音乐数据中心平台离线数仓综合项目
第一个业务:歌曲热度与歌手热度排行
业务分析
- 业务需求: 统计歌曲热度、歌手热度
- 用户可以登录机器进行点播歌曲,根据用户过去每日在机器上的点播歌曲统计出最近 1日、7日、30日 歌曲热度及歌手热度
- 需要统计的指标:
- 1日-7日-30日歌曲热度
- 1日-7日-30日歌手热度
需求
数据准备
- 要完成昨日的歌曲热度与歌手热度分析,需要以下两类数据:
歌曲歌手的基本信息
- 这些信息放在业务系统的关系型数据库 MySql song 表中。通过 sqoop 每天定时全量覆盖抽取到数据仓库 Hive 中的 ODS 层中。
- 关于 song 表的结构信息参看 “01-歌曲热度与歌手热度-数据仓库模型” 文件及 mysql 数据 song 表数据。
用户在机器上
- 这部分数据是用户在各个机器上当天的点歌播放行为数据,这些数据是运维每天零点打包以gz压缩文件的方式上传到HDFS平台,这里我们假定将数据 currentday_clientlog.tar.gz 每天凌晨定时上传到HDFS路径 hdfs://mycluster/logdata 中,这里在企业中应当上传到某个以天命名的结构目录下,通过Spark数据清洗将数据存放到Hive数仓ODS层中。关于用户在机器上的点歌行为数据参照 事件上报协议.docx 文档。
- 日志数据如下图所示:

- 事件上报协议:
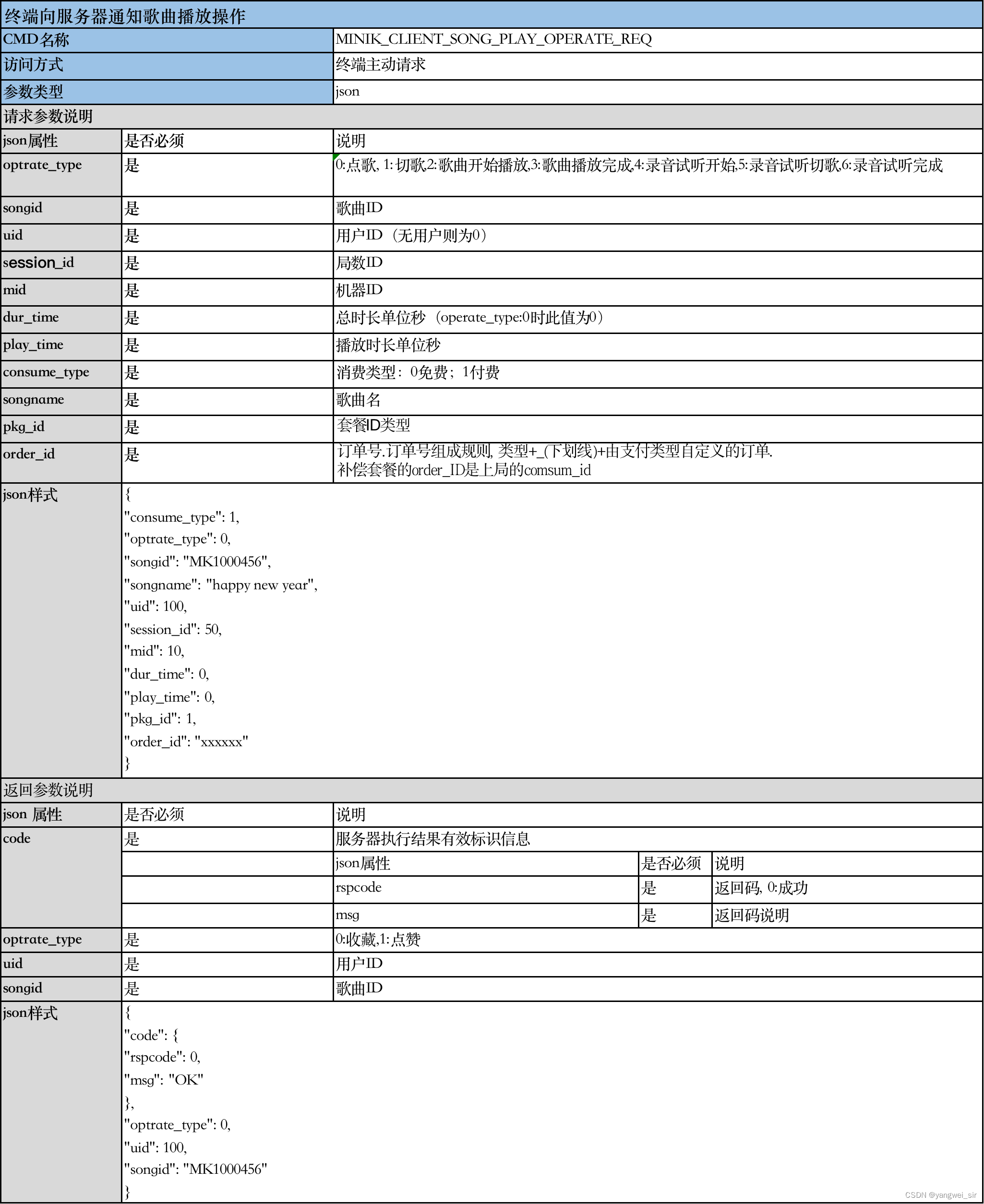
数据仓库分层设计
- 这里根据需求将表分成如下三层:
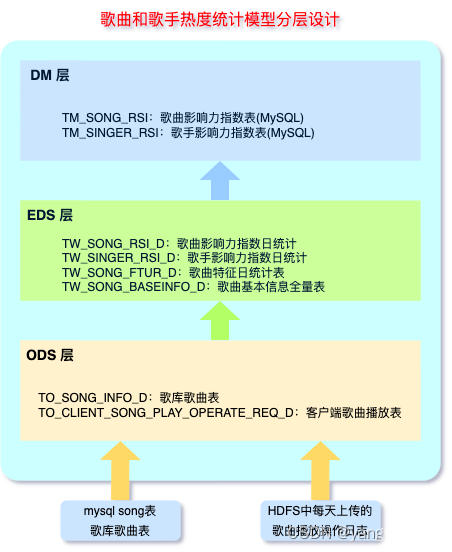
- 基于以上逻辑表建立物理模型如下:
CREATE DATABASE IF NOT EXISTS `music`;
USE `music`;
-- 1. TO_CLIENT_SONG_PLAY_OPERATE_REQ_D 客户端歌曲播放表
CREATE EXTERNAL TABLE IF NOT EXISTS `TO_CLIENT_SONG_PLAY_OPERATE_REQ_D` (
`SONGID` string,
`MID` string,
`OPTRATE_TYPE` string,
`UID` string,
`CONSUME_TYPE` string,
`DUR_TIME` string,
`SESSION_ID` string,
`SONGNAME` string,
`PKG_ID` string,
`ORDER_ID` string
) partitioned by (data_dt string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://node01/user/hive/warehouse/music.db/TO_CLIENT_SONG_PLAY_OPERATE_REQ_D';
-- 2. TO_SONG_INFO_D 歌库歌曲表
CREATE EXTERNAL TABLE IF NOT EXISTS `TO_SONG_INFO_D` (
`NBR` string,
`NAME` string,
`OTHER_NAME` string,
`SOURCE` int,
`ALBUM` string,
`PRDCT` string,
`LANG` string,
`VIDEO_FORMAT` string,
`DUR` int,
`SINGER_INFO` string,
`POST_TIME` string,
`PINYIN_FST` string,
`PINYIN` string,
`SING_TYPE` int,
`ORI_SINGER` string,
`LYRICIST` string,
`COMPOSER` string,
`BPM_VAL` int,
`STAR_LEVEL` int,
`VIDEO_QLTY` int,
`VIDEO_MK` int,
`VIDEO_FTUR` int,
`LYRIC_FTUR` int,
`IMG_QLTY` int,
`SUBTITLES_TYPE` int,
`AUDIO_FMT` int,
`ORI_SOUND_QLTY` int,
`ORI_TRK` int,
`ORI_TRK_VOL` int,
`ACC_VER` int,
`ACC_QLTY` int,
`ACC_TRK_VOL` int,
`ACC_TRK` int,
`WIDTH` int,
`HEIGHT` int,
`VIDEO_RSVL` int,
`SONG_VER` int,
`AUTH_CO` string,
`STATE` int,
`PRDCT_TYPE` string
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://node01/user/hive/warehouse/music.db/TO_SONG_INFO_D';
-- 3. TW_SONG_BASEINFO_D 歌曲基本信息日全量表
CREATE EXTERNAL TABLE IF NOT EXISTS `TW_SONG_BASEINFO_D`(
`NBR` string,
`NAME` string,
`SOURCE` int,
`ALBUM` string,
`PRDCT` string,
`LANG` string,
`VIDEO_FORMAT` string,
`DUR` int,
`SINGER1` string,
