Comment: EMNLP 2020
一句话总结
任务:开放域问答中的retriever,从海量文本中选出与问题接近的文本。
方法:采用正负样本对对比学习的方法,使得相关问题与文本对拉近,不相关的拉远。并将计算的问题与正样本之间的相似度矩阵存储起来,用于后续reader从中提取答案。
abstract
open-domain question answering依赖于有效的文章检索去选择候选文本,传统的离散向量空间方法比如TF-IDF,BM25。在这项工作中,我们证明可以单独使用密集的表示实现检索,在这种情况下,通过简单的双语编码框架从少量的问题和段落中学习了嵌入。
introduction
open-domain question answering从大量文本中检索出答案,包含简化的两个部分框架:
1) context retriever 选出一些包含了答案的段落
2)reader 深入检查这些段落给出具体的答案。
尽管这是一个合理的策略,但在实践中性能急剧退化,表明需要改善检索的需求。
retriever常用的方法是TF-IDF orBM25,用Index高效地匹配关键词,将文本和问题表示为一个高维稀疏的向量。
但在实际中,由完全不同的标记组成的同义词或释义仍然可以映射到彼此接近的向量。稠密的retrieval可以做到,传统的却不能。如原文中提到的例句。dense encoding可以很好地匹配问题中的bad guy”和文本中的“villain“.传统的高维稀疏向量却难以处理。
然而,一般认为学习一个好的密集向量表示需要大量的问题和上下文的标签对。而且之前“Dense retrieval methods”并没有胜过TF-IDF/BM25在开放域QA中。直到ORQA模型的出现。该模型提出了一个复杂的反完形填空任务ICT,预测被Mask掉的句子块当做额外的预训练任务。“question encoder and the reader model”然后使用问题和上下文对微调,虽然这个方法实现了开放域问答的新sota但有两个缺点:一个是那个额外的预训练任务是计算密集型的,我们不完全清楚regular sentences是不是能很好地替代目标函数中的问题;二是context encode 没有用问答对进行微调,其表现可能是次优的。(这里举例了一个方法,谈了他的缺点)
“can we train a better dense embedding model using only pairs of questions and passages (or answers), without additional pretraining” 而是只利用现有的标准BERT预训练模型和双编码器结构。专注于使用small数量的问答对制定更好的训练计划。
通过一系列仔细的消融研究,我们的最终解决方案出乎意料地简单:embedding优化方法为:最大化question和相关文本向量的内积,并客观地比较一批中所有问题和文本对。
我们的方法胜过了BM25 和前文提到的ORQA模型
贡献:
我们证明了通过合理的训练设置,简单的微调问答对encoder也能胜过BM25;
同时证明了类似ORQA那样的额外与训练步骤不一定需要;
在open-domain question answeing任务中,更高的检索精度实际上意味着更高的端到端QA精度;
然后将现在的reader模型应用于我们模型检索出来的top个候选,在开放检索设置下的多个QA数据集上取得了与几个复杂得多的系统相比相当或更好的结果。
2 background
问题定义:提出一个问题,retriever从海量数据中找出相关的排名靠前的前几个文本,reader从中找出最佳答案span.本文专注于retriever
