引言
本文主要介绍 pandas 数据追加 df.append(),更多 Python 进阶系列文章,请参考 Python 进阶学习 玩转数据系列
内容提要:
df1.append()
追加 DataFrame
追加 Series
追加 dict 字典
df1.append()
按行追加拼接,将一个 DataFrame 的行拼接到另外一个 DataFrame 的末尾,返回一个新的 DataFrame。如果列名不在第一个 DataFrame出现,则将以新的列名添加,没有对应内容的会为空。不会改变原来的 DataFrame,只会创建一个新的 DataFrame,包含拼接的数据。
重点:因为会创建一个新的 index 和 data buffer,所以效率不高。推荐用 pd.concat(),而且 pd.concat() 功能更强大,详情请参考 Pandas 数据处理 拼接 pd.concat()
df.append(other: DataFrame | Series[Dtype@append] | Dict[_str, Any], ignore_index: _bool = …, verify_integrity: _bool = …, sort: _bool = …)
| 参数 | 说明 |
|---|---|
| other | 是它要追加的其他 DataFrame 或者类似序列内容 |
| ignore_index | 如果为 True 则重新进行自然索引 |
| verify_integrity | 如果为 True 则遇到重复索引内容时报错 |
| sort | 进行排序 |
追加 DataFrame
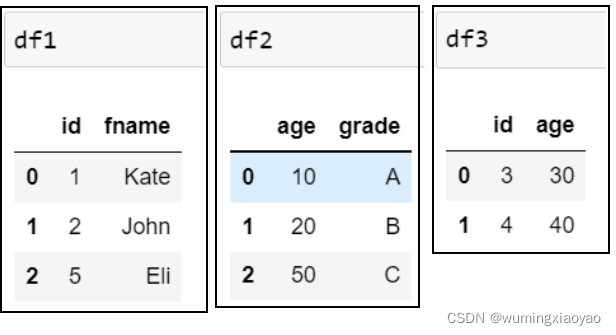
两个 df 拼接,并保留原索引:
多个 df 拼接,在合并不保留原索引,启用新的自然索引
代码:

import pandas as pd
idnumber = [1,2,5]
fname = ['Kate','John','Eli']
age = [10,20,50]
grade = ['A','B','C']
df1 = pd.DataFrame({'id':idnumber,'fname':fname})
df2 = pd.DataFrame({'age':age,'grade':grade})
df3 = pd.DataFrame({'id':[3,4],'age':[30,40]})
print("df1:\n{}".format(df1))
print("df2:\n{}".format(df2))
print("df3:\n{}".format(df3))
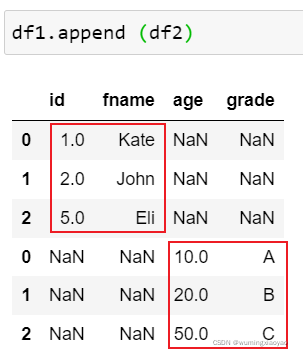
df1_append_df2 = df1.append(df2)
print("df1_append_df2:\n{}".format(df1_append_df2))
df1_append_df2_df3 = df1.append([df2,df3], ignore_index = True)
print("df1_append_df2_df3:\n{}".format(df1_append_df2_df3))
输出:
df1:
id fname
0 1 Kate
1 2 John
2 5 Eli
df2:
age grade
0 10 A
1 20 B
2 50 C
df3:
id age
0 3 30
1 4 40
df1_append_df2:
id fname age grade
0 1.0 Kate NaN NaN
1 2.0 John NaN NaN
2 5.0 Eli NaN NaN
0 NaN NaN 10.0 A
1 NaN NaN 20.0 B
2 NaN NaN 50.0 C
df1_append_df2_df3:
id fname age grade
0 1.0 Kate NaN NaN
1 2.0 John NaN NaN
2 5.0 Eli NaN NaN
3 NaN NaN 10.0 A
4 NaN NaN 20.0 B
5 NaN NaN 50.0 C
6 3.0 NaN 30.0 NaN
7 4.0 NaN 40.0 NaN
追加 Series
拼接 Series 一定要加上参数 ignore_index=True
Series 的 index 会分别对应列名
