一、简介
Bash Shell提供了很多字符串和文件处理的命令。如awk、expr、grep、sed等命令,还有文件的排序、合并和分割等一系列的操作命令。grep、sed和awk内容比较多故单独列出,本文只涉及字符串的处理和部分文本处理命令。
二、字符串处理
1、expr命令
expr引出通用求值表达式,可以实现算术操作、比较操作、字符串操作和逻辑操作等功能。
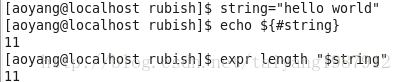
(1)计算字符串长度
字符串名为string,可以使用命令${#string}或expr length $string两种方法来计算字符串的长度。若string包括空格,需用双引号引起来(expr length后面只能跟一个参数,string有空格会当作多个参数处理)。
(2)子串匹配索引
expr的索引命令格式为:expr index $string $substring(子串),在字符串$string上匹配$substring中字符第一次出现的位置,匹配不到,expr index返回0。

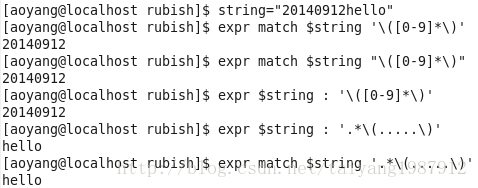
"wo"在字符串string中虽然出现在第7,但还是返回o首次出现的位置5。
(3)子串匹配的长度
expr match $string $substring,在string的开头匹配substring字符串,返回匹配到的substring字符串的长度,若string开头匹配不到则返回0,其中substring可以是字符串也可以是正则表达式。
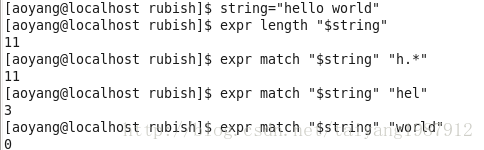
"world"尽管在string中出现,但是未出现在string的开头处,因此返回0。
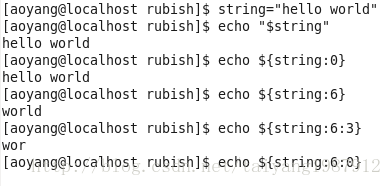
(4)抽取子串
Bash Shell提供两种命令#{...}和expr实现抽取子串功能。
其中#{...}有两种格式。
格式一:#{string:position}从名称为$string的字符串的第$position个位置开始抽取子串,从0开始标号。
格式二:#{string:position:length}增加$length变量,表示从$string字符串的第$position个位置开始抽取长度为$length的子串。
(都是从string的左边开始计数抽取子串)
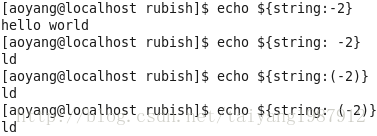
#{...}还提供了从string右边开始计数抽取子串的功能。
格式一:#{string: -position},冒号与横杠间有一个空格
格式二:#{string:(position)}
expr substr也能够实现抽取子串功能,命令格式:expr substr $string $position $length,与#{...}最大不同是expr substr命令从1开始进行标号。

接着使用正则表达式抽取子串的命令,但只能抽取string开头处或结尾处的子串。
抽取字符串开头处的子串,格式一:expr match $string ' $substring '。格式二:expr $string : ' $substring ',其中冒号前后都有一个空格。
抽取字符串结尾处的子串,格式一:expr match $string '.* $substring '。格式二:expr $string : '.* $substring '。.*表示任意字符的任意重复。
(5)删除子串
删除字串是指将原字符串中符合条件的子串删除,命令只有${...}格式。
从string开头处删除子串,格式一:${string#substring},删除开头处与substring匹配的最短子串。格式二:${string##substring}删除开头处与substring匹配的最长子串。其中substring并非是正则表达式而是通配符。
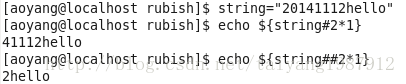
从string结尾处开始删除,格式一:${string%substring},删除结尾处与substring匹配的最短子串。格式二:${string%%substring}删除结尾处与substring匹配的最长子串。与上述命令仅在#和%之间不同。
(5)替换子串
替换子串命令都是${...},可以在任意处、开头处、结尾处替换满足条件的子串。其中的substring都不是正则表达式而是通配符。
在任意处替换子串命令,格式一:${string/substring/replacement},仅替换第一次与substring相匹配的子串。格式二:${string//substring/replacement},替换所有与substring相匹配的子串。
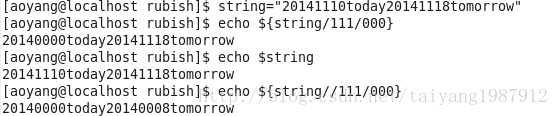
在开头处替换与substring相匹配的子串,格式为:${string/#substring/replacement}。
在结尾除替换与substring相匹配的子串,格式为:${string/%substring/replacement}。

