RLHF 回顾
instruct GPT
目的:使得模型输出和人类偏好输出对齐,提升模型安全性,正确性,流畅性等。
RLHF 原理以及训练过程:
- SFT(supervised fine-tuning)有监督微调:
- 过程:靠标注人员给出指定的高质量答案,来fun-tune GPT模型得到SFT模型
- 训练Reward模型:
-
随机采样一批promot:使用第一阶段fine-tuning的模型产生k个结果
-
由标注人员按照多重标注来进行综合排序
-
使用排序结果来训练pairwise的回报模型来得到Reward Model
- 使用强化学习PPO来优化回报模型:
-
数据:使用第一阶段和第二阶段模型结果不同的promot
-
初始化:由冷启动模型来初始化PPO模型的参数
-
PPO产生输出,reward-model来对整体单词序列进行评价,对PPO参数进行优化
目的:使回报模型产出高reward的答案,产生符合RM标准的高质量回答
第三阶段利用第二阶段的打分模型来优化,产生高reward的回答,类似利用伪标签来扩充高质量训练数据。来使得第二阶段的reward打分更准确
instruct GPT 训练细节
画一个流程图:

SFT过程:
微调细节:
- 使用LR schedule 使用原始学习率的10%,base模型越大,看起来学习率越小,微调batch越小。不使用warm-up策略。
- 16个epoch
- 调整学习率:学习率逐渐减小,有助于模型后续更好的收敛
- 残差丢弃率:防止模型过拟合,

RM-model训练细节:
https://blog.csdn.net/qq_56591814/article/details/130588064
- pairwise的训练方式防止过拟合
- 为什么使用排名学习,而不是打分?减弱不同标注员打分标准不一致的问题,减少噪声问题。
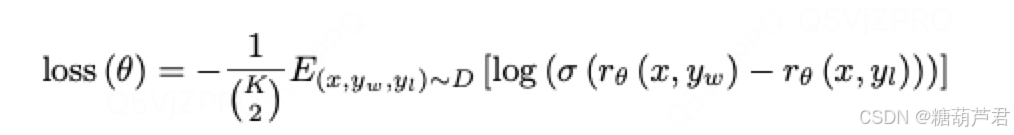
PPO训练细节:
1. 第一项:第一项中r为reward-model给RL模型输出的打分,由于在训练过程中,模型的输出会发生变化,所以reward-model的作用是减少标注成本,并且将reward-model的打分作为优化的基准。后面的KL散度是一个正则化项,用来防止RL-model与SFT-model偏离太远。
2. 第二项:如果只使用上述两项进行训练,会导致该模型仅仅对人类的排序结果较好,而在通用NLP任务上,性能可能会大幅下降。文章通过在loss中加入了GPT-3预训练模型的目标函数来规避这一问题。在预训练数据中进行采样,在RL模型上最大化GPT3与训练数据的概率。
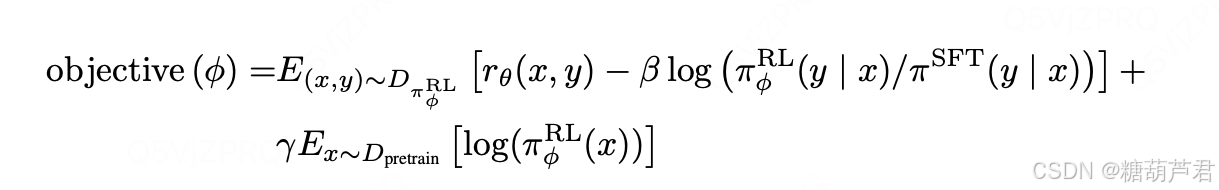
训练loss展开分析:
将loss中的第一项loss展开可以看到,其他它就是ppo 算法的loss,基于RM来最大化奖励,不断优化
