音乐数据中心平台离线数仓综合项目
第二个业务:机器详细信息统计
需求
- 根据两个业务系统中的数据统计机器基础详细信息,这两个业务系统对应的关系型数据库分别是 ycak 和 ycbk。
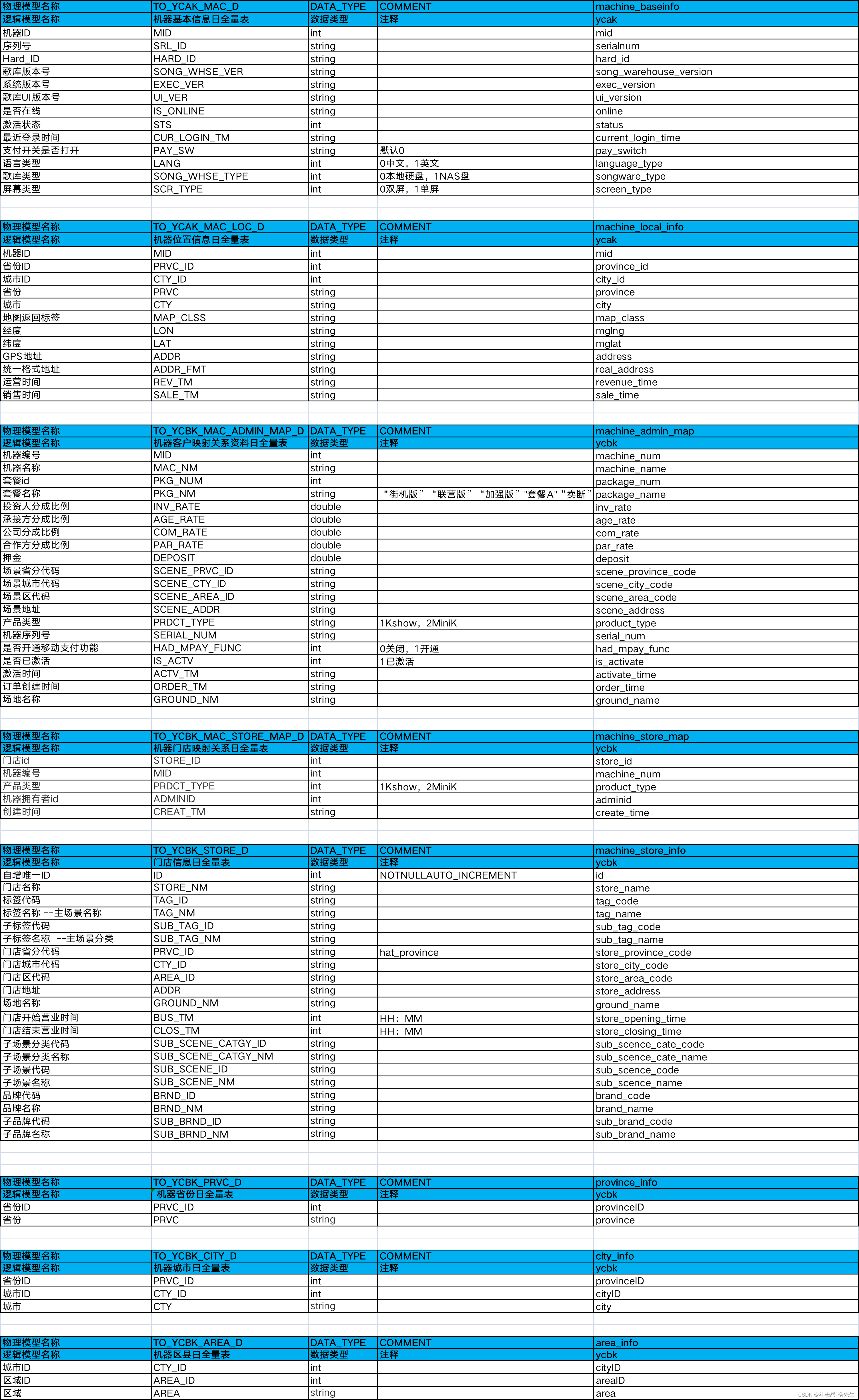
- ycak 库中有两张机器相关的数据库表如下:
- machine_baseinfo:机器基本信息表,记录机器的系统版本、歌库版本、UI版本、最近登录时间等相关信息。
- machine_local_info:机器位置信息日全量表,记录机器所在的省市县及详细地址、运行时间和销售时间等相关信息。
- ycbk 库中有六张表,分别是:
- machine_admin_map:机器客户映射资料表
- machine_store_map:机器门店映射关系表
- machine_store_info:门店信息全量表
- province_info:机器省份日全量表
- city_info:机器城市日全量表
- area_info:机器区县日全量表
注意:所有的机器信息来自于machine_baseinfo机器基本信息表与machine_admin_map机器客户映射资料表。
模型设计
- 完成以上机器详细信息统计,数据是分别存在两个业务系统库中,需要通过ODS将数据从关系型数据库抽取到Hive ODS层。
- 根据需求,针对机器进行分析,在数仓中我们构建“机器”主题,具体数据分层如下:
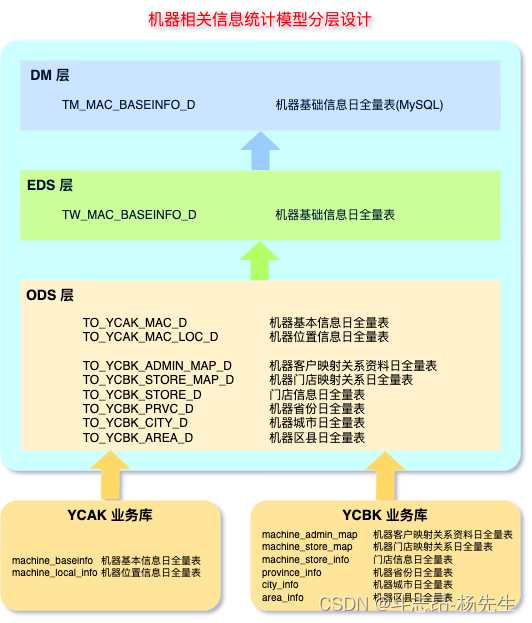
- ODS 层:
- EDS 层:
- 在Hive中创建ODS层对应的表:
USE `music`;
-- 1. TO_YCAK_MAC_D 机器基本信息表
CREATE EXTERNAL TABLE `TO_YCAK_MAC_D` (
`MID` int,
`SRL_ID` string,
`HARD_ID` string,
`SONG_WHSE_VER` string,
`EXEC_VER` string,
`UI_VER` string,
`IS_ONLINE` string,
`STS` int,
`CUR_LOGIN_TM` string,
`PAY_SW` string,
`LANG` int,
`SONG_WHSE_TYPE` int,
`SCR_TYPE` int
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://node01/user/hive/warehouse/music.db/TO_YCAK_MAC_D';
-- 2. TO_YCAK_MAC_LOC_D 机器位置信息表
CREATE EXTERNAL TABLE `TO_YCAK_MAC_LOC_D` (
`MID` int,
`PRVC_ID` int,
`CTY_ID` int,
`PRVC` string,
`CTY` string,
`MAP_CLSS` string,
`LON` string,
`LAT` string,
`ADDR` string,
`ADDR_FMT` string,
`REV_TM` string,
`SALE_TM` string
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://node01/user/hive/warehouse/music.db/TO_YCAK_MAC_LOC_D';
-- 3. TO_YCBK_MAC_ADMIN_MAP_D 机器客户映射资料表
CREATE EXTERNAL TABLE `TO_YCBK_MAC_ADMIN_MAP_D` (
`MID` int,
`MAC_NM` string,
`PKG_NUM` int,
`PKG_NM` string,
`INV_RATE` double,
`AGE_RATE` double,
`COM_RATE` double,
`PAR_RATE` double,
`DEPOSIT` double,
`SCENE_PRVC_ID` string,
`SCENE_CTY_ID` string,
`SCENE_AREA_ID` string,
`SCENE_ADDR` string,
`PRDCT_TYPE` string,
`SERIAL_NUM` string,
`HAD_MPAY_FUNC` int,
`IS_ACTV` int,
`ACTV_TM` string,
`ORDER_TM` string,
`GROUND_NM` string
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://node01/user/hive/warehouse/music.db/TO_YCBK_MAC_ADMIN_MAP_D';
-- 4. TO_YCBK_MAC_STORE_MAP_D 机器门店映射关系表
CREATE EXTERNAL TABLE `TO_YCBK_MAC_STORE_MAP_D` (
`STORE_ID` int,
`MID` int,
`PRDCT_TYPE` int,
`ADMINID` int,
`CREAT_TM` string
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://node01/user/hive/warehouse/music.db/TO_YCBK_MAC_STORE_MAP_D';
-- 5. TO_YCBK_STORE_D 门店信息表
CREATE EXTERNAL TABLE `TO_YCBK_STORE_D` (
`ID` int,
`STORE_NM` string,
`TAG_ID` string,
`TAG_NM` string,
`SUB_TAG_ID` string,
`SUB_TAG_NM` string,
`PRVC_ID` string,
`CTY_ID` string,
`AREA_ID` string,
`ADDR` string,
`GROUND_NM` string,
`BUS_TM` string,
`CLOS_TM` string,
`SUB_SCENE_CATGY_ID` string,
`SUB_SCENE_CATGY_NM` string,
`SUB_SCENE_ID` string,
`SUB_SCENE_NM` string,
`BRND_ID` string,
`BRND_NM` string,
`SUB_BRND_ID` string,
`SUB_BRND_NM` string
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://node01/user/hive/warehouse/music.db/TO_YCBK_STORE_D';
-- 6. TO_YCBK_PRVC_D 机器省份日全量表
CREATE EXTERNAL TABLE `TO_YCBK_PRVC_D` (
`PRVC_ID` int,
`PRVC` string
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://node01/user/hive/warehouse/music.db/TO_YCBK_PRVC_D';
-- 7. TO_YCBK_CITY_D 机器城市日全量表
CREATE EXTERNAL TABLE `TO_YCBK_CITY_D` (
`PRVC_ID` int,
`CTY_ID` int,
`CTY` string
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://node01/user/hive/warehouse/music.db/TO_YCBK_CITY_D';
-- 8. TO_YCBK_AREA_D 机器区县日全量表
CREATE EXTERNAL TABLE `TO_YCBK_AREA_D` (
`CTY_ID` int,
`AREA_ID` int,
`AREA` string
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://node01/user/hive/warehouse/music.db/TO_YCBK_AREA_D';
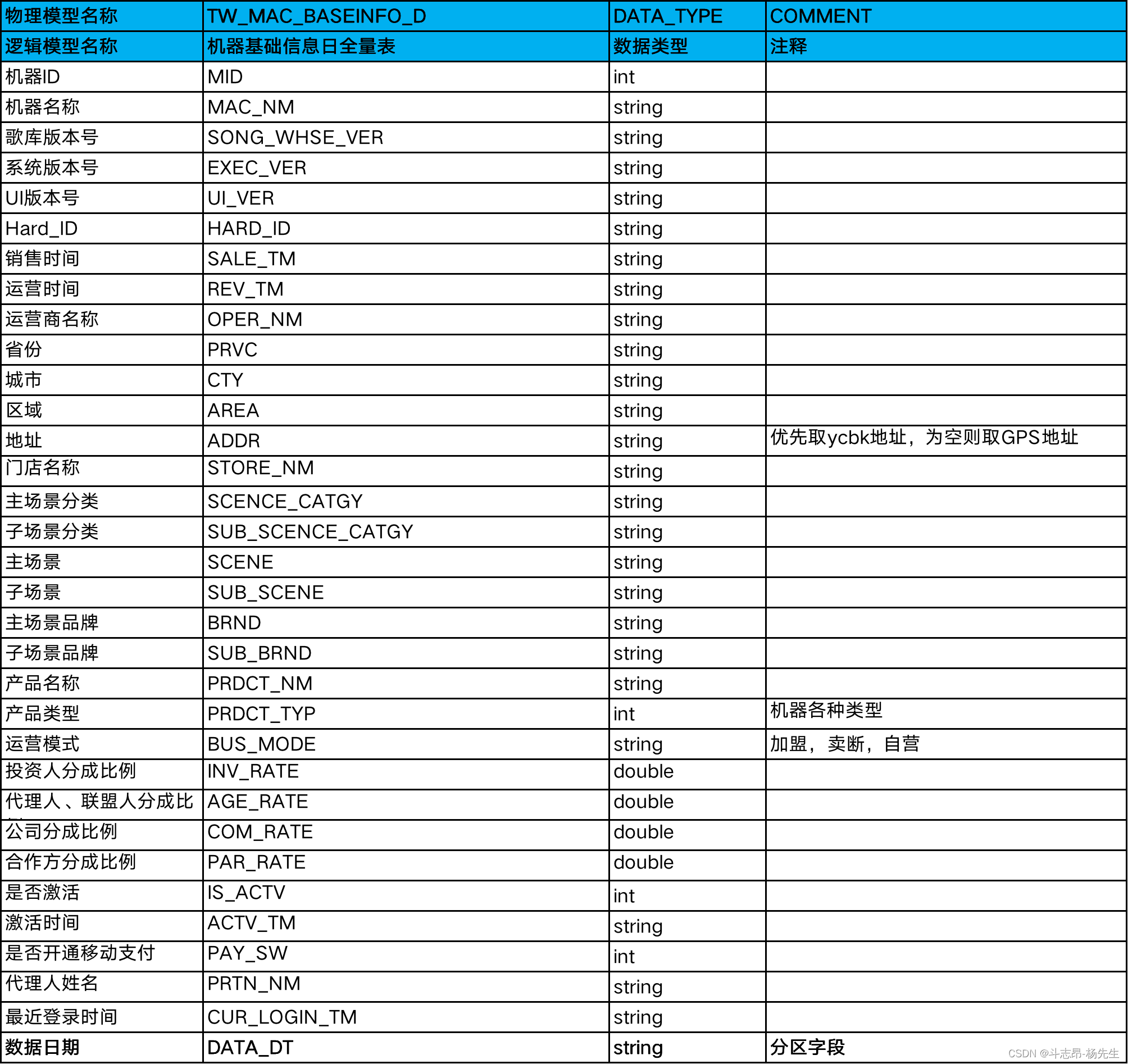
-- 9. TW_MAC_BASEINFO_D 机器基础信息日全量表
CREATE EXTERNAL TABLE `TW_MAC_BASEINFO_D` (
`MID` int,
`MAC_NM` string,
`SONG_WHSE_VER` string,
`EXEC_VER` string,
`UI_VER` string,
`HARD_ID` string,
`SALE_TM` string,
`REV_TM` string,
`OPER_NM` string,
`PRVC` string,
`CTY` string,
`AREA` string,
`ADDR` string,
`STORE_NM` string,
`SCENCE_CATGY` string,
`SUB_SCENCE_CATGY` string,
`SCENE` string,
`SUB_SCENE` string,
`BRND` string,
`SUB_BRND` string,
