随着信息技术和互联网技术的快速发展,利用数据采集技术实现用户感兴趣的数据收集分析成为很多互联网公司研究讨论的热门话题。通过对基于京东商品的数据采集进行商品价格动态变化的需求进行调查分析,发现作为研究商品价格波动变化的重要补充,京东商品信息分析系统对当前电商的商品信息政策决定起着极强的辅助作用。本文通过实现京东商品信息分析系统,来更好的帮助互联网公司提升政策指导性,增加对商品价格的波动研究。
本系统采用Python开发技术,结合广泛使用的MYSQL作为后台存储数据库。利用面向对象的思想,采用业界流行的MVC体系结构即模型-视图-控制器,减少各层之间的耦合,并对未来团队合作开发大型商业应用程序进行实践锻炼。系统主要实现了数据采集模块和数据分析模块。本文通过需求分析、可行性分析、系统总体设计、详细设计和系统开发及测试完成了整个京东商品信息分析系统。本网站有效的提升了对京东商品价格波动数据分析力度,拉近了商品价格信息历史数据查询手段,更好地提升商品信息的准确度和活跃度。
关键词:信息技术;互联网技术;京东商品信息分析;python
研究背景
京东商品信息分析系统是当前网站商品信息管理方式的有效补充。现如今很多网站商品信息管理人员还在使用手工登记等方式进行商品数据管理,这种管理方式在数据量小的情况下,管理还是比较方便的。但是一旦形成数据规模后,这种原始的推荐方式进行数据的监控管理就会变得异常困难。当前大数据技术飞速发展,处于手工推荐的方式已经被慢慢的淘汰,利用数据动态的智能采集信息在走向潮流。
二十一世纪的今天,信息技术发展的广度和深度异常迅速。在原有技术出现与当前管理需要不匹配的情况时,新的技术会很快诞生并快速运用到当前的管理工作中。当前网站商品信息更新速度比之原来提升很多,要对商品信息进行全面的准确推送,手工方式已经不足以满足网站需求,为解决商品信息监控这一热点难点问题,本文以京东商城商品信息采集为例,开发设计京东商品信息分析西逃。本着为提升商品监控水平为出发点,通过调研实际情况,采用Python开发技术,采用MVC框架技术与MYSQL数据库,开发设计商品分析系统。京东商品分析系统不仅可以提升网站对商品价格信息动态监控,而且也对学生理论与实践相结合,综合运用所学专业知识提高分析问题解决问题的能力。
研究现状
当前流行的系统设计模块有CS(客户端服务器)和BS(浏览器服务器)结构,本文依据京东商品信息分析的特点,采用CS结构,通过专门设计的客户端软件增加对数据的动态采集分析,来提升使用商品信息的动态监控。市场上有很多的数据采集分析软件,但好多都与实际数据采集内容重点内容脱节,使用非常不方便,本文针对这一缺点,并结合组织特点,实现一套基于python技术的京东商品信息分析系统。本文的数据采集使用模拟用户操作网页的web应用功能测试工具Selenium。该工具可以对反爬虫机制自动绕行,但因为模拟用户操作,存在电脑资源占用较高,数据采集效率较低的缺点。
当前信息化发展的速度非常快,和国外的数据采集技术相比。国内的数据采集工具还处于一个初级阶段。不少工具还要根据复杂的数据配置才可以进行数据采集。这种配置方式使得的一般用户无法进行快速的上手使用,进而无法对数据进一步采集分析和统计。譬如采集软件配置的各种英文名称信息总是让使用者无法明确输入内容,无法进行让用户实时通过匹配规则进行采集;用户使用无法随时利用对自己掌握的采集数据进行历史数据分析,进而导致采集数据管理指导缺少明确的目标指导。
国外因为信息化程度较高,市场发展比较成熟,对于采集系统的研究处于领先的地位。同时因为python平台在外国使用比较早,各种应用比较多,采用的技术比较先进和成熟。但是要完全照搬系统使用,会带来诸多的不适应。一方面是人们的文化制度、生活习惯的差异性,同时也由于管理方式的不同,造成国内相关数据采集分析系统必须要走自己特色的路子。通过对京东商品数据分析的充分调研,以准确抓取商品价格信息和类型信息为目标,设计和研究适应京东商品信息动态分析和监控的系统。
研究内容
针对京东商品信息的动态监控管理这一商品信息监控提升决策指导的关键管理部分进行详细分析,通过对京东商品信息的数据采集分析系统作用户需求分析,并从技术、经济和操作的可行性角度进行分析、然后完成系统总体设计和详细设计,并最终完成编写代码,生产出可以实际使用的系统,并对所成系统测试和维护。本系统后台数据保存采用MYSQL数据库,服务器端编程python技术,系统框架采用MVC。系统设计以用户操作简单快捷,界面美观大方为原则,以提高京东商品信息的数据采集分析管理为目的,综合提升网站商品信息精准化管理水平。
