1、Elasticsearch是什么
Elasticsearch简称ES,是一款分布式搜索引擎。它是在Apache Lucene基础之上采用Java语言开发的。
Elasticsearch的官方网站对它的解释是:Elasticsearch是一个分布式、RESTful的搜索和数据分析引擎。
通过上边的官方解释,我们可以看出ES提供两大功能:数据的搜索和分析。
2、Elasticsearch的使用场景
- 在线实时日志分析:从最初的ELK到目前的Elastic Stack,包含了在线日志采集、存储和分析等功能。
- 物联网数据监控
- 文献检索和文献计量
- 商务智能(business intelligence,BI)大屏展示
3、Elastic Stack
对于ES的接入方式来说,除了用自己手写的应用程序去写入ES这种方式以外,我们还以使用官方提供的数据采集工具以及第三方的ETL工具来把数据写入到ES中。
官方早期提供了Logstash来作为接入工具去完成进行数据采集和转换的工作。由于运行时比较消耗资源,官方后续推出了一系列命名包含beat的轻量级数据采集器,统称为Beats,我们可以理解为Beats分包了Logstash的数据采集功能。
我们可以通过Beats将采集到的数据数据先汇集到Logstash中再写入到ES,也可以直接通过Beats将采集到的数据直接写到ES中,如下图:
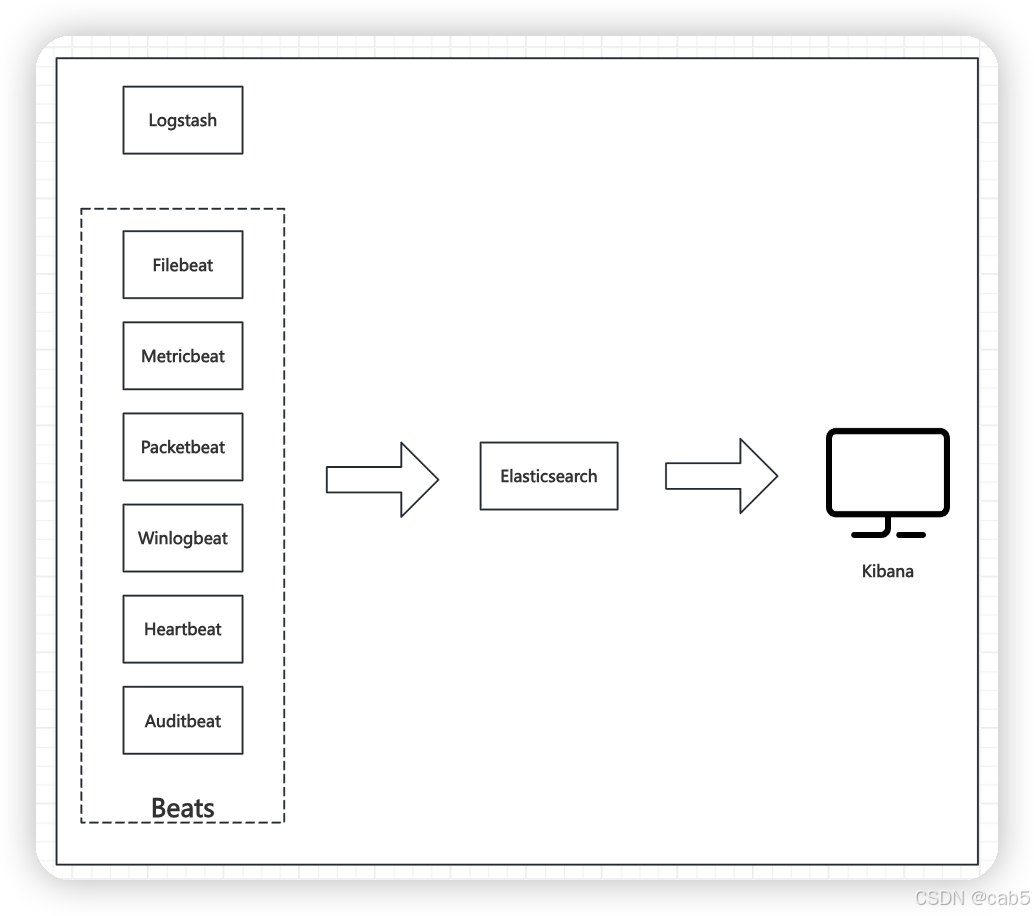
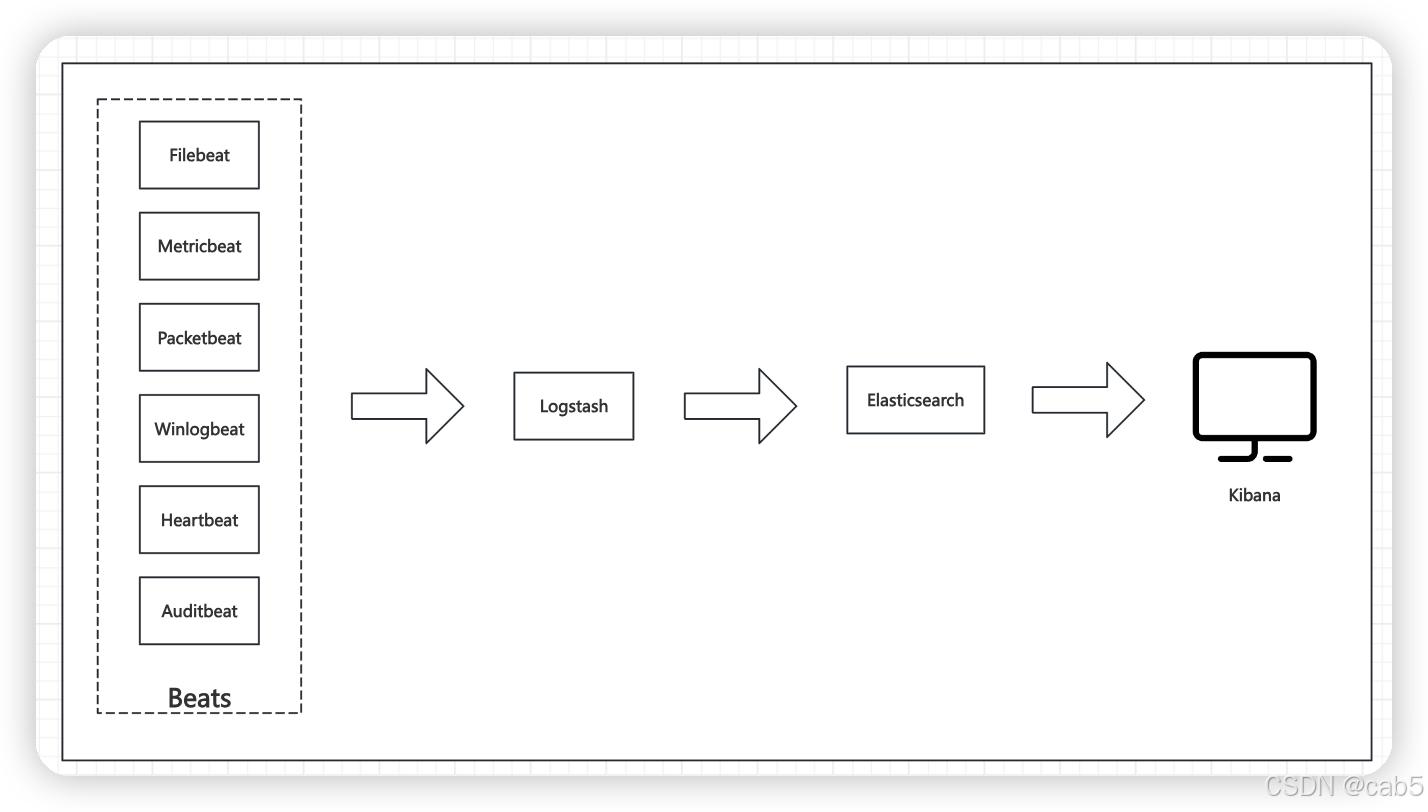
4、专有名词介绍
- 集群(cluster):多个安装Elasticsearch的服务器具有相同的集群名称,则这些服务器组成一个集群,统一对外提供服务。一个集群中有且只有一个主节点,当主节点挂掉了则会选举出一个新的主节点来维持集群的运转。