`PRDCT_NM` string,
`PRDCT_TYP` int,
`BUS_MODE` string,
`INV_RATE` double,
`AGE_RATE` double,
`COM_RATE` double,
`PAR_RATE` double,
`IS_ACTV` int,
`ACTV_TM` string,
`PAY_SW` int,
`PRTN_NM` string,
`CUR_LOGIN_TM` string
) PARTITIONED BY (data_dt string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://node01/user/hive/warehouse/music.db/TW_MAC_BASEINFO_D';
- 以上建模中,处理ODS层的各个表结构之外,EDS层TW_MAC_BASEINFO_D 表在对应的DM层也要一张表对应,这里DM层在mysql中有对应的tm_mac_baseinfo_d 表,以上各个表之间的数据流转过程如下:
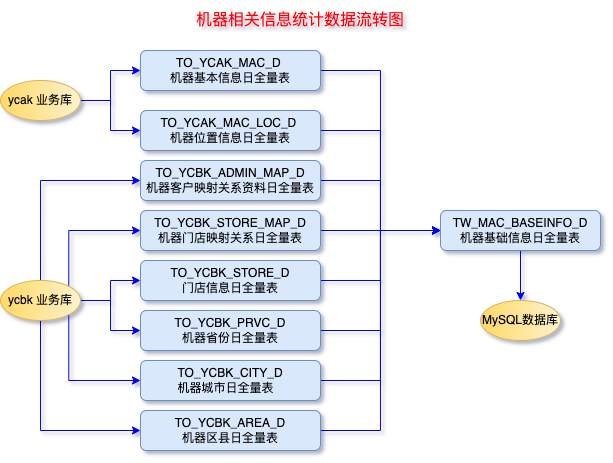
数据处理流程
1. 将数据导入MySQL业务库
- 在MySQL中分别创建 ycak、ycbk 数据库,将 ycak.sql、ycbk.sql 分别运行在对应的库下,将数据导入到业务库中。
create database ycak default character set utf8;
create database ycbk default character set utf8;
2. 使用Sqoop工具抽取数据到Hive ODS层
- 在 node03 上执行 sqoop 导入数据脚本,将 MySQL 中的表数据导入到 Hive 数仓中,脚本内容如下:
#!/bin/bash
ssh hadoop@node03 > /tmp/logs/music_project/machine-info.log 2>&1 <<aabbcc
hostname
source /etc/profile
# ycak
## machine_baseinfo ==>> TO_YCAK_MAC_D
sqoop import --connect jdbc:mysql://node01:3306/ycak?dontTrackOpenResources=true\&defaultFetchSize=10000\&useCursorFetch=true\&useUnicode=yes\&characterEncoding=utf8 --username root --password 123456 --table machine_baseinfo --target-dir /user/hive/warehouse/music.db/TO_YCAK_MAC_D/ --delete-target-dir --num-mappers 1 --fields-terminated-by '\t'
## machine_local_info ==>> TO_YCAK_MAC_LOC_D
sqoop import --connect jdbc:mysql://node01:3306/ycak?dontTrackOpenResources=true\&defaultFetchSize=10000\&useCursorFetch=true\&useUnicode=yes\&characterEncoding=utf8 --username root --password 123456 --table machine_local_info --target-dir /user/hive/warehouse/music.db/TO_YCAK_MAC_LOC_D/ --delete-target-dir --num-mappers 1 --fields-terminated-by '\t'
# ycbk
## machine_admin_map ==>> TO_YCBK_MAC_ADMIN_MAP_D
sqoop import --connect jdbc:mysql://node01:3306/ycbk?dontTrackOpenResources=true\&defaultFetchSize=10000\&useCursorFetch=true\&useUnicode=yes\&characterEncoding=utf8 --username root --password 123456 --table machine_admin_map --target-dir /user/hive/warehouse/music.db/TO_YCBK_MAC_ADMIN_MAP_D/ --delete-target-dir --num-mappers 1 --fields-terminated-by '\t'
## machine_store_map ==>> TO_YCBK_MAC_STORE_MAP_D
sqoop import --connect jdbc:mysql://node01:3306/ycbk?dontTrackOpenResources=true\&defaultFetchSize=10000\&useCursorFetch=true\&useUnicode=yes\&characterEncoding=utf8 --username root --password 123456 --table machine_store_map --target-dir /user/hive/warehouse/music.db/TO_YCBK_MAC_STORE_MAP_D/ --delete-target-dir --num-mappers 1 --fields-terminated-by '\t'
## machine_store_info ==>> TO_YCBK_STORE_D
sqoop import --connect jdbc:mysql://node01:3306/ycbk?dontTrackOpenResources=true\&defaultFetchSize=10000\&useCursorFetch=true\&useUnicode=yes\&characterEncoding=utf8 --username root --password 123456 --table machine_store_info --target-dir /user/hive/warehouse/music.db/TO_YCBK_STORE_D/ --delete-target-dir --num-mappers 1 --fields-terminated-by '\t'
## province_info ==>> TO_YCBK_PRVC_D
sqoop import --connect jdbc:mysql://node01:3306/ycbk?dontTrackOpenResources=true\&defaultFetchSize=10000\&useCursorFetch=true\&useUnicode=yes\&characterEncoding=utf8 --username root --password 123456 --table province_info --target-dir /user/hive/warehouse/music.db/TO_YCBK_PRVC_D/ --delete-target-dir --num-mappers 1 --fields-terminated-by '\t'
## city_info ==>> TO_YCBK_CITY_D
sqoop import --connect jdbc:mysql://node01:3306/ycbk?dontTrackOpenResources=true\&defaultFetchSize=10000\&useCursorFetch=true\&useUnicode=yes\&characterEncoding=utf8 --username root --password 123456 --table city_info --target-dir /user/hive/warehouse/music.db/TO_YCBK_CITY_D/ --delete-target-dir --num-mappers 1 --fields-terminated-by '\t'
## area_info ==>> TO_YCBK_AREA_D
sqoop import --connect jdbc:mysql://node01:3306/ycbk?dontTrackOpenResources=true\&defaultFetchSize=10000\&useCursorFetch=true\&useUnicode=yes\&characterEncoding=utf8 --username root --password 123456 --table area_info --target-dir /user/hive/warehouse/music.db/TO_YCBK_AREA_D/ --delete-target-dir --num-mappers 1 --fields-terminated-by '\t'
aabbcc
echo "all done!"