`SINGER2` string,
`SINGER1ID` string,
`SINGER2ID` string,
`MAC_TIME` int,
`POST_TIME` string,
`PINYIN_FST` string,
`PINYIN` string,
`SING_TYPE` int,
`ORI_SINGER` string,
`LYRICIST` string,
`COMPOSER` string,
`BPM_VAL` int,
`STAR_LEVEL` int,
`VIDEO_QLTY` int,
`VIDEO_MK` int,
`VIDEO_FTUR` int,
`LYRIC_FTUR` int,
`IMG_QLTY` int,
`SUBTITLES_TYPE` int,
`AUDIO_FMT` int,
`ORI_SOUND_QLTY` int,
`ORI_TRK` int,
`ORI_TRK_VOL` int,
`ACC_VER` int,
`ACC_QLTY` int,
`ACC_TRK_VOL` int,
`ACC_TRK` int,
`WIDTH` int,
`HEIGHT` int,
`VIDEO_RSVL` int,
`SONG_VER` int,
`AUTH_CO` string,
`STATE` int,
`PRDCT_TYPE` array<string>
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS PARQUET
LOCATION 'hdfs://node01/user/hive/warehouse/music.db/TW_SONG_BASEINFO_D';
-- 4. TW_SONG_FTUR_D 歌曲特征日统计表
CREATE EXTERNAL TABLE IF NOT EXISTS `TW_SONG_FTUR_D`(
`NBR` string,
`NAME` string,
`SOURCE` int,
`ALBUM` string,
`PRDCT` string,
`LANG` string,
`VIDEO_FORMAT` string,
`DUR` int,
`SINGER1` string,
`SINGER2` string,
`SINGER1ID` string,
`SINGER2ID` string,
`MAC_TIME` int,
`SING_CNT` int,
`SUPP_CNT` int,
`USR_CNT` int,
`ORDR_CNT` int,
`RCT_7_SING_CNT` int,
`RCT_7_SUPP_CNT` int,
`RCT_7_TOP_SING_CNT` int,
`RCT_7_TOP_SUPP_CNT` int,
`RCT_7_USR_CNT` int,
`RCT_7_ORDR_CNT` int,
`RCT_30_SING_CNT` int,
`RCT_30_SUPP_CNT` int,
`RCT_30_TOP_SING_CNT` int,
`RCT_30_TOP_SUPP_CNT` int,
`RCT_30_USR_CNT` int,
`RCT_30_ORDR_CNT` int
) PARTITIONED BY (data_dt string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://node01/user/hive/warehouse/music.db/TW_SONG_FTUR_D';
-- 5. TW_SINGER_RSI_D 歌手影响力日统计表
CREATE EXTERNAL TABLE IF NOT EXISTS `TW_SINGER_RSI_D`(
`PERIOD` int,
`SINGER_ID` string,
`SINGER_NAME` string,
`RSI` string,
`RSI_RANK` int
) PARTITIONED BY (data_dt string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://node01/user/hive/warehouse/music.db/TW_SINGER_RSI_D';
-- 6. TW_SONG_RSI_D 歌曲影响力日统计表
CREATE EXTERNAL TABLE IF NOT EXISTS `TW_SONG_RSI_D`(
`PERIOD` int,
`NBR` string,
`NAME` string,
`RSI` string,
`RSI_RANK` int
) PARTITIONED BY (data_dt string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION 'hdfs://node01/user/hive/warehouse/music.db/TW_SONG_RSI_D';
- DM层两张表会在后期处理过程中,以 SparkSQL 方式每天覆盖更新到 MySQL 表中,这里不单独建立对应的物理模型。
- 以上各个物理表之间的流转关系如下:
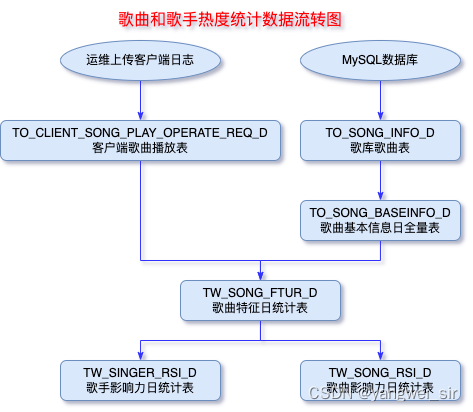
数据处理流程
1. 准备客户端日志,上传至HDFS中
- 将客户端日志 currentday_clientlog.tar.gz 上传至HDFS目录
