Understanding Diffusion Models: A Unified Perspective(二)
文章概括
引用:
@article{luo2022understanding,
title={Understanding diffusion models: A unified perspective},
author={Luo, Calvin},
journal={arXiv preprint arXiv:2208.11970},
year={2022}
}
Luo, C., 2022. Understanding diffusion models: A unified perspective. arXiv preprint arXiv:2208.11970.
原文: https://arxiv.org/abs/2208.11970
代码、数据和视频:https://arxiv.org/abs/2208.11970
系列文章:
请在
《
《
《文章
》
》
》 专栏中查找
变分扩散模型(Variational Diffusion Models)
最简单的方式将变分扩散模型(Variational Diffusion Model, VDM)[4, 5, 6] 理解为一个具有三个关键限制的马尔可夫分层变分自编码器:
- 潜变量的维度与数据维度完全相等。
- 每个时间步的潜变量编码器结构不是通过学习得到的;它被预定义为一个线性高斯模型。换句话说,它是以前一时间步的输出为中心的高斯分布。
- 潜变量编码器的高斯参数随时间变化,使得在最终时间步 T T T的潜变量分布为标准高斯分布。
此外,我们明确保持标准马尔可夫分层变分自编码器中分层转换的马尔可夫性质。
要理解 变分扩散模型(Variational Diffusion Model, VDM) 如何与 马尔可夫分层变分自编码器(Markovian Hierarchical Variational Autoencoder, MHVAE) 联系起来,以及其核心限制和特性,我们需要逐步解析其中的数学关系和直观意义。
1. VDM 的背景与特性
VDM 是扩散模型的一种变分解释形式,其核心思想是将扩散过程视为一种马尔可夫链,在时间步 t = 1 , 2 , … , T t = 1, 2, \dots, T t=1,2,…,T 中,通过潜变量逐步生成数据。这一过程可以看作是对 MHVAE 的特殊化,具有以下限制:
潜变量的维度与数据维度相等:
- 在 VDM 中,潜变量 z t z_t zt 的维度与数据 x x x 的维度完全相同。
- 意义:这使得扩散过程的每一步潜变量都可以直接对应到观测数据的空间,从而便于优化和生成。
潜变量的编码器是线性高斯模型:
- q ϕ ( z t ∣ z t − 1 ) ∼ N ( μ t , σ t 2 I ) q_\phi(z_t|z_{t-1}) \sim \mathcal{N}(\mu_t, \sigma_t^2 \mathbf{I}) qϕ(zt∣zt−1)∼N(μt,σt2I),其中:
- 均值 μ t \mu_t μt 是基于前一步潜变量的线性变换。
- 方差 σ t 2 \sigma_t^2 σt2 是预定义的随时间变化的函数。
- 意义:编码器的参数并不是通过学习得到的,而是固定的。这种设置简化了模型,使其更容易训练,同时保留了生成的多样性。
最终时间步的潜变量分布为标准高斯分布:
- 在时间步 T T T,潜变量 z T ∼ N ( 0 , I ) z_T \sim \mathcal{N}(0, \mathbf{I}) zT∼N(0,I),即标准正态分布。
- 意义:这一特性确保了生成过程的稳定性,并为扩散过程的逆推提供了明确的起点。
2. VDM 的三个限制
2.1 潜变量的维度与数据维度相等
- 在标准 MHVAE 中,潜变量 z t z_t zt 的维度可以小于数据维度,从而实现紧凑的特征表示。
- 在 VDM 中,为了将潜变量直接映射到数据空间,要求 z t z_t zt 与数据 x x x 的维度相同。
- 优势:
- 简化了生成和推断过程,因为每一步潜变量都在数据空间中,方便进行操作。
2.2 预定义的线性高斯编码器
- 编码器的条件分布 q ϕ ( z t ∣ z t − 1 ) q_\phi(z_t|z_{t-1}) qϕ(zt∣zt−1) 被固定为一个线性高斯模型: q ϕ ( z t ∣ z t − 1 ) ∼ N ( μ t , σ t 2 I ) , q_\phi(z_t|z_{t-1}) \sim \mathcal{N}(\mu_t, \sigma_t^2 \mathbf{I}), qϕ(zt∣zt−1)∼N(μt,σt2I), 其中:
- μ t = 1 − β t z t − 1 \mu_t = \sqrt{1 - \beta_t} z_{t-1} μt=1−βtzt−1。
- σ t 2 = β t \sigma_t^2 = \beta_t σt2=βt, β t \beta_t βt 是随时间变化的噪声系数。
- 优势:
- 避免了对编码器参数的复杂优化。
- 确保潜变量的演化是平稳的。
2.3 最终时间步的潜变量分布为标准高斯分布
- 通过将编码器设计为逐步增加噪声的过程,在时间步 T T T 达到标准正态分布: z T ∼ N ( 0 , I ) . z_T \sim \mathcal{N}(0, \mathbf{I}). zT∼N(0,I).
- 优势:
- 确保了扩散过程的收敛性。
- 提供了清晰的生成起点,即从 z T ∼ N ( 0 , I ) z_T \sim \mathcal{N}(0, \mathbf{I}) zT∼N(0,I) 开始逆扩散。
3. 直观理解:扩散模型的噪声和逆过程
VDM 可以看作是对数据逐步加噪声和去噪声的过程:
加噪声(推断过程):
- 从原始数据 x x x 开始,逐步添加噪声,生成一系列潜变量 z 1 , z 2 , … , z T z_1, z_2, \dots, z_T z1,z2,…,zT。
- 在时间步 T T T,潜变量 z T z_T zT 几乎是纯高斯噪声。
去噪声(生成过程):
- 从高斯噪声 z T ∼ N ( 0 , I ) z_T \sim \mathcal{N}(0, \mathbf{I}) zT∼N(0,I) 开始,通过逆扩散逐步去噪,最终生成观测数据 x x x。
4. 总结
VDM 的核心限制:
- 潜变量的维度等于数据维度。
- 编码器为固定的线性高斯模型。
- 最终时间步的潜变量分布为标准高斯分布。
直观理解:
- 推断过程:逐步加噪声。
- 生成过程:逐步去噪声。
优势:
- 简化了训练和实现。
- 模型稳定性更高,适合高维数据(如图像)。
让我们进一步阐述这些假设的含义。根据第一个限制,在稍作符号滥用(abuse of notation)的情况下,我们现在可以将真实数据样本和潜变量都表示为 x t x_t xt,其中 t = 0 t = 0 t=0表示真实数据样本, t ∈ [ 1 , T ] t \in [1, T] t∈[1,T]表示对应的分层潜变量,索引由 t t t标记。
“稍作符号滥用”(abuse of notation)是一个数学和科学领域中常用的术语,指在表述中为了简洁或方便,故意不完全遵守严格的符号规则,但其含义依然清晰且不引起混淆。例如:
复用符号:用同一个符号表示不同的对象,但根据上下文可以轻松区分。
- 在这里, x t x_t xt被用来同时表示“真实数据样本”( t = 0 t=0 t=0时)和“潜变量”( t ≥ 1 t \geq 1 t≥1时),尽管严格来说,它们是不同性质的对象。
略去详细说明:忽略某些公式或定义中的次要细节,使表达更直观。
- 例如,这里直接将真实数据和潜变量用统一的形式 x t x_t xt表示,而未明确区分这两者的确切区别。
这种做法在理论推导中很常见,但需要依赖读者的上下文理解能力。
VDM的后验与MHVAE的后验(公式24)相同,但现在可以重写为:
q ( x 1 : T ∣ x 0 ) = ∏ t = 1 T q ( x t ∣ x t − 1 ) (30) q(x_{1:T}|x_0) = \prod_{t=1}^T q(x_t|x_{t-1}) \tag{30} q(x1:T∣x0)=t=1∏Tq(xt∣xt−1)(30)