3. 使用SparkSQL对ODS层数据进行ETL清洗
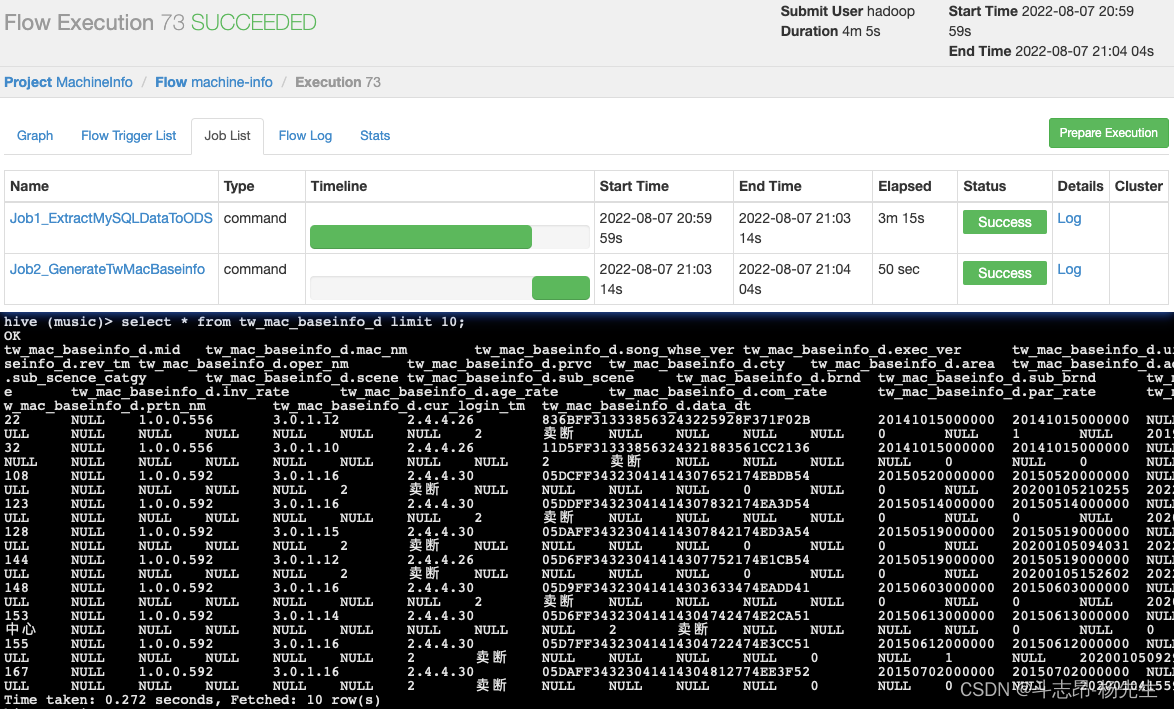
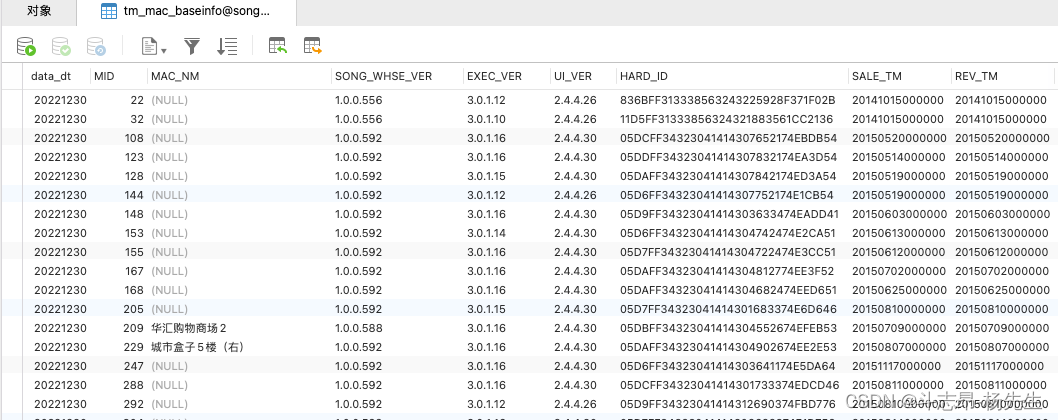
- 对应的数据处理文件:GenerateTwMacBaseinfoD.scala,本地运行该程序并查看结果:
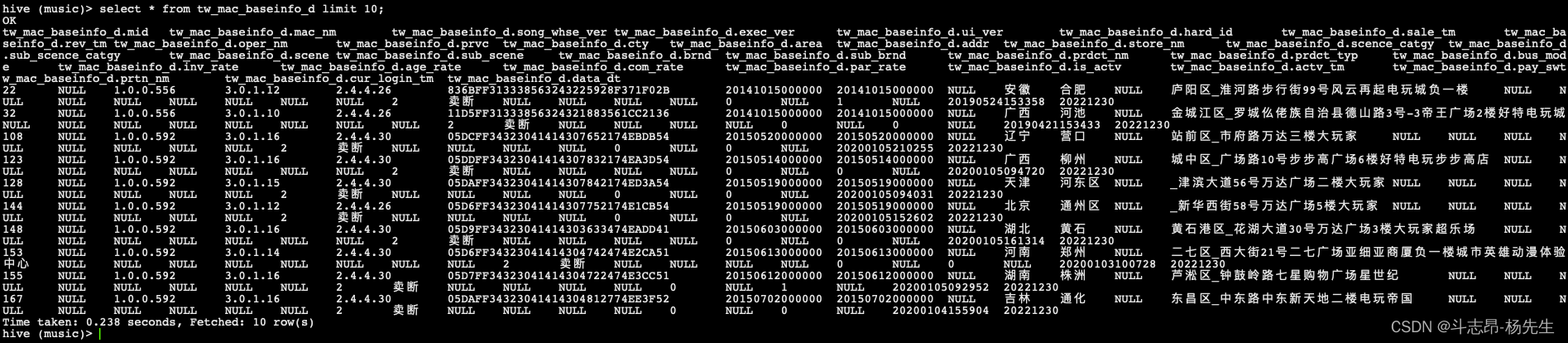
- 至此,我们得到了机器基础信息日全量表。
- 将工程打包并上传到服务器。
使用Azkaban配置任务流
1. 脚本准备
- ① mysql 数据抽取到 Hive ODS 层的脚本 1_extract_mysqldata_to_ods.sh
- ② 处理 8 张 ODS 层表数据,得到机器基本信息表的脚本
2_generate_tw_mac_baseinfo.sh
#!/bin/bash
currentDate=`date -d today +"%Y%m%d"`
if [ x"$1" = x ]; then
echo "====使用自动生成的今天日期===="
else
echo "====使用 Azkaban 传入的日期===="
currentDate=$1
fi
echo "日期为: $currentDate"
ssh hadoop@node01 > /tmp/logs/music_project/machine-info.log 2>&1 <<aabbcc
hostname
cd /bigdata/install/spark-2.3.3-bin-hadoop2.7/bin
./spark-submit --master yarn --class com.yw.musichw.eds.machine.GenerateTwMacBaseinfoD \
/bigdata/data/music_project/musicwh-1.0.0-SNAPSHOT-jar-with-dependencies.jar $currentDate
exit
aabbcc
echo "all done!"
2. 编写 Azkaban 各个Job组成任务流
- 新建
machine-info.flow,内容如下:
nodes:
- name: Job1_ExtractMySQLDataToODS
type: command
config:
command: sh 1_extract_mysqldata_to_ods.sh
- name: Job2_GenerateTwMacBaseinfo
type: command
config:
command: sh 2_generate_tw_mac_baseinfo.sh ${mydate}
dependsOn:
- Job1_ExtractMySQLDataToODS
- 将以上2个脚本文件、
machine-info.flow与flow20.project压缩生成 zip 文件machine-info.zip
3. 清空数据
- 由于前面我们在本地已经将整个数据处理流程跑过一次,现在 hive 和 mysql 中已经存在数据。在提交作业执行前,先清除掉 hive 和 mysql 中的数据。
- 在 node03 节点,编写脚本
vim drop_machine_tables.sql,内容如下:
drop table `music`.`to_ycak_mac_d`;
drop table `music`.`to_ycak_mac_loc_d`;
drop table `music`.`to_ycbk_area_d`;
drop table `music`.`to_ycbk_city_d`;
drop table `music`.`to_ycbk_mac_admin_map_d`;
drop table `music`.`to_ycbk_mac_store_map_d`;
drop table `music`.`to_ycbk_prvc_d`;
drop table `music`.`to_ycbk_store_d`;
drop table `music`.`tw_mac_baseinfo_d`;
- 执行命令:
hive -f drop_machine_tables.sql,删除表。由于这些都是外部表,真正的数据还在 HDFS,所以还需要删除相关的数据。 - 然后重新创建 hive 表,编写脚本
vim create_machine_tables.sql,内容在前面模型设计这一小节。 - 执行命令
hive -f create_machine_tables.sql,创建表。
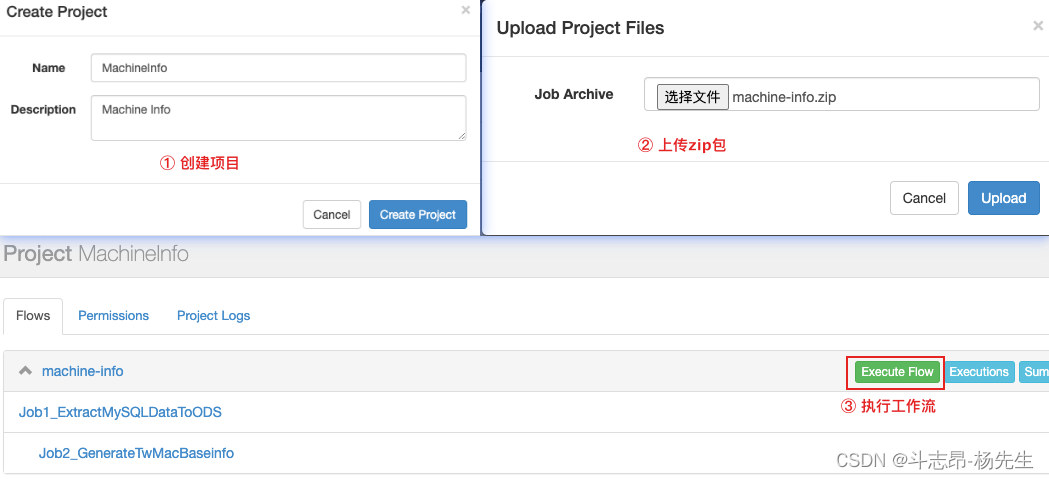
4. 提交Azkaban作业
- 启动Azkaban服务,并在 Azkaban 的 web server ui界面创建项目,然后上传项目 zip 文件
machine-info.zip
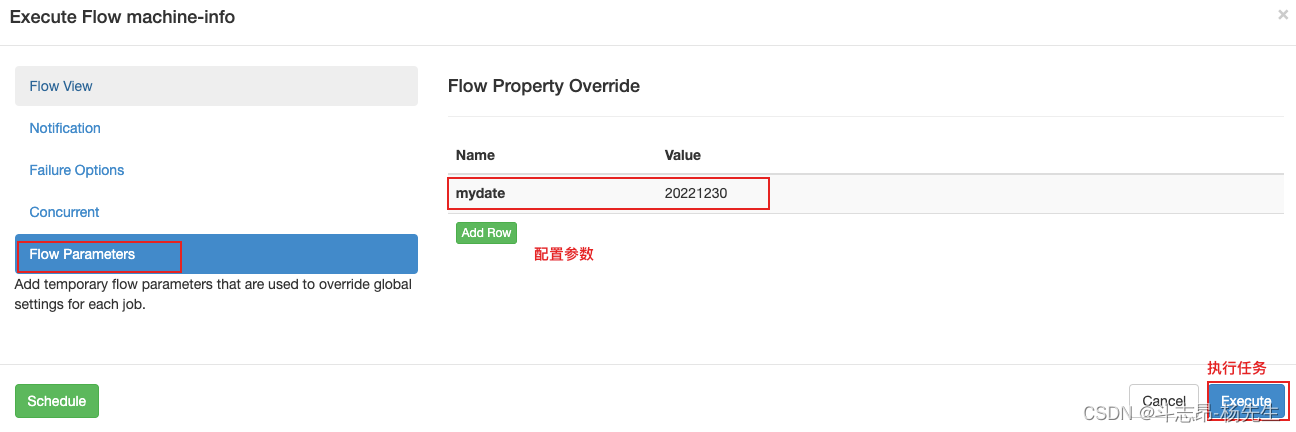
- 查看任务,配置任务参数,并执行
- 执行成功后,最终结果保存到了 mysql 表中