hdfs://node01/logdata下,如果 HDFS 没有此目录需要先创建这个目录。这里模拟运维人员每天凌晨将数据上传至HDFS中。如果程序在本地运行,上传至当前项目下的 data 目录下,可以在项目 application.conf 进行配置。
2. 清洗客户端日志数据,保存到数仓ODS层
- 这里使用的是Spark读取上传到HDFS目录下的压缩数据,压缩数据中有很多张表,本业务中我们只需要获取客户端歌曲播放日志信息即可,这些数据在日志数据中的标识为 MINIK_CLIENT_SONG_PLAY_OPERATE_REQ,这里读取这些数据进行ETL,保存到 HDFS 目录
hdfs://node01/logdata/all_client_tables下,后期使用 SparkSQL 加载到对应的 Hive 仓库 ODS 层的 TO_CLIENT_SONG_PLAY_OPERATE_REQ_D 客户端歌曲播放表中。 - 对应的处理数据的代码文件:ProduceClientLog.scala,本地运行该程序并查看结果:
- 查看 hive 中数据:
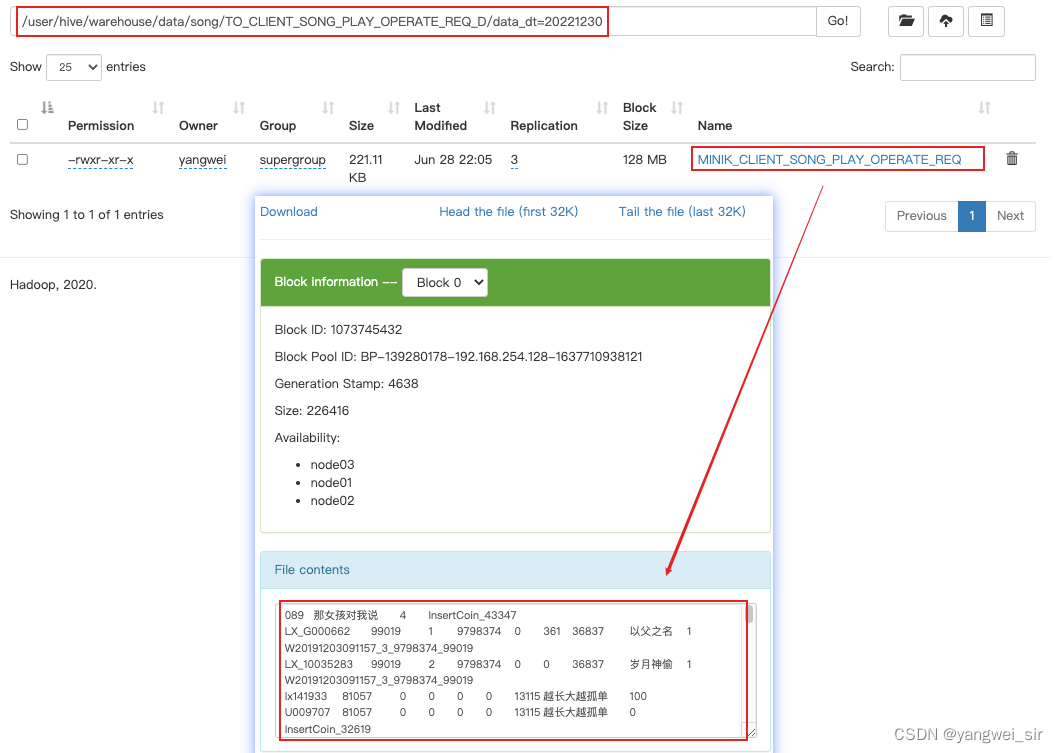
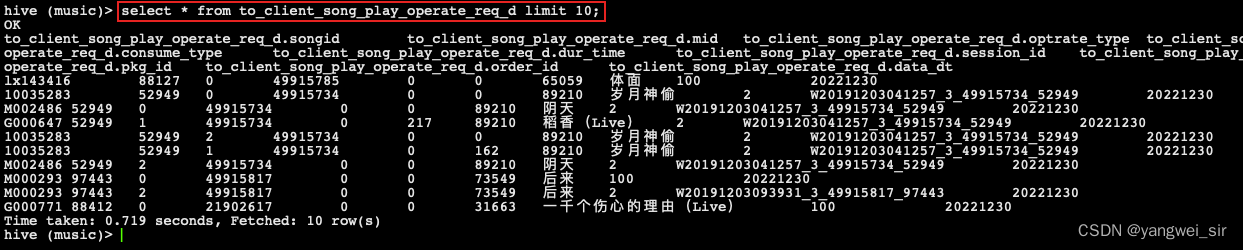
- 至此,我们就得到了 TO_CLIENT_SONG_PLAY_OPERATE_REQ_D 客户端歌曲播放表,客户端日志数据已经导入到 HDFS 中,并将我们对应关注事件的数据存入到 Hive 指定的表中了。
3. 抽取 MySQL 中 song 数据到 Hive ODS
- 将MySQL中的 songdb 库中的 song 表通过 sqoop 抽取到对应的 ODS 层表 TO_SONG_INFO_D 中,这里需要安装 sqoop 工具,每天定时全量覆盖更新到Hive中。
- 在执行导入命令前,先创建 hive 表
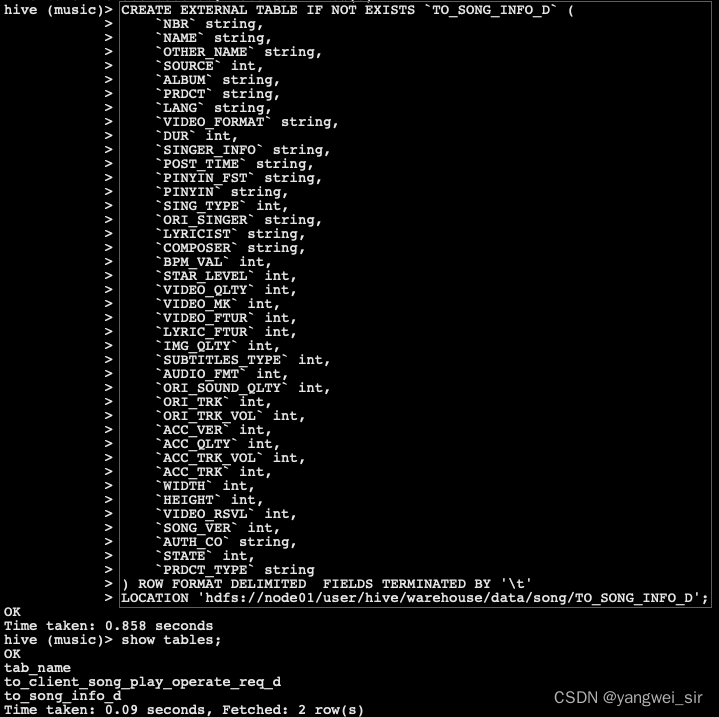
- 在 node03 上执行 sqoop 导入数据脚本,将 MySQL 中的 song 表数据导入到 Hive 数仓 TO_SONG_INFO_D 中,脚本内容如下:
sqoop import --connect jdbc:mysql://node01:3306/songdb?dontTrackOpenResources=true\&defaultFetchSize=10000\&useCursorFetch=true\&useUnicode=yes\&characterEncoding=utf8 --username root --password 123456 --table song --target-dir /user/hive/warehouse/data/song/TO_SONG_INFO_D/ --delete-target-dir --num-mappers 1 --fields-terminated-by '\t'
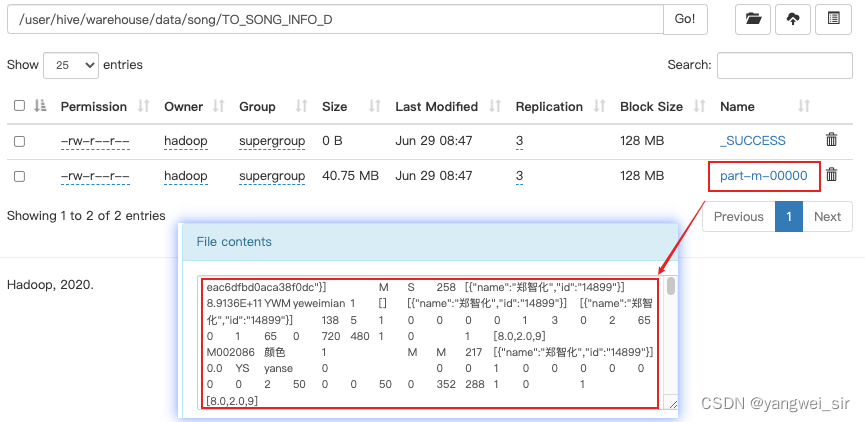
- 查询 hive 表中的数据:

- 至此,我们就得到了 TO_SONG_INFO_D 歌库歌曲表,并将 MySQL 数据库中歌曲的基本信息导入到了 Hive 表中。
Sqoop 后可以指定的参数,解释如下:
- –connect :连接jdbc url
- dontTrackOpenResources=true:你关闭所有的statement和resultset,但是如果你没有关闭connection的话,connection就会引用到statement和resultset上,从而导致GC不能释放这些资源(statement和resultset),当设置参数dontTrackOpenResources=true时,在statement关闭后,resultset也会被关闭,达到节省内存目的。
- defaultFetchSize:设置每次拉取数据量。
- useCursorFetch=true:设置连接属性useCursorFetch=true (5.0版驱动开始支持),表示采用服务器端游标,每次从服务器取fetch_size条数据。
- useUnicode=yes&characterEncoding=utf8:设置编码格式UTF8
- –username:数据库用户名
- –password:数据库密码
- –table:import出的数据库表
- –target-dir:指定数据导入到HDFS中的路径
- –delete-target-dir:如果数据输出目录已存在则先删除
- –num-mappers:当数据导入HDFS中时生成的MR任务使用几个map任务
- –hive-import:将数据从关系数据库中导入到 hive 表中,自动将数据导入到hive中,生成对应–hive-table 指定的表,表中的字段是直接从MySql中映射过来的字段,因此在这里并没有采用这种方式导入
- –hive-database:数据导入Hive中使用的Hive 库
- –hive-overwrite:覆盖掉在 Hive 表中已经存在的数据,与append只能使用一个
- –fields-terminated-by:指定字段列分隔符,默认分隔符是’\001’,建议指定分隔符
- –hive-table:导入的Hive表
4. 清洗“歌库歌曲表”生成“歌曲基本信息日全量表”
- 由ODS层的歌库歌曲表 TO_SONG_INFO_D ETL得到歌曲基本信息日全量表 TW_SONG_BASEINFO_D,主要是对原来数据字段切分、脏数据过滤、时间格式整理、字段提取等操作。