根据第二个假设,我们知道编码器中每个潜变量的分布是以其上一层分层潜变量为中心的高斯分布。与马尔可夫HVAE不同,每个时间步 t t t的编码器结构不是通过学习得到的;它被固定为一个线性高斯模型,其中均值和标准差可以预先设置为超参数 [5],也可以作为参数学习 [6]。我们将高斯编码器参数化为均值 μ t ( x t ) = α t x t − 1 \mu_t(x_t) = \sqrt{\alpha_t}x_{t-1} μt(xt)=αtxt−1,方差 Σ t ( x t ) = ( 1 − α t ) I \Sigma_t(x_t) = (1 - \alpha_t)\mathbf{I} Σt(xt)=(1−αt)I。这些系数的形式被选择为确保潜变量的方差保持在相似的尺度;换句话说,编码过程是保方差的。
需要注意的是,其他高斯参数化方法也是允许的,并会导致类似的推导。关键点在于, α t \alpha_t αt是一个(可能可以学习的)系数,可以随分层深度 t t t变化以提高灵活性。数学上,编码器的转换表示为:
q ( x t ∣ x t − 1 ) = N ( x t ; α t x t − 1 , ( 1 − α t ) I ) (31) q(x_t|x_{t-1}) = \mathcal{N}(x_t; \sqrt{\alpha_t}x_{t-1}, (1 - \alpha_t)\mathbf{I}) \tag{31} q(xt∣xt−1)=N(xt;αtxt−1,(1−αt)I)(31)
1. 编码器的高斯分布
1.1 编码器分布的定义
公式 (31) 定义了编码器的条件分布: q ( x t ∣ x t − 1 ) = N ( x t ; α t x t − 1 , ( 1 − α t ) I ) , q(x_t|x_{t-1}) = \mathcal{N}(x_t; \sqrt{\alpha_t}x_{t-1}, (1 - \alpha_t)\mathbf{I}), q(xt∣xt−1)=N(xt;αtxt−1,(1−αt)I),
其中:
- x t x_t xt:时间步 t t t 的潜变量(latent variable)。
- x t − 1 x_{t-1} xt−1:时间步 t − 1 t-1 t−1 的潜变量。
- α t \alpha_t αt:时间步 t t t 的系数,可以是超参数,也可以是可学习参数。
- α t x t − 1 \sqrt{\alpha_t}x_{t-1} αtxt−1:高斯分布的均值,表示 x t x_t xt 的期望是上一层潜变量的缩放版本。
- ( 1 − α t ) I (1 - \alpha_t)\mathbf{I} (1−αt)I:高斯分布的方差,表示生成 x t x_t xt 时添加的噪声量。
1.2 编码器的直观理解
- 均值 μ t ( x t ) = α t x t − 1 \mu_t(x_t) = \sqrt{\alpha_t}x_{t-1} μt(xt)=αtxt−1:
- x t x_t xt 的均值是 x t − 1 x_{t-1} xt−1 的一个缩放版本。
- α t \alpha_t αt 控制了 x t − 1 x_{t-1} xt−1 对 x t x_t xt 的贡献。
- 方差 Σ t ( x t ) = ( 1 − α t ) I \Sigma_t(x_t) = (1 - \alpha_t)\mathbf{I} Σt(xt)=(1−αt)I:
- 在生成 x t x_t xt 时,添加了服从零均值和 ( 1 − α t ) (1-\alpha_t) (1−αt) 方差的高斯噪声。
- 当 α t → 1 \alpha_t \to 1 αt→1 时,噪声趋于 0, x t x_t xt 几乎等于 x t − 1 x_{t-1} xt−1。
- 当 α t → 0 \alpha_t \to 0 αt→0 时,噪声占主导, x t x_t xt 接近标准高斯噪声。
2. 参数化的数学意义
2.1 保方差的意义
- 编码器被设计为 保方差(variance-preserving),确保潜变量在每一层中具有相似的尺度。
- 具体表现为:假设 x t − 1 x_{t-1} xt−1 的方差为 1,则编码器的输出 x t x_t xt 的方差为: Var ( x t ) = α t Var ( x t − 1 ) + ( 1 − α t ) . \text{Var}(x_t) = \alpha_t \text{Var}(x_{t-1}) + (1 - \alpha_t). Var(xt)=αtVar(xt−1)+(1−αt).
- 如果 Var ( x t − 1 ) = 1 \text{Var}(x_{t-1}) = 1 Var(xt−1)=1,则: Var ( x t ) = α t ⋅ 1 + ( 1 − α t ) = 1. \text{Var}(x_t) = \alpha_t \cdot 1 + (1 - \alpha_t) = 1. Var(xt)=αt⋅1+(1−αt)=1.
- 结果:潜变量在每一层中保持相似的尺度,不会因为多层次的变换而导致方差的爆炸或消失。
Var ( X ) = E [ ( X − E [ X ] ) 2 ] , \text{Var}(X) = \mathbb{E}[(X - \mathbb{E}[X])^2], Var(X)=E[(X−E[X])2],
2.2 灵活性和适应性
- 系数 α t \alpha_t αt 的形式:
- 可以预定义(固定的时间步函数,例如线性衰减)。
- 可以学习(通过训练优化)。
- 灵活性:允许模型调整每一层的缩放和噪声,以适应不同层次的生成需求。
3. 编码器公式的推导
3.1 高斯分布的基本定义 高斯分布的概率密度函数为: N ( x ; μ , Σ ) = 1 ( 2 π ) d ∣ Σ ∣ exp ( − 1 2 ( x − μ ) T Σ − 1 ( x − μ ) ) , \mathcal{N}(x; \mu, \Sigma) = \frac{1}{\sqrt{(2\pi)^d |\Sigma|}} \exp\left(-\frac{1}{2}(x - \mu)^T\Sigma^{-1}(x - \mu)\right), N(x;μ,Σ)=(2π)d∣Σ∣1exp(−21(x−μ)TΣ−1(x−μ)), 其中:
- μ \mu μ 是均值, Σ \Sigma Σ 是协方差矩阵。
- 均值控制分布的中心,协方差矩阵控制分布的形状和范围。
3.2 编码器的具体表达 将高斯分布的均值和方差代入公式: q ( x t ∣ x t − 1 ) = N ( x t ; α t x t − 1 , ( 1 − α t ) I ) , q(x_t|x_{t-1}) = \mathcal{N}(x_t; \sqrt{\alpha_t}x_{t-1}, (1 - \alpha_t)\mathbf{I}), q(xt∣xt−1)=N(xt;αtxt−1,(1−αt)I),
可以展开为: q ( x t ∣ x t − 1 ) = 1 ( 2 π ) d ( 1 − α t ) d exp ( − 1 2 ( 1 − α t ) ∥ x t − α t x t − 1 ∥ 2 ) . q(x_t|x_{t-1}) = \frac{1}{\sqrt{(2\pi)^d (1-\alpha_t)^d}} \exp\left(-\frac{1}{2(1-\alpha_t)}\|x_t - \sqrt{\alpha_t}x_{t-1}\|^2\right). q(xt∣xt−1)=(2π)d(1−αt)d1exp(−2(1−αt)1∥xt−αtxt−1∥2).
- 均值项: α t x t − 1 \sqrt{\alpha_t}x_{t-1} αtxt−1 确保 x t x_t xt 的中心围绕 x t − 1 x_{t-1} xt−1。
- 噪声项: ( 1 − α t ) (1-\alpha_t) (1−αt) 控制噪声的强度。
4. 举例:图像生成中的扩散过程
4.1 数据维度匹配
- 假设数据:MNIST 手写数字图像(28x28 灰度图像)。
- 潜变量:扩散过程中,每一步的潜变量 x t x_t xt 也是 28x28 的矩阵。
4.2 编码过程 从数据开始,逐步加噪生成潜变量 x t x_t xt:
- 初始化: x 0 = 原始图像 x_0 = \text{原始图像} x0=原始图像。
- 每一步 t t t: x t = α t x t − 1 + 1 − α t ϵ , ϵ ∼ N ( 0 , I ) . x_t = \sqrt{\alpha_t}x_{t-1} + \sqrt{1-\alpha_t}\epsilon, \quad \epsilon \sim \mathcal{N}(0, \mathbf{I}). xt=αtxt−1+1−αtϵ,ϵ∼N(0,I).