挑战:为了覆盖各种各样的域,语料库的大小可以很容易地从数百万个文档(如Wikipedia)到数十亿个文档(如Web)。因此,任何开放域QA系统都需要包含一个高效的retriever组件,该组件可以在应用reader提取答案之前选择一小部分相关文本
3 DENSE PASSAGE RETRIEVER
我们的研究重点是改进开放域QA中的检索组件。给定M个文本段落的集合,我们的DPR)的目标是在一个低维和连续的空间中索引所有的段落,这样它就可以在运行时高效地检索与读者输入问题最相关的k个段落。注意,M可以非常大(例如,我们的实验中有2100万段,见4.1节),而k通常很小,如20-100
3.1 overview
度量距离的相似函数很多,我们选择了最简单的内积函数来度量问题与上下文文本之间的距离。(附录中有详细的相似函数选择的消融实验)
encoder
采用两个独立的BERT模型分别编码问题和上下文文本,取[cls]作为向量表示,所以维度为768
inference
在推理时将所有文本使用训练过的文本编码器Ep进行编码,然后使用FAISS离线索引(FAISS是一个非常高效的开源库,用于密集向量的相似性搜索和聚类,它可以很容易地应用于数十亿个向量)。在运行时,输入问题得到其编码,然后在文本中检索与问题最相似的前K个文本。
3.2 train
训练编码器,使点积相似度(Eq.(1))成为一个很好的检索排序函数,本质上是一个度量学习问题。目标是创建一个矢量空间,这样相关的成对问题和文章之间的距离就会更小
输入的样本对为一个问题,一个与问题相似的正样本,N个与问题不相似的负样本,计算相似度后最小化损失函数

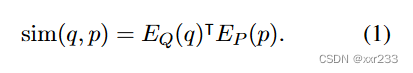
正负样本如何来的呢
对于检索问题,通常情况下正示例是显式可用的,而反示例需要从一个非常大的池中选择。正样本一般数据集就会给,或者用answer找到。集合中的所有其他段落,虽然没有显式指定,但默认情况下可视为无关紧要。在实践中,如何选择反面例子往往被忽视,但可能是学习高质量的编码器的决定性因素。
两种负样本构造方法:
1)随机选择除正样本之外的段落
2)使用BM25选择不包含答案但匹配大多数问题标记的选项
3)gold passages:没有出现在训练集中的其他问题的正样本
训练方法
由于正负样本来自同一个Batch内,计算效率更高,假设batch为B,计算得到的相似矩阵为B*B;当i=j时为正样本对,其他的都为负样本对。在后面的实验中将讨论每种方式的有效性
(后文消融实验有讨论不同的训练方法)
4 实验
4.1 Wikipedia data 预处理
将一些半结构化数据诸如表格,表单、模棱两可的页面清除掉;然后将每篇文章分割成100个词的段落,每个段落前加上[SEP]作为检索的基本单元。
4.2 question answering datsets
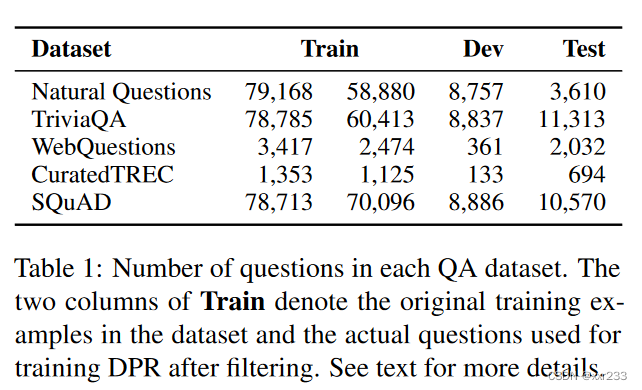
使用了五个常用的QA数据集
“Natural Questions (NQ)”:为端到端问答设计,这些问题是从真实的谷歌搜索查询中挖掘出来的,而答案则是由注释者在维基百科文章中识别出来的。
“TriviaQA”:冷知识问答对,从网页上抓取的
“WebQuestions (WQ)”:使用Google suggest API挑选的问题,答案是实体
“CuratedTREC (TREC)”:来自不同网页的TREC QA 追踪的问题,用于非结构化语料库的开放领域QA。