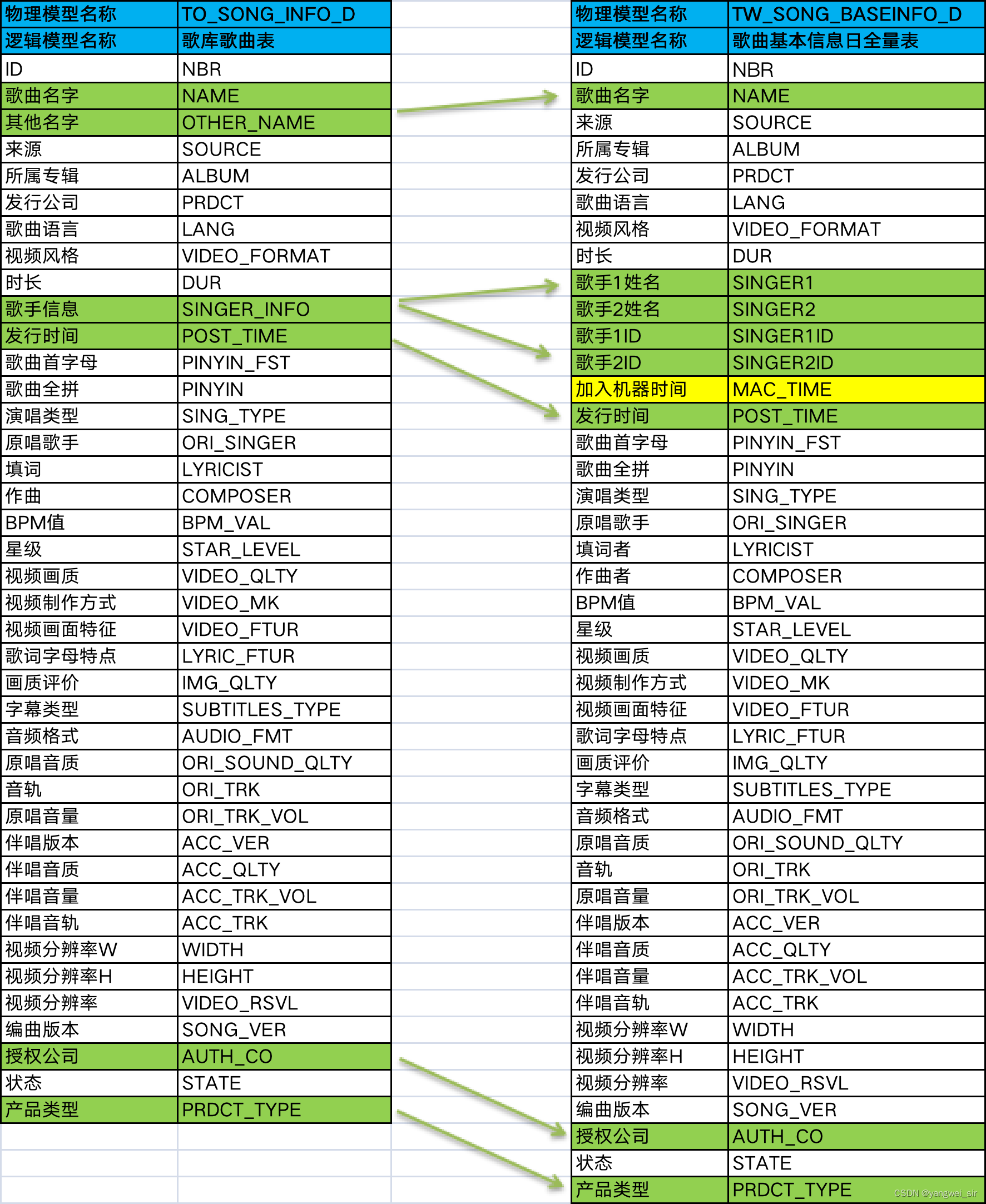
- 创建 hive 表 TW_SONG_BASEINFO_D:
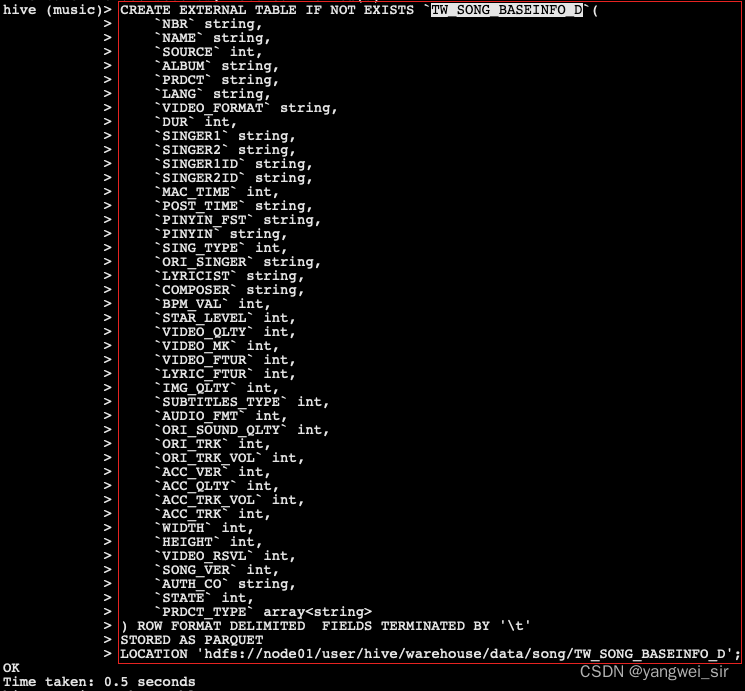
- 对应的 ETL 处理数据的代码文件:GenerateTwSongBaseinfoD.scala,本地运行该程序并查看结果:
- 至此,我们得到了 TO_SONG_BASEINFO_D 歌曲基本信息日全量表,并将 TO_SONG_INFO_D 中的数据清洗存入到该表中。
5. EDS 层生成“歌曲特征日统计表”
- 基于 客户端歌曲播放表 TO_CLIENT_SONG_PLAY_OPERATE_REQ_D 和歌曲基本信息日全量表 TW_SONG_BASEINFO_D,生成歌曲特征日统计表:TW_SONG_FTUR_D,主要是按照两张表的歌曲 ID 进行关联,统计出歌曲在当天、7天、30天内的点唱信息和点赞信息。
- 创建 hive 表 TW_SONG_FTUR_D
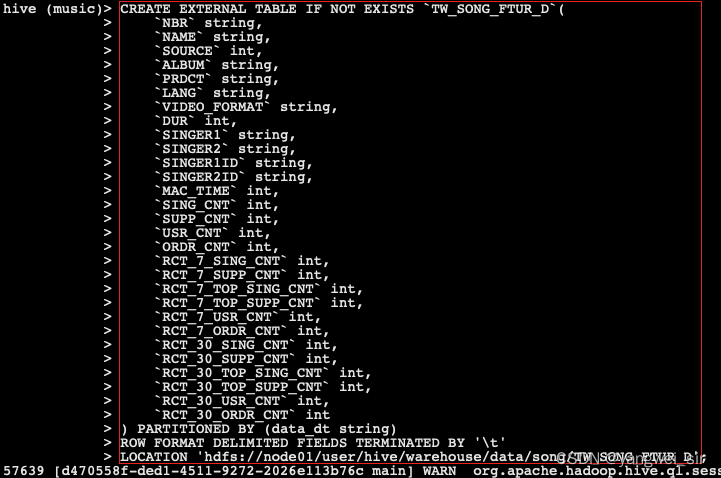
- 对应的数据处理文件:GenerateTwSongFturD.scala,本地运行该程序并查看结果:
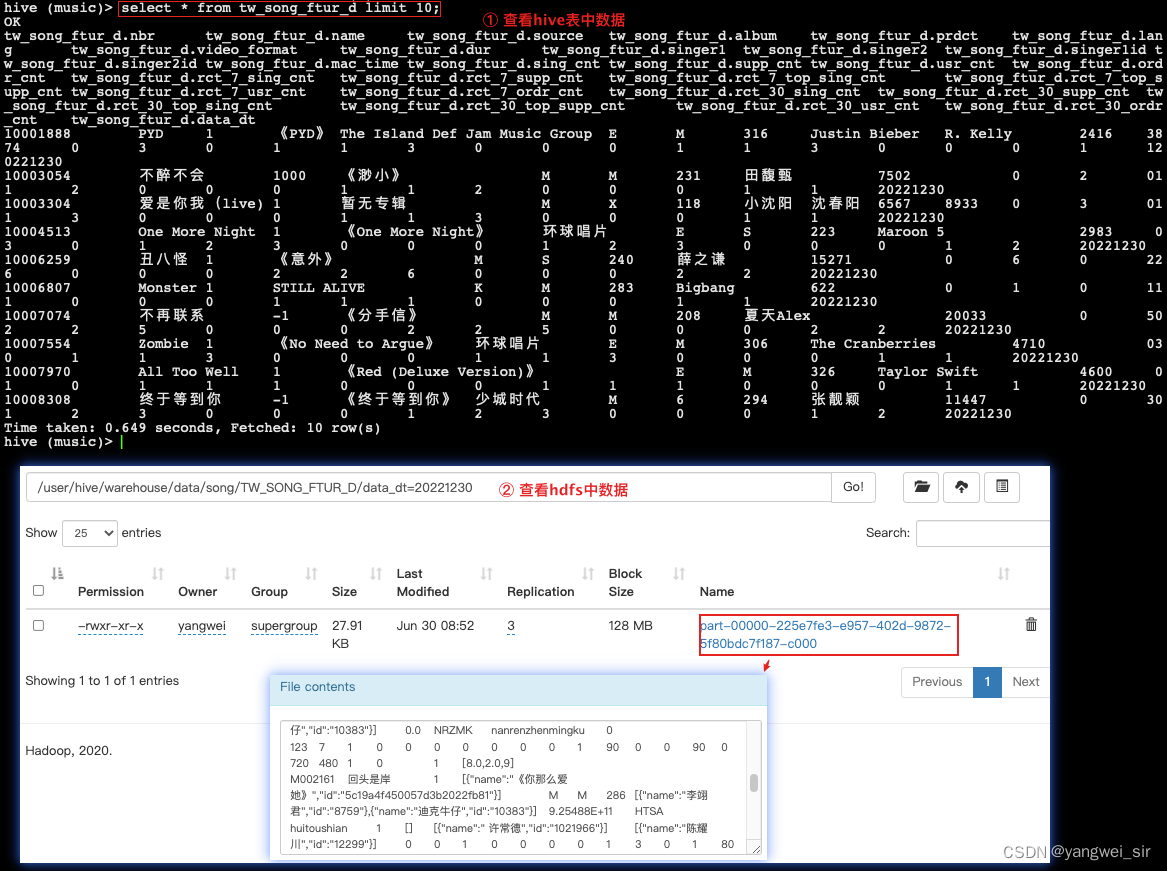
- 至此,我们得到了 TW_SONG_FTUR_D 歌曲特征日统计表,并将统计结果存入到该表中。
6. 统计歌手和歌曲热度
- 这里统计歌手和歌曲热度都是根据歌曲特征日统计表:TW_SONG_FTUR_D 计算得到,主要借助了微信指数来统计对应的歌曲和歌手的热度,统计了当天、近7天、近30天每个歌手和歌曲的热度信息存放在对应的EDS层的歌手影响力指数日统计表 TW_SINGER_RSI_D 和歌曲影响力指数日统计表 TW_SONG_RSI_D。
- 微信传播指数WCI可以显示出微信公众号的热度排名,公式由“清博指数”提供,其计算公式如下:
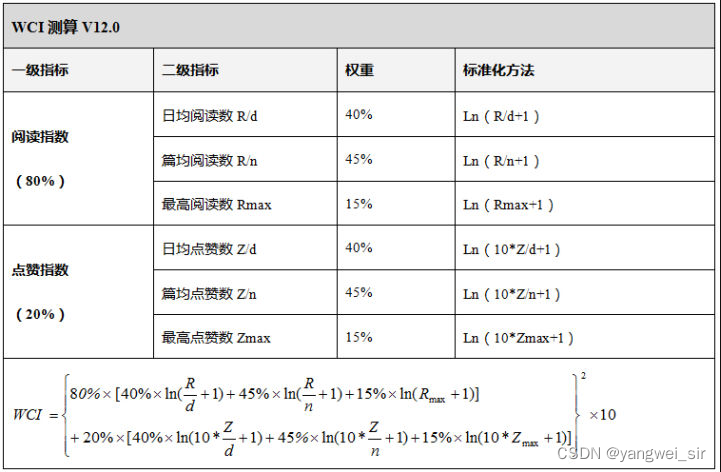
- 说明:
- R 为评估时间段内所有文章(n)的阅读总数,这里可以看成某个歌曲在一段时间内的总点唱数。
- Z 为评估时间段内所有文章(n)的点赞总数,这里可以看成某个歌曲在一段时间内的总点赞数。
- d 为评估时间段内所含天数,一般为周取7天,月取30天,年度取365天,其他自定义时间以真实的天数计算。
- n 为评估时间段内某公众号所发文章数,这里和歌曲无对应。
- Rmax 和 Zmax 为评估时间段内公众号所发文章的最高阅读数和点赞数,这里可以看成某个歌曲在一段时间内的总点唱数和总点赞数。
- 以上指数计算方式对应到歌曲指数计算方式如下:
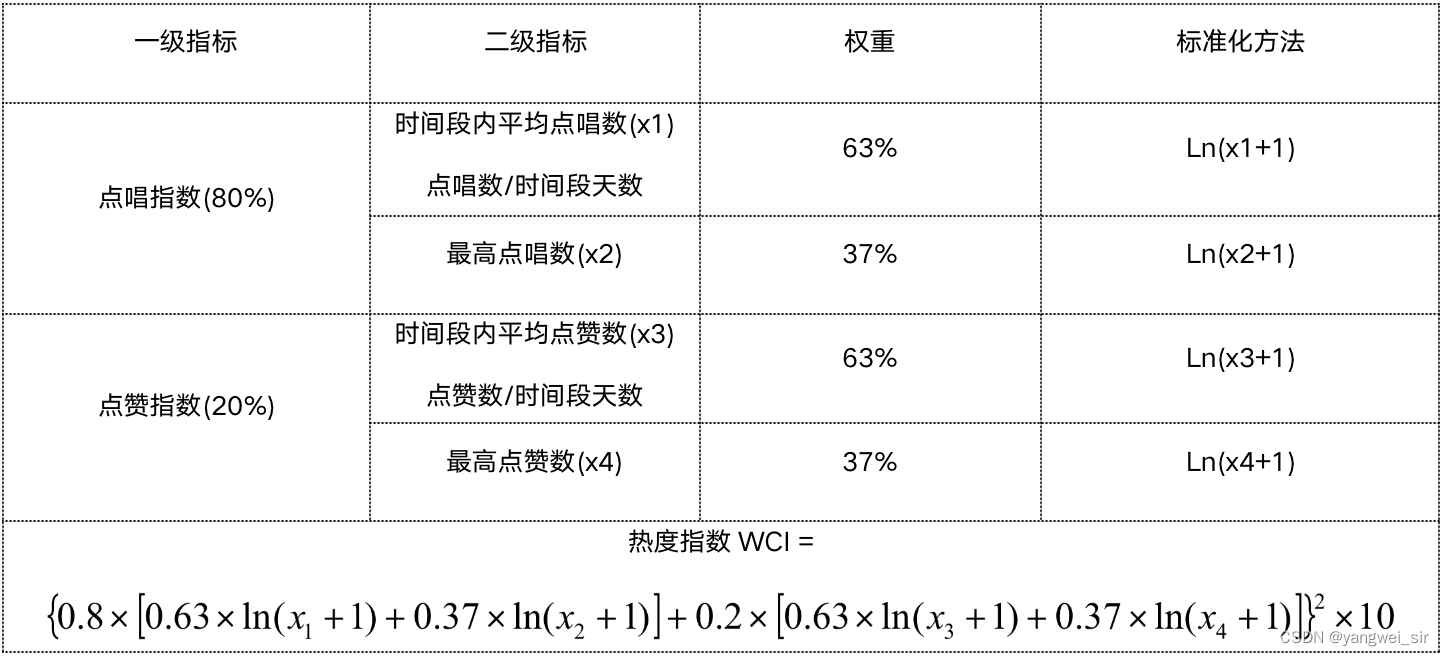
- 在对歌曲特征日统计表 TW_SONG_FTUR_D 进行统计得到 歌手影响力指数日统计表 TW_SINGER_RSI_D 和歌曲影响力指数日统计表 TW_SONG_RSI_D 时,分别还将对应的结果使用 SparkSQL 保存到了 MySQL 中,对应的 MySQL 库为 song_result 库。所以首先创建 MySQL数据库
create database song_result default character set utf8;
- 对应的表分别为:tm_singer_rsi、tm_song_rsi。方便后期从 MySQL 总查看数据结果。
- 首先创建 hive 表 TW_SINGER_RSI_D 和 TW_SONG_RSI_D
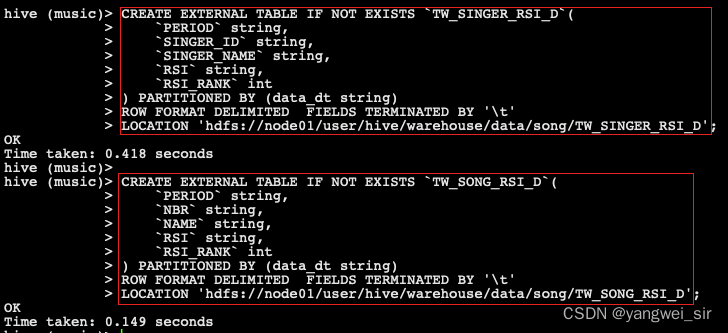
- 对应的数据处理文件:GenerateTmSingerRsiD.scala、GenerateTmSongRsiD.scala,本地运行该程序并查看结果:
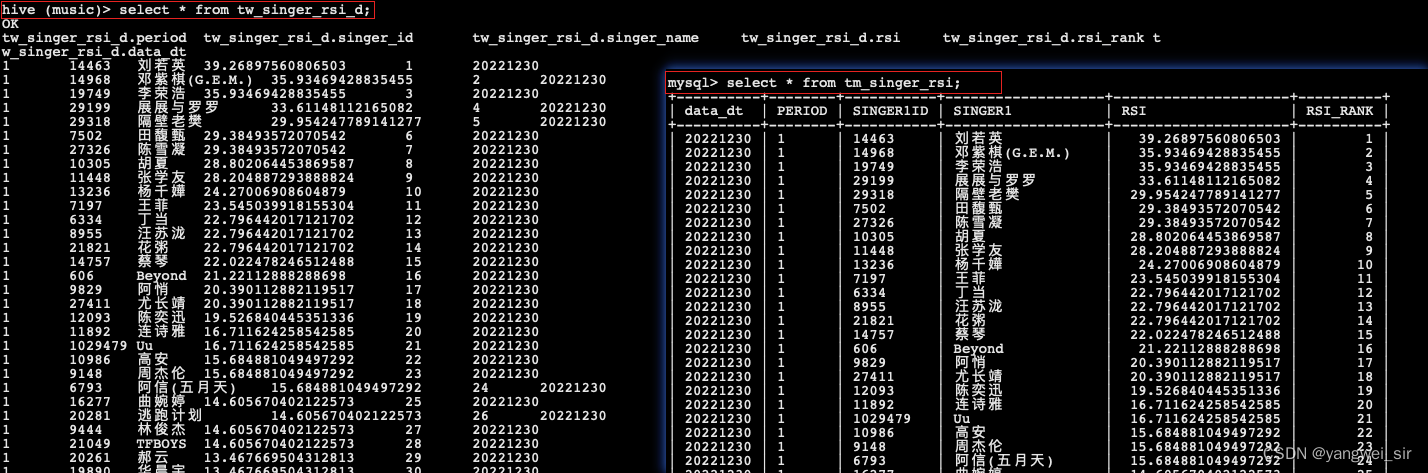
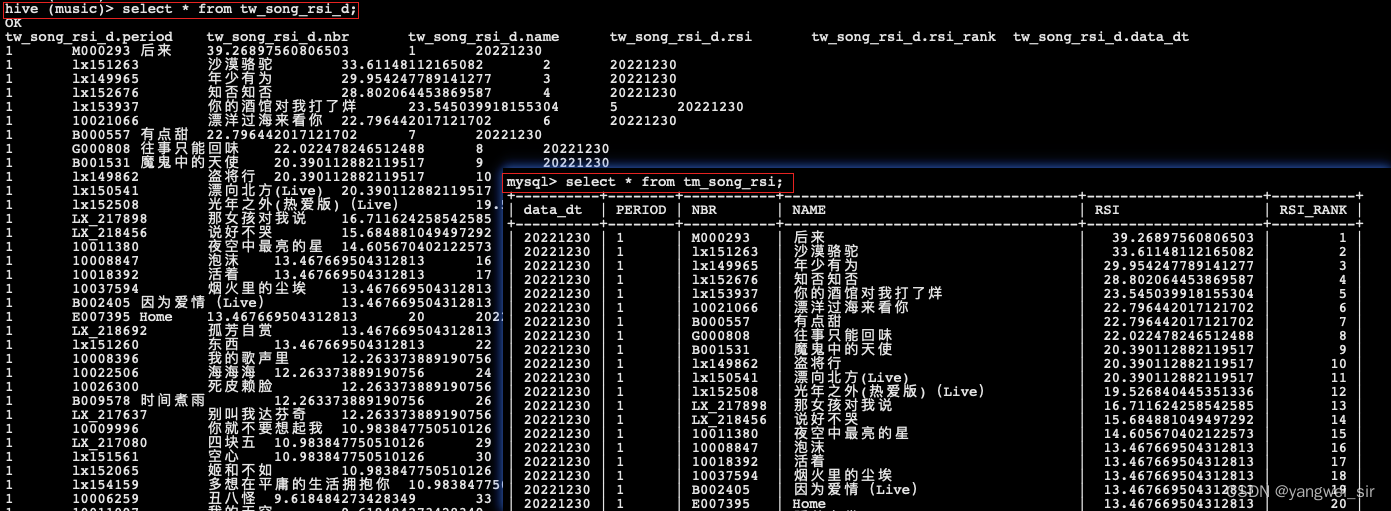
- 至此,我们得到了 TW_SINGER_RSI_D 歌手影响力日统计表 和 TW_SONG_RSI_D 歌曲影响力日统计表,并将统计结果存入到该表中,排名前 30 名的数据还存入到对应的 MySQL 表中。
使用 Azkaban 配置任务流
- 这里使用Azkaban来配置任务流进行任务调度。集群中提交任务,需要修改项目中的 application.conf 文件配置项:local.run=“false”,并打包上传至集群服务器 node01、node02 和 node03 上。
- 保证在 Hive 中对应的表都已经创建好。
1. 脚本准备
- ① 清洗客户端日志脚本
1_produce_clientlog.sh
#!/bin/bash
currentDate=`date -d today +"%Y%m%d"`
if [ x"$1" = x ]; then
echo "====使用自动生成的今天日期===="
else
echo "====使用 Azkaban 传入的日期===="
currentDate=$1
fi
echo "日期为: $currentDate"
ssh hadoop@node01 > /tmp/logs/music_project/music-rsi.log 2>&1 <<aabbcc
hostname
