21年1月来自斯坦福大学的论文“Prefix-Tuning: Optimizing Continuous Prompts for Generation“。
调优实际上是利用大预训练语言模型执行下游任务的方法。然而,它修改了所有的语言模型参数,因此需要为每个任务存储一个完整的副本。本文提出了前缀-调优,一种用于自然语言生成任务的轻量级微调替代方案,它可以保持语言模型参数的冻结,但可以优化一个小的连续任务特定向量(称为前缀)。前缀调优从提示中汲取灵感,允许后续的tokens关注这个前缀,就好像它是“虚拟tokens”一样。将前缀调优应用于GPT-2,生成表-到-文本,并应用于BART做摘要。实验发现,只学习0.1%的参数,前缀-调优在完整的数据集中获得了可对比的性能,在低数据集中优于全调优方法,并能更好地外推到训练中未见主题的示例。
根据提示的直觉,拥有适当的上下文可以引导 LM 而不改变其参数。例如,如果希望 LM 生成一个单词(例如 Obama),可以将其常见搭配作为上下文(例如 Barack),然后 LM 将为所需单词分配更高的概率。将这种直觉扩展到生成单个单词或句子之外,希望找到一个引导 LM 解决 NLG 任务的上下文。直观地说,上下文可以通过指导从 x 中提取什么来影响 x 的编码;并且可以通过引导下一个token 分布来影响 y 的生成。但是,这样的上下文是否存在并不明显。自然语言任务指令(例如“用一句话总结下表”)可能会指导专家注释者解决任务,但对于大多数预训练的 LM 来说都是失败的。对离散指令进行数据驱动的优化可能会有所帮助,但离散优化在计算上具有挑战性。
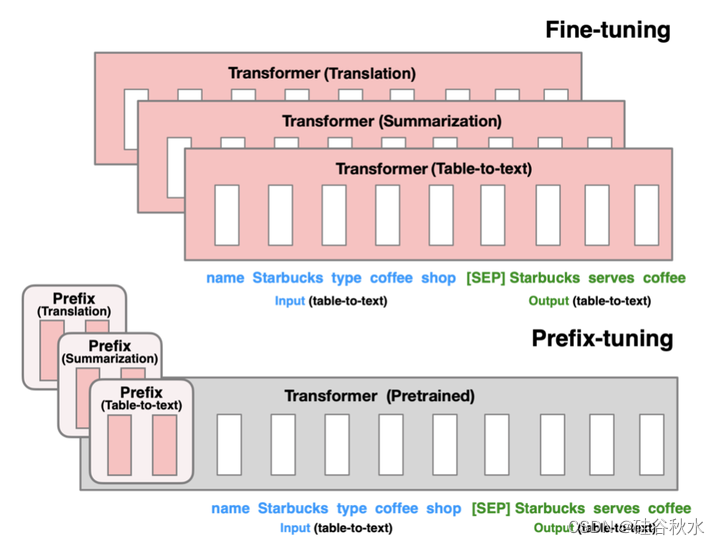
前缀-调优,这是自然语言生成 (NLG) 任务中微调的轻量级替代方案,其灵感来自提示。考虑生成数据表的文本描述的任务,如图所示,其中任务输入是线性化表(例如,“名称:星巴克 | 类型:咖啡店”),输出是文本描述(例如,“星巴克提供咖啡。”)。前缀-调优将一系列连续的任务特定向量添加到输入的前面,称之为前缀,在图(底部)中用红色块表示。对于后续token,Transformer 可以像处理“虚拟tokens”序列一样处理前缀,但与提示不同,前缀完全由与真实tokens不对应的自由参数组成。图(顶部)中的微调会更新所有 Transformer 参数,因此需要为每个任务存储经过调优的模型副本,而前缀-调优仅优化前缀。因此,只需要存储大型 Transformer 的一个副本和一个学习到的任务特定前缀,这样每个额外任务的开销就很小(例如,表格转文本的 250K 个参数)。
全调优(顶部)会更新所有Transformers参数(红色Transformer框),并需要为每个任务存储一个完整的模型副本。前缀-调优(底部)冻结Transformer参数,只优化前缀(红色的前缀块)。因此,只需要为每个任务存储前缀,使前缀调优模块化并节省空间。注意,每个垂直块表示在一个时间步长的Transformer激活。
与微调相比,前缀-调优是模块化的:训练一个上游前缀,它引导下游 LM,而 LM 保持不变。因此,单个 LM 可以同时支持多个任务。在个性化的背景下,任务对应于不同的用户(Shokri & Shmatikov,2015;McMahan,2016),可以为每个用户提供一个单独的前缀,仅根据该用户的数据进行训练,从而避免数据交叉污染。此外,基于前缀的架构甚至可以在单个批次中处理来自多个用户/任务的示例,这是其他轻量级微调方法无法实现的。
用 GPT-2 评估表格到文本生成中的前缀-调优,并使用 BART 评估抽象摘要。在存储方面,前缀-调优存储的参数比微调少 1000 倍。在使用完整数据集进行训练时的性能方面,前缀-调优和微调在表格到文本方面相当,而前缀-调优在摘要方面略有下降。在低数据设置下,前缀-调优整在两个任务上的平均表现都优于微调。前缀-调优还可以更好地推断出具有未见主题的表格(用于表格到文本)和文章(用于摘要)。
下图是一个自回归LM(顶部)前缀-调优和编码器-解码器模型(底部)的注释示例。前缀激活是从可训练矩阵中得出的。剩余的激活由Transformer计算。
对三个标准的神经生成数据集进行了评估,以完成表格转文本任务:E2E(Novikova,2017)、WebNLG(Gardent,2017)和 DART(Radev,2020)。数据集按复杂性和规模的增加排序。E2E 仅有 1 个域(即餐厅评论);WebNLG 有 14 个域,而 DART 是开放域,使用来自 Wikipedia 的开放领域表格。

对于表格到文本生成,将前缀-调优与其他三种方法进行了比较:微调(FINE-TUNE)、仅微调前 2 层(FT-TOP2)和适配器调整(ADAPTER)。还报告了以下这些数据集的当前最佳结果:在 E2E 上,Shen (2019)使用了一种实用信息模型,无需预训练;在 WebNLG 上,Kale(2020)对 T5-large 进行微调;在 DART 上,没有发布在此数据集版本上训练的官方模型。在摘要方面,与微调 BART 进行比较。
结果如下表所示:
