文章目录
C语言第四次笔记
一:常用关键字
1:typedef
(1):作用:
用typedef来给类型取新的名字,简化了复杂类型
#include<stdio.h>
//typedef
typedef unsigned int uint;//用typedef来给类型取新的名字,简化了复杂类型
int main()
{
uint num = 0;
uint num1 = 1;
return 0;
}
(2):在结构体中的应用:
可以对结构体使用 typedef 来定义一个新的数据类型名字,然后使用这个新的数据类型来直接定义结构变量
#include<stdio.h>
typedef struct student
{
char ID[16];
char name[16];
char sex;
float score;
}STUDENT;
(3):typedef与define的区别
typedef 仅限于为类型定义符号名称,#define 不仅可以为类型定义别名,也能为数值定义别名,比如您可以定义 1 为 ONE。
typedef 是由编译器执行解释的,#define 语句是由预编译器进行处理的。
2:static
(1):修饰局部变量
在此之前我们先来学一下void:
void 在英文中作为名词的解释为 “空虚、空间、空隙”,而在 C 语言中,void 被翻译为"无类型"
void 的作用当函数不需要返回值值时,必须使用void限定
#include<stdio.h>
//void 在英文中作为名词的解释为 "空虚、空间、空隙",而在 C 语言中,void 被翻译为"无类型"
//void 的作用当函数不需要返回值值时,必须使用void限定,这就是我们所说的第一种情况。例如:void //func(int a,char *b)。
//当函数不允许接受参数时,必须使用void限定,这就是我们所说的第二种情况。例如:int func(void)。
void test()
{
int a = 1;
a++;
printf("%d ",a);
}
int main()
{
int i = 0;
while (i < 10)
{
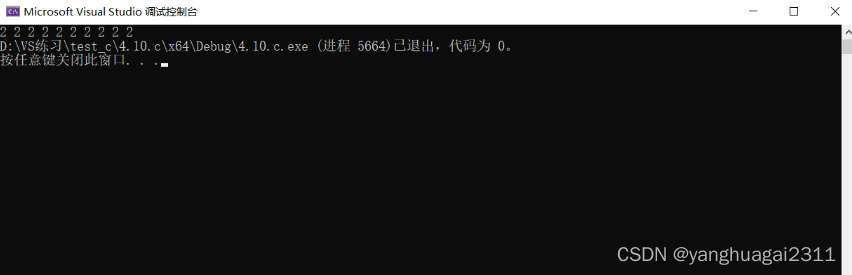
test();//i<10进入到test()中,然后前往void test(),打印出a,因为void无返回值,所以局部变量的生命周期被自动销毁
i++;
}
return 0;
}
由于void无返回值,局部变量被自动销毁
加了static之后:
#include<stdio.h>
//void 在英文中作为名词的解释为 "空虚、空间、空隙",而在 C 语言中,void 被翻译为"无类型"
//void 的作用当函数不需要返回值值时,必须使用void限定,这就是我们所说的第一种情况。例如:void func(int a,char *b)。