source /etc/profile
spark-submit --master yarn-client --class com.yw.musichw.ods.ProduceClientLog \
/bigdata/data/music_project/musicwh-1.0.0-SNAPSHOT-jar-with-dependencies.jar $currentDate
exit
aabbcc
echo "all done!"
- ② mysql 数据抽取数据到 Hive ODS 脚本
2_extract_mysqldata_to_ods.sh
#!/bin/bash
ssh hadoop@node03 > /tmp/logs/music_project/music-rsi.log 2>&1 <<aabbcc
hostname
source /etc/profile
sqoop import --connect jdbc:mysql://node01:3306/songdb?dontTrackOpenResources=true\&defaultFetchSize=10000\&useCursorFetch=true\&useUnicode=yes\&characterEncoding=utf8 \
--username root --password 123456 --table song --target-dir /user/hive/warehouse/music.db/TO_SONG_INFO_D/ \
--delete-target-dir --num-mappers 1 --fields-terminated-by '\t'
exit
aabbcc
echo "all done!"
- ③ 清洗歌库歌曲表脚本
3_generate_tw_song_baseinfo.sh
#!/bin/bash
currentDate=`date -d today +"%Y%m%d"`
if [ x"$1" = x ]; then
echo "====使用自动生成的今天日期===="
else
echo "====使用 Azkaban 传入的日期===="
currentDate=$1
fi
echo "日期为: $currentDate"
ssh hadoop@node01 > /tmp/logs/music_project/music-rsi.log 2>&1 <<aabbcc
hostname
source /etc/profile
spark-submit --master yarn-client --class com.yw.musichw.eds.content.GenerateTwSongBaseinfoD \
/bigdata/data/music_project/musicwh-1.0.0-SNAPSHOT-jar-with-dependencies.jar $currentDate
exit
aabbcc
echo "all done!"
- ④ 生成歌曲特征日统计表脚本
4_generate_tw_song_ftur.sh
#!/bin/bash
currentDate=`date -d today +"%Y%m%d"`
if [ x"$1" = x ]; then
echo "====使用自动生成的今天日期===="
else
echo "====使用 Azkaban 传入的日期===="
currentDate=$1
fi
echo "日期为: $currentDate"
ssh hadoop@node01 > /tmp/logs/music_project/music-rsi.log 2>&1 <<aabbcc
hostname
source /etc/profile
spark-submit --master yarn-client --class com.yw.musichw.eds.content.GenerateTwSongFturD \
/bigdata/data/music_project/musicwh-1.0.0-SNAPSHOT-jar-with-dependencies.jar $currentDate
exit
aabbcc
echo "all done!"
- ⑤ 生成歌手热度脚本
5_generate_tm_singer_rsi.sh
#!/bin/bash
currentDate=`date -d today +"%Y%m%d"`
if [ x"$1" = x ]; then
echo "====使用自动生成的今天日期===="
else
echo "====使用 Azkaban 传入的日期===="
currentDate=$1
fi
echo "日期为: $currentDate"
ssh hadoop@node01 > /tmp/logs/music_project/music-rsi.log 2>&1 <<aabbcc
hostname
source /etc/profile
spark-submit --master yarn-client --class com.yw.musichw.dm.content.GenerateTmSingerRsiD \
/bigdata/data/music_project/musicwh-1.0.0-SNAPSHOT-jar-with-dependencies.jar $currentDate
exit
aabbcc
echo "all done!"