π
R
L
′
\pi^{RL'}
πRL′, 同时使用KL散度来防止学习策略与SFT策略(基线策略)相差不太大。
将ppo loss进一步展开,使用的是PPO-clip的方式来防止每步迭代过程中学习策略
π
R
L
′
\pi^{RL'}
πRL′与上一步策略
π
R
L
\pi^{RL}
πRL偏移太多,将其限制在一定区间范围内,提升训练的稳定性。同时采用经验回放池和重要性采样提升数据利用效率。
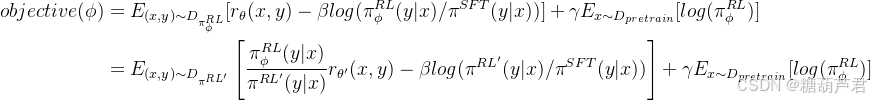
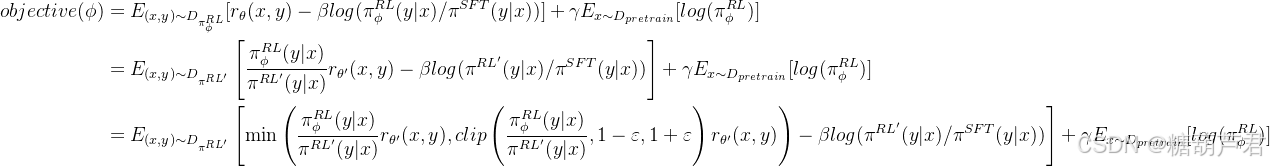
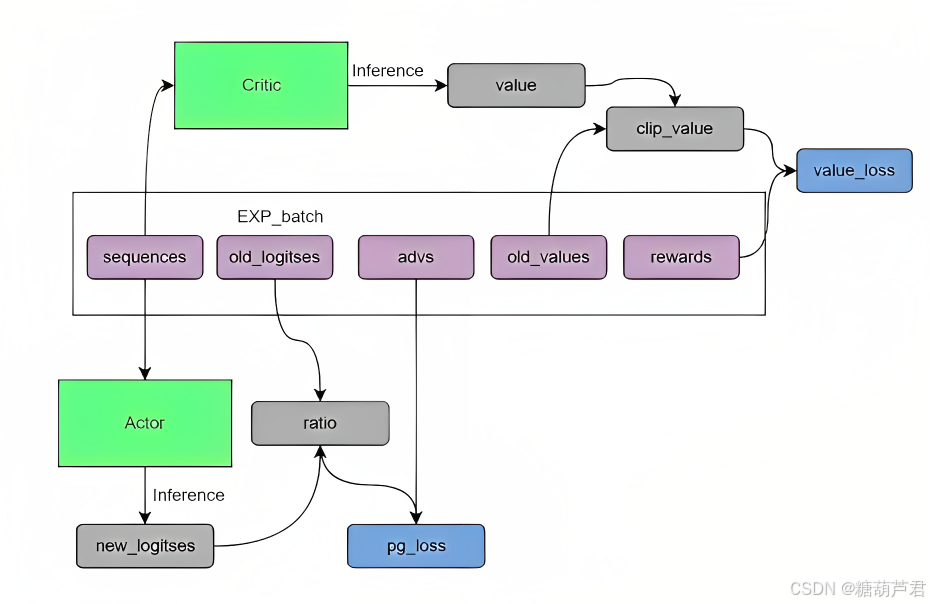
reward:
单个token的reward:
其中r除了reward-model的输出还有每个token对应的kl散度,防止过度优化
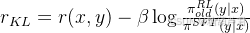
policy-loss:
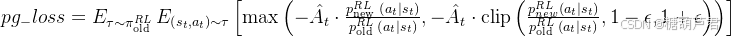
其中策略函数的奖励方式采用的是Advantage函数:
A
t
=
R
t
−
V
t
o
l
d
A_t =R_t - V_{t}^{old}
At=Rt−Vtold
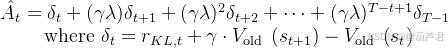
critic-loss:
拟合新价值函数value-function与累积回报reward(reward计算有两种方式)之间的差距,即
R
t
R_t
Rt 与
V
n
e
w
V_{new}
Vnew之间的差距(这里的t是训练步骤):
将
V
n
e
w
V_{new}
Vnew根据老模型进行约束
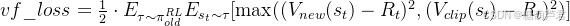
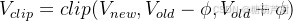
reward细节:
- reward是每个token计算一个还是整个序列生成之后计算?
这个细节在InstructGPT的论文只浅浅提了一嘴:“Given the prompt and response, it produces a reward determined by the reward model and ends the episode.”。幸运的是,上文提到过的这篇论文《Learning from summarize from Human feedback》中的一个引脚标注给出了这个疑问的答案。
论文里说,奖励模型只在最终生成回答之后才给出奖励,在中间的过程中是不给出奖励的(相当于不对序列的中间生成给予reward)
- 那么中间步骤token的奖励方式如何计算呢?