本系统采用快速模型开发的思想,先根据京东商品信息分析系统的原型需求,尽快搭建设计完成系统的核心要求,然后再结合其他辅助要求模块,进行不断叠加设计,最终生产出可以实际使用的系统,并对所成系统测试和维护。
论文结构
本文共分七章。
本次论文共分为五章,组织结构如下:
第一章绪论:讲述平台的研究概况,讨论当前的数据采集分析系统优缺点和研究方向,明确数据采集分析图系统准备采用的技术栈和实现该平台索要完成的工作。
第二章系统分析和开发技术:对课题进行可行性分析及功能需求分析与性能需求分析,明确用户的功能目标,最后概述使用的相关技术。
第三章系统设计:对系统整体进行功能分析和架构设计,并完成各项流程设计。
第四章系统实现:对各个功能实现进行描述讨论。
第五章是系统测试:系统编译完毕之后需要对系统的各个功能进行测试,并得出测试用例。
网络爬虫
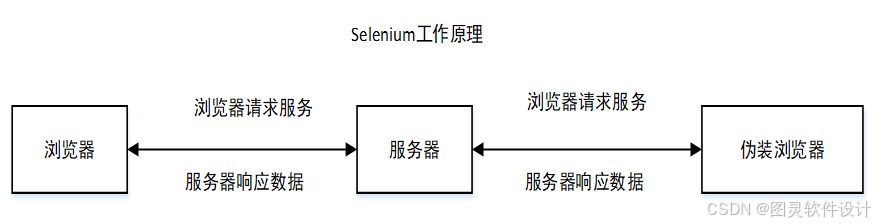
网络爬虫是对网站数据进行采集处理的规范化技术。它采取不同的算法,设置不同的规则,定时的抓取各种网站的信息。Selenium框架是比较流行的网站测试框架,该框架经常使用模拟手工操作自动化技术中。它支持当前流行的各种浏览器,也支持各种流行的编程语言如python、Java和c++等。在当下大数据分析技术中经常利用该框架结合python和火狐浏览器组合进行各种网站数据采集统计。浏览器负责处理js脚本、Selenium框架粘合python与浏览器对象,实现各种手工操作模拟化动作。
网络爬出分为通用型爬虫、增量型爬虫和主题型爬虫。通用型爬虫一般是扫描网页上所有的链接,然后按照深度优先策略或者广度优先策略不断钻取所有链接网页上的相关数据。该技术常用来网站整站爬取。不合适本系统抓取商品信息的特定场景。增量型爬虫针对不同网站的更新策略进行网站数据定时采集,一般采取单体更新方案、统一更新方案和分类更新方案。该技术适用于公告等场景采集。主题网络爬虫是针对特定的网页分析其中的主要数据对象,过滤掉那些不符合预期分析数据的链接信息。该爬虫技术非常适合本系统的商品信息采集。
功能需求
京东商品信息分析系统是针对互联网关注商品信息波动监控进行设计研发的,核心内容管理主要以自动采集监控商品信息为核心,重点解决关注商品信息的动态采集分析,为了尽可能使得系统通用处理,采用数据库中保存数据关键字信息、入库商品关键数据等信息,减少手工管理,为动态监管商品数据提供直观明了规范的商品变化情况信息,减少采用文件数据处理的杂乱和差错,快速准确地掌握商品变化情况。
京东商品信息分析系统主要面向普通用户,通过调查分析,系统主要的功能需求如下:
抓取网页:用于获取京东网页上的商品数据以及在爬取过程中模拟进行翻页、滑滚轮、键盘输入等操作;根据搜索的商品名获得该类商品全部的详细信息和价格。
数据存储:将爬取后的的商品详细信息保存到生成的文本文档和数据库。
数据整理:将获取的商品数据根据用户选择按照价格进行基本的排序便于进行可视化分析。
可视化分析:将得到的商品信息进行处理生成可视化图表。
系统功能设计
如图为系统整体功能设计图
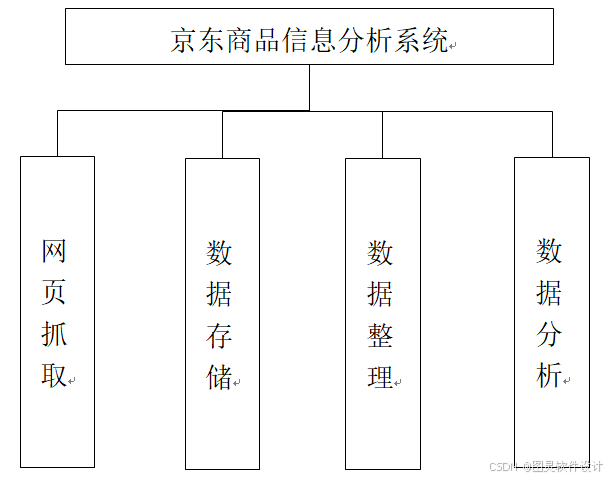
整个系统分为网页抓取模块、数据存储模块、数据整理模块和数据分析模块。网页抓取模块:实现对网页数据的抓取采集;数据存储模块:实现对采集的数据进行及时入库;数据整理模块:实现对入库的数据进行格式化规范整理,为数据分析做好基础工作;数据分析模块:主要用来进行对规范化处理后的数据进行可视化展示。
网页抓取设计
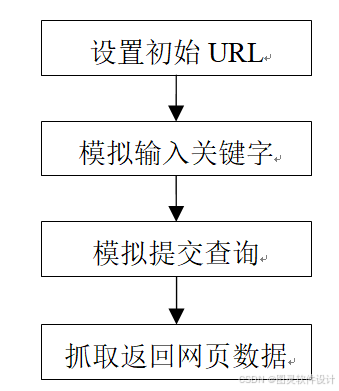
如图为网页抓取功能流程图。
首先设置要抓取网页的起始网址。然后在该网页上模拟手工输入关键字,接着继续模拟手工提交查询,针对返回的网页数据,进行特定格式的数据分析抓取,而不是把所有数据都进行入库。
爬虫算法设计