- ⑥ 生成歌手热度脚本
6_generate_tm_song_rsi.sh
#!/bin/bash
currentDate=`date -d today +"%Y%m%d"`
if [ x"$1" = x ]; then
echo "====使用自动生成的今天日期===="
else
echo "====使用 Azkaban 传入的日期===="
currentDate=$1
fi
echo "日期为: $currentDate"
ssh hadoop@node01 > /tmp/logs/music_project/music-rsi.log 2>&1 <<aabbcc
hostname
source /etc/profile
spark-submit --master yarn-client --class com.yw.musichw.dm.content.GenerateTmSongRsiD \
/bigdata/data/music_project/musicwh-1.0.0-SNAPSHOT-jar-with-dependencies.jar $currentDate
exit
aabbcc
echo "all done!"
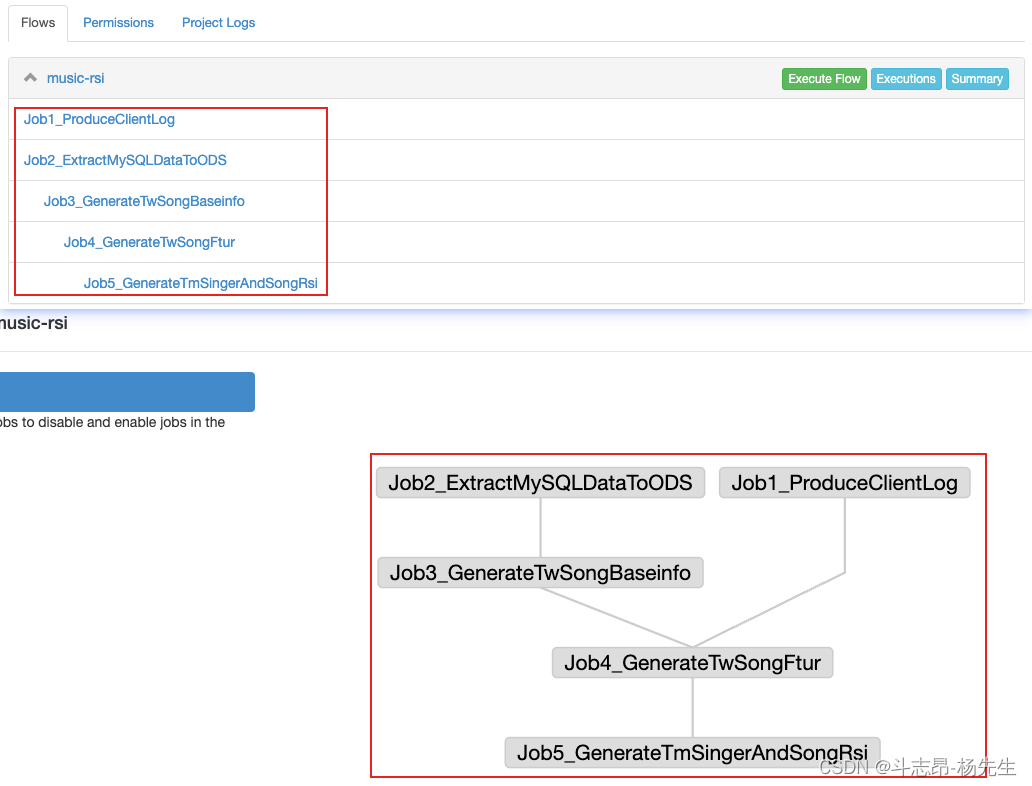
2. 编写 Azkaban 各个Job组成任务流
- 新建
flow20.project,内容如下:
azkaban-flow-version: 2.0
- 新建
music-rsi.flow,内容如下:
nodes:
- name: Job1_ProduceClientLog
type: command
config:
command: sh 1_produce_clientlog.sh ${mydate}
- name: Job2_ExtractMySQLDataToODS
type: command
config:
command: sh 2_extract_mysqldata_to_ods.sh
- name: Job3_GenerateTwSongBaseinfo
type: command
config:
command: sh 3_generate_tw_song_baseinfo.sh
dependsOn:
- Job2_ExtractMySQLDataToODS
- name: Job4_GenerateTwSongFtur
type: command
config:
command: sh 4_generate_tw_song_ftur.sh ${mydate}
dependsOn:
- Job1_ProduceClientLog