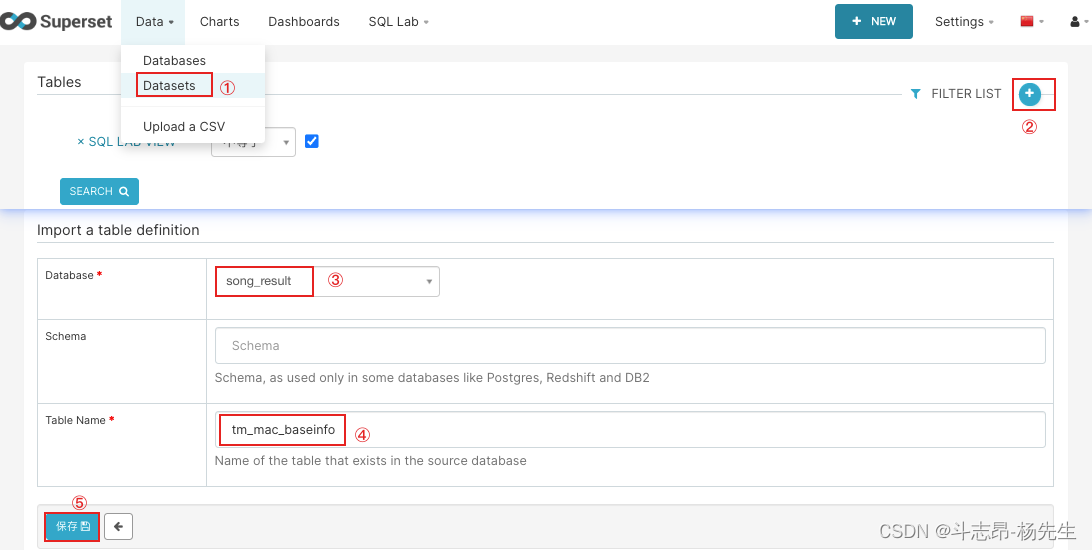
使用Superset数据可视化
- 添加数据表:依次点击 Data → Datasets → 添加,添加“song_result”库下的表“tm_mac_baseinfo”。
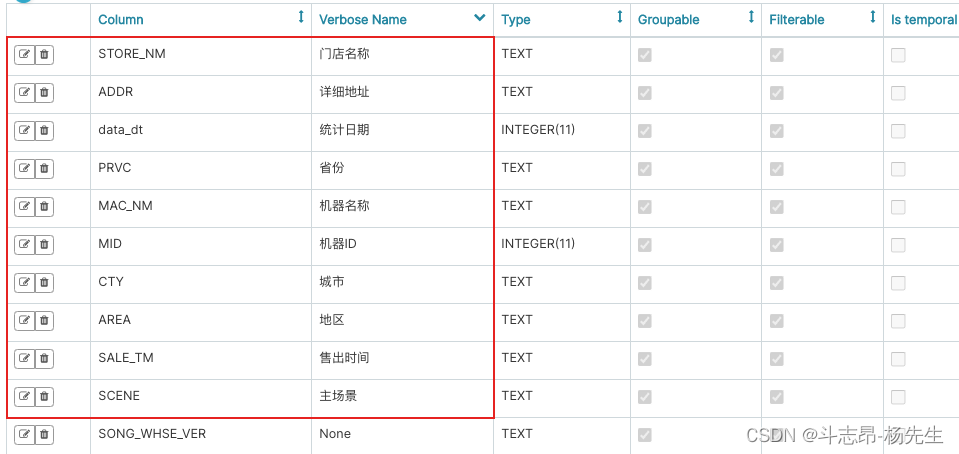
- 修改表中对应字段显示名称:
- 编辑图表《各省份机器数量日统计》:
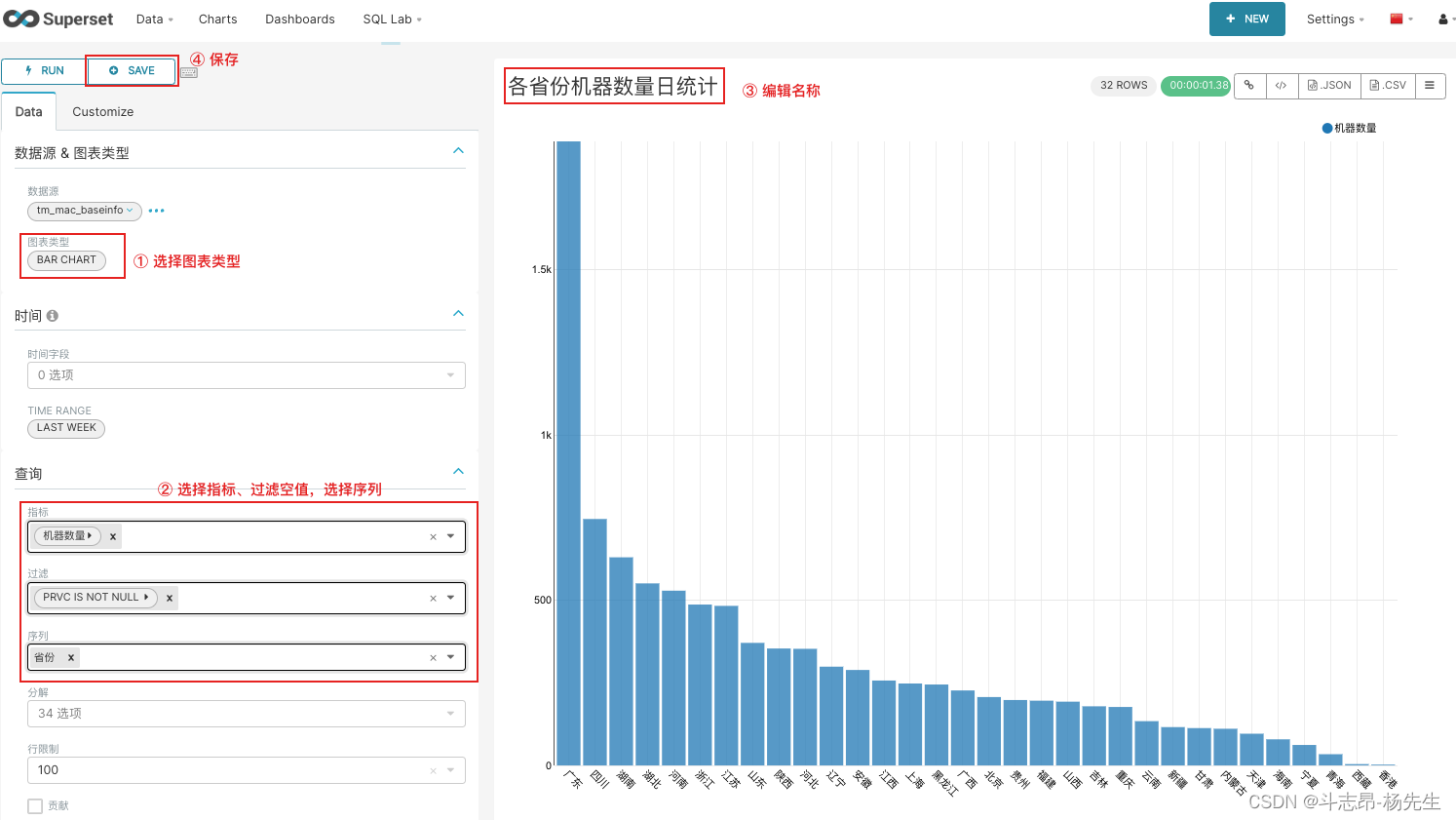
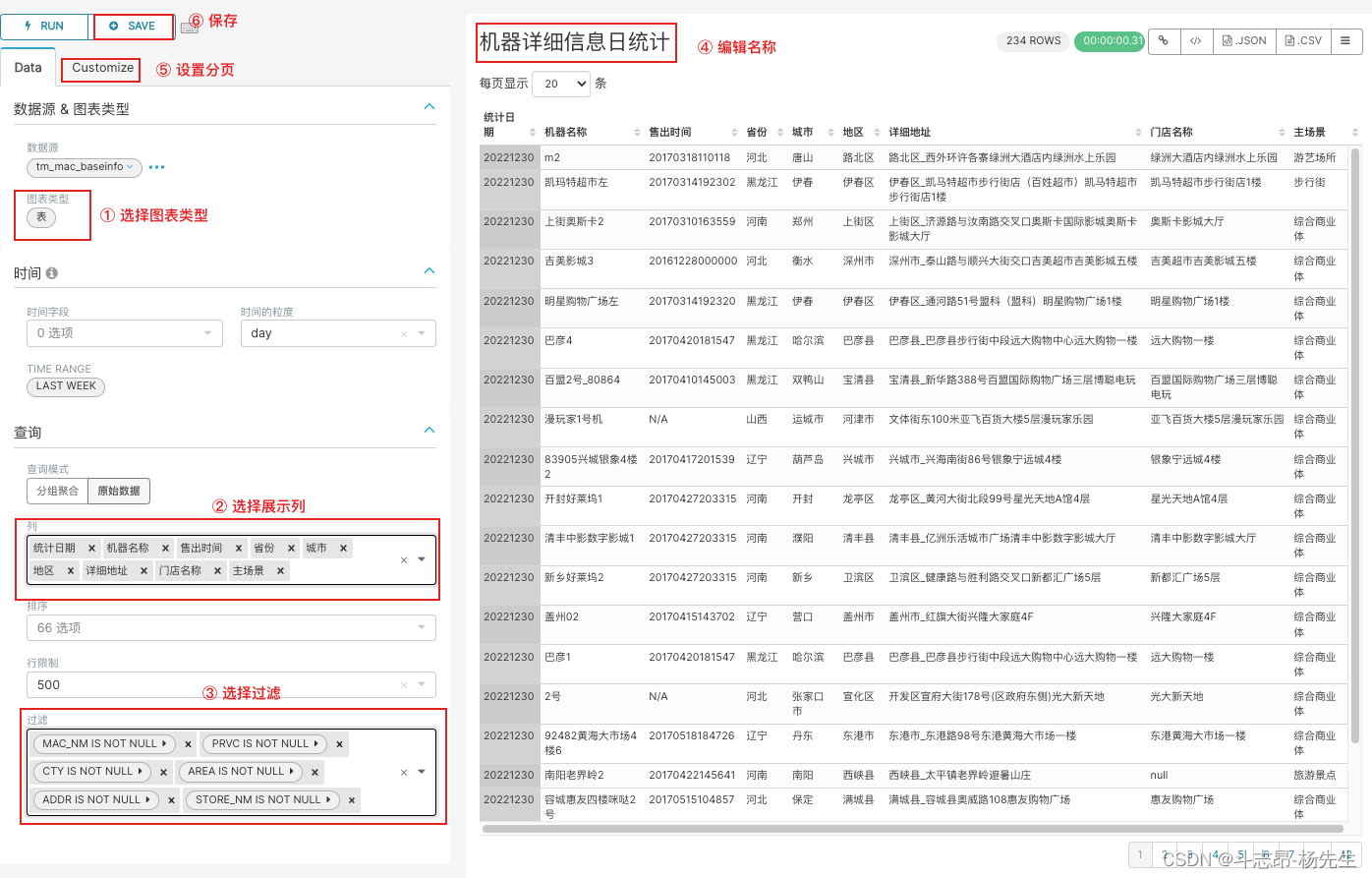
- 编辑图表《机器详细信息日统计》:
- 最终效果:
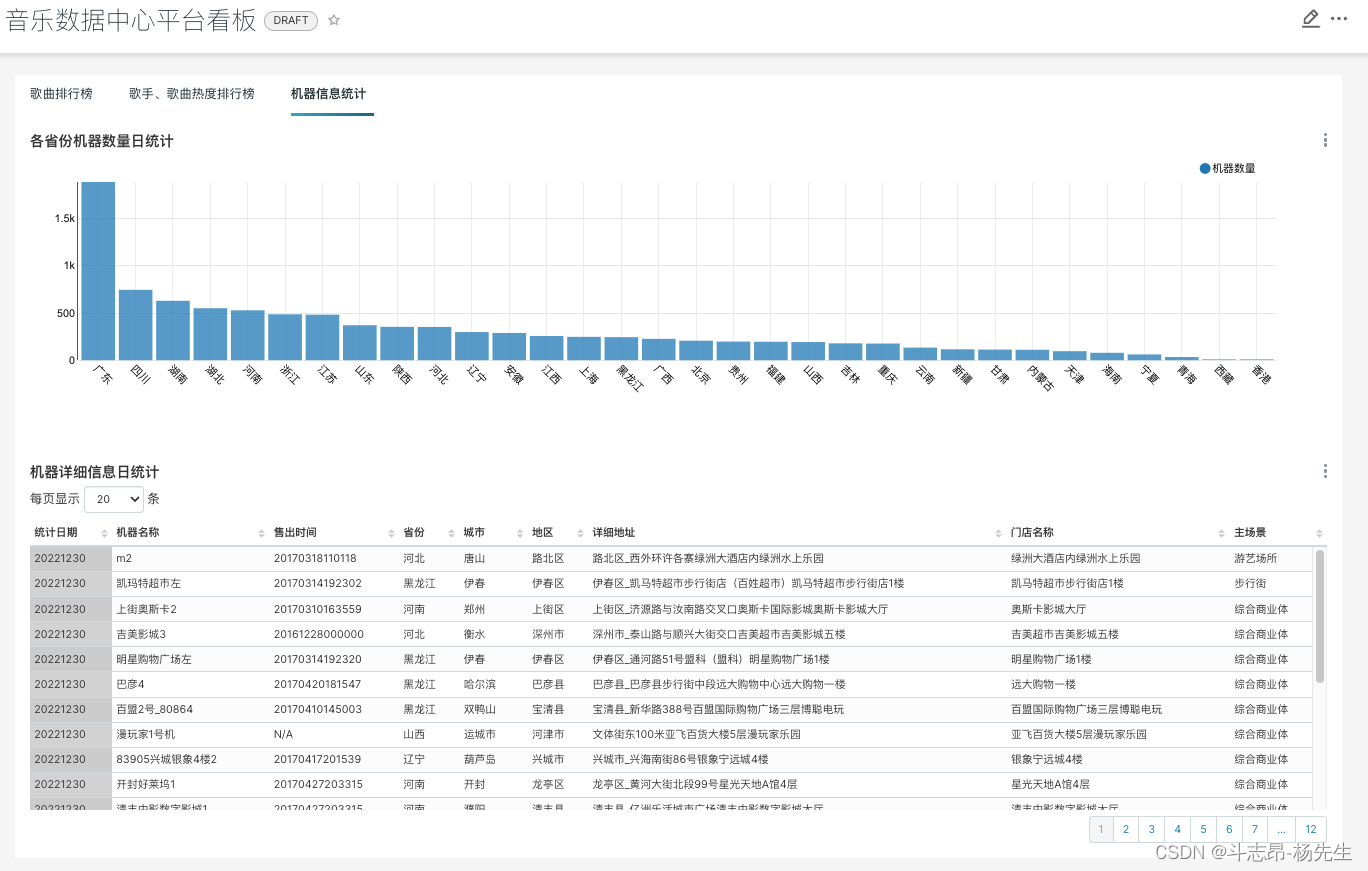
第三个业务:日活跃用户统计
需求
- 每天统计最近7日活跃用户的详细信息。
- 如果计算用户日活情况,需要获取对应的每天用户登录信息,用户登录信息被记录在“ycak”业务库下的“user_login_info”表中,这张表将用户每天登录系统,登出系统的信息记录下来,我们可以将这张表的信息每天增量的抽取到ODS层中,然后把用户的基本信息每天全量抽取到ODS层,然后获取每天活跃的用户信息,进而计算统计出7日用户活跃情况。
- 这里用户的基本信息包含了四类注册用户的数据,存储在“ycak”业务库中,分别是:
- user_wechat_baseinfo:微信注册用户
- user_alipay_baseinfo:支付宝注册用户
- user_qq_baseinfo:QQ注册用户
- user_app_baseinfo:App注册用户
模型设计
- 将业务需要到的数据表通过 Sqoop 抽取到 ODS 层数据。根据业务我们在数仓中构建“用户”主题,具体数据分层如下:
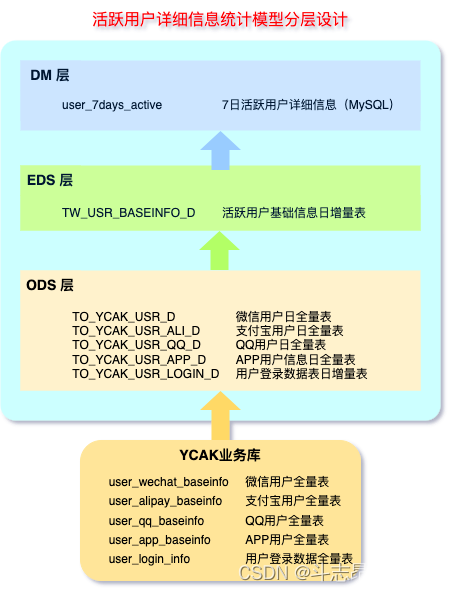
- ODS:
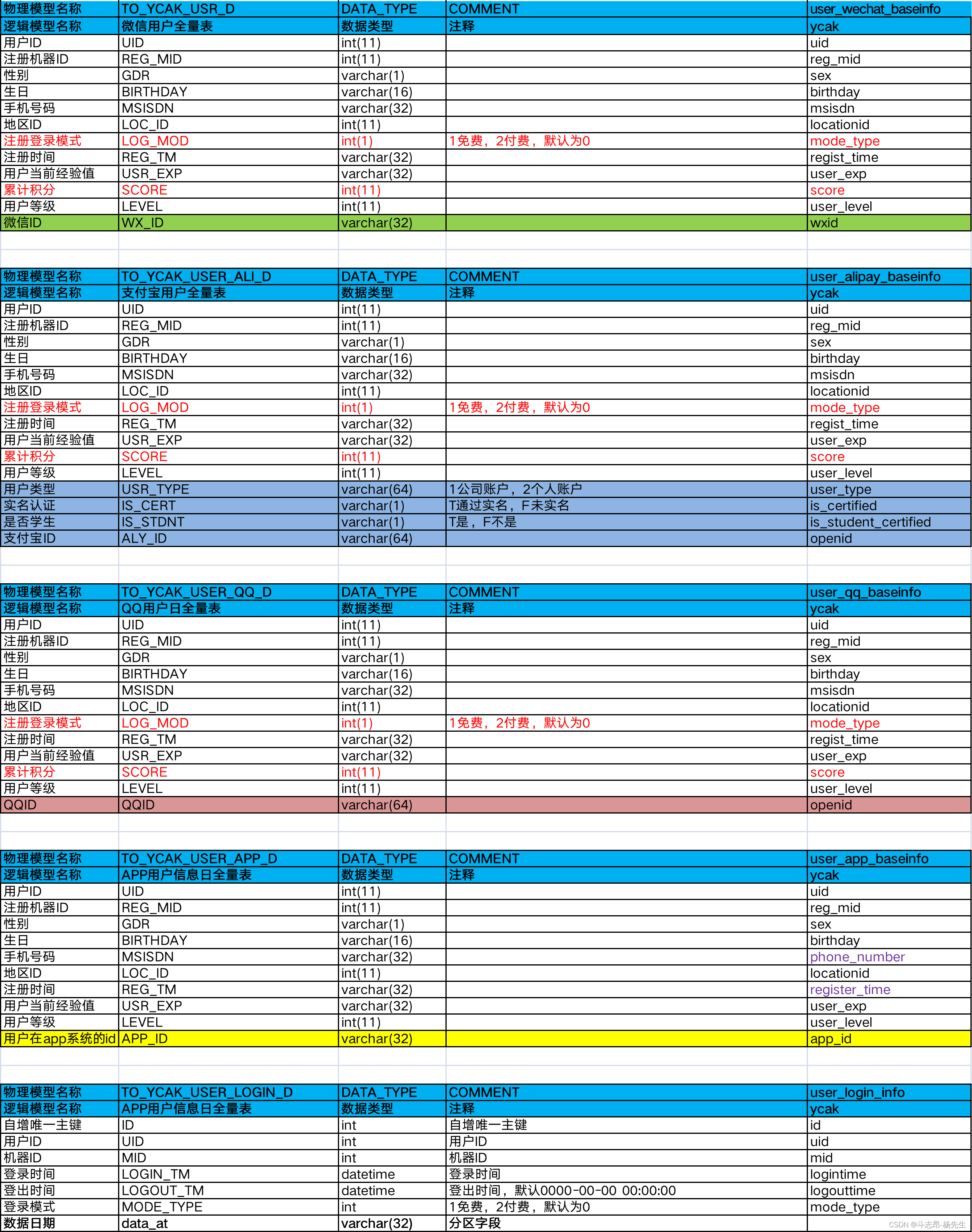
- EDS:
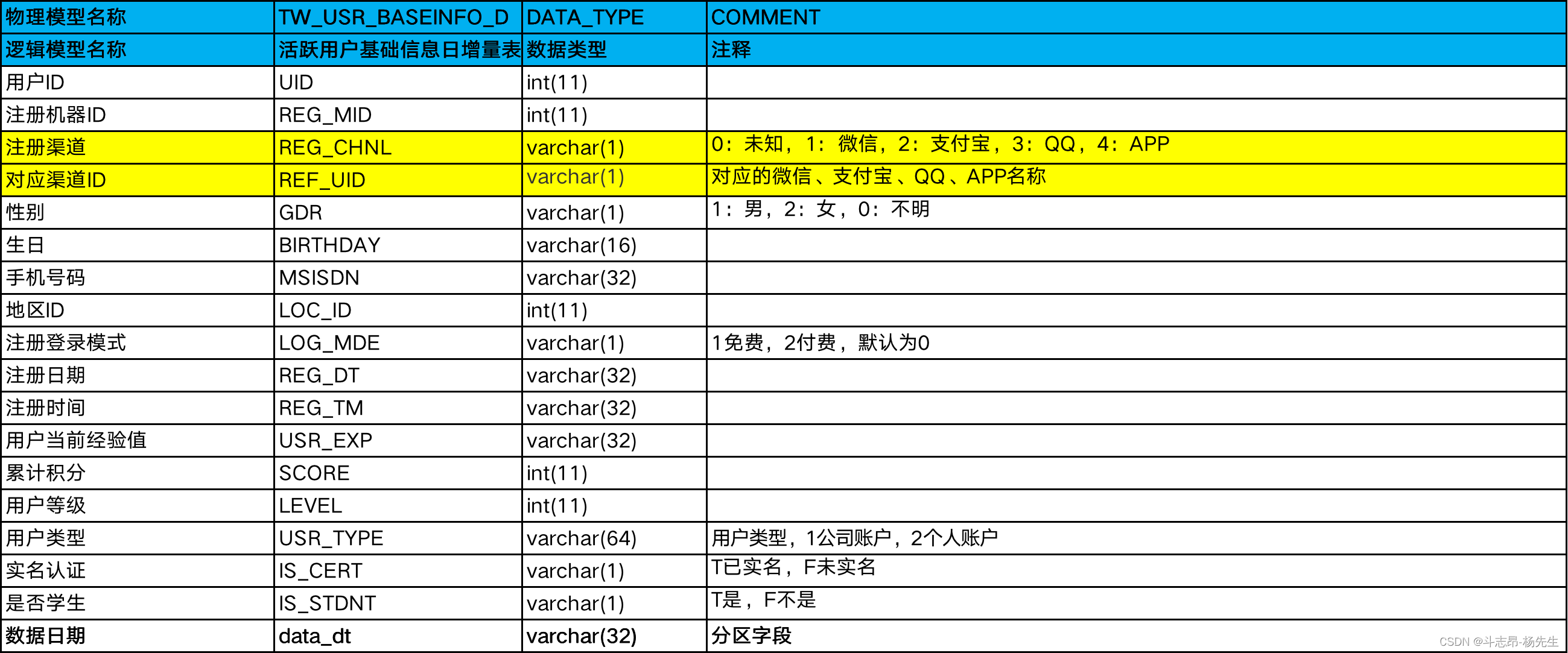
- 在Hive中创建ODS层对应的表:
USE `music`;
-- 1. TO_YCAK_USR_D 微信用户日全量表
CREATE EXTERNAL TABLE `TO_YCAK_USR_D` (
`UID` int,
`REG_MID` int,
`GDR` string,
`BIRTHDAY` string,
`MSISDN` string,
`LOC_ID` int,
`LOG_MDE` int,
`REG_TM` string,
`USR_EXP` string,
`SCORE` int,
`LEVEL` int,
`WX_ID` string
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://node01/user/hive/warehouse/music.db/TO_YCAK_USR_D';
-- 2. TO_YCAK_USR_ALI_D 支付宝用户日全量表
CREATE EXTERNAL TABLE `TO_YCAK_USR_ALI_D` (
`UID` int,
`REG_MID` int,
`GDR` string,
`BIRTHDAY` string,
`MSISDN` string,
`LOC_ID` int,
`LOG_MDE` int,
`REG_TM` string,
`USR_EXP` string,
`SCORE` int,
`LEVEL` int,
`USR_TYPE` string,
`IS_CERT` string,
`IS_STDNT` string,
`ALY_ID` string
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://node01/user/hive/warehouse/music.db/TO_YCAK_USR_ALI_D';
-- 3. TO_YCAK_USR_QQ_D QQ用户日全量表
CREATE EXTERNAL TABLE `TO_YCAK_USR_QQ_D` (
`UID` int,
`REG_MID` int,
`GDR` string,
`BIRTHDAY` string,
`MSISDN` string,
`LOC_ID` int,
`LOG_MDE` int,
`REG_TM` string,
`USR_EXP` string,
`SCORE` int,
`LEVEL` int,
`QQID` string
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://node01/user/hive/warehouse/music.db/TO_YCAK_USR_QQ_D';
-- 4. TO_YCAK_USR_APP_D APP用户信息日全量表
CREATE EXTERNAL TABLE `TO_YCAK_USR_APP_D` (
`UID` int,
`REG_MID` int,
