一、题目解析
训练集是幸福度的调查数据,涵盖调查人员各维度指标,调查结果幸福度分为5级。对测试集的样本进行幸福度分级预测。
数据精度评估标准:

二、数据分析处理
1、数据导入
#导入库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.utils import shuffle
import seaborn as sns
#导入数据
file_input=r"D:\tianchi test\happiness\happiness_train_abbr.csv"
file_input2=r"D:\tianchi test\happiness\happiness_test_abbr.csv"
file_input3=r"D:\tianchi test\happiness\happiness_submit.csv"
output_file=r"D:\tianchi test\happiness\output_file.csv"
df_train=pd.read_csv(file_input,header=0) #header指定第几行为列名
df_test=pd.read_csv(file_input2,header=0)
df_in=pd.read_csv(file_input3,header=0)
y_train=df_train["happiness"]#将df_train中happiness这一栏的数据赋给y_train
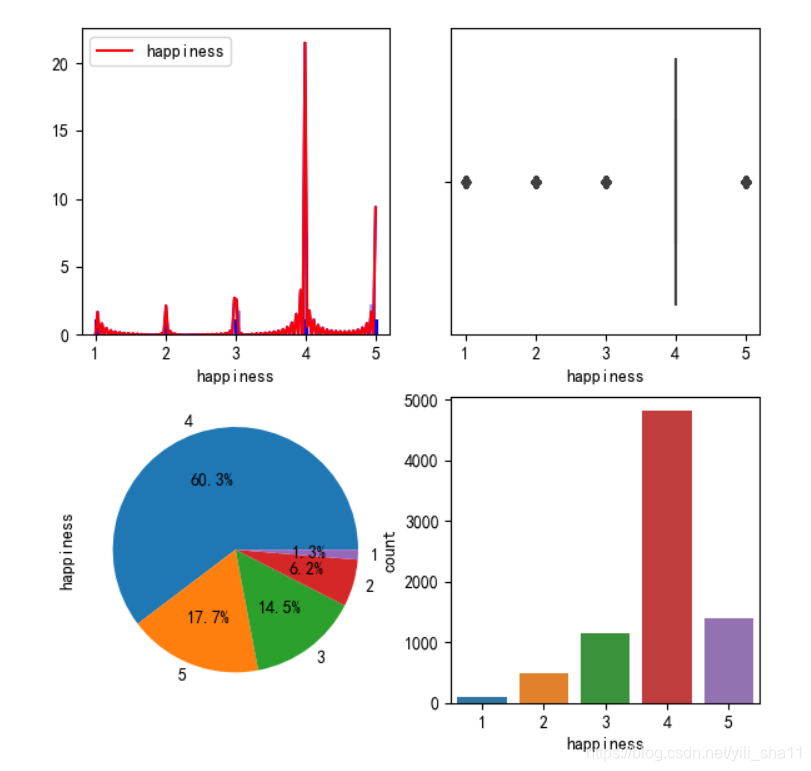
2、数据探索
查看数据分布情况,重点是测试集的y值呈偏态分布。
print(df_train.info())
#关于work属性存在大量的数据缺失。
print(df_test.info())
#同样存在大量数据缺失。
dat=df_train.describe(percentiles=[],include='all').T
dat=dat[['min','max','mean','std']]
null_all = pd.DataFrame(df_train.isnull().sum()) #
print(dat)
print(null_all) #空值行的数目
print(y_train.value_counts()) #统计y_train中各个数值的数目,查看得到数据呈偏态分布
4 4818
5 1410
3 1159
2 497
1 104
-8 12
print(df_in['happiness'].value_counts()) #统计测试集的各个数值的数目,查看得到数据的值都为5
5 2968
3、作图查看数据
构造一个通用的画图函数,用于图表分析。
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负
#数据观察存在大量的负数,非正常情况,需要对负数进行处理。def plot_cm(x):
fig,axes=plt.subplots(2,2,figsize=(7,7))
ax1 = plt.subplot(2,2,1)
ax2 = plt.subplot(2,2,2)
ax3 = plt.subplot(2,2,3)
ax4 = plt.subplot(2,2,4)
plt.sca(ax1) #hist图
sns.distplot(x, hist=True,rug=True,kde=True,color="b")
sns.kdeplot(x,shade=True,color='r')
plt.sca(ax2) #箱线图
sns.boxplot(x)
plt.sca(ax3) #饼图
x.value_counts().plot.pie(autopct='%1.1f%%')
plt.sca(ax4)
sns.countplot(x) #柱状图
plt.show()
#选择需要作图分析的列
x=df_train['happiness'] #data数据
plot_cm(x)
4、数据处理
(1)缺失值处理
(2)异常值处理
(3)无用的列删除
(4)均一化处理
from sklearn.impute import SimpleImputer
ind1 = ['id','happiness','survey_time','inc_ability']
ind2= ['id','survey_time','inc_ability']
# 训练集样本中删除指定列数据
X = df_train.drop(ind1, axis=1)
df_train1 = SimpleImputer(fill_value=-1).fit_transform(X) #空值都设为-1
df_train1[df_train1 < 0] = -1 #小于0的数都设为-1
print(df_train1)
X_test=df_test.drop(ind2,axis=1)
df_test = SimpleImputer(fill_value=-1).fit_transform(X_test) #空值都设为-1
df_test[df_test<0]=-1 #小于0的数都设为-1
#均一化处理
from sklearn.preprocessing import StandardScaler
std = StandardScaler().fit(df_train1)
df_train_std = std.transform(df_train1)
print(df_train_std)
std = StandardScaler().fit(df_test)
df_test_std = std.transform(df_test)
print(df_test_std)
(5)样本均衡处理
训练集第4类占比最高。为保障数据拟合的正确性,对不均衡性进行处理。
# 导入第三方包
from imblearn.over_sampling import SMOTE
#运用SMOTE算法实现训练数据集的平衡
over_samples = SMOTE(random_state=0)
over_samples_X,over_samples_y = over_samples.fit_sample(df_train_std,y_train)
#over_samples_X, over_samples_y = over_samples.fit_sample(df_train_std.values,y_train.values.ravel())
#重抽样前的类别比例
print(y_train.value_counts()/len(y_train))
# 重抽样后的类别比例
print(pd.Series(over_samples_y).value_counts()/len(over_samples_y))
5、模型训练及预测
(1)随机森林拟合分析
#采用随机决策树进行预测
from sklearn.metrics import r2_score, mean_squared_error, mean_absolute_error
from sklearn.ensemble import RandomForestRegressor, ExtraTreesRegressor, GradientBoostingRegressor
rfr = RandomForestRegressor()
rfr.fit(over_samples_X,over_samples_y) #用均衡后的样本进行数据回归
print(y_train)
y_predict = rfr.predict(df_train_std) #对数据进行回归计算
print(y_predict)
#模型评估
#原函数拟合情况
print("随机森林回归的默认评估值为:", rfr.score(df_train_std, y_train))
print("随机森林回归的R_squared值为:", r2_score(y_train, y_predict))
print("随机森林回归的均方误差为:", mean_squared_error(y_train, y_predict))
print("随机森林回归的平均绝对误差为:", mean_absolute_error(y_train, y_predict))y_predict2 = rfr.predict(df_test_std)
print(y_predict2)
#建立评分公式score
score=sum(((y_predict2-df_in['happiness']))**2)/len(df_in['happiness'])
print(“score”,score)
分析结果:
随机森林回归的默认评估值为: 0.8851814141072505
随机森林回归的R_squared值为: 0.8851814141072505
随机森林回归的均方误差为: 0.07695292939409112
随机森林回归的平均绝对误差为: 0.18918377566349523
[3.8 2.8 3.2 ... 4.1 3.1 3.8]
score: 2.860010107816703
(2)xgboost预测与k折交叉验证
这块之前有错误,我对k折交叉验证这块理解不对,导致代码错误。
分析结果:2.91,xgboost预测结果一般。参数调优中。
6、提交结果
三、学习总结
1、对数据样本相关性的分析,需考虑样本的筛选。这块内容可考虑增加。
2、xgboost预测结果还可以,原理还不大明白;随机森林预测结果偏差较大。
3、对不均衡样本的处理,处理后可提高预测精度。
4、通用绘图函数的制作
5、几个预测期的组合。这块内容还需要继续学习。具体可参照https://blog.csdn.net/NUDTDING2019/article/details/92561488。