- 时间步 T T T: x T x_T xT 几乎是纯噪声。
4.3 保方差的作用 在每一步中,通过控制 α t \alpha_t αt,确保加噪后的潜变量保持与原始数据相似的尺度,从而避免数据消失或过大。
4.4 去噪过程
- 从高斯噪声开始: x T ∼ N ( 0 , I ) x_T \sim \mathcal{N}(0, \mathbf{I}) xT∼N(0,I)。
- 逆扩散:逐步去噪得到 x 0 x_0 x0,即重建的图像。
根据第三个假设,我们知道 α t \alpha_t αt随着时间的推移按照一个固定或可学习的计划演变,其结构设计使得最终潜变量的分布 p ( x T ) p(x_T) p(xT)为标准高斯分布。然后,我们可以更新马尔可夫HVAE的联合分布(公式23),以写出VDM(Variational Diffusion Models)的联合分布:
p ( x 0 : T ) = p ( x T ) ∏ t = 1 T p θ ( x t − 1 ∣ x t ) (32) p(x_{0:T}) = p(x_T) \prod_{t=1}^T p_{\theta}(x_{t-1}|x_t) \tag{32} p(x0:T)=p(xT)t=1∏Tpθ(xt−1∣xt)(32)
其中,
p ( x T ) = N ( x T ; 0 , I ) (33) p(x_T) = \mathcal{N}(x_T; 0, \mathbf{I}) \tag{33} p(xT)=N(xT;0,I)(33)
总体而言,这组假设描述的是对图像输入的逐步噪声化过程;我们逐步通过添加高斯噪声来破坏图像,直到最终它完全变得与纯高斯噪声相同。从视觉上看,这一过程如图 3 所示。
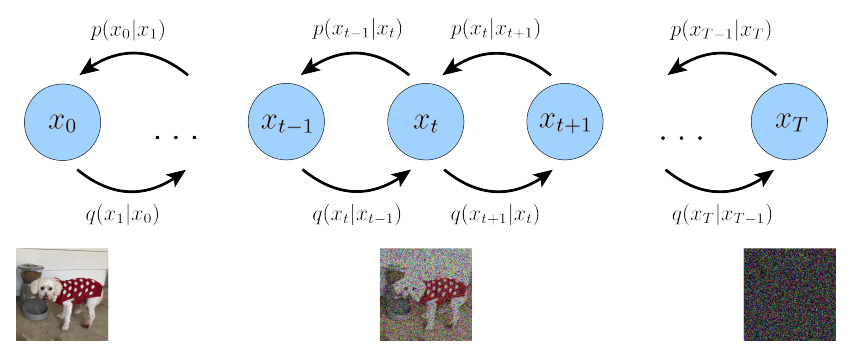
请注意,我们的编码器分布 q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q(xt∣xt−1)不再由 ϕ \phi ϕ参数化,因为它们在每个时间步完全被建模为具有定义均值和方差参数的高斯分布。因此,在VDM中,我们只需要学习条件分布 p θ ( x t − 1 ∣ x t ) p_{\theta}(x_{t-1}|x_t) pθ(xt−1∣xt),以便能够模拟新数据。
在优化完成VDM之后,采样过程非常简单,只需从 p ( x T ) p(x_T) p(xT)中采样高斯噪声,并通过迭代运行去噪转换 p θ ( x t − 1 ∣ x t ) p_{\theta}(x_{t-1}|x_t) pθ(xt−1∣xt) T T T步即可生成一个新的 x 0 x_0 x0。
与任何HVAE一样,VDM可以通过最大化ELBO来优化,其ELBO可以推导为:
log p ( x ) = log ∫ p ( x 0 : T ) d x 1 : T (34) = log ∫ p ( x 0 : T ) q ( x 1 : T ∣ x 0 ) q ( x 1 : T ∣ x 0 ) d x 1 : T (35) = log E q ( x 1 : T ∣ x 0 ) [ p ( x 0 : T ) q ( x 1 : T ∣ x 0 ) ] (36) ≥ E q ( x 1 : T ∣ x 0 ) [ log p ( x 0 : T ) q ( x 1 : T ∣ x 0 ) ] (37) = E q ( x 1 : T ∣ x 0 ) [ log p ( x T ) ∏ t = 1 T p θ ( x t − 1 ∣ x t ) ∏ t = 1 T q ( x 1 ∣ x t − 1 ) ] (38) = E q ( x 1 : T ∣ x 0 ) [ log p ( x T ) p θ ( x 0 ∣ x 1 ) ∏ t = 2 T p θ ( x t − 1 ∣ x t ) q ( x T ∣ x T − 1 ) ∏ t = 1 T − 1 q ( x t ∣ x t − 1 ) ] (39) = E q ( x 1 : T ∣ x 0 ) [ log p ( x T ) p θ ( x 0 ∣ x 1 ) ∏ t = 1 T − 1 p θ ( x t ∣ x t + 1 ) q ( x T ∣ x T − 1 ) ∏ t = 1 T − 1 q ( x t ∣ x t − 1 ) ] (40) = E q ( x 1 : T ∣ x 0 ) [ log p ( x T ) p θ ( x 0 ∣ x 1 ) q ( x T ∣ x T − 1 ) ] + E q ( x 1 : T ∣ x 0 ) [ log ∏ t = 1 T − 1 p θ ( x t ∣ x t + 1 ) q ( x t ∣ x t − 1 ) ] (41) = E q ( x 1 : T ∣ x 0 ) [ log p θ ( x 0 ∣ x 1 ) ] + E q ( x 1 : T ∣ x 0 ) [ log p ( x T ) q ( x T ∣ x T − 1 ) ] + E q ( x 1 : T ∣ x 0 ) [ ∑ t = 1 T − 1 log p θ ( x t ∣ x t + 1 ) q ( x t ∣ x t − 1 ) ] (42) = E q ( x 1 : T ∣ x 0 ) [ log p θ ( x 0 ∣ x 1 ) ] + E q ( x 1 : T ∣ x 0 ) [ log p ( x T ) q ( x T ∣ x T − 1 ) ] + ∑ t = 1 T − 1 E q ( x 1 : T ∣ x 0 ) [ log p θ ( x t ∣ x t + 1 ) q ( x t ∣ x t − 1 ) ] (43) = E q ( x 1 ∣ x 0 ) [ log p θ ( x 0 ∣ x 1 ) ] + E q ( x T − 1 , x T ∣ x 0 ) [ log p ( x T ) q ( x T ∣ x T − 1 ) ] + ∑ t = 1 T − 1 E q ( x t − 1 , x t , x t + 1 ∣ x 0 ) [ log p θ ( x t ∣ x t + 1 ) q ( x t ∣ x t − 1 ) ] (44) = E q ( x 1 ∣ x 0 ) [ log p θ ( x 0 ∣ x 1 ) ] ⏟ reconstruction term − E q ( x T − 1 ∣ x 0 ) [ D K L ( q ( x T ∣ x T − 1 ) ∥ p ( x T ) ) ] ⏟ prior matching term − ∑ t = 1 T − 1 E q ( x t − 1 , x t + 1 ∣ x 0 ) [ D K L ( q ( x t ∣ x t − 1 ) ∥ p θ ( x t ∣ x t + 1 ) ) ] ⏟ consistency term (45) \begin{aligned} \log p(x) &= \log \int p(x_{0:T}) dx_{1:T} &\text{(34)} \\ &= \log \int \frac{p(x_{0:T}) q(x_{1:T}|x_0)}{q(x_{1:T}|x_0)} dx_{1:T} &\text{(35)} \\ &= \log \mathbb{E}_{q(x_{1:T}|x_0)} \left[ \frac{p(x_{0:T})}{q(x_{1:T}|x_0)} \right] &\text{(36)} \\ &\geq \mathbb{E}_{q(x_{1:T}|x_0)} \left[ \log \frac{p(x_{0:T})}{q(x_{1:T}|x_0)} \right] &\text{(37)} \\ &= \mathbb{E}_{q(x_{1:T}|x_0)} \left[ \log \frac{p(x_T)\prod_{t=1}^T p_{\theta}(x_{t-1}|x_t)}{\prod_{t=1}^Tq(x_{1}|x_{t-1})} \right] &\text{(38)} \\ &= \mathbb{E}_{q(x_{1:T}|x_0)} \left[ \log \frac{p(x_T)p_{\theta}(x_0|x_1) \prod_{t=2}^T p_{\theta}(x_{t-1}|x_t)}{q(x_T|x_{T-1}) \prod_{t=1}^{T-1} q(x_t|x_{t-1})} \right]&\text{(39)} \\ &= \mathbb{E}_{q(x_{1:T}|x_0)} \left[ \log \frac{p(x_T)p_{\theta}(x_0|x_1) \prod_{t=1}^{T-1} p_{\theta}(x_t|x_{t+1})}{q(x_T|x_{T-1}) \prod_{t=1}^{T-1} q(x_t|x_{t-1})} \right]&\text{(40)} \\ &= \mathbb{E}_{q(x_{1:T}|x_0)} \left[\log \frac{p(x_T)p_{\theta}(x_0|x_1)}{q(x_T|x_{T-1})} \right] + \mathbb{E}_{q(x_{1:T}|x_0)} \left[ \log \prod_{t=1}^{T-1} \frac{p_{\theta}(x_t|x_{t+1})}{q(x_t|x_{t-1})}\right] &\text{(41)} \\ &= \mathbb{E}_{q(x_{1:T}|x_0)} \left[ \log p_{\theta}(x_0|x_1) \right] + \mathbb{E}_{q(x_{1:T}|x_0)} \left[ \log \frac{p(x_T)}{q(x_{T}|x_{T-1})} \right] + \mathbb{E}_{q(x_{1:T}|x_0)} \left[ \sum_{t=1}^{T-1} \log \frac{p_{\theta}(x_t|x_{t+1})}{q(x_t|x_{t-1})} \right] &\text{(42)} \\ &= \mathbb{E}_{q(x_{1:T}|x_0)} \left[ \log p_{\theta}(x_0|x_1) \right] +\mathbb{E}_{q(x_{1:T}|x_0)} \left[ \log \frac{p(x_T)}{q(x_T|x_{T-1})} \right] + \sum_{t=1}^{T-1} \mathbb{E}_{q(x_{1:T}|x_0)} \left[ \log \frac{p_{\theta}(x_t|x_{t+1})}{q(x_t|x_{t-1})} \right]&\text{(43)} \\ &= \mathbb{E}_{q(x_{1}|x_0)} \left[ \log p_{\theta}(x_0|x_1) \right] +\mathbb{E}_{q(x_{T-1}, x_T | x_0)} \left[ \log \frac{p(x_T)}{q(x_T | x_{T-1})} \right] +\sum_{t=1}^{T-1} \mathbb{E}_{q(x_{t-1}, x_t, x_{t+1} | x_0)} \left[ \log \frac{p_{\theta}(x_t | x_{t+1})}{q(x_t | x_{t-1})} \right]&\text{(44)} \\ &= \underbrace{\mathbb{E}_{q(x_{1}|x_0)} \left[ \log p_{\theta}(x_0|x_1) \right]}_\text{reconstruction term} - \underbrace{\mathbb{E}_{q(x_{T-1}|x_0)} \left[D_{KL}(q(x_T|x_{T-1}) \| p(x_T)) \right]}_\text{prior matching term} - \sum_{t=1}^{T-1} \underbrace{\mathbb{E}_{q(x_{t-1}, x_{t+1}|x_0)} \left[ D_{KL}(q(x_t|x_{t-1}) \| p_{\theta}(x_t|x_{t+1})) \right]}_\text{consistency term} &\text{(45)} \end{aligned} logp(x)=log∫p(x0:T)dx1:T=log∫q(x1:T∣x0)p(x0:T)q(x1:T∣x0)dx1:T=logEq(x1:T∣x0)[q(x1:T∣x0)p(x0:T)]≥Eq(x1:T∣x0)[logq(x1:T∣x0)p(x0:T)]=Eq(x1:T∣x0)[log∏t=1Tq(x1∣xt−1)p(xT)∏t=1Tpθ(xt−1∣xt)]=Eq(x1:T∣x0)[logq(xT∣xT−1)∏t=1T−1q(xt∣xt−1)p(xT)pθ(x0∣x1)∏t=2Tpθ(xt−1∣xt)]=Eq(x1:T∣x0)[logq(xT∣xT−1)∏t=1T−1q(xt∣xt−1)p(xT)pθ(x0∣x1)∏t=1T−1pθ(xt∣xt+1)]=Eq(x1:T∣x0)[logq(xT∣xT−1)p(xT)pθ(x0∣x1)]+Eq(x1:T∣x0)[logt=1∏T−1q(xt∣xt−1)pθ(xt∣xt+1)]=Eq(x1:T∣x0)[logpθ(x0∣x1)]+Eq(x1:T∣x0)[logq(xT∣xT−1)p(xT)]+Eq(x1:T∣x0)[t=1∑T−1logq(xt∣xt−1)pθ(xt∣xt+1)]=Eq(x1:T∣x0)[logpθ(x0∣x1)]+Eq(x1:T∣x0)[logq(xT∣xT−1)p(xT)]+t=1∑T−1Eq(x1:T∣x0)[logq(xt∣xt−1)pθ(xt∣xt+1)]=Eq(x1∣x0)[logpθ(x0∣x1)]+Eq(xT−1,xT∣x0)[logq(xT∣xT−1)p(xT)]+t=1∑T−1Eq(xt−1,xt,xt+1∣x0)[logq(xt∣xt−1)pθ(xt∣xt+1)]=reconstruction term Eq(x1∣x0)[logpθ(x0∣x1)]−prior matching term Eq(xT−1∣x0)[DKL(q(xT∣xT−1)∥p(xT))]−t=1∑T−1consistency term Eq(xt−1,xt+1∣x0)[DKL(q(xt∣xt−1)∥pθ(xt∣xt+1))](34)(35)(36)(37)(38)(39)(40)(41)(42)(43)(44)(45)
推导出的ELBO形式可以根据其各个组成部分进行解释:
-
E q ( x 1 ∣ x 0 ) [ log p θ ( x 0 ∣ x 1 ) ] \mathbb{E}_{q(x_1|x_0)}[\log p_{\theta}(x_0|x_1)] Eq(x1∣x0)[logpθ(x0∣x1)]可以被解释为一个重构项,用于预测在给定第一步潜变量的情况下原始数据样本的对数概率。该项也出现在普通的VAE中,并可以采用类似的方式进行训练。
-
E q ( x T − 1 ∣ x 0 ) [ D K L ( q ( x T ∣ x T − 1 ) ∥ p ( x T ) ) ] \mathbb{E}_{q(x_{T-1}|x_0)}[D_{KL}(q(x_T|x_{T-1}) \| p(x_T))] Eq(xT−1∣x0)[DKL(q(xT∣xT−1)∥p(xT))]是一个先验匹配项;当最终的潜变量分布与高斯先验匹配时,该项被最小化。由于该项没有可训练参数,因此不需要优化;此外,我们假设 T T T足够大,以使最终分布是高斯分布,因此该项实际上为零。
-
E q ( x t − 1 , x t + 1 ∣ x 0 ) [ D K L ( q ( x t ∣ x t − 1 ) ∥ p θ ( x t ∣ x t + 1 ) ) ] \mathbb{E}_{q(x_{t-1}, x_{t+1}|x_0)}[D_{KL}(q(x_t|x_{t-1}) \| p_{\theta}(x_t|x_{t+1}))] Eq(xt−1,xt+1∣x0)[DKL(q(xt∣xt−1)∥pθ(xt∣xt+1))]是一个一致性项;它旨在使 x t x_t xt的分布在前向和后向过程中保持一致。也就是说,从更噪声的图像进行去噪步骤应该与从更干净的图像进行加噪步骤相匹配,这对于每个中间时间步都成立;这一点在数学上通过KL散度体现。当我们训练 p θ ( x t ∣ x t + 1 ) p_{\theta}(x_t|x_{t+1}) pθ(xt∣xt+1)去匹配高斯分布 q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q(xt∣xt−1)时,该项被最小化,而 q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q(xt∣xt−1)在公式 (31) 中定义。
(37) → \rightarrow → (38)
log p ( x ) ≥ E q ( x 1 : T ∣ x 0 ) [ log p ( x 0 : T ) q ( x 1 : T ∣ x 0 ) ] . (37) \log p(x) \geq \mathbb{E}_{q(x_{1:T}|x_0)} \left[ \log \frac{p(x_{0:T})}{q(x_{1:T}|x_0)} \right]. \tag{37} logp(x)≥Eq(x1:T∣x0)[logq(x1:T∣x0)p(x0:T)].(37)
联合分布 p ( x 0 : T ) p(x_{0:T}) p(x0:T) 和辅助分布 q ( x 1 : T ∣ x 0 ) q(x_{1:T}|x_0) q(x1:T∣x0) 的具体形式为: p ( x 0 : T ) = p ( x T ) ∏ t = 1 T p θ ( x t − 1 ∣ x t ) , q ( x 1 : T ∣ x 0 ) = ∏ t = 1 T q ( x t ∣ x t − 1 ) . p(x_{0:T}) = p(x_T) \prod_{t=1}^T p_\theta(x_{t-1}|x_t), \quad q(x_{1:T}|x_0) = \prod_{t=1}^T q(x_t|x_{t-1}). p(x0:T)=p(xT)t=1∏Tpθ(xt−1∣xt),q(x1:T∣x0)=t=1∏Tq(xt∣xt−1). 将其代入 ELBO: E q ( x 1 : T ∣ x 0 ) [ log p ( x T ) ∏ t = 1 T p θ ( x t − 1 ∣ x t ) ∏ t = 1 T q ( x t ∣ x t − 1 ) ] . (38) \mathbb{E}_{q(x_{1:T}|x_0)} \left[ \log \frac{p(x_T) \prod_{t=1}^T p_\theta(x_{t-1}|x_t)}{\prod_{t=1}^T q(x_t|x_{t-1})} \right]. \tag{38} Eq(x1:T∣x0)[log∏t=1Tq(xt∣xt−1)p(xT)∏t=1Tpθ(xt−1∣xt)].(38)
(43) → \rightarrow → (44)
在公式推导中,将 x 1 : T x_{1:T} x1:T 的联合分布拆分为多部分后,部分随机变量(如 x 1 x_1 x1、 x T x_T xT)单独提取进行讨论。这种提取是因为:
特定随机变量的影响突出:
