大模型开发
概念
以大语言模型为功能核心,通过大语言模型的强大理解能力和生成能力,结合特殊的数据或业务逻辑来提供独特功能的应用称为大模型开发。
大模型开发中,我们一般不会大幅度改动模型,而是作为一个调用工具,通过Prompt Engineering, 数据工程, 业务逻辑分解等手段来充分发挥大模型能力,适配应用任务。
大模型开发vs传统AI开发
大模型两个核心能力:指令理解与文本生成提供了复杂业务逻辑的简单平替方案。
开发:
传统AI开发:需要一次拆解复杂的业务逻辑,对于每个子业务训练优化模型,最后形成完整的模型链路来解决整个业务逻辑。
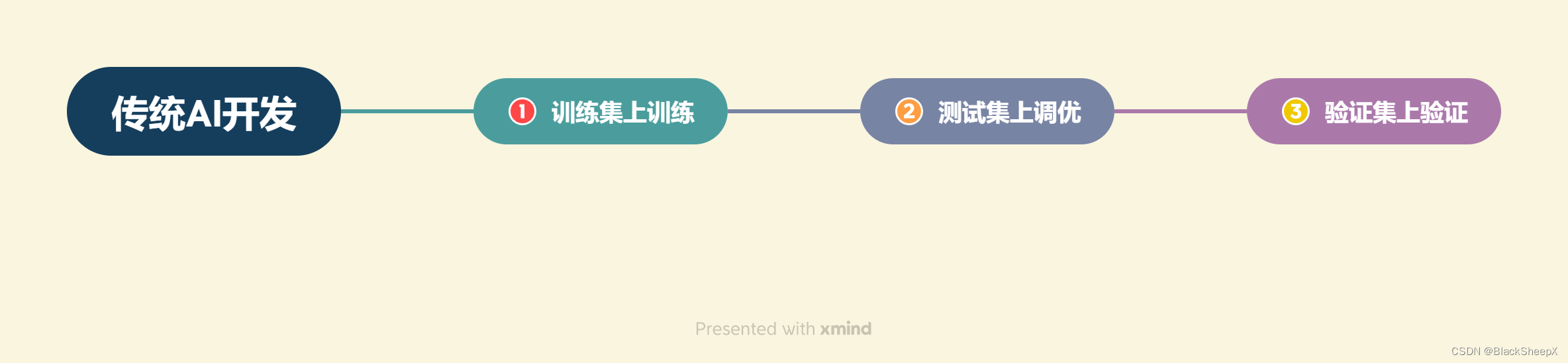
大模型开发:尝试用Prompt Engineering来替代子模型的训练调优,通过Prompt链路组合来实现业务逻辑,用一个通用大模型+若干业务Prompt来解决任务,从而将传统的模型训练调优转变成了更简单轻松的Prompt设计调优。
评估
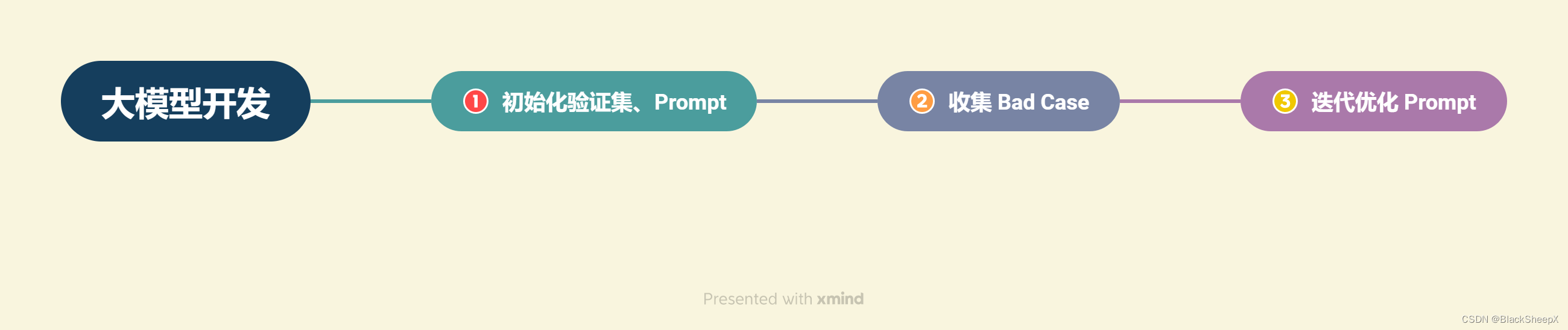
传统AI开发:构造训练集,测试集,验证集,通过在训练集训练模型,测试集调优模型,验证集上最终验证模型效果来评估性能。
大模型开发:直接从实际业务需求出发构造小批量验证集,设计合理Prompt来满足验证集效果,然后不断收集当下Prompt在业务逻辑中的Bad Case,并将其加入验证集,针对性优化Prompt,最后实现较好的泛化效果。
整体流程

- 确定目标 开发应用的场景,目标人群,核心价值
- 设计功能 应用功能,大体逻辑
- 搭建整体架构: 用LangChain搭建架构:Prompt、向量数据库、大模型(、function calling)
- 搭建数据库:向量语义搜索:收集数据并预处理,向量化存储入库。
- Prompt Engineering:
- 验证迭代*
- 搭建前后端
- 体验优化