`GDR` string,
`BIRTHDAY` string,
`MSISDN` string,
`LOC_ID` int,
`REG_TM` string,
`USR_EXP` string,
`LEVEL` int,
`APP_ID` string
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://node01/user/hive/warehouse/music.db/TO_YCAK_USR_APP_D';
-- 5. TO_YCAK_USR_LOGIN_D 用户登录数据日增量表
CREATE EXTERNAL TABLE `TO_YCAK_USR_LOGIN_D` (
`ID` int,
`UID` int,
`MID` int,
`LOGIN_TM` string,
`LOGOUT_TM` string,
`MODE_TYPE` int
) PARTITIONED BY (`data_dt` string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://node01/user/hive/warehouse/music.db/TO_YCAK_USR_LOGIN_D';
-- 6. TW_USR_BASEINFO_D 活跃用户基础信息日增量表
CREATE EXTERNAL TABLE `TW_USR_BASEINFO_D` (
`UID` int,
`REG_MID` int,
`REG_CHNL` string,
`REF_UID` string,
`GDR` string,
`BIRTHDAY` string,
`MSISDN` string,
`LOC_ID` int,
`LOG_MDE` string,
`REG_DT` string,
`REG_TM` string,
`USR_EXP` string,
`SCORE` int,
`LEVEL` int,
`USR_TYPE` string,
`IS_CERT` string,
`IS_STDNT` string
) PARTITIONED BY (`data_dt` string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://node01/user/hive/warehouse/music.db/TW_USR_BASEINFO_D';
- 以上表模型中,最终获取7日用户活跃信息从EDS层“TW_USR_BASEINFO_D”表统计得到,这里将统计到的7日活跃用户情况存放在DM层,通过 SparkSQL 直接将结果存放在“user_7days_active”表中,提供查询展示。
- 以上各个表之间的数据流转关系如下:
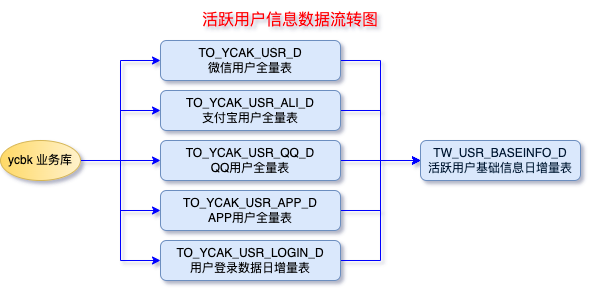
数据处理流程
1. 将数据导入MySQL业务库
- 第二个业务中已经创建了 ycak 数据库,将里面的数据表删除,然后重新执行 ycak.sql 脚本文件。
2. 使用Sqoop抽取mysql数据到ODS层
- 在 node03 上执行 sqoop 导入数据脚本,将 MySQL 中的表数据导入到 Hive 数仓中
- 针对用户注册的4张表,进行全量的导入,脚本
1_extract_mysqldata_to_ods.sh内容如下:
#!/bin/bash
ssh hadoop@node03 > /tmp/logs/music_project/user-info.log 2>&1 <<aabbcc
hostname
source /etc/profile
# ycak
## user_wechat_baseinfo ==>> TO_YCAK_USR_D
sqoop import --connect jdbc:mysql://node01:3306/ycak?dontTrackOpenResources=true\&defaultFetchSize=10000\&useCursorFetch=true\&useUnicode=yes\&characterEncoding=utf8 --username root --password 123456 --table user_wechat_baseinfo --target-dir /user/hive/warehouse/music.db/TO_YCAK_USR_D/ --delete-target-dir --num-mappers 1 --fields-terminated-by '\t'
## user_alipay_baseinfo ==>> TO_YCAK_USR_ALI_D
sqoop import --connect jdbc:mysql://node01:3306/ycak?dontTrackOpenResources=true\&defaultFetchSize=10000\&useCursorFetch=true\&useUnicode=yes\&characterEncoding=utf8 --username root --password 123456 --table user_alipay_baseinfo --target-dir /user/hive/warehouse/music.db/TO_YCAK_USR_ALI_D/ --delete-target-dir --num-mappers 1 --fields-terminated-by '\t'
