1 相关知识介绍
目前对于中文语句的分析来讲,其分词技术多采用Jieba分词技术,该技术是基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG);采用了动态规划(DP)查找最大概率路径,找出基于词频的最大切分组合;对于像各类专有分词、缩写词与新增词等未登录词没有收录在分词词表中,但是必须要切分出来,是采用基于汉字成词能力的HMM模型,使用了维特比(Viterbi)算法实现。
长短期记忆网络(LSTM)是循环神经网络中的一种特殊情况,是一种基于序列式的网络结构。LSTM模型的提出是为了解决循环神经网络中的梯度爆炸和梯度消失的问题。目前的研究中,也有多数学者采用该网络模型用于解决自然语言处理问题,其效果比较理想。LSTM模型的结构图如图1所示,其结构中包含记忆单元Ct、遗忘门模块ft、输入门模块it、输出门模块ot与输出状态ht,该模型的实现过程中的计算公式如下式所示,整体实现了一种时间循环神经网络,解决RNN存在的长期依赖问题而设计的。式(1)表示遗忘门,确定哪些东西需要丢弃或保留;式(2)、(3)、(4)表示输入门,确定更新单元状态;式(5)、(6)表示输出门,表示当前的状态。在对比实验验证时利用该模型与CANN模型进行对比。
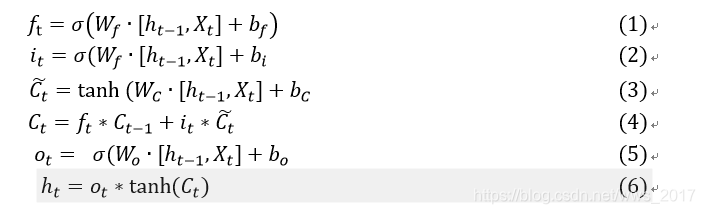
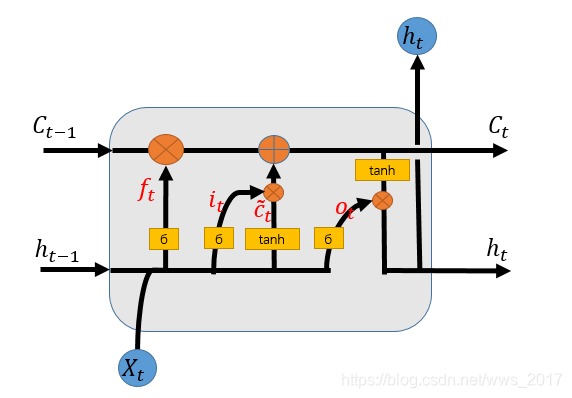
图1 LSTM模型结构图
2 数据集预处理
在本次实例的过程中,采取的数据集为50000条已经标注好的新闻文本信息,其中新闻的种类分别为:体育、娱乐、家居、房产、教育、时尚、时政、游戏、科技和财经,保存在cnew.txt文件中。
把文件读取出来,把文本信息和标签信息分别存储在sentences和labelbanes中,由于标签信息为中文,在模型训练的过程中,不能传入非结构化的数据,所以进行向量化,定义label2id将标签和序号相对应,并且把labelnames中的文字信息转化为数字存储在labels。具体的操作如图2所示。
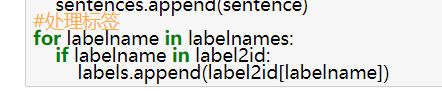
图2 标签的处理
数据文本信息的预处理:
- 定义函数实现删除文本信息中除字母、数字和汉字以外的所有符号,具体的实现步骤如下图3所示。

图3 文本信息处理
- 加载停用词表,我们知道,在实际处理文本信息的时候,有好多的词的重要程度较低,所以会做删除处理。中文停用词表是在网上下载所得,其中的内容存储在chinesStopWords.txt中。
- 将处理后的clear_sentences新闻文本信息通过jieba分词实现对文本信息的分词处理,保存在jb_sentences中,其实现过程如图4所示。

图4 jieba分词过程
我们知道jieba分词后的文本信息还是汉字,是非结构化数据,所以还需要经过词向量转化过程,变成模型可以识别的结构化数据。我们根据汉字的文本信息生成词典,把分词后的数据经过词典转化为矩阵形式,但是我们知道文本信息的长短不一,所以要进行维度的统一化,这里是使用的250个字作为一行信息,多的删除,不足的补零处理,具体的实现过程如图5所示。
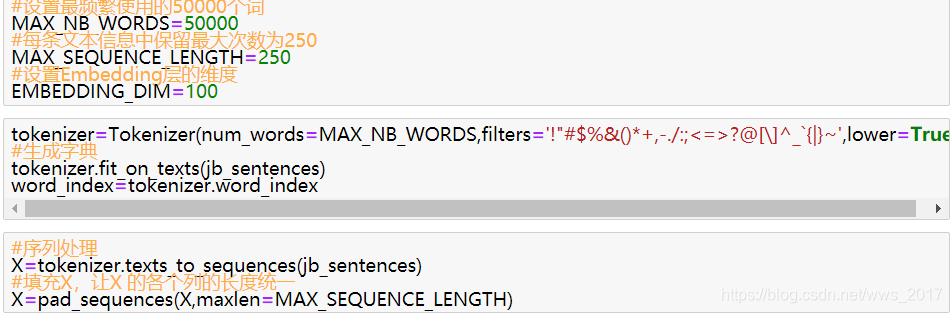
图5 词向量转化过程
同时我们根据词向量转化后的文本信息和处理后的标签信息将数据集分为测试集和训练集,按照标签信息中的比例进行等比分割,其实现过程如图6所示。

图6 拆分数据集
3 模型构建
在本次实例处理新闻文本信息的过程中,采用LSTM网络构建模型,根据大量文献了解到,对于文本分类的问题来讲,LSTM的实现效果较佳。模型包括一层Embedding、一层LSTM和一层全连接层。其中全连接层中采用的激活函数为sigmax函数,优化器采用Adam,其具体过程如图7所示。

图7 LSTM模型构建
4 模型的预测和测试
现在我们已经构建了结构化的数据集和模型,所以只需要把数据送入模型训练就可以了,这里我采用的迭代次数为5次,由于时间较长我实际过程采用了3次迭代,小样本量bacthsize为64,其中训练集中百分之10作为了验证集,进一步实现参数的选取。
将测试集数据送入模型,同时返回其相关指标进行评估模型。
模型的评估:
在使用训练集训练的过程中,其在验证集和训练集上的损失函数和准确率的变化曲线如图8所示。
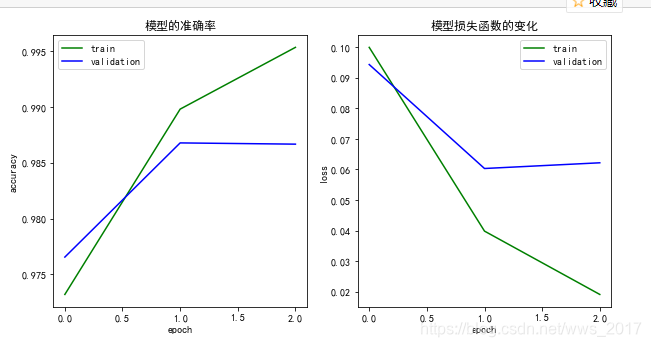
图8 训练过程中准确率和损失函数的变化
测试集送入模型后,得到预测的标签,将预测的标签和实际标签进行比较,可以得到其精确率。召回率、F1测度、准确率、宏平均和权重评价。
其中对于多分类任务中采用使用其宏平均作为评价模型的指标,宏平均为各个种类的平均值,该模型在测试集上的相关指标如图9所示。
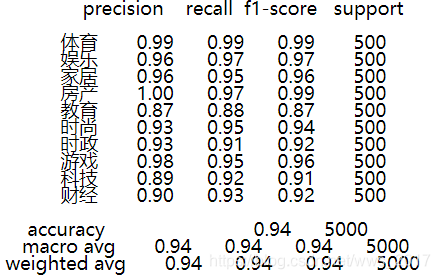
图9 在测试集上的相关指标
从各个指标上可以看出该模型已经达到了很好的收敛效果。
根据预测标签值和实际标签值构建其混淆矩阵如图10所示。

图10 模型在测试集上的混淆矩阵
根据混淆矩阵的效果所示,更进一步的说明该模型的表现效果较好,模型的混淆矩阵中的对角线表示标签预测正确的数量。其中可以看到在某一类的预测中,只有几个的预测结果是错误的。