功能:
本项目主要使用PyQt完成数据处理的功能,根据需求提取数据特征,进行统计整理,按照格式写入存储器中。
需求:
处理一个城市的大量的采集数据,将其中的关键信息从海量的数据提取出来处理,筛选后按不同的类型和用途进行排序,并且按照规定的格式保存。
主要使用python编写,窗口使用QT转化的。
效果图:
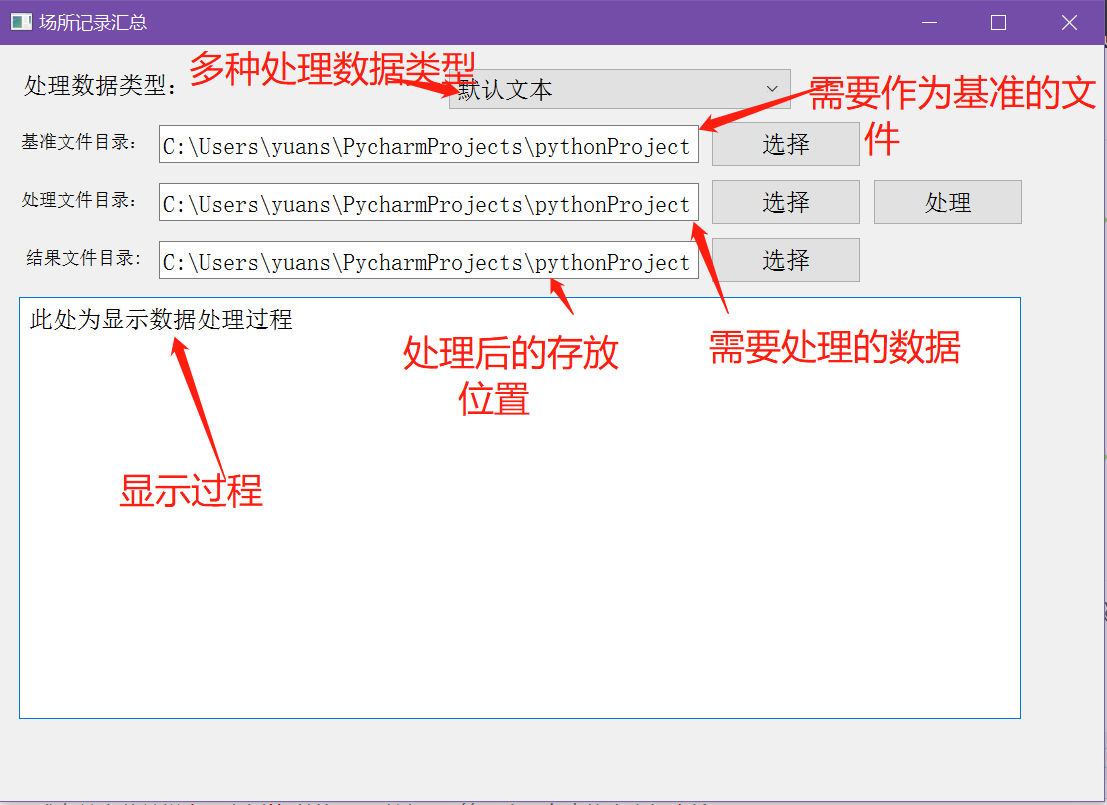
因为需要处理三种类型的数据,使用了一个下拉框,这样可以同时处理也可以分别处理。
处理数据
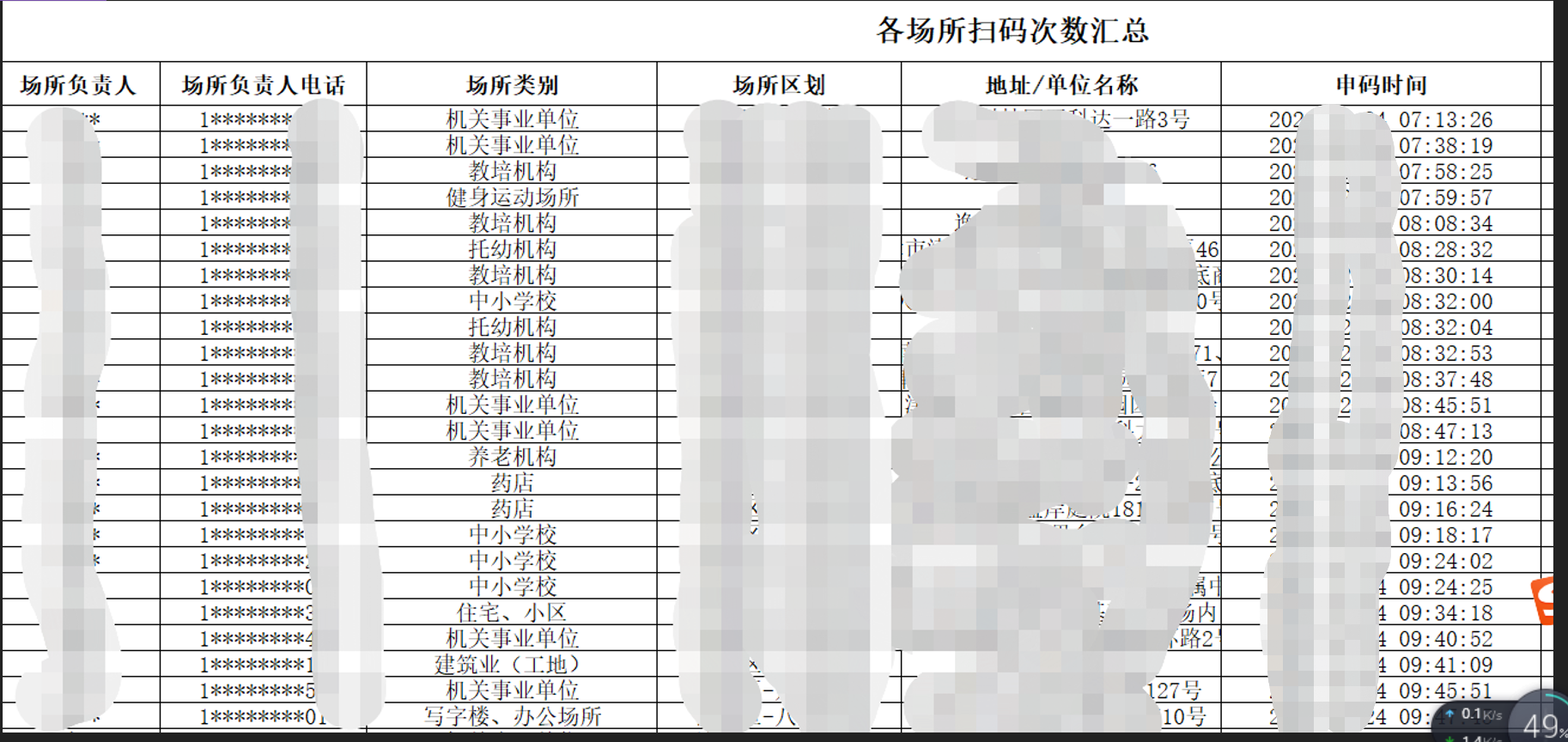
处理前是大量的excel表格数据
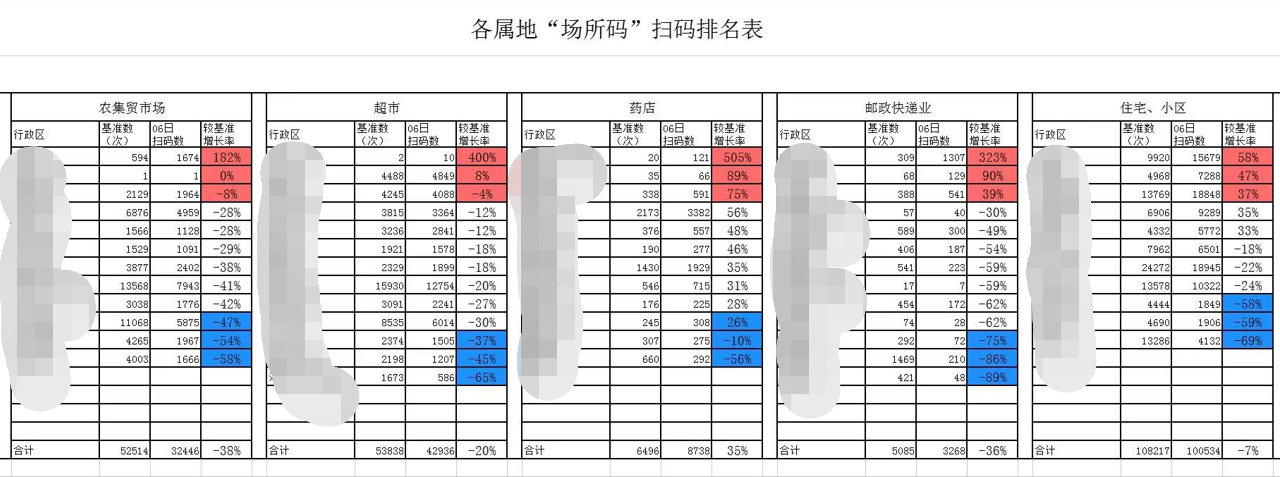
结果文件
处理后提取了各种类型的数据
处理代码
打开文件

处理数据代码(部分)
注意:xlrd,xlwt,xlutils只能操作xls类型的文件,如果想要操作xlsx类型的文件,可以用openpyxl这个库
def data_deal_process(self):
self.text_process.append("处理文件的路径...{}".format(self.lineEdit_deal.text()))
deal_dir = self.lineEdit_deal.text()
result_dir = self.lineEdit_result.text()
dictionary = {}
# 获取当前的索引,读取哪些数据
index = self.comBox_type.currentIndex()
# 获取路径下的所有文件的文件名
if len(deal_dir) != 0:
files = os.listdir(deal_dir)
# 深度遍历文件名
# root_dir, sub_dir, files_n in os.walk(deal_dir, topdown=False)
file_nums = 0
# 用列表来存储行政区及扫码数
area = []
# 多少行数据
all_data = 16
for file in files:
if file.endswith('xlsx'):
file_nums = file_nums + 1
file_path = os.path.join(deal_dir, file)
# 读取表格中第2行
# table = openpyxl.load_workbook(file_path) # 打开要操作的表格
# sheet = table['Sheet1'] # 选择要操作的表单(工作表)
# 读取文件中的内容 header指明哪一行作为列名 usecols为读取的列
# data_content = pd.read_excel(file_path, header=2, usecols=[4, 5, 8])
# data_content = pd.read_excel(file_path)
# 使用xlrd读取表格试一下,总是出现错误
book = xlrd.open_workbook(file_path)
# 获取第一个表格
sheet = book.sheet_by_index(0)
# 获取当前表格的行数和列数
rows = sheet.nrows
cols = sheet.ncols
# 获取表头文件
head = sheet.row_values(1)