- x 1 x_1 x1:与重构项 p θ ( x 0 ∣ x 1 ) p_\theta(x_0|x_1) pθ(x0∣x1) 直接相关,是生成观测数据 x 0 x_0 x0 的关键潜变量。
- x T x_T xT:与先验匹配项相关,是整个扩散过程的终点。
积分的简化:
- 由于 q ( x 1 : T ∣ x 0 ) = q ( x T ∣ x T − 1 ) ∏ t = 1 T − 1 q ( x t ∣ x t − 1 ) q(x_{1:T}|x_0) = q(x_T|x_{T-1}) \prod_{t=1}^{T-1} q(x_t|x_{t-1}) q(x1:T∣x0)=q(xT∣xT−1)∏t=1T−1q(xt∣xt−1),可以利用条件独立性和边缘分布的特性,将积分简化为对特定变量(如 x 1 x_1 x1、 x T x_T xT)的期望形式。
以下是逐步的解释,说明为何可以将 x 1 : T x_{1:T} x1:T 变为 x 1 x_1 x1、 x T x_T xT 等部分。
1. 重构项的推导
在 E q ( x 1 : T ∣ x 0 ) [ log p θ ( x 0 ∣ x 1 ) ] \mathbb{E}_{q(x_{1:T}|x_0)} \left[ \log p_\theta(x_0|x_1) \right] Eq(x1:T∣x0)[logpθ(x0∣x1)] 中:
- x 1 x_1 x1 的原因:
- 重构项只依赖于第一步潜变量 x 1 x_1 x1 和解码器 p θ ( x 0 ∣ x 1 ) p_\theta(x_0|x_1) pθ(x0∣x1)。
- 因此,其他随机变量 x 2 , … , x T x_2, \dots, x_T x2,…,xT 可以直接边缘化:
E q ( x 1 : T ∣ x 0 ) [ log p θ ( x 0 ∣ x 1 ) ] = E q ( x 1 ∣ x 0 ) [ log p θ ( x 0 ∣ x 1 ) ] . \mathbb{E}_{q(x_{1:T}|x_0)} [\log p_\theta(x_0|x_1)] = \mathbb{E}_{q(x_1|x_0)} [\log p_\theta(x_0|x_1)]. Eq(x1:T∣x0)[logpθ(x0∣x1)]=Eq(x1∣x0)[logpθ(x0∣x1)].2. 先验匹配项的推导
在 E q ( x 1 : T ∣ x 0 ) [ log p ( x T ) q ( x T ∣ x T − 1 ) ] \mathbb{E}_{q(x_{1:T}|x_0)} \left[ \log \frac{p(x_T)}{q(x_T|x_{T-1})} \right] Eq(x1:T∣x0)[logq(xT∣xT−1)p(xT)] 中:
- x T x_T xT 的原因:
- 先验匹配项仅涉及最终潜变量 x T x_T xT 和 q ( x T ∣ x T − 1 ) q(x_T|x_{T-1}) q(xT∣xT−1)。
- 其他潜变量 x T − 1 , … , x 1 x_{T-1}, \dots, x_1 xT−1,…,x1 可以边缘化:
E q ( x 1 : T ∣ x 0 ) [ log p ( x T ) q ( x T ∣ x T − 1 ) ] = E q ( x T − 1 , x T ∣ x 0 ) [ log p ( x T ) q ( x T ∣ x T − 1 ) ] . \mathbb{E}_{q(x_{1:T}|x_0)} \left[ \log \frac{p(x_T)}{q(x_T|x_{T-1})} \right] = \mathbb{E}_{q(x_{T-1}, x_T|x_0)} \left[ \log \frac{p(x_T)}{q(x_T|x_{T-1})} \right]. Eq(x1:T∣x0)[logq(xT∣xT−1)p(xT)]=Eq(xT−1,xT∣x0)[logq(xT∣xT−1)p(xT)].
3. 一致性项的推导
在一致性项 ∑ t = 1 T − 1 E q ( x 1 : T ∣ x 0 ) [ log p θ ( x t ∣ x t + 1 ) q ( x t ∣ x t − 1 ) ] \sum_{t=1}^{T-1} \mathbb{E}_{q(x_{1:T}|x_0)} \left[ \log \frac{p_\theta(x_t|x_{t+1})}{q(x_t|x_{t-1})} \right] ∑t=1T−1Eq(x1:T∣x0)[logq(xt∣xt−1)pθ(xt∣xt+1)] 中:
- 为何取 x t − 1 , x t , x t + 1 x_{t-1}, x_t, x_{t+1} xt−1,xt,xt+1:
- 由于条件独立性, q ( x 1 : T ∣ x 0 ) q(x_{1:T}|x_0) q(x1:T∣x0) 可以拆分为:
q ( x 1 : T ∣ x 0 ) = q ( x t ∣ x t − 1 ) q ( x t + 1 ∣ x t ) ∏ other steps . q(x_{1:T}|x_0) = q(x_t|x_{t-1}) q(x_{t+1}|x_t) \prod_{\substack{\text{other steps}}}. q(x1:T∣x0)=q(xt∣xt−1)q(xt+1∣xt)other steps∏.- 只需保留与 t t t 步相关的变量 x t − 1 , x t , x t + 1 x_{t-1}, x_t, x_{t+1} xt−1,xt,xt+1,其他变量边缘化后不影响 KL 散度的计算。
因此一致性项可以写为: ∑ t = 1 T − 1 E q ( x t − 1 , x t , x t + 1 ∣ x 0 ) [ log p θ ( x t ∣ x t + 1 ) q ( x t ∣ x t − 1 ) ] . \sum_{t=1}^{T-1} \mathbb{E}_{q(x_{t-1}, x_t, x_{t+1}|x_0)} \left[ \log \frac{p_\theta(x_t|x_{t+1})}{q(x_t|x_{t-1})} \right]. t=1∑T−1Eq(xt−1,xt,xt+1∣x0)[logq(xt∣xt−1)pθ(xt∣xt+1)].
4. 为什么可以边缘化
条件独立性 在 q ( x 1 : T ∣ x 0 ) q(x_{1:T}|x_0) q(x1:T∣x0) 和 p ( x 0 : T ) p(x_{0:T}) p(x0:T) 中,分布满足马尔可夫性质(只与前一层或者后一层有关系):
- q ( x t ∣ x 1 : t − 1 ) = q ( x t ∣ x t − 1 ) q(x_t|x_{1:t-1}) = q(x_t|x_{t-1}) q(xt∣x1:t−1)=q(xt∣xt−1)。
- p ( x t − 1 ∣ x t : T ) = p ( x t − 1 ∣ x t ) p(x_{t-1}|x_{t:T}) = p(x_{t-1}|x_t) p(xt−1∣xt:T)=p(xt−1∣xt)。
边缘化的作用
- 重构项只依赖 x 1 x_1 x1,将其他变量边缘化简化了计算。
- 先验匹配项只依赖 x T x_T xT,中间变量被边缘化。
- 一致性项涉及 x t − 1 , x t , x t + 1 x_{t-1}, x_t, x_{t+1} xt−1,xt,xt+1,仅保留相关变量。
总结
边缘化简化公式:
- 重构项:保留 x 1 x_1 x1,边缘化其他变量。
- 先验匹配项:保留 x T x_T xT,边缘化其他变量。
- 一致性项:保留 x t − 1 , x t , x t + 1 x_{t-1}, x_t, x_{t+1} xt−1,xt,xt+1,边缘化其他变量。
条件独立性支持边缘化:
- VDM 的马尔可夫性质确保分布依赖关系简单,可以逐步拆解每一步的变量关系。
公式清晰化:
- 边缘化后,公式更直观,便于理解和优化各部分的物理意义。
从视觉上看,这种对ELBO的解释如图4所示。优化VDM的成本主要由第三项主导,因为我们必须对所有时间步 t t t进行优化。
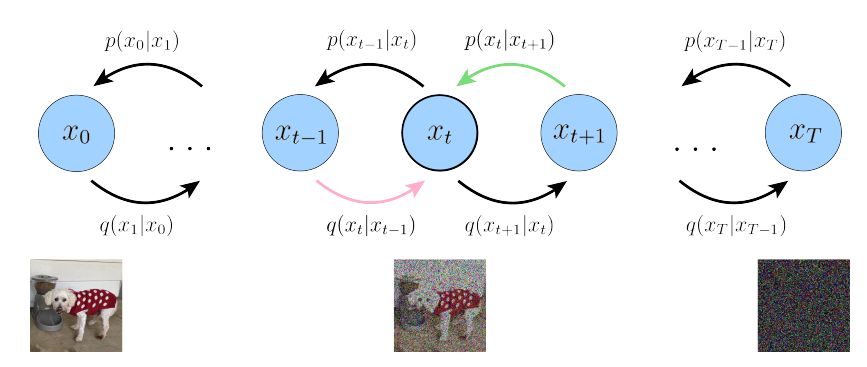
上述图展示了 变分扩散模型(VDM) 中的关键优化目标,即在 加噪过程(前向过程) 和 去噪过程(反向过程) 之间建立一致性。为了帮助您理解所有知识点,我们将逐步分析图中元素及其背后公式,解释为什么要最小化粉色箭头和绿色箭头所代表的分布之间的差异。
1. 图中箭头的含义
- 粉色箭头:表示加噪过程(前向过程)中的条件分布: q ( x t ∣ x t − 1 ) = N ( x t ; α t x t − 1 , ( 1 − α t ) I ) , q(x_t|x_{t-1}) = \mathcal{N}(x_t; \sqrt{\alpha_t}x_{t-1}, (1-\alpha_t)\mathbf{I}), q(xt∣xt−1)=N(xt;αtxt−1,(1−αt)I),
这是前向过程的高斯分布,将潜变量逐步加噪,使其从 x 0 x_0 x0(原始数据)逐步转变为 x T x_T xT(标准高斯噪声)。公式 q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q(xt∣xt−1)描述了潜变量的概率分布,而不是直接生成 x t x_t xt
x t = α t x t − 1 + 1 − α t ϵ , ϵ ∼ N ( 0 , I ) . x_t = \sqrt{\alpha_t}x_{t-1} + \sqrt{1-\alpha_t}\epsilon, \quad \epsilon \sim \mathcal{N}(0, \mathbf{I}). xt=αtxt−1+1−αtϵ,ϵ∼N(0,I).