//当函数不允许接受参数时,必须使用void限定,这就是我们所说的第二种情况。例如:int func(void)。
void test()
{
static int a = 1;//static修饰后的a并没有被销毁,而是继续进入主函数,第八行的代码使用完后就没意义了
a++;
printf("%d ",a);
}
int main()
{
int i = 0;
while (i < 10)
{
test();//i<10进入到test()中,然后前往void test(),打印出a
i++;
}
return 0;
}
普通的局部变量是放在内存的栈区上的,进入局部范围,变量创建,出了局部范围变量销毁
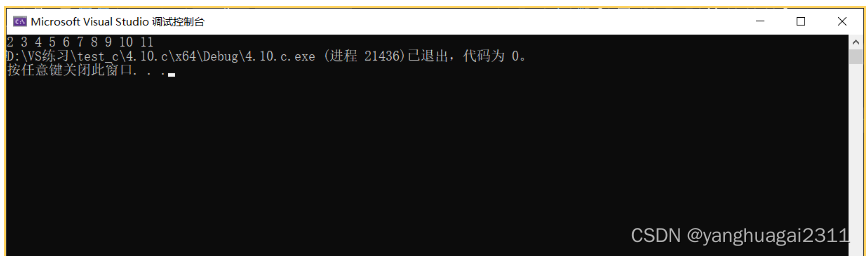
static修饰局部变量的时候,局部变量在静态区开辟空间,局部变量出了作用域,并不销毁。本质上,static修饰局部变量的时候,改变了变量的存储位置,影响了变量的生命周期,使得生命周期变长,和程序生命周期一样,变量存储静态区,变为静态变量。(改变了存储位置,由栈区->静态区,使得变量的生命周期发生了变化。)
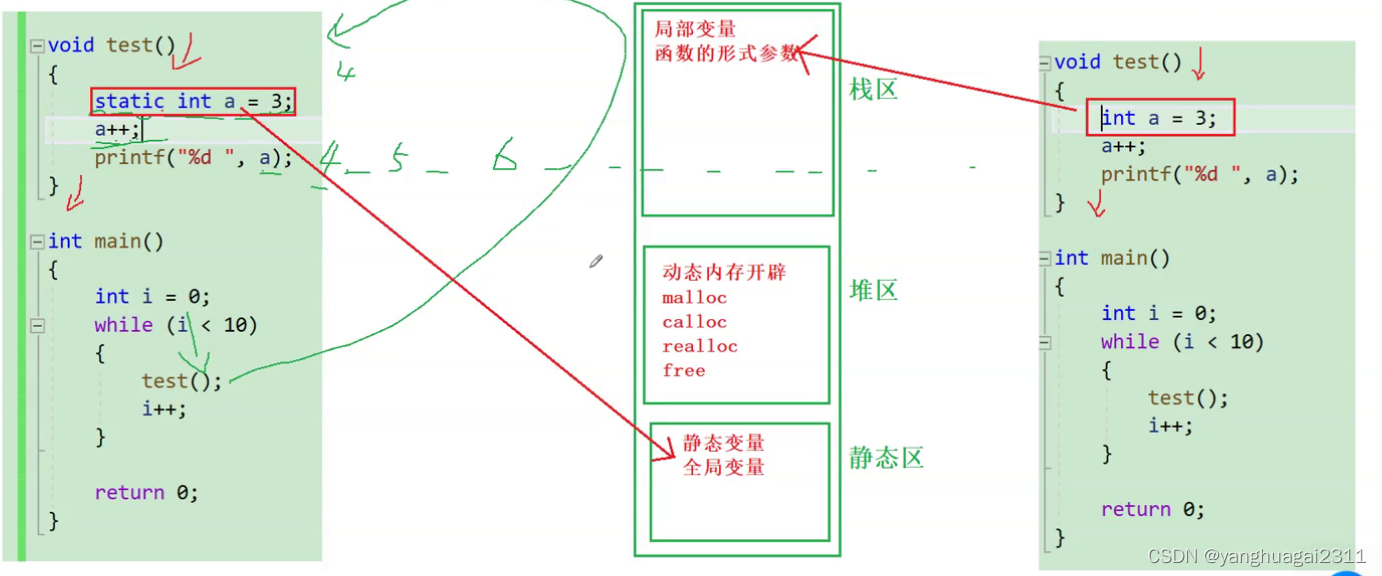
1.1:下面我们来区分一下栈区 堆区和静态区.
静态区(全局区):静态变量和全局变量的存储区域是一起的,一旦静态区的内存被分配, 静态区的内存直到程序全部结束之后才会被释放。
堆区:由程序员调用malloc()函数来主动申请的,需使用free()函数来释放内存,若申请了堆区内存,之后忘记释放内存,很容易造成内存泄漏。
栈区:存放函数内的局部变量,形参和函数返回值。栈区之中的数据的作用范围过了之后,系统就会回收自动管理栈区的内存(分配内存 , 回收内存),不需要开发人员来手动管理。
栈区就像是一家客栈,里面有很多房间,客人来了之后自动分配房间,房间里的客人可以变动,是一种动态的数据变动。
(2):修饰全局变量:
利用extern代码将两个不同的文件连接到一起去
test4.10.1.c
static int a = 10;
test4.10.2.c
#include<stdio.h>
extern int a;
int main()
{
printf("%d ",a);
return 0;
}
//err
此程序报错 a无定义,但是把static去掉,这个代码则是正确的
这是为什么呢?
答:static修饰全局变量的时候,这个全局变量的外部链接属性变成了内部链接属性,其他源文件(.c)就无法再使用这个全局变量了,使用的时候生命周期变短了
(3):修饰函数
同理可知static修饰函数的时候,这个函数本身的外部链接属性变成了内部链接属性,其他源文件(.c)就无法再使用这个全局变量了,使用的时候生命周期变短了.