- 节点(node):一个安装了Elasticsearch的服务机就是一个节点,它是组成集群的基本单元。
- 索引(index):用来存储数据,可以简单的理解为关系型数据库中的表。
- 文档(document):写入索引的基本单元,一个文档就是索引中的一条数据。
- 分片(shard):对于一个索引来说,会有一个主分片和与它对应的零个或多个副本分片。一个分片本质上就是一个Luncene索引。为了保证分片在集群内分布均匀,分片会在集群中进行移动,这个过程就是分片的分配。索引的主分片和副本分片不能位于同一个节点上,我们要保证节点宕机的时候,主分片和副本分片不能同时丢失。
- 主分片(primary shard):负责将文档数据写入索引,同时将数据同步给副本分片。主分片的数量在创建索引的时候就确定了,不允许修改。通常主分片的数量与索引存储数据的数据量成正比。
- 副本分片(replica shard):作为主分片的一个副本,可以承担一部分数据查询的请求(提供搜索的吞吐量),还具有容灾备份的能力,当主分片丢失了(例如:所在节点宕机),副本分片可以被选举为新的主分片来保持数据的完整性。相较于主分片的数量确定后就不可修改,副本分片的数量可以随时修改。
- 分片恢复(shard recovery):将一个分片的数据同步到另外一个分片上的过程,称为分片恢复,这个过程通常伴随着创建和分配。只有等到分片恢复后,副本分片才能对外提供搜索服务。
- 索引缓冲区(index buffer):写入索引的数据会先写入索引缓冲区中,当缓冲区满了的时候,缓冲区中的数据才会被写到磁盘上。