- α t x t − 1 \sqrt{\alpha_t}x_{t-1} αtxt−1 是均值,表示采样的中心。
- 1 − α t ϵ \sqrt{1-\alpha_t}\epsilon 1−αtϵ 是噪声项,表示引入的随机性。
通过这一采样公式,我们得到了一个具体的 x t x_t xt 值。
绿色箭头:表示去噪过程(反向过程)中的条件分布: p θ ( x t ∣ x t + 1 ) , p_\theta(x_t|x_{t+1}), pθ(xt∣xt+1), 这是反向过程的参数化分布(通常为高斯分布),通过神经网络学习,从 x T x_T xT(高斯噪声)逐步生成更清晰的潜变量,直到重构出 x 0 x_0 x0。
目标:在每个时间步 t t t,最小化这两种分布之间的差异,使得反向过程 p θ ( x t ∣ x t + 1 ) p_\theta(x_t|x_{t+1}) pθ(xt∣xt+1) 能够准确地拟合前向过程 q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q(xt∣xt−1)。
2. 为什么要最小化两者的差异?
2.1 从概率一致性角度
- 核心目标:在去噪(生成)过程中,反向过程 p θ ( x t ∣ x t + 1 ) p_\theta(x_t|x_{t+1}) pθ(xt∣xt+1) 的分布需要与前向过程 q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q(xt∣xt−1) 保持一致。
- 如果 p θ ( x t ∣ x t + 1 ) ≈ q ( x t ∣ x t − 1 ) p_\theta(x_t|x_{t+1}) \approx q(x_t|x_{t-1}) pθ(xt∣xt+1)≈q(xt∣xt−1),则去噪步骤能够精确重现前向加噪的反向过程,从而提高生成图像的质量和逼真度。
2.2 从优化目标角度 回顾 ELBO 的一致性项: ∑ t = 1 T − 1 E q ( x t − 1 , x t + 1 ∣ x 0 ) [ D K L ( q ( x t ∣ x t − 1 ) ∥ p θ ( x t ∣ x t + 1 ) ) ] . \sum_{t=1}^{T-1} \mathbb{E}_{q(x_{t-1}, x_{t+1}|x_0)} \left[ D_{KL}(q(x_t|x_{t-1}) \| p_\theta(x_t|x_{t+1})) \right]. t=1∑T−1Eq(xt−1,xt+1∣x0)[DKL(q(xt∣xt−1)∥pθ(xt∣xt+1))].
- KL 散度项:量化了 q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q(xt∣xt−1) 和 p θ ( x t ∣ x t + 1 ) p_\theta(x_t|x_{t+1}) pθ(xt∣xt+1) 之间的差异。
- 目标:通过最小化 KL 散度,优化反向过程 p θ ( x t ∣ x t + 1 ) p_\theta(x_t|x_{t+1}) pθ(xt∣xt+1) 使其逼近前向过程。
2.3 从生成模型的稳定性角度
- 如果前向和反向过程不匹配,会导致生成过程出现分布偏移,生成的图像可能模糊或失真。
- 保证两者匹配,可以让模型在高斯噪声( x T x_T xT)中采样时生成的 x 0 x_0 x0更清晰、更符合真实数据分布。
3. 如何优化分布的匹配?
3.1 粉色箭头:前向过程的高斯分布
前向过程 q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q(xt∣xt−1) 是预定义的高斯分布: q ( x t ∣ x t − 1 ) = N ( x t ; α t x t − 1 , ( 1 − α t ) I ) , q(x_t|x_{t-1}) = \mathcal{N}(x_t; \sqrt{\alpha_t}x_{t-1}, (1-\alpha_t)\mathbf{I}), q(xt∣xt−1)=N(xt;αtxt−1,(1−αt)I),
- 其中, α t \alpha_t αt 是预定义的噪声系数,确保潜变量逐步加噪。
3.2 绿色箭头:反向过程的参数化分布
反向过程 p θ ( x t ∣ x t + 1 ) p_\theta(x_t|x_{t+1}) pθ(xt∣xt+1) 是通过神经网络参数化的高斯分布: p θ ( x t ∣ x t + 1 ) = N ( x t ; μ θ ( x t + 1 , t ) , σ θ 2 ( t ) ) . p_\theta(x_t|x_{t+1}) = \mathcal{N}(x_t; \mu_\theta(x_{t+1}, t), \sigma_\theta^2(t)). pθ(xt∣xt+1)=N(xt;μθ(xt+1,t),σθ2(t)).
- 均值 μ θ ( x t + 1 , t ) \mu_\theta(x_{t+1}, t) μθ(xt+1,t):由神经网络预测,表示从 x t + 1 x_{t+1} xt+1 去噪得到 x t x_t xt 的期望。
- 方差 σ θ 2 ( t ) \sigma_\theta^2(t) σθ2(t):可以是固定的,也可以通过神经网络预测。
3.3 最小化 KL 散度
通过最小化 KL 散度 D K L ( q ( x t ∣ x t − 1 ) ∥ p θ ( x t ∣ x t + 1 ) ) D_{KL}(q(x_t|x_{t-1}) \| p_\theta(x_t|x_{t+1})) DKL(q(xt∣xt−1)∥pθ(xt∣xt+1)),优化去噪模型 p θ ( x t ∣ x t + 1 ) p_\theta(x_t|x_{t+1}) pθ(xt∣xt+1) 的参数 θ \theta θ。优化目标为: E q ( x t − 1 , x t + 1 ∣ x 0 ) [ D K L ( q ( x t ∣ x t − 1 ) ∥ p θ ( x t ∣ x t + 1 ) ) ] . \mathbb{E}_{q(x_{t-1}, x_{t+1}|x_0)} \left[ D_{KL}(q(x_t|x_{t-1}) \| p_\theta(x_t|x_{t+1})) \right]. Eq(xt−1,xt+1∣x0)[DKL(q(xt∣xt−1)∥pθ(xt∣xt+1))].