那么什么是链接呢?
不管我们编写的代码有多么简单,都必须经过「编译 --> 链接」的过程才能生成可执行文件:
编译就是将我们编写的源代码“翻译”成计算机可以识别的二进制格式,它们以目标文件的形式存在;
链接就是一个“打包”的过程,它将所有的目标文件以及系统组件组合成一个可执行文件。
3:register
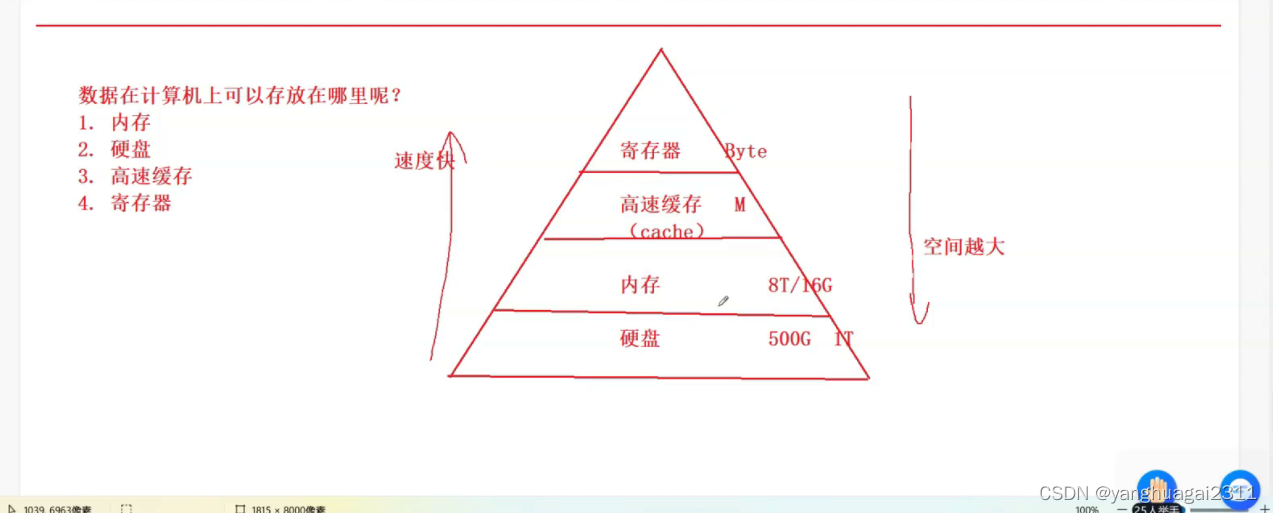
电脑常用的储存设备:寄存器、高速缓存、内存、硬盘
这些设备具有如下关系:
| 寄存器(集成到CPU上) | 越往上读取速度越快 |
|---|---|
| 高速缓存 | 空间越小,造价越高 |
| 内存 | 越往下读取速度越慢 |
| 硬盘 | 空间越大,造价越低 |
在计算机的发展中中,最早期的时候只存在内存的概念,数据主要存放在内存中,运行程序的时候CPU(中央处理器)必须去内存中读取数据来运行程序。
然而随着计算机的发展,CPU处理数据的效率越来越高,然而此时内存的读写速度已经跟不上CPU的处理速度了,这时就出现了高速缓存和寄存器,它们的读写速度更快,可以适应CPU的使用。
就好像垒墙,一个人叠砖头,一个人递砖头,那个垒墙的人速度越来越快,然而那个递砖的却没有加快速度。此时,垒墙的人只能干瞪眼等着砖头,大大降低了工作效率。
然而读写速度越快,设备的造价越高,可容纳的数据容量越小。计算机就选择了这样的运行方式:
数据有限存储在寄存器中,然后存储到高速缓存中,然后储存在内存中,在寄存器中的数据使用完成后,高速缓存的数据会跟进到寄存器中,内存的数据也会跟进到高速缓存中,在这样的数据处理下,大部分的数据都可以在寄存器中获得,这样就跟上了CPU的处理速度。
register后的变量表示建议放到寄存器中,只是建议,真正的放置需要电脑自身的分配。不过现在我们的计算机已经十分先进了,你不写register它也知道哪个该放进寄存器中。
#include<stdio.h>
int main()
{
//寄存器变量
register int num = 3;//3放到寄存器中
return 0;
}
4:#define定义常量和宏
(1):定义常量
#include<stdio.h>
#define NUM 100//此处NUM表示一个常量值为100,为了区别,这个常量名固定为大写
int main()
{
printf("%d\n", NUM);
int n = NUM;
printf("%d\n", n);
int arr[NUM] = { 0 };
return 0;
}
(2):定义宏
#include<stdio.h>
#define ADD(x,y) ((x)+(y))//ADD为宏名,x,y为宏参数,x+y为宏体。
int Add(int x, int y)//注意是Add非ADD
{
return x + y;
}
int main()
{
int a = 10;
int b = 20;
int c = ADD(a, b);//int c =((a)+(b)),将a,b替换到x,y中
