23年9月底Waye在arXiv上上传了其GAIA-1模型的技术论文“GAIA-1: A Generative World Model for Autonomous Driving“。
构建能够安全应对现实世界非结构化复杂场景的自动驾驶系统仍然具有挑战性。一个关键问题在于,随世界演进,如何有效地预测车辆行动可能产生的各种潜在结果。为了应对这一挑战,提出GAIA-1(“Generative AI for Autonomy”),这是一种生成世界模型,利用视频、文本和动作输入生成真实的驾驶场景,同时对自车行为和场景特征提供精细控制。其方法将输入映射到离散token,并预测序列中的下一个token,将世界建模视为一个无监督序列建模问题。该模型的涌现特性包括学习高级结构和场景动力学、上下文意识、泛化和对场景3-D几何的理解。GAIA-1的学习表达捕捉了对未来事件的期望,再加上其生成真实样本的能力,为自主驾驶领域的创新提供了新的可能性,从而增强和加速了自动驾驶技术的训练。
如图所示GAIA-1的体系结构:首先,将来自所有输入模态(视频、文本、动作)的信息编码为一个公共表示,图像、文本和动作被编码为一系列token;世界模型是一个自回归transformer,它以过去的图像、文本和动作token为条件来预测下一个图像token;最后,视频解码器以更高的时间分辨率将预测的图像token映射回像素空间。
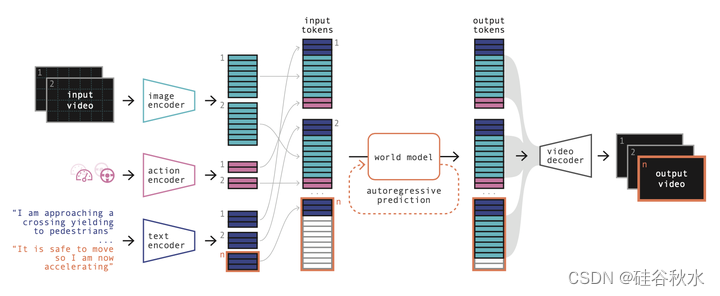
图像token化(0.3B参数)在分辨率为H×W=288×512(9/16比率)的图像上进行训练。编码器的空间下采样为D=16,因此每个图像被编码为n=18×32=576个离散token,词汇大小K=8192。比特压缩≈470。
该模型在4天内训练了20万步,批量大小等于160,分为32个A100 80GB GPU。用5k的线性预热和10k的余弦衰减。
世界模型(6.5B参数)是在频率6.25Hz、T=26大小的视频序列上训练的,这些视频序列对应于4s长的视频。文本被编码为每个时间步长m=32个文本token,动作被编码为l=2个token。因此,世界模型的总序列长度为T×(m+n+l)=15860。
世界模型在15天内训练了100k步,2.5k的线性热身和97.5k的余弦衰减使学习率在训练过程中降低了10倍。批量大小为128,分布在64个A100 80GB GPU中。
在Transformer模块中使用了FlashAttention v2的实现[41],因为其在内存利用率和推理速度方面都具有显著优势。为了优化分布式训练,使用了具有激活检查点的Deepspeed ZeRO-2训练策略[42]。
世界模型以先前的文本、图像和动作token为条件,自回归预测下一个图像标记。给定过去的token,执行n个正向步骤以生成一个新的图像帧。在每一步中,都必须从预测的logits中采样一个token,以选择序列中的下一个token。根据经验,观察到基于最大化的采样(即argmax)生成的未来token会陷入重复循环,类似于语言模型[44]。
相反,如果只是从logits中采样,那么所选的token可能来自概率分布的不可靠尾部区域,这会使模型脱离分布,见图所示:世界模型的复杂度(Perplexity)与生成的token的位置有关;考虑单个图像帧n=576个tokens,将真实图像中的token与以下策略生成的token其复杂度(Perplexity)进行比较:argmax、sampling或top-k。在(a)中,通过检查真实图像的复杂度(Perplexity),注意到它在低值和高值之间波动,这意味着这些token中存在很好的多样性;相反,如果观察argmax策略,会注意到复杂度只取极低值(没有多样性,表现在预测的帧中不断重复);还有,在(b)中,如果从整个分布中采样,由于从不可靠的尾部区域采样,一些token的复杂度可能会取极高值;在(c)中,观察到top-k=50采样产生的token具有与真实 token相似的复杂度分布。
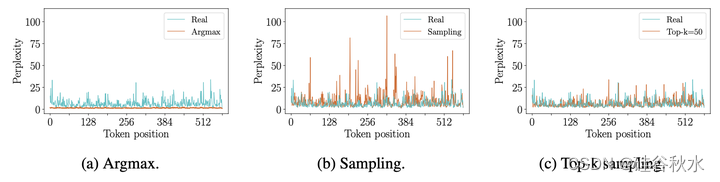