- Job3_GenerateTwSongBaseinfo
- name: Job5_GenerateTmSingerAndSongRsi
type: command
config:
command: sh 5_generate_tm_singer_rsi.sh ${mydate}
command.1: sh 6_generate_tm_song_rsi.sh ${mydate}
dependsOn:
- Job4_GenerateTwSongFtur
- 将以上六个脚本文件、
music-rsi.flow与flow20.project压缩生成 zip 文件music-rsi.zip
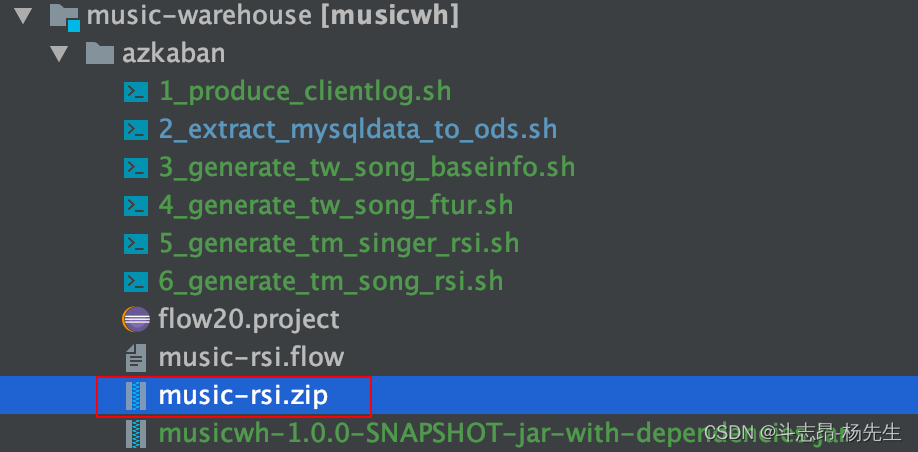
3. 清空数据
- 由于前面我们在本地已经将整个数据处理流程跑过一次,现在 hive 和 mysql 中已经存在数据。在提交作业执行前,先清除掉 hive 和 mysql 中的数据。
- 编写脚本
vim drop_song_tables.sql,内容如下:
drop table `music`.`to_client_song_play_operate_req_d`;
drop table `music`.`to_song_info_d`;
drop table `music`.`tw_singer_rsi_d`;
drop table `music`.`tw_song_baseinfo_d`;
drop table `music`.`tw_song_ftur_d`;
drop table `music`.`tw_song_rsi_d`;
- 执行命令:
hive -f drop_song_tables.sql,删除表。由于这些都是外部表,真正的数据还在 HDFS,所以还需要删除相关的数据。
- 然后重新创建 hive 表,编写脚本
vim create_song_tables.sql,内容在前面”数据仓库分层设计“这一小节。 - 执行命令
hive -f create_song_tables.sql,创建表。 - 删除 mysql 中生成结果的两张表
tm_singer_rsi和tm_song_rsi。 - 把之前的日志数据也清空掉,并执行命令
hdfs dfs -put currentday_clientlog.tar.gz /logdata/上传客户端日志数据
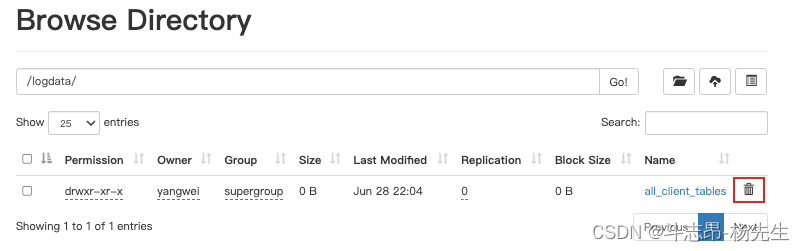
4. 提交Azkaban作业
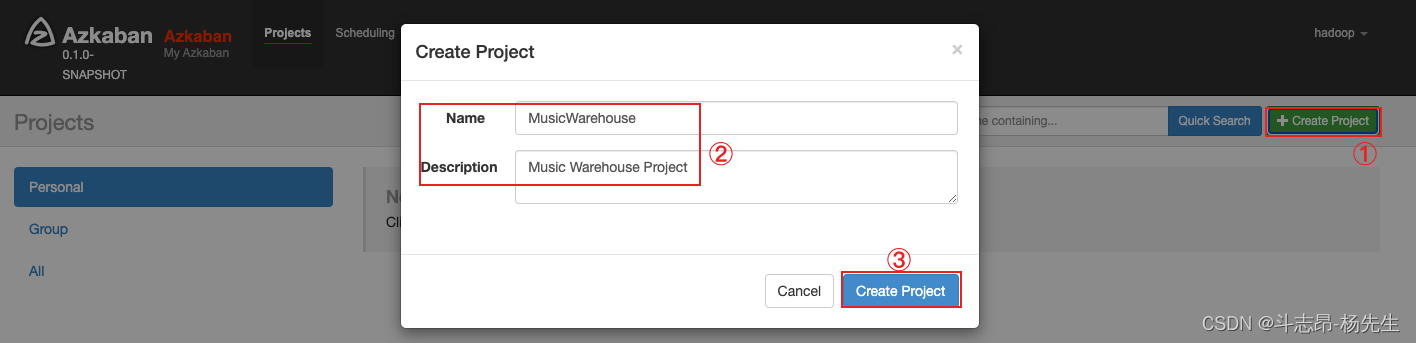
- 在 Azkaban 的 web server ui界面创建项目