## user_qq_baseinfo ==>> TO_YCAK_USR_QQ_D
sqoop import --connect jdbc:mysql://node01:3306/ycak?dontTrackOpenResources=true\&defaultFetchSize=10000\&useCursorFetch=true\&useUnicode=yes\&characterEncoding=utf8 --username root --password 123456 --table user_qq_baseinfo --target-dir /user/hive/warehouse/music.db/TO_YCAK_USR_QQ_D/ --delete-target-dir --num-mappers 1 --fields-terminated-by '\t'
## user_app_baseinfo ==>> TO_YCAK_USR_APP_D
sqoop import --connect jdbc:mysql://node01:3306/ycak?dontTrackOpenResources=true\&defaultFetchSize=10000\&useCursorFetch=true\&useUnicode=yes\&characterEncoding=utf8 --username root --password 123456 --table user_app_baseinfo --target-dir /user/hive/warehouse/music.db/TO_YCAK_USR_APP_D/ --delete-target-dir --num-mappers 1 --fields-terminated-by '\t'
aabbcc
echo "all done!"
- 针对用户登录信息表,进行增量导入,脚本
2_incr_extract_mysqldata_to_ods.sh内容如下:
#!/bin/bash
currentDate=`date -d today +"%Y%m%d"`
if [ x"$1" = x ]; then
echo "====没有导入数据的日期,输入日期===="
exit
else
echo "====使用导入数据的日期 ===="
currentDate=$1
fi
echo "日期为 : $currentDate"
# 查询hive ODS层表 to_ycak_usr_login_d 中目前存在的最大的ID
result=`ssh hadoop@node03 "source /etc/profile;hive -e 'select max(id) from music.to_ycak_usr_login_d'" | grep _c0 -A 1`
maxId=`echo ${result} | awk "{print \\$2}"`
if [ x"${maxId}" = xNULL ]; then
maxId=0
fi
echo "Hive ODS层表 TO_YCAK_USR_LOGIN_D 最大的ID是${maxId}"
ssh hadoop@node03 > /tmp/logs/music_project/user-login-info.log 2>&1 <<aabbcc
hostname
source /etc/profile
## user_login_info ==>> TO_YCAK_USR_LOGIN_D
sqoop import --connect jdbc:mysql://node01:3306/ycak?dontTrackOpenResources=true\&defaultFetchSize=10000\&useCursorFetch=true\&useUnicode=yes\&characterEncoding=utf8 --username root --password 123456 --table user_login_info --target-dir /user/hive/warehouse/music.db/TO_YCAK_USR_LOGIN_D/data_dt=${currentDate} --num-mappers 1 --fields-terminated-by '\t' --incremental append --check-column id --last-value ${maxId}
# 更新Hive 分区
hive -e 'alter table music.to_ycak_usr_login_d add partition(data_dt=${currentDate})'
exit
aabbcc
echo "all done!"
