【深度学习】【RKNN】【C++】应用程序编程接口化处理详细教程
提示:博主取舍了很多大佬的博文并亲测有效,分享笔记邀大家共同学习讨论
文章目录
前言
应用程序编程接口(API)是软件工程中的一种常见做法,本博文将RKNPU2推理代码拆分为不同的API,旨在提高代码的可维护性、复用性和模块化。这样做可以让你的应用更加灵活,更容易扩展,并且可以支持并发开发。
这里需要先学习一下【深度学习】【RKNN】【C++】模型转化、环境搭建以及模型部署的详细教程,本博文是其后续补充。
下列是拆分成不同API后的工程结构总览:
AlexNet_API
└── 3rdparty
├── opencv
| ├── opencv-linux-aarch64
└── librknn_api
├── aarch64
| ├── vlibrknnrt.so
├── include
| ├── rknn_api.h
| ├── rknn_matmul_api.h
└── src
├── engine
| ├── engine.h
| ├── rknn_engine.cpp
| ├── rknn_engine.h
├── process
| ├── postprocess.cpp
| ├── postprocess.h
| ├── preprocess.cpp
| ├── preprocess.h
├── types
| ├── datatype.h
| ├── error.h
├── utils
| ├── engine_helper.h
| ├── logging.h
└── weights
├── AlexNet.rknn
└── CMakeLists.txt
封装RKNN API
NNEngine引擎接口
定义NNEngine抽象类:不能实例化,全部使用纯虚函数,只能作为不同板子的基类使用,使得不同的引擎的接口一致,方便使用,也可以隐藏不同引擎的实现细节,方便维护。
engine.h
// 接口定义
// 预处理器指令 用于防止头文件的重复包含
#ifndef RK3566_DEMO_ENGINE_H
#define RK3566_DEMO_ENGINE_H
#include "types/error.h"
#include "types/datatype.h"
#include <vector>
#include <memory>
class NNEngine
{
public:
virtual ~NNEngine(){}; // 析构函数
virtual nn_error_e LoadModelFile(const char *model_file) = 0; // 加载模型文件,=0表示纯虚函数,必须在子类中实现
virtual const std::vector<tensor_attr_s> &GetInputShapes() = 0; // 获取输入张量的形状
virtual const std::vector<tensor_attr_s> &GetOutputShapes() = 0; // 获取输出张量的形状
virtual nn_error_e Run(std::vector<tensor_data_s> &inputs, std::vector<tensor_data_s> &outpus, bool want_float) = 0; // 运行模型
};
std::shared_ptr<NNEngine> CreateRKNNEngine(); // 智能指针类避免内存泄漏 创建RKNN引擎
#endif // RK3566_DEMO_ENGINE_H
RKEngine引擎接口以及实现
rknn_engine.h
继承自NNEngine接口:新增了部分私有变量。
#ifndef RK3566_DEMO_RKNN_ENGINE_H
#define RK3566_DEMO_RKNN_ENGINE_H
#include "engine.h"
#include <vector>
#include <rknn_api.h>
// 实现NNEngine的接口
class RKEngine : public NNEngine
{
public:
RKEngine() : rknn_ctx_(0), ctx_created_(false), input_num_(0), output_num_(0){}; // 构造函数 初始化
~RKEngine() override; // 析构函数
nn_error_e LoadModelFile(const char *model_file) override; // 加载模型文件
const std::vector<tensor_attr_s> &GetInputShapes() override; // 获取输入张量的形状
const std::vector<tensor_attr_s> &GetOutputShapes() override; // 获取输出张量的形状
nn_error_e Run(std::vector<tensor_data_s> &inputs, std::vector<tensor_data_s> &outputs, bool want_float) override; // 运行模型
private:
// rknn context
rknn_context rknn_ctx_; // rknn context
bool ctx_created_; // rknn context是否创建
uint32_t input_num_; // 输入的数量
uint32_t output_num_; // 输出的数量
std::vector<tensor_attr_s> in_shapes_; // 输入张量的形状
std::vector<tensor_attr_s> out_shapes_; // 输出张量的形状
};
#endif // RK3566_DEMO_RKNN_ENGINE_H
rknn_engine.cpp
实现NNEngine:主要为加载模型和推理模型俩个函数。加载模型函数主要将核心流程中的初始化RKNN模型、获取模型输入输出信息部分整合在一起;推理模型函数则将设置输入、执行推理以及获取输出部分整合在一起。
// rknn_engine.h的实现
#include "rknn_engine.h"
#include <string.h>
#include "utils/engine_helper.h"