# 显示数据 行数+列数+表头名称
# self.text_process.append("{}".format(cols))
# self.text_process.append("{}".format(rows))
# self.text_process.append("{}".format(head))
# 读取某个单元格的内容 此处为str类型
area_value = sheet.cell_value(2, 4)
area_index = area_value.find('-')
area_name = area_value[area_index + 1:]
# 字典中没有此项,则创建
if area_name not in dictionary.keys():
dictionary[area_name] = 0
# 各属地场所
dictionary[area_name, place_type[4]] = 0
dictionary[area_name, place_type[5]] = 0
dictionary[area_name, place_type[1]] = 0
dictionary[area_name, place_type[6]] = 0
dictionary[area_name, place_type[0]] = 0
dictionary[area_name, place_type[7]] = 0
dictionary[area_name, place_type[8]] = 0
dictionary[area_name, place_type[3]] = 0
dictionary[area_name, place_type[2]] = 0
# 各密闭场所
dictionary[area_name, place_type[9]] = 0
dictionary[area_name, place_type[10]] = 0
dictionary[area_name, place_type[11]] = 0
dictionary[area_name, place_type[12]] = 0
dictionary[area_name, place_type[13]] = 0
# 读取每一行的数据,进行提取
for i in range(2, rows - 2):
if sheet.cell_value(i, 7) != 0:
dictionary[area_name] += sheet.cell_value(i, 7)
# 筛选出一些场所, 进行统计
if sheet.cell_value(i, 3).find(place_type[1]) != -1:
dictionary[area_name, place_type[1]] += sheet.cell_value(i, 7)
if sheet.cell_value(i, 3).find(place_type[2]) != -1:
dictionary[area_name, place_type[2]] += sheet.cell_value(i, 7)
# 处理重点场所
if sheet.cell_value(i, 3).find(place_type[3]) != -1 and sheet.cell_value(i, 7) != 0:
dictionary[area_name, place_type[3]] += sheet.cell_value(i, 7)
dictionary[area_name, sheet.cell_value(i, 0), place_type[3]] = sheet.cell_value(i, 7)
if sheet.cell_value(i, 3).find(place_type[4]) != -1:
dictionary[area_name, place_type[4]] += sheet.cell_value(i, 7)
# 处理重点场所
if sheet.cell_value(i, 3).find(place_type[5]) != -1 and sheet.cell_value(i, 7) != 0:
dictionary[area_name, place_type[5]] += sheet.cell_value(i, 7)
dictionary[area_name, sheet.cell_value(i, 0), place_type[5]] = sheet.cell_value(i, 7)
# 处理重点场所 综合体
if sheet.cell_value(i, 3).find(place_type[6]) != -1 and sheet.cell_value(i, 7) != 0:
dictionary[area_name, place_type[6]] += sheet.cell_value(i, 7)
dictionary[area_name, sheet.cell_value(i, 0), place_type[6]] = sheet.cell_value(i, 7)
# 处理重点场所 物流园区
if sheet.cell_value(i, 3).find(place_type[7]) != -1 and sheet.cell_value(i, 7) != 0:
dictionary[area_name, place_type[7]] += sheet.cell_value(i, 7)
dictionary[area_name, sheet.cell_value(i, 0), place_type[7]] = sheet.cell_value(i, 7)
if sheet.cell_value(i, 3).find(place_type[8]) != -1:
dictionary[area_name, place_type[8]] += sheet.cell_value(i, 7)
if sheet.cell_value(i, 3).find(place_type[8]) != -1:
dictionary[area_name, place_type[8]] += sheet.cell_value(i, 7)
# 各封闭场所
if sheet.cell_value(i, 3).find(place_type[9]) != -1:
dictionary[area_name, place_type[9]] += sheet.cell_value(i, 7)
if sheet.cell_value(i, 3).find(place_type[10]) != -1:
dictionary[area_name, place_type[10]] += sheet.cell_value(i, 7)
if sheet.cell_value(i, 3).find(place_type[11]) != -1:
dictionary[area_name, place_type[11]] += sheet.cell_value(i, 7)
if sheet.cell_value(i, 3).find(place_type[12]) != -1:
dictionary[area_name, place_type[12]] += sheet.cell_value(i, 7)