“SQuAD v1.1”:非常出名的阅读理解 benchmark,注释者根据给出的段落提出可以从文本中找到答案的问题。虽然SQuAD曾经用于开放领域的QA研究,但它并不理想,因为许多问题在没有提供段落的情况下缺乏上下文。我们仍然把它包括在我们的实验中,以便与以前的工作进行公平的比较,我们将在5.1节中进一步讨论。
Selection of positive passages:
因为TREC、WebQuestions和TriviaQA6中只提供成对的问题和答案,所以我们使用BM25中包含答案的排名最高的段落作为正样本。如果检索到的前100篇文章都没有答案,那么这个问题将被丢弃。对于SQuAD和Natural Questions,由于原始段落的分割和处理方式不同于我们的候选段落池,在候选段落池中检索能与答案span匹配的段落作为正样本
5 experiments :passage retrieval
评估(DPR)的检索性能,并分析其输出的差异
5.1 result
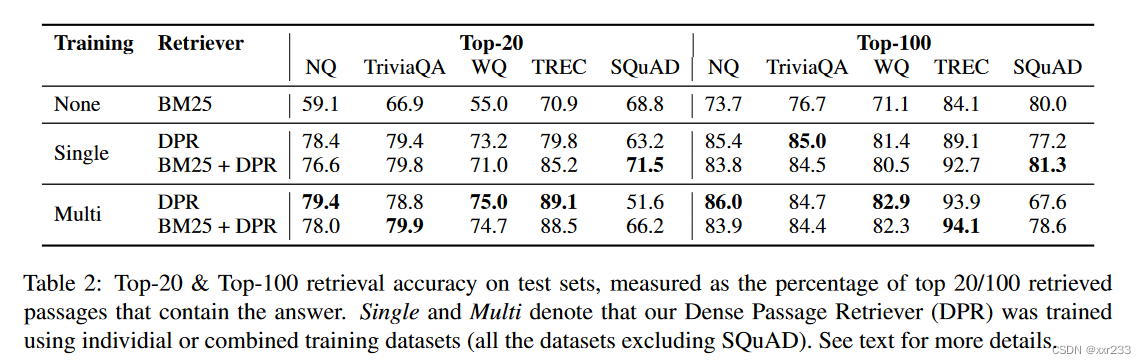
None-BM25:使用BM25传统方法来做;top-20选取最相关的前20篇文章
single:每个数据集单独训练
multi:将除了SQUAD之外的数据混合起来训练
BM25+DPR:“BM25(q,p) + λ · sim(q, p)” ,“λ = 1.1”
除了SQuAD, DPR在所有数据集上都比BM25表现得更好。当k很小时,差距尤其大。我们推测SQuAD的表现较差是由于两个原因。首先,批注者在看到文章后提出问题。因此,文章和问题之间有很高的词汇重叠,这给BM25一个明显的优势。第二,数据仅从500多篇维基百科文章中收集,因此训练示例的分布具有极大的偏倚。
5.2 消融实验
sample efficiency
我们探讨了需要多少训练示例才能获得良好的段落检索性能
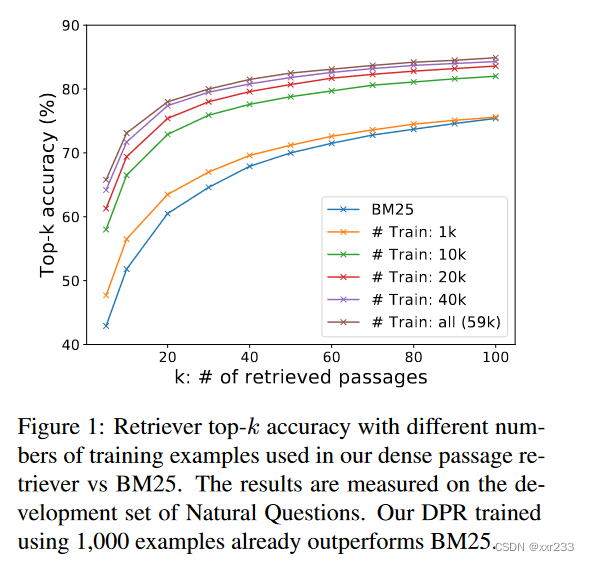
图1展示了不同数量训练示例的top-k检索精度,在Natural Questions开发集上测量。一个只使用1000个样本训练的DPR已经超过BM25。这表明,使用一般的预训练语言模型,可以用少量的问题-段落对训练高质量的DPR。添加更多的训练示例(从1k到59k)进一步持续提高检索精度。
IN-BATCH NEGATIVE TRAINING
我们在Natural Questions开发集上测试不同的训练方案,总结结果如表3所示。

IB:是否使用in-batch negative training方式;;G.+BM25(1) and G.+BM25(2) denote in-batch training with 1 or 2 additional BM25 negatives
最上面的区块是“1-of-N training setting”,其中每个batch的问题都与一篇正面文章和它自己的一组n篇负面文章配对.我们发现,当k≥20时,负样本的选择——“random, BM25 or gold passages (positive passages from other questions)”——在这个设置中不太影响top-k的准确性。
“The middle bock is the in-batch negative training (Section 3.2) setting”我们发现,使用类似的配置(7个gold 负样本), in-batch negative training大大提高了结果。两者的关键区别在于gold 负样本是来自同一批还是来自整个训练集。实际上,n-batch negative training是一种简单且记忆效率高的方法,可以重用批内已经存在的负面例子,而不是创建新的例子。它产生了更多的对,从而增加了训练示例的数量,这可能有助于良好的模型性能。因此,随着批大小的增长,准确性不断提高。
