类和对象
1. Page Object设计原理
Page Object 是selenium 自动化测试实践的最佳设计模式之一,其设计原理是
- 1个html —>1个PageObject类,这个类包含:元素定位、元素操作
- 测试用例单独一个类:测试数据、测试用例
如登录页面login.html 的Page Object设计模式如下:
2. pageobject类设计方案
pageobject 设计有多种方案,常用的两种方案如下,我们以一个简单的输入账号、密码、点击登录的页面作为示例
2.1 方式一: 定位、操作方法、操作方法组合
- 元素定位 : 仅定位元素
user_loc = (By.ID, 'username') - 元素操作方法: 根据定位,将元素的输入文字、点击、获取文字邓操作封装为元素操作方法
def user_input(self,username: str):
self.driver.find_element(*self.user_loc).send_keys(username)
3 .界面操作:元素操作方法组合成一系列的界面操作,如登录的界面操作由三部分组成:输入账号、输入密码、点击登录
def login(self, username, password):
"""登录"""
user_input(username)
password_input(password)
login_click()
2.2 方式二: 定位、操作组合
- 元素定位 : 仅定位元素
user_loc = (By.ID, 'username') - 界面操作: 操作元素 + 元素操作组合
def login(self, username, password):
"""登录"""
self.driver.find_element(*self.user_loc).send_keys(username)
self.driver.find_element(*self.password_loc).send_keys(password)
self.driver.find_element(*self.login_loc).click()
PageObject 设计模式的优点
1、当某个页面的元素发生变化,只需要修改该页面对象中的代码即可,测试用例不需要修改。
2、提高代码重用率。结构清晰,维护代码更容易。
3、测试用例发生变化时,不需要或者只需要修改少数页面对象代码即可。
3. PageObject 设计模式实战
3.1 目录结构与设计模式框架
为演示此设计模式,我们暂且使用一个本地简单的web进行自动化测试用例的编写,
整个目录结构如下:
my_web 目录结构和功能如下:(此目录仅为了演示web功能,实际情况不需要)
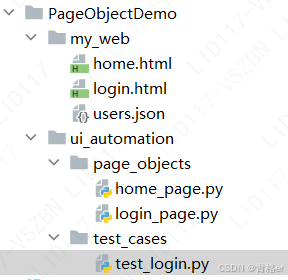
my_web
|-------- login.html :登录页面,账号正确跳转到首页
|-------- home.html : 首页,显示当前登录的用户名
|-------- users.json :存储用户账号密码,模拟与后端登录接口进行交互,实际情况中不需要此文件
UI界面如下,详细源码可再本章资源中下载
UI自动化目录结构和功能如下:

ui_automation
|-- page_objects :存放各个页面的page_onbject的目录
|-------- login_page.py: login.html 页面的page_object类
|-------- home_page.py: home.html 页面的page_object类
|-- test_cases : 存放所有测试用例的目录
|-------- test_login.py :login页面测试用例
3.2 实战代码实现
login_page.py
from selenium.webdriver.remote.webdriver import WebDriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
class LoginPage:
# 初始化获取webdriver
def __init__(self, driver: WebDriver):
self.driver = driver
# 元素定位
user_loc = (By.ID, 'username')
password_loc = (By.ID, 'password')
login_loc = (By.ID, 'submit')
error_message_loc = (By.XPATH, '//*[@id="errorMessage"]')
# 界面操作 - 登录
def login(self, username, password):
"""登录"""
self.driver.find_element(*self.user_loc).send_keys(username)
self.driver.find_element(*self.password_loc).send_keys(password)
self.driver.find_element(*self.login_loc).click()
def get_error_message(self):
"""获取错误提示"""
WebDriverWait(self.driver,10).until(EC.visibility_of_element_located(self.error_message_loc))
return self.driver.find_element(*self.error_message_loc).text
home_page.py
from selenium.webdriver.remote.webdriver import WebDriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
class HomePage:
def __init__(self, driver: WebDriver):
self.driver = driver
# 元素定位
user_info_loc = (By.ID,'username')
# 元素操作
def get_element_exists(self):
# 可采用 异常捕获处理-设置元素等待可见方式 进行判断
WebDriverWait(self.driver, 5).until(EC.visibility_of_element_located(self.user_info_loc))
return self.driver.find_element(*self.user_info_loc).text
测试用例我们写在test_login中,此处我们验证以下3个场景:
| 编号 | 场景 | 步骤 | 预期结果 |
|---|---|---|---|
| test_01_user_name_error | 登录失败:用户名错误 | 输入用户名错误、密码正确,点击登录 | 提示用户名错误 |
| test_02_password_error | 登录失败:密码错误 | 输入用户名正确、密码错误,点击登录 | 提示密码错误 |
| test_03_login_success | 登录成功 | 输入用户名正确、密码正确,点击登录 | 跳转到首页,显示用户登录用户名 |
test_login.py
import unittest
import os
from selenium import webdriver
from PageObjectDemo.ui_automation.page_objects.login_page import LoginPage
from PageObjectDemo.ui_automation.page_objects.home_page import HomePage
class TestLogin(unittest.TestCase):
@classmethod
def setUpClass(cls): # 每个类在开始执行的时候调用一次,此处进行webdriver的初始化,避免每个用例都打开一个浏览器
options = webdriver.ChromeOptions()
options.add_argument("--disable-web-security") # 设置浏览器禁用安全策略,此处是因为测试的web使用的是本地文件,在页面跳转过程中如果不设置非安全模式会因为同源策略问题导致无法跳转到等登录界面,实际情况中可以不设置
cls.driver = webdriver.Chrome(options=options)
file_path = 'file:///' + os.path.abspath('../../my_web/login.html') # 获取当前文件的绝对路径
cls.driver.get(file_path) # 访问页面,实际测试的时候替换成url即可
cls.driver.maximize_window() # 设置浏览器为最大尺寸
@classmethod
def tearDownClass(cls) -> None:
cls.driver.close() # 所有测试用例都执行完成后,关闭浏览器
def tearDown(self):
self.driver.refresh() # 每个用例执行完成会调用一次,刷新页面,以便页面回复默认值(清空先前测试用例输入的文字)
def test_01_user_name_error(self):
LoginPage(self.driver).login( 'admin111', 'pass@123456')
self.assertEqual(LoginPage(self.driver).get_error_message() ,'用户名错误')
def test_02_password_error(self):
LoginPage(self.driver).login('admin', 'pass@12345678')
self.assertEqual(LoginPage(self.driver).get_error_message() , '密码错误')
def test_03_login_success(self):
LoginPage(self.driver).login('admin', '123456')
self.assertTrue(HomePage(self.driver).get_element_exists())
if __name__ == '__main__':
unittest.main() # 执行测试用例
注意:因为 test_login仅打开了一个浏览器,因此登录失败的测试用例的顺序要放在前面执行,如果登录成功的测试用例放在最前面,就会因为登录之后跳转到首页,而其他用例再去执行的时候浏览器处于登录页面,无法进行登录页面的操作,进而导致测试用例失败
以上实战代码可在资源中下载