- 直观上,这意味着在 q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q(xt∣xt−1) 的样本上,训练去噪模型 p θ ( x t ∣ x t + 1 ) p_\theta(x_t|x_{t+1}) pθ(xt∣xt+1) 精确拟合前向过程的分布。
4. 示例:图像生成任务中的匹配优化
任务
- 数据集:生成手写数字(如 MNIST 数据)。
- 前向过程:从清晰图像( x 0 x_0 x0)逐步加噪 x 1 , x 2 , … , x T x_1, x_2, \dots, x_T x1,x2,…,xT,最终变为高斯噪声 x T ∼ N ( 0 , I ) x_T \sim \mathcal{N}(0, \mathbf{I}) xT∼N(0,I)。
- 反向过程:从 x T x_T xT(噪声)逐步去噪,生成清晰图像。
优化目标 在每个时间步 t t t:
- 加噪:从 q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q(xt∣xt−1) 中采样。
- 去噪:训练 p θ ( x t ∣ x t + 1 ) p_\theta(x_t|x_{t+1}) pθ(xt∣xt+1) 模拟加噪分布 q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q(xt∣xt−1)。
- 损失:通过最小化 KL 散度 D K L ( q ( x t ∣ x t − 1 ) ∥ p θ ( x t ∣ x t + 1 ) ) D_{KL}(q(x_t|x_{t-1}) \| p_\theta(x_t|x_{t+1})) DKL(q(xt∣xt−1)∥pθ(xt∣xt+1)),优化去噪模型的参数 θ \theta θ。
Q:为什么不是优化 p ( x t ∣ x t + 1 ) p(x_t|x_{t+1}) p(xt∣xt+1)和 q ( x t + 1 ∣ x t ) q(x_{t+1}|x_t) q(xt+1∣xt)呢,这两个才是互相对应的关系啊?
A:
1. 核心问题简述
提问的核心是:既然去噪的过程 p θ ( x t ∣ x t + 1 ) p_\theta(x_t|x_{t+1}) pθ(xt∣xt+1) 是从 x t + 1 x_{t+1} xt+1 推导出 x t x_t xt,那么为什么我们不直接优化它和 q ( x t + 1 ∣ x t ) q(x_{t+1}|x_t) q(xt+1∣xt)(加噪过程),而是要去优化它和 q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q(xt∣xt−1)?这个问题的关键在于 生成模型的目标和去噪任务的本质,需要从以下三个方面解释:
- 加噪和去噪的方向性本质。
- 概率分布的对称性问题。
- 从噪声生成数据的需求。
2. 加噪和去噪的方向性
2.1 前向过程(加噪) 前向过程是我们人为设计的,逐步向数据添加噪声,使其变得越来越模糊,最终 x T x_T xT 变成标准高斯分布: q ( x t + 1 ∣ x t ) = N ( x t + 1 ; α t + 1 x t , ( 1 − α t + 1 ) I ) , q(x_{t+1}|x_t) = \mathcal{N}(x_{t+1}; \sqrt{\alpha_{t+1}}x_t, (1-\alpha_{t+1})\mathbf{I}), q(xt+1∣xt)=N(xt+1;αt+1xt,(1−αt+1)I),
- 过程:从干净的数据 x 0 x_0 x0 开始,逐步添加噪声,生成 x 1 , x 2 , … , x T x_1, x_2, \dots, x_T x1,x2,…,xT。
- 本质:这是一个不可逆过程,因为每一步加噪都引入了随机性,导致信息丢失。
2.2 后向过程(去噪) 后向过程的目标是从 x T x_T xT(高斯噪声)一步步还原到 x 0 x_0 x0(原始数据),这需要模型学习以下分布: p θ ( x t ∣ x t + 1 ) , p_\theta(x_t|x_{t+1}), pθ(xt∣xt+1),
- 过程:从 x T x_T xT 开始,通过去噪逐步生成 x T − 1 , x T − 2 , … , x 0 x_{T-1}, x_{T-2}, \dots, x_0 xT−1,xT−2,…,x0。
- 本质:去噪模型需要“逆转”前向过程,但因为前向过程不可逆,这只能通过学习近似的逆分布来完成。
3. 为什么优化 q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q(xt∣xt−1) 而不是 q ( x t + 1 ∣ x t ) q(x_{t+1}|x_t) q(xt+1∣xt)
3.1 前向和后向分布的对应关系 后向过程的去噪分布 p θ ( x t ∣ x t + 1 ) p_\theta(x_t|x_{t+1}) pθ(xt∣xt+1) 并不是直接对应前向加噪分布 q ( x t + 1 ∣ x t ) q(x_{t+1}|x_t) q(xt+1∣xt),而是对应于前向过程的“逆分布” q ( x t ∣ x t + 1 ) q(x_t|x_{t+1}) q(xt∣xt+1)。后向分布可以用贝叶斯公式推导: q ( x t ∣ x t + 1 ) ∝ q ( x t + 1 ∣ x t ) q ( x t ) , q(x_t|x_{t+1}) \propto q(x_{t+1}|x_t) q(x_t), q(xt∣xt+1)∝q(xt+1∣xt)q(xt),
- 解释:
- q ( x t + 1 ∣ x t ) q(x_{t+1}|x_t) q(xt+1∣xt):是加噪过程,描述如何从 x t x_t xt 添加噪声生成 x t + 1 x_{t+1} xt+1。
- q ( x t ) q(x_t) q(xt):是全局分布,描述了时间步 t t t 潜变量的分布。
因此:
- 后向去噪过程 p θ ( x t ∣ x t + 1 ) p_\theta(x_t|x_{t+1}) pθ(xt∣xt+1) 的学习目标是拟合 q ( x t ∣ x t + 1 ) q(x_t|x_{t+1}) q(xt∣xt+1),而不是 q ( x t + 1 ∣ x t ) q(x_{t+1}|x_t) q(xt+1∣xt)。
3.2 优化 p θ ( x t ∣ x t + 1 ) p_\theta(x_t|x_{t+1}) pθ(xt∣xt+1) 和 q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q(xt∣xt−1) 的合理性
前向分布的逆关系:
- 加噪过程的定义是从 x t x_t xt 到 x t + 1 x_{t+1} xt+1,即 q ( x t + 1 ∣ x t ) q(x_{t+1}|x_t) q(xt+1∣xt)。
- 去噪过程需要恢复 x t x_t xt 的信息,其对应的是前向过程的逆分布 q ( x t ∣ x t + 1 ) q(x_t|x_{t+1}) q(xt∣xt+1)。
为什么 q ( x t ∣ x t + 1 ) q(x_t|x_{t+1}) q(xt∣xt+1) 与 q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q(xt∣xt−1) 相关:
- q ( x t ∣ x t + 1 ) q(x_t|x_{t+1}) q(xt∣xt+1) 本质上依赖于前向分布 q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q(xt∣xt−1),因为后者是每一步的生成规则。
- 优化 q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q(xt∣xt−1) 是为了让去噪模型能够逐步还原加噪过程中的丢失信息。
3.3 为什么不是 q ( x t + 1 ∣ x t ) q(x_{t+1}|x_t) q(xt+1∣xt) 优化 p θ ( x t ∣ x t + 1 ) p_\theta(x_t|x_{t+1}) pθ(xt∣xt+1) 和 q ( x t + 1 ∣ x t ) q(x_{t+1}|x_t) q(xt+1∣xt) 会导致以下问题:
- 方向性不一致: q ( x t + 1 ∣ x t ) q(x_{t+1}|x_t) q(xt+1∣xt) 是前向分布,而 p θ ( x t ∣ x t + 1 ) p_\theta(x_t|x_{t+1}) pθ(xt∣xt+1) 是后向分布,它们描述的是两个不同的过程。
- 全局信息缺失: q ( x t + 1 ∣ x t ) q(x_{t+1}|x_t) q(xt+1∣xt) 中不包含前向过程的逆信息,也不涉及后向去噪过程中重建数据分布的需求。
4. 直观类比
4.1 前向和后向过程的类比
- 前向过程(加噪):想象你把一张清晰的图片逐步涂上越来越多的噪声,直到它变成一张完全模糊的图片(噪声图像)。
- 后向过程(去噪):现在你需要从这张噪声图像逐步还原到清晰的原始图片。
4.2 如果只优化 q ( x t + 1 ∣ x t ) q(x_{t+1}|x_t) q(xt+1∣xt)
- 这就好比你只关注“如何涂更多的噪声”,而没有学习“如何从噪声中逐步还原图片”。去噪模型没有得到前向过程逆分布的信息,无法正确还原数据。
4.3 优化 q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q(xt∣xt−1)
- 这就好比你学习“如何去掉上一步加的噪声”,并逐步优化去噪过程,使得还原效果更加准确。
5. 数学直观总结
目标 生成模型的目标是从高斯噪声 x T ∼ N ( 0 , I ) x_T \sim \mathcal{N}(0, \mathbf{I}) xT∼N(0,I) 开始,通过去噪模型 p θ ( x t ∣ x t + 1 ) p_\theta(x_t|x_{t+1}) pθ(xt∣xt+1) 逐步生成真实数据 x 0 x_0 x0。
对应关系 去噪分布 p θ ( x t ∣ x t + 1 ) p_\theta(x_t|x_{t+1}) pθ(xt∣xt+1) 的学习目标是拟合前向加噪过程的逆分布 q ( x t ∣ x t + 1 ) q(x_t|x_{t+1}) q(xt∣xt+1),而不是 q ( x t + 1 ∣ x t ) q(x_{t+1}|x_t) q(xt+1∣xt),因为: q ( x t ∣ x t + 1 ) ∝ q ( x t + 1 ∣ x t ) q ( x t ) . q(x_t|x_{t+1}) \propto q(x_{t+1}|x_t) q(x_t). q(xt∣xt+1)∝q(xt+1∣xt)q(xt).