if sheet.cell_value(i, 3).find(place_type[13]) != -1:
dictionary[area_name, place_type[13]] += sheet.cell_value(i, 7)
num = [area_name, dictionary[area_name]]
area.append(num)
# 所处理的文件目录下没有对应的excel表格,返回
if file_nums == 0:
self.text_process.append("所选目录下没有excel文件,无法处理")
return
today = datetime.date.today()
yesterday = today + datetime.timedelta(days=-1)
short_width = 256 * 2
long_width = 256 * 20
long_long_width = 256*30
# 设置合并后的单元格格式
font = xlwt.Font() # 字体
font.bold = True # 粗体
font.height = 300 # 字体大小
font.name = 'Times New Roman'
style = xlwt.XFStyle()
style.font = font
# 对齐
alignment = xlwt.Alignment()
alignment.horz = xlwt.Alignment.HORZ_CENTER
alignment.vert = xlwt.Alignment.VERT_CENTER
style.alignment = alignment
# 设置边框 实线
borders = xlwt.Borders()
borders.left = xlwt.Borders.THIN
borders.right = xlwt.Borders.THIN
borders.top = xlwt.Borders.THIN
borders.bottom = xlwt.Borders.THIN
# 设置对齐方式
sec_style = xlwt.XFStyle()
sec_alignment = xlwt.Alignment()
sec_alignment.horz = xlwt.Alignment.HORZ_RIGHT
sec_alignment.vert = xlwt.Alignment.VERT_BOTTOM
sec_style.alignment = sec_alignment
sec_borders = xlwt.Borders()
sec_borders.bottom = xlwt.Borders.THIN
sec_style.borders = sec_borders
sty = xlwt.XFStyle()
sty.borders = borders
# 设置实线 居中
sty_center = xlwt.XFStyle()
sty_center.borders = borders
sty_center.alignment = alignment
# 创建excel表格类型文件 utf-8是数据的编码格式,style_compression设置是否压缩:0表示不压缩
book = xlwt.Workbook(encoding='utf-8', style_compression=0)
总结:python处理数据表格相当方便。
可根据需求设计定制类似项目软件