为了鼓励多样性和真实性,文中用top-k采样从top-k最可能的选择中采样下一个图像token。所选择的k值是构成图像帧的token数量以及预学习的码本(词汇)大小的函数。
世界模型可以用于在给定起始上下文的情况下推出可能的未来,也可以在没有任何起始上下文的条件下从头开始生成未来。对于长视频生成,如果视频的长度超过世界模型的上下文长度,将使用滑动窗口方法。
视频预测可以用文本来提示,并因此被引导。在训练时,用来自在线叙述或离线元数据源的文本来调节视频序列。由于这些文本源是不完美的,为了提高生成的未来和文本提示之间的一致性,在推理时采用无分类器引导方法[45,46]。引导的效果是减少可能样本的多样性来增加文本图像的对齐性。更准确地说,对于每一个要预测的下一个token,计算以文本为条件的logits以及无条件的logits。在推理时,可以用比例因子放大非文本条件logits和文本条件logits之间的差异,给出用于采样的最终logits。
将非条件logits替换为以另一个文本提示为条件的logits,可以执行“负(negative)”提示[47]。将logits从负提示推到正(positive)提示,会鼓励未来的token在删除“负”提示特征的同时包含“正”提示特征。
安排用于引导token和框架的比例因子很重要。通过对token进行调度,可以对一些token进行高引导采样(因此强烈遵守提示),对另一些token进行低引导采样(从而增加样本多样性)。对图像帧进行调度允许控制从先前帧的变换,以及减轻对后续连续帧的复合指导。如图所示:举例一个12帧的引导;通常用一个时间表对token进行采样,并对token进行线性递减引导,然后对未来帧进行余弦衰减降低引导,无论是否有初始停滞(plateau)。引导尺度和时间表是要根据特定用例进行调整的超参数。

GAIA-1中世界建模任务的公式与大语言模型(LLM)中经常使用的方法有共同点。两种情况下,任务都经过了优化,集中精力预测下一个token。尽管这种方法针对GAIA-1中的世界建模做适应,而不是LLM中的传统语言任务,但值得注意的是,类似于LLM中观察的规模化定律[49,21,27],也适用于GAIA-1。这表明规模化原理也适用于包括自动驾驶在内不同领域的现代人工智能模型。
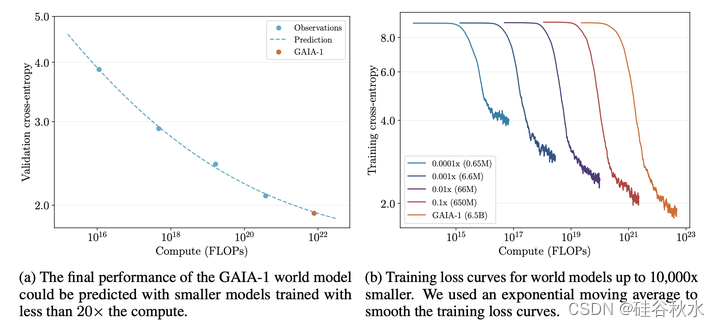
为了探索GAIA-1的规模化定律,文中用小于20倍计算量训练的模型来预测世界模型的最终性能。通过测量交叉熵,在一个固定的地理围栏验证集上评估了这些模型。
下图显示世界模型的验证和训练。如图a中,可以看到GAIA-1的最终交叉熵可以被高精度预测。如图b所示,用于拟合幂律的模型,在参数(0.65M到650M)方面从10000倍小的模型变化到10倍小的模型。与[49]类似,计算是作为参数数量的函数进行估计的。如果用C表示计算,用N表示参数数(不包括嵌入层),则单个token的前向-后向传递的浮点运算数量由C=6N给出。为了获得计算总量,将该值乘以训练token的数量即可完成。
最后一点,GAIA-1发生的以下涌现特性展示出其在世界生成规则达到了一定程度的理解和总结:
1.学习高级结构和场景动力学:生成连贯的场景,目标位于看似合理的位置,并展示真实的目标交互,如红绿灯、道路规则、让路等。这表明,该模型不仅是在记忆统计模式,而且是在理解支配世界中物体排列和行为的基本规则。
2.泛化和创造性:生成新的多样视频,超越训练集中的特定实例。可以产生训练数据中没有明确存在的目标、动作和场景的独特组合,显示出非凡的外推能力。这表明了一定程度的泛化和创造性,也表明理解了支配视频序列的潜生成规则。
3.上下文-觉察:GAIA-1可以捕捉上下文信息,并生成反映这种理解的视频。例如,可以基于所提供的初始条件或上下文在视频中生成连贯的动作和响应。此外,GAIA-1展示了对3D几何形状的理解,有效地捕捉了道路不规则性(如减速带)引起的俯仰和侧倾的复杂作用。这种上下文意识表明,模型不仅仅是在再现统计模式,而是在积极处理和总结给定的信息,生成适当的视频序列。