除了最终token有reward值,中间步骤token的reward的为0+kl散度,最终token的reward为reward+kl散度
(https://blog.csdn.net/jinselizhi/article/details/138963338)

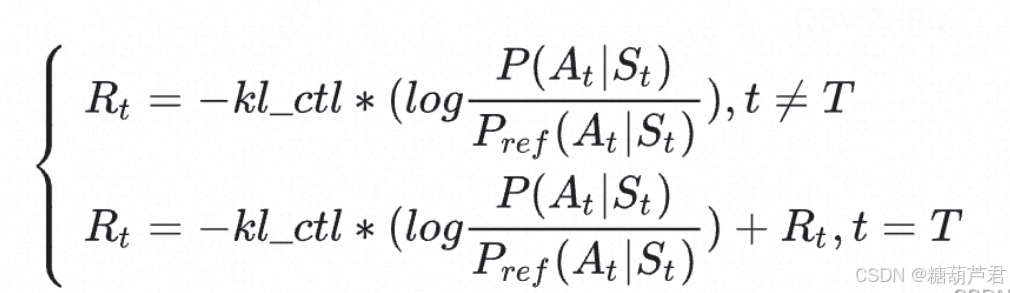
reward序列的计算方式:
- 基于蒙特卡洛的计算方式:
也就是直接从t步开始累积到最后的所有奖励,考虑了所有未来奖励,简单粗暴,不涉及到价值函数的估计。这种方式的好处是估计精准即偏差较小,因为它是根据实际的奖励路径计算的,但是方差较大,因为同一策略的不同奖励路径可能有很大的不同(比如环境具有随机性)。 - GAE(Generalized Advantage Estimation):
基于优势函数与价值函数之和计算每个时间步的回报:
优势函数:对未来所有时间步的TD误差(Temporal-Difference Error,也就是这里的
δ
\delta
δ)进行折扣求和.
TD误差:
δ
t
=
r
K
,
L
+
γ
V
o
l
d
(
s
+
1
)
−
V
o
l
d
(
s
)
\delta_t=r_{K,L}+\gamma V_{old}(s+1) - V_{old}(s)
δt=rK,L+γVold(s+1)−Vold(s)
A
t
=
δ
t
+
(
γ
λ
)
δ
t
+
1
+
(
γ
λ
)
2
δ
t
+
2
+
(
γ
λ
)
T
−
t
+
1
δ
T
−
1
A_t=\delta_t +(\gamma\lambda)\delta_{t+1} +(\gamma\lambda)^2\delta_{t+2}+(\gamma\lambda)^{T-t+1}\delta_{T-1}
At=δt+(γλ)δt+1+(γλ)2δt+2+(γλ)T−t+1δT−1
参数
γ
\gamma
γ用来控制对未来状态估计的衰减程度
考虑两者极端情况:
G
A
E
(
γ
=
0
)
:
A
t
=
r
K
,
L
+
γ
V
o
l
d
(
s
+
1
)
−
V
o
l
d
(
s
)
GAE(\gamma=0):A_t=r_{K,L}+\gamma V_{old}(s+1) - V_{old}(s)
GAE(γ=0):At=rK,L+γVold(s+1)−Vold(s)
G
A
E
(
γ
=
1
)
:
A
t
=
∑
l
=
0
∞
γ
l
δ
t
+
l
=
∑
l
=
0
∞
γ
l
r
t
+
l
−
V
(
s
t
)
GAE(\gamma=1):A_t=\sum^{\infty}_{l=0}\gamma^l\delta_{t+l}=\sum^{\infty}_{l=0}\gamma^lr_{t+l}-V(s_t)
GAE(γ=1):At=∑l=0∞γlδt+l=∑l=0∞γlrt+l−V(st)
γ
=
0
\gamma=0
γ=0: 一步的估计,等价于TD,偏差大,方差小
γ
=
1
\gamma=1
γ=1: 多步的估计,等价于MC, 偏差大,方差小
然后, R t R_t Rt基于 A A A来计算得到, R t = A t o l d + V t o l d R_t = A_t^{old} + V_{t}^{old} Rt=Atold+Vtold(这里的t为生成序列中token对应的顺序位置)
补充知识
问题
-
reward-model的训练过程:每个token都有一个reward进行训练吗?
不是,对序列对进行pairwise训练 -
policy:使用监督baseline进行初始化?是的
-
为什么使用预训练的数据呢
-
真值是什么? 如果是reward-model(训练好的话,那么如何提升呢)
将value-function作为actor的监督信号,value-function在训练过程是同时根据reward-model进行优化。 -
PPO的训练过程:
-
一共几个模型: 6个
Actor, Critic, Actor_old, Critic_old, SFT, reward-model -
ppo在截断loss时是仅仅改变loss值还是停止更新actor-net?
参考
-
https://blog.csdn.net/v_JULY_v/article/details/128579457
-
instruct-GPT论文:
-Training language models to follow instructions with human feedback -
instruct-GPT训练细节:https://blog.csdn.net/qq_56591814/article/details/130588064
-
incontext-learning原理:Why Can GPT Learn In-Context?
Language Models Implicitly Perform Gradient Descent as
Meta-Optimizers -
colossalChat:https://medium.com/pytorch/colossalchat-an-open-source-solution-for-cloning-chatgpt-with-a-complete-rlhf-pipeline-5edf08fb538b
-
GAE论文:https://arxiv.org/abs/1506.02438
-
General Advantage Estimation(GAE): https://blog.csdn.net/weixin_39891381/article/details/105153867
-
PPO调参:https://zhuanlan.zhihu.com/p/345353294