本系统因抓取的是特定主题的商品信息数据,完全符合主题型爬虫。根据主题型爬虫技术,进行如下技术分析:通过深入研究相关网页结构,利用selenium自动化对网页进行分析,并获得网页上相关的数据。利用相关技术,获得返回数据,并将获取到的数据进行可视化分析。通过利用selenium自动化对网页操作进行模拟,获得网页上所需的数据。从京东首页通过预设的定制的网页页面数据分析算法,利用对应的策略筛掉和预定的主题没有关联的网页链接,仅仅把和预定主题有关的网页链接信息存入系统的尚未进行爬取的待爬队列中,通过selenium模拟用户操作在搜索框内输入所需要商品的名称并点击搜索按钮,进入对应商品的搜索结果页面并根据对应的xpath获取该类商品的各种信息并保存。然后再依据开始前已预设指定的爬取下载对应网页的算法依次爬取存放于待爬取队列中的各页面URL地址。
聚焦网络爬虫的设计初衷就是为了满足不同用户在特定领域获取其想要的特定信息。由于只需爬取相关主题信息,对硬件等处理资源与网路资源的节省的效果是显而易见。但在做主题爬虫之前要做的一件事的就是对待爬取网页链接URL地址以及网页内容通过特定算法进行分析。
聚焦爬虫即主题爬虫算法一般情况下存在如下决策机制:
(1)根据链接本身的分析:通常会使用如下两种计算方法,PageRank算法,其通过算法得到对应网页页面的PageRank值,之后再依据对应结果的大小顺序爬取。另一类方法是HITS算法,使用算法直接计算出之前已经爬取的网页的Authority和Hub值,并依据计算出来的值的大小来对其在爬取队列进行排序,最后根据顺序爬取。
(2)基于网页内容分析:鱼群搜索(Fish Search)算法,其原理是将部分网页的关键词作为主题去搜索,整合主题搜索策略与关键词策略,爬虫认为只要含有指定关键词的网页就是与需要找的主题相关的网页,然后将其抓取下来,但其存在一个明显的缺点就是不能计算出页面与关键词明确的关联度,会对之后抓取的结果造成影响。于是之后Herseovic在鱼群算法的基础上充分发挥该算法的优点针对其存在的缺点提出改进意见,增加通过使用空间向量来获得该网页与指定主题的关联度作为一个变量形成一个新算法。
(3)基于语境图:Diligenti等学者提出通过建立语境图(Context Graphs)的方法来培训机器使其能够在运行过程中自发获取记录相关网页的主题关联度,通过对比已获取的网页与当前网页之间的距离,距离大小的表示其与主题的关联度大小。在实例方面,IBM和印度理工大学合作开发了一款基于主题的典型主题爬虫,其通过使用一组相同主题的既定网页作为定义,然后使用分类器进行计算网页的主题关联度,其创造性的摒弃传统的关键词或是加权矢量来定义。
数据分析实现
引入matplotlib包,以及pymysql包。通过使用Matplotlib将保存下来的数据进行处理,生成包含相关信息收的图表
后台数据处理代码:
@app.route('/tb',methods=['post'])
deftb():
dqj=10
lsj=12
x=[]
y=[]
fori in range(0,20):
x.append(str(random.uniform(10, 20)))
y.append(random.uniform(10, 20))
data={"dqj":dqj,"lsj":lsj,'x':x,'y':y}
returnjsonify(data)
if __name__ == '__main__':
app.run()前台数据展示核心代码
varjgzhe={
backgroundColor:'#ffffff'
,
tooltip:{},
xAxis:{
data:data1.x
},
yAxis:{
type:'value'
},
series: [{
name:'金额',
type:'line',
data:data1.y
}]
};
jgzs.setOption(jgzhe,true)

《基于Python的京东商品信息分析与实现》该项目采用技术Python、mysql数据库
软件开发环境及开发工具:
开发语言:python
前端技术:JavaScript、VUE.js(2.X)、css3
开发工具:pycharm、Visual Studio Code、HbuildX
数据库:MySQL 5.7.26(版本号)
数据库管理工具:phpstudy/Navicat或者phpstudy/sqlyog