printf("%d\n",c);
return 0;
}
二:指针
1:内存
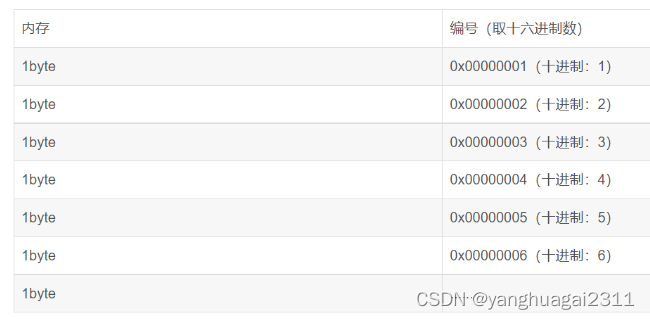
程序的运行需要内存,我们为了有效地使用内存,就需要将内存划分为一个个小的内存单元,每一个单元的大小是一个字节。(一个字节比较合理,这个内存单元太小也不好,太大也不好)为了 能够有效地使用每个内存单元,我们给每一个单元都定了一个编号,这个编号就叫做这个内存单元的地址。
就像在我们的生活中,比如说你在网上购物。你就一定需要告诉商家,你自己的确切位置,比如说xx市xx区xx路xx号(几号楼)几号宿舍。)这个内存的地址也是这个道理,就像楼中的门牌号,通过编号的方式,内存的单元地址也就确定了。我们可以轻松地找到对应的地址,而不需要一个一个去找。
2:地址的生成
我们的电脑中都有硬件电路,用于生成地址的电线叫地址线。当电路中有电路通过时,会产生正负脉冲,从而表示0与1.此处我们以32位电脑为例,它在生成地址时32根地址线同时产生电信号表示1或0,当每一个地址线组合起来时就有了许许多多的不同的排列组合方式。
00000000000000000000000000000000——对应0
00000000000000000000000000000001——对应1
…
1111111111111111111111111111111111111——最终可能会变成32个1
这样的排序方式一共有2^32次方种 内存中一共有这么多byte的空间。
(1024B=1KB 1024KB=1MB 1024MB=1GB) (1byte=8bit)
但是这个数字不是很直观,我们先对它除以1024得到4194304个KB,再除1024得到4096个MB,再除以1024得到4GB,也就是说在早期的三十二位电脑内存中一共有4GB的内存空间。
3:数据的储存
变量是创建内存中的(在内存分配空间的),每个单元都有地址,所以变量也有地址
利用&:
&:取地址操作符,取出谁的地址。
打印地址,%p是以地址的形式打印
#include <stdio.h>
int main()
{
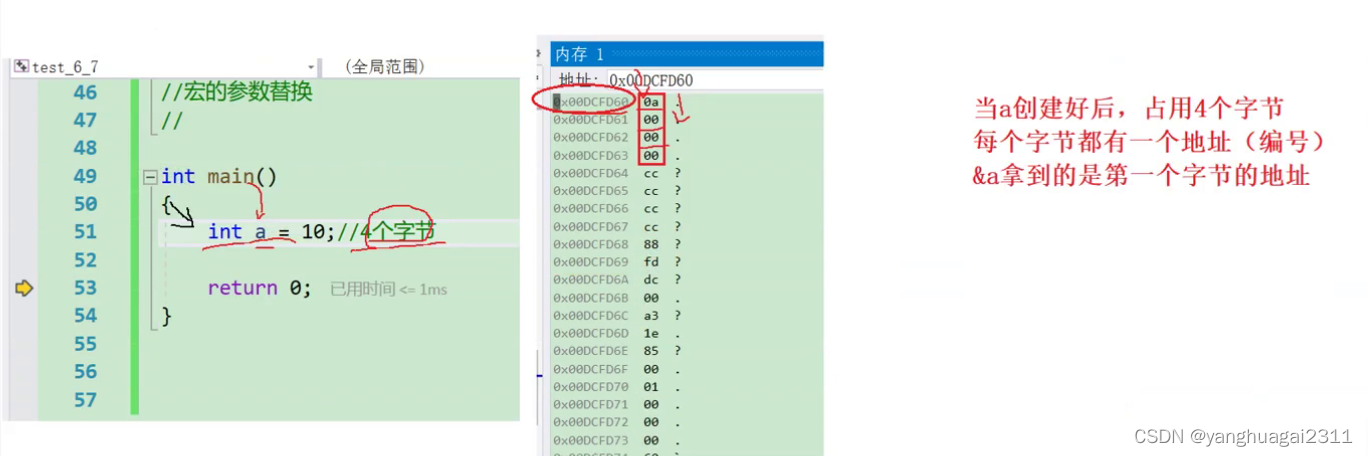
int a = 10;//向内申请4个字节,存储10
&a;//取出a的地址,&为取地址符号
//这里的a共有4个字节,每个字节都有地址,但我们取出的是第一个字节的地址(较小的地址)
printf("%p\n", &a);//打印地址,%p是以地址的形式打印
return 0;
}
打印出来后 通过调试F10 内存 监视窗口得到此图

我们实际上取出的只有0x010FF808这个地址(起始位置的地址)
0a 00 00 00一行显示了四个字节 (设置了四列)