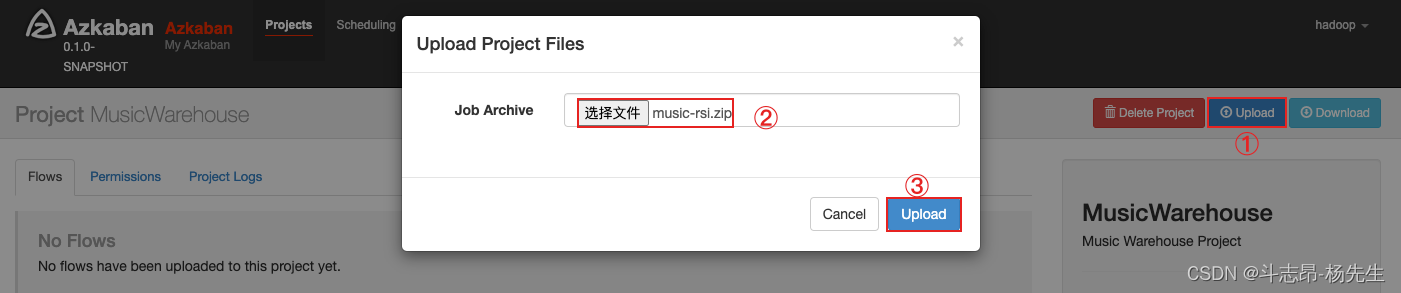
- 然后上传项目 zip 文件
music-rsi.zip
- 查看任务
- 配置任务参数
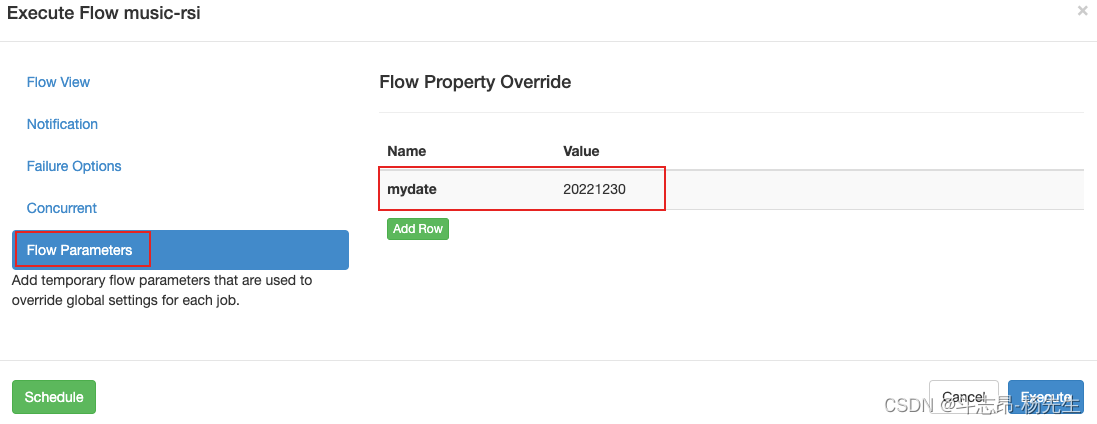
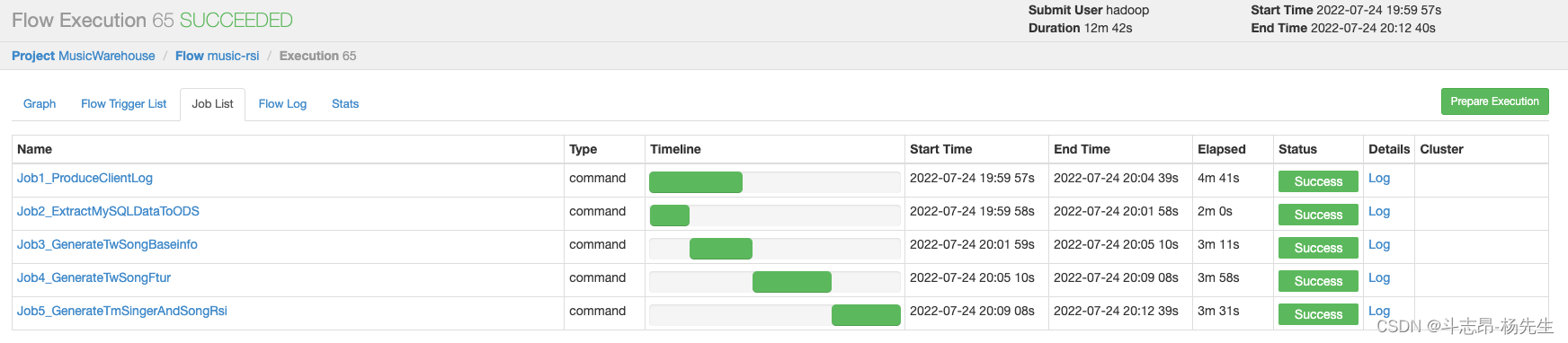
- 执行成功,最终结果保存到了 mysql 表中。
5. 遇到的问题
Access denied for user ‘root‘@‘centos128‘ (using password: YES)
- 解决办法:把远程访问的%改成主机名即可
mysql> grant all privileges on *.* to 'root'@'centos128'' identified by '123456' with grant option;
mysql> flush privileges;
InnoDB is limited to row-logging when transaction isolation level is READ COMMITTED or READ UNCOMMITTED.
- 解决办法:修改配置文件
vim /etc/my.cnf,增加参数binlog_format=row,然后重启 mysql,systemctl restart mysqld

使用Superset数据可视化
1. superset环境搭建
2. 在superset中设计表可视化
- 登录 superset:http://192.168.254.130:8088/
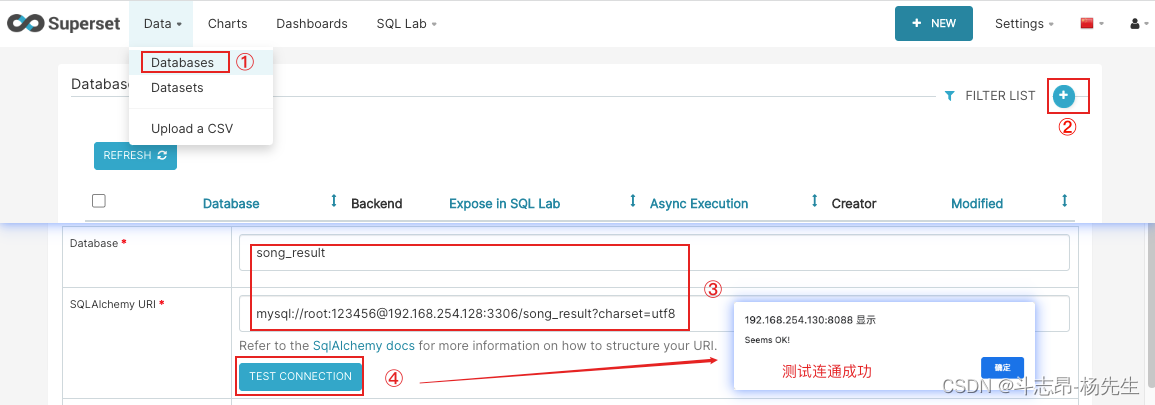
- 添加数据源:依次点击 Data → Databases → 添加,配置 jdbc 连接串,并测试连通性OK后保存。
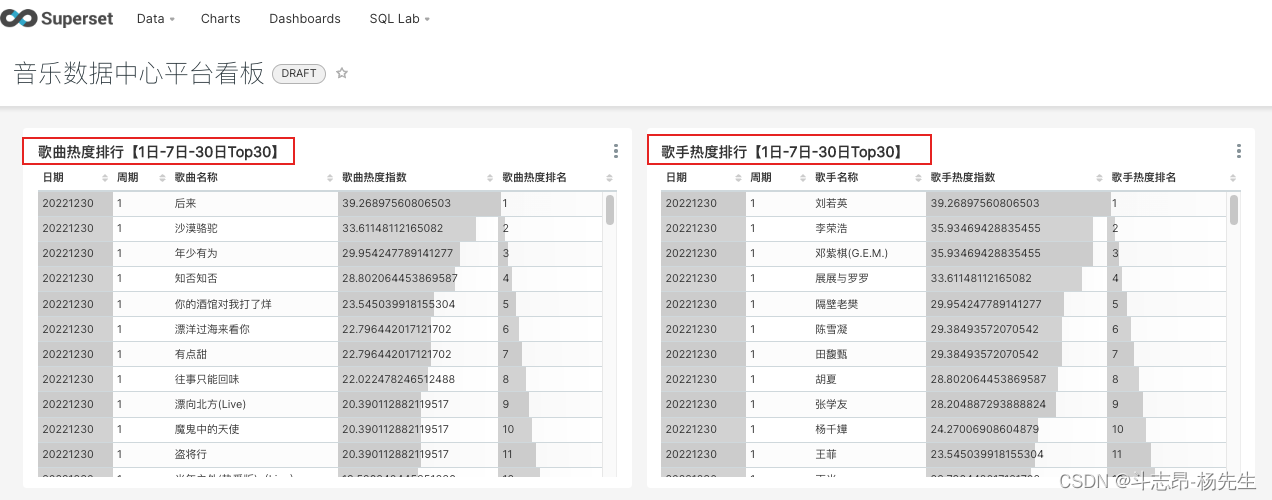
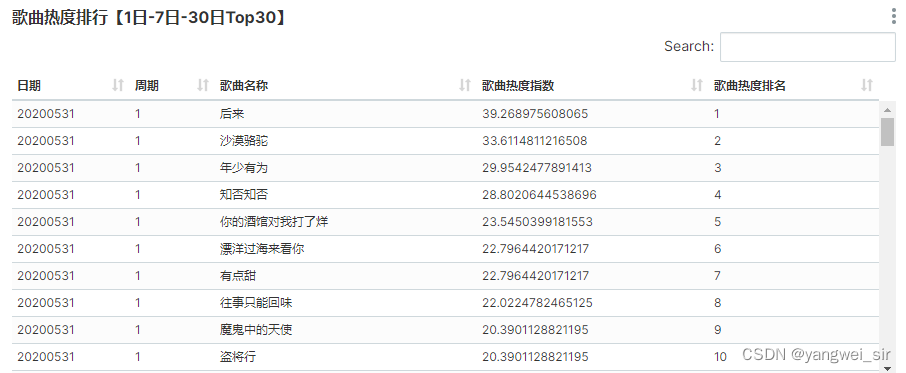
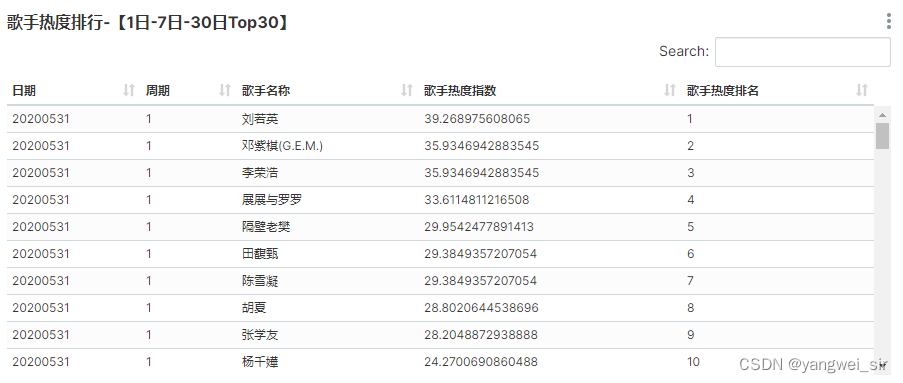
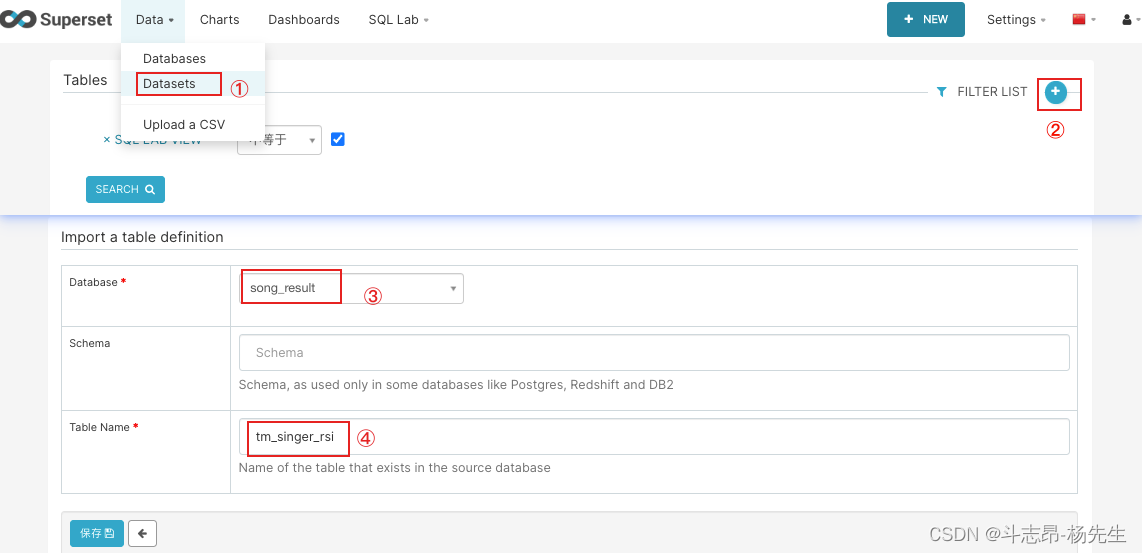
- 添加数据表:依次点击 Data → Datasets → 添加,添加“songresult”库下的表“tm_singer_rsi”和“tm_song_rsi”。
- 修改表中对应字段显示名称:编辑表记录,找到列标签,编辑各个列的全称

- 编辑图表:
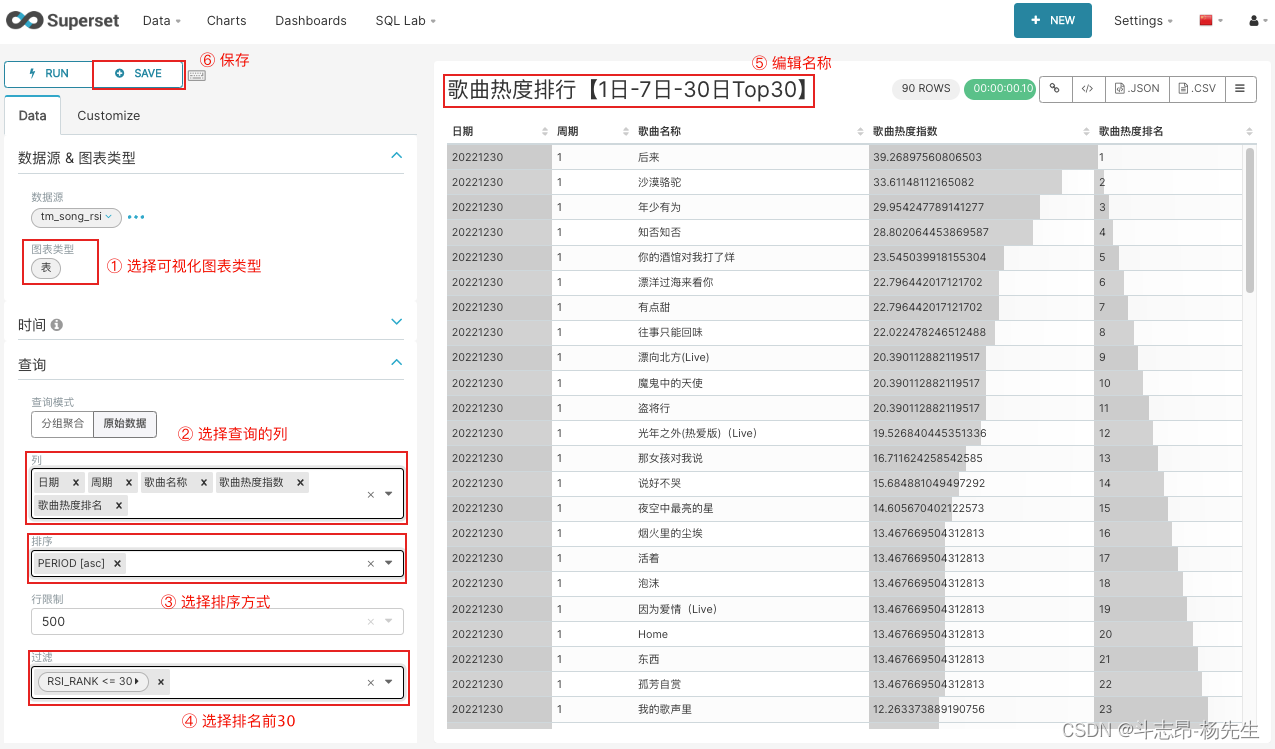
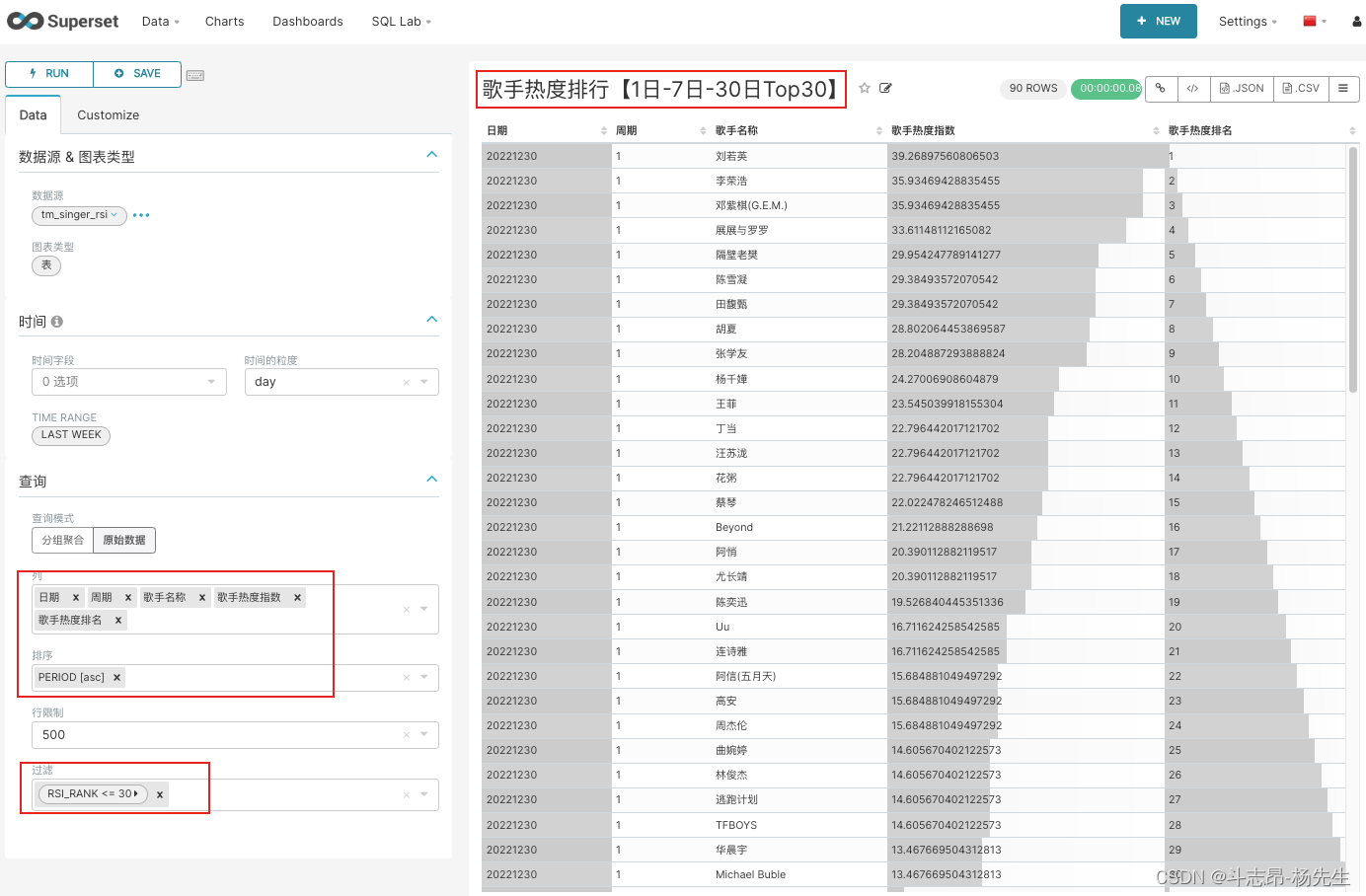
- 面板可视化展示: