如何处理跨库查询,以保证数据一致性?
处理跨库查询以保证数据一致性是一个复杂的问题,通常涉及到分布式数据库系统和事务管理。以下是一些关键步骤和策略:
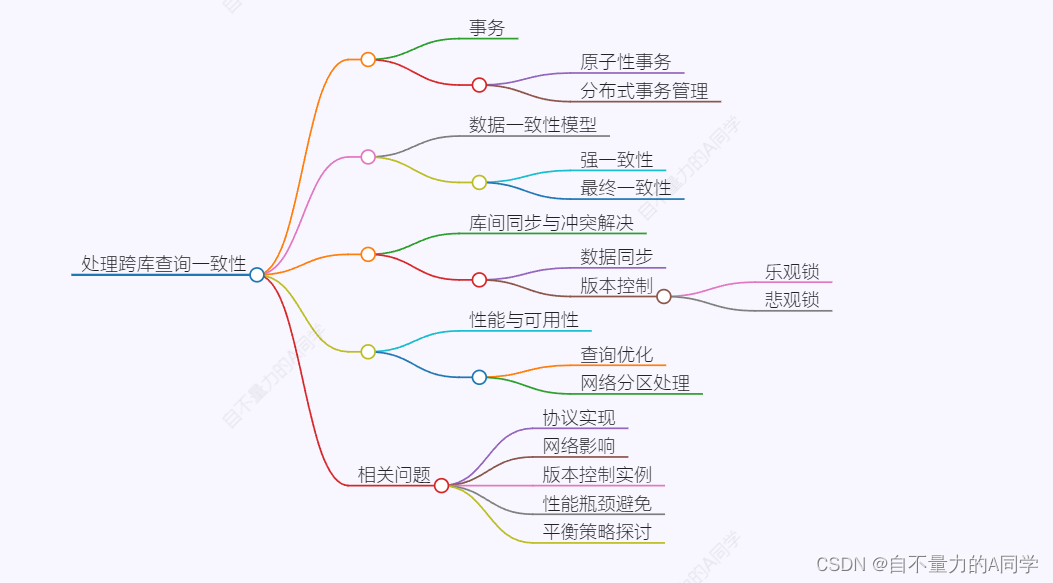
使用事务: 在多个库之间执行操作时,确保它们作为一个原子单元(atomic transaction)进行。这样,如果任何一个操作失败,整个事务都会回滚,保持数据的一致性。
分布式事务管理: 使用分布式事务协议(如两阶段提交、TCC或 saga模式)协调跨库操作,确保要么所有更改都完成,要么全部撤销。
强一致性和最终一致性: 根据应用需求选择合适的模型,强一致性(如在一个读写操作中所有节点返回相同结果)对于金融交易等高可用场景很重要,而最终一致性(数据最终会达到一致,但可能有短时间的不一致)在一些延迟可接受的场景下更合适。
库间的数据同步: 定期同步或事件驱动的数据复制机制,确保所有库中的数据都是最新的。
版本控制: 为跨库依赖引入版本控制,比如乐观锁或悲观锁,避免并发冲突。
数据库设计优化: 尽量减少跨库查询,通过良好的数据库设计将相关的数据存储在一起。
错误恢复和重试策略: 设计适当的错误处理机制,当查询失败时,能够自动或手动重新尝试。
监控和审计: 实施严格的监控,以便及时发现和修复一致性问题,并记录日志便于追踪。