HBase基础
基本概念
1.HBase和mysql一样,是一种数据库,hive不能做数据修改,适合做数据仓库,mysql适合做联机操作。HBase是一种mosql数据库。
2.HBase特性:
1)数据的最终持久化存储是基于HDFS,这样就可以随时在线扩容。
2)HBase的数据增删改查功能模块是分布式系统
3.HBase表结构
表名,行键,列族
列族是多个key-value的集合,每个key-value称为一个cell,同一个key可以对应多个value,用版本号区分。
hbase表的逻辑结构图

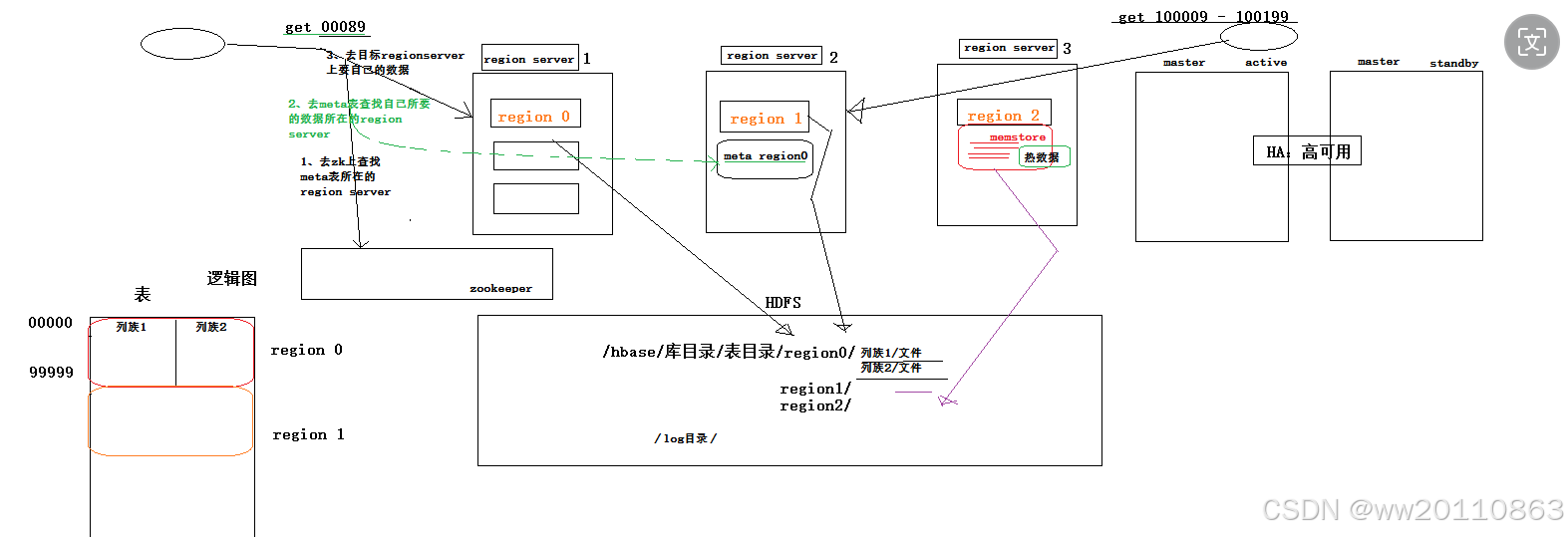
HBase工作机制
1.hbash服务器角色分为master和region server,master负责监控region server是否正常工作,如果掉线了进行数据转移。
region server负责去hdfs中查询数据,返回给客户端。
每张表都分为好几个region,每个hbase服务器管理不同的region。
2.在hbase中,有默认的metaregion,里面存储了表region和对应region server的关系,至于metaregion存储在哪个服务器上,在zk上存储着,客户端首先去访问zk上metaregion的存储服务器,然后去这个服务器上查找表region和对应region server的关系,最后去实际存储的server上获取表数据。
3.建表语句
create ‘t_user_info’,‘base_info’,‘extra_info’
表名 列族名 列族名
在hdfs上存储的目录结构:hbase/region0/base_info
hbase/region0/extra_info
4.插入数据
put ‘t_user_info’,‘001’,‘base_info:username’,‘zhangsan’
5.查询数据
get ‘t_user_info’,‘001’
查询到的数据会通过key进行字典排序
scan 't_user_info’会将整个表的数据全部扫描出来。
结果会根据主键-》列族-》key进行字典排序
hbash中只支持byte[]
6.删除数据
单个单元格删除
delete ‘t_user_info’,‘001’,‘base_info:sex’
整条数据删除
deleteall ‘t_user_info’,‘001’
整个表删除
首先停用表disable ‘t_user_info’
然后删除表 drop ‘t_user_info’
7.region server中的热数据会存储在内存中,会在合适时机或者在服务停止的时候写到hdfs文件中。也会有日志进行持久化。
8.hbase的java客户端在使用的时候会用到布隆过滤器,原理:每次hbase在保存数据到hdfs上时,由于不能更改文件内容,所以都会在hdfs上产生不同的文件,当查询某个key值时,由于存在多个文件,不知道哪个文件中包含要查询的这个key,就可以将每个文件带一个布隆过滤器,将该文件中所有的key值都存到布隆过滤器中,查询的时候看看布隆过滤器是不是符合即可。
9.Hbase重要特性–排序特性(行键)
插入到hbase中去的数据,hbase会自动排序存储:
排序规则: 首先看行键,然后看列族名,然后看列(key)名; 按字典顺序
Hbase的这个特性跟查询效率有极大的关系
比如:一张用来存储用户信息的表,有名字,户籍,年龄,职业…等信息
然后,在业务系统中经常需要:
查询某个省的所有用户
经常需要查询某个省的指定姓的所有用户
思路:如果能将相同省的用户在hbase的存储文件中连续存储,并且能将相同省中相同姓的用户连续存储,那么,上述两个查询需求的效率就会提高!!!
做法:将查询条件拼到rowkey内