我们探索in-batch negative training与额外的“hard”负样本,即那些有较高的BM25分数但不包含答案的段落。这些附加段落被用作同一批次所有问题的否定段落。我们发现,添加一个BM25负样本大大改善了结果,而添加两个没有进一步帮助。
Impact of gold passages
我们使用与原始数据集中黄金上下文匹配的段落作为样本(当可用时),或者,切换到远程监督的段落(使用排名最高的BM25段落包含答案),两种方法只有1个点的误差
Similarity and loss
“dot product, cosine and Euclidean L2 distance”几种相似函数比较。发现L2的性能可与点积相媲美,而且它们都优于余弦。在损失函数方面,类似地,除了negative loglikelihood,还有三重态损失(triplet loss )它直接比较一个问题的正面段落和负面段落。实验表明,采用triplet loss对实验结果影响不大
Cross-dataset generalization
关于DPR的区别性训练,一个有趣的问题是,如果使用“non-iid setting”,它的性能会下降多少。换句话说,当直接应用于不同的数据集而不进行额外的微调时,它还能很好地一般化吗?我们只在Natural Questions上预训练,直接在“WebQuestions and CuratedTREC”数据集上进行测试。我们发现他的泛化性很好,只比在对应数据集上微调后的top-20精度相差3-5个点,且都优于BM25的方法。
5.3 qualitative analysis
虽然DPR总体上优于BM25,但两种方法提取的文本有质的差异。像BM25这样的术语匹配方法对高选择性的关键字和短语很敏感,而DPR更好地捕捉词汇变化或语义关系。在附录中有更多的讨论
5.4 Run-time Efficiency
我们需要一个开放领域QA的检索组件的主要原因是为了减少读者需要考虑的候选文章的数量,这对于实时回答用户的问题至关重要。我们检测了检索速度。在FAISS对实值向量的内存索引的帮助下,DPR可以变得非常高效,每秒处理995.0个问题,每个问题返回前100篇文章。相比之下,BM25/Lucene(在Java中实现,使用文件索引)每CPU线程每秒处理23.7个问题。
另一方面,为稠密向量建立索引所需的时间要长得多。为2100万文章计算密集向量是资源密集型的,但可以很容易地并行化,在8个gpu上大约需要8.8小时。然而,在单服务器上构建2100万个文章的FAISS索引需要8.5小时。相比之下,使用Lucene构建反向索引要便宜得多,总共只需要30分钟。
6 Experiments: Question Answering
我们实现了一个端到端的问答系统,其中我们可以直接插入不同的检索系统。除了检索器,我们的QA系统还包括一个输出问题答案的reader。给定检索到的前k篇文章(在我们的实验中多达100篇),reader会给每一篇文章分配一个文章选择分数。此外,它从每一篇文章中提取一个答案span,并分配一个span分数。文章选择模型通过问题和文章之间的cross-attention来重新排序。虽然cross-attention由于其不可分解的特性不能在大型语料库中检索相关段落,但它比Eq中的双编码器模型sim(q, p)具有更大的容量。将它应用于从少量检索到的候选文章中选择文章,效果很好