三、对文件的排序、合并和分割
文本处理命令包括sort命令、uniq命令、join命令、cut命令、paste命令、split命令、tr命令和tar命令,它们实现对文件记录排序、统计、合并、提取、粘贴、分割、过滤、压缩和解压缩等功能,它们与sed和awk构成了Linux文本处理的所有命令和工具。
(1)sort命令
sort命令是一种对文本排序的工具,它将输入文件看做由多条记录组成的数据流,而记录由可变宽度的字段组成,以换行符作为定界符。sort命令格式:sort [选项] [输入文件]
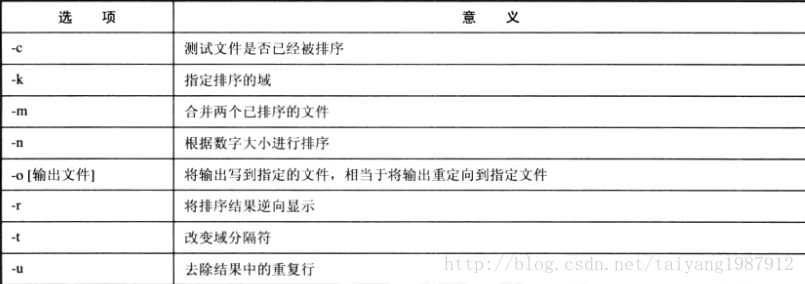
sort命令默认的域分隔符是空格符,-t选项可用于设置分隔符。sort -t: test中-t与":"之间是没有空格的。未指定-t分隔符是空格符,这时记录内开头与结尾的空格都将被忽略,如(空格):root:(空格)则只有一个域,-t:指定冒号则这条记录就包含了三个域。
sort命令默认是按第1个域进行排序的,也可以通过-k选项指定某个域进行排序。例如:sort -t: -k3 test。
sort命令-n选项可以指定根据数字大小进行排序(不按字母顺序排序)。
sort命令-r选项用于将排序结果逆向显示,如使用-n按数字从小到大排序后,使用-r选项将结果逆向显示。
sort命令-u选项去掉排序结果中的重复行。
sort命令-o选项加上文件名将结果保存到另一个文件中(sort默认将排序后的结果输出到屏幕上)。
sort命令-m选项将两个排好序的文件合并成一个排好序的文件,在文件合并前它们必须已经排好序。-m选项对未排序的文件合并是没有任何意义的。
sort和awk都是分域处理文件的工具,两者结合起来可以有效地对文本块进行排序。
(2)uniq命令
uniq命令用于去除文本文件中的重复行,类似sort -u,但uniq命令去除的重复行必须是连续重复出现的行,中间不能夹杂任何其他文本行,而sort -u命令使所有的重复记录都被去掉。
uniq命令有3个选项:

uniq -c test,打印每行在文本中重复出现的次数。
(3)join命令
join命令用于实现两个文件中记录的连接操作,将两个文件中具有相通域的记录选择出来,再将这些记录所有的域放在一行(包含来自两个文件的所有域)。如join -t: a.txt b.txt,将a.txt和b.txt具有共同域的记录连接到一起。
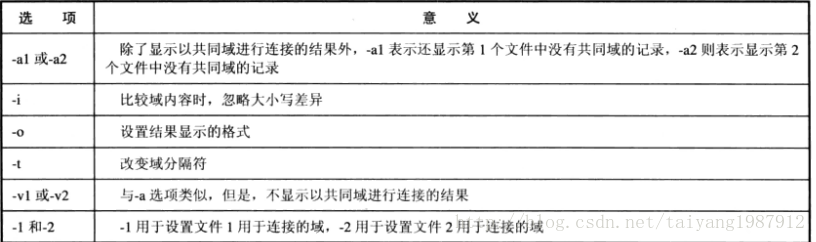
join命令的结果默认是不显示这些未进行连接的记录,-a和-v选项用于显示这些未进行连接的记录,-a1和-v1指显示文件1中未连接的记录,而-a2和-v2指显示文件2中的未连接记录。-a与-v的区别是:-a显示以共同域进行连接的结果和未进行连接的记录,而-v则不显示以共同域进行连接的记录。
join命令默认显示连接记录在两个文件中的所有域,而且按顺序。-o选项用于改变结果显示的格式,可以指定显示哪几个域、按什么顺序显示这些域。例如:join -t: -o1.1 2.2 1.2 a.txt b.txt,其中-o1.1 2.2 1.2表示显示格式依次显示第1个文件中的第1个域、第2个文件中的第2个域、第1个文件中的第2个域,结果显示三个域。
join -t: -i -1 3 -2 1 a.txt b.txt,文件1的第3个域和文件2的第1个域进行连接,-i忽略大小写。join命令在对两个文件进行连接时,两个文件必须都是按照连接域排好序的。
(4)cut命令
cut命令用于从标准输入或文本文件中按域或行提取文本,cut [选项] 文件,cut的选项如下:

