大数据开发之机器学习总结(Spark Mllib)(四)
背景
- 在大数据和机器学习交叉的领域,如果公司选择了hadoop生态,结合spark框架,则spark 的mllib用于机器学习实际应用就是不二选择了。
- 团队有spark基础,学习和适用门槛低。但如果选择python生态,则需要团队有python基础,另外个人认为,python工程化对比java生态还是差了那么一些意思。
1. Spark MLLib简介
- spark的mllib目前支持4种常见机器学习问题,分类,回归,聚类,协同过滤。
- mllib本身还是基于RDD算子实现,所以天生就可以和spark sql,spark streaming无缝结成,也就是spark的四个模块spark sql,spark streaming, spark mllib, graphX可以直接解决大数据数据计算的90%以上场景,覆盖结构化数据处理,流式数据处理,机器学习,图计算。
- mllib的架构图
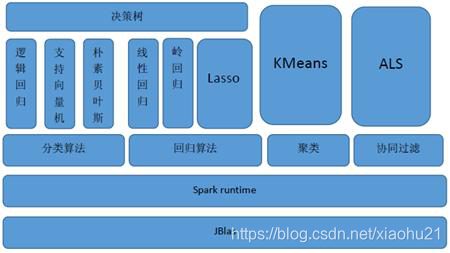
3个组成部分
底层基础:包括Spark的运行库、矩阵库和向量库;
算法库:包含广义线性模型、推荐系统、聚类、决策树和评估的算法;
实用程序:包括测试数据的生成、外部数据的读入等功能。
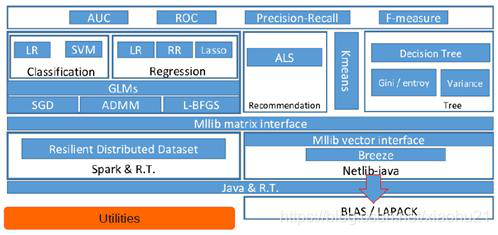
- mllib底层基础
- 基础部分主要包括向量接口Vector和矩阵接口Matrix,这两种接口都会使用Scala语言基于Netlib和BLAS/LAPACK开发的线性代数库Breeze。
这里结合另外一篇数学基础博客,可以直到如果要处理分类,聚类,协同过滤,很多时候就是将事物特征向量提取出来,然后适用算法对向量做相似度或者空间距离计算
而矩阵可以看成是向量集合,更方便向量的计算,因为是一批向量组合为一个矩阵。
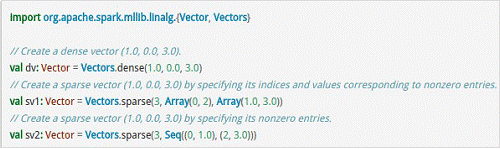
- MLlib支持本地的密集向量和稀疏向量,并且支持标量向量。
注意,在海量数据处理时,如果适用类似数组等集合表示向量,但如果一个10000长度的数组中大部分数据都是相同的如0,少量是1,则没必要真的创建10000长度数组,直接以坐标数组和对应坐标值数组表示会更加节省空间。
如Array(1,8,9,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,18,0,0,0,0,10,0,0,0,0,0,0,0,0,0,11,0,0,0,0,0,89,0,0,0,0,0);这时候就可以采取比这种更加节省内存方式,如tuple: ( 1000, Array[0,1,2,54,63,86,90], Array[1,8,9,18,10,11,89] ),就可以表示一个1000长度数组,index对应是Array[0,1,2,54,63,86,90],对应值是Array[1,8,9,18,10,11,89] 。其他地方都是0,这种叫做稀疏性向量
类似[1,8,9,76,1,23,78,66,12,35,0,0,0,65,87,8,276,28,8,88,98],这种称之为密集型向量
spark中,稀疏和密集型向量对象就是:DenseVector 和SparseVector
示例
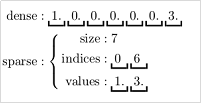
稀疏和密集向量在计算和存储时数据对比
疏矩阵在含有大量非零元素的向量Vector计算中会节省大量的空间并大幅度提高计算速度,如下图所示。

