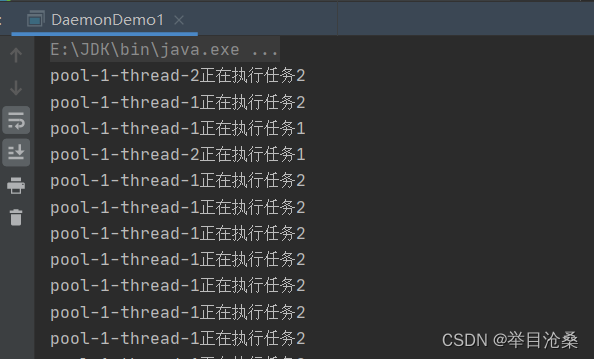
- 1.创建一个可用于执行周期性任务的线程池,返回类型为
ScheduledExecutorService- 2.其本质是调用
ScheduledThreadPoolExecutor类的构造方法
- 6.
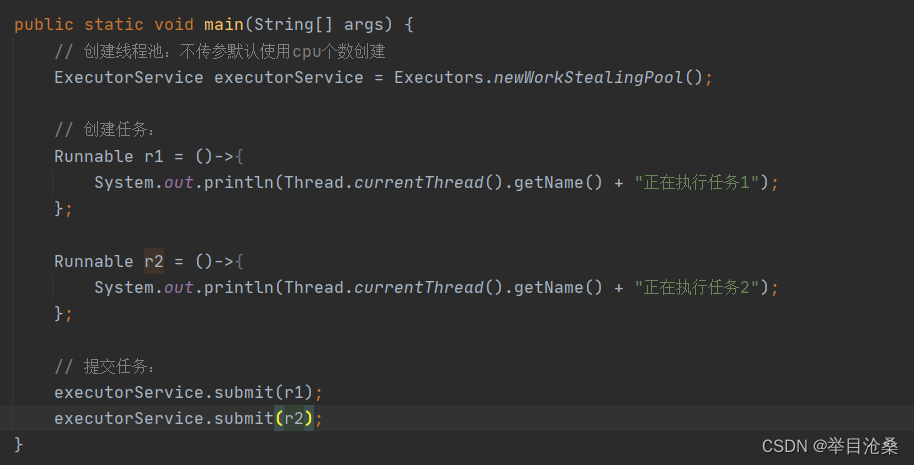
newWorkStealingPool
- 1.创建了一个抢占式的线程池,返回类型为
ExecutorService- 2.其本质是调用
ForkJoinPool类的构造方法- 3.
ForkJoinPool是JDK7引入的一种新线程池,同ThreadPoolExecutor一样也继承AbstractExecutorService抽象类- 4.
ForkJoinPool使用一个无限队列来保存需要执行的任务,线程的数量可通过构造函数传入,如果没有传入则当前计算机可用的CPU数量会被设置为线程数量作为默认值- 5.
ForkJoinPool能够实现工作窃取(Work Stealing),该线程池的每个线程中会维护一个队列来存放需要被执行的任务,当线程自身队列中的任务都执行完毕后,会从别的线程中拿到未被执行的任务并帮助执行- 6.
newWorkStealingPool会创建一个含有足够多线程的线程池来维持相应的并行级别,通过工作窃取的方式使得多核的CPU不会闲置,总会有活着的线程让CPU去运行
4.ThreadPoolExecutor类
public class ThreadPoolExecutor extends AbstractExecutorService { private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0)); // 线程池线程数的bit数,其中Integer.SIZE = 32,所以COUNT_BITS = 29 private static final int COUNT_BITS = Integer.SIZE - 3; // 线程池中最大线程容量 private static final int CAPACITY = (1 << COUNT_BITS) - 1; // runState is stored in the high-order bits // 接受新任务并处理排队任务 private static final int RUNNING = -1 << COUNT_BITS; // 不接受新任务,而是处理已排队的任务 private static final int SHUTDOWN = 0 << COUNT_BITS; // 不接受新任务,不处理排队的任务,不中断正在进行的任务 private static final int STOP = 1 << COUNT_BITS; // 所有任务都已终止,workerCount为零,转换到TIDYING状态的线程将运行terminated()钩子方法 private static final int TIDYING = 2 << COUNT_BITS; // 已完成 private static final int TERMINATED = 3 << COUNT_BITS; // Packing and unpacking ctl // 获取线程池地运行状态 private static int runStateOf(int c) { return c & ~CAPACITY; } // 获取有效工作线程地数量 private static int workerCountOf(int c) { return c & CAPACITY; } // 组装线程数量和线程池状态 private static int ctlOf(int rs, int wc) { return rs | wc; } private static boolean runStateLessThan(int c, int s) { return c < s; } private static boolean runStateAtLeast(int c, int s) { return c >= s; } private static boolean isRunning(int c) { return c < SHUTDOWN; } private boolean compareAndIncrementWorkerCount(int expect) { return ctl.compareAndSet(expect, expect + 1); } private boolean compareAndDecrementWorkerCount(int expect) { return ctl.compareAndSet(expect, expect - 1); } private void decrementWorkerCount() { do {} while (! compareAndDecrementWorkerCount(ctl.get())); } private final BlockingQueue<Runnable> workQueue; private final ReentrantLock mainLock = new ReentrantLock(); private final HashSet<Worker> workers = new HashSet<Worker>(); private final Condition termination = mainLock.newCondition(); private int largestPoolSize; private volatile ThreadFactory threadFactory; private volatile RejectedExecutionHandler handler; private volatile long keepAliveTime; private volatile boolean allowCoreThreadTimeOut; private volatile int corePoolSize; private volatile int maximumPoolSize; private static final RejectedExecutionHandler defaultHandler = new AbortPolicy(); private static final RuntimePermission shutdownPerm = new RuntimePermission("modifyThread"); public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue) { this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, Executors.defaultThreadFactory(), defaultHandler); } public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory) { this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, threadFactory, defaultHandler); } public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, RejectedExecutionHandler handler) { this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, Executors.defaultThreadFactory(), handler); } public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) { if (corePoolSize < 0 || maximumPoolSize <= 0 || maximumPoolSize < corePoolSize || keepAliveTime < 0) throw new IllegalArgumentException(); if (workQueue == null || threadFactory == null || handler == null) throw new NullPointerException(); this.corePoolSize = corePoolSize; this.maximumPoolSize = maximumPoolSize; this.workQueue = workQueue; this.keepAliveTime = unit.toNanos(keepAliveTime); this.threadFactory = threadFactory; this.handler = handler; }public void execute(Runnable command) { if (command == null) throw new NullPointerException(); int c = ctl.get(); // 1.工作线程数量 < corePoolSize => 直接创建线程执行任务 if (workerCountOf(c) < corePoolSize) { if (addWorker(command, true)) return; c = ctl.get(); } // 工作线程数量 >= corePoolSize && 线程池处于运行状态 => 将任务添加至阻塞队列中workQueue.offer(command) if (isRunning(c) && workQueue.offer(command)) { int recheck = ctl.get(); /** * 为什么需要double check线程池地状态? * 1.往阻塞队列中添加任务地时候,有可能阻塞队列已满,需要等待其他的任务移出队列,在这个过程中,线程池的状态可能会发生变化,所以需要doublecheck * 2.如果在往阻塞队列中添加任务地时候,线程池地状态发生变化,则需要将任务remove */ if (! isRunning(recheck) && remove(command)) reject(command); else if (workerCountOf(recheck) == 0) addWorker(null, false); } else if (!addWorker(command, false)) reject(command); } private boolean addWorker(Runnable firstTask, boolean core) { retry: for (;;) { int c = ctl.get(); int rs = runStateOf(c); // Check if queue empty only if necessary. // 线程池状态处于非RUNNING状态,添加worker失败 if (rs >= SHUTDOWN && ! (rs == SHUTDOWN && firstTask == null && ! workQueue.isEmpty())) return false; // 判断线程池中线程数量是否处于该线程池允许的最大线程数量,如果允许创建线程,则cas更新线程池中线程数量,并退出循环检查,执行下面创建线程地逻辑 for (;;) { int wc = workerCountOf(c); if (wc >= CAPACITY || wc >= (core ? corePoolSize : maximumPoolSize)) return false; if (compareAndIncrementWorkerCount(c)) break retry; c = ctl.get(); // Re-read ctl if (runStateOf(c) != rs) continue retry; // else CAS failed due to workerCount change; retry inner loop } } boolean workerStarted = false; boolean workerAdded = false; Worker w = null; try { // 创建线程 w = new Worker(firstTask); final Thread t = w.thread; if (t != null) { final ReentrantLock mainLock = this.mainLock; mainLock.lock(); try { // Recheck while holding lock. // Back out on ThreadFactory failure or if // shut down before lock acquired. int rs = runStateOf(ctl.get()); // 如果线程池处于RUNNING状态,并且线程已经启动则提前抛出线程异常启动异常 if (rs < SHUTDOWN || (rs == SHUTDOWN && firstTask == null)) { if (t.isAlive()) // precheck that t is startable throw new IllegalThreadStateException(); // 将线程加入已创建地线程集合,更新用于追踪线程池中线程数量largestPoolSize字段 workers.add(w); int s = workers.size(); if (s > largestPoolSize) largestPoolSize = s; workerAdded = true; } } finally { mainLock.unlock(); } // 启动线程执行任务 if (workerAdded) { // 启动线程会调用Worker中地runWorker()来执行任务 t.start(); workerStarted = true; } } } finally { if (! workerStarted) addWorkerFailed(w); } return workerStarted; } final void reject(Runnable command) { handler.rejectedExecution(command, this); } final void runWorker(Worker w) { // 获取执行任务线程 Thread wt = Thread.currentThread(); // 获取执行任务 Runnable task = w.firstTask; // 将的任务置空 w.firstTask = null; w.unlock(); // allow interrupts boolean completedAbruptly = true; try { while (task != null || (task = getTask()) != null) { w.lock(); // If pool is stopping, ensure thread is interrupted; // if not, ensure thread is not interrupted. This // requires a recheck in second case to deal with // shutdownNow race while clearing interrupt // 双重检查线程池是否正在停止,如果线程池停止,并且当前线程能够中断,则中断线程 if ((runStateAtLeast(ctl.get(), STOP) || (Thread.interrupted() && runStateAtLeast(ctl.get(), STOP))) && !wt.isInterrupted()) wt.interrupt(); try { // 前置执行任务钩子函数 beforeExecute(wt, task); Throwable thrown = null; try { // 执行当前任务 task.run(); } catch (RuntimeException x) { thrown = x; throw x; } catch (Error x) { thrown = x; throw x; } catch (Throwable x) { thrown = x; throw new Error(x); } finally { // 后置执行任务钩子函数 afterExecute(task, thrown); } } finally { task = null; w.completedTasks++; w.unlock(); } } completedAbruptly = false; } finally { // 回收线程 processWorkerExit(w, completedAbruptly); } }
- 1.
ThreadPoolExecutor类是Java提供用于创建线程池的类,ThreadPoolExecutor继承AbstractExecutorService抽象类,且其中封装了一个内部类Worker作为工作线程,每个Worker中都维持着一个Thread- 2.
《阿里巴巴-Java开发手册》中规定不要使用Executors创建线程池而是通过ThreadPoolExecutor创建,该方式可以明确线程池的运行规则,规避资源耗尽的风险- 3.
ThreadPoolExecutor中使用AtomicInteger类型的ctl属性描述线程池的运行状态和线程数量,通过ctl的高三位来表示线程池的5种状态,低29位表示线程池中现有的线程数量,使用最少的变量来减少锁竞争,提高并发效率
- 4.
ThreadPoolExecutor构造函数中各个参数含义
- 1.
int corePoolSize:线程池的核心线程数,决定是创建新的线程来处理提交的任务还是将其放入缓存队列
- 1.创建了线程池后,默认情况下线程池中并没有任何线程,而是等待有任才创建线程去执行任务
- 2.当线程池中的线程数目达到
corePoolSize后,就会把到达的任务放到缓存队列workQueue中- 2.
int maximumPoolSize:线程池的最大线程数,决定是创建非核心线程来处理提交的任务还是执行拒绝策略
- 1.当线程池中的线程数目达到
corePoolSize后,会判断线程数是否达到maximumPoolSize- 2.当线程池中的线程数目达到
maximumPoolSize后,就会执行拒绝策略,否则会创建非核心线程来执行缓存队列workQueue中的任务- 3.
long keepAliveTime:线程空闲时存活的时间
- 1.当任务执行完后,线程池中空闲线程数量增多,当超过
corePoolSize时,非核心的线程会在指定时间keepAliveTime被销毁- 2.默认情况下只有当线程池中的线程数大于
corePoolSize时,keepAliveTime才会起作用,即当线程池中的线程数大于corePoolSize时,如果一个线程空闲的时间达到keepAliveTime则会终止,直到线程池中的线程数不超过corePoolSize- 3.
allowCoreThreadTimeOut属性表示是否回收核心工作线程,默认false表示不回收核心线程,使用allowCoreThreadTimeOut(true)方法可以设置线程池回收核心线程,如果调用allowCoreThreadTimeOut(boolean)方法,线程池中的线程数不大于corePoolSize时,keepAliveTime参数也会起作用,直到线程池中的线程数为0- 4.
TimeUnit unit:空闲存活时间单位,即参数keepAliveTime的时间单位,其值是TimeUnit枚举类- 5.
BlockingQueue<Runnable> workQueue:任务队列,用于存放已提交但尚未被执行的任务
- 1.一般分为直接提交队列、有界任务队列、无界任务队列、优先任务队列
- 2.本质是一个阻塞队列
BlockingQueue,用来存储等待执行的任务,线程池的排队策略与workQueue有关- 3.阻塞队列有以下几种选择
- 1.
SynchronousQueue:直接提交队列- 2.
ArrayBlockingQueue:有界任务队列- 3.
LinkedBlockingQueue:无界任务队列- 4.
PriorityBlockingQueue:优先级队列- 6.
ThreadFactory threadFactory:线程工厂,用于创建线程执行任务,一般用默认即可,默认使用Executors.defaultThreadFactory()- 7.
RejectedExecutionHandler handler:拒绝策略,当线程池中的线程数达到maximumPoolSize时,使用某种策略来拒绝任务提交,本质是ThreadPoolExecutor的内部类并且实现了RejectedExecutionHandler接口
- 1.
ThreadPoolExecutor.AbortPolicy:默认策略,丢弃任务并抛出拒绝执行RejectedExecutionException异常- 2.
ThreadPoolExecutor.DiscardPolicy:丢弃任务但是不抛出异常- 3.
ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面(最老)的任务然后重新尝试执行任务(重复此过程)- 4.
ThreadPoolExecutor.CallerRunsPolicy:交由调用线程处理该任务- 5.
自定义拒绝策略:扩展RejectedExecutionHandler接口,自定义拒绝策略
- 8.其他可参考
https://juejin.cn/post/6987576686472593415和https://blog.csdn.net/fighting_yu/article/details/89473175
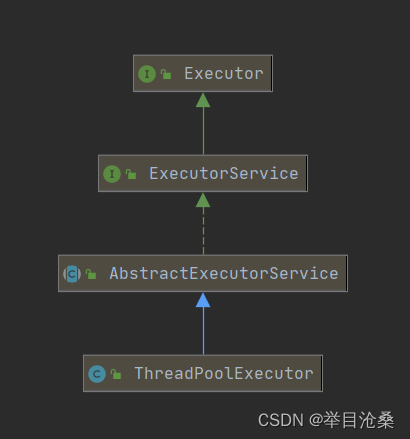
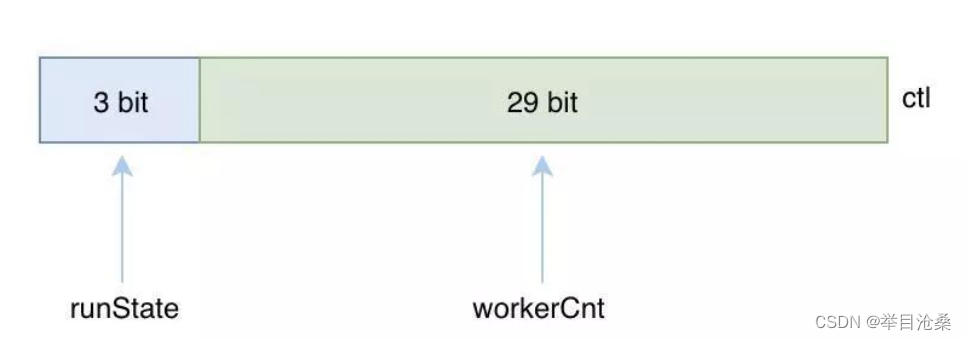
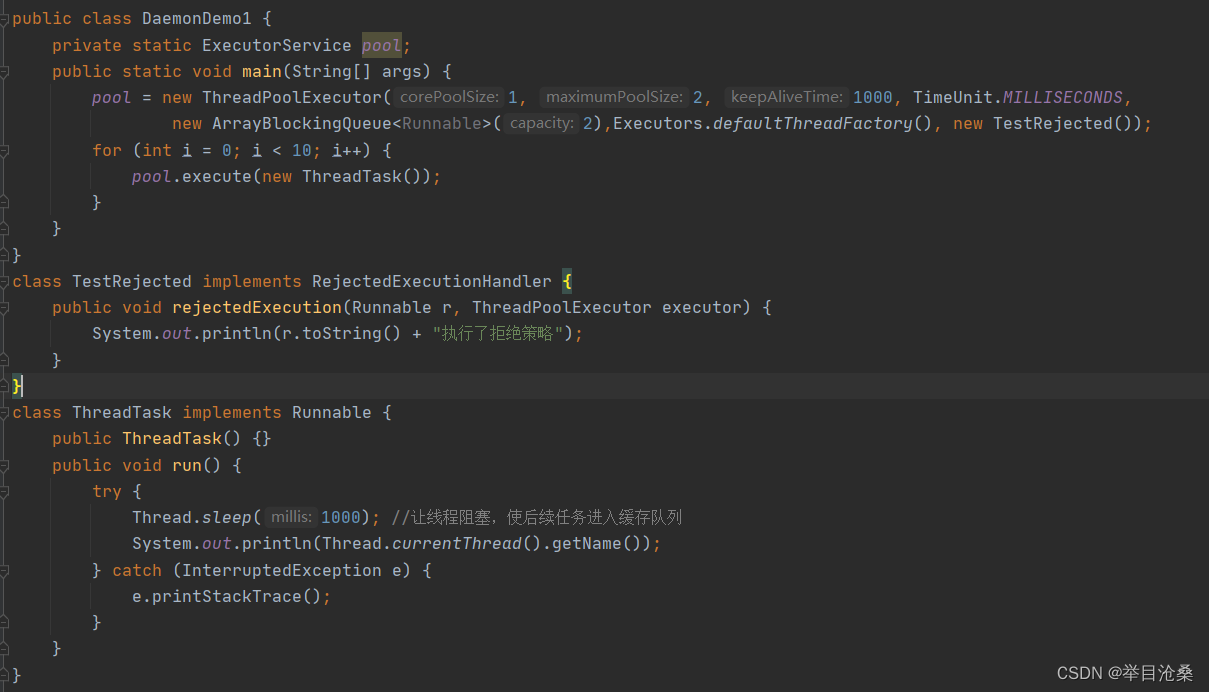
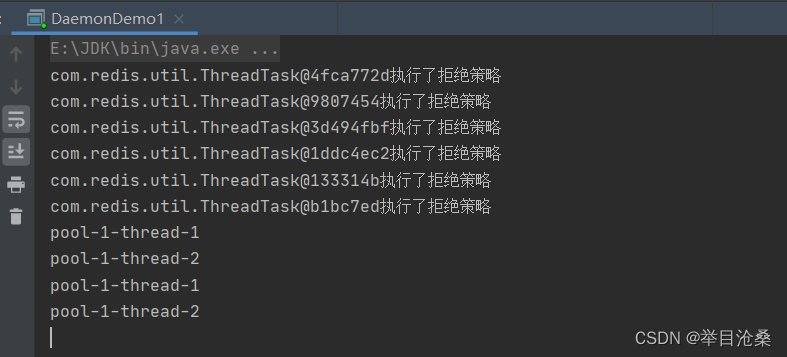
1.直接提交队列
- 1.
SynchronousQueue:直接提交队列,也称为同步队列- 2.
SynchronousQueue:一个特殊的BlockingQueue,其没有容量,每执行一个插入操作就会阻塞,需要在执行一个删除操作才会被唤醒,反之每一个删除操作也都要等待对应的插入操作- 3.上述结果显示当任务队列为
SynchronousQueue,创建的线程数大于maximumPoolSize时,直接执行了拒绝策略抛出异常- 4.使用
SynchronousQueue队列时提交的任务不会被保存,而是马上提交执行- 5.如果用于执行任务的线程数量小于等于
maximumPoolSize,则尝试创建新的进程,如果达到maximumPoolSize设置的最大值,则根据设置的handler执行拒绝策略- 6.因此该方式提交的任务不会被缓存起来而是会被马上执行,这种情况下,需要对程序的并发量有准确的评估,才能设置合适的
maximumPoolSize数量,否则容易会执行拒绝策略
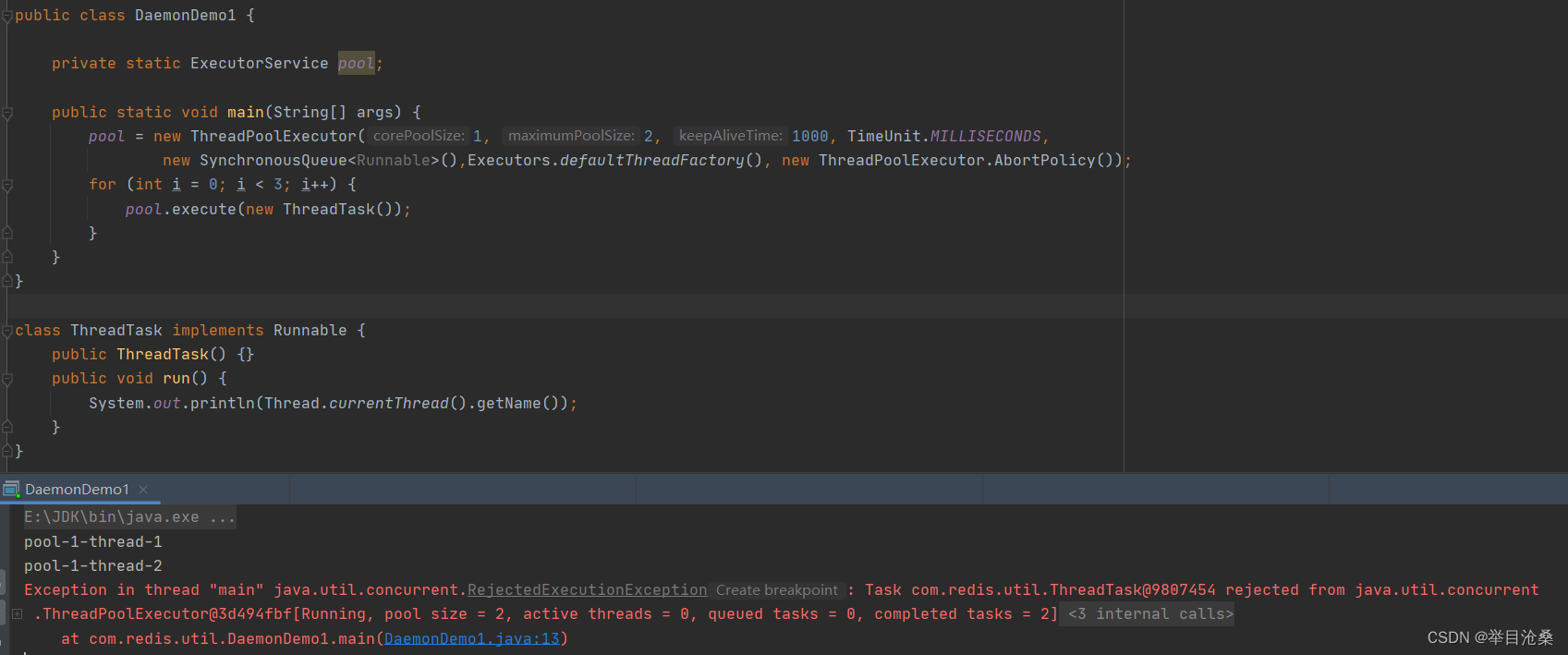
2.有界任务队列
- 1.
ArrayBlockingQueue:有界任务队列- 2.上述结果显示当任务队列为
ArrayBlockingQueue,若有新的任务需要执行时,线程池会创建新的线程,直到创建的线程数量达到corePoolSize时,则会将新的任务加入到等待队列中- 3.若等待队列已满,即超过
ArrayBlockingQueue初始化的容量,则继续创建线程,直到线程数量达到maximumPoolSize设置的最大线程数量,若大于maximumPoolSize则执行拒绝策略- 4.该方式中线程数量的上限与有界任务队列的状态有直接关系,如果有界队列初始容量较大或没有达到超负荷的状态,线程数将一直维持在
corePoolSize以下,反之当任务队列已满时,则会以maximumPoolSize为最大线程数上限
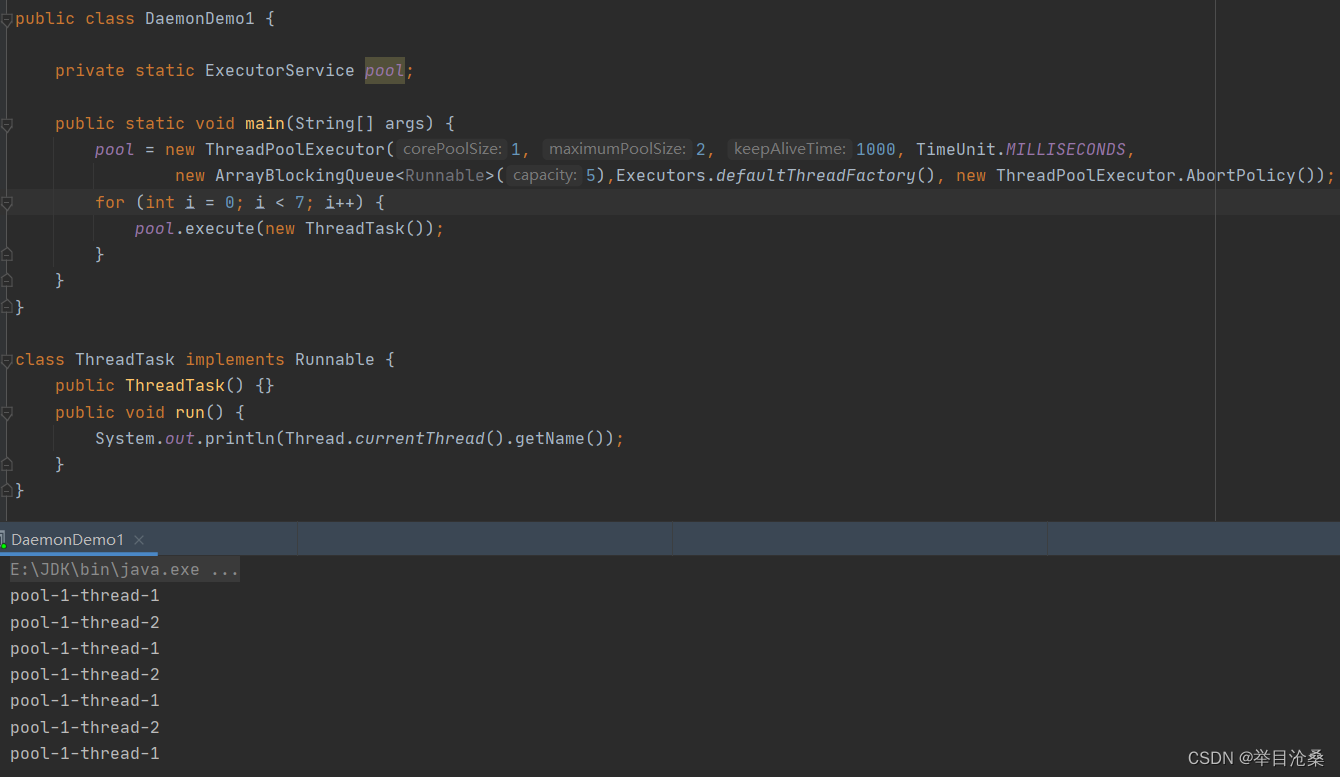
3.无界任务队列
- 1.
LinkedBlockingQueue:无界任务队列- 2.上述结果显示当任务队列为
LinkedBlockingQueue,线程池的任务队列可以无限制的添加新的任务,而线程池创建的最大线程数量就是corePoolSize- 3.该方式中
maximumPoolSize参数是无效的,哪怕任务队列中缓存了很多未执行的任务,当线程池的线程数达到corePoolSize后就不会再增加- 4.若后续有新的任务加入,则直接进入阻塞队列等待,当使用这种任务队列模式时,一定要注意任务提交与处理之间的协调控制,不然会出现队列中的任务由于无法及时处理导致一直增长,直到最后资源耗尽的问题
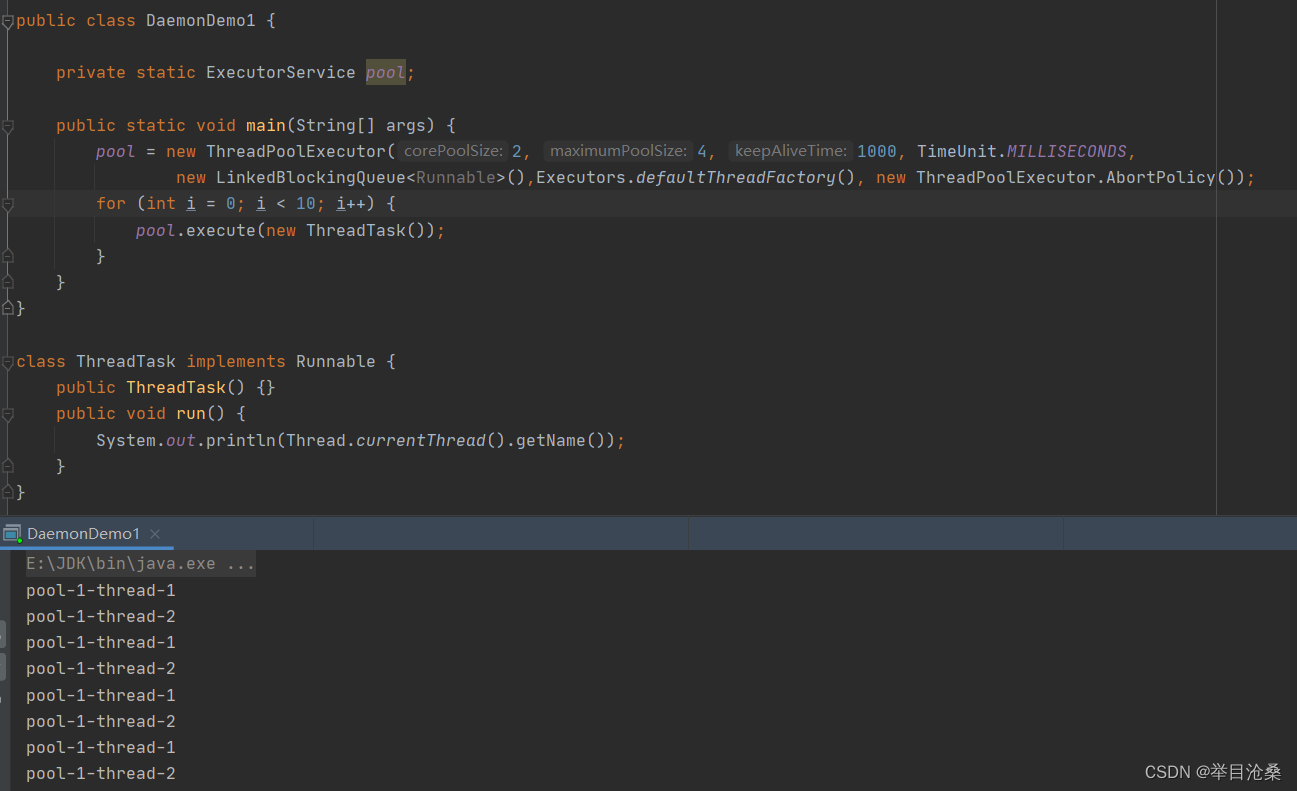
4.优先任务队列
- 1.
PriorityBlockingQueue:优先任务队列- 2.上述结果显示当任务队列为
PriorityBlockingQueue,除了第一个任务直接创建线程执行外,其他的任务都被放入了优先任务队列,按优先级进行了重新排列执行且线程池的线程数一直为corePoolSize- 3.
PriorityBlockingQueue其实是一个特殊的无界队列,其中无论添加了多少个任务,线程池创建的线程数也不会超过corePoolSize的数量- 4.只不过其他队列一般是按照
先进先出的规则处理任务,而PriorityBlockingQueue队列可以自定义规则根据任务的优先级顺序先后执行
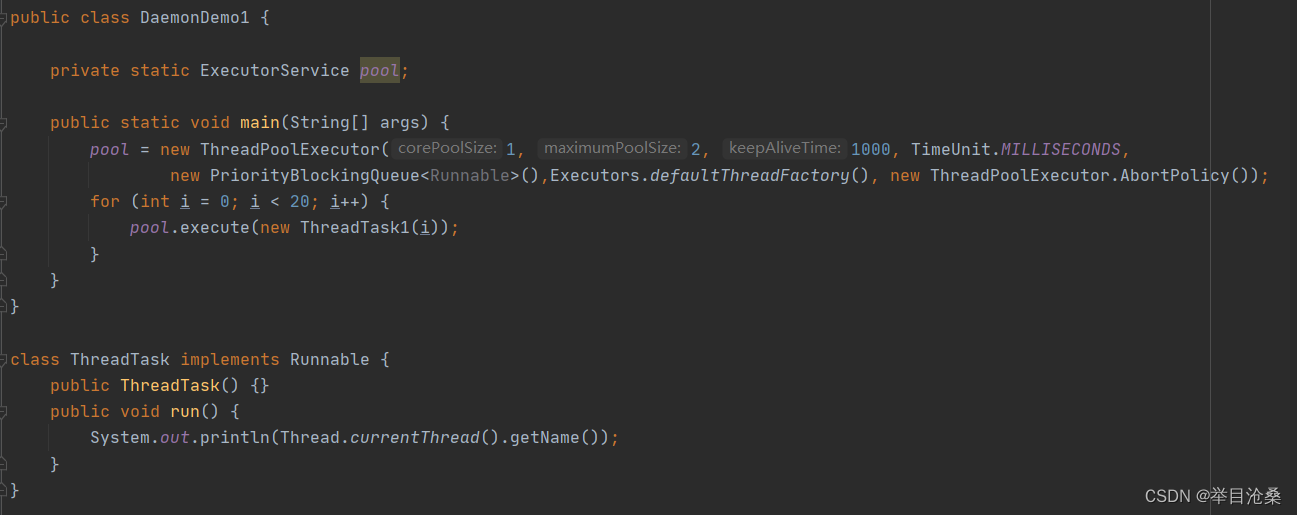
5.线程池的生命周期

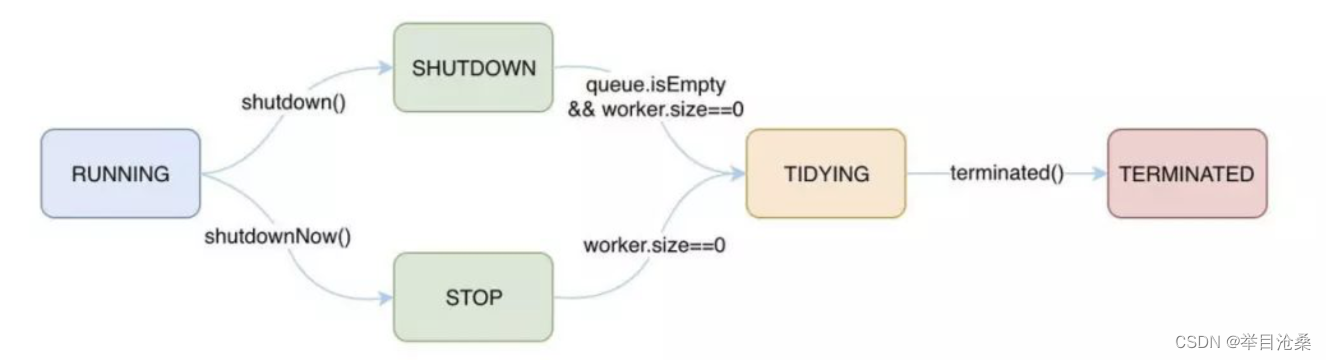
6.线程池的优缺点
- 1.优点
- 1.
降低资源消耗:复用已创建的线程来降低创建和销毁线程的消耗- 2.
提高响应速度:任务到达时可以不需要等待线程的创建立即执行- 3.
提高线程的可管理性:使用线程池能够统一的分配、调优和监控- 2.缺点
- 1.多线程会占
CPU,使用多线程的地方并发量比较高时会导致其他功能响应很慢
7.线程池的执行流程
- 1.一个任务通过
execute(Runnable)方法被添加到线程池,任务就是一个Runnable类型的对象,任务的执行方法就是Runnable类型对象的run()方法- 2.当一个任务通过
execute(Runnable)方法欲添加到线程池时- 3.如果此时线程池中的数量小于
corePoolSize,即使线程池中的线程都处于空闲状态,也要创建新的线程来处理被添加的任务- 4.如果此时线程池中的数量等于
corePoolSize,但是缓冲队列workQueue未满,那么任务被放入缓冲队列- 5.如果此时线程池中的数量大于
corePoolSize,缓冲队列workQueue满了并且线程池中的数量小于maximumPoolSize,创建新的线程来处理被添加的任务- 6.如果此时线程池中的数量大于
corePoolSize,缓冲队列workQueue满了并且线程池中的数量等于maximumPoolSize,则通过handler所指定的拒绝策略来处理此任务- 7.处理任务的优先级为:核心线程
corePoolSize、任务队列workQueue、最大线程maximumPoolSize,如果三者都满了,使用handler处理被拒绝的任务- 8.当线程池中的线程数量大于
corePoolSize时,如果某线程空闲时间超过keepAliveTime线程将被终止,这样线程池可以动态的调整池中的线程数
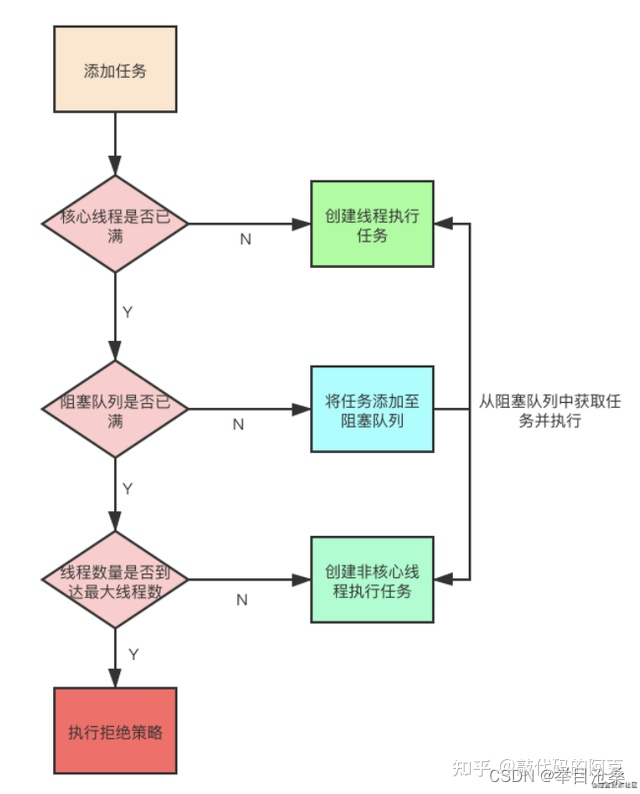
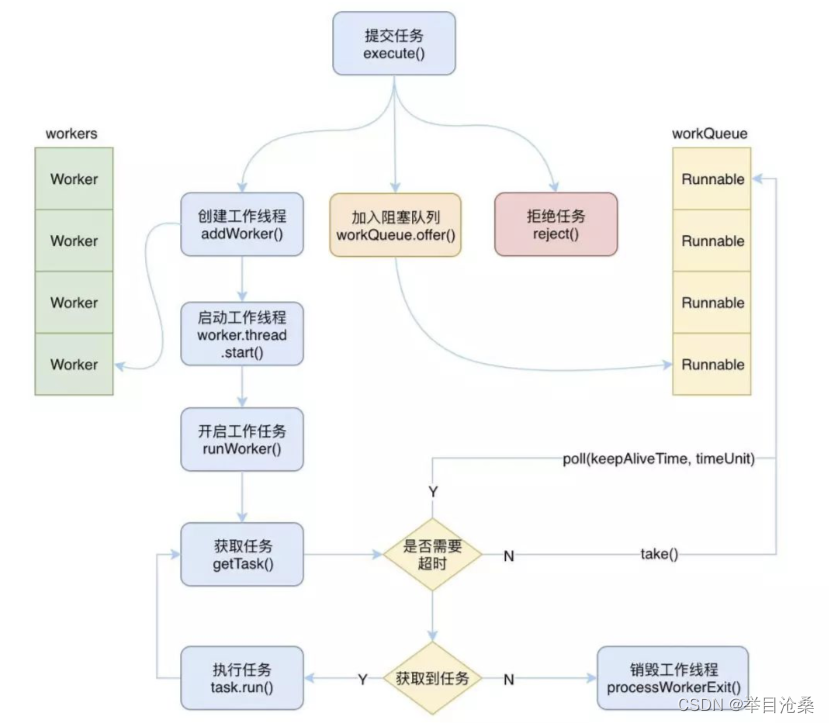
3.进程与线程的区别
- 1.线程是进程
代码段的一次顺序执行流程,一个进程由一个或多个线程组成,一个进程至少有一个线程- 2.线程是
CPU调度的最小单位,进程是操作系统分配资源的最小单位- 3.线程是基于高并发的调度诉求从进程内部演进而来的,线程的出现既充分发挥了
CPU的计算性能,又弥补了进程调度过于笨重的问题- 4.进程之间是相互独立的,但进程内部的各个线程之间并不完全独立,各个线程之间共享进程的方法区内存,堆内存,系统资源(文件句柄,系统信号等)
- 5.切换速度不同:线程上下文切换比进程上下文切换要快
4.锁
- Java内置锁是一个互斥锁,这就意味着最多只有一个线程能够获得该锁,当线程B尝试去获得线程A持有的内置锁时,线程B必须等待或者阻塞,直到线程A释放这个锁,如果线程A不释放这个锁,那么线程B永远等待下去
- Java中每个对象都可以用作锁,这些锁称为内置锁。线程进入同步代码块或方法时会自动获得该锁,在退出同步代码块或方法时会释放该锁。获得内置锁的唯一途径就是进入这个锁保护的同步代码块或方法
1.线程安全问题
- 线程安全:当多个线程并发访问某个Java对象(Object)时,无论系统如何调度这些线程,也无论这些线程将如何交替操作,这个对象都能表现出一致的,正确的行为,那么对这个对象的操作就是线程安全的
- 如果这个对象表现出不一致,错误的行为,那么对这个对象的操作不是线程安全的,发生了线程的安全问题。
- 自增运算不是线程安全的
package threadDemo;
public class NotSafeThreadDemo1 {
private Integer amount = 0;
public void selfAdd(){
amount++;
}
public Integer getAmount(){
return amount;
}
}
package threadDemo;
import java.util.concurrent.CountDownLatch;
public class PlusTest {
static final int MAX_TREAD = 10;
static final int MAX_TURN = 1000;
public static void main(String[] args) throws InterruptedException {
CountDownLatch countDownLatch = new CountDownLatch(MAX_TREAD);
NotSafeThreadDemo1 notSafeThreadDemo1 = new NotSafeThreadDemo1();
Runnable runnable = () -> {
for (int i = 0; i < MAX_TURN; i++) {
notSafeThreadDemo1.selfAdd();
}
countDownLatch.countDown();
};
for (int i = 0; i < MAX_TREAD; i++) {
new Thread(runnable).start();
}
countDownLatch.await();
System.out.println("理论结果:" + MAX_TURN * MAX_TREAD);
System.out.println("实际结果:" + notSafeThreadDemo1.getAmount());
System.out.println("差距是:" + (MAX_TURN * MAX_TREAD - notSafeThreadDemo1.getAmount()) );
}
}
从结果可以看出,++运算在多线程并发执行场景下出现了不一致的错误的行为,自增运算符++不是线程安全的
- 上面代码中,为了获得10个线程的结果,主线程通过CountDownLatch(闭锁)工具类进行了并发线程的等待
- 闭锁是一个非常使用的等待多线程并发的工具类。调用线程可以在闭锁上进行等待,一直等待闭锁的次数减少到0,才继续往下执行,每一个被等待的线程执行完成之后,闭锁的次数减少到0,调用线程可以往下执行,从而达到并发等待的效果
- 原因:自增运算符不是线程安全的
- 实际上一个自增运算符是一个复合操作,至少包括三个JVM指令:内存取值,寄存器增加1,存值到内存,这三个指令在JVM内部是独立进行的,中间完全可能会出现多个线程并发进行。
- 比如在amount=100时,假设有三个线程同一时间读取amount值,读到的都是100,增加1后结果为101,三个线程都将结果存入amount的内存,amount的结果是101,而不是103
- 内存取值,寄存器增加,存值到内存这三个JVM指令本身是不可再分的,他们都具备原子性是线程安全的,也叫原子操作。但是两个或者两个以上的原子操作合在一起进行操作就不在具备原子性了。比如先读后写,就有可能在读之后,其实这个变量被修改了,出现读和写数据不一致的情况。
2.临界区资源和临界区代码块
- 一般来说,只在多个线程对这个资源进行写操作的时候才会出现问题,如果是简单的读操作,不改变资源的话,显然是不会出现问题的
- 注意代码不仅会以线程,串行的方式执行,也可能多个线程并行执行
- 临界区资源:表示一种可以被多个线程使用的公共资源或共享数据,但是每一次只能有一个线程使用它,一旦临界资源被占用,想使用该资源的其他线程则必须等待
- 在并发情况下,临界区资源是受保护的对象。临界区代码段(Critical Section)是每个线程中访问临界资源的那段代码,多个线程必须互斥地对临界区资源进行访问,线程进入临界区代码段之前,必须在进入区申请资源,申请成功之后执行临界区代码段,执行完成之后释放资源
- 竞态条件(Race Conditions):可能是由于在访问临界区代码段时没有互斥地访问而导致的特殊情况。如果多个线程在临界区代码段的并发执行结果可能因为代码的执行顺序不同而不同。我们就说这时在临界区出现了竞态条件问题
- 例如:amount为临界区资源,selfAdd()可以理解为临界区代码段
- 当多个线程访问临界区的selfAdd()方法时,就会出现竞态条件的问题,更标准地说,当两个或多个线程竞争同一个资源时,对资源的访问顺序就变得非常关键
- 为了避免竞态条件的问题,必须保证临界区代码段操作具备排他性。这就意味着当一个线程进入临界区代码段执行时,其他线程不能进入临界区代码段执行。在Java中,我们可以用synchronized关键字同步代码块,对临界区代码段进行排他性保护
- 在Java中,使用synchronized关键字还可以使用Lock显示锁实例,或者使用原子变量(Atomic Variables)对临界区代码段进行排他性保护

3.synchronized关键字
- Java中,线程同步使用最多的方法是使用synchronized关键字。每个Java对象都隐含有一把锁,这里成为Java内置锁(或对象锁,隐式锁)。使用synchronized(syncObject)调用相当于获取syncObject的内置锁,所以可以使用内置锁对临界区代码段进行排他性保护
4.synchronized同步方法
- synchronized关键字是Java的保留字,当使用synchronized关键字修饰一个方法的时候,该方法被声明为同步方法
public synchronized void selfAdd(){
amount++;
}
- 关键字synchronized的位置处于同步方法的返回类型之前。
- 在方法声明中设置synchronized同步关键字,保证其方法的代码执行流程是排他性的。任何时间只允许一个线程进入同步方法(临界区代码段),如果其他线程需要执行同一个方法,那么只能等待和排队
5.synchronized同步块
对于小的临界区,可以直接在方法声明中设置synchronized同步关键字,可以避免竞态条件的问题。但是对于较大的临界区代码段,为了执行效率,最好将同步方法分为小的临界区代码段
public class TwoPlus{
private int sum1 = 0;
private int sum2 = 0;
//同步方法
public synchronized void plus(int val1,int val2){
//临界区代码段
this.sum1 += val1;
this.sum2 += val2;
}
}
- 以上代码中,临界区代码段包含对两个临界区资源的操作,这两个临界区资源分别为sum1和sum2。使用synchronized对plus进行同步保护之后,进入临界区代码段的线程拥有sum1和sum2的操作全,并且是全部占用。一旦线程进入,当线程在操作sum1而没有操作sum2时,也将sum2的操作权白白占用,其他的线程由于没有进入临界区,只能看着sum2被闲置而不能去执行操作
- 所以将synchronized加在方法上,如果其保护的临界区代码段包含的临界区资源(要求是相互独立)多于一个,就会造成临界区资源的闲置等待,进而会影响临界区代码段的吞吐量(单位时间内成功执行临界区代码段的线程数量),为了提升吞吐量,可以将synchronized关键字放在函数体内,同步一个代码块。
synchronized(syncObject){//同步块而不是方法
//临界区代码段的代码块
}
- 在synchroninzed同步块后面的括号中是一个syncObject对象,代表着进入临界区代码段需要获取syncObject对象的监视锁。或者说将synchronized对象监视锁作为临界区代码段的同步锁。由于每一个Java对象都有一把监视锁,因此任何java对象都能作为synchronized的同步锁
- 单个线程在获得synchronized同步块后面的同步锁后才能进入临界区代码段;反过来说,当一个线程获得syncObject对象的监视锁后,其他线程就只能等待。
- 使用synchronized同步块对上面的TwoPlus类进行吞吐量的提升改造:
public class TwoPlus{
private int sum1 = 0;
private int sum2 = 0;
private Integer sum1Lock = new Integer(1);//同步锁一
private Integer sum2Lock = new Integer(2);//同步锁二
public void plus(int val1,int val2){
//同步块1
synchronized(this.sum1Lock){
this.sum1 += val1;
}
//同步块2
synchronized(this.sum2Lock){
this.sum2 += val2;
}
}
}
- 改造之后,对两个独立的临界区资源sum1和sum2的加法操作可以并发执行了,在某个时刻,不同的线程可以对sum1和sum2同时进行加法操作,提升了plus()方法的吞吐量
- 在TowPlus代码中,由于同步块1和同步块2保护着两个独立的临界区代码段,需要两把不同的syncObject对象锁,因此TwoPlus代码新加了sum1Lock和sum2Lock两个新的成员属性,这两个属性没有参与业务处理,TwoPlus仅仅利用了sum1Lock和sum2Lock的内置锁功能
- synchronized方法和synchronized同步块的区别:synchronized方法是一种粗粒度的并发控制,某一时刻只能有一个线程执行该synchronized方法;而synchronized代码块是一种细粒度的并发控制,处于synchronized块之外的其他代码是可以被多个线程并发访问的。在一个方法中,并不一定所有代码都是临界区代码段,可能只有几行代码会涉及线程同步问题,所以synchronized代码块比synchronized方法更加细粒度地控制了多个线程的同步访问
- synchronized方法和synchronized代码块的联系:在Java的内部实现上,synchronized方法实际上等同于用一个synchronized代码块,这个代码块包含同步方法中的所有语句,然后在synchronized代码块的括号中传入this关键字,使用this对象锁作为进入临界区的同步锁(如果有两个synchronized方法,访问的则是同一把锁,synchronized锁的是当前方法所属的对象本身)
- 同一个类中多个方法上加synchronized其实是当前对象的锁,是同一把锁
public void plus(){
synchronized(this){
amount++;
}
}
public synchronized void plus(){
amount++;
}
- synchronized方法的同步锁实质上使用了this对象锁,这样就免去了手工设置同步锁的工作。而使用synchronized代码块需要手工设置同步锁
6.静态的同步方法
- Java一切皆对象,Java有两种对象:Object实例对象和Class对象。每个类运行时的类型信息用Class对象表示,它包含类名称,继承关系,字段,方法有关的信息。Jvm将一个类加载入自己的方法内存时,会为其创建一个Class对象,对于一个类来说其Class对象是唯一的
- Class类没有公共的构造方法,Class对象是在类加载的时候由Java虚拟机调用类加载器中的defineClass方法自动构建的,因此不能显式地声明一个Class对象
- 所有的类都是在第一次使用时被动态加载到JVM中的(懒加载),其各个类都是在必需时才加载的
- JVM为动态加载机制配套了一个判定一个类是否已经被加载的检查动作,使得类加载器首先检查这个类的Class对象是否已经被加载。如果尚未加载,类加载器就会根据类的全限定名查找.class文件,验证后加载到JVM的方法区内存,并构造其对应的Class对象
- 普通的synchronized实例方法,其同步锁是当前this的监视锁。如果某个synchronized方法是static(静态)方法而不是普通的对象实例方法,其同步锁又是什么?
public class SafeStaticMethodPlus{
//静态的临界区资源
private static Integer amount = 0;
//使用synchronized关键字修饰static方法
public static synchronized void selfPlus(){
amount++;
}
}
- 静态方法属于Class实例而不是单个Object实例,在静态方法内部是不可以访问Object实例的this引用(也叫指针,句柄)。所以修饰static方法的synchronized关键字就没有办法获得Object实例的this对象的监视锁。
- 实际上,使用synchronized关键字修饰static方法时,synchronized的同步锁并不是普通Object对象的监视锁,而是类所对应的Class对象的监视锁
- 为了区分,这里将Object对象的监视锁叫做对象锁,将Class对象的监视锁叫做类锁,当synchronized关键字修饰静态成员方法时,同步锁为类锁,由于类的对象实例可以有很多,但是每个类只有一个Class实例,因此使用类锁作为synchronized的同步锁会造成同一个JVM内的所有线程只能互斥地进入临界区段
//对JVM内的所有线程同步
public static synchronized void selfPlus(){
//临界区代码
}
- 所以使用synchronized关键字修饰static方法是非常粗粒度的同步机制
- 通过synchronized关键字所抢占的同步锁什么时候释放?一种场景是synchronized块(代码块或者方法)正确执行完毕,监视锁自动释放;另一种场景是程序出现异常,非正常退出synchronized块,监视锁也会自动释放。所以,使用synchronized块时不必担心监视锁的释放问题
- 对象锁:如果某个类的实例很多,那么这个类的对象锁就会有很多,那么高并发的场景下,大家只抢用到的那个对象锁
- 类锁:整个jvm就只有一个,高并发的场景下,大家只能抢一个类锁
7.生产者-消费者问题
- 生产者-消费者(Producer-Consumer Problem)也称为有限缓冲问题(Bounded-Buffer Problem),是一个多线程同步问题的经典案例
- 生产者-消费者问题描述了两类访问共享缓存区的线程(生产者,消费者)在实际运行时会发生的问题
- 生产者线程的主要功能是生成一定量的数据放到缓冲区,然后重复此过程。消费者线程的主要功能是从缓冲区提取(或消耗)数据
- 生产者-消费者问题的关键是:
1.保证生产者不会在缓冲区满时加入数据,消费者也不会在缓冲区空时消耗数据
2.保证在生产者加入过程,消费者消耗过程,不会产生错误的数据和行为- 生产者-消费者问题不仅仅是一个多线程同步问题的典型案例,而且业内已经将解决该问题的方法抽象成了一种设计模式:生产者-消费者模式
1.生产者-消费者模式
在该模式中,通常有两类线程,即生产者线程(若干个)和消费者线程(若干个)
- 生产者线程向数据缓冲区(DataBuffer)加入数据,消费者线程则从数据缓冲区消耗数据
关键:
1.生产者与生产者之间,消费者与消费者之间,对数据缓冲区的操作是并发进行的
2.数据缓冲区是有容量上限的,数据缓冲区满后,生产者不能再加入数据;数据缓冲区空时,消费者不能再取出数据
3.数据缓冲区是线程安全的,在并发操作数据缓冲区的过程中,不能出现数据不一致的情况;或者在多个线程并发更改共享数据后,不会造成出现脏数据的情况(脏数据:从目标中取出的数据已经过期,错误或者没有意义,这种数据就叫做脏数据;脏读:读取出来脏数据就叫脏读)
4.生产者或者消费者线程在空闲时需要尽可能阻塞而不是执行无效的空操作,尽量节约CPU资源(一般就绪态的线程是即将可以运行的线程,任何时候只有一个线程处于运行态。而从就绪变成运行是将线程从就绪队列里面移出来,交给CPU进行执行,如果阻塞就会把其加入对应的阻塞队列。如果被唤醒就是从对应的阻塞队列移出放入就绪队列,所以阻塞状态是没机会获取CPU执行权,只有就绪队列才有,所以阻塞队列不会浪费CPU资源,但是就绪队列就会不断的空跑,比如死循环,自旋。阻塞队列有很多,其中synchronized锁里也包含阻塞队列)
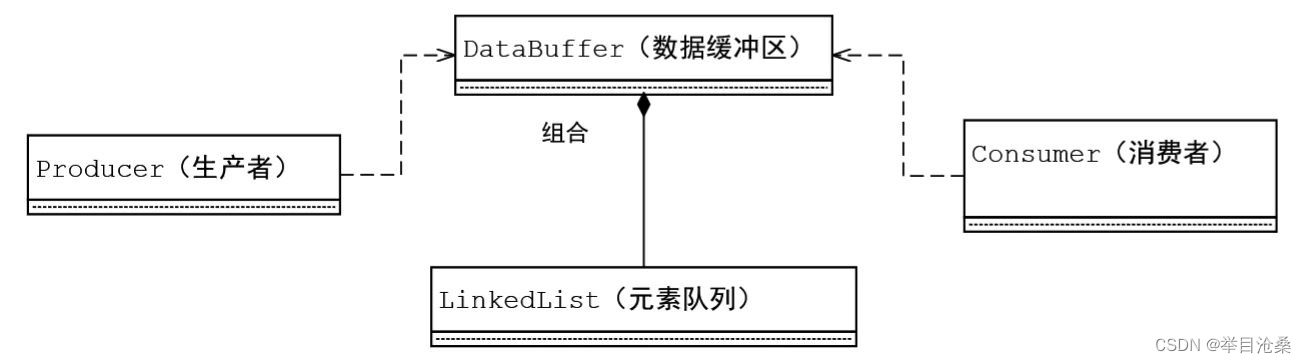
2.线程不安全的实现版本
- 其中包含数据缓冲区(DataBuffer)类,生产者(Producer)类和消费zhe(Consumer)类
8.Java内置对象结构与内置锁
- Java内置锁的很多重要信息都存放在对象结构中
- lock和biased_lock两个标记位组合在一起共同表示Object实例处于什么样的锁状态
- 3.age:4位的Java对象分代年龄。在GC中,对象在Survivor区复制一次,年龄就增加1。当对象达到设定的阈值时,将会晋升到老年代。默然情况下,并行的GC的年龄阈值为15,并发GC的年龄阈值为6,。由于age只有4位,因此最大值为15,这就是-XX:MaxTenuringThreshold选项最大值为15的原因
- 4.identity_hashcode:31位的对象标识HashCode(哈希码)采用延迟加载技术,当调用Object.hashCode()方法或者System.identityHashCode()方法计算对象的HashCode后,其结果将被写到该对象头中。当对象被锁定时,该值会移动到Monitor(监视器)中
- 5.thread:54位的线程ID值为持有偏向锁的线程ID
- 6.epoch:偏向时间戳
- 7.ptr_to_lock_record:占62位,在轻量级锁的状态下指向栈帧中锁记录的指针
- 8.pro_to_heavyweight_monitor:占62位,在重量级锁的状态下指向对象监视器的指针
1.使用JOL工具查看对象的布局
- OpenJDK提供的JOL(Java Object Layout)包,可以帮我们在运行时计算某个对象的大小
- JOL是分析JVM中对象的结构布局的工具,该工具大量使用了Unsafe,JVMTI来解码内部布局情况,它的分析结果相比较精准
- 先引入Maven的依赖坐标
- 由于在JVM中的数据使用大端模式存储和计算,而JOL工具使用小端模式进行输出,因此在以上代码中,通过Java程序手工将hashCode从大端模式转换成小端模式
- 从运行结果中可以看出,当前JVM的运行环境为64位虚拟机。运行结果中输出了ObjectLock的对象布局,所输出的ObjectLock为16字节,其中对象头(Object Header)占12字节,剩下的4字节由amount属性(字段)占用。由于16字节为8字节的倍数,因此没有对齐填充字节
- 分析结果对象的哈希码,如果Java代码没有重写Object.hashcode()方法,那么默认通过Native方式调用os::random()方法产生哈希码,Java代码也可以调用System.identityHashCode(obj)为对象产生哈希码
- 对象一旦生成了哈希码,JVM会将其记录在对象头的Mark Word中。当然,只有调用未重写的Object.hashcode()方法或者调用System.IdentityHashCode(obj)方法时,其值才被记录到Mark Word中。如果调用的是重写的hashcode()方法,也不会记录到Mark Word中。
- 对象一旦生成了哈希码,它就无法进入偏向锁状态,也就是说,只要一个对象已经计算过哈希码,它就无法进入偏向锁状态,并且需要计算其哈希码的话,它的偏向锁会被撤销,并且锁会膨胀为重量级锁
- 偏向锁和对象hashcode不能共存,1.8版本JDK中,hashcodejvm生成一个随即数,然后放到对象头的hashcode段里,对象刚生成是不会有hashcode的,hashcode采用懒加载的方式,只有被调用到了才会生成,放到对象头是为了保证每次调用hashcode都获取到相同的值
- 在无锁状态下,Mark Word中可以存储对象的identity hash code值。当对象的hashCode()方法(非用户自定义)第一次被调用时,JVM会生成对应的identity hash code值,并将该值存储到Mark Word中。后续如果该对象的hashCode()再次被调用则不会再通过JVM进行计算得到,而是直接从Mark Word中获取。(以JDK8为例,JVM默认的计算identity hash code的方式得到的是一个随机数,因而我们必须要保证一个对象的identity hash code只能被底层JVM计算一次)
- 对于轻量级锁,获取锁的线程帧栈中有锁记录(Lock Record)空间,用于存储Mark Word的拷贝,官方称之为Displaced Mark Word,该拷贝中可以包含identity hash code,所以轻量级锁可以和identity hash code共存;对于重量级锁,ObjectMonitor类里有字段可以记录非加锁状态下的mark word,其中也可以存储identity hash code的值,所以重量级锁也可以和identity hash code共存
- 对于偏向锁,在线程获取偏向锁时,会用Thread ID和epoch值覆盖identity hash code所在的位置。如果一个对象的hashCode()方法一经被调用过一次之后,这个对象还能被设置偏向锁吗,不能,因为如果可以的化,那么Mark Word中identity hash code 必然会被偏向线程ID给覆盖,这就会造成同一个对象前后两次调用hashCode()方法得到的结果不一致
- 因为MarkWord中存储的哈希码和偏向锁线程id是一个字段,如果该字段被哈希码占有的化就无法存储线程id了,所以无法进入偏向锁状态
9.无锁,偏向锁,轻量级锁和重量级锁
- jdk1.6版本前,所有的Java内置锁都是重量级锁。重量级锁会造成CPU在用户态和核心态之间的频繁切换,所以代价高,效率低
- jdk1.6版本为了减少获得锁和释放锁所带来的性能消耗,引入了偏向锁和轻量级锁的实现
- jdk1.6版本中内置锁一共有4种状态:无锁状态,偏向锁状态,轻量级锁状态和重量级锁状态,这些状态随着竞争情况逐渐升级。
- 内置锁可以升级但不能降级,意味着偏向锁升级成轻量级锁后不能再降级成偏向锁。这种能升级却不能降级的策略,其目的是提高获得锁和释放锁的效率
1.无锁状态
- Java对象刚创建时还没有任何线程来竞争,说明该对象处于无锁状态(无线程竞争它),这时偏向锁标识位是0,锁状态是01,无锁状态下对象的 Mark Word

2.偏向锁
- 偏向锁是指一段同步代码一直被同一个线程访问,那么该线程会自动获取锁,降低获取锁的代价。如果内置锁处于偏向锁状态,当有一个线程来竞争时,先用偏向锁,标识内置锁偏爱这个线程,这个线程要执行该锁关联的同步代码时,不需要再做任何检查和切换,偏向锁在竞争不激烈的情况下效率非常高。(所谓偏向:只要没有线程竞争,那么执行当前同步代码的线程就可以调过获取和释放锁的一系列操作,使得同步代码的执行效率接近于无锁状态)
- 偏向锁状态的Mark Word会记录内置锁自己偏爱的线程ID,内置锁会将该线程当成自己的熟人
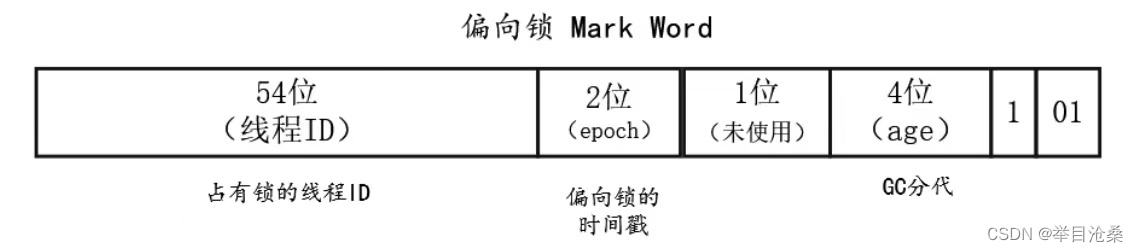
3.轻量级锁状态
- 当有两个线程开始竞争这个锁对象时,情况就发生变化了,不再是偏向(独占)锁了,锁会升级为轻量级锁,两个线程公平竞争,哪个线程先占有锁对象,锁对象的Mark Word就指向哪个线程的栈帧中的锁记录
- 当锁处于偏向锁,又被另一个线程企图抢占时,偏向锁就会升级为轻量级锁,企图抢占的线程会通过自旋的形式尝试获取锁,不会阻塞抢锁线程,以便提高性能
- 线程通过自旋可以避免陷入内核态,所谓进入阻塞状态就是进行系统调用,由操作系统内核进程接手来管理线程对锁的分配,陷入内核态会导致操作系统进行上下文切换(保存用户线程信息,启动内核进程),而上下文切换是很低效的操作;如果每个线程对锁的持有不会持续很长时间,那么频繁在用户态和内核态之间切换就会浪费时间,降低高并发下的吞吐量,如果线程在自旋过程中能拿到锁,就避免了上下文切换,这样的优化让并发线程的执行更轻快,故称之为轻量级锁
- 自旋原理非常简单,如果持有锁的线程能在很短时间内释放锁资源,那么那些等待竞争锁的线程就不需要进行内核态和用户态之间的切换来进入阻塞挂起状态,他们只需要等一等(自旋),等持有锁的线程释放锁后可立即获取锁,这样就避免了用户线程和内核切换的消耗
- 但是线程自旋是需要消耗CPU的,如果一直获取不到锁,那么线程也不能一直占用CPU自旋做无用功,所以需要设定一个自旋等待的最大时间。JVM对于自旋周期的选择,JDK1.6之后引入了适应性自旋锁,适应性自旋锁意味着自旋的时间不是固定的,而是由前一次在同一个锁上的自旋时间以及锁的拥有者的状态来决定的,线程如果自旋成功了,下次自旋的次数就会更多,如果自旋失败了,自旋的次数就会减少
- 如果持有锁的线程执行的时间超过自旋等待的最大时间仍没有释放锁,就会导致其他争用锁的线程在最大等待时间内还是获取不到锁,自旋不会一直持续下去,这时争用线程会停止自旋进入阻塞状态,该锁膨胀为重量级锁
- Java的线程是映射到操作系统原生线程之上的,如果要阻塞或唤醒一个线程就需要操作系统介入,需要在用户态与核心态之间切换,这种切换会消耗大量的系统资源,因为用户态与内核态都有各自专用的内存空间,专用的寄存器等,用户态切换至内核态需要传递给许多变量,参数给内核,内核也需要保护好用户态在切换时的一些寄存器值,变量等,以便内核态调用结束后切换回用户态继续工作
- 自旋其实就是空跑,循环去做一件事,并不会进行系统调用,频繁的进行内核态和用户态的切换,这个太影响性能了,其实自旋就是去争抢CPU时间片,这种也只能是临界资源区间不是小的情况下才可以

4.重量级锁
- 重量级锁会让其他申请的线程之间进入阻塞,性能降低。
- 重量级锁也叫同步锁,这个锁对象Mark Word再次发生变化,会指向一个监视器对象,该监视器对象用集合的形式来登记和管理排队的线程,重量级锁状态下对象的Mark Word

2-1.偏向锁的原理与实战
- 偏向锁主要解决无竞争下的锁性能问题,所谓的偏向就是偏心,即锁会偏向于当前已经占有锁的线程
2.1.1偏向锁的核心原理
- 在实际场景中,如果一个同步块(或方法)没有多个线程竞争,而且总是由同一个线程多次重入获取锁,如果每次还有阻塞线程,唤醒CPU从用户态转为核心态,那么对于CPU是一种资源的浪费,为了解决这类问题,就引入了偏向锁概念
- 偏向锁的核心原理:如果不存在线程竞争的一个线程获得了锁,那么锁就进入偏向状态,此时Mark Word的结构变为偏向状态,此时Mark Word的结构变为偏向锁结构,锁对象的锁标志位(lock)被改为01,偏向标志位(biased_lock)被改为1,然后线程的ID记录在锁对象的Mark Word中(使用CAS操作完成)。以后该线程获取锁时判断一下线程ID和标志位,就可以直接进入同步块,连CAS操作都不需要,这样就省去了大量有关锁申请的操作,从而也就提升了程序的性能
- 偏向锁的主要作用是消除无竞争情况下的同步原语,进一步提升程序性能,所以在没有锁竞争的场合,偏向锁有很好的优化效果,但是,一旦有第二条线程需要竞争锁,那么偏向模式立即结束,进入轻量级锁的状态
- 假如在大部分情况下同步块是没有竞争的,那么可以通过偏向来提高性能。那么可以通过偏向来提高性能,即在无竞争时,之前获得锁的线程再次获得锁时会判断偏向锁的线程ID是否指向自己,如果是那么该线程将不用再次获得锁,直接就可以进入同步块;如果未指向当前线程,当前线程就会采用CAS操作将Mark Word中的线程ID设置为当前线程ID,如果CAS操作成功,那么获取偏向锁成功,执行同步代码块,如果CAS操作失败,那么表示有竞争,抢锁线程被挂起,撤销占锁线程的偏向锁,然后将偏向锁膨胀为轻量级锁
(其实所谓的CAS操作成功,是由于之前的无锁状态,CAS成功变成偏向锁状态,并且说明存在竞争,从而升级为轻量级锁状态)- 偏向锁的缺点:如果锁对象时常被多个线程竞争,偏向锁就是多余的,并且其撤销的过程会带来一些性能开销
- 运行演示案例之后,在看到第一行输出结果之前,程序要等待5秒,因为JVM在启动的时候会延迟启用偏向锁机制,JVM偏向锁延迟了4000毫秒,这就解释了为什么演示为什么要等待5秒才能看到对象锁的偏向状态
- 为什么偏向锁会延迟?因为JVM在启动的时候需要加载资源,这些对象加上偏向锁没有任何意义,不启用偏向锁能减少大量偏向锁撤销的成本
- 如果不想等待(在代码中让线程睡眠),可直接通过修改JVM的启动项来禁止偏向锁延迟,其具体的启动选项如下:
-XX:+UseBiasedLocking
-XX:BiasedLockingStartupDelay=0
具体使用方式:
Java -XX:+UseBiasedLocking
-XX:BiasedLockingStartupDelay=0 mainclass
- 偏向锁的加锁过程为:新线程只需要判断内置锁对象的Mark Word中的线程ID是不是自己的ID,如果是就直接使用这个锁,而不使用CAS交换,新线程将自己的线程ID交换到内置锁的Mark Word中,如果交换成功,就加锁成功。
- 在演示案例的循环抢锁中,每执行一轮抢占,JVM内部都会比较内置锁的偏向线程ID与当前线程ID,如果匹配就表明当前线程已经获得了偏向锁,当前线程可以快速进入临界区,所以偏向锁的效率是非常高德,偏向锁是针对一个线程而言的,线程获得锁之后就不会再有解锁等操作了,可以节省很多开销
2.2.2偏向锁的膨胀与撤销
- 假如有多个线程来竞争偏向锁,此对象锁已经有所偏向,其他线程发现偏向锁并不是偏向自己,就说明存在了竞争,尝试撤销偏向锁(很可能引入安全点),然后膨胀到轻量级锁
2-2轻量级锁
- JDK1.6的轻量级锁使用的是普通自旋锁,且需要使用-XX:+UseSpinning选项手工开启。JDK1.7后,轻量级锁使用自适应自旋锁,JVM启动时自动开启,且自旋时间由JVM自动控制
- 轻量级也被称为非阻塞同步,乐观锁,因为这个过程并没有把线程阻塞挂起,而是让线程空循环等待
轻量级锁的膨胀
- 轻量级锁问题:虽然大部分临界区代码的执行时间很短,但是也会存在执行很慢的临界区代码。临界区代码执行耗时长,在其执行期间,其他线程都在原地自旋等待,会空消耗CPU。因此,如果竞争这个同步锁的线程很多,就会有多个线程在原地等待继续空循环消耗CPU(空自旋。这会带来很大的性能损耗)
- 轻量级锁的本意是为了减少多线程进入操作系统底层的互斥锁(Mutex Lock)的概率,并不是要替代操作系统互斥锁。所以在争用激烈的场景下,轻量级锁会膨胀为基于操作系统内核互斥锁实现的重量级锁
2-3重量级锁的原理与实战
- 在JVM中,每个对象都关联一个监视器,这里的对象包含Object实例和Class实例。监视器是一个同步工具,相当于一个许可证,拿到许可证的线程可进入临界区进行操作,没有拿到则需要阻塞等待。重量级锁通过监视器的方式保障了任何时间只允许一个线程通过收到监视器保护的临界区代码
重量级锁的核心原理:
- JVM中每个对象都会有一个监视器,监视器和对象一起创建,销毁。监视器相对于一个用来监视这些线程进入的特殊房间,其义务是保证同一时间只有一个线程可以访问被保护的临界区代码块(每一个对象都有一个monitor与之关联,当且一个monitor被持有后,它将处于锁定状态,线程执行到monitorenter指令时,将会尝试获取对象锁对应的monitor的所有权,即尝试获得对象的锁,MarkWord里默认数据是存储对象的HashCOde等信息,但是在运行期间,MarkWord存储的数据会随着锁标志位的变化而变化。重量级锁也就是通常说synchronized的对象锁,锁标识位为10,其中指针指向的是monitor对象(也称为管理或监视器锁)的起始地址)
- 本质上,监视器是一种同步工具,也可以说是一种同步机制,主要特点是:
- 1.同步。监视器所保护的临界区代码是互斥地执行的。一个监视器是一个运行许可,任一线程进入临界区代码都需要获得这个许可,离开时把许可归还
- 2.协作。监视器提供Signal机制,允许正持有许可的线程暂时放弃许可进入阻塞等待状态,等待其他线程发送Signal去唤醒;其他拥有线程许可的线程可以发送Signal,唤醒正在阻塞等待的线程,让它可以重新获得许可并启动执行
- 在Hotspot虚拟机中,监视器是由C++类ObjectMonitor实现的,ObjectMonitor类定义在ObjectMonitor.hpp中,其构造器代码大致如下:
//Monitor结构体
ObjectMonitor::ObjectMonitor(){
_header = NULL;
_count = 0;
_waiters = 0,
//线程的重入次数
_recursions = 0;
_object = NULL;
//标识拥有该Monitor的线程
_owner = NULL;
//等待线程组成的双向循环链表
_WaitSet = NULL;
_WaitSetLock = 0;
_Responsible = NULL;
_succ = NULL;
//多线程竞争锁进入时的单向链表
cxq = NULL;
FreeNext = NULL;
//_owner从该双向循环链表中唤醒线程节点
_EntryList = NULL;
_SpinFreq = 0;
_SpinClock = 0;
OwberIsThread = 0;
}
- ObjectMonitor的Owner(_owner),WaitSet(_WaitSet),Cxq(_cxq),EntryList(_EntryList)这几个属性比较关键
- ObjectMonitor的WaitSet,Cxq,EntryList这三个队列存放抢夺重量级锁的线程,而ObjectMonitor的Owner所指向的线程即为获得锁的线程
- Cxq:竞争队列(Contention Queue),所有请求锁的线程首先被放在这个竞争队列中
- EntryList:Cxq中哪些有资格成为候选资源的线程被移动到EntryList中
- WaitSet:某个拥有ObjectMonitor的线程在调用Object.wait()方法之后将被阻塞,然后该线程将被放置在WaitSet链表中
- ObjectMonitor的内部抢锁过程
1.CXq
- Cxq并不是一个真正的队列,只是一个虚拟队列,原因在于Cxq是由Node及其next指针逻辑构成的,并不存在一个队列的数据结构。每次新加入Node会在Cxq的队头进行,通过CAS改变第一个节点的指针为新增节点,同时设置新增节点的next指向后续节点;从Cxq取得元素时,会从队尾获得,显然Cxq是一个无锁结构,因为只有Owner线程才能从队尾取元素,即线程出列操作无争用,当然也就避免了CAS的ABA问题
- 在线程进入Cxq前,抢锁线程会先尝试通过CAS自旋获取锁,如果获取不到,就进入Cxq队列,这明显对于已经进入Cxq队列的线程是不公平的。所以synchronized同步块所使用的重量级锁时不公平锁(如果获取到就不取队列里的,之前排队就白排了,所以不公平)
- Cxq队列是对象监视器里的虚拟队列,要用到对象监视器的时候,说明已经由轻量级锁变为重量级锁,而这个变化过程,只有在发生过cas自旋获取不到锁以后才会发生没如果自旋拿到锁了,就不会进入队列,所以对于之前未进入队列的线程是不公平的)
2.EntryList
- EntryList与Cxq在逻辑上都属于等待队列。Cxq会被线程并发访问,为了降低对Cxq队尾的争用,而建立EntryList,在Owner线程释放锁时,JVM会从Cxq中迁移线程到EntryList,并会指定EntryList中的某个线程(一般为Head)为OnDeckThread(Ready Thread)。EntryList中的线程作为候选竞争线程而存在
3.OnDeck Thread 与 Owner Thread
- JVM不直接把锁传递给Owner Thread,而是把锁竞争的权利交给OnDeck Thread,OnDeck需要重新竞争锁,这样虽然牺牲了一些公平性,但是能极大地提升系统的吞吐量,在JVM中也把这种选择行为称为竞争切换(非公平锁体现之一,已进入entrylist队列的线程仍需要与外部线程竞争锁)
- OnDeck Thread获取到锁资源后会变为Owner Thread。无法获得锁的OnDeck Thread则会依然留在EntryList中,考虑到公平性,OnDeck Thread在EntryList中的位置不发生变化(依然在队头)
- 在OnDeck Thread成为Owner的过程中,还有一个不公平的事情,即后来的新抢线程可能直接通过CAS自旋成为Owner而抢到锁
- 可以类比Aqs中的队列和抢锁以及唤醒机制并不是唤醒所有线程去抢占锁而是唤醒队列中首个线程
4.WaitSet
- 如果Owner线程被Object.wait()方法阻塞,就转移到WaitSet队列中,知道某个时刻通过Object.notify()或者Object.notifyAll()唤醒,该线程就会重新进入EntryList中
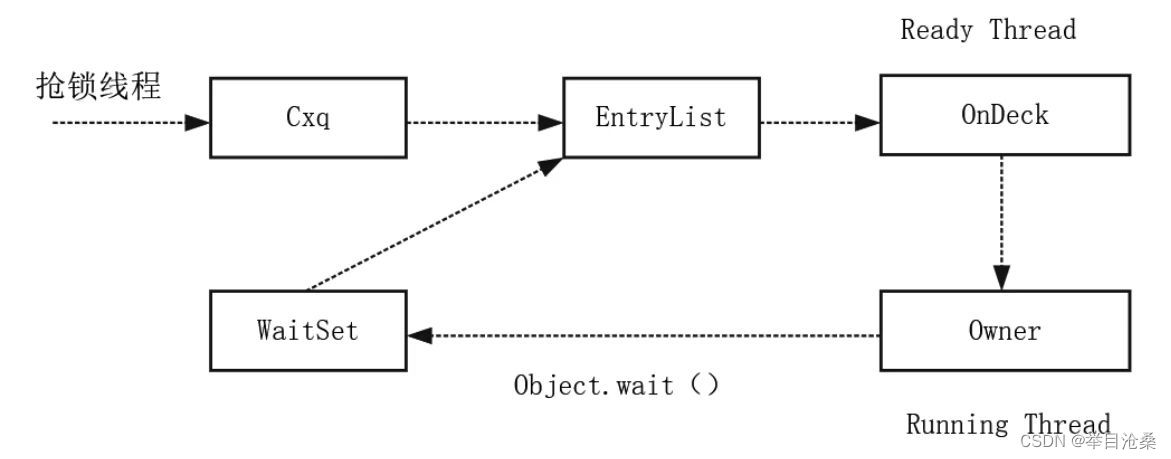
2.3.1重量级锁的开销
- 处于ContentionList,EntryList,WaitSet中的线程都处于阻塞状态,线程的阻塞或者唤醒都需要操作系统来帮忙,Linux内核下采用pthread_mutex_lock系统调用实现,进程需要从用户态切换到内核态
- Linux系统的体系架构分为用户态(或者用户空间)和内核态(或者内核空间)
- Linux系统的内核是一组特殊的软件程序,负责控制计算机的硬件资源,如协调CPU资源,分配内存资源,并且提供稳定的环境供应应用程序运行。应用程序的活动空间为用户空间,应用程序的执行必须依托于内核提供的资源,包括CPU资源,存储资源,I/O资源等
- 用户态与内核态有各自专用的内存空间,专用的寄存器等,进程从用户态切换至内核态需要传递许多变量,参数给内核,内核也需要保护好用户态在切换时的一些寄存器值,变量等,以便内核态调用结束后切换回用户态继续工作。
- 用户态的进程能够访问的资源受到了极大地控制,而运行在内核态的进程可以为所欲为,一个进程可以运行在用户态,也可以运行在内核态,那么肯定存在用户态和内核态切换的过程,进程从用户态到内核态切换主要包括以下三种方式:
- 1.硬件中断。硬件中断也称为外设中断,当外设完成用户的请求时会向CPU发送中断信号
- 2.系统调用。其实系统调用本身就是中断,只不过是软件中断,跟硬件中断不同
- 3.异常。如果当前进程运行在用户态,这个时候发生了异常事件(例如缺页异常),就会触发切换
- 用户态是应用程序运行的空间,为了能访问到内核管理的资源(例如CPU,内存,I/O),可以通过内核态所提供的访问接口实现,这些接口就叫系统调用
- pthread_mutex_lock系统调用时内核态为用户态进程提供的Linux内核态下互斥锁的访问机制,所以使用pthread_mutex_lock系统调用时,进程需要从用户态切换到内核态,而这种切换是需要消耗很多时间的,有可能比用户执行代码的时间还要长
- 由于JVM轻量级锁使用CAS自旋抢锁,这些CAS操作都处于用户态下,进程不存在用户态和内核态之间的运行切换,因此JVM轻量级锁开销较小。而JVM重量级锁使用了Linux内核态下的互斥锁,这是重量级锁开销很大的原因
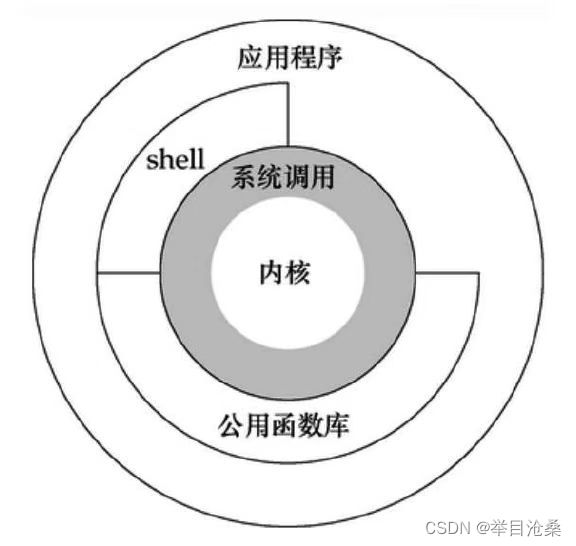
10.偏向锁,轻量级锁,重量级锁的对比
- 总结synchronized的执行过程:
- 1.线程抢锁时,JVM首先检查内置锁对象Mark Word中的biased_lock(偏向锁标识)是否设置成1,lock(锁标志位)是否为01,如果都满足,确认内置锁对象为可偏向状态
- 2.在内置锁对象确认为可偏向状态之后,JVM检查Mark Word中的线程ID是否为抢锁线程ID,如果是,就表示抢锁线程处于偏向锁状态,抢锁线程快速获得锁,开始执行临界区代码
- 3.如果Mark Word中的线程ID并未指向抢锁线程,就通过CAS操作竞争锁。如果竞争成功,就将Mark Word中的线程ID设置为抢锁线程,偏向标志位设置为1,锁标志位设置为01,然后执行临界区代码,此时内置锁对象处于偏向锁状态。
- 4.如果CAS操作竞争失败,就说明发生了竞争,撤销偏向锁,进而升级为轻量级锁
- 5.JVM使用CAS锁将锁对象的Mark Word替换为抢锁线程的锁记录指针,如果成功,抢锁线程就获得锁。如果替换失败,就表示其他线程竞争锁,JVM尝试使用CAS自旋替换抢锁线程的锁记录指针,如果自旋成功(抢锁成功),那么锁对象依然处于轻量级锁状态
- 6.如果JVM的CAS替换锁记录指针自旋失败,轻量级锁就膨胀为重量级锁,后面等待锁的线程也要进入阻塞状态
- 总体来说,偏向锁是在没有发生锁争用的情况下使用的;一旦有了第二个线程争用锁,偏向锁就会升级为轻量级锁;如果锁争用很激烈,轻量级锁的CAS自旋达到阈值后,轻量级锁就会升级为重量级锁

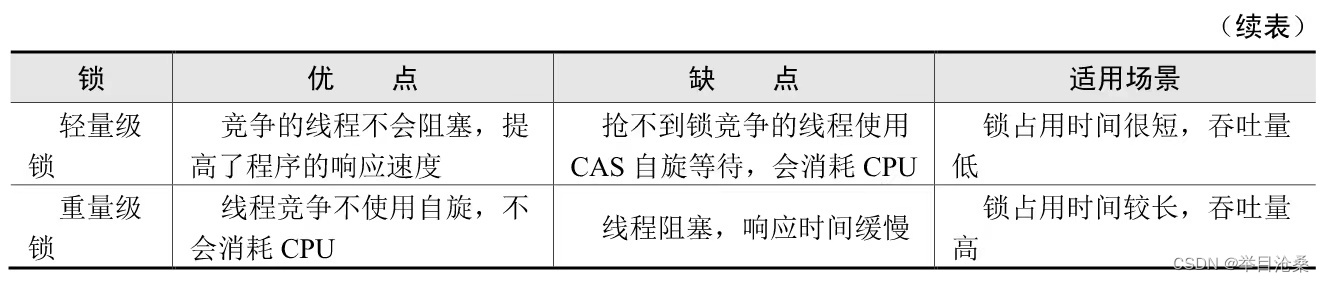
11.线程间通信
- 线程是操作系统调度的最小单位,有自己的栈空间,可以按照既定的代码逐步执行,但是如果每个线程间都孤立地运行,就会造成资源浪费
- 所以在现实中,如果需要多个线程按照指定的规则共同完成一个任务,那么这些线程之间就需要互相协调,这个过程被称为线程的通信
线程间通信的定义:
- 线程的通信可以被定义为:当多个线程共同操作共享的资源时,线程间通过某种方式互相告知自己的状态,以避免无效的资源争夺
- 线程间通信的方式可以有很多种:
- 1.等待-通知
- 2.共享内存
- 3.管道流
- 每种方式用不同的方法来实现,这里首先介绍等待-通知的通信方式
- 等待-通知通信方式是Java中使用普遍的线程间通信方式,其经典的案例是生产者-消费者模式
低效的线程轮询
- 首先回到前面的生产者-消费者安全版本的数据缓冲区类SafeDataBuffer。其存在一个隐蔽但又很耗性能的问题:消费者每一轮消费,无论数据区是否为空,都需要进行数据区的询问和判断,其轮询代码如下:
public synchronized IGoods get() throws Exception{
IGoods good = null;
if(amount <= 0){
System.out.printf("队列已经空了");
return null;
}
}
当数据区空时(amount <= 0),消费者无法取出数据,但是仍然做无用的数据区询问工作,白白消耗了CPU的时间片,对于生产者来说,也存在类似的无效轮询问题。当数据区满时,生产者无法加入数据,这时生产者执行add(T element)方法也白白耗费了CPU的时间片,其中的轮询代码如下:
public synchronizedboid add(Telement) throws Exception{
if(zmount.get() > MAX_AMOUNT){
System.out.printf("队列已经满了");
return;
}
}
- 如何在生产者和消费者空闲时节约CPU时间片,免去巨大的CPU消费浪费呢?
- 一个非常有效的方法是:使用等待-通知方式进行生产者与消费者之间的线程通信
- 具体来说,在数据区满(amount.get() > MAX_AMOUNT)时,可以让生产者等待,等到下次数据区中可以加入数据时,给生产者发通知,让生产者唤醒。同样,在数据区为空(amount <= 0)时,可以让消费者等待,等到下次数据区中可以取出数据时,消费者才能被唤醒
- 那么,由谁去唤醒等待状态的生产者呢?可以在消费者取出一个数据后,由消费者去唤醒等待的生产者,同样,由谁去唤醒等待状态的消费者呢?可以在生产者加入一个数据后,由生产者去唤醒等待的消费者。
- Java语言中等待-通知方式的线程间通信使用对象的wait(),notify()两类方法来实现。每个Java对象都有wait(),notify()两类实例方法,并且wait(),notify()方法和对象的监视器是紧密相关的
- 说明:Wait(),notify()两类方法在数量上不止两个,wait(),notify()两类方法不属于Thread类,而是属于Java对象实例(Object实例或者Class实例)
wait方法和notify方法的原理
Java对象中的wait(),notify()两类方法就如同信号开关,等于等待方和通知方之间的交互
1.对象的wait()方法的主要作用是让当前线程阻塞并等待被唤醒。wait()方法与对象监视器紧密相关,使用wait()方法时一定要放在同步块中
synchronized(locko){
locko.wait();
}
Object 类中的wait()方法有三个版本:
- 1.void wait
- 这是一个基础版本,当前线程调用了同步对象的locko的wait()实例方法后,将导致当前线程等待,当前线程进入locko的监视器WaitSet,等待被其他线程唤醒
- 2.void wait(long timeout)
- 这是一个限时等待版本,导致当前的线程等待,等待被其他线程唤醒,或者指定的时间timeout用完,线程不再等待
- 3.void wait(long timeout,int nanos)
- 这是一个高精度限时等待版本,其主要作用是更精确地控制等待时间,参数nanos是一个附加的纳秒级别的等待时间,从而实现更加高精度的等待时间控制
wait()方法的核心原理:
对象的wait()方法的核心原理大致如下:
- 1.当线程调用了locko(某个同步锁对象)的wait()方法后,JVM会将当前线程加入locko监视器的WaitSet(等待集),等待被其他线程唤醒
- 2.当前线程会释放locko对象监视器的Owner权利,让其他线程可以抢夺locko对象的监视器
- 3.让当前线程等待,其状态变成WAITING
在线程调用了同步对象locko的wait()方法之后,同步对象locko的监视器内部状态
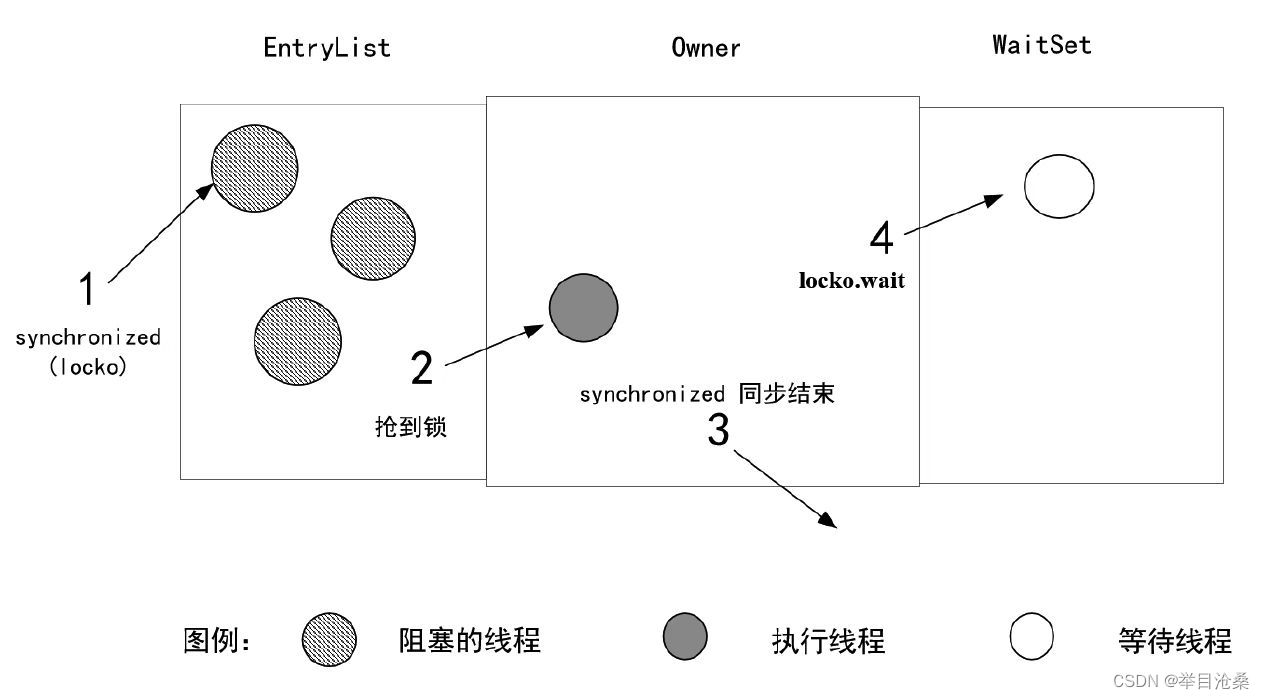
对象的notify()方法
- 对象的notify()方法的主要作用是唤醒在等待的线程。notify()方法与对象监视器紧密相关,调用notify()方法时也需要放在同步块中
synchronized(locko){
locko.notify();
}
- notify()方法有两个版本:
- 版本一:void notify()
- notify()方法的主要作用为:locko.notify()调用后,唤醒locko监视器等待集中的第一条等待线程;被唤醒的线程进入EntryList,其状态从WAITING变成BLOCKED
- 版本二:void notifyAll()
- locko.notifyAll()被调用后,唤醒locko监视器等待集中的全部等待线程,所有被唤醒的线程进入EntryList,线程状态总长WAITING变成BLOCKED
notify()方法的核心原理
- 当线程调用了locko(某个同步锁对象)的notify()方法后,JVM会唤醒locko监视器WaitSet中的第一条等待线程
- 当线程调用了locko的notifyAll()方法后,JVM会唤醒locko监视器WaitSet中的所有等待线程
- 等待线程被唤醒后,会从监视器的WaitSet移动到EntryList,线程具备了排队抢夺监视器Owner权利的资格,其状态从WAITING变成了BLOCKED
- EntryList中的线程抢夺到监视器的Owner权利后,线程的状态从BLOCKED变成Runnable,具备重新执行的资格
等待-通知通信模式演示案例
- Java的等待-通知机制是指:一个线程A调用了同步对象的wait()方法进入等待状态,而另一线程B调用了同步对象的notify()或者notifyAll()方法通知等待线程,当线程A收到通知后,重新进入就绪状态,准备开始执行
- 线程间的通信需要借助
CAS原理与JUC原子类
- 由于JVM的Synchronized重量级锁涉及操作系统(如Linux)内核态下互斥锁的使用,因此其线程阻塞和唤醒都涉及进程在用户态到内核态的频繁切换,导致重量级锁开销大、性能低。而JVM的Synchronized轻量级锁使用CAS(Compare And Swap,比较并交换)进行自旋抢锁,CAS是CPU指令级的原子操作,并处于用户态下,所以JVM轻量级锁的开销较小。
- 由于JVM的Synchronized重量级锁涉及操作系统(如Linux)内核态下互斥锁的使用,因此其线程阻塞和唤醒都涉及进程在用户态到内核态的频繁切换,导致重量级锁开销大、性能低。而JVM的Synchronized轻量级锁使用CAS(Compare And Swap,比较并交换)进行自旋抢锁,CAS是CPU指令级的原子操作,并处于用户态下,所以JVM轻量级锁的开销较小。
CAS
- JDK 5所增加的JUC(java.util.concurrent)并发包对操作系统的底层CAS原子操作进行了封装,为上层Java程序提供了CAS操作的API
Unsafe类中的CAS方法
- Unsafe是位于sun.misc包下的一个类,主要提供一些用于执行低级别、不安全的底层操作,如直接访问系统内存资源、自主管理内存资源等。Unsafe大量的方法都是native方法,基于C++语言实现,这些方法在提升Java运行效率、增强Java语言底层资源操作能力方面起到了很大的作用。
- Unsafe类的全限定名为sun.misc.Unsafe,从名字中可以看出这个类对普通程序员来说是“危险”的,一般的应用开发都不会涉及此类,Java官方也不建议直接在应用程序中使用这些类
- 为什么此类取名为Unsafe呢?由于使用Unsafe类可以像C语言一样使用指针操作内存空间,这无疑增加了指针相关问题、内存泄漏问题出现的概率。总之,在程序中过度使用Unsafe类会使得程序出错的概率变大,使得安全的语言Java变得不再安全,因此对Unsafe的使用一定要慎重。
- 操作系统层面的CAS是一条CPU的原子指令(cmpxchg指令),正是由于该指令具备原子性,因此使用CAS操作数据时不会造成数据不一致的问题,Unsafe提供的CAS方法直接通过native方式(封装C++代码)调用了底层的CPU指令cmpxchg。
完成Java应用层的CAS操作主要涉及Unsafe方法的调用,具体如下:
(1)获取Unsafe实例。
(2)调用Unsafe提供的CAS方法,这些方法主要封装了底层CPU的CAS原子操作。
(3)调用Unsafe提供的字段偏移量方法,这些方法用于获取对象中的字段(属性)偏移量,此偏移量值需要作为参数提供给CAS操作。
1.获取Unsafe实例
- Unsafe类是一个final修饰的不允许继承的最终类,而且其构造函数是private类型的方法,具体的源码如下
public final class Unsafe { private static final Unsafe theUnsafe; ... private Unsafe() { } @CallerSensitive public static Unsafe getUnsafe() { Class var0 = Reflection.getCallerClass(); if (!VM.isSystemDomainLoader(var0.getClassLoader())) { throw new SecurityException("Unsafe"); } else { return theUnsafe; } } ...- 因此,我们无法在外部对Unsafe进行实例化,那么怎么获取Unsafe的实例呢?可以通过反射的方式自定义地获取Unsafe实例的辅助方法,代码如下:
package com.crazymakercircle.util;
// 省略import
public class JvmUtil
{
//自定义地获取Unsafe实例的辅助方法
public static Unsafe getUnsafe()
{
try
{
Field theUnsafe = Unsafe.class.getDeclaredField("theUnsafe");
theUnsafe.setAccessible(true);
return (Unsafe) theUnsafe.get(null);
} catch (Exception e)
{
throw new AssertionError(e);
}
}
// 省略不相干代码
}
2.调用Unsafe提供的CAS方法
/**
* 定义在Unsafe类中的三个“比较并交换”原子方法
* @param o 需要操作的字段所在的对象
* @param offset 需要操作的字段的偏移量(相对的,相对于对象头)
* @param expected 期望值(旧的值)
* @param update 更新值(新的值)
* @return true 更新成功 | false 更新失败
*/
public final native boolean compareAndSwapObject(
Object o, long offset, Object expected, Object update);
public final native boolean compareAndSwapInt(
Object o, long offset, int expected,int update);
public final native boolean compareAndSwapLong(
Object o, long offset, long expected, long update);
- Unsafe提供的CAS方法包含4个操作数——字段所在的对象、字段内存位置、预期原值及新值。在执行Unsafe的CAS方法时,这些方法首先将内存位置的值与预期值(旧的值)比较,如果相匹配,那么CPU会自动将该内存位置的值更新为新值,并返回true;如果不匹配,CPU不做任何操作,并返回false。
- Unsafe的CAS操作会将第一个参数(对象的指针、地址)与第二个参数(字段偏移量)组合在一起,计算出最终的内存操作地址。
3.调用Unsafe提供的偏移量相关
- Unsafe提供的获取字段(属性)偏移量的相关操作主要如下
/**
* 定义在Unsafe类中的几个获取字段偏移量的方法
* @param o 需要操作字段的反射
* @return 字段的偏移量
*/
public native long staticFieldOffset(Field field);
public native long objectFieldOffset(Field field);
- staticFieldOffset()方法用于获取静态属性Field在Class对象中的偏移量,在CAS中操作静态属性时会用到这个偏移量。objectFieldOffset()方法用于获取非静态Field(非静态属性)在Object实例中的偏移量,在CAS中操作对象的非静态属性时会用到这个偏移量。
- 一个获取非静态Field(非静态属性)在Object实例中的偏移量的示例代码如下
static
{
try
{
//获取反射的Field对象
OptimisticLockingPlus.class.getDeclaredField("value");
//取得内存偏移
valueOffset = unsafe.objectFieldOffset();
} catch (Exception ex)
{
throw new Error(ex);
}
}
使用CAS进行无锁编程
- CAS是一种无锁算法,该算法关键依赖两个值——期望值(旧值)和新值,底层CPU利用原子操作判断内存原值与期望值是否相等,如果相等就给内存地址赋新值,否则不做任何操作。
- 使用CAS进行无锁编程的步骤大致如下:
(1)获得字段的期望值(oldValue)。
(2)计算出需要替换的新值(newValue)。
(3)通过CAS将新值(newValue)放在字段的内存地址上,如果CAS失败就重复第(1)步到第(2)步,一直到CAS成功,这种重复俗称CAS自旋。
do
{
获得字段的期望值(oldValue);
计算出需要替换的新值(newValue);
} while (!CAS(内存地址,oldValue,newValue))
- 下面用一个简单的例子对以上伪代码进行举例说明。假如某个内存地址(某对象的属性)的值为100,现在有两个线程(线程A和线程B)使用CAS无锁编程对该内存地址进行更新,线程A欲将其值更新为200,线程B欲将其值更新为300,如图3-1所示。>* 线程是并发执行的,谁都有可能先执行。但是CAS是原子操作,对同一个内存地址的CAS操作在同一时刻只能执行一个。因此,在这个例子中,要么线程A先执行,要么线程B先执行。假设线程A的CAS(100,200)执行在前,由于内存地址的旧值100与该CAS的期望值100相等,因此线程A会操作成功,内存地址的值被更新为200。
线程A执行CAS(100,200)成功之后,内存地址的值如图3-2所示。
- 接下来执行线程B的CAS(100,300)操作,此时内存地址的值为200,不等于CAS的期望值100,线程B操作失败。线程B只能自旋,开始新的循环,这一轮循环首先获取到内存地址的值200,然后进行CAS(200,300)操作,这一次内存地址的值与CAS的预期值(oldValue)相等,线程B操作成功。
- 当CAS将内存地址的值与预期值进行比较时,如果相等,就证明内存地址的值没有被修改,可以替换成新值,然后继续往下运行;如果不相等,就说明内存地址的值已经被修改,放弃替换操作,然后重新自旋。当并发修改的线程少,冲突出现的机会少时,自旋的次数也会很少,CAS的性能会很高;当并发修改的线程多,冲突出现的机会多时,自旋的次数也会很多,CAS的性能会大大降低。所以,提升CAS无锁编程效率的关键在于减少冲突的机会
使用无锁编程实现轻量级安全自增
- 在第1章开头讲到的第二个面试典故中,临行时笔者给候选人Y君建议回去做一个线程安全的自增小实验:使用10个线程,对一个共享的变量,每个线程自增100万次,看看最终的结果是不是1000万。
- 在第2章学习synchronized关键字时提供了一个线程安全的自增实现版本。由于在争用激烈的场景下,synchronized内置锁会膨胀为重量级锁,因此第2章的实现版本实际上是一个低性能的实现版本。这里使用CAS无锁编程算法实现一个轻量级的安全自增实现版本:总计10个线程并行运行,每个线程通过CAS自旋对一个共享数据进行自增运算,并且每个线程需要成功自增运算1000次。
- 基于CAS无锁编程的安全自增实现版本的具体代码如下:
package com.crazymakercircle.cas;
// 省略import
public class TestCompareAndSwap
{
// 基于CAS无锁实现的安全自增
static class OptimisticLockingPlus
{
//并发数量
private static final int THREAD_COUNT = 10;
//内部值,使用volatile保证线程可见性
private volatile int value;//值
//不安全类
private static final Unsafe unsafe = getUnsafe();;
//value 的内存偏移(相对于对象头部的偏移,不是绝对偏移)
private static final long valueOffset;
//统计失败的次数
private static final AtomicLong failure = new AtomicLong(0);
static
{
try
{
//取得value属性的内存偏移
valueOffset = unsafe.objectFieldOffset(
OptimisticLockingPlus.class.getDeclaredField("value"));
Print.tco("valueOffset:=" + valueOffset);
} catch (Exception ex)
{
throw new Error(ex);
}
}
//通过CAS原子操作,进行“比较并交换”
public final boolean unSafeCompareAndSet(int oldValue, int newValue)
{
//原子操作:使用unsafe的“比较并交换”方法进行value属性的交换
return unsafe.compareAndSwapInt(
this, valueOffset,oldValue ,newValue );
}
//使用无锁编程实现安全的自增方法
public void selfPlus()
{
int oldValue = value;
//通过CAS原子操作,如果操作失败就自旋,一直到操作成功
do
{
// 获取旧值
oldValue = value;
//统计无效的自旋次数
if (i++ > 1)
{
//记录失败的次数
failure.incrementAndGet();
}
} while (!unSafeCompareAndSet(oldValue, oldValue + 1));
}
//测试用例入口方法
public static void main(String[] args) throws InterruptedException
{
final OptimisticLockingPlus cas = new OptimisticLockingPlus();
//倒数闩,需要倒数THREAD_COUNT次
CountDownLatch latch = new CountDownLatch(THREAD_COUNT);
for (int i = 0; i < THREAD_COUNT; i++)
{
// 提交10个任务
ThreadUtil.getMixedTargetThreadPool().submit(() ->
{
//每个任务累加1000次
for (int j = 0; j < 1000; j++)
{
cas.selfPlus();
}
latch.countDown(); // 执行完一个任务,倒数闩减少一次
});
}
latch.await(); //主线程等待倒数闩倒数完毕
Print.tco("累加之和:" + cas.value);
Print.tco("失败次数:" + cas.failure.get());
}
}
}

- 从上面的输出结果可以看出,调用Unsafe.objectFieldOffset(…)方法所获取到的value属性的偏移量为12。为什么value属性的偏移量为12呢?接下来为大家详细地分析。
字段偏移量的计算
- 调用Unsafe.objectFieldOffset(…)方法获取到的Object字段(也叫Object成员属性)的偏移量值是字段相对于Object头部的偏移量,是一个相对的内存地址值,不是绝对的内存地址值。
- 首先回顾一下3.1.3节用到的OptimisticLockingPlus类,该类所包含的字段如下:
// 模拟CAS 算法
static class OptimisticLockingPlus
{ //静态常量:线程数
private static final int THREAD_COUNT = 10;
//成员属性:包装的值
volatile private int value;
//静态常量:JDK不安全类的实例
private static final Unsafe unsafe = JvmUtil.getUnsafe();
//静态常量:value 成员的相对偏移(相对于对象头)
private static final long valueOffset;
//静态常量:CAS的失败次数
private static final AtomicLong failure = new AtomicLong(0);
// 省略其他不相干的代码
}
- // 模拟CAS 算法
static class OptimisticLockingPlus
{ //静态常量:线程数
private static final int THREAD_COUNT = 10;
//成员属性:包装的值
volatile private int value;
//静态常量:JDK不安全类的实例
private static final Unsafe unsafe = JvmUtil.getUnsafe();
//静态常量:value 成员的相对偏移(相对于对象头)
private static final long valueOffset;
//静态常量:CAS的失败次数
private static final AtomicLong failure = new AtomicLong(0);
// 省略其他不相干的代码
}
- 通过图3-3可以看出,在64位的JVM堆区中一个OptimisticLockingPlus对象的Object Header(头部)占用了12字节,其中Mark Word占用了8字节(64位),压缩过的Class Pointer占用了4字节。接在Object Header之后的就是成员属性value的内存区域,所以value属性相对于Object Header的偏移量为12。
- 通过图3-3可以看出,在64位的JVM堆区中一个OptimisticLockingPlus对象的Object Header(头部)占用了12字节,其中Mark Word占用了8字节(64位),压缩过的Class Pointer占用了4字节。接在Object Header之后的就是成员属性value的内存区域,所以value属性相对于Object Header的偏移量为12。
package com.crazymakercircle.cas;
// 省略import
public class TestCompareAndSwap
{
@Test
public void printObjectStruct()
{
//创建一个对象
OptimisticLockingPlus object=new OptimisticLockingPlus();
//给成员赋值
object.value=100;
//通过JOL工具输出内存布局
String printable = ClassLayout.parseInstance(object).toPrintable();
Print.fo("object = " + printable);
}
// 省略不相关代码
}
[TestCompareAndSwap.printObjectStruct]:object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 50 08 01 f8 (01010000 00001000 00000001 11111000) (-134150064)
12 4 int OptimisticLockingPlus.value 100
Instance size: 16 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
- 从以上JOL输出的结果可以看出,一个TestCompareAndSwap对象的Object Header占用了12字节,而value属性的内存位置紧挨在Object Header之后,所以value属性的相对偏移量值为12。
JUC原子类
- 在多线程并发执行时,诸如“++”或“–”类的运算不具备原子性,不是线程安全的操作。通常情况下,大家会使用synchronized将这些线程不安全的操作变成同步操作,但是这样会降低并发程序的性能。所以,JDK为这些类型不安全的操作提供了一些原子类,与synchronized同步机制相比,JDK原子类是基于CAS轻量级原子操作的实现,使得程序运行效率变得更高。
JUC中的Atomic原子操作包
- Atomic操作翻译成中文是指一个不可中断的操作,即使在多个线程一起执行Atomic类型操作的时候,一个操作一旦开始,就不会被其他线程中断。所谓Atomic类,指的是具有原子操作特征的类。
JUC并发包中原子类的位置
- JUC并发包中的原子类都存放在java.util.concurrent.atomic类路径下
- 根据操作的目标数据类型,可以将JUC包中的原子类分为4类:基本原子类、数组原子类、原子引用类和字段更新原子类
1.基本原子类
基本原子类的功能是通过原子方式更新Java基础类型变量的值。基本原子类主要包括以下三个:
基本原子类的功能是通过原子方式更新Java基础类型变量的值。基本原子类主要包括以下三个:>·AtomicInteger:整型原子类。
·AtomicLong:长整型原子类。
·AtomicBoolean:布尔型原子类。
2.数组原子类
数组原子类的功能是通过原子方式更新数组中的某个元素的值。数组原子类主要包括以下三个:·AtomicIntegerArray:整型数组原子类。·AtomicLongArray:长整型数组原子类。·AtomicReferenceArray:引用类型数组原子类。
3.引用原子类
引用原子类主要包括以下三个
·AtomicReference:引用类型原子类
·AtomicMarkableReference:带有更新标记位的原子引用类型。
·AtomicStampedReference:带有更新版本号的原子引用类型。
AtomicMarkableReference类将boolean标记与引用关联起来,可以解决使用
AtomicInteger进行原子更新时可能出现的ABA问题。
AtomicStampedReference类将整数值与引用关联起来,可以解决使用AtomicInteger进行原子更新时可能出现的ABA问题。
4.字段更新原子类
字段更新原子类主要包括以下三个
·AtomicIntegerFieldUpdater:原子更新整型字段的更新器。
·AtomicLongFieldUpdater:原子更新长整型字段的更新器。
·AtomicReferenceFieldUpdater:原子更新引用类型中的字段。
首先介绍基础原子类。由于AtomicInteger、AtomicLong、AtomicBoolean三个基础原子类所提供的方法几乎相同,因此这里以AtomicInteger为例来介
可见性与有序性的原理
- 原子性、可见性、有序性是并发编程所面临的三大问题。Java通过CAS操作解决了并发编程中的原子性问题,本章为大家介绍Java如何解决剩余的两个问题——可见性和有序性问题
1.CPU物理缓存结构
- 由于CPU的运算速度比主存(物理内存)的存取速度快很多,为了提高处理速度,现代CPU不直接和主存进行通信,而是在CPU和主存之间设计了多层的Cache(高速缓存),越靠近CPU的高速缓存越快,容量也越小。
- PU高速缓存结构如图4-1所示。按照数据读取顺序和与CPU内核结合的紧密程度,CPU高速缓存有L1和L2高速缓存(即一级高速缓存和二级缓存高速),部分高端CPU还具有L3高速缓存(即三级高速缓存)。每一级高速缓存中所存储的数据都是下一级高速缓存的一部分,越靠近CPU的高速缓存读取越快,容量也越小。所以L1高速缓存容量很小,但存取速度最快,并且紧靠着使用它的CPU内核。L2容量大一些,存取速度也慢一些,并且仍然只能被一个单独的CPU核使用。L3在现代多核CPU中更普遍,容量更大、读取速度更慢些,能被同一个CPU芯片板上的所有CPU内核共享。最后,系统还拥有一块主存(即主内存),由系统中的所有CPU共享。拥有L3高速缓存的CPU,CPU存取数据的命中率可达95%,也就是说只有不到5%的数据需要从主存中去存取
- 图4-1中的L1高速缓存和L2高速缓存都只能被一个单独的CPU内核使用,L3高速缓存可以被同一个CPU芯片上的所有CPU内核共享,而主存可以由系统中的所有CPU共享。
- CPU内核读取数据时,先从L1高速缓存中读取,如果没有命中,再到L2、L3高速缓存中读取,假如这些高速缓存都没有命中,它就会到主存中读取所需要的数据。
- 高速缓存大大缩小了高速CPU内核与低速主存之间的速度差距。以三层高速缓存架构为例:
·L1高速缓存最接近CPU,容量最小(如32KB、64KB等)、存取速度最快,每个核上都有一个L1高速缓存。
·L2高速缓存容量更大(如256KB)、速度低些,在一般情况下,每个内核上都有一个独立的L2高速缓存。
·L3高速缓存最接近主存,容量最大(如12MB)、速度最低,由在同一个CPU芯片板上的不同CPU内核共享。
知名Java专家Martin和Mike在QCon Presentation演讲中给出了一些缓存未命中情况下的时间消耗参考数据,如表4-1所示。
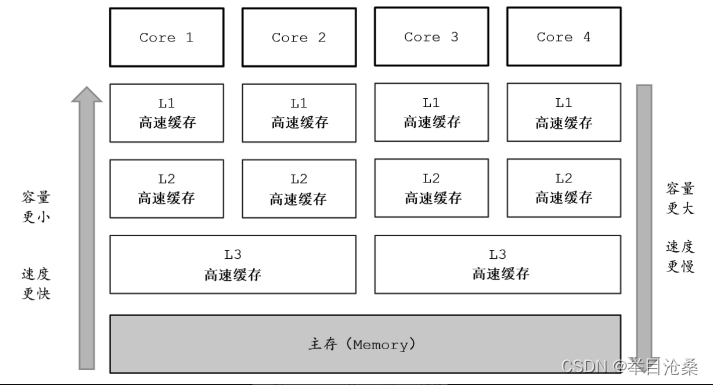
JUC显示锁的原理与实战
与Java内置锁不同,JUC显式锁是一种非常灵活的、使用纯Java语言实现的锁,这种锁的使用非常灵活,可以进行无条件的、可轮询的、定时的、可中断的锁获取和释放操作。由于JUC锁加锁和解锁的方法都是通过Java API显式进行的,因此也叫显式锁。
显式锁
- 使用Java内置锁时,不需要通过Java代码显式地对同步对象的监视器进行抢占和释放,这些工作由JVM底层完成,而且任何一个Java对象都能作为一个内置锁使用,所以Java的对象锁使用起来非常方便。但是,Java内置锁的功能相对单一,不具备一些比较高级的锁功能,比如:
(1)限时抢锁:在抢锁时设置超时时长,如果超时还未获得锁就放弃,不至于无限等下去。
(2)可中断抢锁:在抢锁时,外部线程给抢锁线程发一个中断信号,就能唤起等待锁的线程,并终止抢占过程。
(3)多个等待队列:为锁维持多个等待队列,以便提高锁的效率。比如在生产者-消费者模式实现中,生产者和消费者共用一把锁,该锁上维持两个等待队列,即一个生产者队列和一个消费者队列。- 除了以上功能问题之外,Java对象锁还存在性能问题。在竞争稍微激烈的情况下,Java对象锁会膨胀为重量级锁(基于操作系统的Mutex Lock实现),而重量级锁的线程阻塞和唤醒操作需要进程在内核态和用户态之间来回切换,导致其性能非常低。所以,迫切需要提供一种新的锁来提升争用激烈场景下锁的性能。
- Java显式锁就是为了解决这些Java对象锁的功能问题、性能问题而生的。JDK 5版本引入了Lock接口,Lock是Java代码级别的锁。为了与Java对象锁相区分,Lock接口叫作显式锁接口,其对象实例叫作显式锁对象。
显式锁Lock接口
- JDK 5版本引入了java.util.concurrent并发包,简称为JUC包,里面提供了各种高并发工具类,通过此JUC工具包可以在Java代码中实现功能非常强大的多线程并发操作。所以,Java显式锁也叫JUC显式锁。
- JUC出自并发大师Doug Lea之手,Doug Lea对Java并发性能的提升做出了巨大的贡献。除了实现JUC包外,Doug Lea还提供了高并发IO模式——Reactor模式多个版本的参考实现。Reactor模式是Java高并发服务端编程的一个至关重要的模式,有关其原理和详细知识请参考本书的上一卷《Java高并发核心编程 卷1:NIO、Netty、Redis、ZooKeeper》。
- Lock接口位于java.util.concurrent.locks包中,是JUC显式锁的一个抽象,Lock接口的主要抽象方法如表5-1所示。
- JUC包中提供了一系列的显式锁实现类(如ReentrantLock),当然也允许应用程序提供自定义的锁实现类。
- 与synchronized关键字不同,显式锁不再作为Java内置特性来实现,而是作为Java语言可编程特性来实现。这就为多种不同功能的锁实现留下了空间,各种锁实现可能有不同的调度算法、性能特性或者锁定语义。
- 从Lock提供的接口方法可以看出,显式锁至少比Java内置锁多了以下优势:
(1)可中断获取锁使用synchronized关键字获取锁的时候,如果线程没有获取到被阻塞,阻塞期间该线程是不响应中断信号(interrupt)的;而调用Lock.lockInterruptibly()方法获取锁时,如果线程被中断,线程将抛出中断异常。
(2)可非阻塞获取锁使用synchronized关键字获取锁时,如果没有成功获取,线程只有被阻塞;而调用Lock.tryLock()方法获取锁时,如果没有获取成功,线程也不会被阻塞,而是直接返回false。
(3)可限时抢锁调用Lock.tryLock(long time,TimeUnit unit)方法,显式锁可以设置限定抢占锁的超时时间。而在使用synchronized关键字获取锁时,如果不能抢到锁,线程只能无限制阻塞。
除了以上能通过Lock接口直接观察出来的三点优势之外,显式锁还有不少其他的优势,稍后在介绍显式锁种类繁多的实现类时,大家就能感觉到。
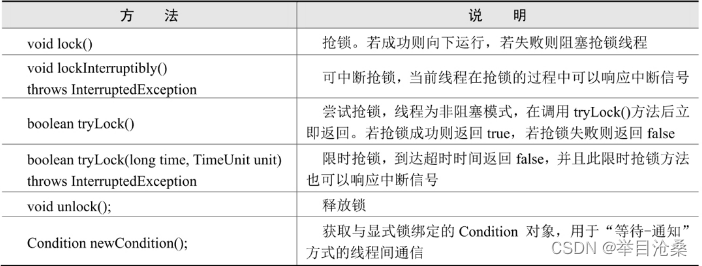
可重入锁ReentrantLock
- ReentrantLock是JUC包提供的显式锁的一个基础实现类,ReentrantLock类实现了Lock接口,它拥有与synchronized相同的并发性和内存语义,但是拥有了限时抢占、可中断抢占等一些高级锁特性。此外,ReentrantLock基于内置的抽象队列同步器(Abstract Queued Synchronized,AQS)实现,在争用激烈的场景下,能表现出表内置锁更佳的性能。
- 抽象队列同步器是JUC包同步机制的基础设施,更是JUC锁框架的基础,会在第6章进行重点和专题介绍。
- ReentrantLock是一个可重入的独占(或互斥)锁,其中两个修饰词的含义为
(1)可重入的含义:表示该锁能够支持一个线程对资源的重复加锁,也就是说,一个线程可以多次进入同一个锁所同步的临界区代码块。比如,同一线程在外层函数获得锁后,在内层函数能再次获取该锁,甚至多次抢占到同一把锁。下面是一段对可重入锁进行两次抢占和释放的伪代码,具体如下:
lock.lock(); // 第一次获取锁
lock.lock(); // 第二次获取锁,重新进入
try {
// 临界区代码块
} finally {
lock.unlock(); // 释放锁
lock.unlock(); // 第二次释放锁
}
(2)独占的含义:在同一时刻只能有一个线程获取到锁,而其他获取锁的线程只能等待,只有拥有锁的线程释放了锁后,其他的线程才能够获取锁。
- 一个简单地使用ReentrantLock进行同步累加的演示案例如下:
package com.crazymakercircle.demo.lock;
// 省略import
public class LockTest
{
@org.junit.Test
public void testReentrantLock()
{
// 每个线程的执行轮数
final int TURNS = 1000;
// 线程数
final int THREADS = 10;
//线程池,用于多线程模拟测试
ExecutorService pool = Executors.newFixedThreadPool(THREADS);
//创建一个可重入、独占的锁对象
Lock lock = new ReentrantLock();
// 倒数闩
CountDownLatch countDownLatch = new CountDownLatch(THREADS);
long start = System.currentTimeMillis();
//10个线程并发执行
for (int i = 0; i < THREADS; i++)
{
pool.submit(() ->
{
try
{
//累加 1000 次
for (int j = 0; j < TURNS; j++)
{
//传入锁,执行一次累加
IncrementData.lockAndFastIncrease(lock);
}
Print.tco("本线程累加完成");
} catch (Exception e)
{
e.printStackTrace();
}
//线程执行完成,倒数闩减少一次
countDownLatch.countDown();
});
}
try
{
//等待倒数闩归零,所有线程结束
countDownLatch.await();
} catch (InterruptedException e)
{
e.printStackTrace();
}
float time = (System.currentTimeMillis() - start) / 1000F;
//输出统计结果
Print.tcfo("运行的时长为:" + time);
Print.tcfo("累加结果为:" + IncrementData.sum);
}
// 省略其他代码
}
& 分离变与不变是软件设计的一个基本原则。本章后续会演示多种锁(包括乐观锁、悲观锁、公平锁、可中断锁、自旋锁等等)的使用,在这些使用案例中,变化的部分为锁的创建代码,而不变的部分为锁的使用代码。因为JUC中的显式锁都实现了Lock接口,所以对于不同锁对象的使用代码是模板化的、套路化的。我们可以将演示案例中创建锁的代码(变化的部分)和使用锁的代码(不变的部分)进行分离。出于“分离变与不变”的设计原则,这里将临界区使用锁的代码进行了抽取和封装,形成一个可以复用的独立类——IncrementData累加类,具体代码如下:
package com.crazymakercircle.demo.lock;
// 省略import
//封装锁的使用代码
public class IncrementData
{
public static int sum = 0;
public static void lockAndFastIncrease(Lock lock)
{
lock.lock(); //step1:抢占锁
try
{
//step2:执行临界区代码
sum++;
} finally
{
lock.unlock(); //step3:释放锁
}
}
// 省略其他代码
}
运行以上使用ReentrantLock进行累加同步的演示案例,其结果如下:
使用显式锁的模板
- 代码上一小节讲到,因为JUC中的显式锁都实现了Lock接口,所以不同类型的显式锁对象的使用方法都是模板化的、套路化的,本小节专门介绍一下使用显式锁的模板代码。
1.使用lock()方法抢锁的模板代码
- 通常情况下,大家会调用lock()方法进行阻塞式的锁抢占,其模板代码如下:
//创建锁对象,SomeLock为Lock的某个实现类,如ReentrantLock
Lock lock = new SomeLock();
lock.lock(); //step1:抢占锁
try {
//step2:抢锁成功,执行临界区代码
} finally {
lock.unlock(); //step3:释放锁
}
- 以上抢锁模板代码有以下几个需要注意的要点:
- (1)释放锁操作lock.unlock()必须在try-catch结构的finally块中执行,否则,如果临界区代码抛出异常,锁就有可能永远得不到释放。
- (2)抢占锁操作lock.lock()必须在try语句块之外,而不是放在try语句块之内。为什么呢?原因之一是lock()方法没有申明抛出异常,所以可以不包含到try块中;原因之二是lock()方法并不一定能够抢占锁成功,如果没有抢占成功,当然也就不需要释放锁,而且在没有占有锁的情况下去释放锁,可能会导致运行时异常。
- (3)在抢占锁操作lock.lock()和try语句之间不要插入任何代码,避免抛出异常而导致释放锁操作lock.unlock()执行不到,导致锁无法被释放。
- 以上代码的抢锁操作在try语句块之内,如果抢锁操作没有成功,也就是当前线程没有获取到锁,在finally语句块调用unlock()方法时就会抛出异常。

2.调用tryLock()方法非阻塞抢锁的模板代码
- lock()是阻塞式抢占,在没有抢到锁的情况下,当前线程会阻塞。如果不希望线程阻塞,可以调用tryLock()方法抢占锁。tryLock()是非阻塞抢占,在没有抢到锁的情况下,当前线程会立即返回,不会被阻塞。
- 调用tryLock()方法非阻塞抢占锁,大致的模板代码如下:
//创建锁对象,SomeLock为Lock的某个实现类,如ReentrantLock
Lock lock = new SomeLock();
if (lock.tryLock()) { //step1:尝试抢占锁
try {
//step2:抢锁成功,执行临界区代码
} finally {
lock.unlock(); //step3:释放锁
}
}
else
{
//step4:抢锁失败,执行后备动作
}
- 调用tryLock()方法时,线程拿不到锁就立即返回,这种处理方式在实际开发中使用不多,但是其重载版本tryLock(long time,TimeUnit unit)方法在限时阻塞抢锁的场景中非常有用。
3.调用tryLock(long time,TimeUnit unit)方法抢锁的模板代码
- tryLock(long time,TimeUnit unit)方法用于限时抢锁,该方法在抢锁时会进行一段时间的阻塞等待,其中的time参数代表最大的阻塞时长,unit参数为时长的单位(如秒)。
- 调用tryLock(long time,TimeUnit unit)方法限时抢锁,其大致的代码模板如下:
//创建锁对象,SomeLock为Lock的某个实现类,如ReentrantLock
Lock lock = new SomeLock();
//抢锁时阻塞一段时间,如1秒
if (lock.tryLock(1, TimeUnit.SECONDS)) { //step1:限时阻塞抢占
try {
//step2:抢锁成功,执行临界区代码
} finally {
lock.unlock(); //step3:释放锁
}
}
else
{
//限时抢锁失败,执行后备操作
}
- 对lock()、tryLock()、tryLock(long time,TimeUnit unit)这三个方法总结如下:
- (1)lock()方法用于阻塞抢锁,抢不到锁时线程会一直阻塞。
- (2)tryLock()方法用于尝试抢锁,该方法有返回值,如果成功就返回true,如果失败(锁已被其他线程获取)就返回false。此方法无论如何都会立即返回,在抢不到锁时,线程不会像调用lock()方法那样一直被阻塞。
- (3)tryLock(long time,TimeUnit unit)方法和tryLock()方法类似,只不过这个方法在抢不到锁时会阻塞一段时间。如果在阻塞期间获取到锁就立即返回true,超时则返回false。
基于显式锁进行“等待-通知”方式的线程间通信
- 在前面介绍Java的线程间通信机制时,基于Java内置锁实现一种简单的“等待-通知”方式的线程间通信:通过Object对象的wait、notify两类方法作为开关信号,用来完成通知方线程和等待方线程之间的通信。
- “等待-通知”方式的线程间通信机制,具体来说是指一个线程A调用了同步对象的wait()方法进入等待状态,而另一线程B调用了同步对象的notify()或者notifyAll()方法去唤醒等待线程,当线程A收到线程B的唤醒通知后,就可以重新开始执行了。
- 需要特别注意的是,在通信过程中,线程需要拥有同步对象的监视器,在执行Object对象的wait、notify方法之前,线程必须先通过抢占到内置锁而成为其监视器的Owner。
- 与Object对象的wait、notify两类方法相类似,基于Lock显式锁,JUC也为大家提供了一个用于线程间进行“等待-通知”方式通信的接口——java.util.concurrent.locks.Condition。
1.Condition接口的主要方法
public interface Condition
{
//方法1:等待。此方法在功能上与 Object.wait()语义等效
//使当前线程加入 await() 等待队列中,并释放当前锁
//当其他线程调用signal()时,等待队列中的某个线程会被唤醒,重新去抢锁
void await() throws InterruptedException;
//方法2:通知。此方法在功能上与Object.notify()语义等效
// 唤醒一个在 await()等待队列中的线程
void signal();
//方法3:通知全部。唤醒 await()等待队列中所有的线程
//此方法与object.notifyAll()语义上等效
void signalAll();
//方法4:限时等待。此方法与await()语义等效
//不同点在于,在指定时间time等待超时后,如果没有被唤醒,线程将中止等待
//线程等待超时返回false,其他情况返回true
boolean await(long time, TimeUnit unit) throws InterruptedException;
}
- 以上是Condition接口的常用方法,await(系列)方法对应于Object.wait方法,signal方法对应于Object.notify方法,signalAll方法对应于Object.notifyAll方法。
- 为了避免与Object中的wait/notify/notifyAll方法在使用时发生混淆,JUC对Condition接口的方法改变了名称,同样的wait/notify/notifyAll方法,在Condition接口中名称被改为await/signal/signalAll方法。
- Condition的“等待-通知”方法和Object的“等待-通知”方法的语义等效关系为:
·Condition类的await方法和Object类的wait方法等效。
·Condition类的signal方法和Object类的notify方法等效。
·Condition类的signalAll方法和Object类的notifyAll方法等效。
Condition对象的signal(通知)方法和同一个对象的await(等待)方法是一一配对使用的,也就是说,一个Condition对象的signal(或signalAll)方法不能去唤醒其他Condition对象上的await线程。- Condition对象是基于显式锁的,所以不能独立创建一个Condition对象,而是需要借助于显式锁实例去获取其绑定的Condition对象。不过,每一个Lock显式锁实例都可以有任意数量的Condition对象。具体来说,可以通过lock.newCondition()方法去获取一个与当前显式锁绑定的Condition实例,然后通过该Condition实例进行“等待-通知”方式的线程间通信。
2.显式锁Condition演示案例
- 下面是一个简单的通过Condition完成线程间“等待-通知”方式通信的演示实例:
package com.crazymakercircle.demo.lock;
// 省略import
public class ReentrantCommunicationTest
{
// 创建一个显式锁
static Lock lock = new ReentrantLock();
// 获取一个显式锁绑定的Condition对象
static private Condition condition = lock.newCondition();
// 等待线程的异步目标任务
static class WaitTarget implements Runnable
{
public void run()
{
lock.lock(); // ①抢锁
try
{
Print.tcfo("我是等待方");
condition.await(); // ② 开始等待,并且释放锁
Print.tco("收到通知,等待方继续执行");
} catch (InterruptedException e)
{
e.printStackTrace();
} finally
{
lock.unlock();//释放锁
}
}
}
//通知线程的异步目标任务
static class NotifyTarget implements Runnable
{
public void run()
{
lock.lock(); //③抢锁
try
{
Print.tcfo("我是通知方");
condition.signal(); // ④发送通知
Print.tco("发出通知了,但是线程还没有立马释放锁");
} finally
{
lock.unlock(); //⑤释放锁之后,等待线程才能获得锁
}
}
}
public static void main(String[] args) throws InterruptedException
{
//创建等待线程
Thread waitThread = new Thread(new WaitTarget(), "WaitThread");
//启动等待线程
waitThread.start();
sleepSeconds(1); //稍等一下
//创建通知线程
Thread notifyThread = new Thread(new NotifyTarget(), "NotifyThread");
//启动通知线程
notifyThread.start();
}
}

以上演示案例中,使用ReentrantLock(重入锁)作为显式锁的实现类,然后通过该显式锁去获取一个Condition实例。
在调用await()方法前,等待线程必须获得显式锁(如语句①),await()方法会让当前线程加入Condition对象等待队列中。在语句②调用await()方法后,线程会释放当前占用的显式锁,以便通知线程能够抢到锁。通知线程抢到锁之后,才可以进入临界区发送通知。
不过,在调用signal()方法前,通知线程也必须获得相应的显式锁(如语句③)。在语句④调用signal()方法后,JUC会从Condition对象等待队列中唤醒一个线程。当等待线程被唤醒后,将会重新尝试获得与Condition对象绑定的显式锁,一旦抢占成功将继续执行。所以,通知线程在调用signal()方法后,一定要记得释放当前占用的显式锁(如语句⑤),只有这样,被唤醒的等待线程才能有获得锁的机会,才能继续执行。
由于Lock有公平锁和非公平锁之分,而Condition是与Lock绑定的,因此就有与Lock一样的公平特性:如果是公平锁,等待线程按照FIFO(先进先出)顺序从Condition对象的等待队列中唤醒;如果是非公平锁,后续的唤醒次序就不保证FIFO顺序了。说明
作为练习,建议大家基于Condition的“等待-通知”通信机制实现一个更高性能的生产者-消费者程序。由于其核心的实现逻辑与第2章基于Java内置锁的“等待-通知”通信机制所实现的生产者-消费者程序相同,因此这里不再赘述
LockSupport
LockSupport是JUC提供的一个线程阻塞与唤醒的工具类,该工具类可以让线程在任意位置阻塞和唤醒,其所有的方法都是静态方法
1.LockSupport的常用方法
LockSupport的常用方法大致如下:
// 无限期阻塞当前线程
public static void park();
// 唤醒某个被阻塞的线程
public static void unpark(Thread thread);
// 阻塞当前线程,有超时时间的限制
public static void parkNanos(long nanos);
// 阻塞当前线程,直到某个时间
public static void parkUntil(long deadline);
// 无限期阻塞当前线程,带blocker对象,用于给诊断工具确定线程受阻塞的原因
public static void park(Object blocker);
// 限时阻塞当前线程,带blocker对象
public static void parkNanos(Object blocker, long nanos);
// 获取被阻塞线程的blocker对象,用于分析阻塞的原因
public static Object getBlocker(Thread t);
- LockSupport的方法主要有两类:park和unpark。park的英文意思为停车,如果把Thread看成一辆车的话,park()方法就是让车停下,其作用是将调用park()方法的当前线程阻塞;而unpark()方法是让车启动,然后跑起来,其作用是将指定线程Thread唤醒。
2.LockSupport的演示实例
下面是一个简单的通过LockSupport阻塞和唤醒线程的演示实例:
package com.crazymakercircle.demo.lock;
// 省略import
public class LockSupportDemo
{
public static class ChangeObjectThread extends Thread
{
public ChangeObjectThread(String name)
{
super(name);
}
@Override
public void run()
{
Print.tco("即将进入无限时阻塞");
//阻塞当前线程
LockSupport.park();
if (Thread.currentThread().isInterrupted())
{
Print.tco("被中断了,但仍然会继续执行");
} else
{
Print.tco("被重新唤醒了");
}
}
}
//LockSupport 测试用例
@org.junit.Test
public void testLockSupport()
{
ChangeObjectThread t1 = new ChangeObjectThread("线程一");
ChangeObjectThread t2 = new ChangeObjectThread("线程二");
//启动线程一
t1.start();
sleepSeconds(1);
//启动线程二
t2.start();
sleepSeconds(1);
//中断线程一
t1.interrupt();
//唤醒线程二
LockSupport.unpark(t2);
}
}

3.LockSupport.park()和Thread.sleep()的区别
从功能上说,LockSupport.park()与Thread.sleep()方法类似,都是让线程阻塞,二者的区别如下:
(1)Thread.sleep()没法从外部唤醒,只能自己醒过来;而被LockSupport.park()方法阻塞的线程可以通过调用LockSupport.unpark()方法去唤醒。
(2)Thread.sleep()方法声明了InterruptedException中断异常,这是一个受检异常,调用者需要捕获这个异常或者再抛出;而调用LockSupport.park()方法时不需要捕获中断异常。
(3)被LockSupport.park()方法、Thread.sleep()方法所阻塞的线程有一个特点,当被阻塞线程的Thread.interrupt()方法被调用时,被阻塞线程的中断标志将被设置,该线程将被唤醒。不同的是,二者对中断信号的响应方式不同:LockSupport.park()方法不会抛出InterruptedException异常,仅仅设置了线程的中断标志;而Thread.sleep()方法会抛出InterruptedException异常。
(4)与Thread.sleep()相比,调用LockSupport.park()能更精准、更加灵活地阻塞、唤醒指定线程。
(5)Thread.sleep()本身就是一个Native方法;LockSupport.park()并不是一个Native方法,只是调用了一个Unsafe类的Native方法(名字也叫park)去实现。
(6)LockSupport.park()方法还允许设置一个Blocker对象,主要用来供监视工具或诊断工具确定线程受阻塞的原因。
通过Thread.sleep()方法进入阻塞的线程不会释放持有的锁,因此在持有锁的时候调用该方法需要谨慎。那么通过LockSupport.park()方法进入阻塞的线程,会不会释放所持有的锁呢?当然也不会。
4.LockSupport.park()与Object.wait()的区别
(1)Object.wait()方法需要在synchronized块中执行,而LockSupport.park()可以在任意地方执行。
(2)当被阻塞线程被中断时,Object.wait()方法抛出了中断异常,调用者需要捕获或者再抛出;当被阻塞线程被中断时,LockSupport.park()不会抛出异常,调用时不需要处理中断异常。
(3)如果线程在没有被Object.wait()阻塞之前被Object.notify()唤醒,也就是说在Object.wait()执行之前去执行Object.notify(),就会抛出IllegalMonitorStateException异常,是不被允许的;而线程在没有被LockSupport.park()阻塞之前被LockSupport.unPark()唤醒,也就是说在LockSupport.park()执行之前去执行LockSupport.unPark(),不会抛出任何异常,是被允许的。
下面的演示代码演示在LockSupport.park()执行之前,通过执行LockSupport.unPark()唤醒一个线程,具体如下:
package com.crazymakercircle.demo.lock;
// 省略import
public class LockSupportDemo
{
@org.junit.Test
public void testLockSupport2()
{
Thread t1 = new Thread(() ->
{
try
{
Thread.sleep(1000); //使sleep阻塞当前线程,时长为1秒
} catch (InterruptedException e)
{
e.printStackTrace();
}
Print.tco("即将进入无限时阻塞");
//使用LockSupport.park()阻塞当前线程
LockSupport.park();
Print.tco("被重新唤醒了");
}, "演示线程"); //通过匿名对象创建一个线程
t1.start();
//唤醒一次没有使用 LockSupport.park()阻塞的线程
LockSupport.unpark(t1);
//再唤醒一次没有调用 LockSupport.park()阻塞的线程
LockSupport.unpark(t1);
sleepSeconds(2);
//中断线程一
//第三唤醒调用 LockSupport.park()阻塞的线程
LockSupport.unpark(t1);
}
// 省略其他
}
通过结果可以看出,前两次LockSupport.unpark(t1)唤醒操作没有发生任何作用,因为线程t1还没有被LockSupport.park()阻塞。只有在被LockSupport.park()阻塞之后,LockSupport.unpark(t1)唤醒操作才能将线程t1唤醒。
显式锁的分类
- 显式锁有很多种,从不同的角度来看,显式锁大概有以下几种分类:可重入锁和不可重入锁、悲观锁和乐观锁、公平锁和非公平锁、共享锁和独占锁、可中断锁和不可中断锁。
1.可重入锁和不可重入锁
- 从同一个线程是否可以重复占有同一个锁对象的角度来分,显式锁可以分为可重入锁与不可重入锁。可重入锁也叫作递归锁,指的是一个线程可以多次抢占同一个锁。例如,线程A在进入外层函数抢占了一个Lock显式锁之后,当线程A继续进入内层函数时,如果遇到有抢占同一个Lock显式锁的代码,线程A依然可以抢到该Lock显式锁。
- 不可重入锁与可重入锁相反,指的是一个线程只能抢占一次同一个锁。例如,线程A在进入外层函数抢占了一个Lock显式锁之后,当线程A继续进入内层函数时,如果遇到有抢占同一个Lock显式锁的代码,线程A不可以抢到该Lock显式锁。除非线程A提前释放了该Lock显式锁,才能第二次抢占该锁。
- JUC的ReentrantLock类是可重入锁的一个标准实现类。
2.悲观锁和乐观锁
- 从线程进入临界区前是否锁住同步资源的角度来分,显式锁可以分为悲观锁和乐观锁
悲观锁
- 悲观锁就是悲观思想,每次进入临界区操作数据的时候都认为别的线程会修改,所以线程每次在读写数据时都会上锁,锁住同步资源,这样其他线程需要读写这个数据时就会阻塞,一直等到拿到锁。总体来说,悲观锁适用于写多读少的场景,遇到高并发写时性能高。
- Java的synchronized重量级锁是一种悲观锁。
乐观锁
- 乐观锁是一种乐观思想,每次去拿数据的时候都认为别的线程不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,采取在写时先读出当前版本号,然后加锁操作(比较跟上一次的版本号,如果一样就更新),如果失败就要重复读-比较-写的操作。总体来说,乐观锁适用于读多写少的场景,遇到高并发写时性能低。
- Java中的乐观锁基本都是通过CAS自旋操作实现的。CAS是一种更新原子操作,比较当前值跟传入值是否一样,是则更新,不是则失败。在争用激烈的场景下,CAS自旋会出现大量的空自旋,会导致乐观锁性能大大降低。
- Java中的乐观锁基本都是通过CAS自旋操作实现的。CAS是一种更新原子操作,比较当前值跟传入值是否一样,是则更新,不是则失败。在争用激烈的场景下,CAS自旋会出现大量的空自旋,会导致乐观锁性能大大降低。
- Java的synchronized轻量级锁是一种乐观锁。另外,JUC中基于抽象队列同步器(AQS)实现的显式锁(如ReentrantLock)都是乐观锁。
- 注意
- 既然在争用激烈的场景下乐观锁的性能非常低,那么为什么JUC的显式锁都是乐观锁呢?根本的原因是,JUC的显式锁都是基于AQS实现的,而AQS通过对队列的使用很大程度上减少了锁的争用,极大地减少了空的CAS自旋。所以,即使在争用激烈的场景下,基于AQS的JUC乐观锁也能表现出比悲观锁更佳的性能。
详情
- 独占锁其实就是一种悲观锁,Java的synchronized是悲观锁。悲观锁可以确保无论哪个线程持有锁,都能独占式访问临界区。虽然悲观锁的逻辑非常简单,但是存在不少问题。
悲观锁存在的问题
- 悲观锁总是假设会发生最坏的情况,每次线程读取数据时,也会上锁。这样其他线程在读取数据时就会被阻塞,直到它拿到锁。传统的关系型数据库用到了很多悲观锁,比如行锁、表锁、读锁、写锁等。
- 悲观锁机制存在以下问题:
(1)在多线程竞争下,加锁、释放锁会导致比较多的上下文切换和调度延时,引起性能问题。
(2)一个线程持有锁后,会导致其他所有抢占此锁的线程挂起。
(3)如果一个优先级高的线程等待一个优先级低的线程释放锁,就会导致线程的优先级倒置,从而引发性能风险。- 解决以上悲观锁的这些问题的有效方式是使用乐观锁去替代悲观锁。与之类似,数据库操作中的带版本号数据更新、JUC包的原子类,都使用了乐观锁的方式提升性能。
通过CAS实现乐观锁
- 乐观锁的操作主要就是两个步骤:
- (1)第一步:冲突检测。
- (2)第二步:数据更新。
- 乐观锁一种比较典型的就是CAS原子操作,JUC强大的高并发性能是建立在CAS原子之上的。CAS操作中包含三个操作数:
需要操作的内存位置(V)、
进行比较的预期原值(A)和
拟写入的新值(B)。- 如果内存位置V的值与预期原值A相匹配,那么处理器会自动将该位置的值更新为新值B;否则处理器不做任何操作。
- CAS操作可以非常清晰地分为两个步骤:
(1)检测位置V的值是否为A。
(2)如果是,就将位置V更新为B值;否则不要更改该位置。- CAS操作的两个步骤其实与乐观锁操作的两个步骤是一致的,都是在冲突检测后进行数据更新。
- 乐观锁是一种思想,而CAS是这种思想的一种实现。实际上,如果需要完成数据的最终更新,仅仅进行一次CAS操作是不够的,一般情况下,需要进行自旋操作,即不断地循环重试CAS操作直到成功,这也叫CAS自旋。
- 通过CAS自旋,在不使用锁的情况下实现多线程之间的变量同步,也就是说,在没有线程被阻塞的情况下实现变量的同步,这叫作“非阻塞同步”(Non-Blocking Synchronization),或者说“无锁同步”。使用基于CAS自旋的乐观锁进行同步控制,属于无锁编程(Lock Free)的一种实践。
- 接下来为大家介绍如何基于CAS自旋实现一个简单的自旋锁。
不可重入的自旋锁
- 自旋锁的基本含义为:当一个线程在获取锁的时候,如果锁已经被其他线程获取,调用者就一直在那里循环检查该锁是否已经被释放,一直到获取到锁才会退出循环。
- CAS自旋锁的实现原理为:抢锁线程不断进行CAS自旋操作去更新锁的owner(拥有者),如果更新成功,就表明已经抢锁成功,退出抢锁方法。如果锁已经被其他线程获取(也就是owner为其他线程),调用者就一直在那里循环进行owner的CAS更新操作,一直到成功才会退出循环。
- 作为演示,这里先实现一个简单版本的自旋锁——不可重入的自旋锁,具体的代码如下:
package com.crazymakercircle.demo.lock.custom;
// 省略import
public class SpinLock implements Lock
{
/**当前锁的拥有者
* 使用Thread 作为同步状态
*/
private AtomicReference<Thread> owner = new AtomicReference<>();
/**
* 抢占锁
*/
@Override
public void lock()
{
Thread t = Thread.currentThread();
//自旋
while (owner.compareAndSet(null, t))
{
// DO nothing
Thread.yield();//让出当前剩余的CPU时间片
}
}
/**
* 释放锁
*/
@Override
public void unlock()
{
Thread t = Thread.currentThread();
//只有拥有者才能释放锁
if (t == owner.get())
{
// 设置拥有者为空,这里不需要 compareAndSet操作
// 因为已经通过owner做过线程检查
owner.set(null);
}
}
// 省略其他代码
}
- 仔细分析以上代码就可以看出,上述SpinLock是不支持重入的,即当一个线程第一次已经获取到了该锁,在锁没有被释放之前,如果又一次重新获取该锁,第二次将不能成功获取到。
可重入的自旋锁
- 为了实现可重入锁,这里引入一个计数器,用来记录一个线程获取锁的次数。一个简单的可重入的自旋锁的代码大致如下:
package com.crazymakercircle.demo.lock.custom;
// 省略import
public class ReentrantSpinLock implements Lock
{
/**当前锁的拥有者
* 使用拥有者 Thread 作为同步状态,而不是使用一个简单的整数作为同步状态
*/
private AtomicReference<Thread> owner = new AtomicReference<>();
/**
* 记录一个线程重复获取锁的次数
* 此变量为同一个线程在操作,没有必要加上volatile保障可见性和有序性
*/
private int count = 0;
/**
* 抢占锁
*/
@Override
public void lock()
{
Thread t = Thread.currentThread();
// 如果是重入,增加重入次数后返回
if (t == owner.get())
{
++count;
return;
}
//自旋
while (owner.compareAndSet(null, t))
{
// DO nothing
Thread.yield();//让出当前剩余的CPU时间片
}
}
/**
* 释放锁
*/
@Override
public void unlock()
{
Thread t = Thread.currentThread();
//只有拥有者才能释放锁
if (t == owner.get())
{
if (count > 0)
{
// 如果重入的次数大于0, 减少重入次数后返回
--count;
} else
{
// 设置拥有者为空
// 这里不需要 compareAndSet, 因为已经通过owner做过线程检查
owner.set(null);
}
}
}
// 省略其他代码
}
- 自旋锁的特点:线程获取锁的时候,如果锁被其他线程持有,当前线程将循环等待,直到获取到锁。线程抢锁期间状态不会改变,一直是运行状态(RUNNABLE),在操作系统层面线程处于用户态。
- 自旋锁的问题:在争用激烈的场景下,如果某个线程持有锁的时间太长,就会导致其他空自旋的线程耗尽CPU资源。另外,如果大量的线程进行空自旋,还可能导致硬件层面的“总线风暴”。
CAS可能导致总线风暴
- 这里通过从CPU(以Intel X86为例)平台下的汇编代码入手为大家分析一下CAS的实现原理。下面是sun.misc.Unsafe类的compareAndSwapInt()方法的源代码:
public final class Unsafe {
//Unsafe中的CAS操作
public final native boolean compareAndSwapInt(
Object o, //操作对象
long offset, //字段偏移
int expected, //预期值
int x); //待更新的值
// 省略不相干代码
}
- sun.misc.Unsafe类的compareAndSwapInt()方法是一个Native方法调用,该本地方法在JDK中依次调用的C++代码为:
#define LOCK_IF_MP(mp) __asm cmp mp, 0 \
__asm je L0 \
__asm _emit 0xF0 \
__asm L0:
inline jint Atomic::cmpxchg(jint exchange_value,
volatile jint* dest, jint compare_value) {
// alternative for InterlockedCompareExchange
int mp = os::is_MP();
__asm {
mov edx, dest
mov ecx, exchange_value
mov eax, compare_value
LOCK_IF_MP(mp)
cmpxchg dword ptr [edx], ecx
}
}
- 以上程序会根据当前CPU的类型是否为多核CPU来决定是否为cmpxchg指令添加lock前缀。如果程序在多核CPU上运行,就为cmpxchg指令加上lock前缀(lock cmpxchg)。反之,如果程序在单核CPU上运行,就省略lock前缀,因为单核CPU不需要lock前缀提供的内存屏障效果。
- 接下来,以SMP架构的CPU为例分析一下CAS可能导致的“总线风暴”。
- 目前的CPU架构大体可以分为三类:多处理器结构(Symmetric Multi-Processor,SMP);非一致存储访问结构(Non-Uniform Memory Access,NUMA)和海量并行处理结构(Massive Parallel Processing,MPP)。常见的PC、手机、老式服务器都是SMP架构,其架构简单,但拓展性能非常差。第4章在介绍volatile关键字原理时讲到,lock前缀指令有以下三个作用:
(1)将当前CPU缓存行的数据立即写回系统内存。
(2)lock前缀指令会引起在其他CPU中缓存了该内存地址的数据无效。
(3)lock前缀指令禁止指令重排。- 由于在Intel X86平台下CAS的汇编指令lock cmpxchg也是一个lock前缀指令,因此CAS操作和volatile一样,也需要CPU保障变量的缓存一致性。
- 在SMP架构的CPU平台上,所有的Core(内核)会共享一条总线(BUS),靠此总线连接主存。每个核都有自己的高速缓存,各核相对于BUS对称分布。因此,这种结构称为“对称多处理器”。一个8核的SMP架构CPU大致如图5-1所示。
- 假设Core 1和Core 2可同时把某个变量加载到自己的高速缓存中,当Core 1在自己的高速缓存中修改这个位置的值时,会通过总线使Core 2中L1高速缓存对应的值“失效”,而Core 2一旦发现自己缓存中的值失效,就会通过总线从内存中读取最新的值,使得Core 2和Core 1中的值再次一致,这样CPU就保障了变量的“缓存一致性”。
- 前面讲到,CPU会通过MESI协议保障变量的缓存一致性。为了保障“缓存一致性”,不同的内核需要通过总线来回通信,因而所产生的流量一般被称为“缓存一致性流量”。因为总线被设计为固定的“通信能力”,如果缓存一致性流量过大,总线将成为瓶颈,这就是所谓的“总线风暴”。
- 总线风暴当然与CPU的架构和设计有关,并不是所有的CPU都会产生总线风暴。
- 由于使用lock前缀指令的Java操作(包括CAS、volatile)恰恰会产生缓存一致性流量,当有很多线程同时执行lock前缀指令操作时,在SMP架构的CPU平台上必然会导致总线风暴。
- 前面讲到,在争用激烈的场景下,Java轻量级锁会快速膨胀为重量级锁,其本质上一是为了减少CAS空自旋,二是为了避免同一时间大量CAS操作所导致的总线风暴。
- 那么,JUC基于CAS实现的轻量级锁如何避免总线风暴呢?答案是:使用队列对抢锁线性进行排队,最大程度上减少了CAS操作数量。
CLH自旋锁
- CLH锁其实就是一种基于队列(具体为单向链表)排队的自旋锁,由于是Craig、Landin和Hagersten三人一起发明的,因此被命名为CLH锁,也叫CLH队列锁。
- 简单的CLH锁可以基于单向链表实现,申请加锁的线程首先会通过CAS操作在单向链表的尾部增加一个节点,之后该线程只需要在其前驱节点上进行普通自旋,等待前驱节点释放锁即可。由于CLH锁只有在节点入队时进行一下CAS的操作,在节点加入队列之后,抢锁线程不需要进行CAS自旋,只需普通自旋即可。因此,在争用激烈的场景下,CLH锁能大大减少CAS操作的数量,以避免CPU的总线风暴。
- JUC中显式锁基于AQS抽象队列同步器,而AQS是CLH锁的一个变种,为了方便大家理解AQS的原理(此为Java工程师的必备知识),这里详细介绍一下CLH锁的实现和核心原理。
- 1.实现CLH锁的一个学习版本
首先为大家提供一个CLH锁的简单实现版本,代码如下:
package com.crazymakercircle.demo.lock.custom;
// 省略import
public class CLHLock implements Lock
{
/**
* 当前节点的线程本地变量
*/
private static ThreadLocal<Node> curNodeLocal = new ThreadLocal();
/**
* CLHLock队列的尾部指针,使用AtomicReference,方便进行CAS操作
*/
private AtomicReference<Node> tail = new AtomicReference<>(null);
public CLHLock()
{
//设置尾部节点
tail.getAndSet(Node.EMPTY);
}
//加锁操作:将节点添加到等待队列的尾部
@Override
public void lock()
{
Node curNode = new Node(true, null);
Node preNode = tail.get();
//CAS自旋:将当前节点插入队列的尾部
while (!tail.compareAndSet(preNode, curNode))
{
preNode = tail.get();
}
//设置前驱节点
curNode.setPrevNode(preNode);
// 自旋,监听前驱节点的locked变量,直到其值为false
// 若前驱节点的locked状态为true,则表示前一个线程还在抢占或者占有锁
while (curNode.getPrevNode().isLocked())
{
//让出CPU时间片,提高性能
Thread.yield();
}
// 能执行到这里,说明当前线程获取到了锁
// Print.tcfo("获取到了锁!!!");
//将当前节点缓存在线程本地变量中,释放锁会用到
curNodeLocal.set(curNode);
}
//释放锁
@Override
public void unlock()
{
Node curNode = curNodeLocal.get();
curNode.setLocked(false);
curNode.setPrevNode(null); //help for GC
curNodeLocal.set(null); //方便下一次抢锁
}
//虚拟等待队列的节点
@Data
static class Node
{
public Node(boolean locked, Node prevNode)
{
this.locked = locked;
this.prevNode = prevNode;
}
// true:当前线程正在抢占锁,或者已经占有锁
// false:当前线程已经释放锁,下一个线程可以占有锁了
volatile boolean locked;
// 前一个节点,需要监听其locked字段
Node prevNode;
// 空节点
public static final Node EMPTY = new Node(false, null);
}
// 省略其他代码
}
- 2.CLHLock锁的测试用例
下面实现一个CLHLock的测试用例:基于前面抽取出来的公共IncrementData累加类,编写一个10个线程各种累加100 000次的累加程序,并使用CLHLock作为累加的同步锁。测试用例的代码具体如下:
package com.crazymakercircle.demo.lock;
// 省略import
public class LockTest
{
@org.junit.Test
public void testCLHLockCapability()
{
// 速度对比
// ReentrantLock 1 000 000 次 0.154 秒
// CLHLock 1 000 000 次 2.798 秒
// 每个线程的执行轮数
final int TURNS = 100000;
// 线程数
final int THREADS = 10;
//线程池,用于多线程模拟测试
ExecutorService pool = Executors.newFixedThreadPool(THREADS);
Lock lock = new CLHLock();
// Lock lock = new ReentrantLock();
// 倒数闩
CountDownLatch countDownLatch = new CountDownLatch(THREADS);
long start = System.currentTimeMillis();
for (int i = 0; i < THREADS; i++)
{
pool.submit(() ->
{
for (int j = 0; j < TURNS; j++)
{
IncrementData.lockAndFastIncrease(lock);
}
Print.tcfo("本线程累加完成");
//倒数闩减少1次
countDownLatch.countDown();
});
}
try
{
//等待倒数闩归0,所有线程结束
countDownLatch.await();
} catch (InterruptedException e)
{
e.printStackTrace();
}
float time = (System.currentTimeMillis() - start) / 1000F;
//输出统计结果
Print.tcfo("运行的时长为:" + time);
Print.tcfo("累加结果为:" + IncrementData.sum);
}
// 省略其他代码
}
- 通过以上结果可以看出通过CLHLock进行累加同步,10个线程累加100?000次之后结果为1?000?000。实际上,该累加结果是正确的,这也说明以上CLHLock实现版本没有功能问题。
- 但是,由于仅仅是一个学习版本,以上CLHLock实现版本存在严重的性能问题。经过对比,其性能足足比JUC的ReentrantLock锁差20倍左右。尽管如此,以上CLHLock实现版本用于学习CLHLock的原理还是非常有价值的。
- 3.CLH锁的原理分析
简单回顾一下CLH的算法:抢锁线程在队列尾部加入一个节点,然后仅在前驱节点上进行普通自旋,它不断轮询前一个节点状态,如果发现前一个节点释放锁,当前节点抢锁成功。CLH的算法有以下几个要点:
(1)初始状态队列尾部属性(tail)指向一个EMPTY节点。
/**
* CLHLock队列的尾部指针,使用AtomicReference,方便进行CAS操作
*/
private AtomicReference<Node> tail = new AtomicReference<>(null);
public CLHLock()
{
//设置尾部节点
tail.getAndSet(Node.EMPTY);
}
- tail属性使用AtomicReference类型是为了使得多个线程并发操作tail时不会发生线程安全问题。
(2)Thread在抢锁时会创建一个新的Node加入等待队列尾部:tail指向新的Node,同时新的Node的preNode属性指向tail之前指向的节点,并且以上操作通过CAS自旋完成,以确保操作成功。
(3)Thread加入抢锁队列之后,会在前驱节点上自旋:循环判断前驱节点的locked属性是否为false,如果为false就表示前驱节点释放了锁,当前线程抢占到锁。
(4)Thread抢到锁之后,它的locked属性一直为true,一直到临界区代码执行完,然后调用unlock()方法释放锁,释放之后其locked属性才为false。释放锁的代码如下:
释放锁操作为:线程从本地变量curNodeLocal中获取当前节点curNode,将其状态设置为false,以便其后继节点能获得锁。
线程在设置当前节点curNode的locked状态为false前,为了GC能回收前驱节点,需要将curNode前驱节点引用设置为空。另外,为了使得线程下一次抢锁不会出错,需要将线程本地变量curNodeLocal中的节点引用设置为空。
3.公平锁和非公平锁
- 公平锁是指不同的线程抢占锁的机会是公平的、平等的,从抢占时间上来说,先对锁进行抢占的线程一定被先满足,抢锁成功的次序体现为FIFO(先进先出)顺序。简单来说,公平锁就是保障各个线程获取锁都是按照顺序来的,先到的线程先获取锁。
- 使用公平锁,比如线程A、B、C、D依次去获取锁,线程A首先获取到了锁,然后它处理完成释放锁之后,会唤醒下一个线程B去获取锁。后续不断重复前面的过程,线程C、D依次获取锁。
- 非公平锁是指不同的线程抢占锁的机会是非公平的、不平等的,从抢占时间上来说,先对锁进行抢占的线程不一定被先满足,抢锁成功的次序不会体现为FIFO(先进先出)顺序。
- 使用公平锁,比如线程A、B、C、D依次去获取锁,假如此时持有锁的是线程A,然后线程B、C、D尝试获取锁,就会进入一个等待队列。当线程A释放掉锁之后,会唤醒下一个线程B去获取锁。在唤醒线程B的这个过程中,如果有别的线程E尝试去请求锁,那么线程E是可以先获取到的,这就是插队。为什么线程E可以插队呢?因为CPU唤醒线程B需要进行线程的上下文切换,这个操作需要一定的时间,线程E可能与线程A、B不在同一个CPU内核上执行,而是在其他的内核上执行,所以不需要进行线程的上下文切换。在线程A释放锁和线程B被唤醒的这段时间,锁是空闲的,其他内核上的线程E此时就能趁机获取非公平锁,这样做的目的主要是利用锁的空档期,提高其利用效率。
- 默认情况下,ReentrantLock实例是非公平锁,但是,如果在实例构造时传入了参数true,所得到的锁就是公平锁。另外,ReentrantLock的tryLock()方法是一个特例,一旦有线程释放了锁,正在tryLock的线程就能优先取到锁,即使已经有其他线程在等待队列中。
4.可中断锁和不可中断锁
- 什么是可中断锁?如果某一线程A正占有锁在执行临界区代码,另一线程B正在阻塞式抢占锁,可能由于等待时间过长,线程B不想等待了,想先处理其他事情,我们可以让它中断自己的阻塞等待,这种就是可中断锁。
- 什么是不可中断锁?一旦这个锁被其他线程占有,如果自己还想抢占,只能选择等待或者阻塞,直到别的线程释放这个锁,如果别的线程永远不释放锁,那么自己只能永远等下去,并且没有办法终止等待或阻塞。
- 简单来说,在抢锁过程中能通过某些方法终止抢占过程,这就是可中断锁,否则就是不可中断锁。Java的synchronized内置锁就是一个不可中断锁,而JUC的显式锁(如ReentrantLock)是一个可中断锁。
5.共享锁和独占锁
- 独占锁指的是每次只有一个线程能持有的锁。独占锁是一种悲观保守的加锁策略,它不必要地限制了读/读竞争,如果某个只读线程获取锁,那么其他的读线程都只能等待,这种情况下就限制了读操作的并发性,因为读操作并不会影响数据的一致性。
- JUC的ReentrantLock类是一个标准的独占锁实现类。
- 共享锁允许多个线程同时获取锁,容许线程并发进入临界区。与独占锁不同,共享锁是一种乐观锁,它放宽了加锁策略,并不限制读/读竞争,允许多个执行读操作的线程同时访问共享资源。
- JUC的ReentrantReadWriteLock(读写锁)类是一个共享锁实现类。使用该读写锁时,读操作可以有很多线程一起读,但是写操作只能有一个线程去写,而且在写入的时候,别的线程也不能进行读的操作。
- 用ReentrantLock锁替代ReentrantReadWriteLock锁虽然可以保证线程安全,但是也会浪费一部分资源,因为多个读操作并没有线程安全问题,所以在读的地方使用读锁,在写的地方使用写锁,可以提高程序执行效率。