cut -c1-5 a.txt,提取a.txt的第1~5个字符。-c有三种表示方式:-cn表示第n个字符、-cn,m表示第n个字符和第m个字符、-cn-m表示第n个字符到第m个字符。-c是按字符提取文本的,无须使用-d改变域分隔符,-f按域提取文本时就需要使用-d设置域分隔符了。-f同样也可以用三种方式指定域数或域范围。
cut可以灵活提取文本文件中的内容,默认将提取内容放在标准输出上,也可以使用文件重定向来将内容保存到文件。
(5)paste命令
paste命令用于将文本文件或标准输出中的内容粘贴到新的文件,它可以将来自不同文件的数据粘贴到一起,形成新的文件。paste命令格式:paste [选项] file1 file2,其选项如下:

paste FILE1 FILE2,粘贴FILE1和FILE2,FILE1在前,将FILE1的内容作为每行记录的第1域、FILE2的内容作为第2域。可以使用-d设置域分隔符paste -d: FILE1 FILE2。
paste命令默认是将一个文件按列粘贴的,-s选项可以实现将一个文件按行粘贴。
ls | paste -d" " - - - -,从标准输入中读取数据时"-"选项才起作用,"-"表示读取1次标准输入数据即读取到标准输入数据中的一个域,- - - - 每行显示4个文件名。
(6)split命令
split命令用于将大文件切割成小文件,split可以按照文件的行数、字节数切割文件,并能在输出的多个小文件中自动加上编号。split命令格式:splite [选项] 待切割的大文件 输出的小文件。

split -2 a.txt final.txt,按2行对a.txt进行切割,每2行记录切割成1个文件。split命令在final.txt后面自动加上编号以区分不同的小文件,编号为aa~zz。
split -b100 a.txt,-b选项在切割文件时仅考虑了文件大小并未考虑记录的完整性。split -C100 a.txt,按100B切割a.txt,按-C并不严格按照100B的大小进行切割,而是在切割时尽量维持每行的完整性。
(7)tr命令
tr命令实现字符转换功能,类似于sed命令,tr能实现的功能sed命令都可以实现。tr [选项] buffer1 buffer2 < outputfile,其选项有三个,它只能从标准输入读取数据。

tr -d A-Z < a.txt,删除a.txt文件中所有的大写字母。
tr -d "[\n]" < a.txt,删除a.txt文件中所有的换行符。
tr -s "[\n]" < a.txt,将重复出现的换行符压缩成一个换行符。
tr命令也可以加上buffer1和buffer2,将buffer1用buffer2来替换,tr "[a-z]" "[A-Z]" < a.txt,将a.txt中的小写字母替换成大写字母。
(8)tar命令
tar命令是linux的归档命令,实现linux系统文件的压缩和解压缩。tar [选项] 文件名或目录名,tar的常用选项如下:
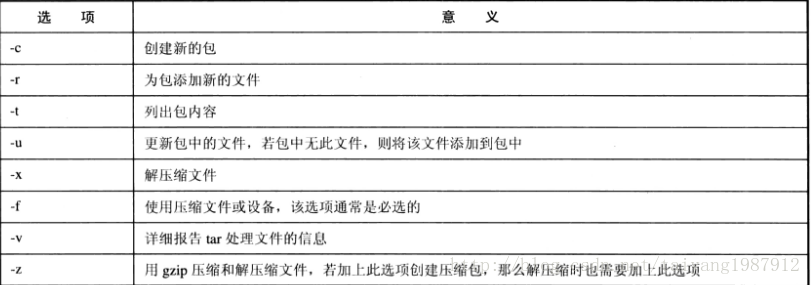
tar -cf a.tar *.txt,将所有的.txt结尾的文件放入压缩包a.tar。-c表示创建新的包,-f通常是必选选项。
tar -tf a.tar,查看a.tar压缩包的内容。-t列出包内容。
tar -rf a.tar log*,将以log开头的文件添加到a.tar中,-u选项也可用于为包添加新的文件,-u选项完全能代替-r选项。
解压非gzip格式的压缩包:tar -xvf 压缩包名称
解压gzip格式的压缩包:tar -zxvf 压缩包名称
四、总结
(1)字符串处理和文本处理命令经常出现在各种shell脚本程序中,应熟练地掌握这些命令。
(2)sort、uniq、join、cut、paste、split、tr和tar与grep、sed、awk构成了linux文本处理的所有命令和工具。
(3)该文仅其向导,对命令的详细选项功能还须参考相应的文档。