3. 使用SparkSQL对ODS层数据进行清洗
- 对应的处理数据的scala文件:GenerateTwUsrBaseinfoD.scala,本地运行该程序并查看结果:
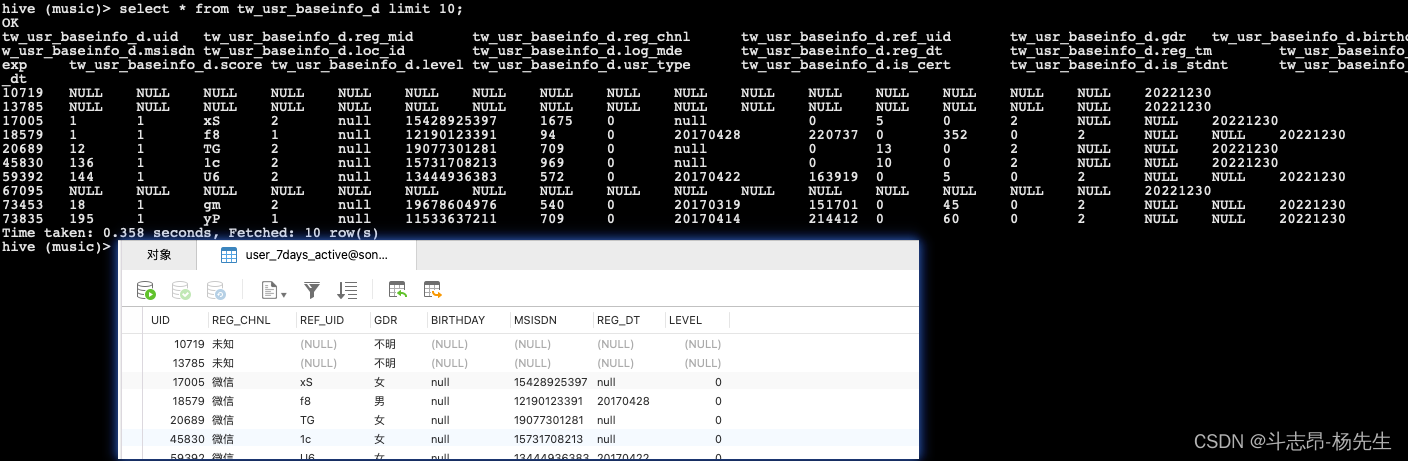
- 将工程打包并上传到服务器。
使用Azkaban配置任务流
1. 脚本准备
- ① 4 张用户注册信息的 mysql 表数据,全量抽取到 Hive ODS 层的脚本 1_extract_mysqldata_to_ods.sh
- ② 1张用户登录信息的 mysql 表数据,全量抽取到 Hive ODS 层的脚本 2_incr_extract_mysqldata_to_ods.sh
- ③ 根据 ODS 层表数据,得到用户基本信息表的脚本
3_generate_tw_usr_baseinfo_d.sh
#!/bin/bash
currentDate=`date -d today +"%Y%m%d"`
if [ x"$1" = x ]; then
echo "====使用自动生成的今天日期===="
else
echo "====使用 Azkaban 传入的日期===="
currentDate=$1
fi
echo "日期为: $currentDate"
ssh hadoop@node01 > /tmp/logs/music_project/user-info.log 2>&1 <<aabbcc
hostname
cd /bigdata/install/spark-2.3.3-bin-hadoop2.7/bin
./spark-submit --master yarn --class com.yw.musichw.eds.user.GenerateTwUsrBaseinfoD \
/bigdata/data/music_project/musicwh-1.0.0-SNAPSHOT-jar-with-dependencies.jar $currentDate
exit
aabbcc
echo "all done!"
2. 编写Azkaban各个Job组成任务流
- 编写
user-info.flow,内容如下:
nodes:
- name: Job1_ExtractMySQLDataToODS
type: command
config:
command: sh 1_extract_mysqldata_to_ods.sh
command.1: sh 2_incr_extract_mysqldata_to_ods.sh ${mydate}
- name: Job2_GenerateTwUsrBaseinfo
type: command
config:
command: sh 3_generate_tw_usr_baseinfo_d.sh ${mydate}
dependsOn:
- Job1_ExtractMySQLDataToODS
- 将以上3个脚本文件、
user-info.flow与flow20.project压缩生成 zip 文件user-info.zip