#include "utils/logging.h"
static const int g_max_io_num = 10; // 最大输入输出张量的数量
/**
* @brief 加载模型文件、初始化rknn context、获取rknn版本信息、获取输入输出张量的信息
* @param model_file 模型文件路径
* @return nn_error_e 错误码
*/
nn_error_e RKEngine::LoadModelFile(const char *model_file)
{
int model_len = 0; // 模型文件大小
auto model = load_model(model_file, &model_len); // 加载模型文件
if (model == nullptr)
{
NN_LOG_ERROR("load model file %s fail!", model_file);
return NN_LOAD_MODEL_FAIL; // 返回错误码:加载模型文件失败
}
int ret = rknn_init(&rknn_ctx_, model, model_len, 0, NULL); // 初始化rknn context
if (ret < 0)
{
NN_LOG_ERROR("rknn_init fail! ret=%d", ret);
return NN_RKNN_INIT_FAIL; // 返回错误码:初始化rknn context失败
}
// 打印初始化成功信息
NN_LOG_INFO("rknn_init success!");
ctx_created_ = true;
// 获取rknn版本信息
rknn_sdk_version version;
ret = rknn_query(rknn_ctx_, RKNN_QUERY_SDK_VERSION, &version, sizeof(rknn_sdk_version));
if (ret < 0)
{
NN_LOG_ERROR("rknn_query fail! ret=%d", ret);
return NN_RKNN_QUERY_FAIL;
}
// 打印rknn版本信息
NN_LOG_INFO("RKNN API version: %s", version.api_version);
NN_LOG_INFO("RKNN Driver version: %s", version.drv_version);
// 获取输入输出个数
rknn_input_output_num io_num;
ret = rknn_query(rknn_ctx_, RKNN_QUERY_IN_OUT_NUM, &io_num, sizeof(io_num));
if (ret != RKNN_SUCC)
{
NN_LOG_ERROR("rknn_query fail! ret=%d", ret);
return NN_RKNN_QUERY_FAIL;
}
NN_LOG_INFO("model input num: %d, output num: %d", io_num.n_input, io_num.n_output);
// 保存输入输出个数
input_num_ = io_num.n_input;
output_num_ = io_num.n_output;
// 输入属性
NN_LOG_INFO("input tensors:");
rknn_tensor_attr input_attrs[io_num.n_input];
memset(input_attrs, 0, sizeof(input_attrs));
for (int i = 0; i < io_num.n_input; i++)
{
input_attrs[i].index = i;
ret = rknn_query(rknn_ctx_, RKNN_QUERY_INPUT_ATTR, &(input_attrs[i]), sizeof(rknn_tensor_attr));
if (ret != RKNN_SUCC)
{
NN_LOG_ERROR("rknn_query fail! ret=%d", ret);
return NN_RKNN_QUERY_FAIL;
}
print_tensor_attr(&(input_attrs[i]));
// set input_shapes_
in_shapes_.push_back(rknn_tensor_attr_convert(input_attrs[i]));
}
// 输出属性
NN_LOG_INFO("output tensors:");
rknn_tensor_attr output_attrs[io_num.n_output];
memset(output_attrs, 0, sizeof(output_attrs));
for (int i = 0; i < io_num.n_output; i++)
{
output_attrs[i].index = i;
ret = rknn_query(rknn_ctx_, RKNN_QUERY_OUTPUT_ATTR, &(output_attrs[i]), sizeof(rknn_tensor_attr));
if (ret != RKNN_SUCC)
{
NN_LOG_ERROR("rknn_query fail! ret=%d", ret);
return NN_RKNN_QUERY_FAIL;
}
print_tensor_attr(&(output_attrs[i]));
// set output_shapes_
out_shapes_.push_back(rknn_tensor_attr_convert(output_attrs[i]));
}
return NN_SUCCESS;
}
// 获取输入张量的形状
const std::vector<tensor_attr_s> &RKEngine::GetInputShapes()
{
return in_shapes_;
}
// 获取输出张量的形状
const std::vector<tensor_attr_s> &RKEngine::GetOutputShapes()
{
return out_shapes_;
}
/**
* @brief 运行模型,获得推理结果
* @param inputs 输入张量
* @param outputs 输出张量
* @param want_float 是否需要float类型的输出
* @return nn_error_e 错误码
*/
nn_error_e RKEngine::Run(std::vector<tensor_data_s> &inputs, std::vector<tensor_data_s> &outputs, bool want_float)
{
// 检查输入输出张量的数量是否匹配
if (inputs.size() != input_num_)
{
NN_LOG_ERROR("inputs num not match! inputs.size()=%ld, input_num_=%d", inputs.size(), input_num_);
return NN_IO_NUM_NOT_MATCH;
}
if (outputs.size() != output_num_)
{
NN_LOG_ERROR("outputs num not match! outputs.size()=%ld, output_num_=%d", outputs.size(), output_num_);
return NN_IO_NUM_NOT_MATCH;
}
// 设置rknn inputs
rknn_input rknn_inputs[g_max_io_num];
for (int i = 0; i < inputs.size(); i++)
{
// 将自定义的tensor_data_s转换为rknn_input
rknn_inputs[i] = tensor_data_to_rknn_input(inputs[i]);
}
int ret = rknn_inputs_set(rknn_ctx_, (uint32_t)inputs.size(), rknn_inputs);
if (ret < 0)
{
NN_LOG_ERROR("rknn_inputs_set fail! ret=%d", ret);
return NN_RKNN_INPUT_SET_FAIL;
}
// 推理
NN_LOG_DEBUG("rknn running...");
ret = rknn_run(rknn_ctx_, nullptr);
if (ret < 0)
{
NN_LOG_ERROR("rknn_run fail! ret=%d", ret);
return NN_RKNN_RUNTIME_ERROR;
}
// 获得输出
rknn_output rknn_outputs[g_max_io_num];
memset(rknn_outputs, 0, sizeof(rknn_outputs));
for (int i = 0; i < output_num_; ++i)
{
rknn_outputs[i].want_float = want_float ? 1 : 0;
}
ret = rknn_outputs_get(rknn_ctx_, output_num_, rknn_outputs, NULL);
if (ret < 0)
{
printf("rknn_outputs_get fail! ret=%d\n", ret);
NN_LOG_ERROR("rknn_outputs_get fail! ret=%d", ret);
return NN_RKNN_OUTPUT_GET_FAIL;
}
NN_LOG_DEBUG("output num: %d", output_num_);
// copy rknn outputs to tensor_data_s
for (int i = 0; i < output_num_; ++i)
{
// 将rknn_output转换为自定义的tensor_data_s
rknn_output_to_tensor_data(rknn_outputs[i], outputs[i]);
NN_LOG_DEBUG("output[%d] size=%d", i, outputs[i].attr.size);
}
return NN_SUCCESS;
}
// 析构函数
RKEngine::~RKEngine()
{
if (ctx_created_)
{
rknn_destroy(rknn_ctx_);
NN_LOG_INFO("rknn context destroyed!");
}
}
// 创建RKNN引擎
std::shared_ptr<NNEngine> CreateRKNNEngine()
{
return std::make_shared<RKEngine>();
}
封装前后处理
前处理
preprocess.h
核心流程中的预处理输入数据:对输入数据进行颜色空间转换,尺寸缩放操作。
// 前处理
#ifndef RK3566_DEMO_PREPROCESS_H
#define RK3566_DEMO_PREPROCESS_H
#include <opencv2/opencv.hpp>
#include "types/datatype.h"
void imgPreprocess(const cv::Mat &img, cv::Mat &img_resized, uint32_t width, uint32_t height);
#endif //RK3566_DEMO_PREPROCESS_H
preprocess.cpp
// 前处理
#include "preprocess.h"
#include "utils/logging.h"
void imgPreprocess(const cv::Mat &img, cv::Mat &img_resized, uint32_t width, uint32_t height)
{
// img has to be 3 channels
if (img.channels() != 3)
{
NN_LOG_ERROR("img has to be 3 channels");
exit(-1);
}
cv::Mat img_rgb;
// bggr to rgb
cv::cvtColor(img, img_rgb, cv::COLOR_BGR2RGB);
// resize img
cv::resize(img_rgb, img_resized, cv::Size(width, height), 0, 0, cv::INTER_LINEAR);
}
后处理
postprocess.h
核心流程中的后处理推理结果:推理完成后,从输出张量中获取结果数据,根据需要对结果进行后处理,以获得最终的预测结果。
// 后处理
#ifndef RK3566_DEMO_POSTPROCESS_H
#define RK3566_DEMO_POSTPROCESS_H
#include <stdint.h>
#include <vector>
#include "opencv2/core/core.hpp"
#include "opencv2/imgcodecs.hpp"
#include "opencv2/imgproc.hpp"
int get_classification(float* pfProb, uint32_t out_w, uint32_t out_h);
#endif //RK3566_DEMO_POSTPROCESS_H
postprocess.cpp
// 后处理
#include <string.h>
#include <stdlib.h>
#include <algorithm>
#include <iostream>
#include "postprocess.h"
#include "utils/logging.h"
int get_classification(float* pfProb, uint32_t out_w, uint32_t out_h) {
// 1x5 获取输出数据并包装成一个cv::Mat对象,为了方便后处理
cv::Mat prob(out_w, out_h, CV_32F, (float*) pfProb);
std::cout << "prob : " << prob << std::endl;
// 后处理推理结果
cv::Point maxL, minL; // 用于存储图像分类中的得分最小值索引和最大值索引(坐标)
double maxv, minv; // 用于存储图像分类中的得分最小值和最大值
cv::minMaxLoc(prob, &minv, &maxv, &minL, &maxL);
int max_index = maxL.x; // 获得最大值的索引,只有一行所以列坐标既为索引
return max_index;
}
封装自定义类型
定义的NNEngine接口,其子类实现了RKNN API封装,同样也可以对未来新增的不同框架API进行封装,为了NNEngine与包括RKNN API在内的不同官方类型进行转化,提升兼容性和可扩展性,因此需要自定义类型。
RKNN API官方类型librknn_api/include/rknn_api.h中。
自定义数据类型
datatype.h
// 自定义定义数据类型
#ifndef RK3566_DEMO_DATATYPE_H
#define RK3566_DEMO_DATATYPE_H
#include <stdint.h>
#include <stdlib.h>
#include "utils/logging.h"
#include "types/error.h"
// 输入数据(张量)的不同通道布局
typedef enum _tensor_layout
{
// N批次batch,C通道数channel,H高度height,W宽度width
NN_TENSORT_LAYOUT_UNKNOWN = 0,
NN_TENSOR_NCHW = 1,
NN_TENSOR_NHWC = 2,
NN_TENSOR_OTHER = 3,
} tensor_layout_e;
// 输入数据(张量)的不同数据类型
typedef enum _tensor_datatype
{
NN_TENSOR_INT8 = 1,
NN_TENSOR_UINT8 = 2,
NN_TENSOR_FLOAT = 3,
NN_TENSOR_FLOAT16 = 4,
} tensor_datatype_e;
// 输入数据(张量)的维度
static const int g_max_num_dims = 4;
// 输入数据(张量)的基本信息
typedef struct
{
uint32_t index; // 存在多个输入数据时的索引
uint32_t n_dims; // 输入数据维度的数量
uint32_t dims[g_max_num_dims]; // 不同维度的大小
uint32_t n_elems; // 输入数据元素的个数
uint32_t size; // 元素的占用空间(字节):元素的个数×每个元素的占用空间
tensor_datatype_e type; // 元素的数据类型,不同类型就和不同占用空间有关
tensor_layout_e layout; // 输入数据的通道布局
int32_t zp; // 非对称仿射量化方法中的零点值
float scale; // 非对称仿射量化方法中的缩放值
} tensor_attr_s;
// 输入数据(张量)的完整内容:输入数据基本信息+输入数据本身
typedef struct
{
tensor_attr_s attr;
void *data;
} tensor_data_s;
// 不同数据类型的占用空间
static size_t nn_tensor_type_to_size(tensor_datatype_e type)
{
switch (type)
{
case NN_TENSOR_INT8:
return sizeof(int8_t);
case NN_TENSOR_UINT8:
return sizeof(uint8_t);
case NN_TENSOR_FLOAT:
return sizeof(float);
case NN_TENSOR_FLOAT16:
return sizeof(uint16_t);
default:
NN_LOG_ERROR("unsupported tensor type");
exit(-1);
}
}
// 设置输入数据的完整内容:整个过程就是将基本信息复制到完整内容中
static void nn_tensor_attr_to_cvimg_input_data(const tensor_attr_s &attr, tensor_data_s &data)
{
if (attr.n_dims != 4)
{
NN_LOG_ERROR("unsupported input dims");
exit(-1);
}
data.attr.n_dims = attr.n_dims;
data.attr.index = 0;
data.attr.type = NN_TENSOR_UINT8; // 在转成rknn模型时候通常会选择量化,因此输入数据类型通常都是UINT8
data.attr.layout = NN_TENSOR_NHWC; // 在转成rknn模型时候通常是NHWC格式
if (attr.layout == NN_TENSOR_NCHW)
{
data.attr.dims[0] = attr.dims[0];
data.attr.dims[1] = attr.dims[2];
data.attr.dims[2] = attr.dims[3];
data.attr.dims[3] = attr.dims[1];
}
else if (attr.layout == NN_TENSOR_NHWC)
{
data.attr.dims[0] = attr.dims[0];
data.attr.dims[1] = attr.dims[1];
data.attr.dims[2] = attr.dims[2];
data.attr.dims[3] = attr.dims[3];
}
else
{
NN_LOG_ERROR("unsupported input layout");
exit(-1);
}
// 计算输入元素个数
data.attr.n_elems = data.attr.dims[0] * data.attr.dims[1] *
data.attr.dims[2] * data.attr.dims[3];
// 计算输入元素的占用空间
data.attr.size = data.attr.n_elems * sizeof(uint8_t);
}
#endif // RK3566_DEMO_DATATYPE_H
自定义错误类型
error.h
// 自定义错误码
#ifndef RK3566_DEMO_ERROR_H
#define RK3566_DEMO_ERROR_H
typedef enum
{
NN_SUCCESS = 0, // 成功
NN_LOAD_MODEL_FAIL = -1, // 加载模型失败
NN_RKNN_INIT_FAIL = -2, // rknn初始化失败
NN_RKNN_QUERY_FAIL = -3, // rknn查询失败
NN_RKNN_INPUT_SET_FAIL = -4, // rknn设置输入数据失败
NN_RKNN_RUNTIME_ERROR = -5, // rknn运行时错误
NN_IO_NUM_NOT_MATCH = -6, // 输入输出数量不匹配
NN_RKNN_OUTPUT_GET_FAIL = -7, // rknn获取输出数据失败
NN_RKNN_INPUT_ATTR_ERROR = -8, // rknn输入数据属性错误
NN_RKNN_OUTPUT_ATTR_ERROR = -9, // rknn输出数据属性错误
NN_RKNN_MODEL_NOT_LOAD = -10, // rknn模型未加载
} nn_error_e;
#endif // RK3566_DEMO_ERROR_H
封装辅助功能
日志包装器
logging.h
宏定义来实现日志记录是一种强大且灵活的方法,它可以帮助开发者更好地控制日志输出,实现代码的灵活性,同时提高代码的性能和可维护性。
rknn_engine.cpp很多信息输出都是用日志记录的形式。
// 日志包装器,便于更换
#ifndef RK3566_DEMO_LOGGING_H
#define RK3566_DEMO_LOGGING_H
#include <stdio.h>
// 日志等级:从低到高
// 0: no log
// 1: error
// 2: error, warning
// 3: error, warning, info
// 4: error, warning, info, debug
static int32_t g_log_level = 4;
// 打印信息日志信息
// #defin 宏定义配合 do...while(0) 结构是常见的编程技巧,用于确保宏定义的行为类似于一个单独的语句
#define NN_LOG_ERROR(...) \
do \
{ \
if (g_log_level >= 1) \
{ \
printf("[NN_ERROR] "); \
printf(__VA_ARGS__); \
printf("\n"); \
} \
} while (0)
#define NN_LOG_WARNING(...) \
do \
{ \
if (g_log_level >= 2) \
{ \
printf("[NN_WARNING] "); \
printf(__VA_ARGS__); \
printf("\n"); \
} \
} while (0)
#define NN_LOG_INFO(...) \
do \
{ \
if (g_log_level >= 3) \
{ \
printf("[NN_INFO] "); \
printf(__VA_ARGS__); \
printf("\n"); \
} \
} while (0)
#define NN_LOG_DEBUG(...) \
do \
{ \
if (g_log_level >= 4) \
{ \
printf("[NN_DEBUG] "); \
printf(__VA_ARGS__); \
printf("\n"); \
} \
} while (0)
#endif // RK3566_DEMO_LOGGING_H
辅助互换函数
engine_helper.h
实现了加载标签和模型文件的辅助函数,以及实现了nn自定义类型和rknn官方类型的互换函数,未来封装更多API后,可扩展nn自定义类型和其他官方类型的互换函数。
// 辅助互换函数
#ifndef RK3566_DEMO_ENGINE_HELPER_H
#define RK3566_DEMO_ENGINE_HELPER_H
#include <fstream>
#include <string.h>
#include <vector>
#include <rknn_api.h>
#include "utils/logging.h"
#include "types/datatype.h"
/**
* @brief 加载标签文件
* @param labels_txt_file 标签文件路径
* @return std::vector<std::string> 输出标签名称
*/
std::vector<std::string> readClassNames(std::string labels_txt_file)
{
std::vector<std::string> classNames;
std::ifstream fp(labels_txt_file);
if (!fp.is_open())
{
printf("could not open file...\n");
exit(-1);
}
std::string name;
while (!fp.eof())
{
std::getline(fp, name);
if (name.length())
classNames.push_back(name);
}
fp.close();
return classNames;
}
/**
* @brief 加载模型文件
* @param filename 模型文件路径
* @param model_size 模型文件大小,会在函数内部赋值
* @return unsigned char* 模型文件数据
*/
static unsigned char *load_model(const char *filename, int *model_size)
{
FILE *fp = fopen(filename, "rb");
if (fp == nullptr)
{
NN_LOG_ERROR("fopen %s fail!", filename);
return nullptr;
}
fseek(fp, 0, SEEK_END);
int model_len = ftell(fp);
unsigned char *model = (unsigned char *)malloc(model_len);
fseek(fp, 0, SEEK_SET);
if (model_len != fread(model, 1, model_len, fp))
{
NN_LOG_ERROR("fread %s fail!", filename);
free(model);
return nullptr;
}
*model_size = model_len;
if (fp)
{
fclose(fp);
}
return model;
}
// 打印模型的输入输出的基本信息
static void print_tensor_attr(rknn_tensor_attr *attr)
{
NN_LOG_INFO(" index=%d, name=%s, n_dims=%d, dims=[%d, %d, %d, %d], n_elems=%d, size=%d, fmt=%s, type=%s, qnt_type=%s, "
"zp=%d, scale=%f",
attr->index, attr->name, attr->n_dims, attr->dims[0], attr->dims[1], attr->dims[2], attr->dims[3],
attr->n_elems, attr->size, get_format_string(attr->fmt), get_type_string(attr->type),
get_qnt_type_string(attr->qnt_type), attr->zp, attr->scale);
}
// 通道布局:nn转换成对应的rknn
static rknn_tensor_format rknn_layout_convert(tensor_layout_e fmt)
{
switch (fmt)
{
case NN_TENSOR_NCHW:
return RKNN_TENSOR_NCHW;
case NN_TENSOR_NHWC:
return RKNN_TENSOR_NHWC;
default:
NN_LOG_ERROR("unsupported nn layout: %d\n", fmt);
// exit program
exit(1);
}
}
// 数据类型:nn转换成对应的rknn
static rknn_tensor_type rknn_type_convert(tensor_datatype_e type)
{
switch (type)
{
case NN_TENSOR_UINT8:
return RKNN_TENSOR_UINT8;
case NN_TENSOR_FLOAT:
return RKNN_TENSOR_FLOAT32;
default:
NN_LOG_ERROR("unsupported nn type: %d\n", type);
// exit program
exit(1);
}
}
// 通道布局:rkknn转化成对应的nn
static tensor_layout_e rknn_layout_convert(rknn_tensor_format fmt)
{
switch (fmt)
{
case RKNN_TENSOR_NCHW:
return NN_TENSOR_NCHW;
case RKNN_TENSOR_NHWC:
return NN_TENSOR_NHWC;
default:
return NN_TENSOR_OTHER;
}
}
// 数据类型:rknn转换成对应的nn
static tensor_datatype_e rknn_type_convert(rknn_tensor_type type)
{
switch (type)
{
case RKNN_TENSOR_UINT8:
return NN_TENSOR_UINT8;
case RKNN_TENSOR_FLOAT32:
return NN_TENSOR_FLOAT;
case RKNN_TENSOR_INT8:
return NN_TENSOR_INT8;
case RKNN_TENSOR_FLOAT16:
return NN_TENSOR_FLOAT16;
default:
NN_LOG_ERROR("unsupported rknn type: %d\n", type);
// exit program
exit(1);
}
}
// 输入数据:rknn官方类型转nn自定义类型
static tensor_attr_s rknn_tensor_attr_convert(const rknn_tensor_attr &attr)
{
tensor_attr_s shape;
shape.n_dims = attr.n_dims;
shape.index = attr.index;
for (int i = 0; i < attr.n_dims; ++i)
{
shape.dims[i] = attr.dims[i];
}
shape.size = attr.size;
shape.n_elems = attr.n_elems;
shape.layout = rknn_layout_convert(attr.fmt);
shape.type = rknn_type_convert(attr.type);
shape.zp = attr.zp;
shape.scale = attr.scale;
return shape;
}
// 输入数据:nn自定义类型转rknn官方类型,为了输入到rknn模型
static rknn_input tensor_data_to_rknn_input(const tensor_data_s &data)
{
rknn_input input;
memset(&input, 0, sizeof(input));
// set default not passthrough
input.index = data.attr.index;
input.type = rknn_type_convert(data.attr.type);
input.size = data.attr.size;
input.fmt = rknn_layout_convert(data.attr.layout);
input.buf = data.data;
return input;
}
// 输出数据:rknn官方类型转nn自定义类型,方便后处理
static void rknn_output_to_tensor_data(const rknn_output &output, tensor_data_s &data)
{
data.attr.index = output.index;
data.attr.size = output.size;
NN_LOG_DEBUG("output size: %d", output.size);
NN_LOG_DEBUG("output want_float: %d", output.want_float);
memcpy(data.data, output.buf, output.size);
}
#endif // RK3566_DEMO_ENGINE_HELPER_H
主函数和CMake配置文件
AlexNet_API.cpp
// 导入相关库
#include <iostream>
#include <opencv2/opencv.hpp>
#include "engine/engine.h"
#include "process/preprocess.h"
#include "process/postprocess.h"
#include "utils/logging.h"
#include "utils/engine_helper.h"
int main(int argc, char **argv)
{
// 模型文件路径
const char *model_file = argv[1];
// 图片文件路径
const char *img_file = argv[2];
std::string labels_txt_file = "src/flower_classes.txt";
std::vector<std::string> labels = readClassNames(labels_txt_file);
// ==================== 1. 加载引擎 ====================
// 使用shared_ptr智能指针创建引擎,类型是接口中定义的NNEngine,但是实际上是RKEngine
std::shared_ptr<NNEngine> engine = CreateRKNNEngine();
// 加载模型文件、初始化rknn context、获取rknn版本信息、获取输入输出张量的信息
engine->LoadModelFile(model_file);
// 获取输入输出张量的形状
auto input_attrs = engine->GetInputShapes();
auto output_attrs = engine->GetOutputShapes();
NN_LOG_INFO("processing input data");
uint32_t n_dims = input_attrs[0].n_dims;
uint32_t batch = input_attrs[0].dims[0]; // 根据输入属性查询输入张量的批次(参考:dims=[1, 224, 224, 3])
uint32_t in_h = input_attrs[0].dims[1]; // 高度
uint32_t in_w = input_attrs[0].dims[2]; // 宽度
uint32_t channel = input_attrs[0].dims[3]; // 通道
tensor_datatype_e type = input_attrs[0].type; // 数据类型
tensor_layout_e layout = input_attrs[0].layout; // 通道布局
uint32_t bytes = nn_tensor_type_to_size(type); // 数据类型的占用空间
// ==================== 2. 读取、预处理图片 ====================
// 加载图片
cv::Mat orig_img = cv::imread(img_file);
// 预处理 bgr->rgb, resize
cv::Mat img_resized;
imgPreprocess(orig_img, img_resized, in_w, in_h);
// ==================== 3. 设置输入、输出属性 ====================
// 输入数据
tensor_data_s input;
input.attr.n_dims = n_dims;
input.attr.dims[0] = batch;
input.attr.dims[1] = in_h;
input.attr.dims[2] = in_w;
input.attr.dims[3] = channel;
input.attr.size = channel * in_h * in_w;
// input.attr.type = type;
input.attr.type = NN_TENSOR_UINT8;
input.attr.layout = layout;
input.data = malloc(input.attr.size * bytes);
// 将图片数据拷贝到input.data中
memcpy(input.data, img_resized.data, input.attr.size);
// 将input追加到inputs中
std::vector<tensor_data_s> inputs;
inputs.push_back(input);
NN_LOG_DEBUG("done preprocessing input data");
// 输出数据
std::vector<tensor_data_s> outputs;
tensor_data_s output;
output.data = malloc(output_attrs[0].n_elems * sizeof(float));
outputs.push_back(output);
// ==================== 4. 推理 ====================
NN_LOG_INFO("running...");
engine->Run(inputs, outputs, true);
// ==================== 5. 后处理 ====================
uint32_t out_h = output_attrs[0].dims[0]; // 高度
uint32_t out_w = output_attrs[0].dims[1]; // 宽度
float *buffer = (float *)output.data;
int max_index = get_classification(buffer, out_h, out_w);
std::cout << "label id: " << max_index << std::endl;
cv::putText(orig_img, labels[max_index], cv::Point(50, 50), cv::FONT_HERSHEY_SIMPLEX, 1.0, cv::Scalar(0, 0, 255), 2, 8);
cv::imwrite("./output.jpg", orig_img);
return 0;
}
CMakeLists.txt
# 设置最低版本号
cmake_minimum_required(VERSION 3.11 FATAL_ERROR)
# 设置项目名称
project(rk3566-demo VERSION 0.0.1 LANGUAGES CXX)
# 输出系统信息
message(STATUS "System: ${CMAKE_SYSTEM_NAME} ${CMAKE_SYSTEM_VERSION}")
# 设置编译器
set(CMAKE_CXX_STANDARD 14)
set(CMAKE_CXX_STANDARD_REQUIRED ON)
# 设置库架构
# rknn_api 文件夹路径
set(RKNN_API_PATH ${CMAKE_CURRENT_SOURCE_DIR}/librknn_api)
# rknn_api include 路径
set(RKNN_API_INCLUDE_PATH ${RKNN_API_PATH}/include)
# rknn_api lib 路径
set(RKNN_API_LIB_PATH ${RKNN_API_PATH}/aarch64/librknnrt.so)
# 寻找OpenCV库,使用自定义的OpenCV_DIR
set(3RDPARTY_PATH ${CMAKE_CURRENT_SOURCE_DIR}/3rdparty)
set(OpenCV_DIR ${3RDPARTY_PATH}/opencv/opencv-linux-aarch64/share/OpenCV)
find_package(OpenCV 3.4.5 REQUIRED)
# 输出OpenCV信息
message(STATUS " include path: ${OpenCV_INCLUDE_DIRS}")
# 用来搜索头文件的目录
include_directories(
${OpenCV_INCLUDE_DIRS}
${RKNN_API_INCLUDE_PATH}
${CMAKE_CURRENT_SOURCE_DIR}/src
)
# 构建预处理和后处理库
add_library(nn_process SHARED
src/process/preprocess.cpp
src/process/postprocess.cpp
)
# 链接库
target_link_libraries(nn_process
${OpenCV_LIBS}
)
# 构建自定义封装API库
add_library(rknn_engine SHARED
src/engine/rknn_engine.cpp)
# 链接库
target_link_libraries(rknn_engine
${RKNN_API_LIB_PATH}
)
# 测试自定义封装API
add_executable(alexnet_api src/AlexNet_API.cpp)
# 链接库
target_link_libraries(alexnet_api
rknn_engine
nn_process
)
编译和链接,完成推理,查看结果:
# 用于配置 CMake 项目的命令
# -S .: 指定了源代码目录,.当前目录
# -B build: 指定了构建目录,当前目录下创建build子目录
cmake -S . -B build
# 使用先前配置好的构建系统来编译和链接项目
cmake --build build
# 执行推理
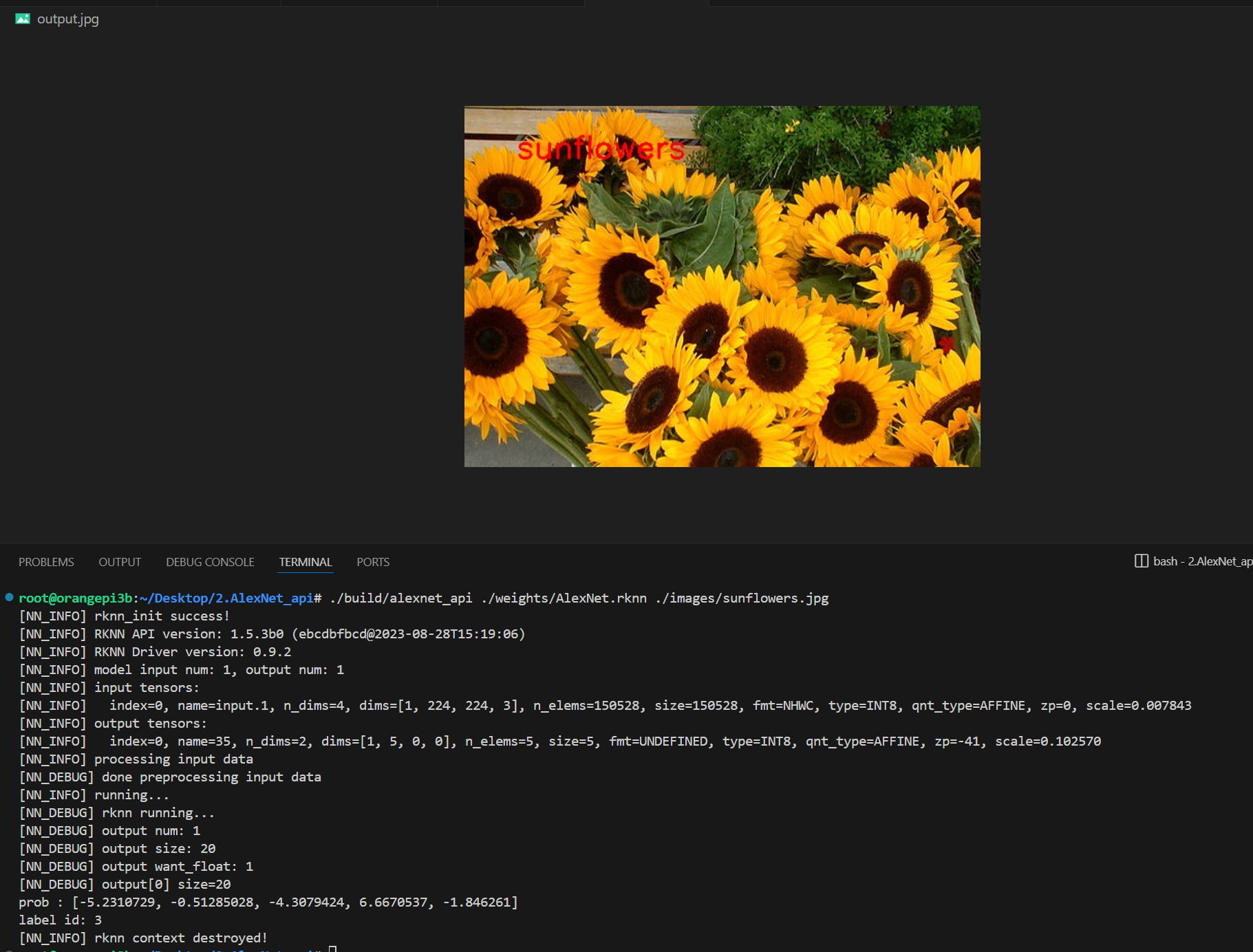
./build/alexnet_api ./weights/AlexNet.rknn ./images/sunflowers.jpg
图片依旧正确预测为向日葵:
总结
尽可能简单、详细的介绍了RKNN C++ 应用程序编程接口化处理详细教程。