- 传输模块(transport module):当一个节点接收到请求后无法处理或者无法单独处理的时候,会将这个请求转发给其他节点,节点之间相互通讯是通过传输模块来完成的。
- 网关模块 (gateway module):网关模块存储着集群的信息以及每个索引分片的持久化数据。默认使用的是本地网关,它会把数据存储到本地文件系统中。
- 节点发现模块(node discovery module):用于节点之间相互识别,将新的节点加入到集群中。
- 线程池(thread pool):ES内提供了很多用于处理不同操作的线程池,例如:analyze线程池用于处理文本分析的请求,write线程池用于处理索引数据的写入请求,search线程池用于处理搜索请求。
5、配置JVM的堆内存大小
在ES节点上有三个重要的配置文件: elasticsearch.yml用于配置节点的参数、jvm.options用来配置Elasticsearch运行时占用的堆内存大小、log4j2.properties用来配置Elasticsearch运行时的日志参数。
我们通过jvm.options配置文件来设置ES运行时JVM堆内存的大小。如果JVM堆内存设置过小,可能查询时内存不够导致宕机;如果设置过大,又会超过JVM用于压缩对象指针的阈值而导致内存浪费。
设置JVM堆内存大小需要满足以下2个条件
-
堆内存最大不得超过开启压缩对象指针的阈值,一般最大可以是31GB(不同的系统可能有区别)。
-
在堆内存不超过上述阈值的前提下,其大小可以设置为其所在节点内存的一半。
例如,你的服务器有16GB内存,就可以把堆内存大小设置为8GB,但是如果服务器内存为128GB,则通常堆内存最多只能设置为31GB。
默认JVM堆内存的大小为1G。
6、参考文献
- 《Elasticsearch数据搜索与分析实战》——王深湛