代码:
import pandas as pd
idnumber = [1,2,5]
fname = ['Kate','John','Eli']
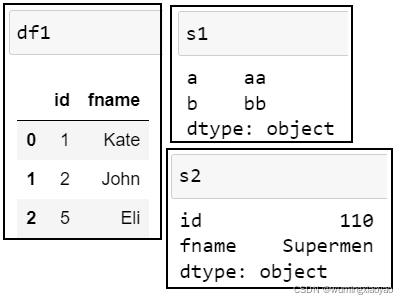
df1 = pd.DataFrame({'id':idnumber,'fname':fname})
s1 = pd.Series(["aa", "bb"], index=["a", "b"])
s2 = pd.Series(["110", "Supermen"], index=["id", "fname"])
print("df1:\n{}".format(df1))
print("s1:\n{}".format(s1))
print("s2:\n{}".format(s2))
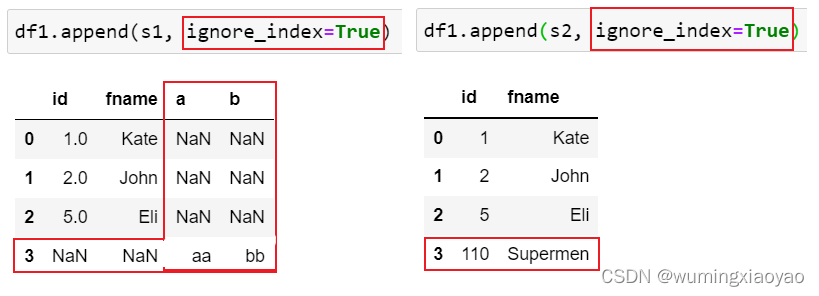
df1_appened_s1 = df1.append(s1, ignore_index=True)
df1_appened_s2 = df1.append(s2, ignore_index=True)
print("df1_appened_s1:\n{}".format(df1_appened_s1))
print("df1_appened_s2:\n{}".format(df1_appened_s2))
输出:
df1:
id fname
0 1 Kate
1 2 John
2 5 Eli
s1:
a aa
b bb
dtype: object
s2:
id 110
fname Supermen
dtype: object
df1_appened_s1:
id fname a b
0 1.0 Kate NaN NaN
1 2.0 John NaN NaN
2 5.0 Eli NaN NaN
3 NaN NaN aa bb
df1_appened_s2:
id fname
0 1 Kate
1 2 John
2 5 Eli
3 110 Supermen
追加 dict 字典
代码:

import pandas as pd
idnumber = [1,2,5]
fname = ['Kate','John','Eli']
df1 = pd.DataFrame({'id':idnumber,'fname':fname})
dicts_1 =[{"a":"aa", "b":"bb"},{"a":"aaa", "b":"bbb"}]
dicts_2 =[{"id":"110", "fname":"Supermen"},{"id":"111", "fname":"Superwoman"}]
print("df1:\n{}".format(df1))
print("dicts_1:\n{}".format(dicts_1))
print("dicts_1:\n{}".format(dicts_1))
df1_appened_dicts_1 = df1.append(dicts_1)
df1_appened_dicts_2 = df1.append(dicts_2, ignore_index=True)
print("df1_appened_dicts_1:\n{}".format(df1_appened_dicts_1))
print("df1_appened_dicts_2:\n{}".format(df1_appened_dicts_2))
输出:
df1:
id fname
0 1 Kate
1 2 John
2 5 Eli
dicts_1:
[{'a': 'aa', 'b': 'bb'}, {'a': 'aaa', 'b': 'bbb'}]
dicts_1:
[{'a': 'aa', 'b': 'bb'}, {'a': 'aaa', 'b': 'bbb'}]
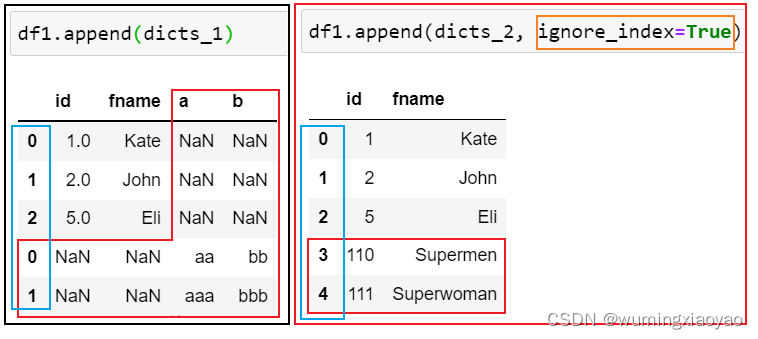
df1_appened_dicts_1:
id fname a b
0 1.0 Kate NaN NaN
1 2.0 John NaN NaN
2 5.0 Eli NaN NaN
0 NaN NaN aa bb
1 NaN NaN aaa bbb
df1_appened_dicts_2:
id fname
0 1 Kate
1 2 John
2 5 Eli
3 110 Supermen
4 111 Superwoman