标量LabledPoint在实际中也被大量使用,例如判断邮件是否为垃圾邮件时就可以使用类似于以下的代码:
可以把表示为1.0的判断为正常邮件,而表示为0.0则作为垃圾邮件来看待。
对于矩阵Matrix而言,本地模式的矩阵如下所示。

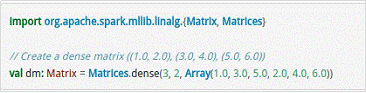
- MLlib同时支持本地矩阵和分布式矩阵,支持的分布式矩阵分为RowMatrix、IndexedRowMatrix、CoordinateMatrix等。
在大数据处理时,分布式矩阵的引入更有意义,当然也支持本地矩阵。
分布式计算最主要就是数据切分和任务切分,这样可以充分利用各个节点的并行计算能力。其他考虑点则是优化数据切分策略,数据传输策略,中间计算结果保存,计算结果保存,任务切分,任务调度等等因素。
- 矩阵编程接口
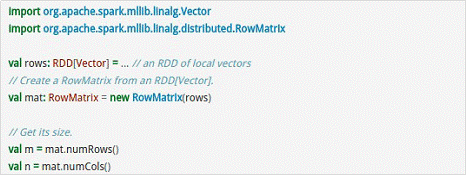
- RowMatrix直接通过RDD[Vector]来定义并可以用来统计平均数、方差、协同方差等:
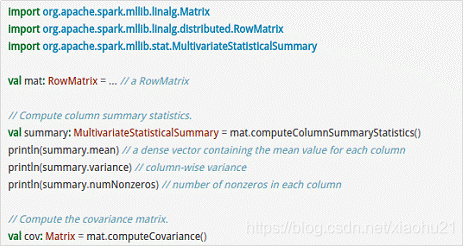
平均数,如何计算就不赘述
均值描述的是样本集合的中间点,它告诉我们的信息是很有限的
标准差
标准差给我们描述的则是样本集合的各个样本点到均值的距离之平均
方差
方差则仅仅是标准差的平方

协方差


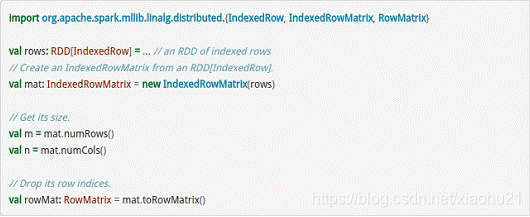
- IndexedRowMatrix是带有索引的Matrix,但其可以通过toRowMatrix方法来转换为RowMatrix,从而利用其统计功能,代码示例如下所示。
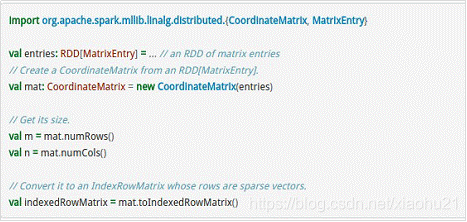
- CoordinateMatrix常用于稀疏性比较高的矩阵,是由RDD[MatrixEntry]来构建的,MatrixEntry是一个Tuple类型的元素,其中包含行、列和元素值,代码示例如下所示:
- 特征向量处理(规范化)
把原始数据中的值直接转入向量,各特征的值量纲可能差距很大,对算法的效果产生巨大负面效应(某些特征可能会掩盖掉其他特征的作用)所以需要对向量进行缩放(规范化、归一化),mllib中有四种工具
- 范数规范器:Normalizer
针对一行来操作!
.setP(2) 2阶P范数

import org.apache.spark.ml.feature.Normalizer
// 正则化每个向量到1阶范数
val normalizer = new Normalizer()
.setInputCol("features")
.setOutputCol("normFeatures")
.setP(1.0)
val l1NormData = normalizer.transform(dataFrame)
println("Normalized using L^1 norm")
l1NormData.show()
// 将每一行的规整为1阶范数为1的向量,1阶范数即所有值绝对值之和。
+-----+---------------------+-----------------------------------+
| id | features | normFeatures |
+-----+----------------------+----------------------------------+
| 0| [1.0,0.5,-1.0] | [0.4,0.2,-0.4] |
| 1| [2.0,1.0,1.0