6. 总结:优化目标的选择
去噪过程的核心目标:
- 学习从 x t + 1 x_{t+1} xt+1 还原 x t x_t xt 的分布 p θ ( x t ∣ x t + 1 ) p_\theta(x_t|x_{t+1}) pθ(xt∣xt+1),这需要优化其与 q ( x t ∣ x t + 1 ) q(x_t|x_{t+1}) q(xt∣xt+1) 的差异。
优化 q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q(xt∣xt−1) 的作用:
- q ( x t ∣ x t + 1 ) q(x_t|x_{t+1}) q(xt∣xt+1) 是通过贝叶斯公式定义的,依赖于 q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q(xt∣xt−1)。优化 q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q(xt∣xt−1) 可以保证去噪模型逐步逆转加噪过程。
为什么不是 q ( x t + 1 ∣ x t ) q(x_{t+1}|x_t) q(xt+1∣xt):
- q ( x t + 1 ∣ x t ) q(x_{t+1}|x_t) q(xt+1∣xt) 是加噪分布,无法直接提供去噪需要的逆分布信息。
通过优化 q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q(xt∣xt−1) 和 p θ ( x t ∣ x t + 1 ) p_\theta(x_t|x_{t+1}) pθ(xt∣xt+1),模型能够准确还原加噪过程,实现从高斯噪声到数据分布的逐步生成。
根据此推导,ELBO的所有项都被计算为期望,因此可以使用蒙特卡洛估计进行近似。然而,实际上使用我们刚刚推导出的这些项来优化ELBO可能并非最优;因为一致性项在每个时间步都是对两个随机变量 { x t − 1 , x t + 1 } \{x_{t-1}, x_{t+1}\} {xt−1,xt+1}的期望,因此其蒙特卡洛估计的方差可能比每个时间步仅涉及一个随机变量的项更大。此外,由于一致性项需要对 T − 1 T-1 T−1项求和,对于较大的 T T T值,ELBO的最终估计值可能会有较高的方差。
因此,让我们尝试推导一种形式,其中ELBO的每一项在每个时间步只涉及一个随机变量的期望。关键的见解是,我们可以将编码器的转换 q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q(xt∣xt−1)重写为 q ( x t ∣ x t − 1 , x 0 ) q(x_t|x_{t-1}, x_0) q(xt∣xt−1,x0),其中由于马尔可夫性质,额外的条件项是多余的。然后,根据贝叶斯公式,我们可以将每个转换重写为:
q ( x t ∣ x t − 1 , x 0 ) = q ( x t − 1 ∣ x t , x 0 ) q ( x t ∣ x 0 ) q ( x t − 1 ∣ x 0 ) (46) q(x_t | x_{t-1}, x_0) = \frac{q(x_{t-1} | x_t, x_0) q(x_t | x_0)}{q(x_{t-1} | x_0)} \tag{46} q(xt∣xt−1,x0)=q(xt−1∣x0)q(xt−1∣xt,x0)q(xt∣x0)(46)
1. 背景知识:ELBO 和一致性项的优化问题
在优化 ELBO 时,一致性项的表达式是: ∑ t = 1 T − 1 E q ( x t − 1 , x t + 1 ∣ x 0 ) [ D K L ( q ( x t ∣ x t − 1 ) ∥ p θ ( x t ∣ x t + 1 ) ) ] . \sum_{t=1}^{T-1} \mathbb{E}_{q(x_{t-1}, x_{t+1}|x_0)} \left[ D_{KL}(q(x_t|x_{t-1}) \| p_\theta(x_t|x_{t+1})) \right]. t=1∑T−1Eq(xt−1,xt+1∣x0)[DKL(q(xt∣xt−1)∥pθ(xt∣xt+1))]. 这里,一致性项的优化存在两个主要问题:
期望中涉及两个随机变量 { x t − 1 , x t + 1 } \{x_{t-1}, x_{t+1}\} {xt−1,xt+1}:
- 计算 E q ( x t − 1 , x t + 1 ∣ x 0 ) [ ⋅ ] \mathbb{E}_{q(x_{t-1}, x_{t+1}|x_0)}[\cdot] Eq(xt−1,xt+1∣x0)[⋅] 需要同时采样 x t − 1 x_{t-1} xt−1 和 x t + 1 x_{t+1} xt+1,这会导致估计的方差较高。
- 高方差可能会使优化过程变得不稳定。
对于大 T T T 的累积方差:
- T − 1 T-1 T−1 项的和会累积方差,导致整体的估计值变得不可靠。
解决目标:为了降低蒙特卡洛估计的方差,我们希望找到一种新的形式,使得每一项的期望只涉及一个随机变量,而不是两个随机变量。
2. 马尔可夫性质的应用
在扩散模型中,前向过程是一个马尔可夫过程。这意味着: q ( x t ∣ x t − 1 , x 0 ) = q ( x t ∣ x t − 1 ) , q(x_t|x_{t-1}, x_0) = q(x_t|x_{t-1}), q(xt∣xt−1,x0)=q(xt∣xt−1),
即:给定 x t − 1 x_{t-1} xt−1, x t x_t xt 的分布与 x 0 x_0 x0 无关。因此,额外的条件 x 0 x_0 x0 是多余的。
3. 利用贝叶斯公式重写分布
4. 为什么重写有用?
通过将 q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q(xt∣xt−1) 表示为 q ( x t ∣ x 0 ) q(x_t|x_0) q(xt∣x0) 和 q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1}|x_t, x_0) q(xt−1∣xt,x0) 的形式,我们可以:
减少涉及的随机变量:
- 原始一致性项需要对 x t − 1 x_{t-1} xt−1 和 x t + 1 x_{t+1} xt+1 同时取期望。
- 现在,每一项只涉及单个随机变量 x t x_t xt 或 x t − 1 x_{t-1} xt−1。
降低蒙特卡洛估计的方差:
- 期望中涉及的变量减少,方差更低,优化过程更稳定。
5. 直观解释:公式 (46) 的意义
为了更直观地理解公式 (46),让我们用以下步骤类比:
前向过程:加噪
- 例如,从图像 x 0 x_0 x0 开始,我们通过 q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q(xt∣xt−1) 添加噪声生成 x t x_t xt。
- 在每一步中, x t x_t xt 只与 x t − 1 x_{t-1} xt−1 直接相关。
后向过程:去噪
- 去噪的目标是从 x t + 1 x_{t+1} xt+1 推导出 x t x_t xt,但这个过程可以通过 x 0 x_0 x0(原始数据)提供更多信息来优化。
贝叶斯公式:逆向信息的利用
- q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1}|x_t, x_0) q(xt−1∣xt,x0):表示在知道 x t x_t xt 和 x 0 x_0 x0 后,如何推导出 x t − 1 x_{t-1} xt−1。
- q ( x t ∣ x 0 ) q(x_t|x_0) q(xt∣x0):表示 x t x_t xt 在全局分布中的位置。
通过利用这些信息,我们可以更有效地建模每一步的噪声分布,减少不必要的复杂性。
6. 总结
通过将 q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q(xt∣xt−1) 重新表示为 q ( x t ∣ x 0 ) q(x_t|x_0) q(xt∣x0) 和 q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1}|x_t, x_0) q(xt−1∣xt,x0) 的形式,我们可以:
- 减少随机变量的依赖:
- 从原来需要采样 { x t − 1 , x t + 1 } \{x_{t-1}, x_{t+1}\} {xt−1,xt+1} 的形式,简化为只需采样单个变量 x t x_t xt。
- 降低蒙特卡洛估计的方差:
- 减少了多变量联合采样的不确定性,使优化过程更加高效。
- 利用全局信息 x 0 x_0 x0:
- 通过 x 0 x_0 x0 的条件信息,增强了建模的鲁棒性。
这种重写形式在扩散模型中是降低方差和提高训练稳定性的重要技巧。