a的值为10,用二进制表示即为:0000 0000 0000 0000 0000 0000 0000 1010(二进制的数字表达最后一位表示2的0次方,倒数第二位就表示2的1次方,以此类推,十就是2的3次方加2的一次方也就是1010),在这个时候我们以每个四位为一组,就可以得到数据的表示方法:00 00 00 0a(在16进制数中,a表示10,b表示11,c表示12,d表示13,e表示14,f表示15)
** 0000 0000 0000 0000 0000 0000 0000 1010
0 0 0 0 0 0 0 a**
其实十进制的储存方式是这样的
0x 00 00 00 0a 倒着存
4:指针变量
#include<stdio.h>
int main()
{
int a = 10;
int* p = &a;
//我们把a这个变量的地址储存在这个变量p中,这个p就叫做指针变量,类型为int*
//变量p是创建出来存放地址(指针)的。
return 0;
}
在内存单元中 编号就是地址 而地址就是指针


对int* p =&a;的理解
1.p代表0x010FF808这个起始位置的地址
2.中间的表示p是个指针变量,注意指针变量是p,而不是p
3.int说明p指向的对象是int类型的(本例子说明p指向的是a)
4.p为指针变量,接受&a的内容,(即应该将地址存到指针变量中去)也就是变量的首地址
5:解引用操作符*
*(解引用操作符/间接操作符):通过地址找到地址所指向的内容。
*p表示对指针变量p解引用(p就是p所指的对象),通过p中存放的地址找到p所指的对象(对应的内容)
#include <stdio.h>
int main()
{
int a = 10;//向内申请4个字节,存储10
&a;//取出a的地址,&为取地址符号
//这里的a共有4个字节,每个字节都有地址,但我们取出的是第一个字节的地址(较小的地址)
//printf("%p\n", &a);//打印地址,%p是以地址的形式打印
int* p = &a;//p指向了a 接受了&a,即接受了a的内容
//*p通过p中存放的地址,找到p指向的空间(对象/变量)
*p = 20;//p指向了a,等价于a=20
printf("%d\n",a);
return 0;
}
6:指针变量的大小
%zu表示打印sizeof
#include <stdio.h>
int main()
{
printf("%zu\n", sizeof(char*));//zu表示打印sizeof
printf("%zu\n", sizeof(short*));
printf("%zu\n", sizeof(int*));
printf("%zu\n",sizeof(float*));
printf("%zu\n", sizeof(double*));
return 0;
}
你可能认为输出结果是:1 2 4 4 8
但实际上是:4\8 4\8 4\8 4\8 4\8 (4或8)
因为:
指针变量储存的是地址,也就是说指针变量的大小取决于存放一个地址需要多大的空间,32位平台下地址是32个bit位(即4个字节),而64位平台下地址是64个bit位(即8个字节),所以指针变量的大小就是4或8.