3. 清空数据
- 在 node03 节点,编写脚本
vim drop_user_tables.sql,内容如下:
drop table `music`.`to_ycak_usr_ali_d`;
drop table `music`.`to_ycak_usr_app_d`;
drop table `music`.`to_ycak_usr_d`;
drop table `music`.`to_ycak_usr_login_d`;
drop table `music`.`to_ycak_usr_qq_d`;
drop table `music`.`tw_usr_baseinfo_d`;
- 执行命令:
hive -f drop_user_tables.sql,删除表。由于这些都是外部表,真正的数据还在 HDFS,所以还需要删除相关的数据。 - 然后重新创建 hive 表,编写脚本
vim create_user_tables.sql,内容在前面模型设计这一小节。 - 执行命令
hive -f create_user_tables.sql,创建表。
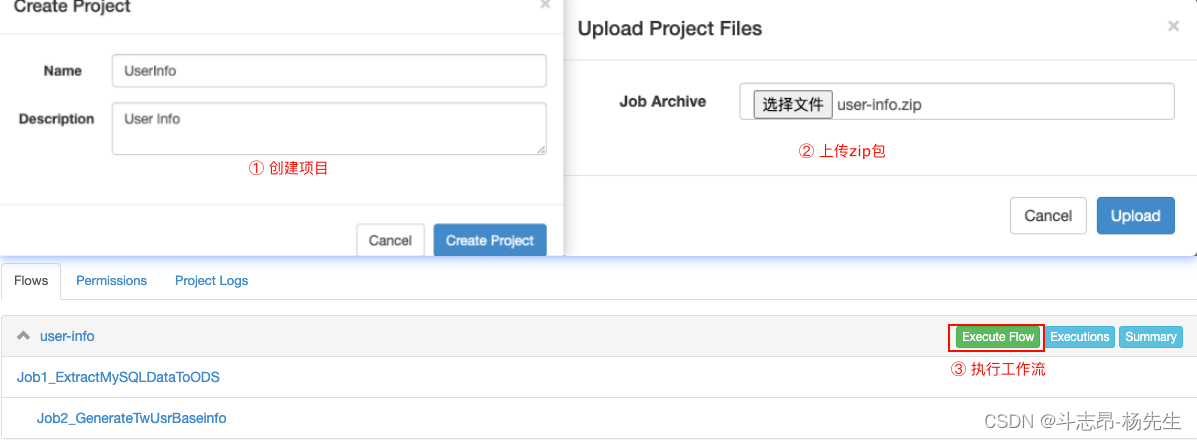
4. 提交Azkaban作业
- 启动Azkaban服务,并在 Azkaban 的 web server ui界面创建项目,然后上传项目 zip 文件
user-info.zip
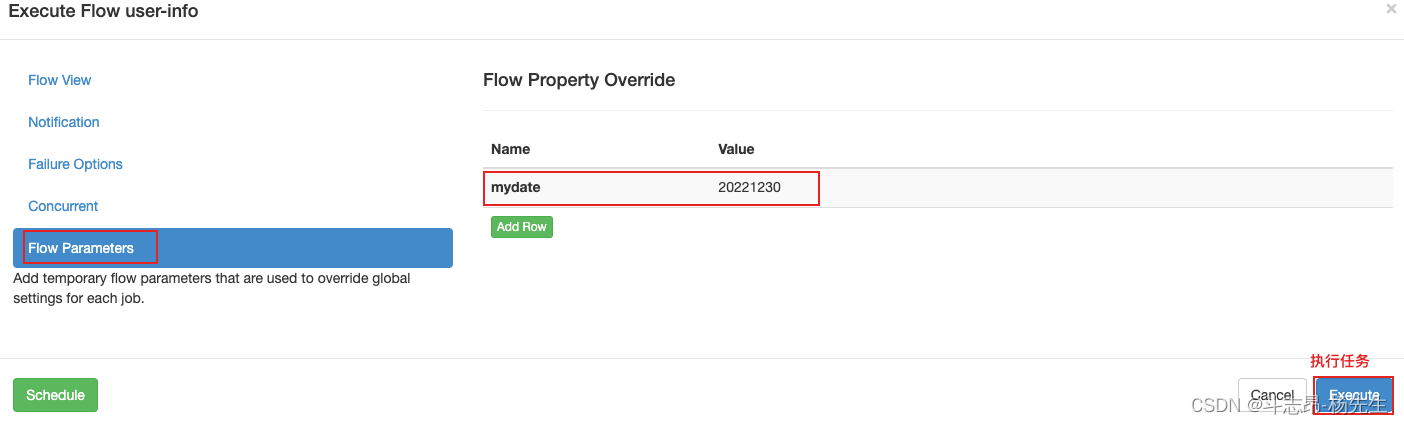
- 查看任务,配置任务参数,并执行
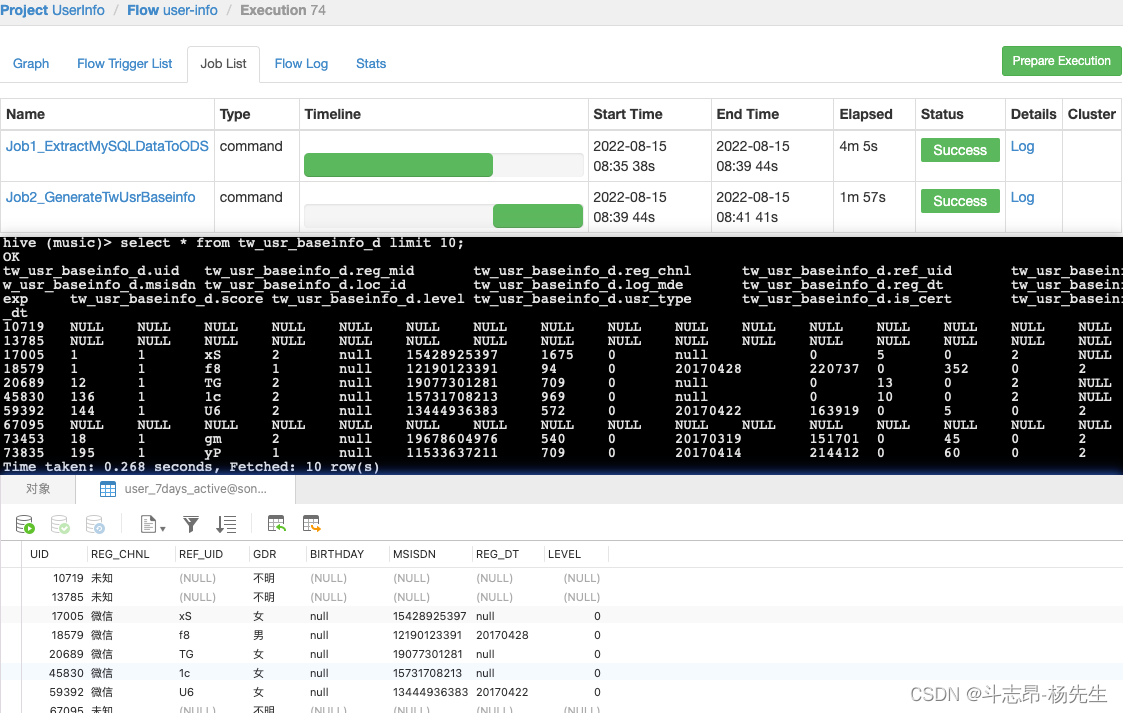
- 执行成功后,最终结果保存到了 mysql 表中
使用Superset数据可视化
- 添加数据表:依次点击 Data → Datasets → 添加,添加“song_result”库下的表“user_7days_active”。
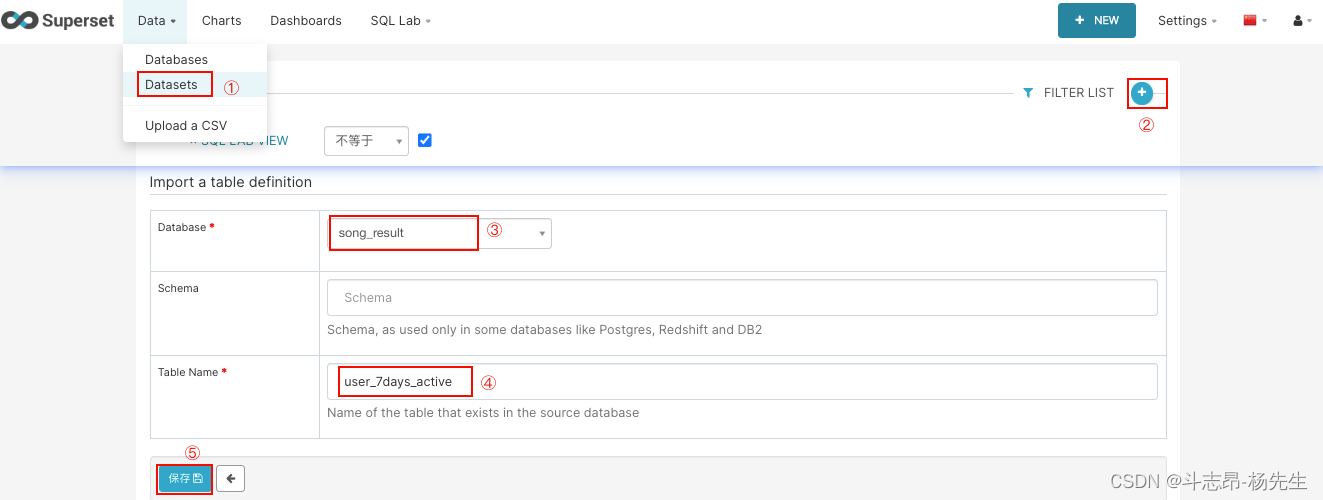
- 修改表中对应字段显示名称:
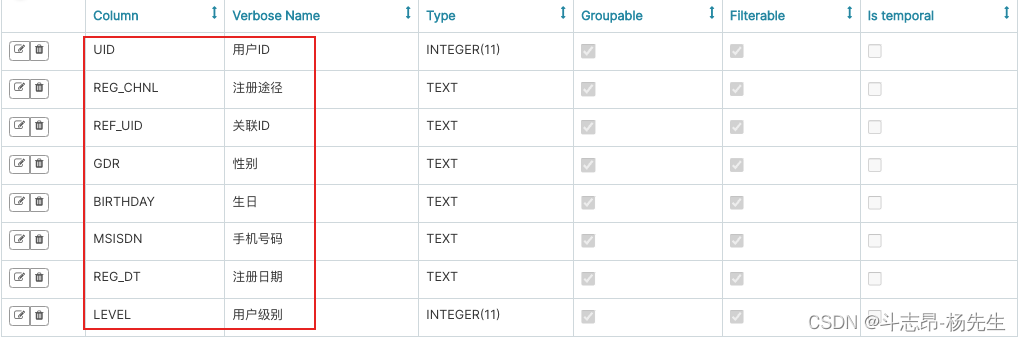
- 处理结果中的空值,例如处理生日如果为空,则显示无信息,“数据源”->“数据表”,找到列标签中对应的生日列,表达式处理空值
case when BIRTHDAY is null then '无信息' when BIRTHDAY = 'null' then '无信息' else BIRTHDAY end
case when REG_DT is null then '无信息' when REG_DT = 'null' then '无信息' else REG_DT end

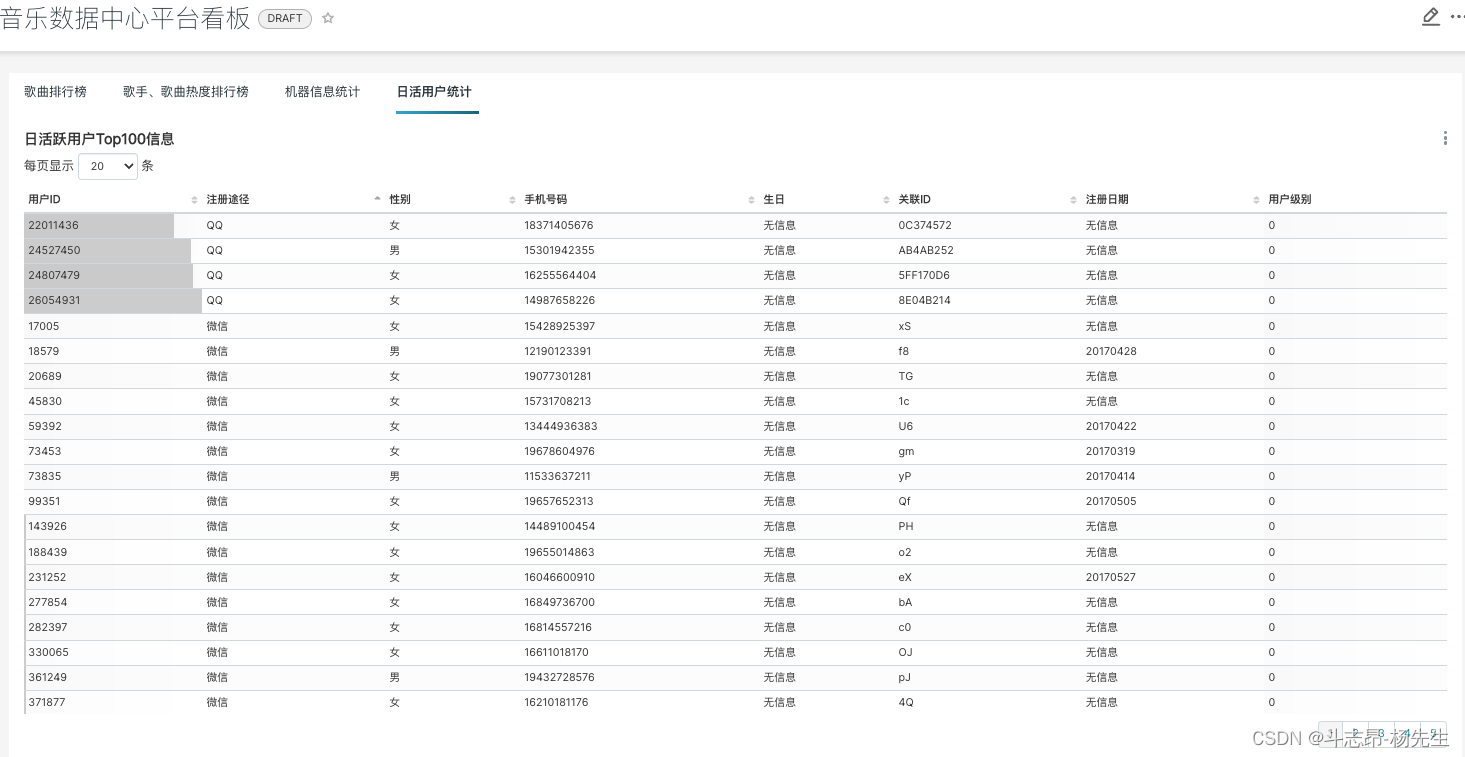
- 编辑图表《日活跃用户Top100信息》:
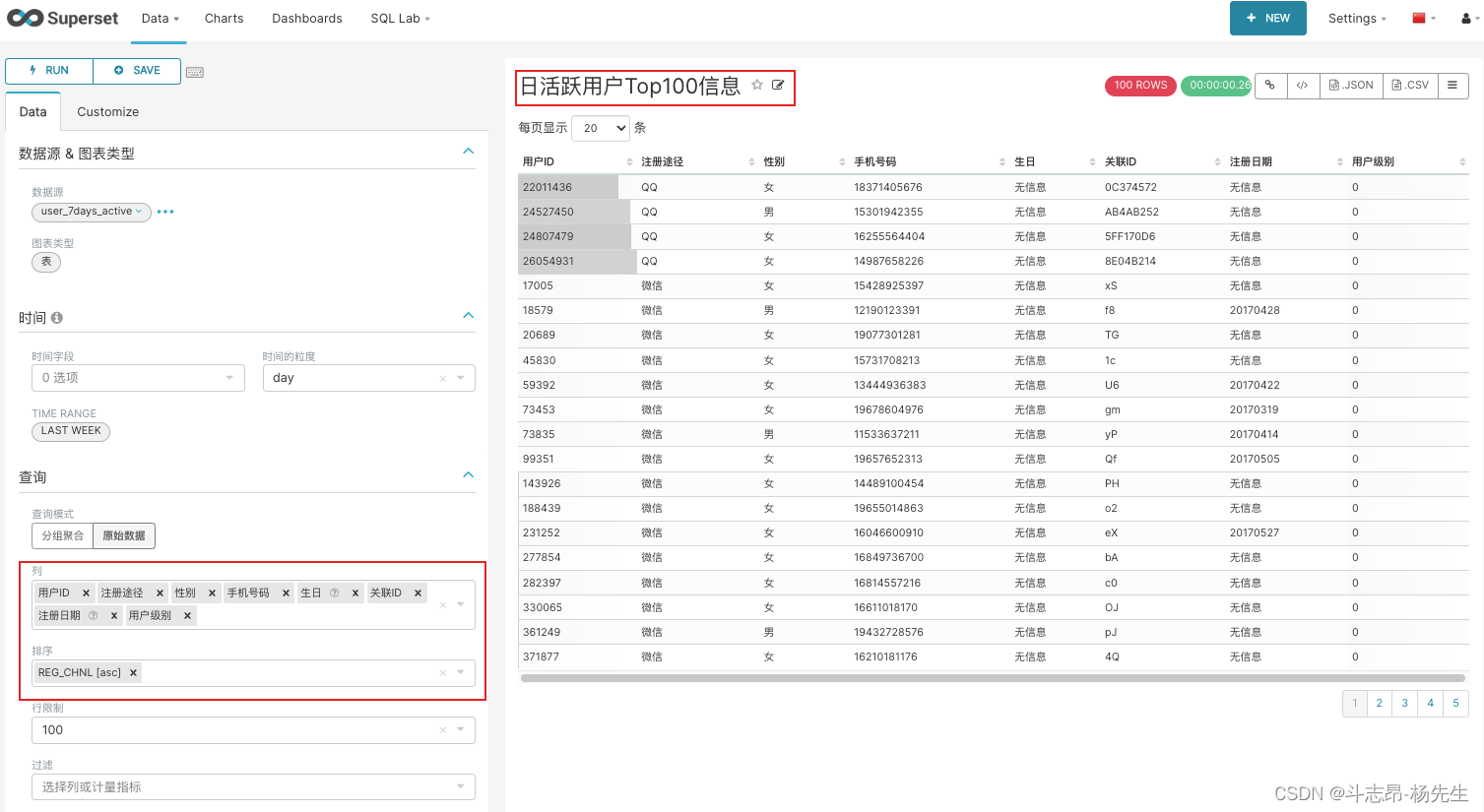
- 最终展示图表: