转载自廖雪峰老师的教程:
一 概述
简单地说,SQL就是访问和处理关系数据库的计算机标准语言。
数据据库作为一种专门管理数据的软件。应用程序不需要自己管理数据,而是通过数据库软件提供的接口来读写数据。
常见类型
| 名称 | 类型 | 说明 |
| INT | 整型 | 4字节整数类型,范围约+/-21亿 |
| BIGINT | 长整型 | 8字节整数类型,范围约+/-922亿亿 |
| REAL | 浮点型 | 4字节浮点数,范围约+/-10 38 |
| DOUBLE | 浮点型 | 8字节浮点数,范围约+/-10 308 |
| DECIMAL(M,N) | 高精度小数 | 由用户指定精度的小数,例如,DECIMAL(20,10)表示一共20位,其中小数10位,通常用于财务计算 |
| CHAR(N) | 定长字符串 | 存储指定长度的字符串,例如,CHAR(100)总是存储100个字符的字符串 |
| VARCHAR(N) | 变长字符串 | 存储可变长度的字符串,例如,VARCHAR(100)可以存储0~100个字符的字符串 |
| BOOLEAN | 布尔类型 | 存储True或者False |
| DATE | 日期类型 | 存储日期,例如,2018-06-22 |
| TIME | 时间类型 | 存储时间,例如,12:20:59 |
| DATETIME | 日期和时间类型 | 存储日期+时间,例如,2018-06-22 12:20:59 |
通常来说,BIGINT能满足整数存储的需求,VARCHAR(N)能满足字符串存储的需求,这两种类型是使用最广泛的。
教程约定:SQL关键字总是大写,以示突出,表名和列名均使用小写。
二 安装
mysql两种引擎
- InnoDB:由Innobase Oy公司开发的一款支持事务的数据库引擎,2006年被Oracle收购;
- MyISAM:MySQL早期集成的默认数据库引擎,不支持事务。
分支:
- MariaDB:由MySQL的创始人创建的一个开源分支版本
- Aurora:由Amazon改进的一个MySQL版本
- PolarDB:由Alibaba改进的一个MySQL版本
登录: mysql -u root -p,然后输入口令
三 关系模型
- 表的每一行称为记录(Record),记录是一个逻辑意义上的数据。
- 表的每一列称为字段(Column),同一个表的每一行记录都拥有相同的若干字段。字段定义了数据类型(整型、浮点型、字符串、日期等),以及是否允许为NULL。注意null不是0,也不是空串""。
在关系数据库中,关系是通过主键和外键来维护的。对于关系表,有个很重要的约束,就是任意两条记录不能重复。能够通过某个字段唯一区分出不同的记录,这个字段被称为主键。
对主键的要求,最关键的一点是:记录一旦插入到表中,主键最好不要再修改。选取主键的一个基本原则是:不使用任何业务相关的字段作为主键。
一般把这个字段命名为id。常见的可作为id字段的类型有:
- 自增整数类型:数据库会在插入数据时自动为每一条记录分配一个自增整数,这样我们就完全不用担心主键重复,也不用自己预先生成主键;
- 全局唯一GUID类型:使用一种全局唯一的字符串作为主键,类似8f55d96b-8acc-4636-8cb8-76bf8abc2f57。
可以使用多个列作为联合主键,但联合主键并不常用。
在students表中,通过class_id的字段,可以把数据与另一张表关联起来,这种列称为外键。
由于外键约束会降低数据库的性能,大部分互联网应用程序为了追求速度,并不设置外键约束,而是仅靠应用程序自身来保证逻辑的正确性。
通过中间表,我们就定义了一个“多对多”关系。还有一些应用会把一个大表拆成两个一对一的表,目的是把经常读取和不经常读取的字段分开,以获得更高的性能。
索引的效率取决于索引列的值是否散列。使用主键索引的效率是最高的,因为主键会保证绝对唯一。通过创建唯一索引,可以保证某一列的值具有唯一性。
四 查询数据
使用SELECT * FROM students时,SELECT是关键字,表示将要执行一个查询,*表示“所有列”,FROM表示将要从哪个表查询。SELECT查询的结果是一个二维表。
SELECT语句其实并不要求一定要有FROM子句。许多检测工具会执行一条SELECT 1;来测试数据库连接。
通过WHERE条件查询,可以筛选出符合指定条件的记录,而不是整个表的所有记录。
| 使用<>判断不相等 | score <> 80 | name <> 'abc' | |
| 使用LIKE判断相似 | name LIKE 'ab%' | name LIKE '%bc%' | %表示任意字符,例如'ab%'将匹配'ab','abc','abcd' |
使用SELECT *表示查询表的所有列,使用SELECT 列1, 列2, 列3则可以仅返回指定列,这种操作称为投影。可以对结果集的列进行重命名 SELECT 列1 别名1, 列2 别名2 FROM XXX
使用ORDER BY可以对结果集进行排序;可以对多列进行升序、倒序排序。ASC DESC
使用LIMIT OFFSET 可以对结果集进行分页,每次查询返回结果集的一部分;
OFFSET是可选的,如果只写LIMIT 15,那么相当于LIMIT 15 OFFSET 0。OFFSET超过了查询的最大数量并不会报错,而是得到一个空的结果集。
SQL提供了专门的聚合函数,使用聚合函数进行查询,就是聚合查询。除了COUNT()函数外,SQL还提供了如下聚合函数:
| 函数 | 说明 |
| COUNT | 计算某一列数量 |
| SUM | 计算某一列的合计值,该列必须为数值类型 |
| AVG | 计算某一列的平均值,该列必须为数值类型 |
| MAX | 计算某一列的最大值 |
| MIN | 计算某一列的最小值 |
要特别注意:如果聚合查询的WHERE条件没有匹配到任何行,COUNT()会返回0,而SUM()、AVG()、MAX()和MIN()会返回NULL
GROUP BY可以进行分组
多表查询又称笛卡尔查询,使用笛卡尔查询时要非常小心,结果集是目标表的行数乘积。使用多表查询可以获取M x N行记录;
SQL还允许给表设置一个别名,让我们在投影查询中引用起来稍微简洁一点。
最常用的一种内连接——INNER JOIN。
- 先确定主表,仍然使用FROM 的语法;
- 再确定需要连接的表,使用INNER JOIN 的语法;
- 然后确定连接条件,使用ON ,这里的条件是s.class_id = c.id,表示students表的class_id列与classes表的id列相同的行需要连接;
- 可选:加上WHERE子句、ORDER BY等子句
假设查询语句是:
SELECT ... FROM tableA JOIN tableB ON tableA.column1 = tableB.column2;
我们把tableA看作左表,把tableB看成右表。
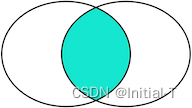
INNER JOIN是选出两张表都存在的记录:
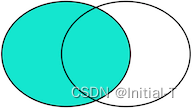
LEFT OUTER JOIN是选出左表存在的记录:
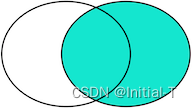
RIGHT OUTER JOIN是选出右表存在的记录:
FULL OUTER JOIN则是选出左右表都存在的记录:

五 增删改
增: INSERT
如:
INSERT INTO students (class_id, name, gender, score) VALUES (2, '大牛', 'M', 80);也可以插入多条,如
INSERT INTO students (class_id, name, gender, score) VALUES (1, '大宝', 'M', 87), (2, '二宝', 'M', 81);改: UPDATE
UPDATE students SET name='大牛', score=66 WHERE id=1;在UPDATE语句中,更新字段时可以使用表达式。
UPDATE students SET score=score+10 WHERE score<80;最后,要特别小心的是,UPDATE语句可以没有WHERE条件,例如:
UPDATE students SET score=60;这时,整个表的所有记录都会被更新。
删: DELETE
DELETE FROM students WHERE id=1;要特别小心的是,和UPDATE类似,不带WHERE条件的DELETE语句会删除整个表的数据:
DELETE FROM students;这时,整个表的所有记录都会被删除。所以,在执行DELETE语句时也要非常小心,最好先用SELECT语句来测试WHERE条件是否筛选出了期望的记录集,然后再用DELETE删除。
六 MYSQL
客户端
MySQL Client和MySQL Server的关系如下:

在MySQL Client中输入的SQL语句通过TCP连接发送到MySQL Server。
登录语句:
mysql -h 10.0.1.99 -u root -p命令行程序
mysql实际上是MySQL客户端,真正的MySQL服务器程序是mysqld,在后台运行
管理MYSQL
库
要列出所有数据库,使用命令SHOW:
mysql> SHOW DATABASES;要创建一个新数据库,使用命令CREATE:
mysql> CREATE DATABASE test;要删除一个数据库,使用命令DROP:
mysql> DROP DATABASE test;对一个数据库进行操作时,要首先将其切换为当前数据库USE:
mysql> USE test;表
列出当前数据库的所有表,使用命令SHOW:
mysql> SHOW TABLES;要查看一个表的结构,使用命令DESC:
mysql> DESC students;还可以使用以下命令查看创建表的SQL语句SHOW CREATE TABLE:
mysql> SHOW CREATE TABLE students;创建表使用CREATE TABLE语句,而删除表使用DROP TABLE语句:
mysql> DROP TABLE students;修改表就比较复杂,使用ALTER TABLE。如果要给students表新增一列birth:
ALTER TABLE students ADD COLUMN birth VARCHAR(10) NOT NULL;要修改birth列,例如把列名改为birthday,类型改为VARCHAR(20):
ALTER TABLE students CHANGE COLUMN birth birthday VARCHAR(20) NOT NULL;要删除列,使用:
ALTER TABLE students DROP COLUMN birthday;退出MySQL
使用EXIT命令退出MySQL:
mysql> EXIT实用语句
使用REPLACE语句,这样就不必先查询,再决定是否先删除再插入:
REPLACE INTO students (id, class_id, name, gender, score) VALUES (1, 1, '小明', 'F', 99);希望插入一条新记录(INSERT),但如果记录已经存在,就更新该记录,此时,可以使用INSERT INTO ... ON DUPLICATE KEY UPDATE ...语句:
INSERT INTO students (id, class_id, name, gender, score) VALUES (1, 1, '小明', 'F', 99) ON DUPLICATE KEY UPDATE name='小明', gender='F', score=99;希望插入一条新记录(INSERT),但如果记录已经存在,就啥事也不干直接忽略,此时,可以使用INSERT IGNORE INTO ...语句:
INSERT IGNORE INTO students (id, class_id, name, gender, score) VALUES (1, 1, '小明', 'F', 99);如果想要对一个表进行快照,即复制一份当前表的数据到一个新表,可以结合CREATE TABLE和SELECT:
-- 对class_id=1的记录进行快照,并存储为新表students_of_class1:
CREATE TABLE students_of_class1 SELECT * FROM students WHERE class_id=1;用一条语句写入各班的平均成绩:
INSERT INTO statistics (class_id, average) SELECT class_id, AVG(score) FROM students GROUP BY class_id;使用FORCE INDEX强制查询使用指定的索引。例如:
> SELECT * FROM students FORCE INDEX (idx_class_id) WHERE class_id = 1 ORDER BY id DESC;前提是索引idx_class_id必须存在。
七 事务
1 概念
这种把多条语句作为一个整体进行操作的功能,被称为数据库事务。
数据库事务具有ACID这4个特性:
- A:Atomic,原子性,将所有SQL作为原子工作单元执行,要么全部执行,要么全部不执行;
- C:Consistent,一致性,事务完成后,所有数据的状态都是一致的,即A账户只要减去了100,B账户则必定加上了100;
- I:Isolation,隔离性,如果有多个事务并发执行,每个事务作出的修改必须与其他事务隔离;
- D:Duration,持久性,即事务完成后,对数据库数据的修改被持久化存储。
单条SQL语句,数据库系统自动将其作为一个事务执行,这种事务被称为隐式事务。
要手动把多条SQL语句作为一个事务执行,使用BEGIN开启一个事务,使用COMMIT提交一个事务,这种事务被称为显式事务
BEGIN; UPDATE accounts SET balance = balance - 100 WHERE id = 1; UPDATE accounts SET balance = balance + 100 WHERE id = 2; COMMIT;使用ROLLBACK进行回滚
BEGIN; UPDATE accounts SET balance = balance - 100 WHERE id = 1; UPDATE accounts SET balance = balance + 100 WHERE id = 2; ROLLBACK;SQL标准定义了4种隔离级别,分别对应可能出现的数据不一致的情况:
| Isolation Level | 脏读(Dirty Read) | 不可重复读(Non Repeatable Read) | 幻读(Phantom Read) |
| Read Uncommitted | Yes | Yes | Yes |
| Read Committed | - | Yes | Yes |
| Repeatable Read | - | - | Yes |
| Serializable | - | - | - |
2 四种隔离
- 在Read Uncommitted隔离级别下,一个事务可能读取到另一个事务更新但未提交的数据,这个数据有可能是脏数据。
- 在Read Committed隔离级别下,一个事务可能会遇到不可重复读(Non Repeatable Read)的问题。不可重复读是指,在一个事务内,多次读同一数据,在这个事务还没有结束时,如果另一个事务恰好修改了这个数据,那么,在第一个事务中,两次读取的数据就可能不一致。
- 在Repeatable Read隔离级别下,一个事务可能会遇到幻读(Phantom Read)的问题。幻读是指,在一个事务中,第一次查询某条记录,发现没有,但是,当试图更新这条不存在的记录时,竟然能成功,并且,再次读取同一条记录,它就神奇地出现了。
- Serializable是最严格的隔离级别。在Serializable隔离级别下,所有事务按照次序依次执行,因此,脏读、不可重复读、幻读都不会出现。虽然Serializable隔离级别下的事务具有最高的安全性,但是,由于事务是串行执行,所以效率会大大下降,应用程序的性能会急剧降低。如果没有特别重要的情景,一般都不会使用Serializable隔离级别。
默认隔离级别
如果没有指定隔离级别,数据库就会使用默认的隔离级别。在MySQL中,如果使用InnoDB,默认的隔离级别是Repeatable Read。