结论:
32位环境下,地址的序列就由32个1/0组成的二进制序列,要存储进来,需要4个字节。
64位环境下,地址的序列就由64个1/0组成的二进制序列,要存储进来,需要8个字节。
7:如何一口气定义好几个指针变量?
int main()
{
int* p1,p2,p3 = &a;
//这个定义方式是不正确的,只有p1是指针变量而其他两个是整型变量
int* p1,*p2,*p3;
//这个定义方法才是正确的,在第一种方法下,*只给第一个变量使用
return 0;
}
三:结构体
结构体(struct)使C语言有能力描述复杂的类型。其能把单一类型组合在一起
比如描述一个学生,一个学生包含: 名字+年龄+性别+学号。
我们用基本的数据类型没有办法描述这样的复杂对象,这里就只能使用结构体来描述了。
struct Stu//struct表示创建结构体,Stu表示这个数据类型叫struct Stu
{
char name[20];
int age;
char sex[10];
char tele[12];
};
//通过结构体将这些简单数据类型集合来描述一个复杂的对象
struct Stu s = { "zhangsan",18,"male","2022000415" };
//定义一个struct Stu类型的结构体变量s
做个类比 我们盖房子需要图纸
上述代码就是图纸
struct Stu s类似于房子 s这个时候在内存有一个独立的空间存在
#include<stdio.h>
struct Stu//struct表示创建结构体,Stu表示这个数据类型叫struct Stu
{
char name[20];
int age;
char sex[10];
char tele[12];
};
int main()
{
//通过结构体将这些简单数据类型集合来描述一个复杂的对象
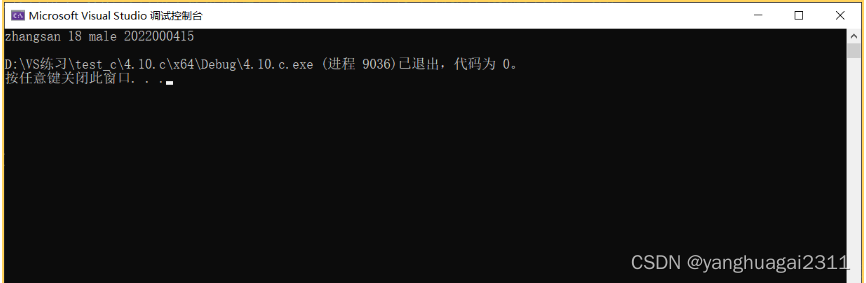
struct Stu s = { "zhangsan", 18, "male", "2022000415" };
//定义一个struct Stu类型的结构体变量s
printf("%s %d %s %s\n", s.name, s.age, s.sex, s.tele);//s.代表从结构体中摘取过来的数据,切记数据之间不可替换顺序
return 0;
}
**s.代表从结构体中摘取过来的数据,切记数据之间不可替换顺序,否则编译器会崩溃,它是有序性的
.操作符 在结构体中的用法——//结构体对象.内部变量名
还有其他的打印方法:
#include<stdio.h>
struct Stu//struct表示创建结构体,Stu表示这个数据类型叫struct Stu
{
char name[20];
int age;
char sex[10];
char tele[12];
};
void print(struct Stu* ps)//将地址存到指针变量中去
{
printf("%s %d %s %s\n", (*ps).name, (*ps).age, (*ps).sex, (*ps).tele);//ps里面存了s的地址
//(*ps)得到了结构体变量s,这个.表示在结构体内部找到变量
//.的用法:结构体对象+内部变量名
//(*ps).name:将ps解引用找到结构体,再找到name变量
printf("%s %d %s %s\n", ps->name, ps->age, ps->sex, ps->tele);
//ps->就表示在指针指向的结构体中找到对应的变量
//->的用法:结构体指针变量+内部变量名
//ps->name:找到指针变量指向的结构体内的name变量
//一般用第二种打印方法 第一种太麻烦了
}
int main()
{
//通过结构体将这些简单数据类型集合来描述一个复杂的对象
struct Stu s1 = { "zhangsan", 18, "male", "2022000415" };
struct Stu s2 = {"lisi", 20, "male", "202200618"};
//定义一个struct Stu类型的结构体变量s
//输入数据到s2中
scanf("%s %d %s %s\n", s2.name, &s2.age, s.sex, s.tele);//结构体数组中不需要输入&(取地址操作符)
//结构体对象.内部变量名(.操作符在结构体中的用法)
printf("%s %d %s %s\n", s.name, s.age, s.sex, s.tele);//s.代表从结构体中摘取过来的数据,切记数据之间不可替换顺序
print(&s2);//print函数,把s2地址取出来给函数
return 0;
}