星火大模型是科大讯飞推出的一款人工智能语言模型,它采用了华为的昇腾910 AI处理器。这款处理器是一款人工智能处理器,具有强大的计算能力和高效的能耗控制能力。
华为昇腾910 AI处理器采用了创新的Da Vinci架构,这种架构在设计上充分考虑了AI计算的特性和需求。它具有高度的并行性,可以同时处理大量的计算任务,大大提高了计算效率。此外,它还具有优秀的能效比,可以在保证计算性能的同时,有效控制能耗,降低运行成本。
星火大模型利用华为昇腾910 AI处理器的强大计算能力,可以进行深度学习、自然语言处理等多种复杂的AI任务。它的应用领域非常广泛,包括语音识别、语义理解、机器翻译、情感分析等。
今天就带大家体验一把大语言模型的api调用,首先去官网注册账号,并实名认证;认证通过后,我们就可以体验星火大模型的api功能,目前星火大模型有3个版本,分别是1.5、2.0、3.0.我们这次试验的是3.0版本

下面这个控制台会显示token的调用数量,一般情况下
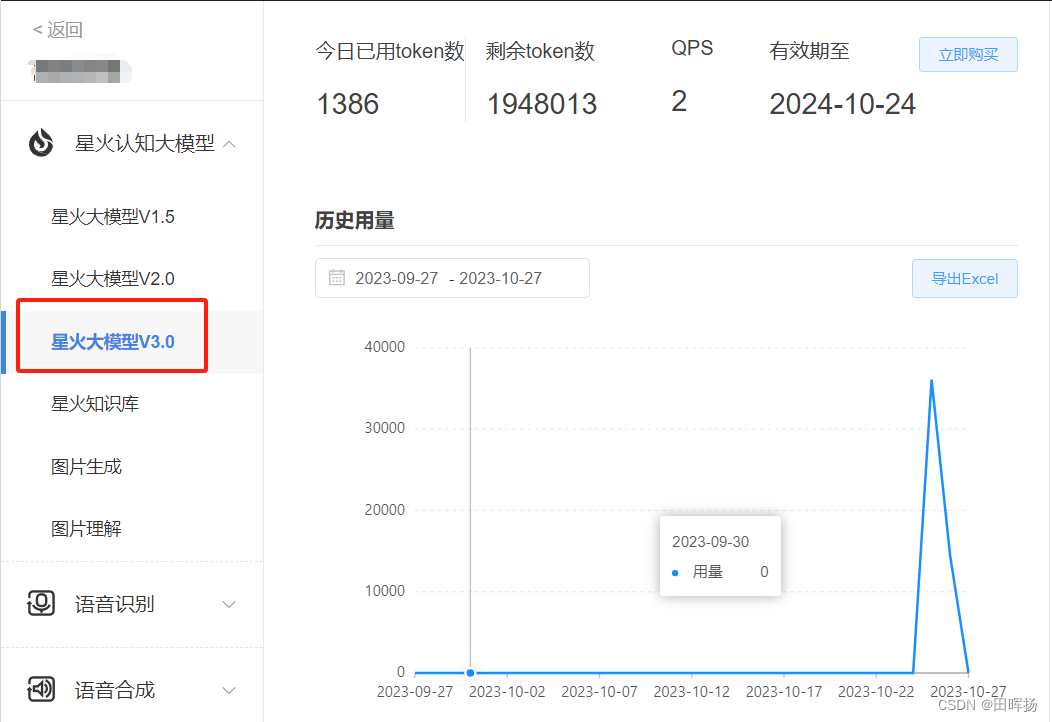
每个版本的模型都会赠送200万的tokens体验,具体的tokens代表的是多少信息量请看下图

然后我们 下载python的调用文档,注意我们这里需要把APPID、APISecret、APIKey拷贝下来
python的调佣文档有两个文件一个是SparkApi.py、test.py;我们只需要略微修改test.py代码即可
import SparkApi
#以下密钥信息从控制台获取
appid = "XXXXXXXX" #填写控制台中获取的 APPID 信息
api_secret = "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX" #填写控制台中获取的 APISecret 信息
api_key ="XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX" #填写控制台中获取的 APIKey 信息
#用于配置大模型版本,默认“general/generalv2”
domain = "general" # v1.5版本
# domain = "generalv2" # v2.0版本
#云端环境的服务地址
Spark_url = "ws://spark-api.xf-yun.com/v1.1/chat" # v1.5环境的地址
# Spark_url = "ws://spark-api.xf-yun.com/v2.1/chat" # v2.0环境的地址
text =[]
# length = 0
def getText(role,content):
jsoncon = {}
jsoncon["role"] = role
jsoncon["content"] = content
text.append(jsoncon)
return text
def getlength(text):
length = 0
for content in text:
temp = content["content"]
leng = len(temp)
length += leng
return length
def checklen(text):
while (getlength(text) > 8000):
del text[0]
return text
if __name__ == '__main__':
text.clear
while(1):
Input = input("\n" +"我:")
question = checklen(getText("user",Input))
SparkApi.answer =""
print("星火:",end = "")
SparkApi.main(appid,api_key,api_secret,Spark_url,domain,question)
getText("assistant",SparkApi.answer)
# print(str(text))
运行text.py文件后,就会有一个对话框了,这个时候我们就可以跟他进行对话了

链接:https://pan.baidu.com/s/1qulEMRgi721IGlkz7t5rHA?pwd=1234
提取码:1234
复制这段内容后打开百度网盘手机App,操作更方便哦