项目流程
step 1:项目规划与需求分析
- 项目目标:基于个人知识库的问答助手
- 核心功能:
- 上传文档、创建知识库
- 选择知识库,检索用户提问的知识片段
- 提供知识片段与提问,获取大模型回答
- 流式回复
- 历史对话记录
- 确定技术架构与工具:
- LangChain框架
- Chroma知识库
- 大模型API调用
- 前后端使用Gradio和Streamlit
step 2:数据准备和向量知识库构建
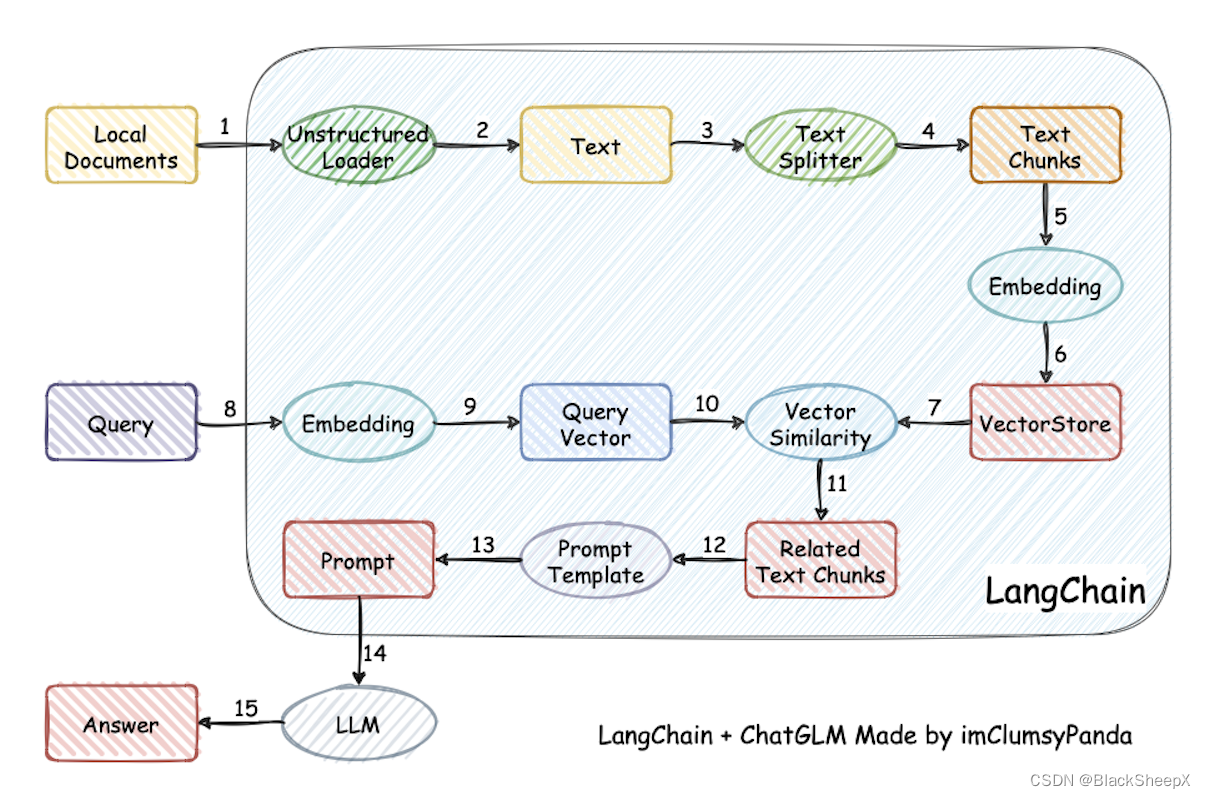
项目过程:加载本地文档 -> 读取文本 -> 文本分割 -> 文本向量化 -> question向量化 -> 匹配question向量匹配topk ->匹配出的文本作为上下文和问题一起添加到Prompt -> 提交给LLM生成回答
step 3:大模型集成和API连接
- 集成GPT、星火、文心、GLM等大模型,配置API连接
- 编写代码,实现与大模型API的交互,以便获取问题答案
step 4:核心功能实现
- 构建Prompt Engineering,实现大模型回答功能,根据用户提问和知识库内容生成回答
- 实现流式回复,允许用户进行多轮对话
- 添加历史对话记录功能,保存用户和助手的交互历史
step 5:核心功能迭代优化
- 进行验证评估,收集Bad Case
- 根据Bad Case迭代优化核心功能实现
step 6:前端与用户交互界面开发
- 使用Gradio和Streamlit搭建前端界面
- 实现用户上传文档、创建知识库功能
- 设计用户界面,包括问题输入、知识库选择、历史记录展示等
step 7:部署测试与上线
- 部署问答助手到服务器或云平台,确保可在互联网上访问
- 进行生产环境测试,确保用户稳定
- 上线发布
step 8:维护与持续改进
项目架构
对于项目的解析较为简单,跟着接下来的教程继续编写即可